學習一個深度學習模型,我們首先需要從理論的角度理解它的構架,進而理解代碼。
Transformer背景
首先我們知道,神經網絡有一個巨大的家族,其中的CNN(卷積神經網絡)源于視覺研究,目標是讓機器自動學習圖像特征,而RNN的出現是源于對記憶和序列建模的需求,目標是處理自然語言、語音等時序數據。循環神經網絡(RNN)的關鍵思想是:不僅考慮當前輸入,它還會記住之前的輸入信息,把歷史信息通過隱藏狀態(hidden state)傳遞到下一步,從而實現“記憶”。所以,RNN可以用于自然語言處理(機器翻譯、文本生成),語音處理(語音識別),時間序列預測(天氣預測)等。
在RNN之前,語言模型主要是采用N-Gram,即預測當前詞是什么的時候,我們只假設它和前面的N個詞相關。顯然這個模型并不靠譜,因為有時候關鍵信息藏在幾句話之前。所以RNN出現了,它理論上可以向前/前后看任意多詞:
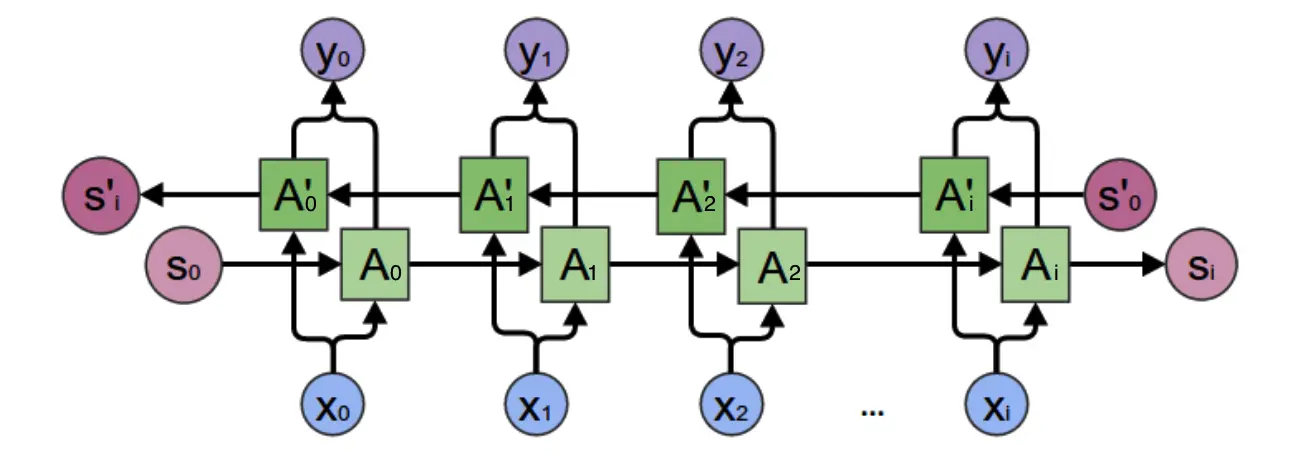
雙向循環神經網絡結構
因此,RNN一定程度解決了N-Gram無法處理的問題(RNN詳解見循環神經網絡)。但是RNN也存在自己的不足:
1. RNN在處理長序列問題的時候,反向傳播梯度會變得極小或極大,造成梯度消失或梯度爆炸
2. RNN難以捕捉長距離的依賴關系
3. RNN必須逐步處理輸入,無法并行計算,訓練速度緩慢
針對以上問題,科學家們想到了通過引入單元狀態(cell state)的方法(長短時記憶網絡)。LSTM的輸入包括:當前時刻的輸入值,上一時刻LSTM的輸出值
,以及上一時刻的單元狀態
。LSTM的輸出包括:當前時刻輸出值
,和當前時刻單元狀態
。LSTM的關鍵就是怎樣控制長期狀態
。它引入了三個狀態開關,即三個門:
1. 遺忘門:它決定了上一個時刻的單元狀態有多少保留到當前時刻單元狀態
2. 輸入門:它決定當前時刻網絡輸入有多少保留到單元狀態
3. 輸出門:它控制單元狀態有多少輸出到LSTM的當前輸出值

LSTM的前向計算
這樣,遺忘門的控制可以保留很早期的信息,輸入門的控制又可以避免當前無關緊要的信息進入記憶,輸出門的控制又可以保證輸出結果中包含早期的記憶。LSTM的引入使RNN能保留長期的依賴信息,緩解了梯度消失/爆炸的問題。后來在LSTM的基礎上還發展出了GRU,Seq2Seq架構。但是,這些模型并沒有本質上解決長距離依賴和訓練效率低的問題。直到Transformer的出現。
(LSTM詳解見長短時記憶網絡(LSTM))
Transformer前言
一、獨熱編碼(One-Hot Encoding)
計算機只能處理0/1編碼,所以在面對文字的時候,我們需要一個詞表來表示詞(Token),即通過0/1將詞表示為高維度稀疏向量(維度高,但大部分元素是0)。但是這樣表示出來的句子無法包含上下文信息,詞與詞之間完全沒有關系。因此在此基礎上,我們引入了詞嵌入。
二、詞嵌入
所謂詞嵌入,就是為詞表中的每個詞分配一個詞向量,將其映射到語義空間中。這里語義空間維度表示詞向量的維度,語義空間維度越高,語義表達能力就越強。詞向量的每個值都是浮點數,詞向量之間的距離也和詞的語義距離有關。例如,我們可以將“紅蘋果”表示為 [0.13, 0.16, -0.89, 0.9] ,“青蘋果”表示為 [0.12, 0.17, -0.88, 0.9] ,兩者十分相似。常見的語義空間維度包括512(Transformer),12288(GPT3)。
三、嵌入矩陣
假設我們通過一個維度為的語義空間表示了一個大小為
的詞表,則其中的每個Token都是一個維度為
的浮點向量,該詞表也就是一個
的矩陣。我們想要表示一個句子,那么在詞表中選擇我們用到的詞組成一個嵌入矩陣即可。例如“紅蘋果不是青蘋果”可以表示為:
四、位置編碼
在實現通過嵌入矩陣表示一個句子之后,我們如何把每個詞在句子中的位置表示給模型呢,畢竟詞之間的位置差異也會反映詞向量的相關關系。這里,我們就需要用到位置編碼。與詞嵌入相似,位置編碼也是一種將句中位置關系映射到一個向量中的方法。Transformer的位置編碼為:
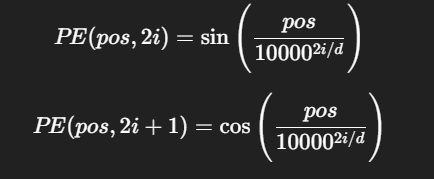
其中表示單詞在句子中的位置(0, 1, 2...),
表示當前維度的下標,即一個詞嵌入的第
個位置,
表示語義空間總維度。
這樣,假設詞向量維度,則對于一個三個Token的句子,它的位置編碼矩陣為:

最后,Transformer再將詞嵌入矩陣與位置編碼矩陣相加,得到文本序列的詞和詞序信息。
至于這個位置編碼是如何設計出來的,可以參考博客:Transformer位置編碼設計原理詳解
自注意力機制
在圖像分類任務中,我們知道判斷圖像類別是通過對圖像的特征進行分析得到的,那么在序列中我們也可以通過觀察句子中特定的詞來理解句子的意思,這種對序列特征的觀察就叫注意力。因此對于一個句子,其中的每個Token都應該有不同的注意力權重,當然,這個權重是相對于任意兩個Token之間的關系來說的。
那么Transformer是怎么做的呢?
首先,假設我們得到了一個句子的兩個詞向量和
,該向量包含了位置編碼信息。現在,我們通過每個Token?
映射出三個向量,表示為:
,query;
,key和
,value。其中這個三個向量的維度可以和詞向量維度不同,
的維度可以和
、
不同。這三個向量是如何映射得到的呢:
其中為三個可學習的權重矩陣。假設Token的維度為128(1*128),則通過128*64的權重矩陣,我們可以得到一個1*64的
。
接下來,我們計算對
的注意力和
對
的注意力:
這樣,我們通過將兩個64*1和1*64的向量相乘,會得到兩個結果,當這兩個向量維度較大時,點積的數值幅度會顯著增大,導致訓練時梯度消失。為了解決這個問題,Transformer對點積的結果進行縮放,縮放因子為:,
為向量維度,即:
當一個序列中有個Token時,我們兩兩計算其注意力,可以得到一個
的注意力矩陣,表示為:
接下來,我們對這個注意力矩陣進行歸一化,使其等同于概率分布。這里的歸一化是針對注意力矩陣的每一行進行的,即一個句子中的第個Token(第
行),這樣,我們可以得到第
個Token相對于句子中其它Token的概率分布。
最后一步,我們會用到value矩陣。假設一個句子有6個Token(
),則
矩陣會是一個6*64的結構,每一行表示一個Token的value,將其與
矩陣相乘(6*6):
可以得到一個6*64的矩陣,這個矩陣就是最終的注意力矩陣。
為什么Transformer要這樣做呢?
首先,計算了句子中一個Token與另一個Token的匹配程度(注意力分數),矩陣中第
行第
列即表示了
Token對
Token的注意力。Softmax后我們就可以知道哪些位置相對來說更重要。而為了結合具體的語義信息,我們還需要將這個歸一化權重與句子的初始嵌入相乘得到加權詞矩陣,這樣,這個最后的矩陣就是“每個Token的新表示”矩陣,包括了上下文信息的矩陣。
部分內容參考:零基礎入門深度學習(9) - Transformer (2/3)
多頭注意力
多頭注意力機制,按其字面信息,即表示多個參數向量組——多個向量。單頭注意力存在一定缺陷,每個序列的Token只能通過一個投影矩陣
去學習相關性和信息,但是語言的關系是多樣的(比如語法結構和語義依賴關系是兩種完全不同的語義空間),這樣,我們就需要多個注意力頭在不同的子語義空間計算注意力,關注一個序列的不同面。
為了不增加計算量和模型參數量,通常設置每個注意力頭的維度是原先的,即:
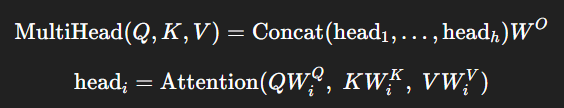
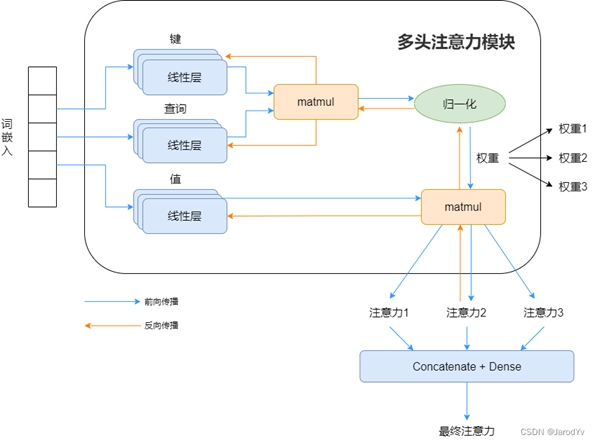
計算過程:
首先不同投影矩陣把輸入序列映射到多個子空間,每個子空間的維度是
,
在每個子空間分別計算注意力,得到多個head
拼接所有head的結果,
為Token數,
為head數,
為子空間維度
乘投影回原先語義空間維度
因果注意力
與普通的注意力不同,Transformer在生成文本時只能看到該位置之前的Token,因此與用于理解文本的雙向注意力相比,單向注意力機制——因果注意力會有所不同。這種單向注意力機制可以通過掩碼實現。
假設輸入序列的Token數為,掩碼矩陣定義為:
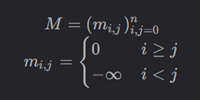
不難發現,表示允許當前位置和歷史位置交互,
表示禁止與未來位置交互,其中
表示
向量的位置,
表示
向量的位置,即
位置的注意力只能由
位置之前的Token決定。掩碼矩陣
實際上是一個上三角矩陣:
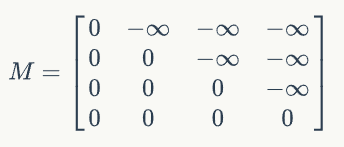
在計算注意力權重時,掩碼矩陣直接通過相加融入注意力矩陣:

Transformer整體架構
Transformer總體上采用編碼器+解碼器的結構:
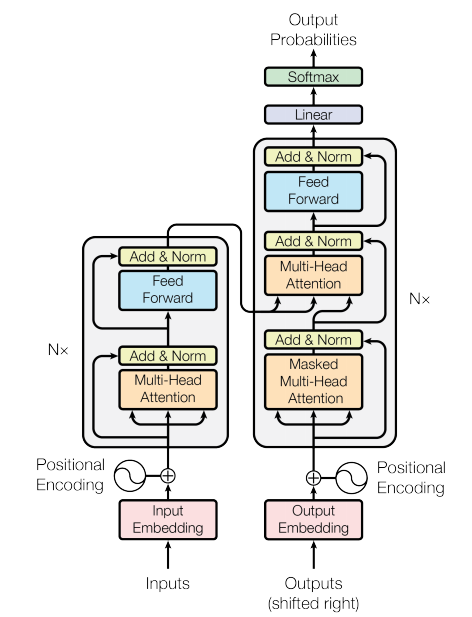
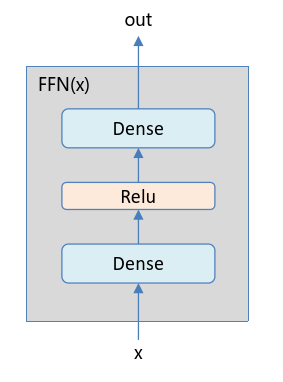
首先,編碼器負責接收序列輸入inputs,輸出為編碼到語義空間的一系列Token。具體來說,輸入先轉換為詞嵌入,再引入位置嵌入,然后輸入多頭注意力層;接下來,殘差網絡的引入(Add)解決了梯度消失等問題(詳見ResNet);層歸一化(Norm)保證訓練穩定,加速模型收斂;FFN提供非線性變化,同時為Token內各個維度提供了信息整合的渠道,即Token向量內部變換。上述子串構成了一個編碼器層,一個完整的Transformer編碼器包含N個編碼器層。
解碼器負責生成新的序列。解碼序列中有兩個特殊的Token:[start]和[end],表示生成序列的開始與結束。
解碼器的結構和編碼器非常相似,除了兩點不同:第一點不同,解碼器只能根據已經生成的Token去生成新的Token,因此需要使用因果注意力機制,即用Masked Multi-Head Attention替代了編碼器中的Multi-Head Attention。
第二點不同,解碼器在生成每個Token時,需要將編碼器的輸出序列也作為輸入序列的一部分,因此需要一個額外的Multi-Head Attention子層實現編碼器和解碼器的交叉注意力機制。具體來說,解碼器根據上一子層Masked Multi-Head Attention的輸出投影向量,根據編碼器對應層的輸出投影
,
向量,再根據注意力公式進行計算,從而使得解碼器輸出的Token可以融合編碼器輸出Token的信息。
一個完整的Transformer解碼器包含個解碼器層,在Transformer的設計中,編碼器和解碼器層數相同。這樣,每個解碼器層都可以將對應的編碼器層輸出作為輸入,從而可以同步頂層、中層和低層信息。
解碼器最終如何輸出詞表中的詞呢?當解碼器的最后一個Transformer層輸出后,這個輸出經過一次線性變換Linear,將維度從詞向量維度變為詞表的大小
,再經過
Softmax歸一化后,使之產生概率的意義。即最后的輸出Output Probabilities是一個向量,其維度是詞表大小,這個向量的每個元素對應詞表中的詞的預測概率。對這個概率進行采樣,就可以輸出對應的詞。
(以上內容參考零基礎入門深度學習(10) - Transformer (3/3))