一 數據建模綜述
1.1 為什么要數據建模
-
背景:
隨著DT時代的來臨,數據爆發式增長,如何對數據有序,有結構地分類組織額存儲是關鍵 -
定義:
數據模型時數據組織和存儲的方法,強調從業務、數據存取、使用角度 合理存儲數據 -
優點:
- 性能-幫助我們快速查詢數據,減少數據I/O吞吐
- 成本-減少不必要的數據冗余,降低大數據系統的存儲和計算成本
- 效率-改善用戶使用數據的體驗,提高數據使用效率
- 質量-改善數據統計口徑的不一致性,減少數據計算錯誤的可能性
數據建模方法能幫助我們更好地組織和存儲數據,以便在性能、成本、效率、質量之間取得平衡。
數據建模的作用,我認為這和我們管理自己的知識體系一樣,我們的知識體系講究層級和網狀并存,來實現我們了解的信息既能夠準確分類,又能夠連接產生新的想法,產生知識創新,我認為數據建模就是為了使得信息高效流通,是一個不斷萃取的過程,從數據到信息,再到知識,最重是智慧,一句話就是一個知識管理模型
1.2 關系數據庫系統和數據倉庫
不管是Hadoop、Spark還是阿里巴巴的MaxComputer系統,仍然使用sql進行數據加工,使用table存儲數據,使用關系理論描述數據之間的關系,只是在大數據領域,基于數據存取特點在關系數據模型的范式上有了不同的選擇
關于大數據領域的建模基礎可供參考《數據庫系統概念》
1.3 從OLAP和OLTP的區別看模型方法論的選擇
-
OLTP:OLTP系統通常面向數據操作的隨機讀寫,主要采用滿足3NF的實體關系模型存儲數據,從而在事務處理中解決數據的冗余和一致性問題
-
OLAP:OLAP系統面向主要數據操作是批量讀寫,事物處理中的一致性不是OLAP所關注的,主要關注數據的整合,以及在一次性的復雜大數據查詢和處理中的性能,因此它需要采用一些不同的數據建模方法
1.4 典型的數據倉庫建模方法論
1.4.1 ER模型(實體關系模型,符合3NF)
數倉中的ER模型是站在企業的角度上,使用3NF來整合數據,將各個系統中的數據以整個企業角度按主題進行相似性組合和合并,并進行一致性處理,為數據分析決策服務,但是并不能直接用于分析決策.
OLAP中的ER模型是站在企業角度面向主題的抽象,而不是針對某個具體業務流程的實體對象關系抽象
-
特點
- 需要全面了解企業業務和數據
- 實施周期非常長
- 對建模人員的能力要求非常高
-
建模步驟分為3步:
- 高層建模:一個高度抽象的模型,描述主要的主題以及主題間的關系,用于描述企業的業務總體概況
- 中層建模:細化主題的數據項
- 物理建模:在中層模型基礎上,進行物理建模,比如表的合并、分區設計等
1.4.2 維度模型
- 適合場景
- 從分析決策的需求出發構建模型,為分析服務,重點關注用戶如何更快速完成需求分析,同時具有較好的大規模復雜查詢能力
- 典型代表是:星型模型、雪花模型
- 構建步驟
- 選擇需要分析決策的業務過程(業務過程可以是單個業務事件,也可以是事件的狀態,也可以是一系列相關業務事件。具體要看我們分析的是某事件發生情況,還是當前狀態,或是事件流轉效率
- 選擇粒度,即一行數據
- 識別維度
- 選擇事實。確定分析需要衡量的指標
1.4.3 Data Vault模型
-
ER模型的衍生,目的是為了是實現數據的整合,但不能直接用于數據分析決策。強調建立一個可審計的基礎數據層,也就是強調數據的歷史性、可追溯性、原子性,而不要求對數據進行過度的一致性處理和整合,同時基于主題概念將企業數據進行結構化組織,并引入更進一步的范式處理來優化模型,來應對源系統變更的擴展性。
-
組成
- Hub:企業的核心業務實體。由實體key、數據倉庫序列代理鍵、裝載時間、數據來源組成
- Link:代表Hub之間的關系,與ER模型最大的區別是將關系作為一個獨立的單元抽象,可以提升模型的擴展性
- Satellite:描述Hub的詳細描述內容,一個Hub可以有多個Satellite
-
核心:Hub 可以想象成人的骨架, Link 就是連接骨架的韌帶,而 SateIIite 就是骨架上面的血肉
1.4.4 Anchor模型
-
是對Data Vault模型做進一步規范化處理,為了高度可擴展的模型,核心思想是所有擴展知識田間而不是修改,模型規范到6NF,基本變成k-v結構化模型
-
組成
- Anchors:代表業務實體,且只有主鍵
- Attributes:將其全部k-v結構化,一個表只有一個Anchors的屬性描述
- Ties:類似于Data Vault的Link,提升模型的擴展能力
- Knots:屬性
1.5 阿里巴巴數據模型實踐綜述
阿里選擇維度建模為核心理念的模型方法論,同時對其進行一定的升級和擴展
數據公共層建設的目的是著力解決數據存儲和計算的共享問題
阿里巴巴數據公共層建設的指導方法是一套統一化的集團數據整合及管理的方法體系,集團內部成為‘OneData’,其包括一致性的指標定義體系、模型設計方法體系以及配套工具
二 阿里巴巴數據整合及管理體系
2.1. 概述
-
構建統一、規范、可共享的全域數據體系,避免數據的冗余和重復建設,規避數據煙囪和不一致性,充分發揮阿里巴巴在大數據海量、多樣性方面的獨特優勢
-
核心 :從業務架構設計到模型設計,從數據研發到數據服務,做到數據可管理 、可追溯、可規避重復建設
-
定位: 建設統一的、規范化的數據接入層(ODS)和數據中間層(DWD和DWS),通過數據服務和數據產品,完成服務于阿里巴巴的大數據體系建設,即數據公共程建設。提供標準的(Standard)、共享的(Shared)、數據服務(Service)能力,降低數據互通成本,釋放計算、存儲、人力等資源,以消除業務和技術之痛
-
體系架構
- 業務板塊
- 規范定義: 根據行業數據倉庫建設經驗和公司數據自身特點,設計出一套數據規范命名體系,規范定義將會被用在模型設計中
- 模型設計: 以維度建模理論為基礎,基于維度建模總線架構,構建一致性的維度和事實(進行規范定義)。同時,在落地表模型時,基于公司自身業務特點,設計一套表現規范命名體系
2.2 規范定義
-
規范定義:指以維度建模作為理論基礎 構建總線矩陣,劃分和定義數據域、業務過程、維度、度量 原子指標、修飾類型、修飾詞、時間周期、派生指標。
-
名詞術語:數據域、業務過程、時間周期、修飾類型、修飾詞、度量/原子指標、維度、維度屬性、派生指標
-
指標體系
- 基本原則:組成體系之間的關系,原子指標 + 時間周期修飾詞 + 其他修飾詞 = 派生指標
- 操作細則
- 了解原子指標、派生指標、修飾詞、時間周期
- 命名約定
- 算法:原子指標、修飾詞、派生指標的算法的計算邏輯
- 派生指標的種類
- 事物型指標:對業務活動進行衡量的指標。如訂單支付金額,商品數…
- 存量型指標:指對實體對象某些狀態的統計
- 復合性指標:在事物型指標和存量型指標的基礎上復合而成的,一般是什么什么率,占比
- 其他規則
2.3 模型設計
阿里巴巴數據公共層設計理念主要以維度建模理論為基礎,基于維度數據模型總線架構,構建一致性的維度和事實。
指導理論遵循維度建模思想,可參考 Star Schern The Complete Reference The Dαtα Warehouse Toolkit-The Definitive Guide to Dimensional Modeling。
2.3.1 模型層次
-
操作數據層(ODS)
- 同步:結構化數據增量或全量同步到集群
- 結構化:非結構化(日志)結構化處理并存儲集群
- 累計歷史、清洗:根據數據業務需求及稽核和審計要求保存歷史數據、清洗數據
-
公共維度層(CDM),又分為明細數據層(DWD)、匯總數據層(DWS)
存放明細事實數據、維表數據及公共指標匯總數據 其中明細事實數據、維表數 一般根據 ODS 層數據加工生成 :公共指標匯總數據 般根據維表數據和明細事實數據加工生成。明細數據層和匯總數據層,采用維度模型方法,更多采用一些維度退化手法,將維度退化至事實表中,減少事實表和維表的關聯,提高明細數據表的易用性;同時在匯總數據層,加強指標的維度退化,采取更多的寬表化手段構建公共指標數據層,提高公共指標的復用性,較少重復加工
-
ADS層
存放數據產品個性化的統計指標數據,根據CDM層和ODS層加工生成
數據調用服務優先使用公共維度模型層( CDM)數據,當公共層沒有數據時,需評估是否需要創建公共層數據,當不需要建設公用的公共層時,方可直接使用操作數據層( ODS )數據。應用數據層( ADS)作為產品特有的個性化數據,一般不對外提供數據服務,但是 ADS 作為被服務方也需要遵守這個約定。
2.3.2 基本原則
-
- 高內聚和低耦合
-
- 核心模型與擴展模型分離
-
- 公共處理邏輯下沉及單一
-
- 成本與性能平衡
-
- 數據可回滾
-
- 一致性
-
- 命名清洗、可理解
2.4 模型實施
模型的實施主要關注 如何從具體的需求或項目轉換為可實施的解決方案,如何進行需求分析、架構設計、詳細模型設計等
2.4.1 業界常用的模型實施過程
- Kimball模型
- 步驟1: 探討需求分析
- 步驟2:高層模型設計 定義業務過程維度模型的范圍,提供每種星形模式技術和功能描述。產出目標是創建高層維度模型圖,它是對業務過程中的維表和事實表的圖形描述,確定維表創建初始屬性列表,為每個事實表創建提議度量
- 步驟3:詳細模型設計 對每個星形模型添加屬性和度量信息。是為了給高層模型填補缺失信息,解決設計問題,并不斷測試模型是否能滿足業務需求,確保模型的完備性。確定每個維表 的屬性和每個事實表的度量,并確定信息來源的位置、定義、確定屬性和度量如何填入模型的初步業務規則
- 步驟4:模型審查、再審計和驗證 產生詳細設計文檔,提交ETL設計和開發;召集相關人員進行模型的審查和驗證,根據審查結果對詳細維度進行再設計
- Inmon模型
- Inmon 對數據模型的定位是:扮演著通往數據倉庫其他部分的智能路線圖的角色。由于數據倉庫的建設不是一蹴而就的,為了協調不同人員的工作以及適應不同類型的用戶,非常有必要建立一個路線圖——數據模型,描述數據倉庫各部分是如何結合在一起的
- ERD層:實體關系圖
- DIS層:數據項集
- 物理層:物理模型
- 其他模型實施過程
- 業務建模,生成業務模型,解決業務層面的分解和程序化
- 領域建模,生成領域模型,主要是對業務模型進行抽象處理,生成領域概念模型
- 邏輯建模,生成邏輯模型,主要將領域模型的概念實體以及實體之間的關系進行數據庫層次的邏輯化
- 物理建模,生成物理模型,主要解決邏輯建模對不同關系數據庫的物理化以及性能等一些具體 的技術問題
2.4.2 指導方針
-
數據調研。在建設大數據數據倉庫時,要進行充分的業務調研和需求分析
-
業務調研:數據倉庫是要涵蓋所有業務領域,還是各個業務領域獨自建設,業務領域內的業務線也同樣面臨著這個問題。所以要構建大數據數據倉庫,就需要了解各個業務領域、業務線的業務有什么共同點和不同點,以及各個業務線可以細分為哪幾個業務員板塊,每個業務板塊具體的業務流程又是怎樣的
-
需求調研:通過分析師、業務運營人員去了解;通過報表系統中現有的報表進行研究分析
-
-
數據總體架構設計。主要是根據數據域對數據進行劃分,按照維度建模理論,構建總線矩陣、抽象出業務過程和維度
-
數據域劃分:是指面向業務分析,將業務過程或者維度進行抽象的集合,業務過程是一個個不可拆分的行為事件,數據域需要抽象提煉,并且長期維護和更新,但不輕易變動。在劃分數據域時,既能涵蓋當前所有的業務需求,又能在新業務進入時無影響地被包含進已有的數據域中或者擴展新的數據域。
-
構建總線矩陣:明確兩件事:明確每個數據域下有哪些業務過程;業務過程與哪些維度相關,并確定每個數據域下的業務過程和維度
-
-
規范定義。主要定義指標體系,包括原子指標,修飾詞,時間周期和派生指標
-
模型設計:主要包括維度及屬性的規范定義,維表、明細事實表和匯總事實表的模型設計
-
代碼研發和運維
OneData 的實施過程是一個高度迭代和動態的過程, 般采用螺旋式實施方法。在總體架構設計完成之后,開始根據數據域進行迭代式模型設計和評審。在架構設計、規范定義和模型設計等模型實施過程中,都會引人評審機制,以確保模型實施過程的正確性。
三 維度設計
3.1 維度設計基礎
這就像描述一個事物,需要各種條件來限定,對其進行鎖定,維度就是環境條件,事實就是度量,代表其程度
-
基本概念
-
在維度建模中,將度量稱為”事實“,將環境描述為”維度“,維度是用于分析事實所需要的多樣環境
-
維度所包含的表示維度的列,稱為維度屬性。維度屬性是查詢約束條件、分組和報表標簽生成的基本來源,是數據易用性的關鍵。
-
維度使用主鍵標識其唯一性,主鍵也是確保與之相連的任何事實表之間存在引用完整性的基礎。主鍵有兩種:代理鍵和自然鍵,它們都是用于標識某維度的具體值。但代理鍵是不具有業務含義的鍵,一般用于處理緩慢變化維;自然鍵是具有業務含義的鍵
-
如何獲取維度或維度屬性?如上面所提到的,一方面,可以在報表中獲取;另一方面,可以在和業務人員的交談中發現維度或維度屬性。
-
-
設計方法
維度的設計過程就是確定維度屬性的過程,如何生成維度屬性,以及所生成的維度屬性的優劣,決定了維度使用的方便性,成為數據倉庫易用性的關鍵。正如 Kimball 所說的,數據倉庫的能力直接與維度屬性的質量和深度成正比。- 方法:
- 選擇維度或新建維度,作為維度模型的核心,必須保證維度的唯一性
- 確定主維表,其一般是ODS層
- 確定相關維表, 數據倉庫是業務源系統的數據整合,不同業務系統或者同 業務系統中的表之間存在關聯性。根據對業務的梳理,確定哪些表和主維表存在關聯關系,并選擇其中的某些表用于生成維度屬性。
- 確定維度屬性。一般是兩個階段,一是從主維表中選擇維度屬性或生成新的維度屬性;第二階段是從相關維表中選擇維度屬性或生成新的維度屬性
- 提示
- 盡可能生成豐富的維度屬性
- 盡可能多地給出寶庫奧一些富有意義的文字性描述
- 區分數值型屬性和事實
- 盡量沉淀出通用的維度屬性
- 方法:
-
層次結構
維度中的一些描述屬性以層次方式或一對多的方式相互關聯,可以被理解為包含連續主從關系的屬性層次。層次的最底層代表維度中描述最低級別的詳細信息,最高層代表最高級別的概要信息。維度常常有多個這樣的嵌入式層次結構。比如淘寶商品維度,有賣家、類目、品牌等。商品屬于類目,類目屬于行業,其中類目的最低級別是葉子類目,葉子類目屬于二級類目,二級類目屬于一級類目。 -
規范化和反規范化
- 在OLTP中,為了避免數據冗余導致的不一致性,會采用范式的處理,
- 在OLAP中,由于數據量大,注重讀寫查詢,所以會犧牲掉一部分存儲性能,來提高查詢速度
將維度的屬性層次合并到單個維度中的操作稱為反規范化。分析系統的主要目的是用于數據分析和統計,如何更方便用戶進行統計分析決定了分析系統的優劣。采用雪花模式,用戶在統計分析的過程中需要量的關聯操作,使用復雜度高,同時查詢性能很差;而采用反規范化處理,則方便、易用且性能好。
-
一致性維度和交叉探查
Kimball 的數據倉庫總線架構提供了 種分解企 級數據倉庫規劃任務的合理方法,通過構建企業范圍內 致性維度和事實來構建總線架構。
維度一致性的表現形式: 共享維表; 一致性上卷;交叉屬性
3.2 維度設計高級主題
-
維度整合
-
數據倉庫是一個面向主題的、集成的、非易失的且隨時間變化的數據集合,用來支持管理人員的決策,其中集成是數據倉庫的四個特性中最重要一個
-
數據倉庫的數據來源是不同的面向應用的操作型環境,不同的應用是設計考慮不一樣,應用之間差異巨大,導致整合難度大,但非常重要
-
差異表現:
- 應用在編碼、命名習慣、度量單位等方面會存在很大的差異
- 應用出于性能和擴展性的考慮,或者隨技術架構的演變,以及業務的發展,采用不同的物理實現
-
數據由面向應用的操作型環境進入數據倉庫后,需要進行集成。將面向應用的數據轉換為面向主題的數據倉庫數據,本身就是一種集合。
集成規范:
- 命名規范的統一,表名、字段名等的統一
- 字段類型的統一
- 公共代碼及代碼值的統一
- 業務含義相同的表的統一:
- 1)采用主從表的設計方式
- 2)直接合并
- 3)不合并
- 垂直整合
- 水平整合
-
-
水平拆分
維度通常可以按照類別或類型進行細分,如何設計維度- 兩種解決方案:
- 將維度的不同分類實例化為不同的維度,同時在主維度中保存公共屬性
- 維護單一維度,包含所有可能的屬性
選擇哪種方案:
- 三個原則(擴展性,效能,易用性)
- 兩個依據:
- 是維度的不同分類的屬性差異情況
- 業務的關聯程度
- 兩種解決方案:
-
垂直拆分
出于擴展性、產出時間、易用性等方面的考慮,設計主從維度。主維表存放穩定 產出時間早、熱度高的屬性;從維表存放變化較快、產出時間晚、熱度低的屬性。 -
歷史歸檔
顧名思義,定期將歷史數據歸檔至歷史維表- 歸檔策略
- 歸檔策略 一:同前臺歸檔策略,在數據倉庫中實現前臺歸檔算法,定期對歷史數據進行歸檔
- 歸檔策略 二:同前臺歸檔策略,但采用數據庫變更日志的方式
- 歸檔策略 三:數據倉庫自定義歸檔策略。
- 歸檔策略
3.3 維度變化
-
緩慢變化維
緩慢變化維的提出是因為在現實世界中,維度的屬性并不是靜態的,它會隨著時間的流逝發生緩慢的變化與數據增長較為快速的事實表相比,維度變化相對緩慢。- Kimball 的理論中,種處理緩慢變化維的方式
-
- 第一種處理方式 :重寫維度值。采用此種方式,不保留歷史數據,始終取最新數據。
-
- 第二種處理方式:插入新的維度行。采用此種方式,保留歷史數據,維度值變化前的事實和過去的維度值關聯,維度值變化后的事實和當前維度值關聯
-
- 第三種處理方式:添加維度列。采用此種處理方式不能將變化前后記錄的事實歸 為變化前的維度或者歸 為變化后的維度。
-
選擇哪種處理方式沒有一個固定的方式,可以根據業務需求進行選擇
- Kimball 的理論中,種處理緩慢變化維的方式
-
快照維表
在阿里巴巴數據倉庫實踐中,處理緩慢變化維的方法是采用快照方式,數據倉庫的計算周期一般是每天一次,基于此周期,處理維度變化的方式就是每天保留一份全量快照數據-
原因:
在 Kimball的維度建模中,必須使用代理鍵作為每個維表的主鍵,用于處理緩慢變化維。但在阿里的數據量巨大,對于分布式計算系統,不存在事務的概念,對于每個表的記錄生成穩定的全局唯一的代理鍵難度很大;使用代理建會大大增加ETL的復雜性,對ETL的開發和維護成本很高。而快照維表很好的解決了這個問題,數據倉庫的計算周期 一般是每天 1次,基于此周期,處理維度變化的方式就是每天保留一份全量快照數據。 -
優點:簡單而有效,開發和維護成本低;使用方便,理解性好
-
弊端:存儲上的極大浪費。此方法主要就是實現了犧牲存儲獲取 ETL 效率的優化和邏輯上的簡化。但是 一定要杜絕過度使用這種方法,而且必須要有對應的數據生命周期制度,清除無用的歷史數據。
-
-
極限存儲
極限存儲是比快照維表更優的方法,即可以實現快照維表的優點,又可以避免存儲浪費。
歷史拉鏈存儲是指利用維度模型中緩慢變化維的第二種處理方式。這種處理方式是通過新增兩個時間戳字段(start_dt end_dt ),將所有以天為粒度的變更數據都記錄下來。通常分區字段也是時間戳字段。
但是這種存儲方式對于下游使用方存在一定的理解障礙,另外,這種儲方式用 start_dt end_dt 做分區,隨 時間的推移,分區數量會極度膨脹,而現行的數據庫系統都有分區數量限制。
為了解決上述問題,采用極限存儲采用- 透明化
- 分月做歷史拉鏈表
采用極限存儲的處理方式,極大地壓縮了全量存儲的成本,又可以達到對下游用戶透明的效果,是一種比較理想的存儲方式。但是其本身也有一定 的局限性,首先,其產出效率很低,大部分極限存儲通常需要t-2。 其次,對于變化頻率高的數據并不能達到節約成本的效果
-
微型維度
微型維度的創建是通過將一部分不穩定的屬性從主維度中移出,并將它們放置到擁有自己代理鍵的新表中來實現的。這些屬性相互之間沒有直接關聯,不存在自然鍵。通過為每個組合創建新行的一次性過程來加載數據。可以解決維度的過度增長導致極限存儲效果大打折扣的問題。其中一種解決方法就是上一節提到的垂直拆分,保持主維度的穩定性;另一種解決方式是采用微型維度。
3.4 特殊維度
-
遞歸層次
維度的遞歸層次,按照層級是否固定分為均衡層次結構和非均衡層次結構。- 層次結構扁平化
降低遞歸層次使用復雜度的最簡單和有效的方法是層次結構的扁平化,通過建立維度 的固定數量級別的屬性來實現,可以在一定程度上解決上鉆和下鉆的問題。對于均衡層次結構,采用扁平化最有效 - 層次橋接表:
針對層次結構扁平化所存在的問題,可以采用橋接表的方式來解決,不需要預先知道所屬層級,不需要回填,也可解決非均衡層次結構的問題。與扁平化方法相比,該方法適合解決更寬泛的分析問題,靈活性好;但復雜性高,使用成本高。
- 層次結構扁平化
-
行為維度(類似的維度,都和事實相關,如交易、物流等,稱之為“行為維度”,或“事實衍生的維度”。)
-
多值維度
- 三種處理方式,可根據業務的表現形式和統計分析需求進行選擇
- 第一種,處理方式是降低事實表的粒度
- 第二種,采用多字段
- 第三種,采用較為通用的橋接表
- 三種處理方式,可根據業務的表現形式和統計分析需求進行選擇
-
多值屬性
-
雜項維度
四 事實表設計
4.1 事實表基礎
4.1.1 事實表特性
事實表作為數據倉庫維度建模的核心,緊緊圍繞著業務過程來設計,通過獲取描述業務過程的度量來表達業務過程,包含了引用的維度和與業務過程有關的度量。
事實表中一條記錄所表達的業務細節程度被稱為粒度。通常粒度可以通過兩種方式來表述:一種是維度屬性組合所表示的細節程度;一種是所表示的具體業務含義
作為度量業務過程的事實,一般為整型或浮點型的十進制數值,有可加性、半可加性和不可加性三種類型
維度屬性也可以存儲到事實表中,這種存儲到事實表中的維度列被稱為“退化維度”。與其他存儲在維表中的維度一樣 ,退化維度也可以用來進行事實表的過濾查詢、實現聚合操作等。
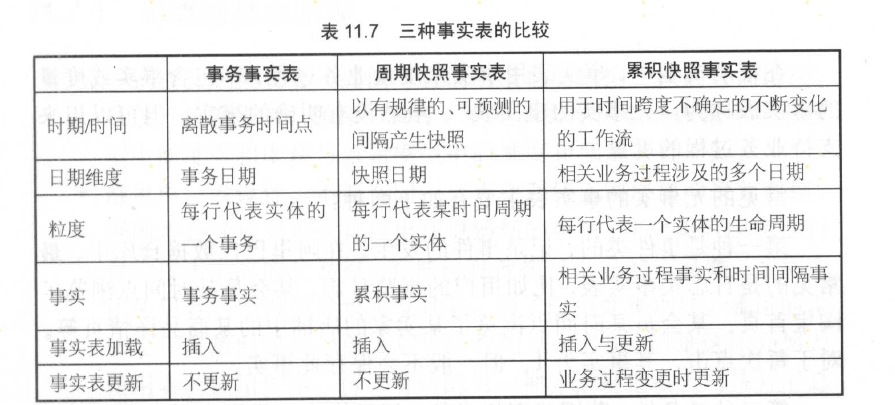
事實表有三種類型:事物事實表、周期快照事實表、累計快照事實表。
- 事物事實表: 用來描述業務過程,跟蹤空間或事件上某點的度量事件,保存的是最原子的數據,也成為“原子事實表”
- 周期快照事實表: 以具有規律性的、可預見性的事件間隔記錄事實,時間間隔如每天、每月…
- 累計快照事實表: 用來表述過程開始和結束之間的關鍵步驟事件,覆蓋過程的整個生命周期,通常具有多個日期字段來記錄關鍵時間帶你,當過程隨著生命周期不斷變化時,記錄也會隨著過程的變化而被修改
4.1.2 事實表設計原則
- 盡可能包含所有與業務過程相關的事實
- 只選擇與業務過程相關的事實
- 分解不可加性事實為可加的組件
- 在選擇維度和事實之前必須先聲明粒度
- 在同一個事實表中不能有多種不同粒度的事實
- 事實的單位要保持一致
- 對事實的null值要處理
- 使用退化維度提高事實表的易用性
4.1.3 事實表設計方法
- 選擇業務員過程及確定事實表類型
在明確了業務需求以后,接下來需要進行詳細的需求分析,對業務的整個生命周期進行分析,明確關鍵的業務步驟,從而選擇與需求有關的業務過程。
在明確了流程所包含的業務過程后,需要根據具體的業務需求來選擇與維度建模有關的業務過程 - 聲明粒度
粒度的聲明是事實表建模非常重要的一步,意味著精確定義事實表的每一行所表示的業務含義,粒度傳遞的是與事實表度量有關的細節層次。明確的粒度能確保對事實表中行的意思的理解不會產生混淆,保證所有的事實按照同樣的細節層次記錄。
應該盡量選擇最細級別的原子粒度,以確保事實表的應用具有最大的靈活性。 - 確定維度
- 確定事實
確定事實的過程需要將不可加性事實分解為可加的組件 - 冗余維度
是為了方便下游用戶使用效率提高
4.2 事物事實表
任何類型的事件都可以被理解為 種事務。比如交易過程中的創訂單、買家付款,物流過程中的攬貨、發貨、簽收,退款中的申請退款、申請小 介入等,都可以被理解為 種事務。事務事實表, 即針對這些過程構建的一類事實表,用以跟蹤定義業務過程的個體行為,提供豐富的分析能力,作為數據倉庫原子的明細數據。
-
設計過程
-
- 選擇業務過程
-
- 確定粒度
-
- 確定維度
-
- 確定事實
-
- 冗余維度
-
-
單事物事實表
-
多事物事實表
兩種方法進行事實的處理:- 不同業務過程的事實使用不同的事實字段進行存放;
- 不同業務過程的事實使用同一個事實字段進行存放,但增加一個業務過程標簽
-
設計過程分析
- 業務過程: 單事務:一個; 多事務:多個
- 粒度和維度: 單事務:相互間不相關; 多事務:粒度和維度一致
- 事實: 單事務:只取當前業務過程中的事實; 多事務:保留多個業務過程中的事實,非當前業務過程中的事實需要置零處理
- 下游業務使用: 單事務:易于理解,不會混淆; 多事務:難以理解,需要通過標簽來限定
- 計算存儲成本: 單事務:較多,每個業務過程都需要計算存儲一次; 多事務:較少 ,不同業務過程融合到一起,降低了存儲計算成本,但是非當前業務過程的度量存在大量零值
-
事實的設計準則
-
- 事實的完整性
-
- 事實的一致性
-
- 事實可加性
-
4.3 周期快照事實表
-
定義:
快照事實表在確定的間隔內對實體的度量進行抽樣,這樣可以很容易地研究實體的度量值,而不需要聚集長期的事務歷史。 -
種類:
- 單維度快照事實表
- 混合維度快照事實表
- 全量快照事實表
-
特性
快照事實表的設計有一些 區別于事務事實表設計的性質。事務事實表的粒度能以多 種方式表達,但快照事實表的粒度通常以維度形式聲明;事務事實表是稀疏的,但快照事實表是稠密的 事務事實表中的事實是完全可加的,但快照模型將至少包含一個用來展示半可加性質的事實。- 用快照采樣狀態
- 快照粒度
- 密度與稀疏性
- 半可加性
-
設計步驟
-
- 確定快照事 表的快照粒度。
-
- 確定快照事實表采樣的狀態度量。
-
-
注意事項
-
- 事務與快照成對設計
-
- 附加事實
-
- 周期到日期度量
-
4.4 累積快照事實表
- 設計過程
-
- 選擇業務過程
-
- 確定粒度
-
- 確定維度
-
- 確定事實
-
- 確定維度
-
- 特點
-
- 數據不斷更新
-
- 多業務過程日期
-
- 特殊處理
-
- 非線性過程
-
- 多源過程
-
- 業務過程取舍
-
- 物理實現
- 第一種方式是全量表的形式
- 第二種方式是全量表的變化形式
- 第三種方式是以業務實體的結束時間分區
4.5 三種事實表的比較
4.6 無事實的事實表
4.7 聚集型事實表
聚集主要是通過匯總明細粒度數據來獲得改進查詢性能的效果。通過訪問聚集數據,可以減少數據庫在響應查詢時必須執行的工作量,能夠快速響應用戶的查詢,同時有利于減少不同用戶訪問明細數據帶來的結果不一致問題。盡管聚集能帶來良好的收益,但需要事先對其進行加載和維護這將會對給 ETL 帶來更多的挑戰。
- 基本原則
- 一致性
- 避免單一表設計
- 聚集粒度可不同
- 聚集的基本步驟
-
- 確定聚集維度
-
- 確定一致性上鉆
-
- 確定聚集事實
-








與LED點陣驅動原理)




——靜態方法)

)
)


