五、TCP 進階機制
(一)TCP 頭部標志位
TCP 頭部的標志位是控制通信行為的 “開關”,常用標志位功能:
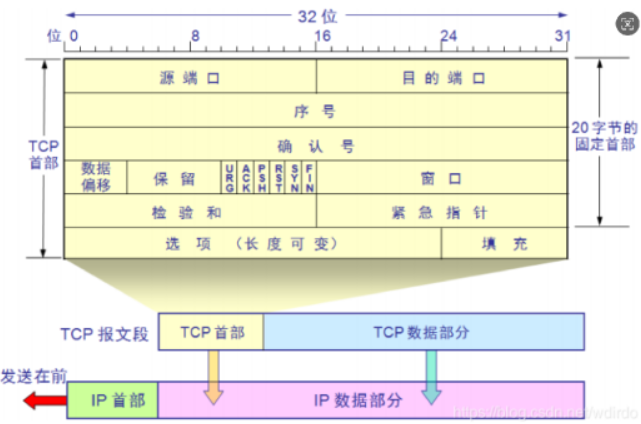
| 標志位 | 含義 | 典型場景 |
|---|---|---|
| SYN | 請求建立連接 | 三次握手第一步,發起連接請求 |
| ACK | 響應報文確認 | 回復對方,確認已收到數據 |
| PSH | 攜帶數據通知 | 告訴接收方 “立即從緩沖區取數據”,避免延遲 |
| FIN | 請求斷開連接 | 四次揮手第一步,發起斷開請求 |
| RST | 復位連接 | 強制重置異常連接(如網絡擁塞時) |
| URG | 緊急數據標識 | 標記 “緊急數據”,需優先處理 |
(二)TCP 安全可靠傳輸機制
1. 三次握手 & 四次揮手
- 三次握手:通過?
SYN/SYN+ACK/ACK?三次交互,確認雙方收發能力,為可靠通信奠基。 - 四次揮手:因服務端可能殘留未發數據,需拆分?
FIN/ACK/FIN/ACK?四步,保證數據發完再斷開。
2. 應答機制
TCP 采用 **“序列號 + 確認號”** 實現可靠應答:
- 發送方用 ** 序列號(Sequence Number)** 標記數據段的 “起始編號”;
- 接收方回復確認號(Acknowledgment Number),值為 “收到的最后一個字節編號 + 1”,告訴發送方 “已收到到這里,下一個該發啥”。
示例:發送方發?[0-999]?數據,序列號為?0;接收方回復確認號?1000,表示 “0-999 已收到,繼續發 1000 開頭的數據”。
3. 超時重傳機制
發送方數據發出后,若超時未收到確認號,則認為數據丟失,觸發重傳。類似 “快遞沒收到,重新發貨”,保障數據不丟包。
4. 滑動窗口機制
TCP 用滑動窗口管理發送與確認:
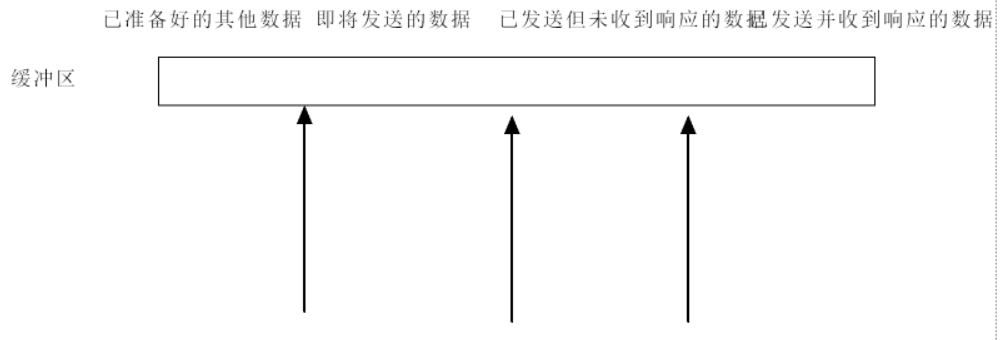
- 窗口內是 “已發送但未確認 + 待發送” 的數據;
- 收到確認號后,窗口 “滑動”,釋放已確認數據的緩沖區,繼續發送新數據。
( 理解:已發送并確認、已發送未確認、即將發送、準備好的數據,隨窗口滑動動態變化 )
(三)TCP 效率優化機制
1. 延遲應答機制
發送數據的同時,接收方不立即回復?ACK,而是等待一段時間(攢一批數據再回復),減少 ACK 報文數量,降低網絡開銷。
2. 流量控制機制
通過 TCP 頭部 **“窗口大小(Window Size)”(滑動窗口)** 字段實現:
- 接收方根據自身緩沖區剩余空間,動態調整 “窗口大小”;
- 發送方依據窗口大小控制發送速率,避免接收方緩沖區溢出。
3. 捎帶應答機制
ACK?報文有時候不單獨發送,而是 “附著” 在應用層數據里一起發(類似于變為三次揮手),減少單獨發 ACK 的次數,提升效率。
六、HTTP 協議
(一)萬維網通信基礎
- WWW(萬維網):由網頁、服務器、客戶端(瀏覽器)組成的信息系統,通過 URL 定位資源。
- URL(統一資源定位符):格式?
<協議>://<主機>:<端口>/<路徑>?,示例:https://www.baidu.com/s?wd=關鍵詞?,精準定位網絡資源。 - HTTP(超文本傳輸協議):應用層協議,基于 TCP 傳輸,默認端口?
80/8080,負責客戶端與服務器的請求 - 響應交互。 - HTML(超文本標記語言):瀏覽器解析后展示網頁內容的語言,HTTP 響應報文里的 “實體主體” 常包含 HTML 代碼。
(二)HTTP 通信流程
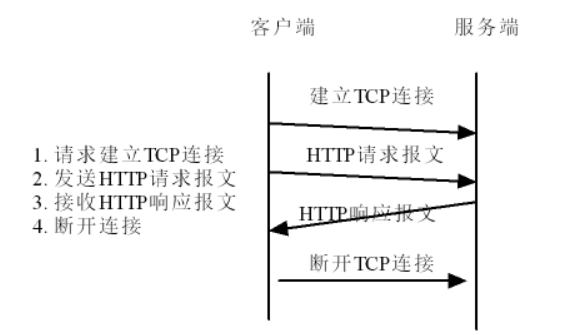
- 建立 TCP 連接:客戶端與服務器通過 TCP 三次握手建立連接(如訪問百度時,先建 TCP 連接 )。
- 發送 HTTP 請求報文:客戶端向服務器發請求,包含 “請求方法(如 GET/POST)、URL、協議版本” 等(示例:
GET / HTTP/1.1?表示用 GET 方法請求根路徑資源 )。 - 接收 HTTP 響應報文:服務器處理請求后,回復包含 “狀態碼、響應頭、實體主體(如 HTML 內容)” 的報文(示例:
HTTP/1.1 200 OK?表示請求成功 )。 - 斷開 TCP 連接:默認短連接(
Connection: close?)直接斷開;長連接(Connection: keep-alive?)會保持連接一段時間,復用傳輸其他資源。
(三)HTTP 報文格式
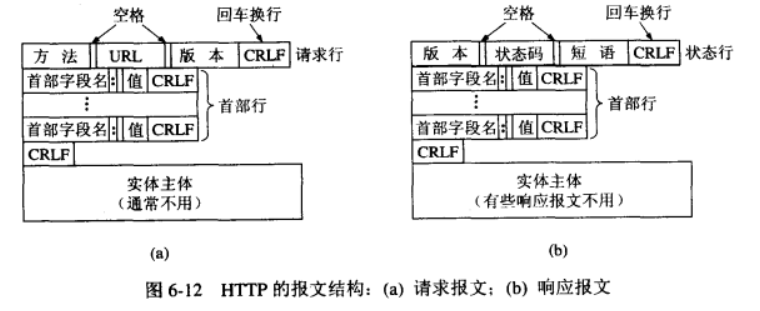
1. 請求報文結構(以 GET 為例)
請求行:方法 URL 版本 CRLF (如:GET /index.html HTTP/1.1\r\n)
首部行:字段名: 值 CRLF (如:Host: www.baidu.com\r\n)
...(更多首部行)
空行:CRLF
實體主體:(GET 通常無實體主體,POST 可帶數據)
2. 響應報文結構
狀態行:版本 狀態碼 短語 CRLF (如:HTTP/1.1 200 OK\r\n)
首部行:字段名: 值 CRLF (如:Content-Type: text/html\r\n)
...(更多首部行)
空行:CRLF
實體主體:(如 HTML 代碼、文件內容等)
3. 狀態碼分類
| 狀態碼分類 | 含義 | 典型碼值 | 場景 |
|---|---|---|---|
| 1xx | 通知信息 | 100 | 表示 “繼續”,常為中間響應 |
| 2xx | 成功 | 200 | 請求成功,服務器正常返回數據 |
| 3xx | 重定向 | 302 | 請求的資源 “搬家了”,需重新定向 |
| 4xx | 客戶端錯誤 | 404 | 資源不存在;400 表示請求語法錯 |
| 5xx | 服務器錯誤 | 500 | 服務器內部故障;502 表示網關錯誤 |
(四)HTTP 請求方法
HTTP 定義了多種請求方法,控制對資源的操作:
| 方法 | 含義 | 典型場景 |
|---|---|---|
| OPTION | 查詢選項 | 探知服務器支持的方法 |
| GET(常見) | 請求資源 | 瀏覽網頁、獲取圖片等(參數放 URL 里) |
| HEAD | 請求資源頭部 | 只獲取響應頭,不下載實體主體 |
| POST(常見) | 提交數據 | 登錄、上傳文件(參數放請求體) |
| PUT | 上傳文檔 | 在指定 URL 存儲文檔(需權限) |
| DELETE | 刪除資源 | 刪除指定 URL 對應的資源(需權限) |
| TRACE | 環回測試 | 調試用,查看請求的傳輸路徑 |
| CONNECT | 代理連接 | 用于代理服務器,建立隧道 |
(五)爬蟲
爬蟲(Web Crawler)?是一種自動化程序,模擬瀏覽器的 HTTP 請求 - 響應流程,批量抓取網絡資源:
工作邏輯:
- 構造 HTTP 請求(模仿瀏覽器發 GET/POST),獲取網頁 HTML;
- 解析 HTML 提取鏈接、數據;
- 遞歸抓取新鏈接,形成 “自動瀏覽 - 采集” 的流程。
總結
- TCP 核心:通過 “三次握手建連接、四次揮手斷連接、序列號 + 確認號應答、滑動窗口控速率”,實現可靠且高效的傳輸。
- HTTP 核心:基于 TCP 傳輸,用請求 - 響應模式交互,通過 URL 定位資源,用狀態碼反饋結果,是萬維網的 “通信語言”。
- 爬蟲本質:自動化的 HTTP 請求 - 解析工具。
![[element-plus] el-table在行單擊時獲取行的index](http://pic.xiahunao.cn/[element-plus] el-table在行單擊時獲取行的index)

——查詢構建、Text2SQL、查詢重構與分發)
)






:plt.imshow() - 繪制矩陣與圖像的強大工具)

)

)

-定長內存池)

)
