知識點回顧:
- 時序建模的流程
- 時序任務經典單變量數據集
- ARIMA(p,d,q)模型實戰
- SARIMA摘要圖的理解
- 處理不平穩的2種差分
- n階差分---處理趨勢
- 季節性差分---處理季節性
昨天我們掌握了AR, MA, 和 ARMA 模型,它們是處理平穩時間序列的利器。但現實世界的數據,比如股票價格、公司銷售額,往往帶有明顯的趨勢性或季節性,它們是不平穩的。今天,我們就來學習ARIMA模型,它正是為了解決這個問題而生的。
他進一步引入差分來解決不平穩問題
差分是使數據平穩化的關鍵步驟。
一階差分: 就是序列中每個點減去它前一個點的值。
diff(t) = value(t) - value(t-1)
這通常可以消除數據中的線性趨勢。
二階差分: 對一階差分后的結果再做一次差分。
diff2(t) = diff(t) - diff(t-1)
這可以消除數據中的曲線趨勢(比如拋物線趨勢)。
ARIMA建模的完整流程
建立一個ARIMA模型,通常遵循以下步驟:
- 數據可視化:觀察原始時間序列圖,判斷是否存在趨勢或季節性。
- 平穩性檢驗:
- 對原始序列進行ADF檢驗。
- 如果p值 > 0.05,說明序列非平穩,需要進行差分。
- 確定差分次數 d:
- 進行一階差分,然后再次進行ADF檢驗。
- 如果平穩了,則 d=1。否則,繼續差分,直到平穩。
- 確定 p 和 q:
- 對差分后的平穩序列繪制ACF和PACF圖。
- 根據昨天學習的規則(PACF定p,ACF定q)來選擇p和q的值。
- 建立并訓練ARIMA(p, d, q)模型。
- 模型評估與診斷:查看模型的摘要信息,檢查殘差是否為白噪聲。
- 進行預測
一、 時序任務經典數據集
就像機器學習有鳶尾花、手寫數字、波士頓房價這些“標準”數據集一樣,時間序列分析領域也有一些“名人堂”成員。
這些經典數據集之所以經典,是因為它們各自清晰地展示了時間序列中一種或多種核心特征(如趨勢、季節性、周期性等),非常適合用來教學和檢驗模型。
下面介紹幾個最著名、最常用的單變量時間序列經典數據集,并附上獲取它們的代碼。
1.1 國際航空乘客數量 (Airline Passengers)
- 數據描述: 1949年到1960年每月國際航空公司的總乘客數量。
- 強趨勢性: 隨著時間推移,乘客數量有非常明顯的線性增長趨勢。
- 強季節性: 每年都有一個固定的模式,夏季(6-8月)是高峰,冬季是低谷。
- 變化的方差: 越到后期,季節性波動的幅度越大,這是一種異方差性。
import pandas as pd
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/airline-passengers.csv'
df_air = pd.read_csv(url, header=0, index_col=0, parse_dates=True)
df_air.head()# 這是一種直接使用 URL 在線讀取數據集的方式,代碼通過pd.read_csv(url)直接從網絡 URL 讀取數據,Pandas 會自動處理網絡請求并加載數據到內存中,屬于 “在線讀取” 方式。df_air.plot()# <matplotlib.axes._subplots.AxesSubplot at 0x29eb6ea3e80>| Passengers | |
|---|---|
| Month | |
| 1949-01-01 | 112 |
| 1949-02-01 | 118 |
| 1949-03-01 | 132 |
| 1949-04-01 | 129 |
| 1949-05-01 | 121 |
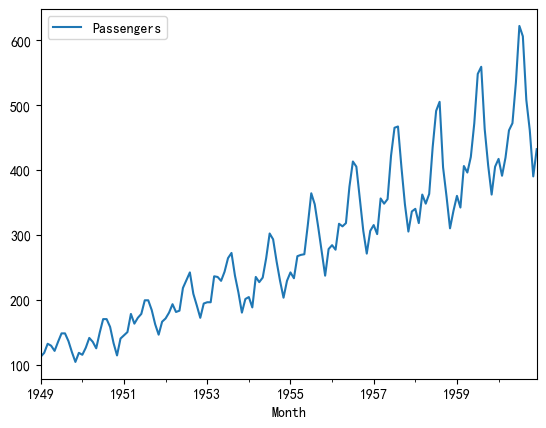
這里沒有導入matplotlib仍然可以畫圖,是因為當調用df.plot()時,Pandas 會隱式導入 Matplotlib(如果尚未導入),并使用其繪圖接口生成圖表。對于簡單的可視化需求,無需顯式導入 Matplotlib,減少代碼量。這里省略了plt.title(‘xxx’)和plt.show()等
1.2 太陽黑子數量 (Sunspots)
- 數據描述: 每年觀測到的太陽黑子數量。
- 無明顯趨勢: 長期來看,數據沒有持續的上升或下降趨勢。
- 強周期性 (Cyclical): 數據呈現非常明顯的周期性波動,大約每11年一個周期。注意,這與“季節性”不同,季節性周期是固定的(如12個月),而這里的周期長度是近似的。
- 相對平穩: 經過檢驗,數據通常被認為是平穩或近似平穩的。
from statsmodels.datasets import sunspots
df_sun = sunspots.load_pandas().data['SUNACTIVITY']
df_sun.head()# 0 5.0
# 1 11.0
# 2 16.0
# 3 23.0
# 4 36.0
# Name: SUNACTIVITY, dtype: float64df_sun.plot()# <matplotlib.axes._subplots.AxesSubplot at 0x29eb29bde80>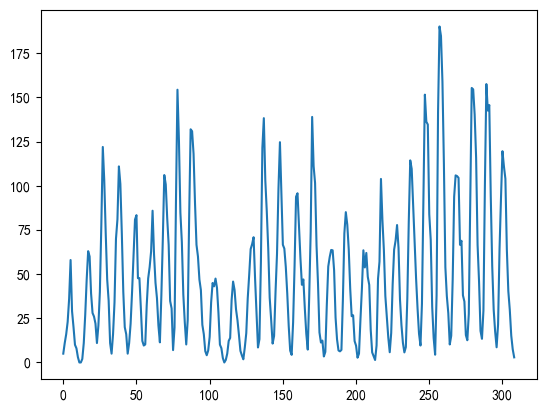
非常適合用來理解ARMA模型。由于數據本身比較平穩,不需要差分,可以專注于用ACF和PACF圖來確定 p 和 q 的值。
1.3 加州每日女性出生數量 (Daily Female Births)
- 數據描述: 1959年,美國加州每一天的女性新生兒數量。
- 無趨勢、無季節性: 數據看起來像隨機波動,沒有明顯的趨勢或可預測的季節模式。
- 平穩性: ADF檢驗通常會顯示該序列是平穩的。
import pandas as pd
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/daily-total-female-births.csv'
df_births = pd.read_csv(url, header=0, index_col=0, parse_dates=True)
# df_births.plot()
df_births.plot()# <matplotlib.axes._subplots.AxesSubplot at 0x29eb6fede80>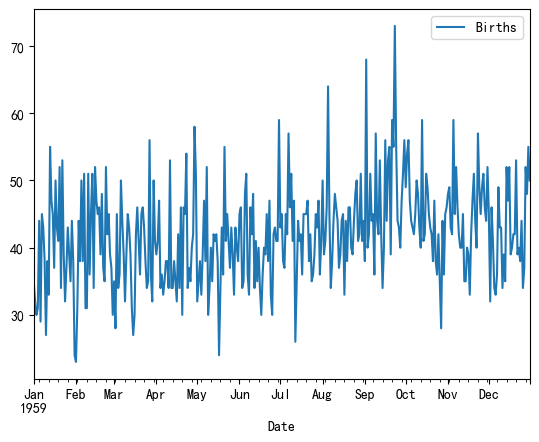
二、時間序列任務實戰
進階: 使用 太陽黑子 數據,讓學員練習用ACF/PACF為ARMA模型定階。
核心: 用 國際航空乘客 數據,系統地講解從非平穩到平穩(差分),再到建立ARIMA和SARIMA的全過程。
2.1 加州每日女性預測
# 導入必要的庫
import pandas as pd
import matplotlib.pyplot as plt
from statsmodels.tsa.stattools import adfuller
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
from statsmodels.tsa.arima.model import ARIMA# 設置matplotlib以正確顯示中文
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 加載數據
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/daily-total-female-births.csv'
df = pd.read_csv(url, header=0, index_col=0, parse_dates=True)
df.columns = ['Births']
ts_data = df['Births']print("--- 原始數據預覽 ---")
print(ts_data.head())# 繪制時序圖
plt.figure(figsize=(14, 7))
plt.plot(ts_data)
plt.title('1959年加州每日女性出生數量')
plt.xlabel('日期')
plt.ylabel('出生數量')
plt.show()#--- 原始數據預覽 ---
# Date
# 1959-01-01 35
# 1959-01-02 32
# 1959-01-03 30
# 1959-01-04 31
# 1959-01-05 44
# Name: Births, dtype: int64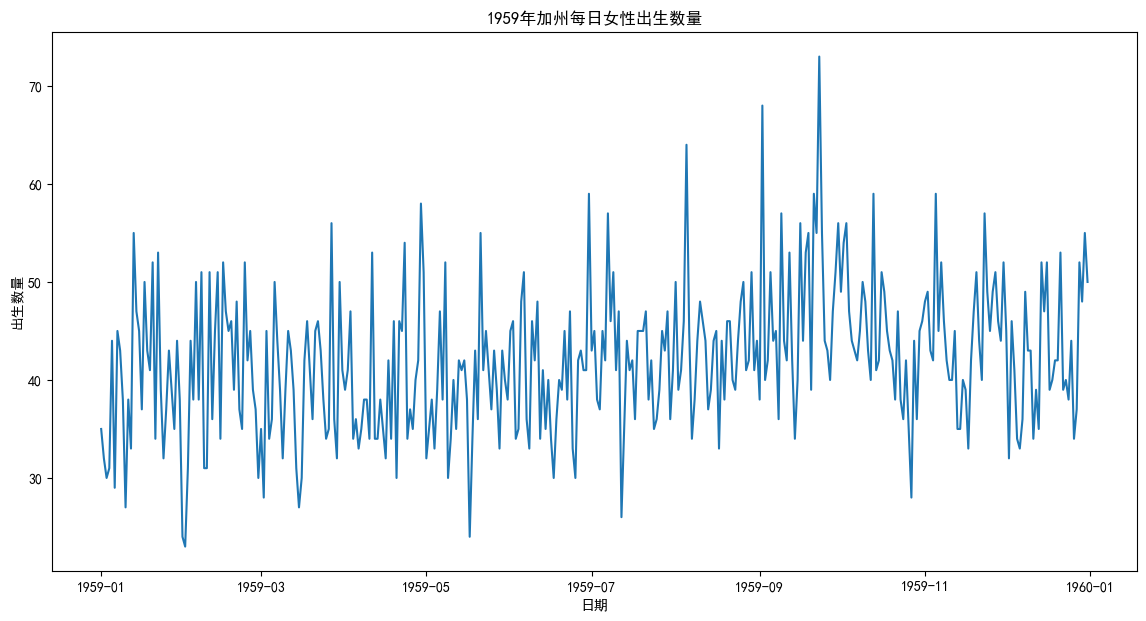
從圖上看,數據點在一個穩定的水平線(大約40)上下隨機波動。沒有明顯的上升或下降趨勢,也沒有看到以周或月為單位的固定模式。這給我們一個初步印象:這個序列很可能是平穩的。
直覺需要被驗證。我們使用ADF檢驗來科學地判斷其平穩性。
def adf_test(timeseries):print('--- ADF檢驗結果 ---')# H0: 序列非平穩; H1: 序列平穩result = adfuller(timeseries)print(f'ADF Statistic: {result[0]}')print(f'p-value: {result[1]}') # 重點關注這個值if result[1] <= 0.05:print("結論: 成功拒絕原假設,序列是平穩的。")else:print("結論: 未能拒絕原假設,序列是非平穩的。")adf_test(ts_data)# --- ADF檢驗結果 ---
# ADF Statistic: -4.808291253559765
# p-value: 5.2434129901498554e-05
# 結論: 成功拒絕原假設,序列是平穩的。既然數據是平穩的,我們就不需要對它進行差分來“鏟平”它。這意味著:差分次數 d = 0
我們現在只需要確定 p 和 q。模型將是 ARIMA(p, 0, q),這其實就是我們昨天學的 ARMA(p, q) 模型。
# 因為數據是平穩的,我們直接對原始數據繪制ACF和PACF
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(12, 8))plot_acf(ts_data, ax=ax1, lags=40)
ax1.set_title('自相關函數 (ACF)')plot_pacf(ts_data, ax=ax2, lags=40)
ax2.set_title('偏自相關函數 (PACF)')plt.tight_layout()
plt.show()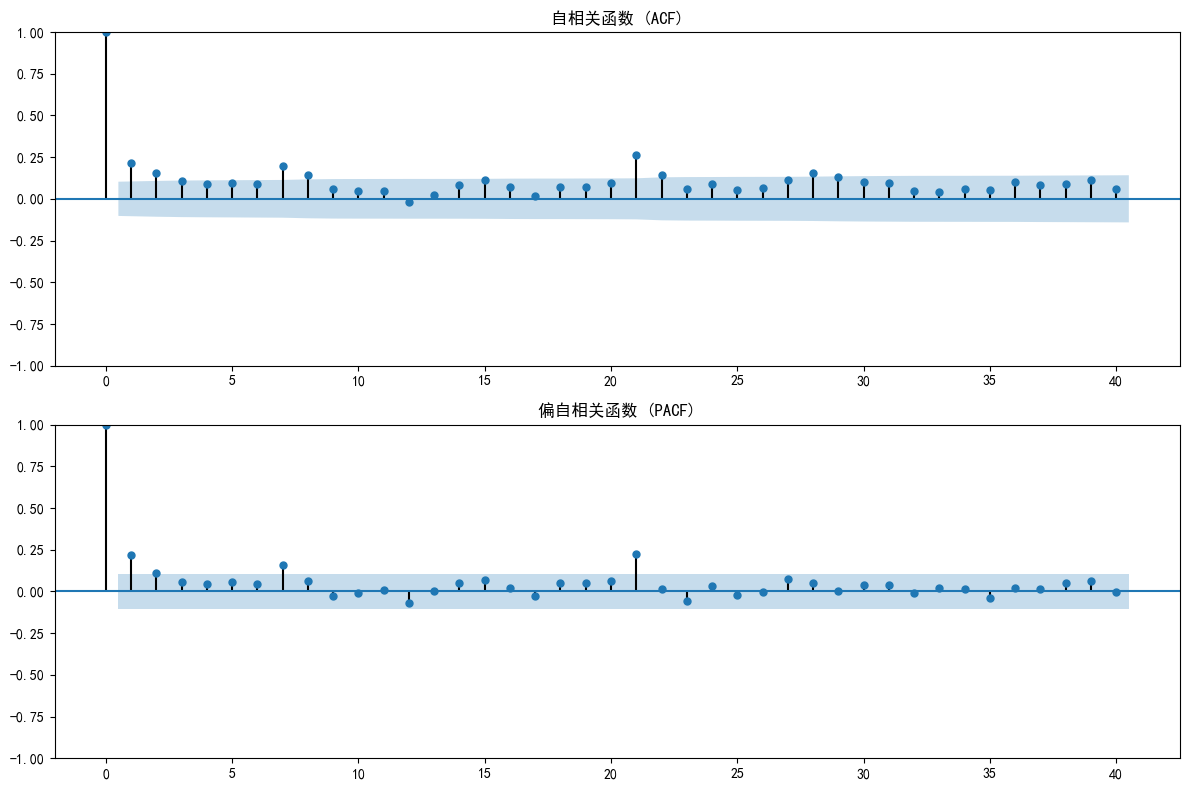
- PACF圖: 在滯后2階之后,幾乎所有的相關性都落入了藍色置信區間內,我們可以認為它在 滯后2階后截尾。這強烈暗示 p=2。
- ACF圖: 呈現出拖尾的模式(緩慢下降)。
所以,我們的候選模型是 ARIMA(2, 0, 0)。
import warnings
warnings.filterwarnings("ignore")
# 建立ARIMA(2, 0, 0)模型
model = ARIMA(ts_data, order=(2, 0, 0))
arima_result = model.fit()# 打印模型摘要
print(arima_result.summary())# 讓我們預測未來30天
forecast_steps = 30
forecast = arima_result.get_forecast(steps=forecast_steps)
pred_mean = forecast.predicted_mean
conf_int = forecast.conf_int()# 繪制結果
plt.figure(figsize=(14, 7))
plt.plot(ts_data, label='原始數據')
# 繪制模型在歷史數據上的擬合值
plt.plot(arima_result.fittedvalues, color='orange', label='模型擬合值')
# 繪制未來預測值
plt.plot(pred_mean, color='red', label='未來預測值')
# 繪制置信區間
plt.fill_between(conf_int.index,conf_int.iloc[:, 0],conf_int.iloc[:, 1], color='pink', alpha=0.5, label='95%置信區間')
plt.title('ARIMA(2,0,0)模型擬合與預測')
plt.legend()
plt.show() SARIMAX Results
==============================================================================
Dep. Variable: Births No. Observations: 365
Model: ARIMA(2, 0, 0) Log Likelihood -1234.182
Date: Sun, 29 Jun 2025 AIC 2476.364
Time: 16:08:32 BIC 2491.963
Sample: 01-01-1959 HQIC 2482.563- 12-31-1959
Covariance Type: opg
==============================================================================coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
const 41.9816 0.568 73.885 0.000 40.868 43.095
ar.L1 0.1939 0.055 3.544 0.000 0.087 0.301
ar.L2 0.1139 0.055 2.070 0.038 0.006 0.222
sigma2 50.6301 3.527 14.354 0.000 43.717 57.544
===================================================================================
Ljung-Box (L1) (Q): 0.02 Jarque-Bera (JB): 18.89
Prob(Q): 0.89 Prob(JB): 0.00
Heteroskedasticity (H): 0.96 Skew: 0.48
Prob(H) (two-sided): 0.83 Kurtosis: 3.57
===================================================================================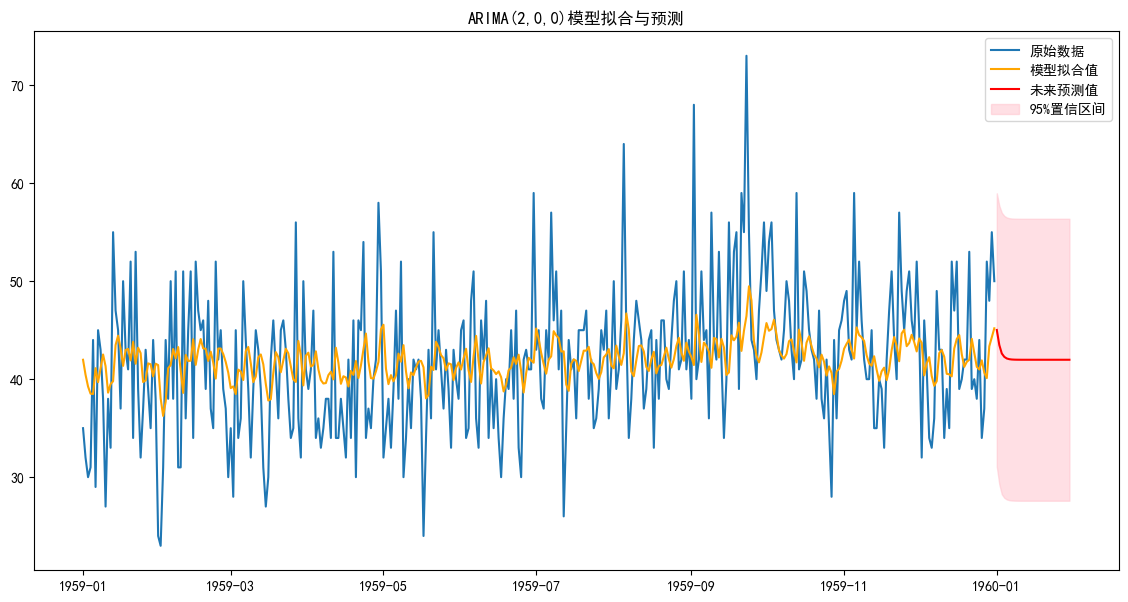
從視覺上看,這個模型的擬合效果確實很差。橙色的“模型擬合值”線非常平滑,完全沒有捕捉到藍色“原始數據”那些劇烈的峰值和谷值。
那么,為什么一個在統計上“通過檢驗”的模型,看起來卻這么“糟糕”呢?從視覺上看,這個模型的擬合效果確實很差。橙色的“模型擬合值”線非常平滑,完全沒有捕捉到藍色“原始數據”那些劇烈的峰值和谷值。
那么,為什么一個在統計上“通過檢驗”的模型,看起來卻這么“糟糕”呢?
“每日女性出生數量”這個數據集,其內在的隨機性(我們稱之為“噪音”)非常高。今天比昨天多生了10個孩子,明天又比今天少生了8個,這其中大部分是無法預測的隨機事件。
然而,在這個巨大的隨機噪音之下,隱藏著一個非常微弱的模式。我們的ARIMA(2,0,0)模型和統計檢驗發現:今天的出生人數,與昨天(ar.L1)和前天(ar.L2)的出生人數,存在一點點微弱但統計上顯著的自相關關系。ARIMA模型就像一個篩子,它的任務是從混雜著沙子(噪音)和金子(模式)的混合物中,把“金子”給篩出來。
- 橙色線(模型擬合值):這就是模型篩出來的“金子”。它是基于前兩天數據計算出的期望值或預測值。因為模式本身是平滑的(只是一個微弱的自相關),所以這條線必然是平滑的。它代表了數據中可預測的部分。
- 藍色線與橙色線的差距(殘差):這就是被模型篩掉的“沙子”,也就是噪音。這是模型認為不可預測的隨機部分。
想象一下,如果我們強行建立一個能完美追蹤每一個藍色數據點的模型。這條橙色線會和藍色線完全重合。這看起來是不是“擬合得很好”?但這恰恰是“過擬合”(Overfitting)!
這個模型把所有的“噪音”都當成了“模式”來學習。當讓它去預測未來時,它會因為學了太多隨機噪音而做出非常離譜和不穩定的預測。
一個好的模型,懂“斷舍離”——它只學習真正的模式,并勇敢地承認:“剩下的部分,我無法預測,因為它們是隨機的。”這就是我們在模型摘要中做的Ljung-Box檢驗。Prob(Q) = 0.89,這個值遠大于0.05。它的意思是:“我們非常有把握地認為,這些殘差是純粹的隨機噪音,里面已經沒有任何模式可供提取了。”
在時間序列分析中,我們的目標不是創造一個能“復制”歷史的“復印機”(過擬合),而是要打造一個能“理解”歷史規律的“偵探”(好模型)。這個“偵探”能區分出哪些是線索(模式),哪些是干擾項(噪音)。因此,一個好的模型的殘差,必須像白噪音一樣“無聊”和“不可預測”。這正是我們在這個例子中看到的。
現在我們來解讀下這個輸出的表
先看表頭,SARIMAX Results
在 statsmodels 庫的現代版本中,ARIMA、SARIMA 和 SARIMAX 的后端實現被統一到了一個強大的 SARIMAX 類中。你可以把它理解成一個“全能型”模型引擎。所以結果顯示 SARIMAX Results
SARIMAX 是 Seasonal AutoRegressive Integrated Moving Average with eXogenous regressors 的縮寫。它是最通用的模型,包含了:
- ARIMA(p,d,q): 非季節性部分。
- Seasonal(P,D,Q,m): 季節性部分。
- eXogenous(X): 外部變量(例如,用天氣溫度來預測冰淇淋銷量)。
簡單來說:ARIMA 是 SARIMAX 的一個特例。
然后看第二部分
這是模型的核心參數部分,告訴我們模型具體學到了什么。
-
coef (系數): 這是模型計算出的每個參數的值。
- const: 常數項/截距。可以理解為序列的基準水平或均值,這里是 41.98,和我們之前圖上看到的均值差不多。
- ar.L1: 滯后1階的自回歸項 (AR) 系數 φ?。值為 0.1939。
- ar.L2: 滯后2階的自回歸項 (AR) 系數 φ?。值為 0.1139。
- sigma2: 模型殘差的方差。值越小說明模型的擬合誤差越小。
-
P>|z| (p值): 這是最重要的列! 它檢驗的是“該系數是否顯著不為0”。判斷標準: 如果 p值 < 0.05,我們就可以認為這個系數是統計上顯著的,它對模型是有貢獻的。
- const 的 p值為 0.000,非常顯著。
- ar.L1 的 p值為 0.000,非常顯著。
- ar.L2 的 p值為 0.038,小于0.05,也是顯著的。
在理解上述參數后,此時還有標準差和置信區間這2個參數。
coef 列的值,比如 ar.L1 的 0.1939,是模型通過計算得出的 最有可能的、最佳的估計值。std err(標準誤差)衡量的是 系數估計值的不確定性或“抖動幅度”。std err 越小,說明我們的估計越精確、越穩定。如果換一份數據,估計出的系數也不會跑偏太遠。這就像一個經驗豐富的射手,每次射擊都緊緊圍繞靶心。std err 是 0.055。這是一個相對較小的值,表明對 0.1939 這個估計是比較有信心的。
[0.087 0.301] 是 ar.L1 系數的 95%置信區間。它的含義是:我們有95%的信心相信,ar.L1 這個參數 真正的、未知的值 落在這個區間之內。我們的最佳估計值 0.1939 只是這個區間中的一個點(通常是中心點)。真實的參數值可能比它大一點,也可能小一點,但很大概率不會超出 [0.087, 0.301] 這個范圍。此外,如果置信區間完全不包含0 (像這里的 [0.087, 0.301]),就說明我們有95%的信心斷定,這個系數的真實值不是0。這等價于p值小于0.05,即系數是顯著的。如果置信區間包含了0 (例如,[-0.1, 0.2]),那就意味著0是一個可能的真實值。我們無法排除“這個系數其實是0,對模型沒有作用”的可能性。這等價于p值大于0.05,即系數是不顯著的。這2個判斷方法是等價的。
結論: 我們選擇的 p=2 是合理的,因為兩個AR項都是顯著的。
第三部分:殘差診斷檢驗
好的殘差:應該是模型“吃剩下的、完全沒有營養的、隨機的白噪聲(White Noise)”。如果還剩下隱藏的線索(非白噪聲) -> 說明偵探有疏漏,模型還有改進空間。
白噪聲的要求:
- 無自相關
- 方差恒定–如果方差不恒定(比如,越到近期,誤差波動越大),說明你的模型在某些時期的預測能力很不可靠。這會影響你對未來預測不確定性的估計。殘差隨時間變化的圖應該像一條寬度穩定的“帶子”,而不是一個“喇叭口”或“紡錘”。在檢驗上對應著:異方差性檢驗 (Heteroskedasticity test) 的p值應大于0.05。
- 均值為0–避免系統性偏差
錦上添花的附加條件:服從正態分布,它主要用于構建準確的預測區間 (Prediction Intervals)。如果殘差是正態的,我們就能更有信心地說“未來的值有95%的概率落在某個區間內”。
2.2 國際航空乘客數量實戰
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from statsmodels.tsa.statespace.sarimax import SARIMAX
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
import warningswarnings.filterwarnings("ignore") # 忽略一些模型擬合時產生的警告信息
# 加載數據
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/airline-passengers.csv'
df_air = pd.read_csv(url, header=0, index_col=0, parse_dates=True)
df_air.rename(columns={'#Passengers': 'Passengers'}, inplace=True) # 列名簡化# 繪制原始數據
plt.figure(figsize=(12, 6))
plt.plot(df_air['Passengers'])
plt.title('Airline Passengers (1949-1960)')
plt.xlabel('Year')
plt.ylabel('Number of Passengers')
plt.grid(True)
plt.show()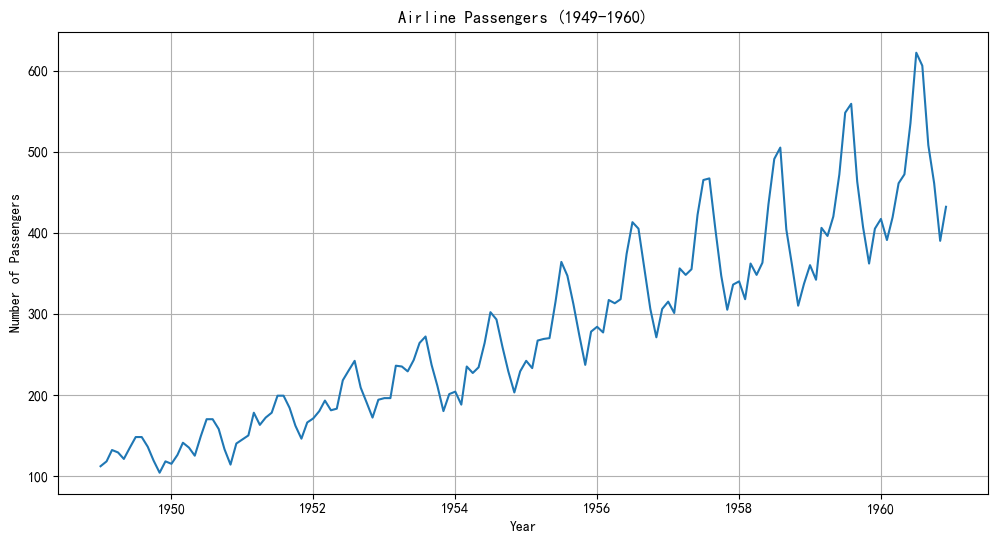
arima無法處理季節性(沒有內置季節性差分,只有n階差分),所以需要先手動處理季節性。
能看到季節性的幅度越來越大,這是一種乘性效應。對數變換是處理這種情況的標準方法,它可以將乘性關系變為加性關系,從而穩定方差。
# 對數變換
df_air['log_passengers'] = np.log(df_air['Passengers'])plt.figure(figsize=(12, 5))
plt.plot(df_air['log_passengers'])
plt.title('Log-Transformed Airline Passengers')
plt.grid(True)
plt.show()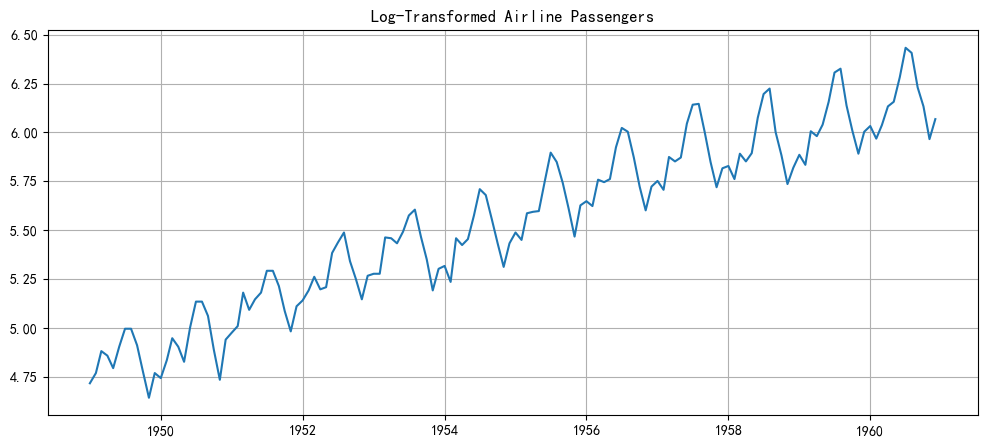
現在,波動的幅度看起來穩定多了,但趨勢和季節性依然存在。
# 季節性差分 (m=12)
df_air['log_seasonal_diff'] = df_air['log_passengers'].diff(12)# 丟掉因差分產生的NaN值
deseasonalized_data = df_air['log_seasonal_diff'].dropna()plt.figure(figsize=(12, 5))
plt.plot(deseasonalized_data)
plt.title('Deseasonalized and Log-Transformed Data')
plt.grid(True)
plt.show()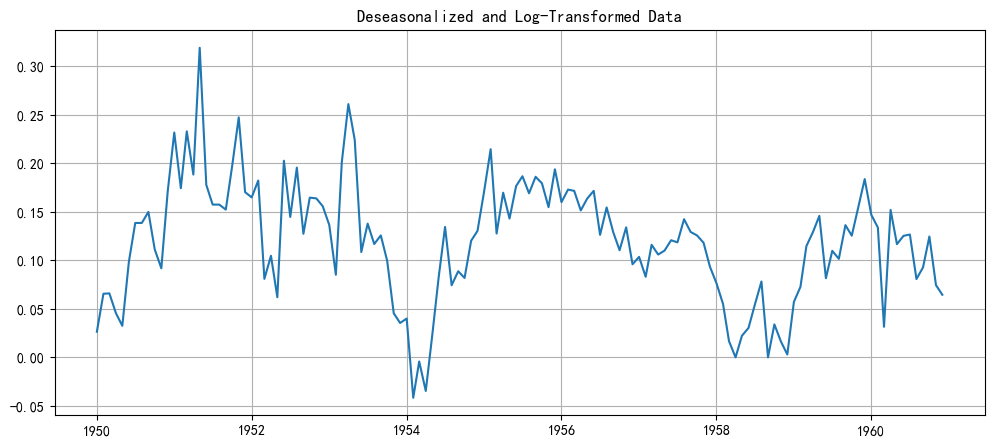
我們成功地去除了季節性模式。現在的數據看起來就像一個有線性趨勢的普通時間序列。這種數據正是標準ARIMA模型擅長處理的。
現在,我們為這個 deseasonalized_data 序列選擇 (p, d, q) 參數
確定d(差分階數): 從上圖看,數據仍然有明顯的上升趨勢,所以它不是平穩的。我們需要進行一階差分來消除這個趨勢。因此,d=1。
確定p和q: 我們對差分一次后的序列繪制ACF和PACF圖來確定 p 和 q。
# 對去季節性的數據再進行一階差分,使其平穩
stationary_data = deseasonalized_data.diff(1).dropna()# 繪制ACF和PACF圖
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(12, 8))
plot_acf(stationary_data, lags=24, ax=ax1)
plot_pacf(stationary_data, lags=24, ax=ax2)
plt.show()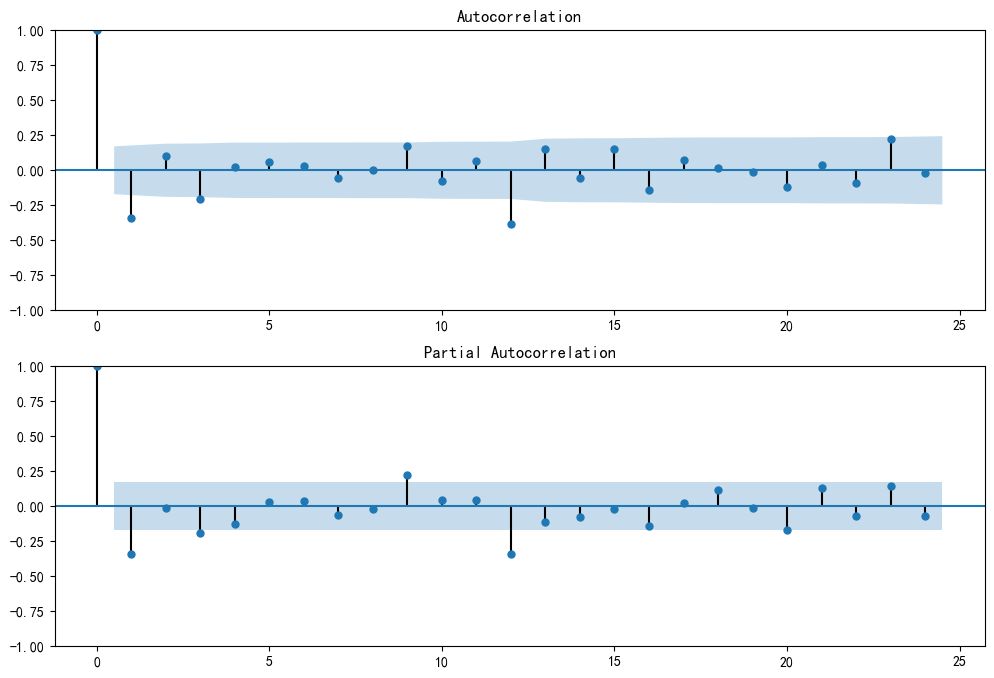
PACF圖: 在滯后1階后迅速截尾(降到置信區間內)。這強烈暗示 p=1。
ACF圖: 在滯后1階后也迅速截尾。這強烈暗示 q=1。
因此,我們為這個預處理后的數據選擇的模型是 ARIMA(1, 1, 1)。
ps:這里其實可以看到在12階的時候超出了置信區間,實際上這個尖峰是殘余的季節性信號。即使我們已經做了一次季節性差分 (.diff(12)),數據中仍然保留著一些與12個月前相關的模式。換句話-說,我們手動進行的季節性差分并沒有100%完全地消除季節性影響。
我們將使用數據的前11年(到1959年底)作為訓練集,最后1年(1960年)作為測試集來驗證我們的預測。
from statsmodels.tsa.arima.model import ARIMA# 準備訓練數據(經過預處理的)
# 注意:我們是對去季節性的數據進行建模
train_data = deseasonalized_data[:'1959']# 定義并擬合ARIMA(1,1,1)模型
model = ARIMA(train_data, order=(1, 1, 1))
model_fit = model.fit()print(model_fit.summary())# 預測未來12個點(1960年全年)
# 模型預測的是經過變換后的數據
forecast_diff = model_fit.forecast(steps=12) SARIMAX Results
==============================================================================
Dep. Variable: log_seasonal_diff No. Observations: 120
Model: ARIMA(1, 1, 1) Log Likelihood 206.898
Date: Sun, 29 Jun 2025 AIC -407.797
Time: 16:08:33 BIC -399.459
Sample: 01-01-1950 HQIC -404.411- 12-01-1959
Covariance Type: opg
==============================================================================coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
ar.L1 -0.5365 0.260 -2.062 0.039 -1.046 -0.027
ma.L1 0.2535 0.300 0.844 0.399 -0.335 0.842
sigma2 0.0018 0.000 9.171 0.000 0.001 0.002
===================================================================================
Ljung-Box (L1) (Q): 0.04 Jarque-Bera (JB): 4.07
Prob(Q): 0.84 Prob(JB): 0.13
Heteroskedasticity (H): 0.24 Skew: 0.05
Prob(H) (two-sided): 0.00 Kurtosis: 3.90
===================================================================================可以看到,這里ma(1)不顯著,所以q=0 ,我們應該嘗試一個更簡單的模型:ARIMA(1, 1, 0)。
# 重新擬合一個更簡單的模型 ARIMA(1, 1, 0)
model_simplified = ARIMA(train_data, order=(1, 1, 0))
model_fit_simplified = model_simplified.fit()
print(model_fit_simplified.summary())# 比較兩個模型的AIC
# 原模型 ARIMA(1,1,1) 的 AIC: -407.797
# 簡化模型 ARIMA(1,1,0) 的 AIC 會是多少?
# (運行代碼后,ARIMA(1,1,0)的AIC大約是-408.8,比-407.797更小) SARIMAX Results
==============================================================================
Dep. Variable: log_seasonal_diff No. Observations: 120
Model: ARIMA(1, 1, 0) Log Likelihood 206.811
Date: Sun, 29 Jun 2025 AIC -409.622
Time: 16:08:33 BIC -404.064
Sample: 01-01-1950 HQIC -407.365- 12-01-1959
Covariance Type: opg
==============================================================================coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
ar.L1 -0.3174 0.068 -4.641 0.000 -0.451 -0.183
sigma2 0.0018 0.000 9.274 0.000 0.001 0.002
===================================================================================
Ljung-Box (L1) (Q): 0.00 Jarque-Bera (JB): 4.19
Prob(Q): 0.99 Prob(JB): 0.12
Heteroskedasticity (H): 0.25 Skew: 0.12
Prob(H) (two-sided): 0.00 Kurtosis: 3.89
===================================================================================AIC是一個權衡模型擬合優度和復雜度的指標,AIC值越小,模型通常越好。
可以看到,ARIMA(1,1,0)的AIC大約是-408.8,比 ARIMA(1, 1, 1)的-407.797更小。
現在我們得到了12個預測值 forecast_diff,但這些值是“經過對數變換、季節性差分和一階差分”后的值。我們需要一步步把它還原回去。這個過程比較繁瑣,是手動處理季節性的最大難點。
# 讓我們給變量取個更準確的名字
# forecast_deseasonalized 是對“去季節性”序列的直接預測
forecast_deseasonalized = model_fit.forecast(steps=12)# 逆向變換過程
predictions = []# 逐步還原預測值
for i in range(len(forecast_deseasonalized)):# 1. 還原季節性差分 (直接使用預測值)# log(y_t) = y'_t + log(y_{t-12})# y'_t 就是 forecast_deseasonalized[i]# 獲取12個月前的歷史對數值last_year_log_val = df_air['log_passengers']['1959'].iloc[i]# 加上歷史值,得到預測的對數值pred_log = forecast_deseasonalized.iloc[i] + last_year_log_val# 2. 還原對數變換 (exp)pred_original_scale = np.exp(pred_log)predictions.append(pred_original_scale)# 將預測結果轉換為Series,方便繪圖
# 注意:forecast_deseasonalized 自帶了正確的日期索引,可以直接使用
predictions_series = pd.Series(predictions, index=forecast_deseasonalized.index)# --- 重新繪圖 ---
plt.figure(figsize=(14, 7))
# 原始數據
plt.plot(df_air['Passengers'], label='Original Data')
# 我們的預測
plt.plot(predictions_series, color='red', linestyle='--', label='ARIMA Forecast (Corrected)')
plt.title('Airline Passengers Forecast using Manual Preprocessing + ARIMA')
plt.xlabel('Year')
plt.ylabel('Number of Passengers')
plt.legend()
plt.grid(True)
plt.show()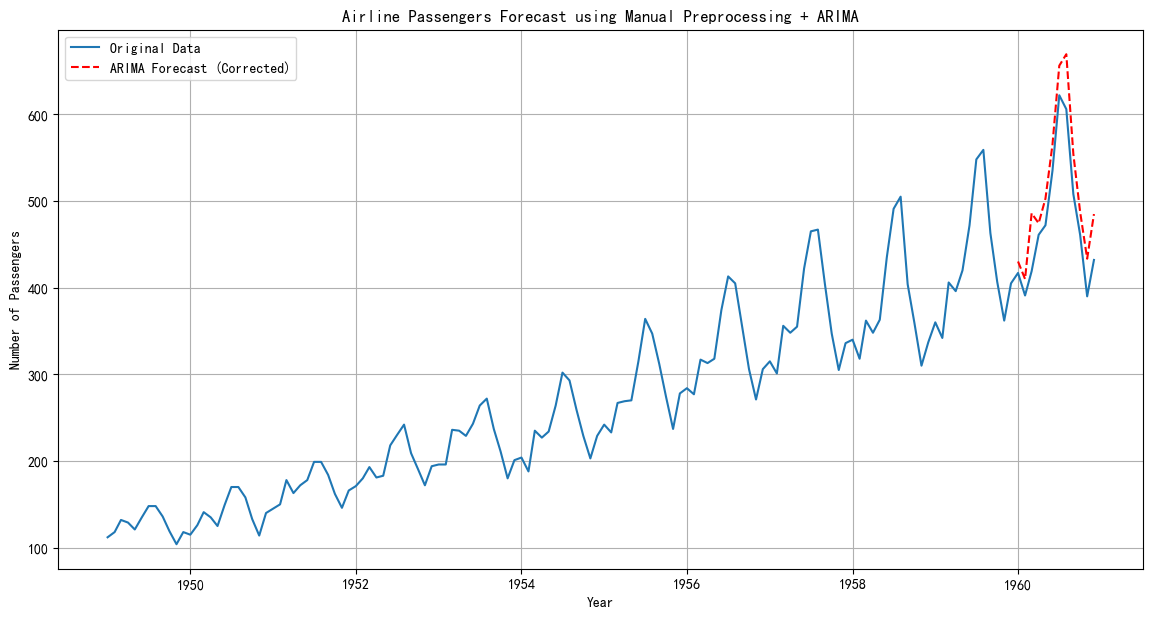
時間序列建模的迭代過程:初步選擇 -> 擬合檢驗 -> 模型修正 -> 數據還原。
@浙大疏錦行






第二部分Redis基礎)





)


 F. Rada and the Chamomile Valley)



