梯度下降(Gradient Descent)是深度學習中最核心的優化方法之一,它通過迭代更新模型參數,使得損失函數達到最小值,從而訓練出性能良好的神經網絡模型。
基礎原理
損失函數
在深度學習中,損失函數 L(θ) 是衡量模型預測值與真實值差距的函數,θ 表示模型參數。常見的損失函數包括:
-
均方誤差(MSE):適用于回歸問題
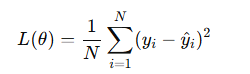
-
交叉熵損失(Cross-Entropy Loss):適用于分類問題
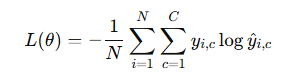
損失函數是梯度下降的優化目標,梯度下降通過計算損失函數對參數的偏導數,引導參數向最優值更新。
梯度與偏導數
梯度是多變量函數在某一點處的方向導數向量,它指向函數上升最快的方向。在深度學習中:
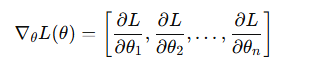
梯度下降通過沿梯度的反方向更新參數,使損失函數下降:
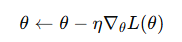
其中 η 是學習率(learning rate),控制每次更新的步長。
學習率的重要性
學習率 η 是梯度下降的核心超參數:
- 過大:可能導致訓練不收斂,甚至發散
- 過小:收斂速度慢,可能陷入局部最優
常用的策略包括:
- 學習率衰減(Learning Rate Decay):隨訓練輪數減小學習率
- 自適應學習率方法:如 Adam、RMSProp 等,自動調整每個參數的學習率
梯度下降算法及其變體
批量梯度下降(Batch Gradient Descent)
原理:每次迭代使用整個訓練集計算梯度更新參數。
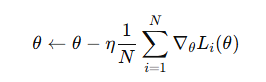
優點:
- 收斂穩定,方向正確
- 適合凸優化問題
缺點:
- 數據量大時計算量大,內存消耗高
- 對非凸優化容易陷入局部最優
隨機梯度下降(Stochastic Gradient Descent, SGD)
原理:每次迭代僅使用一個樣本計算梯度。
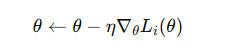
優點:
- 計算效率高,可處理大規模數據
- 可跳出局部最優,具有一定隨機性
缺點:
- 梯度波動大,收斂不穩定
- 需要設置較小的學習率以保證收斂
小批量梯度下降(Mini-batch Gradient Descent)
原理:每次迭代使用一小批數據計算梯度。
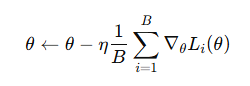
其中 B 為批大小(Batch Size)。
優點:
- 綜合了批量和隨機梯度下降的優點
- 可利用 GPU 并行計算,提高訓練效率
- 梯度波動適中,有利于跳出局部最優
缺點:
- 批大小選擇敏感,過小梯度噪聲大,過大收斂慢
動量法(Momentum)
動量法在更新參數時引入慣性項,緩解 SGD 的震蕩:
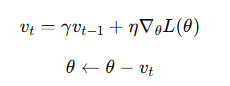
- γ 是動量因子(通常取 0.9)
- 優點:加速收斂,尤其在陡峭斜坡方向
- 類比物理:參數像有慣性的粒子在損失函數曲面上滾動
自適應學習率方法
AdaGrad
-
思路:根據參數歷史梯度調整學習率,小梯度方向加大步長,大梯度方向減小步長
-
更新公式:
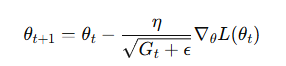
其中 Gt 為歷史梯度平方和矩陣,?\epsilon? 防止除零
缺點:學習率單調下降,可能過早停止
RMSProp
-
改進 AdaGrad,使用指數加權平均避免學習率過早減小
-
更新公式:
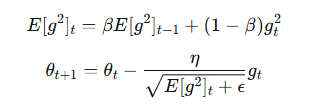
Adam
-
結合動量法和 RMSProp
-
利用一階矩估計和二階矩估計動態調整學習率
-
更新公式:
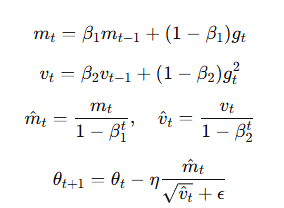
Adam 是目前深度學習中最常用的優化器之一,適合大多數場景。
梯度下降的挑戰與解決方案
梯度消失與爆炸
在深層神經網絡中,反向傳播可能導致梯度過小(消失)或過大(爆炸),影響收斂。原因包括:
- 梯度消失:如 sigmoid 激活函數在飽和區域導數接近 0。
- 梯度爆炸:梯度在深層網絡中累積放大。
局部極小值與鞍點
深度學習的損失函數通常是非凸的,存在局部極小值和鞍點。隨機梯度下降的噪聲有助于跳出局部極小值,而動量法和自適應優化器可加速逃離鞍點。
計算效率
深度學習模型涉及大量參數和數據,梯度計算成本高。解決方案包括:
- 分布式訓練:如數據并行和模型并行。
- 混合精度訓練:利用半精度浮點數(如 FP16)加速計算。
- 高效硬件:如 GPU、TPU 加速矩陣運算。
學習率選擇與調參
學習率的選擇對收斂至關重要。過大可能導致發散,過小則收斂緩慢。解決方案包括:
- 學習率搜索:如網格搜索或隨機搜索。
- 自動調參工具:如 Optuna 或 Ray Tune。
- 自適應優化器:如 Adam 減少手動調參需求。
梯度下降在深度學習中的應用
梯度下降廣泛應用于深度學習的各個領域,包括但不限于:
- 計算機視覺:
- 卷積神經網絡(CNN):如 ResNet、EfficientNet 用于圖像分類、目標檢測。
- 視覺 Transformer:如 ViT 用于圖像分割、圖像生成。
- 自然語言處理:
- 循環神經網絡(RNN):如 LSTM 用于序列建模。
- Transformer 模型:如 BERT、GPT 用于機器翻譯、文本生成。
- 強化學習:
- 深度 Q 網絡(DQN):優化策略函數。
- 策略梯度方法:如 PPO 用于機器人控制。
- 生成模型:
- 生成對抗網絡(GAN):優化生成器和判別器。
- 變分自編碼器(VAE):優化編碼器和解碼器。
- 推薦系統:如深度因子分解機(DeepFM)優化用戶偏好預測。
總結
梯度下降作為深度學習的核心優化算法,以其簡單性和高效性成為模型訓練的基石。從批量梯度下降到 Adam 等自適應優化器,梯度下降的變體和優化策略不斷演進,顯著提高了收斂速度和穩定性。然而,面對日益復雜的模型和任務,梯度下降仍需應對梯度消失/爆炸、計算效率和泛化能力等挑戰。








:常見組件和容器低代碼開發示例(ArkTS))

實踐:Istio在導購系統中的應用)







)
 算法原理)