1) 深入剖析:核心方法與圖示(Figure)逐一對應
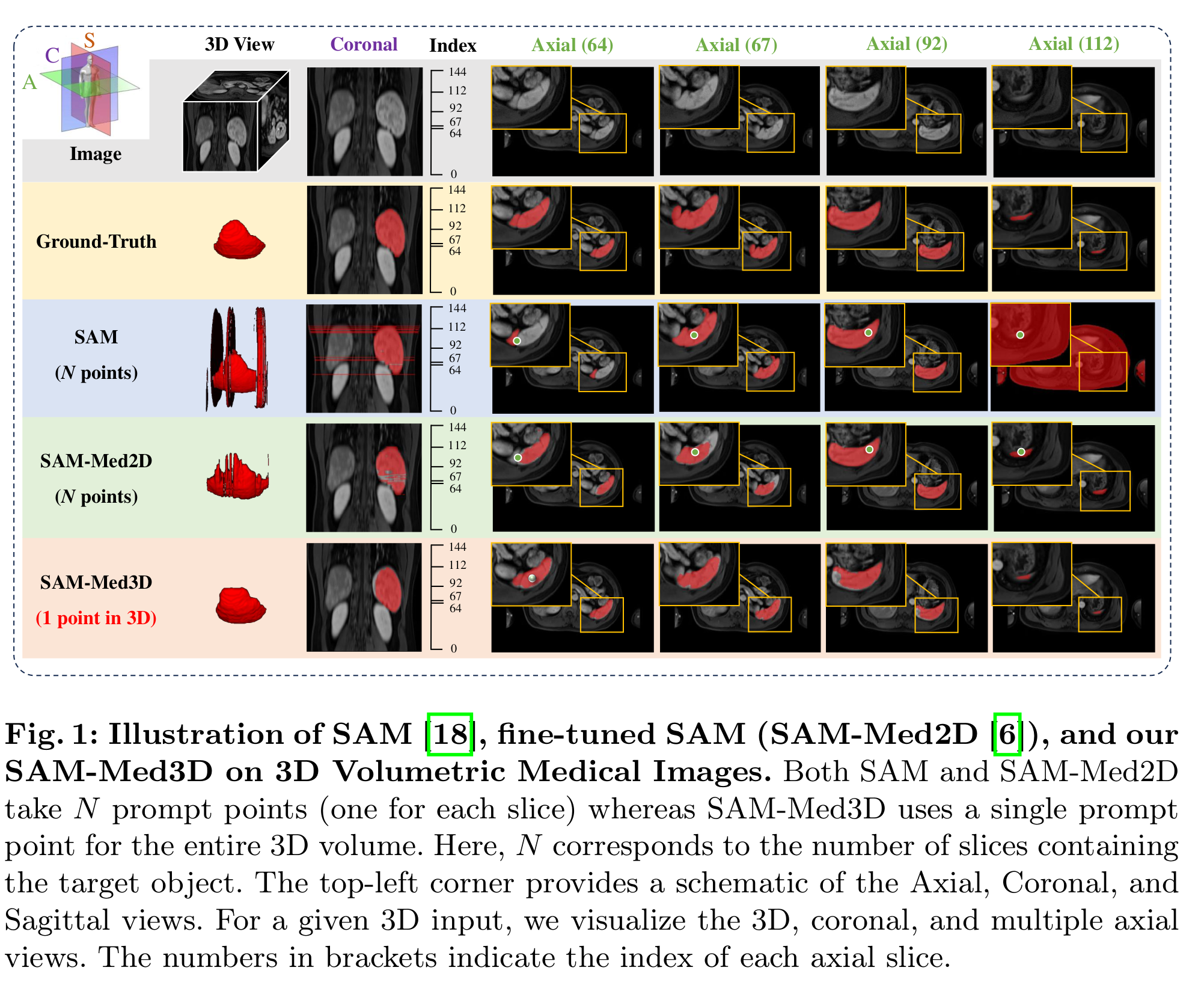
1.1 單點三維提示的任務設定(Figure 1)
- 論文首先將3D交互式分割的提示形式從“2D逐片(每片1點,共N點)”切換為“體素級單點(1個3D點)”。Figure 1直觀對比了 SAM(2D)/SAM-Med2D 與 SAM-Med3D(1點/體) 的差異:前兩者對體數據需 N 個逐片點,而 SAM-Med3D 對整卷僅需一個三維點,顯著減少交互負擔。
- 圖中還標注了軸位/冠狀/矢狀多視角展示,強調體素級提示對整體三維空間一致性的正向作用。
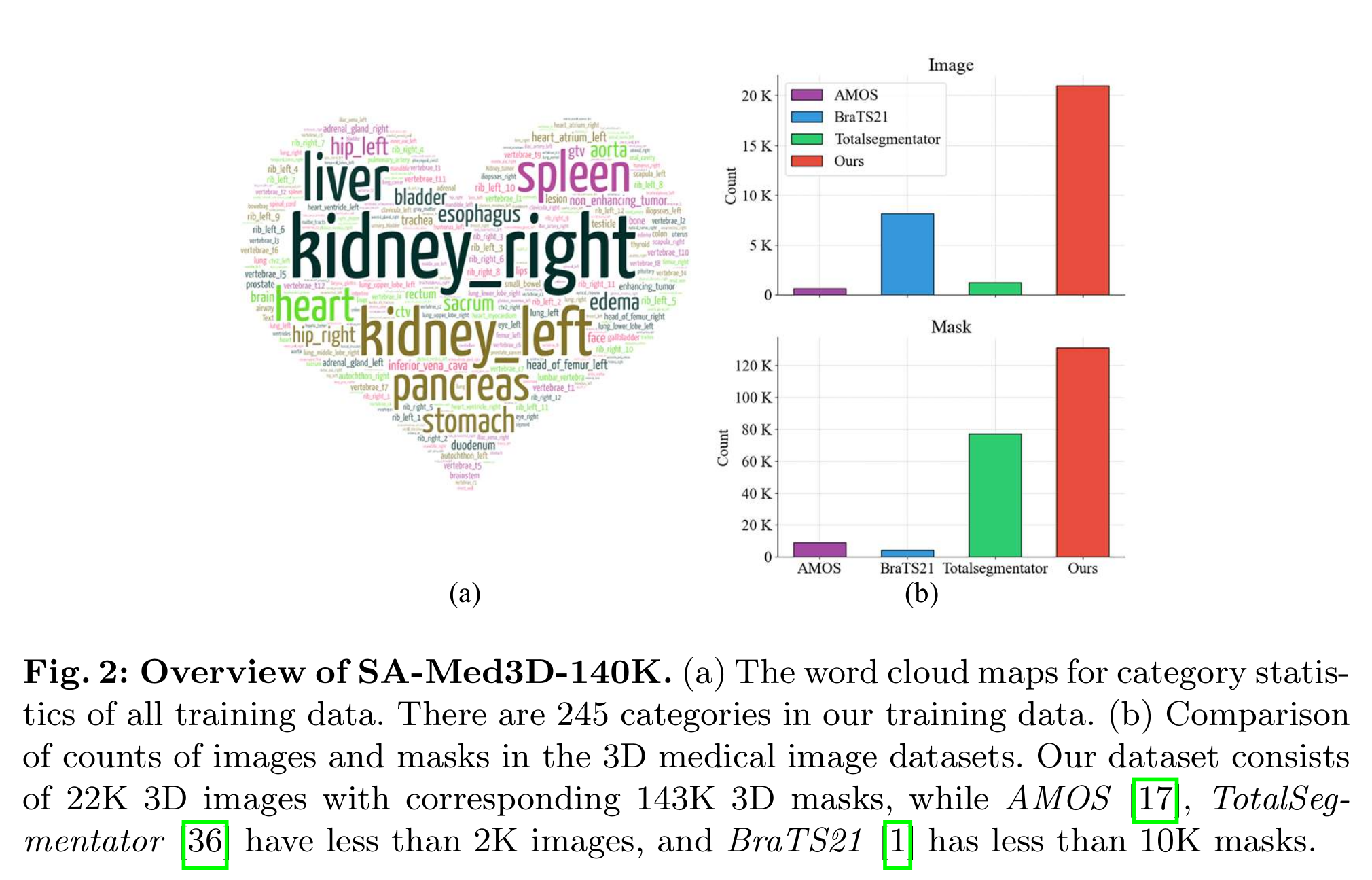
1.2 訓練數據與規模(Figure 2)
- 為支撐“通用型”能力,作者構建了 SA-Med3D-140K:共 22K 體數據、143K 3D mask、245 類別,來源于 70 個公開與 24 個私有數據集(并輔以清洗與歧義消解流程;見圖中流程與詞云示意)。
- Figure 2(b) 對比了該數據與 AMOS、TotalSegmentator、BraTS 等常用集的數量級差異,凸顯其“大而全”的覆蓋面。
1.3 端到端純三維架構(Figure 3)
Figure 3 給出了 SAM-Med3D 的三維化 ViT 架構:由 3D 圖像編碼器、3D 提示編碼器、3D 掩碼解碼器三部分組成,并在各處使用 3D 絕對位置編碼(3D Abs PE)、3D 多頭自注意力(MSA)、3D MLP / 3D LayerNorm / 3D Conv 等三維算子,以原生三維方式建模體空間關系。
- 3D 圖像編碼器:將 [H, W, D] 體數據分塊嵌入后,經堆疊的 3D 自注意力 + 3D MLP 模塊提取三維上下文特征(圖中“3D Attention Block”“Transformer Block×2”“3D MLP×2”等標注)。
- 3D 提示編碼器:把 3D 點 (x,y,z) 編為提示向量,配合 Q/K/V 與 3D 相對/絕對位置編碼,使提示與體特征在三維空間對齊(圖中“3D Rel/Abs PE”“Q K V”“Prompt Embeddings”)。
- 3D 掩碼解碼器:接收圖像/提示特征,輸出體素級 mask(圖中“3D Mask Decoder / Mask / Prediction”),完成少點交互→三維掩碼的映射。
- 設計動機:作者比較了三種將 SAM 遷移到3D的方式(逐片聚合;2D主干+3D adapter;純3D從頭訓練)。表2 的預實驗結論是:adapter 在“












與LED點陣驅動原理)




——靜態方法)

)