一、Redis? DB
Redis 數據庫的數量在單機和集群模式下有根本性的區別。
1. 單機模式 (Standalone)
在單機模式下,Redis 默認提供?16 個邏輯數據庫,索引編號為?0 到 15。
選擇數據庫: 使用?
SELECT <index>?命令進行切換。例如,SELECT 0?使用第一個數據庫,SELECT 15?使用最后一個數據庫。配置數量: 這個數量可以通過修改 Redis 配置文件?
redis.conf?中的?databases 16?指令來增加或減少。重要特性: 這些數據庫是邏輯隔離的。它們在同一個 RDB/AOF 文件中持久化,由同一個 Redis 進程管理,但?
KEYS,?FLUSHDB,?SWAPDB?等命令只對當前選中的數據庫生效。
總結:單機模式默認有 16 個邏輯 DB,可配置。
2. 集群模式 (Cluster)
在官方 Redis Cluster 模式下,只有 1 個數據庫,即數據庫 0。
無法選擇: 嘗試使用?
SELECT?命令選擇任何非 0 的數據庫都會報錯。設計原因:
簡化設計:集群的核心目標是分片(Sharding),將數據分散到多個節點上。如果再支持多個邏輯數據庫,會使鍵分布、故障轉移和集群管理變得異常復雜。
命名空間隔離:在集群中,不同的業務數據應該通過鍵名前綴(如?
user:1001,?order:5002) 來進行區分和隔離,而不是使用不同的數據庫。
總結:集群模式強制使用且只能使用 DB 0。
對比表格
| 特性 | 單機模式 (Standalone) | 集群模式 (Cluster) |
|---|---|---|
| 數據庫數量 | 默認 16 個 (0-15),可配置 | 只有 1 個 (DB 0) |
SELECT?命令 | 支持,可切換數據庫 | 不支持,使用非 0 索引會報錯 |
| 設計目的 | 邏輯隔離不同應用的數據 | 數據分片與高可用 |
| 數據持久化 | 所有 DB 存儲在同一個 RDB/AOF 文件 | 每個節點的 DB 0 獨立存儲 |
| 使用建議 | 可用于隔離不同環境/應用的數據 | 必須使用鍵前綴來隔離數據 |
二、Redis持久化
1.為什么需要持久化
Redis 是一個基于內存的數據庫,所有數據都存儲在內存中。這使得它的讀寫速度極快。然而,內存是易失性的,如果發生服務器斷電、崩潰或進程退出,內存中的數據會全部丟失。
持久化的目的就是為了解決這個問題:將內存中的數據保存到磁盤等非易失性存儲中,以便在 Redis 重啟后能夠重新加載數據,防止數據丟失。
2.怎么持久化
redis兩種持久化機制。這兩種機制,其實是快照與日志的形式。
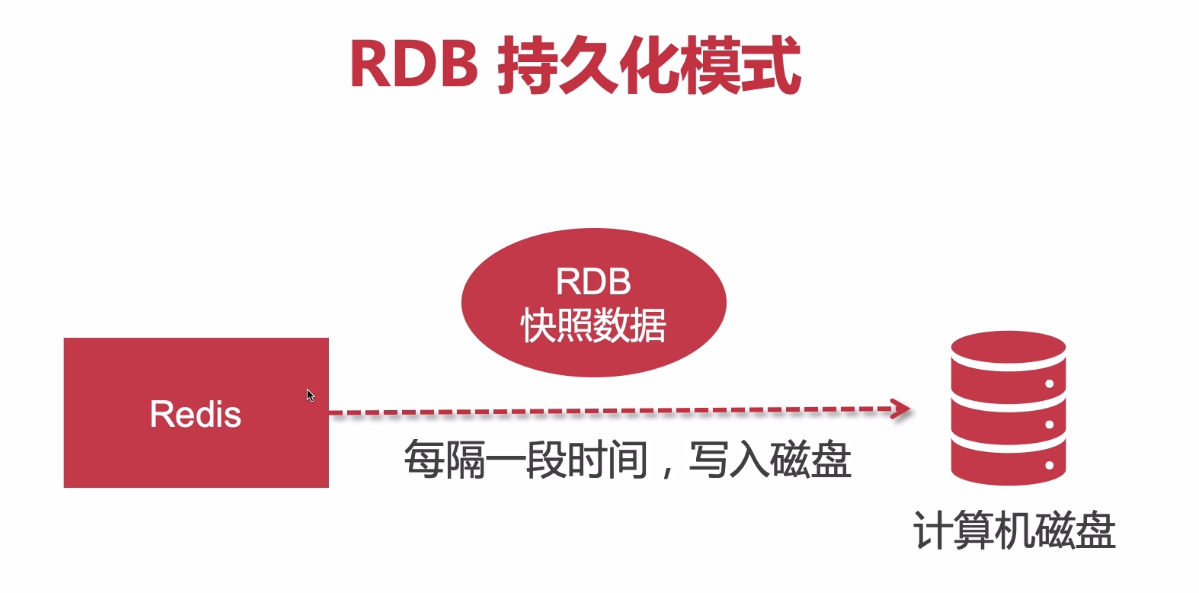
(1)快照RDB (Redis Database)
就是當前數據的備份,我可以拷貝到磁盤,也可以拷貝到別的服務器,如此一來,萬一現有redis的計算機節點被惡意攻擊或者被人刪庫跑路,那么你的原有數據還是可以恢復的。像你的云服務器也有快照功能,被人攻擊以后直接拿來恢復就行。它是一個緊湊的二進制文件(默認名為?dump.rdb)。是全量備份,也是Redis的默認備份方案。當redis恢復的時候會全量的恢復,此時redis處于阻塞狀態。
A.優點:
全量備份:每隔一段時間備份,全量備份,比較適合做冷備。
性能高:父進程不需要進行任何磁盤 I/O 操作,由子進程負責,對主服務性能影響極小。
文件緊湊:RDB 文件是二進制壓縮格式,非常適合災難恢復和備份。災備簡單,可以遠程傳輸到其他服務器
恢復速度快:恢復大數據集時,比 AOF 方式更快。
- 父子進程相互隔離:子進程備份的時候,主(父)進程的寫操作可以和子進程隔離,數據互不影響,保證備份數據的的完整性
B.缺點:
可能丟失更多數據:如果在下一次快照之前服務器宕機,從上一次快照之后的所有數據更改都會丟失。
fork 可能阻塞:如果數據集非常大,fork 子進程的過程可能會耗時較長,導致服務短暫停頓(毫秒級或秒級)。
- 子進程內存損耗:子進程會有一定的內存消耗,尤其是當有大量新的寫操作涌入的時候,那些都會有額外的內存開支
- 全量實時備份不適用:由于定時全量備份是重量級操作,所以對于實時備份的業務場景,就不適用了。
C.RDB的保存方式
問題:假設現在是凌晨1點開始備份,由于有時間損耗,01點鐘 05分產生了RDB文件保存到磁盤,那么會如下問題:
- 這個RDB文件的內容是凌晨1點的數據?
- 這個RDB文件內容是01點鐘05分的數據?
- 這個RDB文件內容是凌晨1點的數據,并且記錄了開始 備份到結束(1點到1點05分之間)的數據?
redis有兩種保存方式,一個是save命令,一個是bgsave命令
(1)save
備份rdb到磁盤,阻塞當前進程,redis不接受任何寫操作,
(2)bgsave
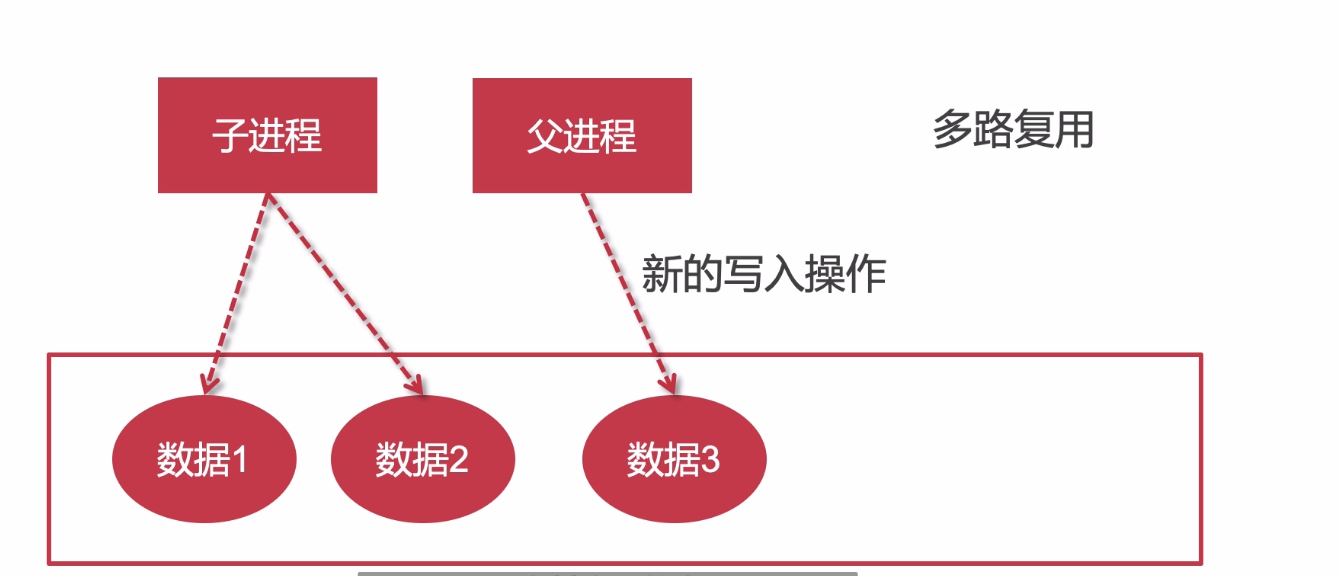
fork(創建)一個新的子進程,子進程把rdb數據寫入磁盤,寫操作由父進程去處理,兩個進程之間數據隔離,所以rdb的數據不會因為有新的寫操作而發生變化。
新的子進程指向的緩存數據和redis父進程一致,所以速度很快。(本質是指針,指向地址,而不是復制一個新的數據,所以父進程有新的寫操作是寫到新的內存地址,而子進程指向的地址不變)
通過?BGSAVE?命令在凌晨 1:00 開始創建的,由于?BGSAVE?是異步操作,它需要?Fork?一個子進程。Fork 操作完成后,子進程會擁有一個與父進程(主Redis進程)在 fork 那一刻完全一致的內存數據副本。子進程隨后將這個副本寫入 RDB 文件。
因此,RDB 文件的內容是開始執行?BGSAVE?命令后,成功完成 fork 操作那個瞬間的數據。 fork 操作非常快(通常如此),這個時間點非常接近凌晨 1:00,我們可以近似地認為是 1:00 的數據。但從嚴格的技術上講,它記錄的是 fork 成功那一刻的數據。
所以上面的問題:無論是?SAVE?還是?BGSAVE,RDB 文件都代表了創建過程開始后、某個瞬間的數據。對于配置的定時任務(比如在?crontab?里設置每天 1:00 執行),我們通常會說“這是凌晨 1 點的備份數據”。
提問:既然bgsave這么好用,為啥還設計一個save命令呢?
不論是開發游戲還是普通的項目,肯定會有維護期,那么在維護期的時候,就會用到save,直接阻塞,不讓新的數據寫入,游戲項目是最常見的,直接停服了,所有玩家等著新版本上線后才能重新進入。
D.RDB 自動保存機制
redis的核心配置有這么一段內容,這個是觸發bgsave的條件,他是自動的,滿足條件就會執行rdb的備份。(要注意,它是bgsave)

stop-writes-on-bgsave-error
- yes:如果save過程出錯,則停止寫操作
- no:可能造成數據不一致
rdbcompression
- yes:開啟rdb壓縮模式
- no:關閉,會節約cpu性能開支
rdbchecksum
- yes:使用CRC64算法校驗對rdb進行數據校驗,有10%性能損耗
- no:不校驗
dbfilename:rdb的默認名稱,可以自定 dump.rdb
(2)日志AOF (Append Only File)
A、解釋和特征
AOF其實就類似于我們開發系統的時候用戶的操作日志,這里指的是用戶的每次寫操作日志,比如增加key,修改key以及刪除key,這些命令,追加式備份,都會記錄下來形成一個日志文件。那么在需要恢復的時候,只需要執行這個日志文件里的所有命令,就能達到恢復數據的目的。以日志的形式記錄每一個寫操作命令(例如?SET,?SADD,?LPUSH),并在 Redis 重啟時通過重放這些命令來恢復數據。秒級別備份。
如果追求數據的一致性,RDB會丟失最后一次的備份數據,所以往往會采用AOF來做。AOF丟失的數據會比RDB相對來說少一些。
默認不開啟,需要在配置文件中設置?
appendonly yes。所有寫命令會追加到 AOF 文件的末尾。redis是先執行寫操作指令,隨后再把指令追加進aof中,追加的形式是append,一個個命令追加,而不是修改,
隨著寫入越來越多,AOF 文件會越來越大。Redis 提供了?AOF 重寫機制來壓縮文件。AOF文件的大小不直接與“時間”掛鉤,而是與期間發生的“寫操作”的數量和大小掛鉤。
從頭到尾恢復AOF:redis恢復的時候是讀取aof中的命令,從頭到尾讀一遍,然后數據恢復。
redis恢復的時候先恢復aof,如果aof有問題(比如破損),則再恢復rdb。
B、優點:
數據更安全:根據策略配置,最多丟失一秒的數據(
everysec)。所以AOF可以每秒備份一次,使用fsync操作。可讀性:AOF 文件是純文本格式,便于理解和手動修復(雖然不推薦)。
- 以log日志形式追加,如果磁盤滿了,會執行 redis-check-aof 工具。它的核心功能是檢查AOF文件的完整性,并修剪掉末尾不完整或格式錯誤的數據。
redis-check-aof --fix?命令修復AOF文件后再重啟。 - 當數據太大的時候,redis可以在后臺自動重寫aof。當redis繼續把日志追加到老的文件中去時,重寫也是非常安全的,不會影響客戶端的讀寫操作。
- AOF 日志包含的所有寫操作,會更加便于redis的解析恢復。
C、缺點
文件更大:通常 AOF 文件會比同期的 RDB 文件大。
恢復速度慢:恢復大數據集時,需要重新執行所有命令,比 RDB 方式慢。
性能影響:在寫入負載高時,AOF 對性能的影響通常比 RDB 大。針對不同的同步機制,AOF會比RDB慢,因為AOF每秒都會備份做寫操作,這樣相對與RDB來說就略低。 每秒備份fsync沒毛病,但是如果客戶端的每次寫入就做一次備份fsync的話,那么redis的性能就會下降。
D、AOF大文件問題
 假如,假如某一天redis宕機掛了
假如,假如某一天redis宕機掛了
- 這個10年的AOF有多大?最大可以占用多少空間?有沒有可能達到10來個T,或者更大?
按理說會,如果你吃飽了沒事做,就只對某個key,新增,修改,刪除,無限次的做這樣的操作,持續了十來年,那么這個aof文件會很大,而且都是重復的命令。但是AOF可以壓縮重寫,使得體積不大。
一個積累了10年、從未進行過重寫的AOF文件,對于一個寫入頻繁的大型系統來說,達到10TB是完全合理的,甚至可能更大。這凸顯了定期執行BGREWRITEAOF(通常通過配置auto-aof-rewrite-percentage和auto-aof-rewrite-min-size來自動執行)對于Redis生產運維是絕對必要的。放任AOF無限增長是一種運維事故。
- 恢復10T文件的時候,內存不大會不會溢出?
不會。雖然文件很大,但是有效的命令實際的不會很多。而且可以壓縮重寫,這樣體積不大,讀取肯定更加快速。
- 10T的aof恢復需要多久,有沒有可能幾個月,甚至1年?
按照現有情況來說,有可能吧。恢復時間極長是肯定的,但“幾個月或一年”在典型的服務器硬件上是一個過于極端和悲觀的估計。更可能的時間范圍是幾天到幾周,但這完全取決于硬件性能和一個關鍵因素:AOF文件中的操作類型。在使用了高性能NVMe SSD,并且AOF文件是經過重寫、相對精簡的情況下,恢復10TB的AOF可能需要幾十個小時(2-4天)。
以上三點都是aof文件龐大而出現的顧慮,其實aof可以重寫,對日志有一個重寫機制bgrewriteaof,其實也就是瘦身的作用
E、AOF 重寫 (AOF Rewrite):
目的:去除冗余命令,用最小命令集合重建當前數據集狀態。例如,對一個 key 先后執行了 100 次?
INCR,重寫后只需記錄一條?SET key 100。觸發:手動執行?
BGREWRITEAOF?或自動根據配置(auto-aof-rewrite-percentage,?auto-aof-rewrite-min-size)觸發。過程:與?
BGSAVE?類似,也是 fork 一個子進程在后臺完成,不會阻塞主進程。
F、同步策略 (appendfsync):這是影響性能和數據安全性的關鍵配置。

always:每個寫命令都同步刷寫到磁盤。數據最安全,性能最差。
everysec:每秒同步一次。平衡了性能和安全,是默認推薦配置。最多丟失 1 秒鐘的數據。
no:由操作系統決定何時同步。性能最好,但數據最不安全。
# AOF 默認關閉,yes可以開啟
appendonly no# AOF 的文件名
appendfilename "appendonly.aof"# no:不同步
# everysec:每秒備份,推薦使用
# always:每次操作都會備份,安全并且數據完整,但是慢性能差
appendfsync everysec# 重寫的時候是否要同步,no可以保證數據安全
no-appendfsync-on-rewrite no# 重寫機制:避免文件越來越大,自動優化壓縮指令,會fork一個新的進程去完成重寫動作,新進程里的內存數據會被重寫,此時舊的aof文件不會被讀取使用,類似rdb
# 當前AOF文件的大小是上次AOF大小的100% 并且文件體積達到64m,滿足兩者則觸發重寫
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
但是這個64MB如何確認了,萬一瘦身后,本來就應該高于64MB。
第一、想象一個全新的Redis實例,啟動后寫入了僅僅1MB的數據。如果沒有這個最小size限制,只要AOF文件大小翻倍(達到2MB,滿足100%的增長),就會觸發重寫。重寫本身是有成本(fork、I/O、CPU)的,為了節省這區區1MB的空間而進行重寫是得不償失的。64MB這個值意味著Redis認為,只有當你的數據量已經達到一定規模(至少64MB)時,重寫帶來的收益才值得付出這個成本。
第二、64MB是Redis社區經過長期實踐得出的一個經驗值,它對絕大多數開發測試環境和小型生產環境都是一個安全且合理的起點。它確保了一個非常小的Redis實例不會自己折騰自己。
第三、“萬一壓縮后的本來就是高于64會怎么辦?”這個問題其實是一個誤解。觸發判斷依據的是當前舊AOF文件的大小,而不是重寫后新AOF文件的大小。“壓縮后高于64MB”是正常且普遍的情況。64MB只是一個觸發重寫的下限門檻,而不是重寫后文件大小的上限。只要你的數據集本身大于64MB,重寫后的文件也必然大于64MB。
第四、壓縮后的長時間高于64MB,這樣就會不停地觸發重寫,重寫本身是有成本(fork、I/O、CPU)的。折舊這就說明你該調參了。
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 200MB第五、如果AOF追加磁盤滿了,會怎么樣?Redis主進程在嘗試執行write系統調用,向AOF文件追加命令時,操作系統會返回一個錯誤(如ENOSPC),告知磁盤空間已滿。
(3)AOF與RDB的混合持久化(4.x后的新特性)

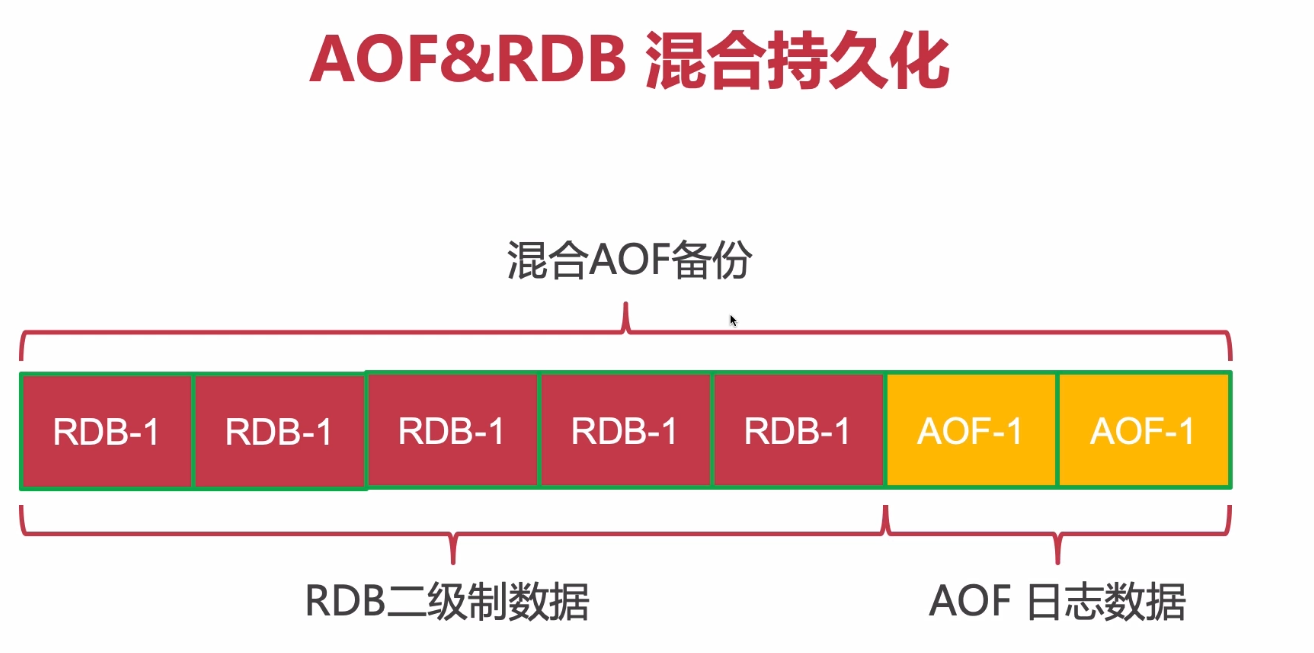
- yes:AOF重寫,redis會把當前所有的數據以rdb形式存入到aof中,這都是二進制數據,數據量小,隨后新的數據以aof形式追加到這個aof中,那么這個aof中包含兩種文件類型數據,一個是rdb,一個是aof,那么恢復的時候redis會同時恢復,這樣恢復過程會更快。這相當于是一個混合體。
- no:關閉混合模式,aof只會壓縮重復的命令,這是4.x以前老版本的機制,也就是把重復的沒有意義的指令去除,減少文件體積,也減少恢復的時間。
在重寫AOF的時候,如果有新的命令進來要寫入怎么辦?那么他其實也會fork一個子進程,子進程復制重寫,而新的那些寫入命令會被記錄到一個緩沖區,待子進程重寫完畢后,緩沖工區的新的寫命令會被追加到新的AOF文件中,這樣就保持了數據在重寫前后的一致性。
(3).修復損壞AOF文件
上面也講了損壞情況
redis-check-aof --fix [aof文件名]
目的:刪除不符合語法的指令
aof-load-truncated yes:Redis啟動加載aof,命令語法不完整則修復。設置為no,Redis啟動失敗,需要手動用redis-check-aof 工具修復
(4)生產環境推薦策略
通常,為了在性能和安全性之間取得最佳平衡,建議同時開啟 RDB 和 AOF:
使用 RDB:定期做冷備,用于快速恢復和歷史歸檔。
使用 AOF:使用?
appendfsync everysec?策略,保證最多只丟失一秒的數據。
這樣,在 Redis 重啟時:
如果 AOF 文件存在,優先加載 AOF 文件(因為它的數據更完整)。
如果 AOF 文件不存在,則加載 RDB 文件。
如果說用戶對redis的寫操作不多甚至沒有,95%以上都是讀操作,那么用rdb也沒啥問題。我們有一個項目是采用的緩存預熱方式,用戶幾乎沒有寫操作,所以直接采用RDB就夠用了,因為哪怕redis掛了,甚至RDB沒了,數據還是能通過預熱重新載入。
如果說你們的Redis要作為一部分的數據庫來使用,那么需要用到aof,或者rdb&aof的混合模式,這樣數據的完整性就更大了。

)









生成 PPT 的完整流程)
:適合存儲對象的數據結構,優勢與坑點解析)



相關)


