目錄
一、前言
二、Docker 搭建kafka介紹
2.1 Docker 命令部署
2.2 使用Docker Compose 部署
2.3 使用 Docker Swarm
2.4 使用 Kubernetes
2.5 部署建議
三、Docker 搭建kafka操作方式一
3.1 前置準備
3.2 完整操作過程
3.2.1 創建docker網絡
3.2.2 啟動zookeeper容器
3.3 啟動kafka容器
3.4 效果測試與驗證
四、Docker 搭建kafka操作方式二
4.1 前置說明
4.2 KRaft 模式部署kafka操作過程
4.2.1 前置準備
4.2.2 獲取鏡像
4.2.3 創建數據目錄
4.2.4 啟動 Kafka Broker
4.2.5 驗證生產消費是否可用
五、寫在文末
一、前言
kafka作為一款性能強勁且經過各類大型項目考驗過的消息中間件,在全世界的知名度和認可度非常高,也是很多處理高并發、大數據量場景下的首選。隨著Docker容器化的發展越加成熟,基于Docker部署各類中間件時間成本越越來越低,本文介紹下基于Docker部署kafka的兩種操作方式。
二、Docker 搭建kafka介紹
Docker 是一個開源的應用容器引擎,讓開發者可以打包、分發和運行應用程序在任何環境上。使用 Docker 部署 Kafka 可以簡化配置和管理,特別是在需要快速搭建開發和測試環境時非常有用。下面介紹幾種 Docker 搭建 Kafka 的一些常用方案及其與傳統部署方式的對比。
2.1 Docker 命令部署
使用純粹的 Docker 命令(docker run)來部署 Kafka。這種方式更直接,便于理解容器運行的細節,也非常適合快速啟動單個容器進行測試。這種方式通常需要搭配zookeeper一起部署使用。
2.2 使用Docker Compose 部署
這是最簡單、最快速的啟動方式,通過一個 YAML 文件定義和運行多個容器(ZooKeeper 和 Kafka)。參考下面的示例。
優點:一鍵部署、配置即代碼、易于版本控制和分享。
缺點:單機部署,無法充分利用 Docker Swarm 或 Kubernetes 的集群能力。
version: '3.8'
services:zookeeper:image: confluentinc/cp-zookeeper:7.4.0hostname: zookeepercontainer_name: zookeeperports:- "2181:2181"environment:ZOOKEEPER_CLIENT_PORT: 2181ZOOKEEPER_TICK_TIME: 2000volumes:- ./zk-data:/var/lib/zookeeper/data- ./zk-logs:/var/lib/zookeeper/logkafka:image: confluentinc/cp-kafka:7.4.0hostname: kafkacontainer_name: kafkadepends_on:- zookeeperports:- "9092:9092"- "29092:29092" # 用于容器內網絡訪問的監聽器environment:KAFKA_BROKER_ID: 1KAFKA_ZOOKEEPER_CONNECT: "zookeeper:2181"KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT# 外部客戶端(宿主機或其他機器)通過這個地址連接KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9092,PLAINTEXT_HOST://localhost:29092KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1KAFKA_AUTO_CREATE_TOPICS_ENABLE: "true"KAFKA_PROCESS_ROLES: "broker"KAFKA_CONTROLLER_LISTENER_NAMES: "CONTROLLER"volumes:- ./kafka-data:/var/lib/kafka/data2.3 使用 Docker Swarm
這種方式適用于簡單的集群部署,Docker Compose 的集群模式版本。它可以在一組主機上部署服務,并提供簡單的服務發現和負載均衡。特點:
-
使用
docker stack deploy -c docker-compose.yml kafka_stack命令部署。 -
需要配置共享存儲(如 NFS、Ceph)以便所有 Swarm 節點都能訪問 Kafka 和 ZooKeeper 的數據卷,復雜度較高。
-
對于有狀態且需要穩定網絡標識的服務 like Kafka,Swarm 的管理不如 Kubernetes 成熟。
2.4 使用 Kubernetes
這是部署生產級、高可用 Kafka 集群最強大和最推薦的方式。
-
Operator 模式:這是最主流的方式。Operator 是一種自定義 Kubernetes 控制器,它封裝了管理 Kafka 集群的專業知識(如部署、配置、擴縮容、升級、故障轉移)。
-
Strimzi Operator:目前最流行、功能最全面的 Kafka Kubernetes Operator。它提供了極其豐富的 CRD(自定義資源)來定義 Kafka 集群、Topic、用戶等。
-
Confluent Operator:Confluent 公司官方提供的 Operator,與 Confluent 平臺的其他組件(如 Connect、Schema Registry)集成更好,但部分高級功能需要商業許可。
-
2.5 部署建議
-
開發與測試環境:強烈推薦使用 Docker Compose。它是搭建本地和測試環境的事實標準,能極大提升效率。
-
生產環境:
-
如果追求敏捷、彈性、云原生,并且技術團隊具備相應能力,使用 Kubernetes + Strimzi Operator 是最佳選擇。
-
如果對性能有極致要求,或者運維體系基于傳統物理機/虛擬機且非常穩定,傳統部署方式仍然是可靠的選擇。許多大規模互聯網公司依然采用物理機部署核心消息隊列集群。
-
最終,選擇哪種方式取決于你的團隊技術棧、業務需求和對運維模式的規劃。
三、Docker 搭建kafka操作方式一
3.1 前置準備
-
服務器環境:Linux操作系統
-
服務器配置:2核4G
-
Docker環境,提前安裝好Docker環境;
3.2 完整操作過程
搭配zookeeper進行使用,這個是部署kafka比較經典的方式,參考下面的完整操作過程。
3.2.1 創建docker網絡
為了更好的讓kafka與zookeeper交互,提前創建一個docker網絡
docker network create kafka-net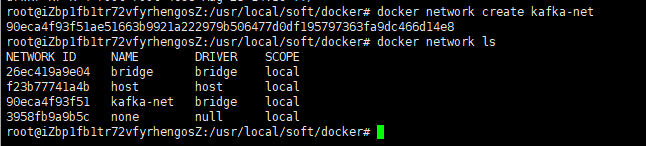
3.2.2 啟動zookeeper容器
使用下面的命令啟動zk容器
docker run -d \--name zookeeper_01 \--network kafka-net \-p 12179:2181 \-e ZOO_TICK_TIME=2000 \zookeeper:latest
參數解釋:
-
-d: 后臺運行容器。 -
--name: 為容器指定一個名稱。 -
--network: 加入創建的kafka-net網絡。 -
-p 12179:2181: 將容器的12179端口映射到宿主機的 2181 端口。 -
-e ZOO_TICK_TIME=2000: 設置 ZooKeeper 的基本時間單位(毫秒)。
3.3 啟動kafka容器
使用下面的命令啟動kafka容器
docker run -d \
--name kafka_01 \
-p 19091:9092 \
-e KAFKA_BROKER_ID=0 \
-e KAFKA_ZOOKEEPER_CONNECT=服務器公網IP:12179 \
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://服務器公網IP:19091 \
-e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 \
wurstmeister/kafka:latest
docker 參數說明:
-
KAFKA_ADVERTISED_LISTENERS: 非常重要。Broker 發布給客戶端(生產者、消費者)的連接地址。如果客戶端在宿主機外,需替換localhost為宿主機 IP。 -
KAFKA_LISTENERS: Broker 實際監聽的地址和協議,0.0.0.0表示監聽所有網絡接口。 -
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 設置內部偏移量主題的副本因子,單機設為 1 即可。
3.4 效果測試與驗證
kafka的服務搭建完成之后,接下來驗證下是否可以先通過客戶端操作命令正常使用topic進行收發消息。
1)進入 Kafka 容器:
docker exec -it kafka_01 /bin/bash2)創建一個topic
# 傳統模式
kafka-topics.sh --create --zookeeper 公網IP:12179 --replication-factor 1 --partitions 1 --topic test-topic
3)啟動生產者窗口
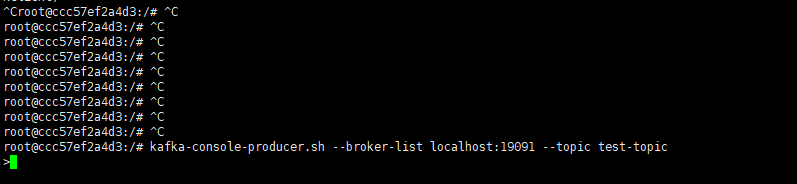
開啟一個生產者窗口,嘗試往上面的topic中發送消息
kafka-console-producer.sh --broker-list 公網IP:19091 --topic test-topic看到下面的效果說明生產端連接上了
4)啟動消費者窗口
開啟一個新的消費者窗口,嘗試從上面的topic中接收消息
kafka-console-consumer.sh --bootstrap-server 公網IP:19091 --topic test-topic --from-beginning看到下面的效果說明消費端接收消息就緒了

5)發送消息
接下來從生產者窗口發送一條消息,可以看到消息能夠正常的發送出去,同時消費端也能接收到消息

四、Docker 搭建kafka操作方式二
4.1 前置說明
基于Docker部署kafka目前有兩種主流的方式,一是使用ZooKeeper 的模式,另一種則是無需zk的KRaft 模式,兩種模式的區別如下:
| 特性 | 傳統 ZooKeeper 模式 | KRaft 模式 (無需 ZooKeeper) |
| 架構 | Kafka Broker 依賴外部的 ZooKeeper 集群進行元數據管理 | Kafka 使用內置的 Raft 協議進行元數據管理,無需額外組件 |
| 資源占用 | 較高(需運行 ZooKeeper 容器) | 較低(只需運行 Kafka 容器) |
| 復雜度 | 相對較高(需管理兩個容器及它們之間的配置) | 相對較低(配置集中于單個容器) |
| 推薦場景 | 學習、測試兼容舊版本 | 希望部署更簡單、資源占用更少的新版本環境 |
4.2 KRaft 模式部署kafka操作過程
接下來演示基于KRaft 模式部署kafka完整過程。
4.2.1 前置準備
確保你的系統已安裝 Docker。可以通過以下命令檢查:
docker --version
4.2.2 獲取鏡像
我們將使用廣泛認可的 wurstmeister/kafka 和 zookeeper 鏡像(用于傳統模式)或 apache/kafka 鏡像(用于 KRaft 模式)。這里使用KRaft 的方式獲取安裝的鏡像(無需zookeeper)。
docker pull apache/kafka:3.9.0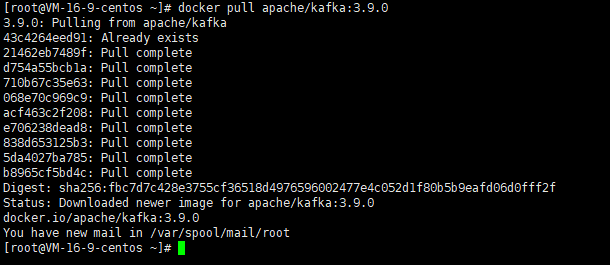
4.2.3 創建數據目錄
可選,用于數據持久化
mkdir -p /data/kafka/data
mkdir -p /data/kafka/config
mkdir -p /data/kafka/secrets4.2.4 啟動 Kafka Broker
使用下面的命令啟動kafka容器
# 運行容器
sudo docker run --privileged=true \
--net=bridge \
-d --name=kafka-kraft \
-v /data/kafka/data:/var/lib/kafka/data \
-v /data/kafka/config:/mnt/shared/config \
-v /data/kafka/secrets:/etc/kafka/secrets \
-p 9092:9092 -p 9093:9093 \
-e TZ=Asia/Shanghai \
-e LANG=C.UTF-8 \
-e KAFKA_NODE_ID=1 \
-e CLUSTER_ID=kafka-cluster \
-e KAFKA_PROCESS_ROLES=broker,controller \
-e KAFKA_INTER_BROKER_LISTENER_NAME=PLAINTEXT \
-e KAFKA_CONTROLLER_LISTENER_NAMES=CONTROLLER \
-e KAFKA_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093 \
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://公網IP:9092 \
-e KAFKA_CONTROLLER_QUORUM_VOTERS=1@localhost:9093 \
apache/kafka:3.9.0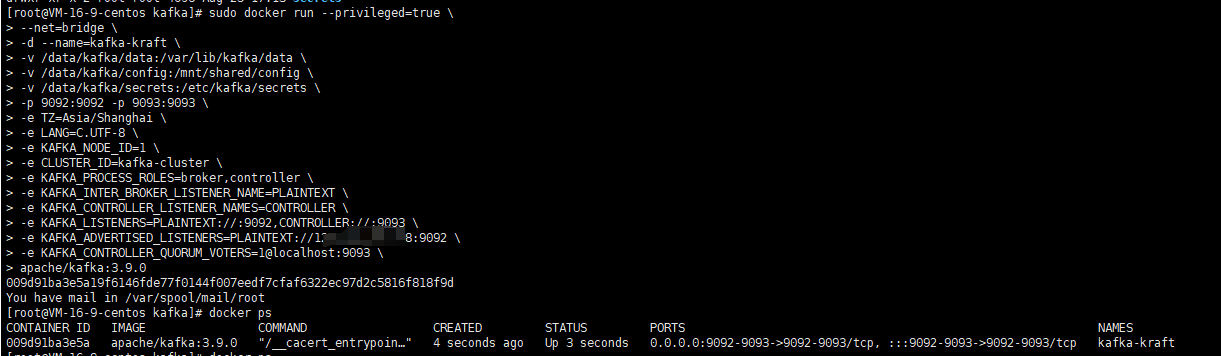
| 參數 | 參數說明 |
| docker run | 運行 Docker 容器 |
| -d | 容器將在后臺運行,而不是占用當前的終端會話 |
| --privileged=true | Docker會賦予容器幾乎與宿主機相同的權限 |
| --net=bridge | 網絡模式配置,默認是bridge,bridge表示使用容器內部配置網絡 |
| --name kafka-kraft | 給容器命名為 kafka-kraft,以便于管理和引用該容器 |
| -p 9092:9092 -p 9093:9093 | 映射 kafka 的客戶端通信端口和控制器端口 |
| -e KAFKA_NODE_ID=1 | 節點ID,用于標識每個集群中的節點,需要是不小于1的整數,同一個集群中的節點ID不可重復 |
| -e CLUSTER_ID=kafka-cluster | 集群ID,可以自定義任何字符串作為集群ID,同一個集群中所有節點的集群ID必須配置為一樣 |
| -e KAFKA_PROCESS_ROLES=broker,controller | 節點類型,broker,controller表示該節點是混合節點,通常單機部署時需要配置為混合節點 |
| -e KAFKA_INTER_BROKER_LISTENER_NAME= PLAINTEXT | Kafka的Broker地址前綴名稱,固定為PLAINTEXT即可 |
| -e KAFKA_CONTROLLER_LISTENER_NAMES= CONTROLLER | Kafka的Controller地址前綴名稱,固定為CONTROLLER即可 |
| -e KAFKA_LISTENERS= PLAINTEXT://:9092,CONTROLLER://:9093 | 表示Kafka要監聽哪些端口,PLAINTEXT://:9092,CONTROLLER://:9093表示本節點作為混合節點,監聽本機所有可用網卡的9092和9093端口,其中9092作為客戶端通信端口,9093作為控制器端口 |
| -e KAFKA_ADVERTISED_LISTENERS= PLAINTEXT://192.168.3.9:9092 | 配置Kafka的外網地址,需要是PLAINTEXT://外網地址:端口的形式,當客戶端連接Kafka服務端時,Kafka會將這個外網地址廣播給客戶端,然后客戶端再通過這個外網地址連接,除此之外集群之間交換數據時也是通過這個配置項得到集群中每個節點的地址的,這樣集群中節點才能進行交互。需要修改為對應的Kafka的外網地址。 |
| -e KAFKA_CONTROLLER_QUORUM_VOTERS= 1@localhost:9093 | 投票節點列表,通常配置為集群中所有的Controller節點,格式為節點id@節點外網地址:節點Controller端口,多個節點使用逗號,隔開,由于是混合節點,因此配置自己就行了 |
| -v /data/docker/kafka-kraft/data: /var/lib/kafka/data | 持久化數據文件夾,如果運行出現問題可以清空該數據卷文件重啟再試 |
| -v /data/docker/kafka-kraft/config: /mnt/shared/config | 持久化配置文件目錄 |
| -v /data/docker/kafka-kraft/secrets: /etc/kafka/secrets | 持久化秘鑰相關文件夾 |
4.2.5 驗證生產消費是否可用
參考上面的方式,分別創建一個生產者和一個消費者,查看消費者是否能夠收到生產者生產的消息
# 1.進入kafka容器內
sudo docker exec -it kafka-kraft /bin/bash# 2.進入kafka安裝目錄
cd /opt/kafka/bin# 3、創建一個測試的topic
./kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic test01 # 4、查詢主題列表
./kafka-topics.sh --bootstrap-server localhost:9092 --list# 5.生產消息
./kafka-console-producer.sh --topic test01 --bootstrap-server localhost:9092# 6.消費消息
./kafka-console-consumer.sh --topic test01 --from-beginning --bootstrap-server localhost:9092 --partition 0# 查詢消費組列表
./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list1)創建一個topic

2)查看topic 列表

3)開啟一個生產者窗口

發送2條消息

4)開啟一個消費者窗口

五、寫在文末
本文通過案例操作演示了基于Docker環境部署單節點kafka服務的完整操作過程,更多深入的點有興趣的同學可以基于研究,本篇到此介紹,感謝觀看。



![for in+邏輯表達式 生成迭代對象,最后轉化為列表 ——注意list是生成器轉化為列表,但[生成器]得到的就是一個列表,其中包含一個生成器元素](http://pic.xiahunao.cn/for in+邏輯表達式 生成迭代對象,最后轉化為列表 ——注意list是生成器轉化為列表,但[生成器]得到的就是一個列表,其中包含一個生成器元素)


:融合FSATFusion的醫學圖像分割)







)

TCP并發服務器構建)


