說明:這是一個機器學習實戰項目(附帶數據+代碼+文檔),如需數據+代碼+文檔可以直接到文章最后關注獲取 或者私信獲取。
1.項目背景
在大數據分析與智能建模領域,高維數據廣泛存在于金融預測、環境監測和工業過程控制等場景中。冗余或無關特征不僅增加計算復雜度,還會導致BP神經網絡回歸模型出現過擬合、收斂緩慢和預測精度下降等問題。有效的特征選擇是提升模型性能的關鍵環節。鯨魚果蠅優化算法(Whale Fruit-fly Optimization Algorithm, WFOA)融合了鯨魚優化算法(WOA)的全局探索能力與果蠅優化算法(FOA)的局部開發優勢,具備較強的尋優能力和收斂精度。本研究提出一種基于WFOA的特征選擇方法,用于優化BP神經網絡回歸模型的輸入特征子集,旨在篩選出對輸出變量預測貢獻最大的特征組合,從而構建高效、穩定的回歸模型,提升預測準確性與模型可解釋性。
本項目通過基于WFOA與BP神經網絡回歸模型的特征選擇方法研究(Python實現)。???????????????????????????????????????
2.數據獲取
本次建模數據來源于網絡(本項目撰寫人整理而成),數據項統計如下:
| 編號 | 變量名稱 | 描述 |
| 1 | x1 | |
| 2 | x2 | |
| 3 | x3 | |
| 4 | x4 | |
| 5 | x5 | |
| 6 | x6 | |
| 7 | x7 | |
| 8 | x8 | |
| 9 | x9 | |
| 10 | x10 | |
| 11 | y | 因變量 |
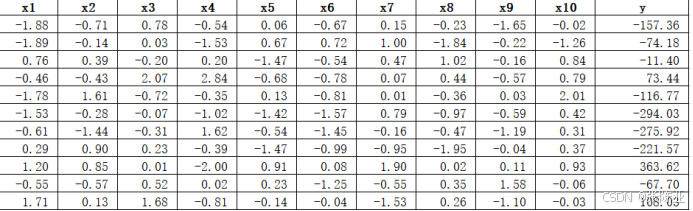
數據詳情如下(部分展示):
3.數據預處理
3.1?用Pandas工具查看數據
使用Pandas工具的head()方法查看前五行數據:

關鍵代碼:

3.2數據缺失查看
使用Pandas工具的info()方法查看數據信息:
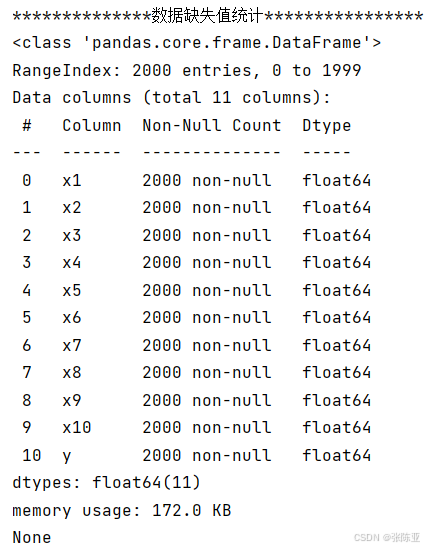
從上圖可以看到,總共有11個變量,數據中無缺失值,共2000條數據。
關鍵代碼:

3.3數據描述性統計?
通過Pandas工具的describe()方法來查看數據的平均值、標準差、最小值、分位數、最大值。
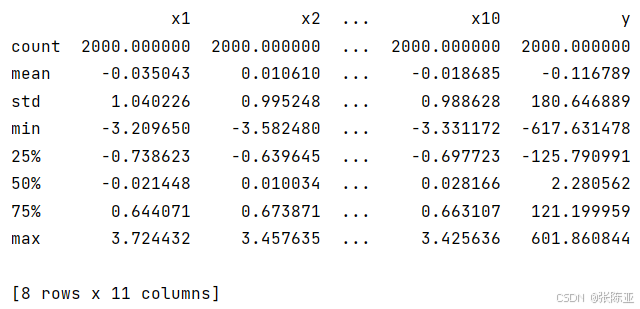
關鍵代碼如下: ?

4.探索性數據分析
4.1 y變量分布直方圖
用Matplotlib工具的hist()方法繪制直方圖:
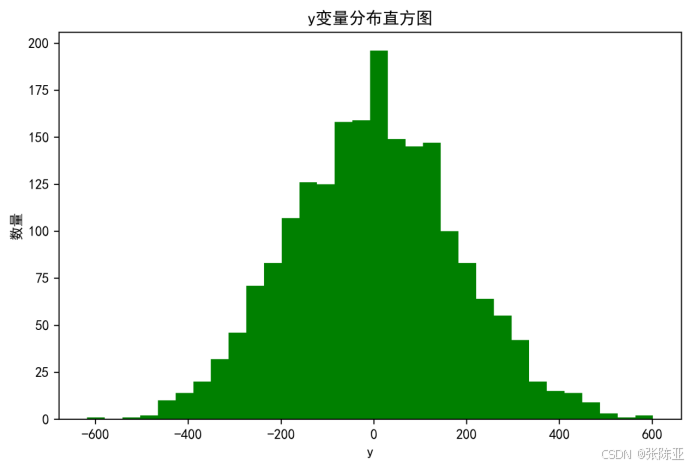
4.2 相關性分析
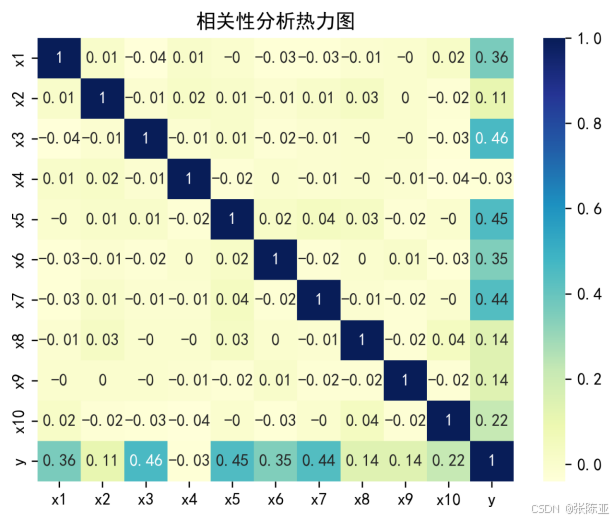
5.特征工程
5.1 建立特征數據和標簽數據
關鍵代碼如下:

5.2?數據集拆分
通過train_test_split()方法按照80%訓練集、20%測試集進行劃分,關鍵代碼如下:

6.構建特征選擇模型 ???
主要使用通過基于WFOA與BP神經網絡回歸模型的特征選擇方法研究(Python實現)。?????????????????????????????????????
6.1 尋找最優特征??
最優特征:
![]()
6.2 最優特征構建模型
| 編號 | 模型名稱 | 參數 |
| 1 | BP神經網絡回歸模型 ??? | units=64 |
| 2 | optimizer=opt | |
| 3 | epochs=50 |
6.3 模型摘要信息??

6.4 模型訓練集測試集損失曲線圖?
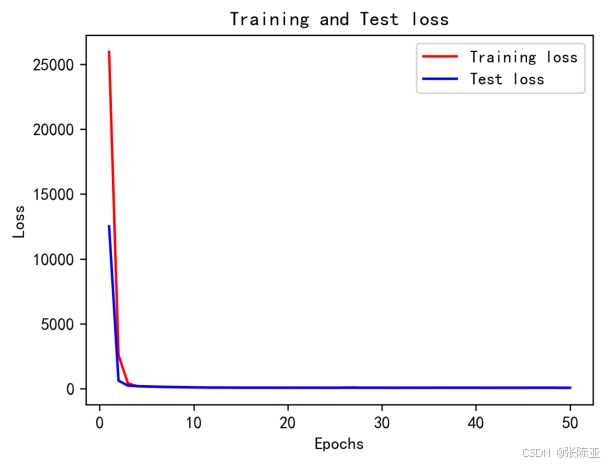
7.模型評估
7.1評估指標及結果 ???
評估指標主要包括R方、均方誤差、解釋性方差、絕對誤差等等。
| 模型名稱 | 指標名稱 | 指標值 |
| 測試集 | ||
| BP神經網絡回歸模型 ??? | R方 | 0.9979 |
| 均方誤差 | 76.2438 | |
| 解釋方差分 | 0.9979 | |
| 絕對誤差 | 6.847 | |
從上表可以看出,R方分值為0.9979,說明模型效果良好。 ??????
關鍵代碼如下: ????????????

7.2 真實值與預測值對比圖 ?
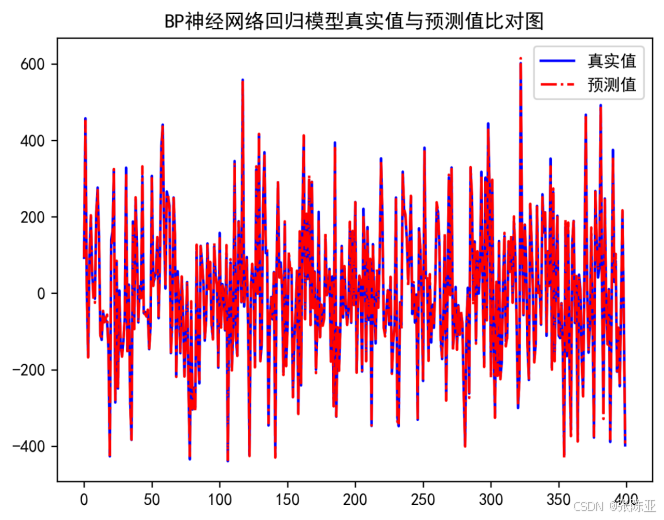
從上圖可以看出真實值和預測值波動基本一致,模型效果良好。??????????
8.結論與展望
綜上所述,本文采用了基于WFOA與BP神經網絡回歸模型的特征選擇方法研究(Python實現),最終證明了我們提出的模型效果良好。此模型可用于日常產品的預測。



)

)
)
: Qwen3?Max?Preview上線、GLM-4.5提供一鍵遷移、Gemini for Home,AI風向何在?)











