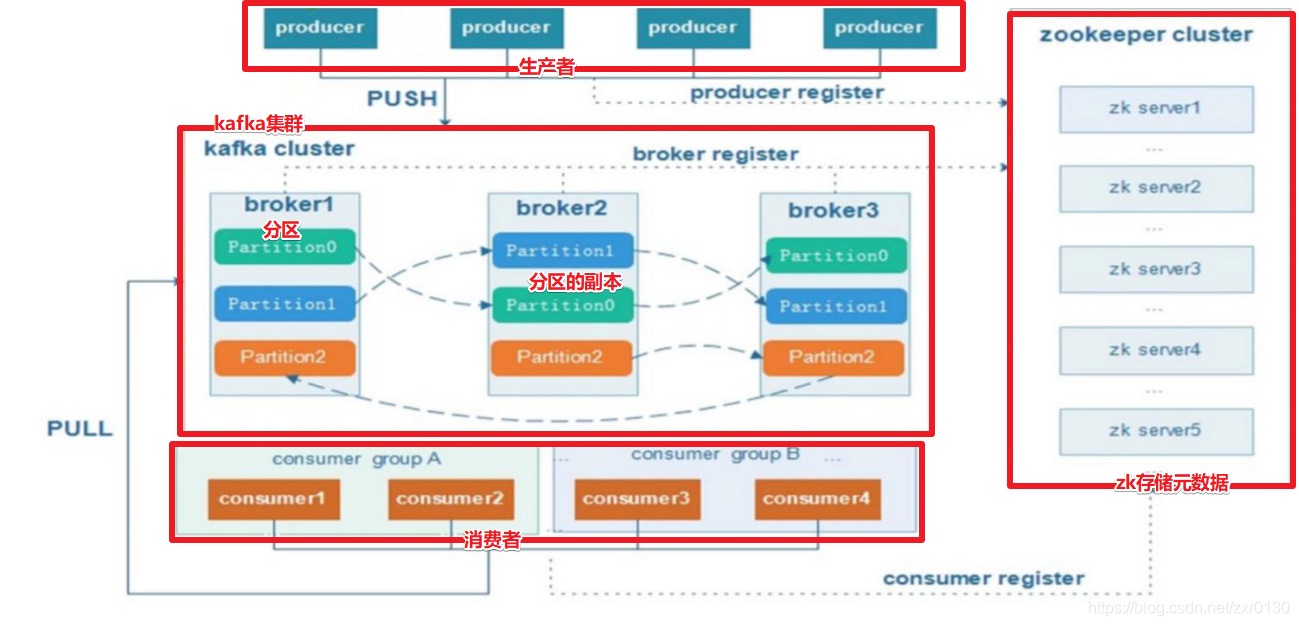
一個kafka集群中包含一個或多個Producer、一個或多個broker、一個或多個ConsumerGrop以及一個Zookeeper集群。kafka通過Zookeeper管理kafka集群配置、leader副本的選舉、生產者的負載均衡等。Producer使用push模式將消息發布到broker,Consumer使用pull模式從broker訂閱并消費消息。
專業術語
- kafkaCluster : kafka集群,由一個或多個Broker節點組成。
- Broker : 一個Kafka集群包括一個或多個服務器,一臺服務器就是一個Broker節點。Broker用于保存Producer發送的消息。
- Producer :生產者,用來發送指定的Topic的消息到Broker。生產者可以是代碼,還可以是命令行工具。本質上是一個進程或者線程。
- Consumer :消費者,用來接收/消費Kafka集群中的消息。每個Consumer屬于一個ConsumerGroup(如果在創建消費者時沒有指定Consumer,系統會默認分配一個ConsumerGroup),消費者可以是代碼,還可以是命令行工具,本質上就是一個進程/線程。
- ConsumerGroup :消費者組,由一個或多個Consumer組成(在同一個消費者組的消費者具有相同的
group.id),便于管理Consumer。 - Zookeeper :在Kafka集群中用來存儲元數據,如:有Broker節點信息、分區的信息、分區與Broker的對應關系、生產者的負載均衡等等。
- Topic :主題,主題用于區分業務,比如訂單主題業務,購物車主題業務,物流主題業務……方便對消息進行分類管理
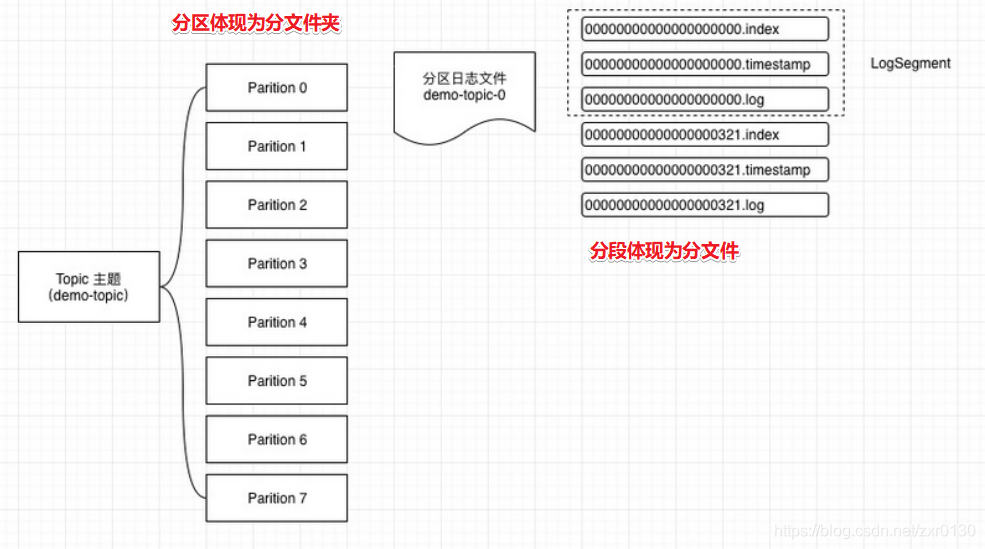
- Partition :分區,一個Topic的消息由一個或多個Partition存儲。分區的作用是提高讀寫并行度/讀寫效率。
- Segment :分段,發送到kafka集群的消息會先存到內存中,然后劃分文件夾、劃分文件存入磁盤中
- Replication :副本,副本的作用是保證數據的安全性,副本分為Leader(主副本)和Follower(從副本),Leader只有一個,Follower可以有多個,但是副本數一般都為1-3個(副本數過多會占用大量的存儲空間)。
注意:讀寫都只能從Leader進行,Follower在Leader宕機后自動選舉出新的Leader。
擴展: 為什么讀寫都只能從Leader進行?
答:保證數據的一致性,只在Leader中進行寫入數據,Follow同步Leader中的數據,在寫過程中避免了多個副本中存儲的數據不同的問題。Leader 和 Follow之間同步數據存在延時,所以讀操作也需要在Leader中進行。
11. ISR : 表示目前Alive(活著的)且與Leader能夠 “Catch-up”(跟得上)的Replicas(Follower)集合。
12. Record :記錄,就是發送到Kafka集群的消息。一條消息就是一條記錄。
13. offset : 偏移量,用于記錄消息的序號,各個分區的偏移量都是從0開始。
備注: Kafka中有分區和分段的概念,分區就是分文件夾,分段就是分文件。這個思想在Hive中也有:Hive中的分區就是分文件夾,Hive中的分桶就是分文件。
跟RocketMQ的區別
1,元素據管理:
RocketMQ 有自己的管理節點 Nameserver, Kafka中是依賴zookeeper做元素據的管理。
2,消息存儲
RocketMQ 所有Topic數據同時只會寫一個文件。Kafka每個Top


)
- MTK mtk_drm_crtc.c(Part1))




)
:(七)雙向鏈表)
重新找工作開始聊起)
八股小記)






讀書筆記 25)
