- 隨機種子
- 內參的初始化
- 神經網絡調參指南
- 參數的分類
- 調參的順序
- 各部分參數的調整心得
作業:對于day41的簡單cnn,看看是否可以借助調參指南進一步提高精度。
隨機種子
import torch
import torch.nn as nn# 定義簡單的線性模型(無隱藏層)
# 輸入2個緯度的數據,得到1個緯度的輸出
class SimpleNet(nn.Module):def __init__(self):super(SimpleNet, self).__init__()# 線性層:2個輸入特征,1個輸出特征self.linear = nn.Linear(2, 1)def forward(self, x):# 前向傳播:y = w1*x1 + w2*x2 + breturn self.linear(x)# 創建模型實例
model = SimpleNet()# 查看模型參數
print("模型參數:")
for name, param in model.named_parameters():print(f"{name}: {param.data}")
torch中很多場景都會存在隨機數
1. 權重、偏置的隨機初始化
2. 數據加載(shuffling打亂)與批次加載(隨機批次加載)的隨機化
3. 數據增強的隨機化(隨機旋轉、縮放、平移、裁剪等)
4. 隨機正則化dropout
5. 優化器中的隨機性
import torch
import numpy as np
import os
import random# 全局隨機函數
def set_seed(seed=42, deterministic=True):"""設置全局隨機種子,確保實驗可重復性參數:seed: 隨機種子值,默認為42deterministic: 是否啟用確定性模式,默認為True"""# 設置Python的隨機種子random.seed(seed) os.environ['PYTHONHASHSEED'] = str(seed) # 確保Python哈希函數的隨機性一致,比如字典、集合等無序# 設置NumPy的隨機種子np.random.seed(seed)# 設置PyTorch的隨機種子torch.manual_seed(seed) # 設置CPU上的隨機種子torch.cuda.manual_seed(seed) # 設置GPU上的隨機種子torch.cuda.manual_seed_all(seed) # 如果使用多GPU# 配置cuDNN以確保結果可重復if deterministic:torch.backends.cudnn.deterministic = Truetorch.backends.cudnn.benchmark = False# 設置隨機種子
set_seed(42)介紹一下這個隨機函數的幾個部分:
1. python的隨機種子,需要確保random模塊、以及一些無序數據結構的一致性
2. numpy的隨機種子,控制數組的隨機性
3. torch的隨機種子,控制張量的隨機性,在cpu和gpu上均適用
4. cuDNN(CUDA Deep Neural Network library ,CUDA 深度神經網絡庫)的隨機性,針對cuda的優化算法的隨機性
上述種子可以處理大部分場景,實際上還有少部分場景(具體的函數)可能需要自行設置其對應的隨機種子。
日常使用中,在最開始調用這部分已經足夠。
內參的初始化
我們都知道,神經網絡的權重需要通過反向傳播來實現更新,那么最開始肯定需要一個值才可以更新參數。
這個最開始的值是什么樣子的呢?如果恰好他們就是那一組最佳的參數附近的數,那么可能我訓練的速度會快很多。
為了搞懂這個問題,幫助我們真正理解神經網絡參數的本質,我們需要深入剖析一下,關注以下幾個問題:①初始值的區間;②初始值的分布;③初始值是多少。
先介紹一下神經網絡的對稱性----為什么神經元的初始值需要各不相同?
本質神經網絡的每一個神經元都是在做一件事,輸入x--輸出y的映射,這里我們假設激活函數是sigmoid。
y=sigmoid(wx+b),其中w是連接到該神經元的權重矩陣,b是該神經元的偏置。
如果所有神經元的權重和偏置都一樣:
1. 如果都為0,那么所有神經元的輸出都一致,無法區分不同特征;此時反向傳播的時候梯度都一樣,無法學習到特征,更新后的權重也完全一致。
2. 如果不為0,同上。
所以,無論初始值是否為 0,相同的權重和偏置會導致神經元在訓練過程中始終保持同步。(因為神經網絡的前向傳播是導致權重的數學含義是完全對稱的)具體表現為:
同一層的神經元相當于在做完全相同的計算,無論輸入如何變化,它們的輸出模式始終一致。例如:輸入圖像中不同位置的邊緣特征,會被這些神經元以相同方式處理,無法學習到空間分布的差異。
所以需要隨機初始化,讓初始的神經元各不相同。即使初始差異很小,但激活函數的非線性(梯度不同)會放大這種差異。隨著訓練進行,這種分歧會逐漸擴大,最終形成功能各異的神經元。
所以初始值一般不會太大,結合不同激活函數的特性,而且初始值一般是小的值。最終訓練完畢可能就會出現大的差異,這樣最開始讓每個參數都是有用的,至于最后是不是某些參數歸0(失去價值),那得看訓練才知道。
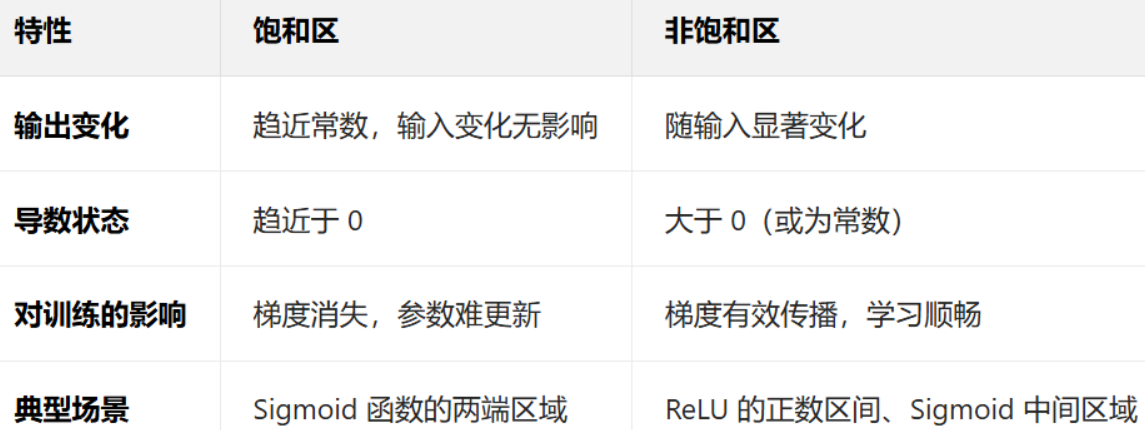
避免梯度消失 / 爆炸:
以 sigmoid 激活函數為例,其導數在輸入絕對值較大時趨近于 0(如 | x|>5 時,導數≈0)。若初始權重過大,輸入 x=w?input+b 可能導致激活函數進入 “飽和區”,反向傳播時梯度接近 0,權重更新緩慢(梯度消失)。
類比:若初始權重是 “大值”,相當于讓神經元一開始就進入 “極端狀態”,失去對輸入變化的敏感度。
如果梯度相對較大,就可以讓變化處于sigmoid函數的非飽和區。
所以其實對于不同的激活函數 ,都有對應的飽和區和非飽和區,深層網絡中,飽和區會使梯度在反向傳播時逐層衰減,底層參數幾乎無法更新;
注意下,這里是wx后才會經過激活函數,是多個權重印象的結果,不是收到單個權重決定的,所以單個權重可以取負數,但是如果求和后仍然小于0,那么輸出會為0。
所以初始值一般不會太大,結合不同激活函數的特性,而且初始值一般是小的值。最終訓練完畢可能就會出現大的差異,這樣最開始讓每個參數都是有用的,至于最后是不是某些參數歸0(失去價值),那得看訓練才知道。

import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import numpy as np# 設置設備
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")# 定義極簡CNN模型(僅1個卷積層+1個全連接層)
class SimpleCNN(nn.Module):def __init__(self):super(SimpleCNN, self).__init__()# 卷積層:輸入3通道,輸出16通道,卷積核3x3self.conv1 = nn.Conv2d(3, 16, kernel_size=3, padding=1)# 池化層:2x2窗口,尺寸減半self.pool = nn.MaxPool2d(kernel_size=2)# 全連接層:展平后連接到10個輸出(對應10個類別)# 輸入尺寸:16通道 × 16x16特征圖 = 16×16×16=4096self.fc = nn.Linear(16 * 16 * 16, 10)def forward(self, x):# 卷積+池化x = self.pool(self.conv1(x)) # 輸出尺寸: [batch, 16, 16, 16]# 展平x = x.view(-1, 16 * 16 * 16) # 展平為: [batch, 4096]# 全連接x = self.fc(x) # 輸出尺寸: [batch, 10]return x# 初始化模型
model = SimpleCNN()
model = model.to(device)# 查看模型結構
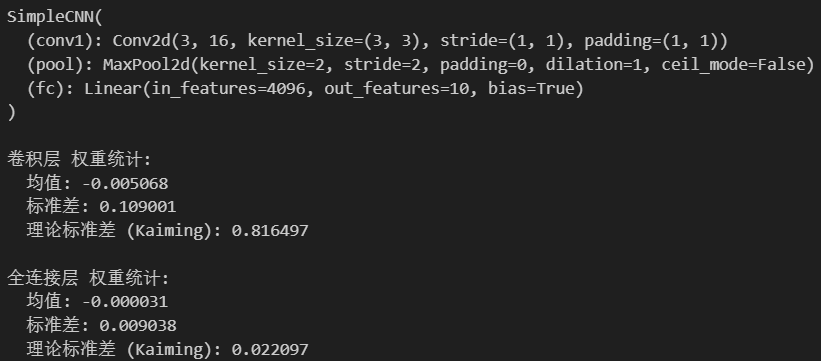
print(model)# 查看初始權重統計信息
def print_weight_stats(model):# 卷積層conv_weights = model.conv1.weight.dataprint("\n卷積層 權重統計:")print(f" 均值: {conv_weights.mean().item():.6f}")print(f" 標準差: {conv_weights.std().item():.6f}")print(f" 理論標準差 (Kaiming): {np.sqrt(2/3):.6f}") # 輸入通道數為3# 全連接層fc_weights = model.fc.weight.dataprint("\n全連接層 權重統計:")print(f" 均值: {fc_weights.mean().item():.6f}")print(f" 標準差: {fc_weights.std().item():.6f}")print(f" 理論標準差 (Kaiming): {np.sqrt(2/(16*16*16)):.6f}")# 改進的可視化權重分布函數
def visualize_weights(model, layer_name, weights, save_path=None):plt.figure(figsize=(12, 5))# 權重直方圖plt.subplot(1, 2, 1)plt.hist(weights.cpu().numpy().flatten(), bins=50)plt.title(f'{layer_name} 權重分布')plt.xlabel('權重值')plt.ylabel('頻次')# 權重熱圖plt.subplot(1, 2, 2)if len(weights.shape) == 4: # 卷積層權重 [out_channels, in_channels, kernel_size, kernel_size]# 只顯示第一個輸入通道的前10個濾波器w = weights[:10, 0].cpu().numpy()plt.imshow(w.reshape(-1, weights.shape[2]), cmap='viridis')else: # 全連接層權重 [out_features, in_features]# 只顯示前10個神經元的權重,重塑為更合理的矩形w = weights[:10].cpu().numpy()# 計算更合理的二維形狀(嘗試接近正方形)n_features = w.shape[1]side_length = int(np.sqrt(n_features))# 如果不能完美整除,添加零填充使能重塑if n_features % side_length != 0:new_size = (side_length + 1) * side_lengthw_padded = np.zeros((w.shape[0], new_size))w_padded[:, :n_features] = ww = w_padded# 重塑并顯示plt.imshow(w.reshape(w.shape[0] * side_length, -1), cmap='viridis')plt.colorbar()plt.title(f'{layer_name} 權重熱圖')plt.tight_layout()if save_path:plt.savefig(f'{save_path}_{layer_name}.png')plt.show()# 打印權重統計
print_weight_stats(model)# 可視化各層權重
visualize_weights(model, "Conv1", model.conv1.weight.data, "initial_weights")
visualize_weights(model, "FC", model.fc.weight.data, "initial_weights")# 可視化偏置
plt.figure(figsize=(12, 5))# 卷積層偏置
conv_bias = model.conv1.bias.data
plt.subplot(1, 2, 1)
plt.bar(range(len(conv_bias)), conv_bias.cpu().numpy())
plt.title('卷積層 偏置')# 全連接層偏置
fc_bias = model.fc.bias.data
plt.subplot(1, 2, 2)
plt.bar(range(len(fc_bias)), fc_bias.cpu().numpy())
plt.title('全連接層 偏置')plt.tight_layout()
plt.savefig('biases_initial.png')
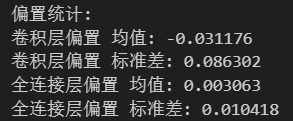
plt.show()print("\n偏置統計:")
print(f"卷積層偏置 均值: {conv_bias.mean().item():.6f}")
print(f"卷積層偏置 標準差: {conv_bias.std().item():.6f}")
print(f"全連接層偏置 均值: {fc_bias.mean().item():.6f}")
print(f"全連接層偏置 標準差: {fc_bias.std().item():.6f}")
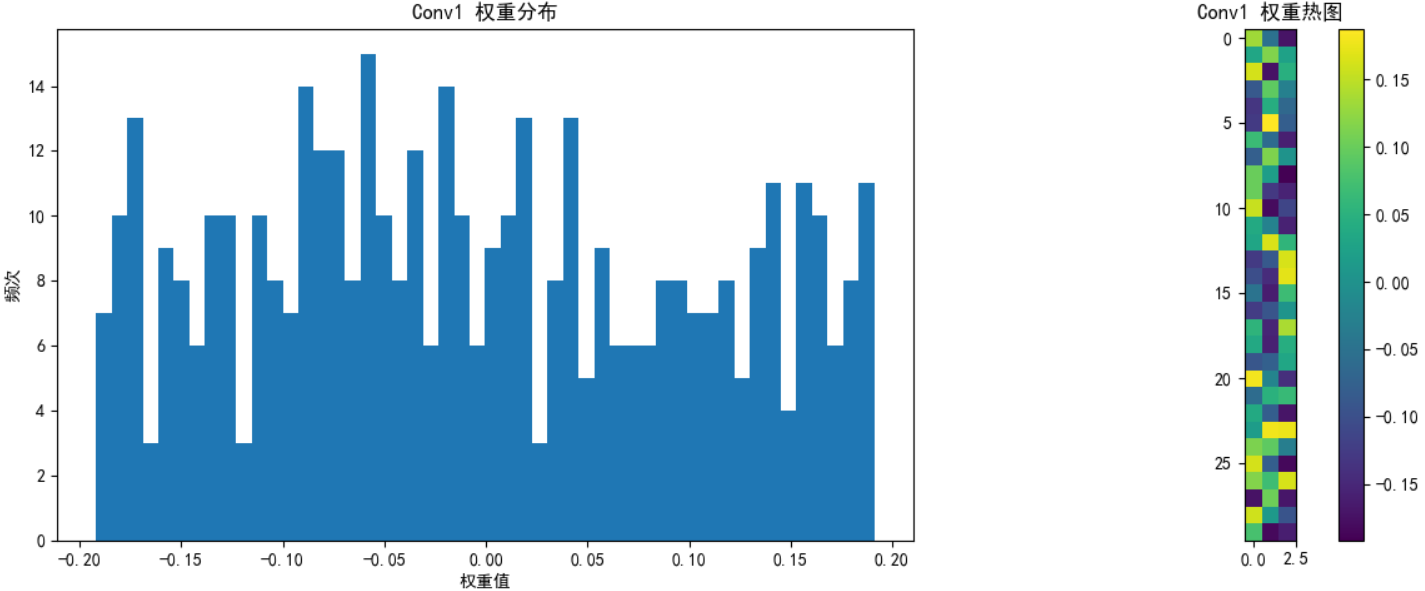
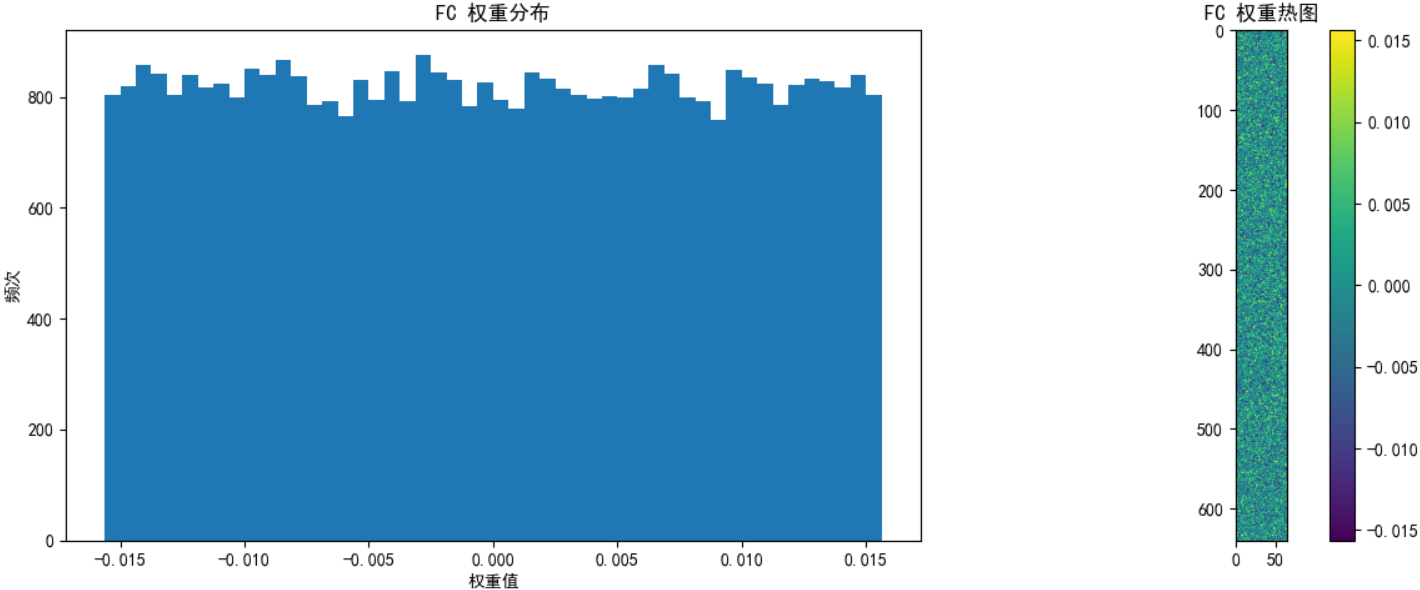
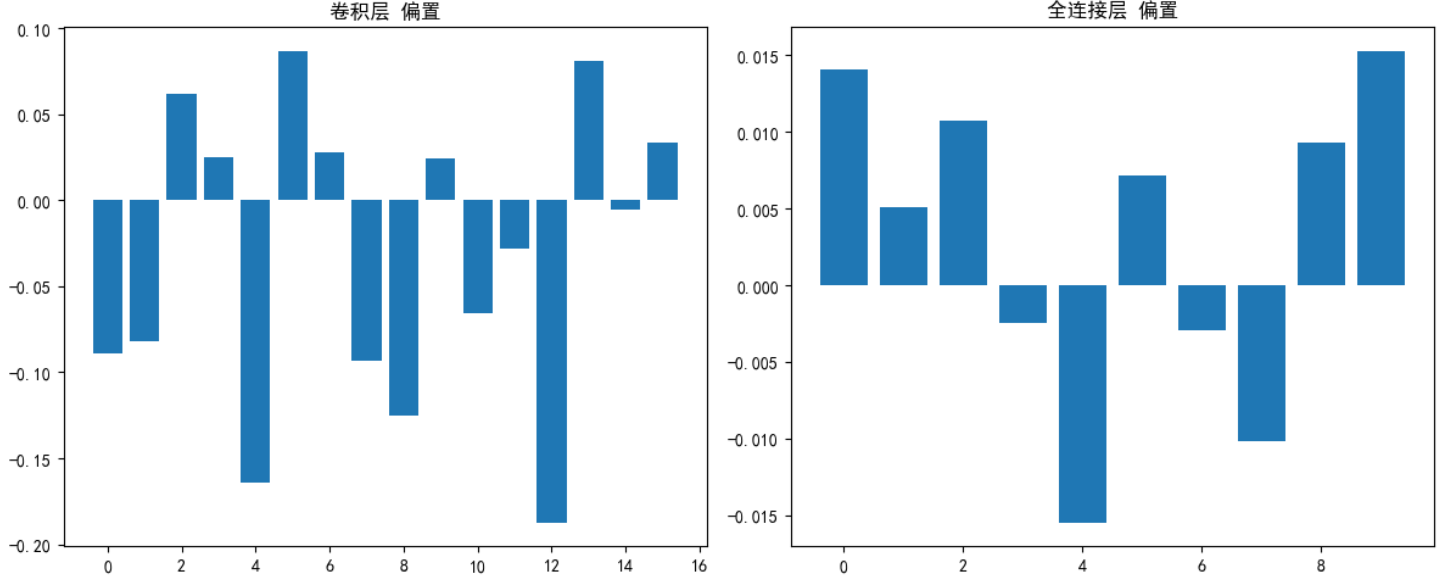
訓練時,權重會隨反向傳播迭代更新。通過權重分布圖,能直觀看到其從初始化(如隨機分布)到逐漸收斂、形成規律模式的動態變化,理解模型如何一步步 “學習” 特征 。比如,卷積層權重初期雜亂,訓練后可能聚焦于邊緣、紋理等特定模式。
識別梯度異常:
1. 梯度消失:若權重分布越來越集中在 0 附近,且更新幅度極小,可能是梯度消失,模型難學到有效特征(比如深層網絡用 Sigmoid 激活易出現 )。
2. 梯度爆炸:權重值突然大幅震蕩、超出合理范圍(比如從 [-0.1, 0.1] 跳到 [-10, 10] ),要警惕梯度爆炸,可能讓訓練崩潰。
借助tensorboard可以看到訓練過程中權重圖的變化。
神經網絡調參指南
大部分時候,由于光是固定超參數的情況下,訓練完模型就已經很耗時了,所以正常而言,基本不會采用傳統機器學習的那些超參數方法,網格、貝葉斯、optuna之類的,看到一些博主用這些寫文案啥的,感覺這些人都是腦子有問題的,估計也沒學過機器學習直接就學深度學習了,搞混了二者的關系。
工業界卡特別多的情況下,可能可以考慮,尤其是在探究一個新架構的時候,我們直接忽視這些即可,只有手動調參這一條路。
參數的分類
之前我們介紹過了,參數=外參(實例化的手動指定的)+內參,其中我們把外參定義為超參數,也就是不需要數據驅動的那些參數
通常可以將超參數分為三類:網絡參數、優化參數、正則化參數。
①網絡參數:包括網絡層之間的交互方式(如相加、相乘或串接)、卷積核的數量和尺寸、網絡層數(深度)和激活函數等。
②優化參數:一般指學習率、批樣本數量、不同優化器的參數及部分損失函數的可調參數。
③正則化參數:如權重衰減系數、丟棄比率(dropout)。
超參數調優的目的是優化模型,找到最優解與正則項之間的關系。網絡模型優化的目的是找到全局最優解(或相對更好的局部最優解),而正則項則希望模型能更好地擬合到最優。兩者雖然存在一定對立,但目標是一致的,即最小化期望風險。模型優化希望最小化經驗風險,但容易過擬合,而正則項用來約束模型復雜度。因此,如何平衡兩者關系,得到最優或較優的解,就是超參數調整的目標。
調參順序
調遵循 “先保證模型能訓練(基礎配置)→ 再提升性能(核心參數)→ 最后抑制過擬合(正則化)” 的思路,類似 “先建框架,再裝修,最后修細節”。
我們之前的課上,主要都是停留在第一步,先跑起來,如果想要更進一步提高精度,才是這些調參指南。所以下面順序建立在已經跑通了的基礎上。
1. 參數初始化----有預訓練的參數直接起飛
2. batchsize---測試下能允許的最高值
3. epoch---這個不必多說,默認都是訓練到收斂位置,可以采取早停策略
4. 學習率與調度器----收益最高,因為鞍點太多了,模型越復雜鞍點越多
5. 模型結構----消融實驗或者對照試驗
6. 損失函數---選擇比較少,試出來一個即可,高手可以自己構建
7. 激活函數---選擇同樣較少
8. 正則化參數---主要是droupout,等到過擬合了用,上述所有步驟都為了讓模型過擬合
這個調參順序并不固定,而且也不是按照重要度來選擇,是按照方便程度來選擇,比如選擇少的選完后,會減小后續實驗的成本。
初始化參數
預訓練參數是最好的參數初始化方法,在訓練前先找找類似的論文有無預訓練參數,其次是Xavir,尤其是小數據集的場景,多找論文找到預訓練模型是最好的做法。關于預訓練參數,我們介紹過了,優先動深層的參數,因為淺層是通用的;其次是學習率要采取分階段的策略。
如果從0開始訓練的話,PyTorch 默認用 Kaiming 初始化(適配 ReLU)或 Xavier 初始化(適配 Sigmoid/Tanh)。
bitchsize的選擇
一般學生黨資源都有限,所以基本都是bitchsize不夠用的情況,富哥當我沒說。
當Batch Size 太小的時候,模型每次更新學到的東西太少了,很可能白學了因為缺少全局思維。所以盡可能高一點,16的倍數即可,越大越好。
學習率調整
學習率就是參數更新的步長,LR 過大→不好收斂;LR 過小→訓練停滯(陷入局部最優)
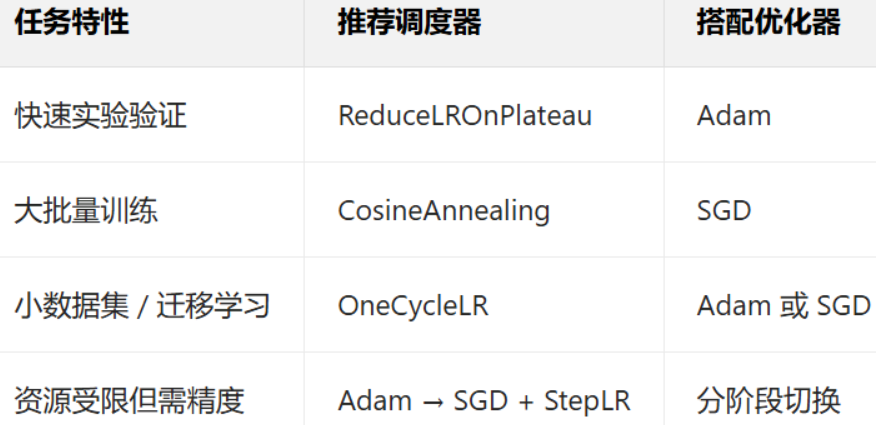
一般最開始用adam快速收斂,然后sgd收尾,一般精度會高一點;只能選一個就adam配合調度器使用。比如 CosineAnnealingLR余弦退火調度器、StepLR固定步長衰減調度器,比較經典的搭配就是Adam + ReduceLROnPlateau,SGD + CosineAnnealing,或者Adam → SGD + StepLR。
比如最開始隨便選了做了一組,后面為了刷精度就可以考慮選擇更精細化的策略了。
激活函數的選擇
視情況選擇,一般默認relu或者其變體,如leaky relu,再或者用tanh。只有二分類任務最后的輸出層用sigmoid,多分類任務用softmax,其他全部用relu即可。此外,還有特殊場景下的,比如GELU(適配 Transformer)
損失函數的選擇
大部分我們目前接觸的任務都是單個損失函數構成的,正常選即可
分類任務:
1. 交叉熵損失函數Cross-Entropy Loss——多分類場景
2. 二元交叉熵損失函數Binary Cross-Entropy Loss——二分類場景
3. Focal Loss——類別不平衡場景
注意點:
①CrossEntropyLoss內置 Softmax,輸入應為原始 logits(非概率)。
②BCEWithLogitsLoss內置 Sigmoid,輸入應為原始 logits。
③若評價指標為準確率,用交叉熵損失;若為 F1 分數,考慮 Focal Loss 或自定義損失。
回歸任務
1. 均方誤差MSE
2. 絕對誤差MAE
這個也要根據場景和數據特點來選,不同損失受到異常值的影響程度不同。
此外,還有一些序列任務的損失、生成任務的損失等等,以后再提。
后面會遇到一個任務中有多個損失函數構成,比如加權成一個大的損失函數,就需要注意到二者的權重配比還有數量級的差異。
模型架構中的參數
比如卷積核尺寸等,一般就是7*7、5*5、3*3這種奇數對構成,其實我覺得無所謂,最開始不要用太過分的下采樣即可。
神經元的參數,直接用 Kaiming 初始化(適配 ReLU,PyTorch 默認)或 Xavier 初始化(適配 Sigmoid/Tanh)。
正則化系數
droupout一般控制在0.2-0.5之間,這里說一下小技巧,先追求過擬合后追求泛化性。也就是說先把模型做到過擬合,然后在慢慢增加正則化程度。
正則化中,如果train的loss可以很低,但是val的loss還是很高,則說明泛化能力不強,優先讓模型過擬合,在考慮加大正則化提高泛化能力,可以分模塊來droupout,可以確定具體是那部分參數導致過擬合,這里還有個小trick是引入殘差鏈接后再利用droupout。
L2權重衰減這個在優化器中就有,這里提一下,也可以算是正則化吧。
其他補充
對于復雜的項目,盡可能直接對著別人已經可以跑通的源碼來改。----注意是可以跑通的,目前有很多論文的開源都是假開源。
在調參過程中可以監控tensorboard來關注訓練過程。
無論怎么調參,提升的都是相對較小,優先考慮數據+特征工程上做文章。還有很多試驗灌水的方法,自行搜索即可。
今天說的內容其實相對而言比較基礎,非常多的trick現在提也沒有價值,主要都是隨便一試出來了好結果然后編個故事,不具有可以系統化標準化的理解,掌握到今天說的這個程度夠用咯.大家現階段能把復雜的模型跑通和理解已經實屬不易。
@浙大疏錦行

)





全面解析)



)







:維護更多信息)