1.數據集的使用:
先使用load導入鳶尾花數據:
from sklearn.datasets import load_iris然后定義一個函數來查看鳶尾花數據集:
數據集的獲取:
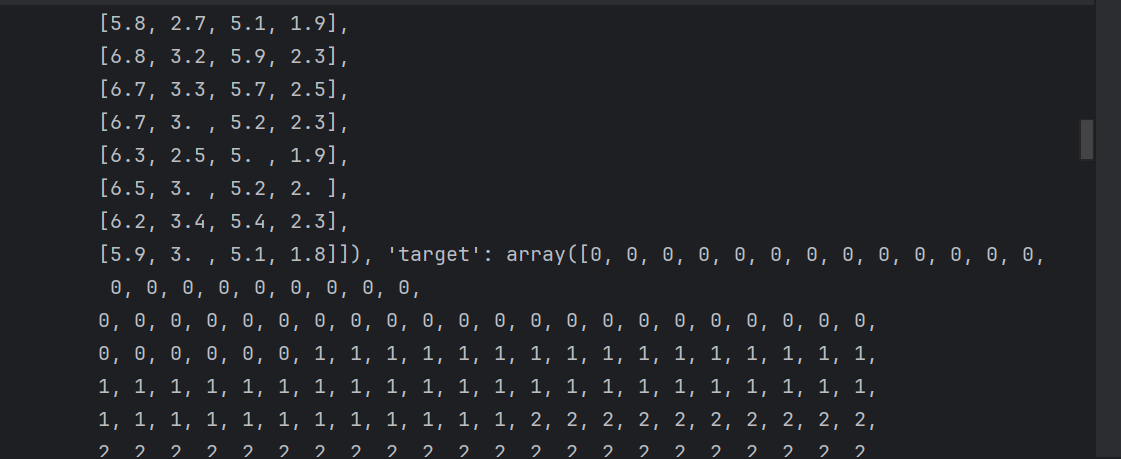
iris = load_iris()print('鳶尾花的數據集:\n',iris)使用iris['DESCR']來查看數據及里面的描述:
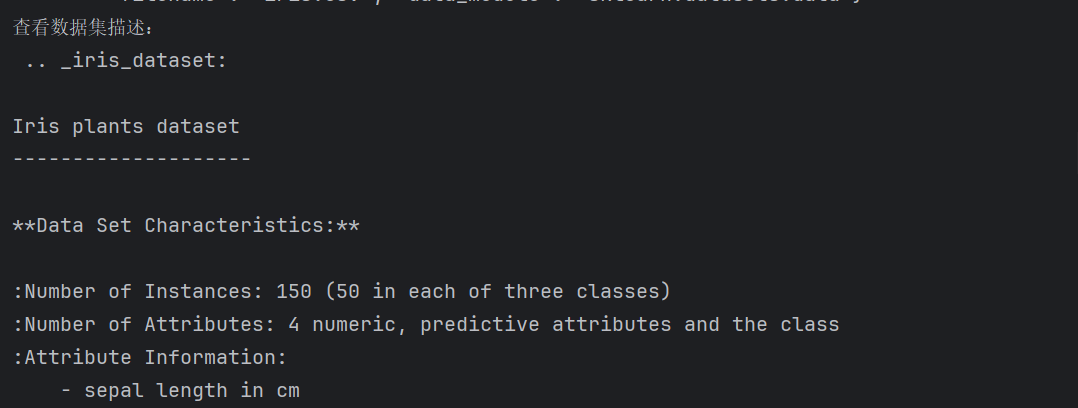
print('查看數據集描述:\n',iris['DESCR'])獲取特征值的名字iris.feature_names

print('查看特征值的名字:\n',iris.feature_names)查看特征值:iris.data
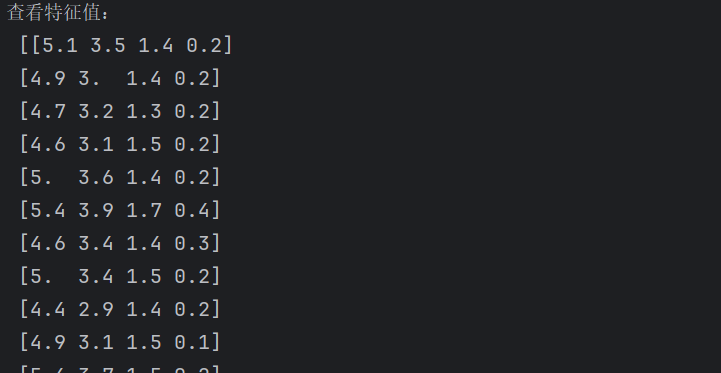
特征值的形狀:iris.data.shape:特征值是150行4列的數據
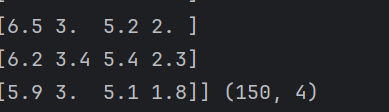
print('查看特征值:\n', iris.data,iris.data.shape)數據集劃分:
先導入對應模塊:
from sklearn.model_selection import train_test_splitiris.data
表示鳶尾花數據集的特征矩陣(即輸入數據),通常是一個二維數組或矩陣,每一行代表一個樣本,每一列代表一個特征(如花萼長度、花萼寬度等)。iris.target
表示鳶尾花數據集的標簽(即目標值),通常是一個一維數組,每個元素對應一個樣本的類別(如0、1、2分別代表不同品種的鳶尾花)。test_size=0.2
指定測試集的比例為20%,即訓練集占80%。可以是浮點數(比例)或整數(樣本數)。random_state=22
隨機種子,用于控制數據分割的隨機性。固定此值可確保每次運行代碼時,劃分結果一致(適用于可復現的實驗)。
輸出變量說明
x_train
訓練集的特征數據,包含80%的原始樣本特征,用于訓練模型。x_test
測試集的特征數據,包含20%的原始樣本特征,用于評估模型性能。y_train
訓練集的標簽數據,與?x_train?中的樣本一一對應。y_test
測試集的標簽數據,與?x_test?中的樣本一一對應。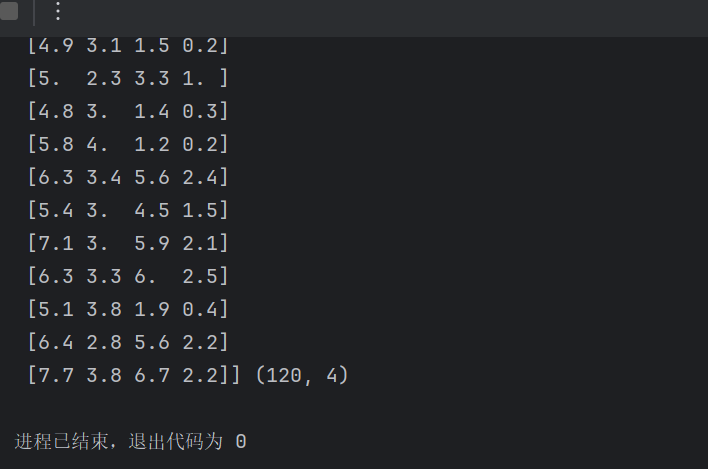
x_train,x_test,y_train,y_test=train_test_split(iris.data, iris.target, test_size=0.2,random_state=22)print('訓練集的特征值:\n',x_train,x_train.shape)完整代碼:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_splitdef datasets_demo():"""sklearn數據集的使用:return:"""#獲取數據集iris = load_iris()print('鳶尾花的數據集:\n',iris)print('查看數據集描述:\n',iris['DESCR'])print('查看特征值的名字:\n',iris.feature_names)print('查看特征值:\n', iris.data,iris.data.shape)#數據集劃分x_train,x_test,y_train,y_test=train_test_split(iris.data, iris.target, test_size=0.2,random_state=22)print('訓練集的特征值:\n',x_train,x_train.shape)return Noneif __name__ == '__main__':datasets_demo()2.字典特征抽取:
導入對應模塊:
from sklearn.feature_extraction import DictVectorizer
先定義一些數據:
data=[{'city':'北京','temperature':100},{'city':'上海','temperature':50},{'city':'深圳','temperature':60}]第一步先實例化一個轉換器:
?sparse默認是true 返回的是一個稀疏矩陣,需要將其改為False才能夠得到對應的矩陣,如果默認不寫將出現下列的情況:
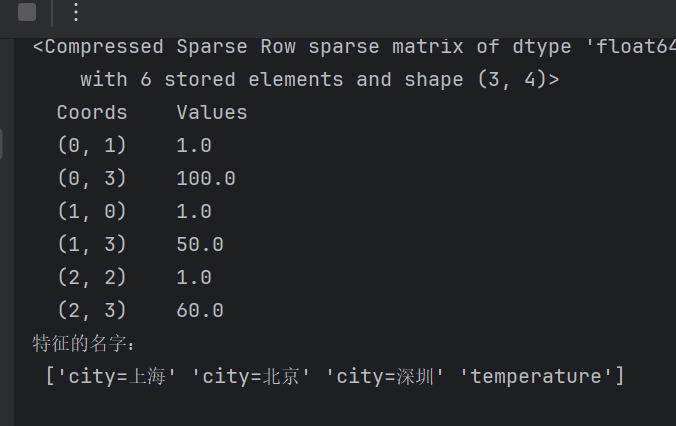
transformer = DictVectorizer(sparse=False)第二步調用fit_transform()并輸出打印:
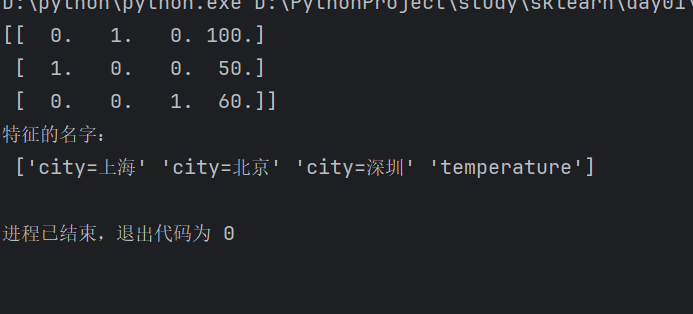
data_new=transformer.fit_transform(data)print(data_new)print('特征的名字:\n',transformer.get_feature_names_out())完整代碼:
from sklearn.feature_extraction import DictVectorizerdef dict_demo():"""字典特征抽取:return:"""data=[{'city':'北京','temperature':100},{'city':'上海','temperature':50},{'city':'深圳','temperature':60}]#1.實例化一個轉換器類# sparse默認是true 返回的是一個稀疏矩陣transformer = DictVectorizer(sparse=False)#2.調用fit_transform()data_new=transformer.fit_transform(data)print(data_new)print('特征的名字:\n',transformer.get_feature_names_out())return Noneif __name__ == '__main__':dict_demo()3.文本特征抽取:統計樣本出現的次數
導入對應模塊:
from sklearn.feature_extraction.text import CountVectorizer隨便定義一些單詞:
data=["life is short ,i like like python","life is too long,i dislike python"]第一步還是實例化一個轉換器:
transformer = CountVectorizer()第二步調用:
toarray()是sparse矩陣里的一個方法作用是一樣的

data_new=transformer.fit_transform(data)print(data_new.toarray()) print('特征名字:',transformer.get_feature_names_out())完整代碼:
from sklearn.feature_extraction.text import CountVectorizerdef count_demo():"""文本特征抽取:統計樣本出現的次數:return:"""data=["life is short ,i like like python","life is too long,i dislike python"]#1.實例化一個轉換器transformer = CountVectorizer()# 2.調用fit_transformdata_new=transformer.fit_transform(data)print(data_new.toarray()) # toarray()是sparse矩陣里的一個方法作用是一樣的print('特征名字:',transformer.get_feature_names_out())if __name__ == '__main__':count_demo()4.中文文本抽取特征:
導入所需要的庫:
import jieba
from sklearn.feature_extraction.text import CountVectorizer隨機寫入一些中文:
data=["一種還是一種今天很殘酷,明天更殘酷,后天很美好,但絕對大部分是死在明天晚上,所以每個人不要放棄今天","我們看到的從很遠星系來的光是在幾百萬年之前發出的,這樣當我們看到宇宙時,我們是在看它的過去","如果只用一種方式了解某樣事物,你就不會真正了解它。了解事物真正含義的秘密取決于如何將其與我們所了解的事物相聯系。"]首先我們應該先定義一個jieba函數:
將這些數據先轉為列表要不然輸出臺會出現生成器不便于觀察,在用字符串拼接起來:
def cut_words(text):"""進行中文分詞:param text::return:"""return "".join(list(jieba.cut(text)))定義一個空的列表,來對上后面的data進行遍歷并添加到這個空列表中:
data_new=[]for item in data:data_new.append(cut_words(item))完整代碼:

import jieba
from sklearn.feature_extraction.text import CountVectorizerdef cut_words(text):"""進行中文分詞:param text::return:"""return "".join(list(jieba.cut(text)))def count_words():"""中文文本特征抽取,自動分詞:return:"""#1. 將中文文本進行分詞data=["一種還是一種今天很殘酷,明天更殘酷,后天很美好,但絕對大部分是死在明天晚上,所以每個人不要放棄今天","我們看到的從很遠星系來的光是在幾百萬年之前發出的,這樣當我們看到宇宙時,我們是在看它的過去","如果只用一種方式了解某樣事物,你就不會真正了解它。了解事物真正含義的秘密取決于如何將其與我們所了解的事物相聯系。"]data_new=[]for item in data:data_new.append(cut_words(item))# 1.實例化一個轉換器transformer = CountVectorizer()# 2.調用fit_transformdata_new = transformer.fit_transform(data_new)print(data_new.toarray()) # toarray()是sparse矩陣里的一個方法作用是一樣的print('特征名字:', transformer.get_feature_names_out())return Noneif __name__ == '__main__':count_words()
5.TFIDF文本抽取
導入對應模塊
from sklearn.feature_extraction.text import TfidfVectorizer完整代碼:

from sklearn.feature_extraction.text import TfidfVectorizerdef Tfidf_words():"""文本特征抽取:return:"""#1. 將中文文本進行分詞data=["一種還是一種今天很殘酷,明天更殘酷,后天很美好,但絕對大部分是死在明天晚上,所以每個人不要放棄今天","我們看到的從很遠星系來的光是在幾百萬年之前發出的,這樣當我們看到宇宙時,我們是在看它的過去","如果只用一種方式了解某樣事物,你就不會真正了解它。了解事物真正含義的秘密取決于如何將其與我們所了解的事物相聯系。"]# 1.實例化一個轉換器transformer = TfidfVectorizer()# 2.調用fit_transformdata_new = transformer.fit_transform(data)print(data_new.toarray()) # toarray()是sparse矩陣里的一個方法作用是一樣的print('特征名字:', transformer.get_feature_names_out())return Noneif __name__ == '__main__':Tfidf_words()

)
)


-Matplotlib樣式系統深度解析:從入門到企業級應用)





)





)
