目錄
一、進程和文件的關系
二、背景補充
三、打開文件接口
(1) FILE *fopen(const char* filename , const char *mode)
(2)open 系統調用
文件描述符
open和fopen的關系
(3)size_t fwrite(const void * ptr, size_t size, size_t nmemb,FILE*stream)
(4)size_t fread(void *buffer, size_t size,size_t nmemb,FILE? *stream)
四、輸入輸出流
(1)重定向?
追加重定向的原理
重定向接口
五、struct file
六、文件繼承
七、理解一切皆文件(硬件方向)
八、文件緩沖區
1、緩沖區的理解
2、緩沖區的刷新策略
3、FILE緩沖區
(1)引入
(2)本質
(3)FILE刷新方式(緩沖區到內核緩沖區)
(4)一個現象
九、內核文件區
(1)內核文件緩沖區的刷新方式
(2)接口
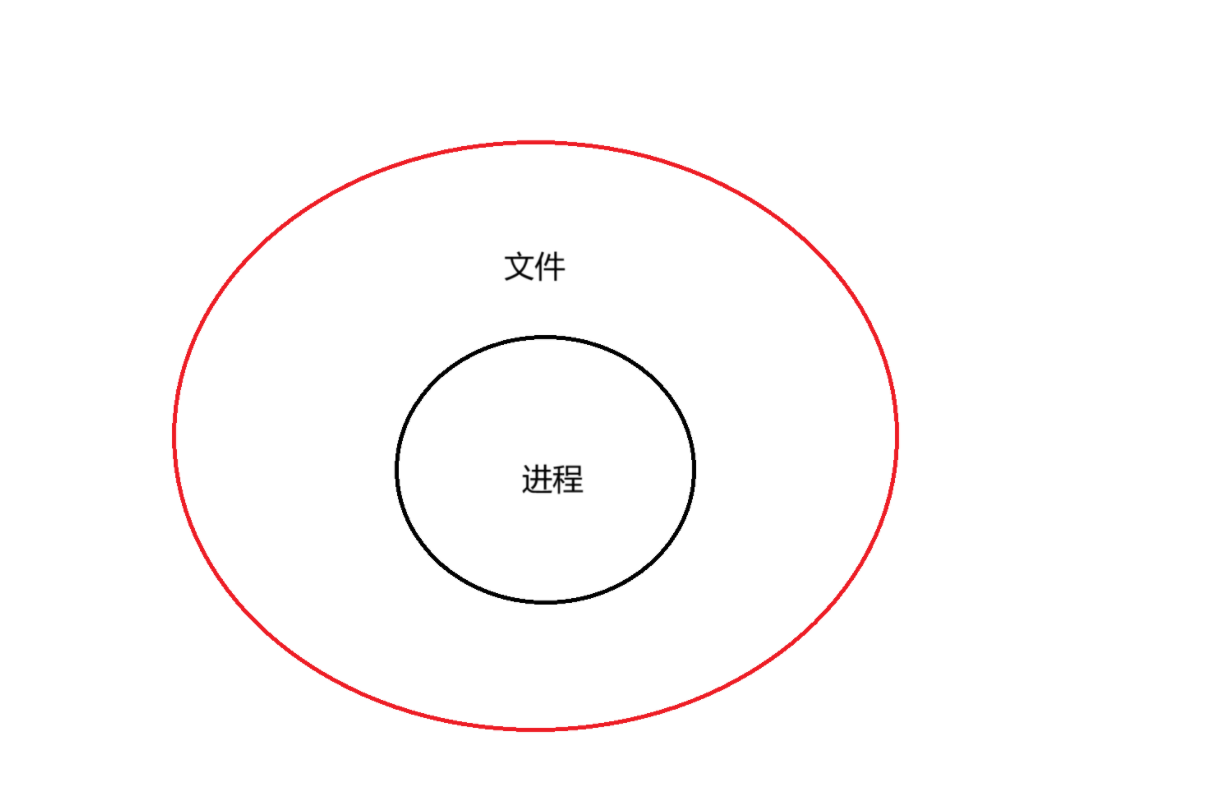
一、進程和文件的關系
二、背景補充
- 文件 = 內容 + 屬性? 所以對文件操作本質 就分為 對內容做操作 或者對屬性做操作
- 訪問一個文件,都必須先把對應的文件打開 因為根據馮諾依曼我們對文件進行操作的時候必須要要保證文件在內存中,而打開一個一個文件就是把這個文件加載到內存(本質就是把文件的屬性和內容加載到內存中)
- 如果一個文件沒有被打開,他就在磁盤中,此磁盤的管理者是操作系統
- ?進程(用戶通過bash,啟動進程(進程通過操作系統))打開文件對文件操作本質是進程對文件的操作
- OS內,一定同時存在大量的被打開的文件(通過數據結構管理被打開的文件)
三、打開文件接口
(1) FILE *fopen(const char* filename , const char *mode)
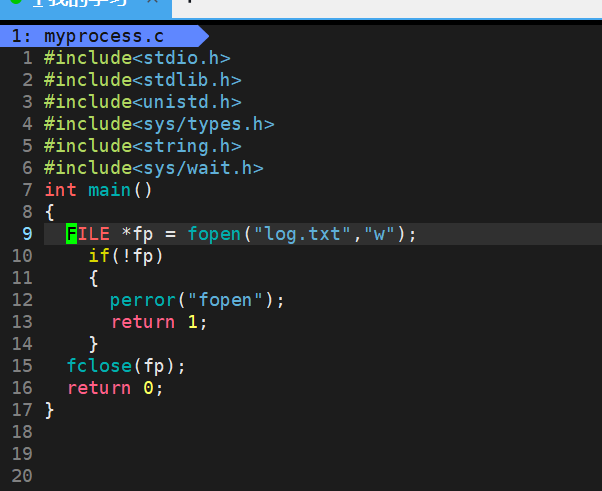

- 我們可以發現以w方式打開文件,如果文件不存在,會在當前工作路徑下創建一個文件,為什會在當前路徑下本質是因為每一個進程在運行起來都一個cwd,默認會在cwd的后面在加上當前文件名進行創建
- 打開文件,必須要先找到文件,要找到文件就必須要知道文件的路徑+文件名,這也是為什么進程要有cwd的原因之一
方式
- w :文件不存在創建,文件存在清空
- w+: 文件不存在就創建,讀寫打開文件
- r :? ?讀文件
- r+: 讀寫打開文件
- a :? ? 不清空文件,從當前文件的結尾處追加
- a+ : 讀和追加
- 讀寫文件有讀寫位置:在我看來文件就是一個"一維數組"所以讀寫位置就是數組下標
- > : 重定向就是以w的方式打開文件
- >>:追加重定向就是以a+的方式打開文件
(2)open 系統調用
int open(const char * pathname , int flags ,mode_t mode)
? ?pathname:
- 若pathname以路徑的方式給出,則當需要創建該文件時,就在pathname路徑下進行創建。
- 若pathname以文件名的方式給出,則當需要創建該文件時,默認在當前路徑下進行創建。(注意當前路徑的含義)
flags:??
打開方式(標志位): 首先它的類型為int 有32個比特位,一個比特位就有一個標志位(本質是宏)在open函數內部就可以通過使用與運算來判斷是否設置了某一選項
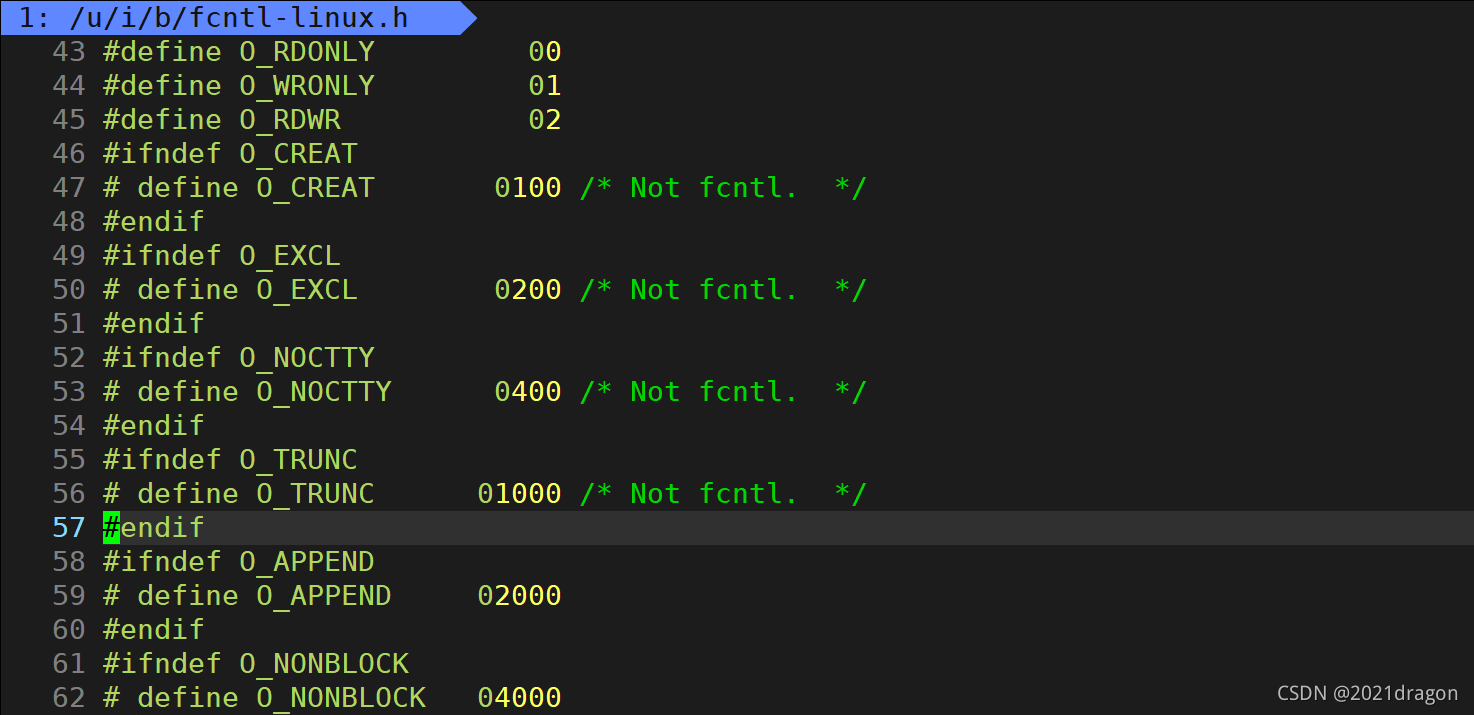
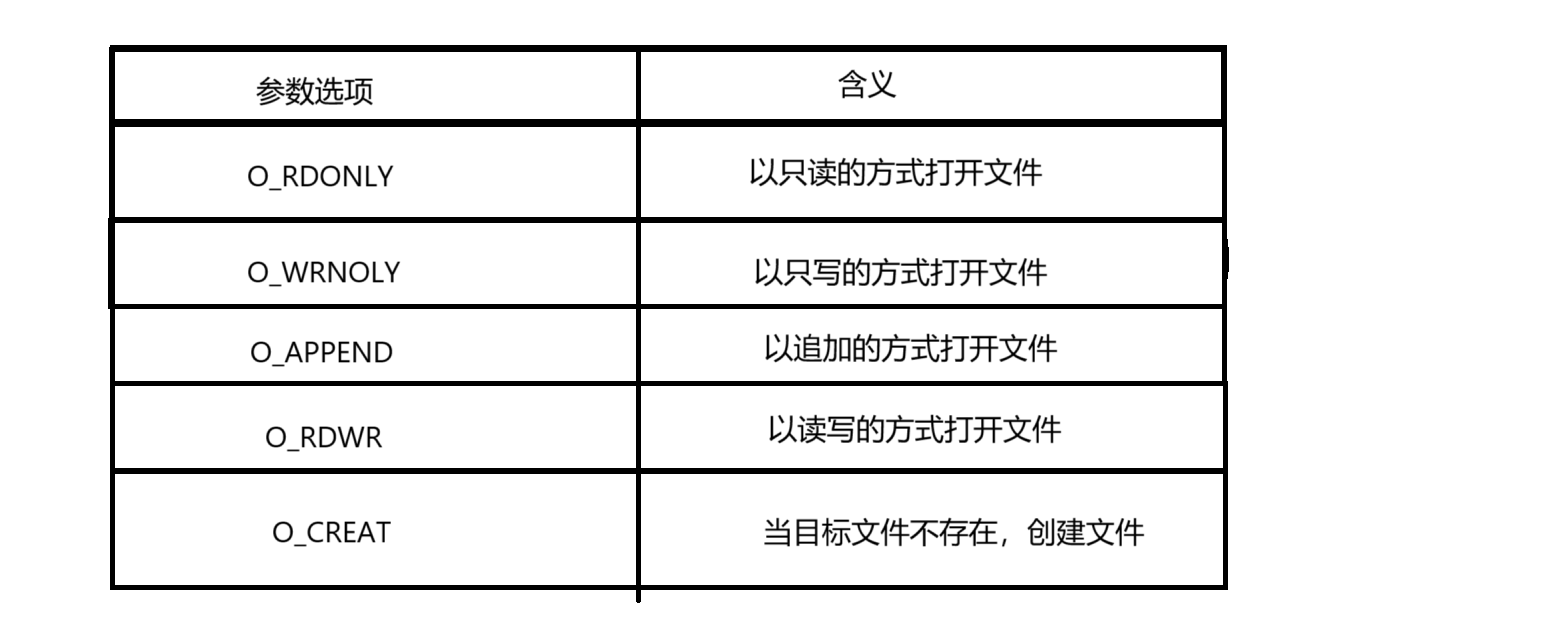
例:

mode:??權限
放回值: 失敗-1 ,成功文件描述符
文件描述符
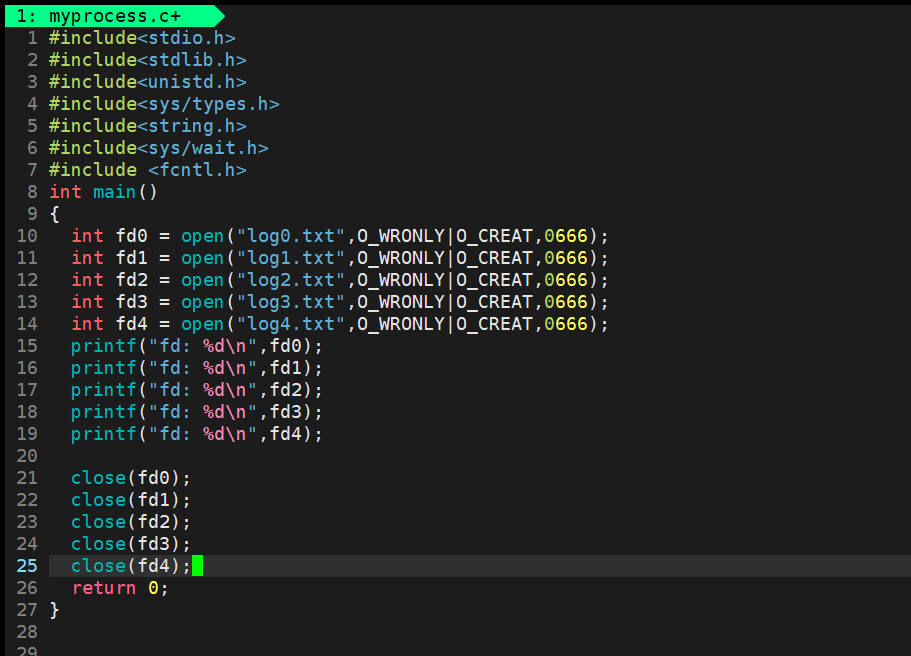
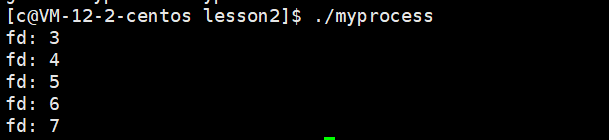
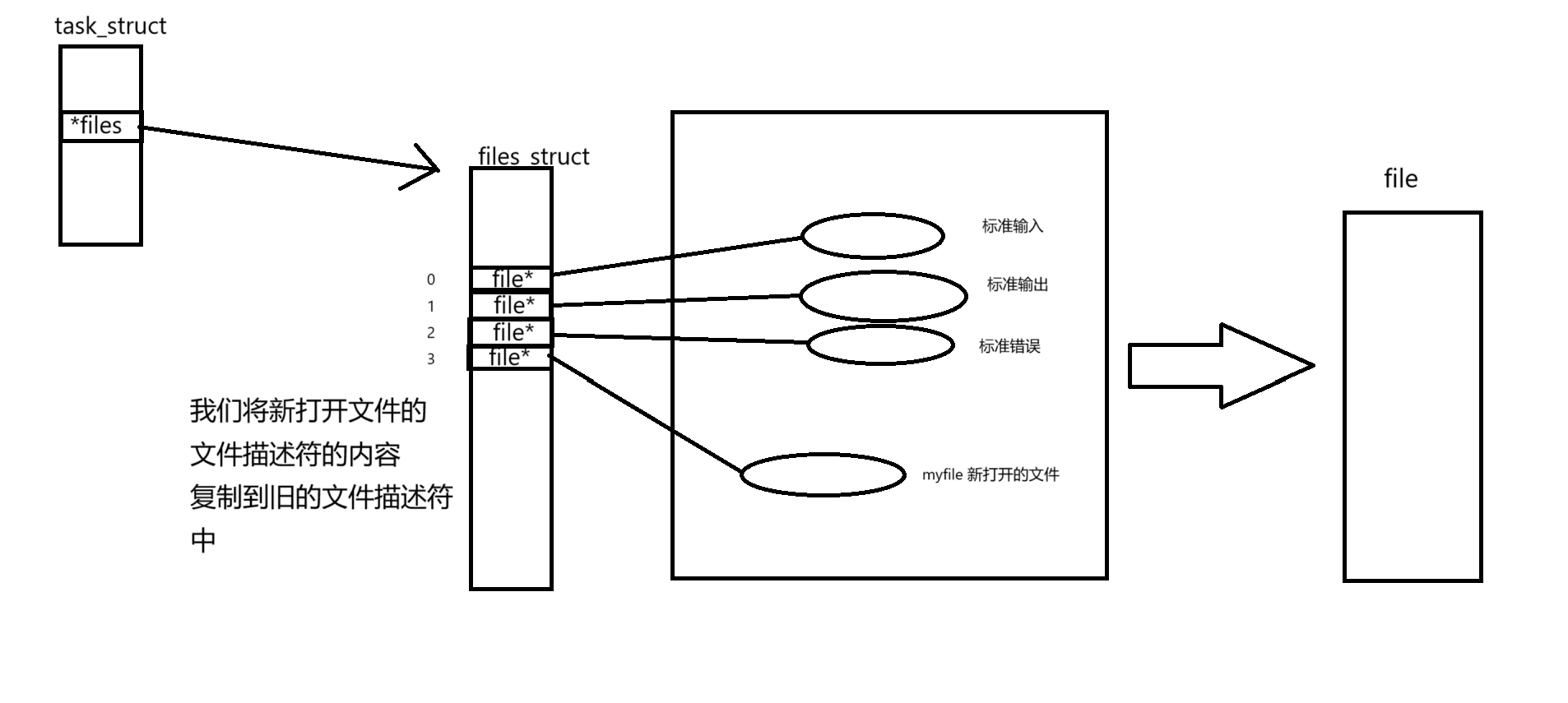
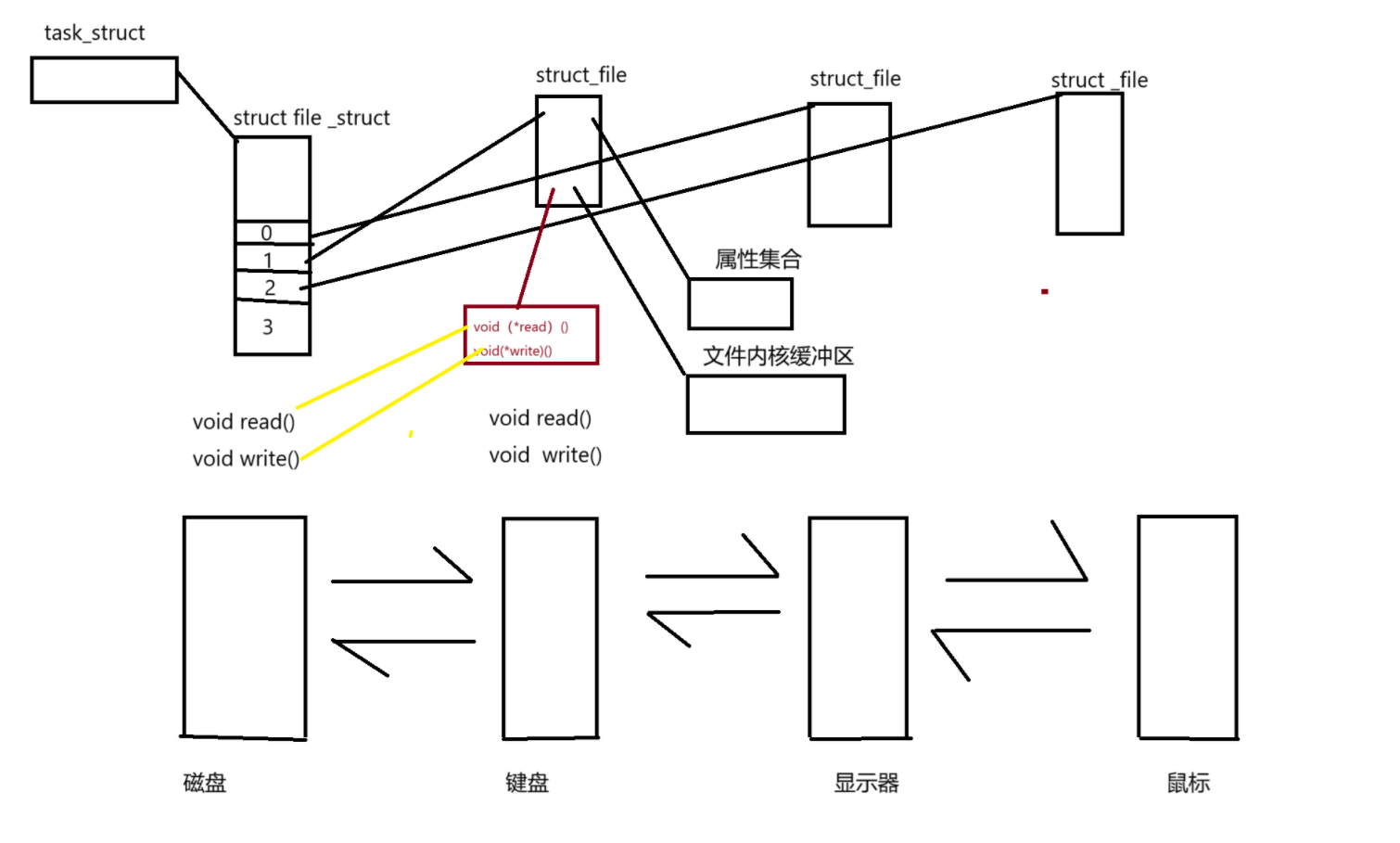
- 因為進程和文件的比例關系為 1 : n 且 OS內,一定存在大量被打開的文件,操作系統對這些文件進行管理(struct file),這些對這些文件進行管理變成對struct file鏈表的增刪查改,但是這么多文件,是被多個進程打開的,系統需要表示那個文件是由那個進程打開的由此產生了文件描述符
- 我們知道,當一個程序運行起來時,操作系統會將該程序的代碼和數據加載到內存,然后為其創建對應的task_struct、mm_struct、頁表等相關的數據結構,并通過頁表建立虛擬內存和物理內存之間的映射關系。
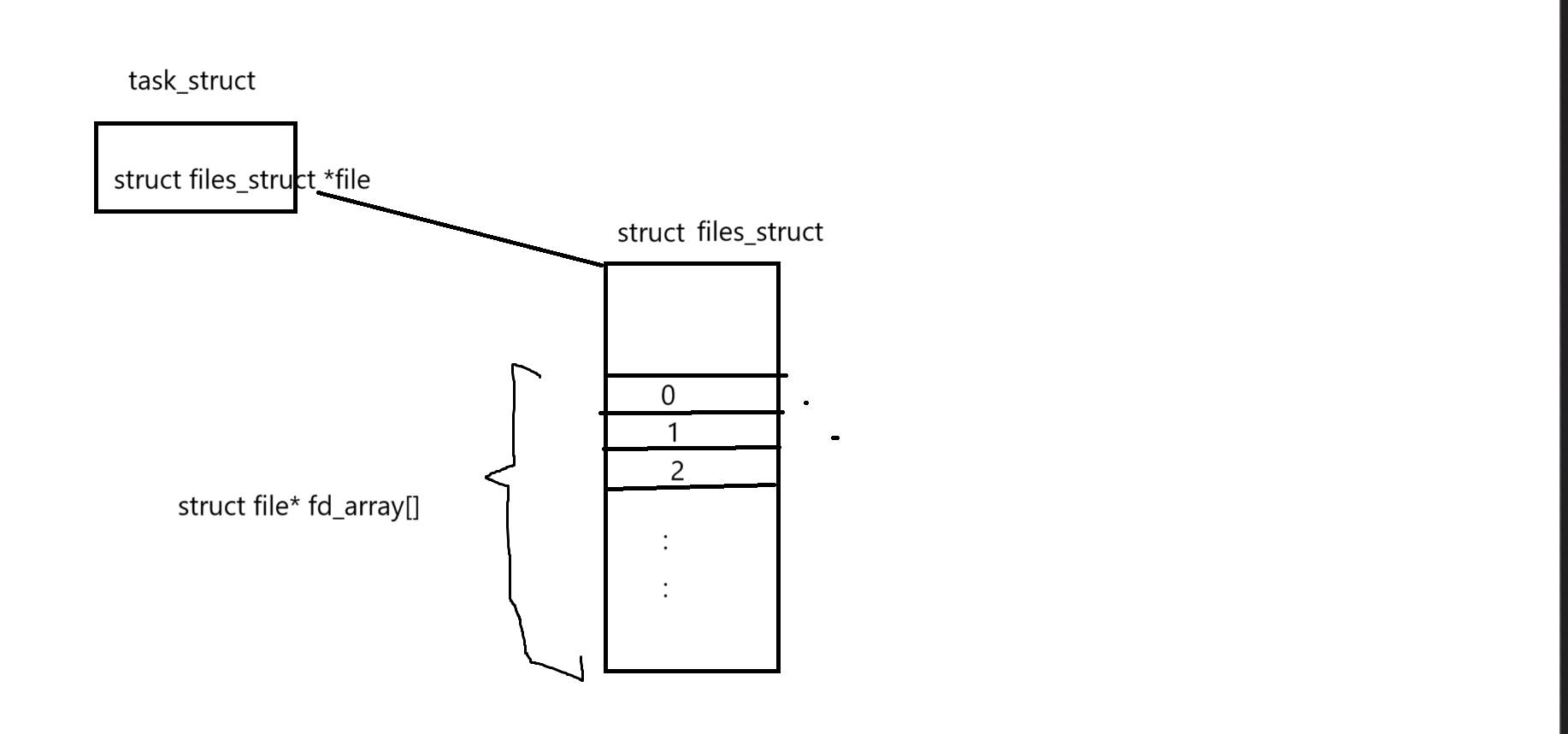
- 而task_struct當中有一個指針,該指針指向一個名為files_struct的結構體,在該結構體當中就有一個名為fd_array的指針數組,該數組的下標就是我們所謂的文件描述符。
- 當進程打開文件時,我們需要先將該文件從磁盤當中加載到內存,形成對應的struct file,將該struct file連入文件雙鏈表,并將該結構體的首地址填入到fd_array數組當中下標為3的位置,使得fd_array數組中下標為3的指針指向該struct file,最后返回該文件的文件描述符給調用進程即可。
?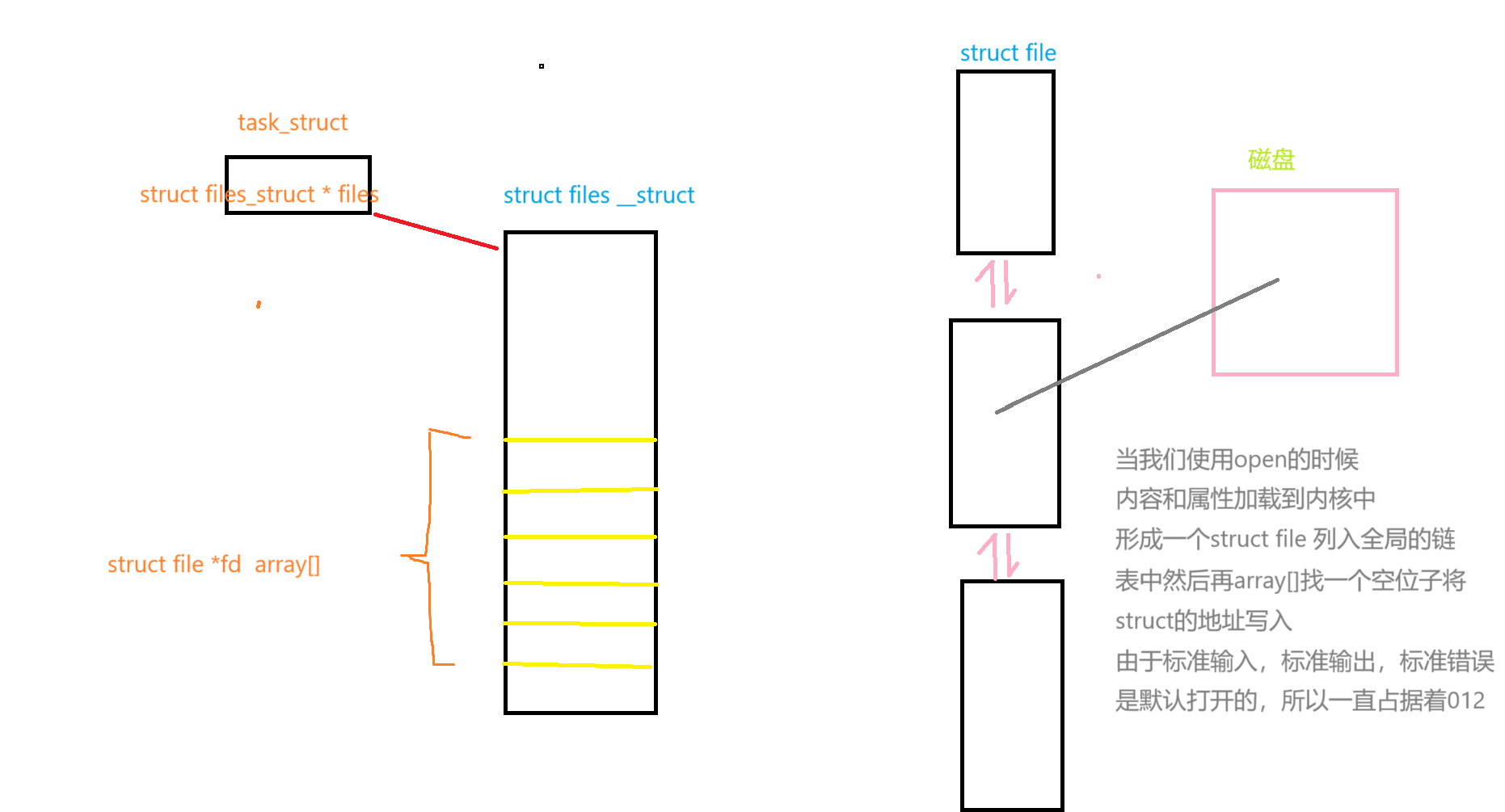
- 文件描述符本質是數組下標,在OS內部,OS識別被打開的文件,OS只認fd
open和fopen的關系
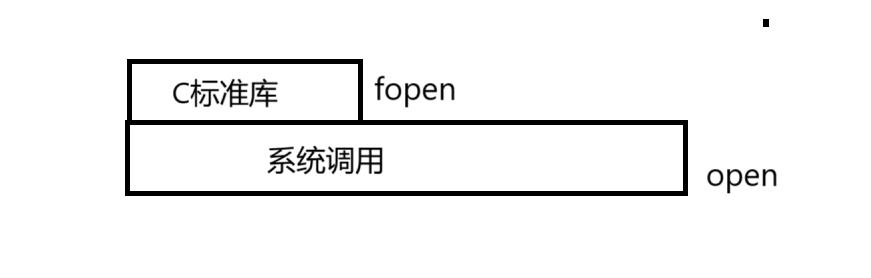
為什么c語言要封裝文件操作接口
系統調用太麻煩了? ?跨平臺性? 可移植性?
為什么大部分的語言,都對系統調用做封裝
需要具有跨平臺性(增加語言的競爭性)
?如何做到跨平臺性
所有版本的都寫一遍
(3)size_t fwrite(const void * ptr, size_t size, size_t nmemb,FILE*stream)
? ? ? ptr:?? 寫入的起始地址?
? ? ? size:寫入的基本單元的大小?
? ? ? nmemb:? 寫幾個? ?
? ? ? stream:? 向哪一個文件流中寫
注意:我們不需要strlen(str)+1 將字符串的\0帶上,等到讀取字符串的時候加上就行了
(4)size_t fread(void *buffer, size_t size,size_t nmemb,FILE? *stream)
? ? ? ? ? ? ? buffer:? ?讀到那? ?
? ? ? ? ? ? ? size:? ? 基本單元? ? ? ?
? ? ? ? ? ? ?nmemb:幾個? ? ? ? ? ?
? ? ? ? ? ? stream :?從哪里讀
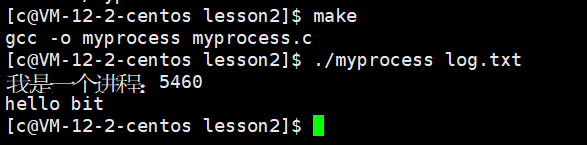
寫一個cat
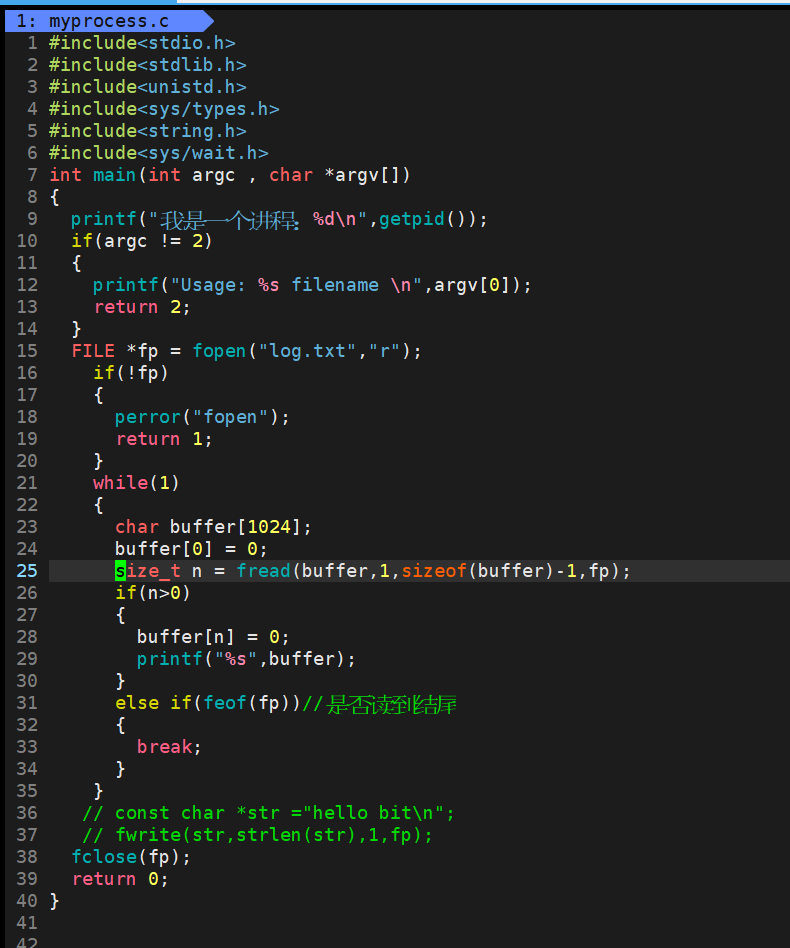 ? ? ? ??
? ? ? ??
- ?補充: 今天我們向顯示器寫入1234就是向顯示器中寫入了"1" "2" "3" 所以顯示器叫做字符設備 。我們向鍵盤輸入1234,我們實際上輸入的是"1" "2" "3" "4" 所以鍵盤叫做字符設備
- 所以我們使用printf()函數的時候必須要使用%d? % f,它的本質是將我們輸入的數據打散為字符(這就叫格式化輸入)
- scanf()同理就叫做格式化輸入
- 顯示器和鍵盤是文本文件,而二進制文件不需要做格式化工作(可以使用fwrite)
四、輸入輸出流
- stdin; stdout ; stderr;(進程在啟動的時候,默認會打開三個輸入輸出流,就是這三個文件)
- 標準輸入 標準輸出? 標準錯誤
為什么默認打開他們
因為進程大多數都是使用CPU資源進行計算的,都需要有數據的輸入,輸出結果,輸出錯誤(所以他們默認占據文件描述符的012)
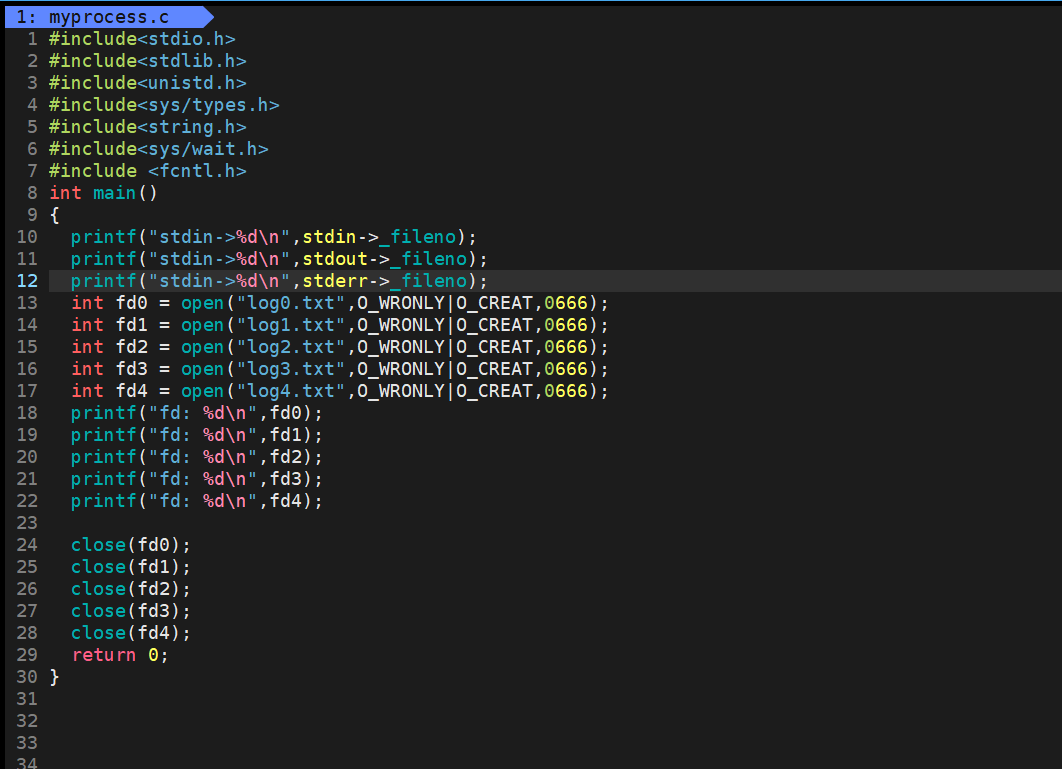 ?
?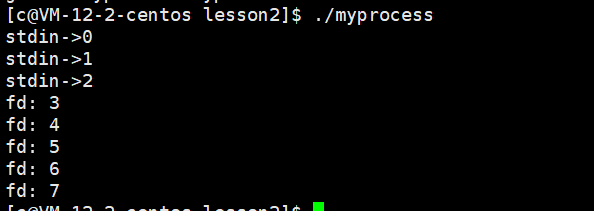
- 文件描述符的分配規則:給新打開的文件分配fd,從文件描述符表數組中尋找:最小的,沒有被使用的下標,作為作為改文件的fd?
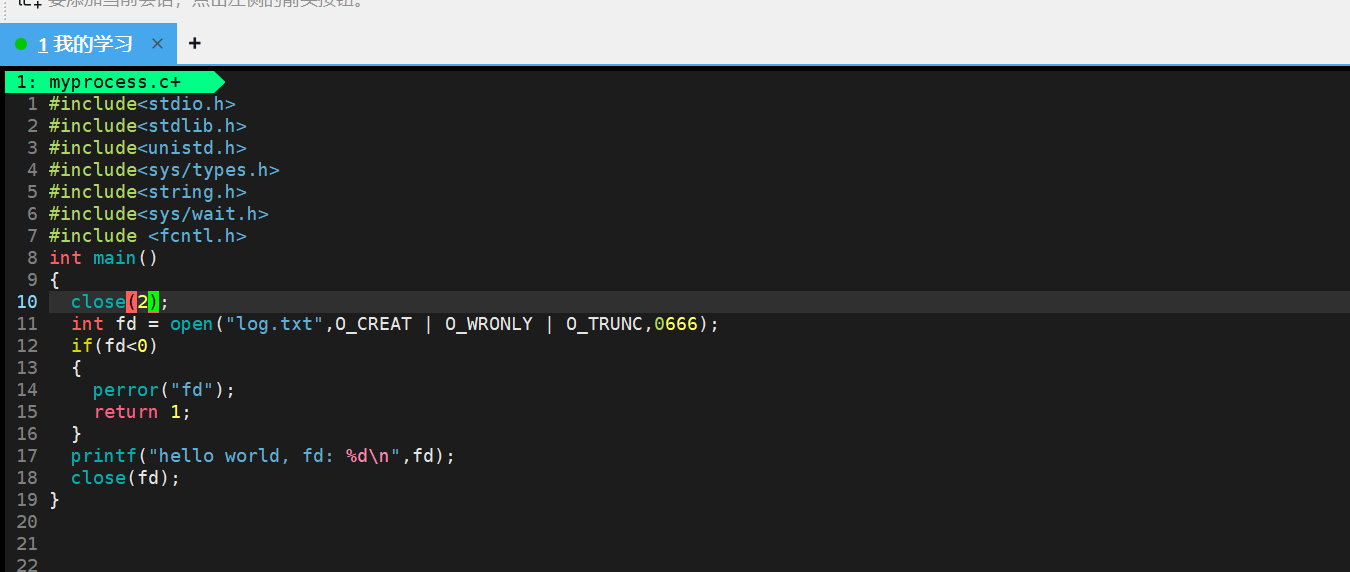
?

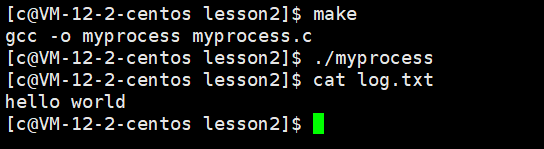
(1)重定向?
- 輸出重定向就是,將我們本應該輸出到一個文件的數據重定向輸出到另一個文件中
- 例如:關閉了1 打開文件,默認會將文件描述符1給他,printf默認會向stdout里面打印,但是stdout默認封裝了文件描述符1 ,所以會像log.txt里面打印,這就叫輸出重定向
- stdout指向是一個struct FILE 結構體,該結構體當中有一個文件描述符變量,stdout的文件描述符變量就是1
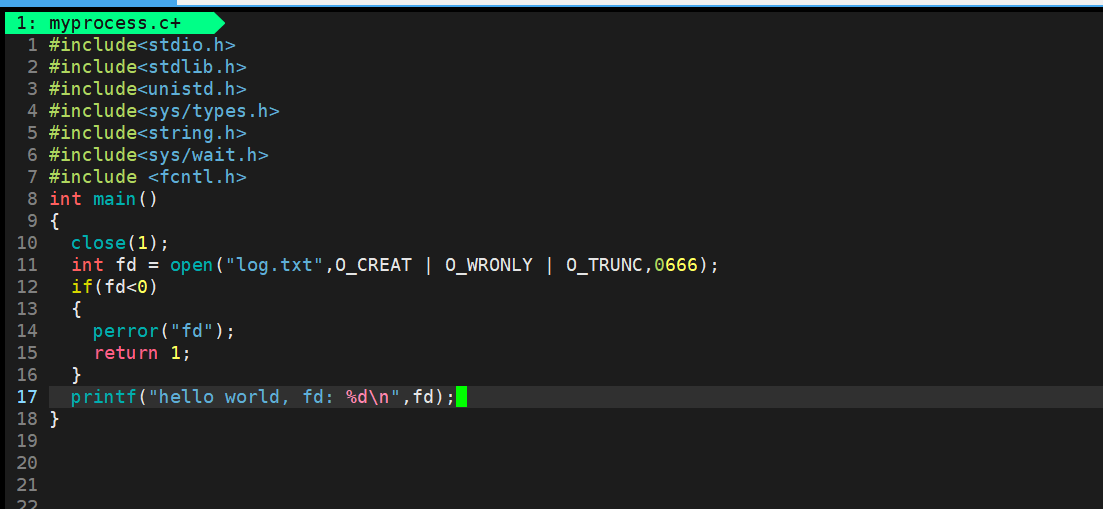
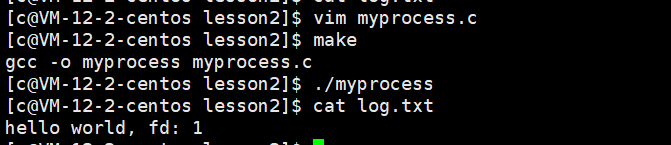
追加重定向的原理
輸出重定向和追加重定向唯一的區別就是輸出重定向是先清空文件,而追加重定向是追加式輸出
重定向接口
int dup2 (int oldfd ,int newfd)
注意:如果oldfd不是有效的文件描述符,則dup2調用失敗
? ? ? ? ? ?如果oldfd是一個有效的文件描述符,但是newfd和oldfd具有相同的值則直接放回newold
返回值:成功返回文件描述符,失敗返回-1
?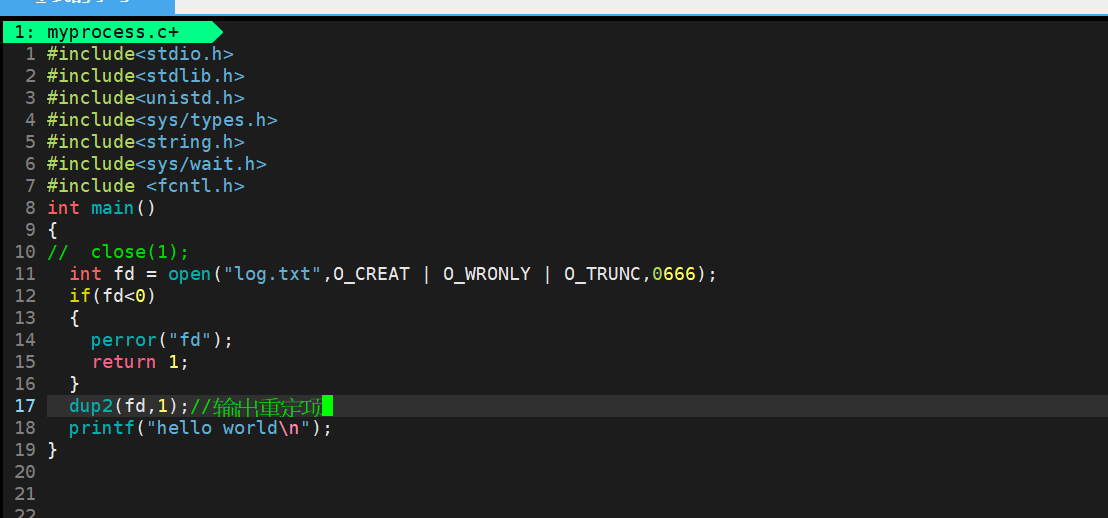
五、struct file
?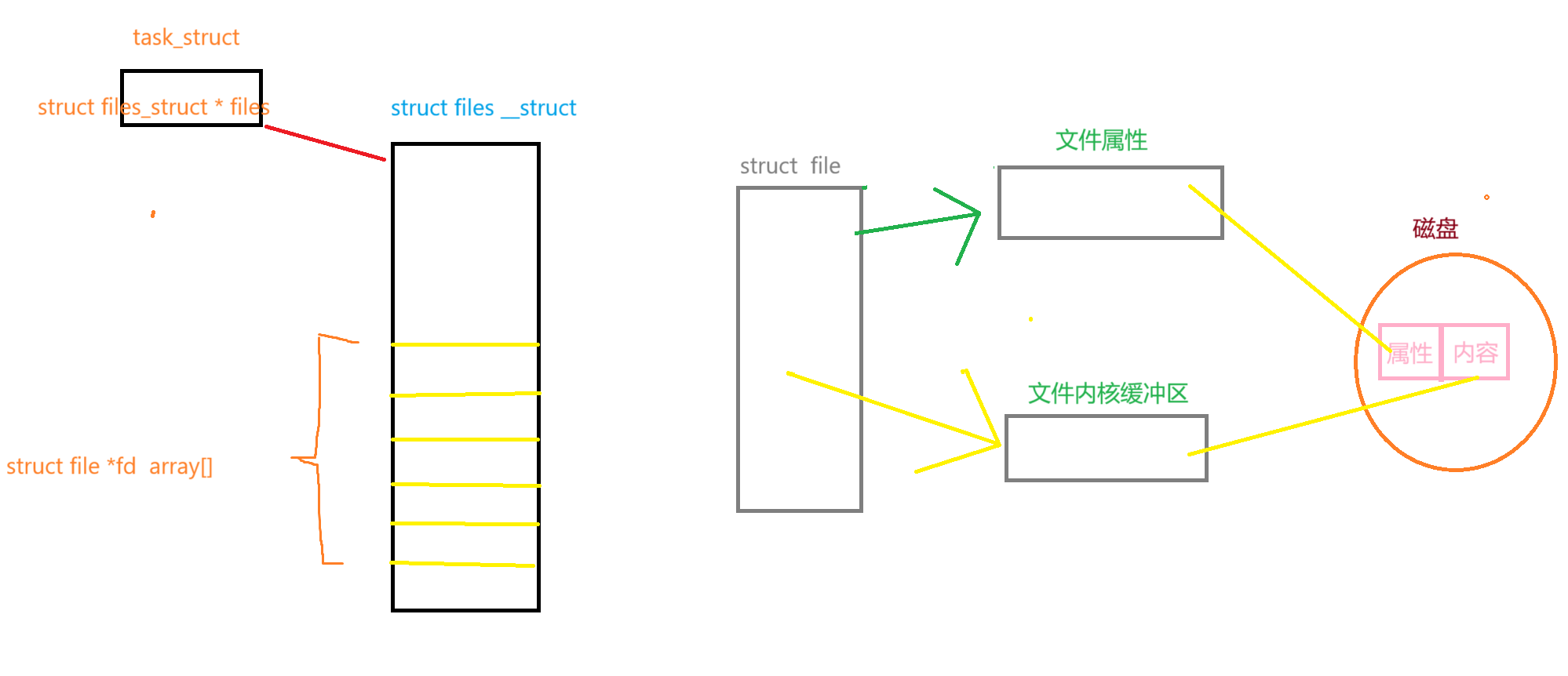
- ?在調用open之前已經有了task_struct 和 struct files_struct表
- 當我們在使用write(文件描述符,“要寫入的內容”)的時候,我們通過task_struct找到文件描述符表,通過文件描述符找到對應的struct file,然后將要寫入的內容寫到文件內核的緩沖區,在通過文件內核刷新到磁盤中
- 所以write根本不是寫入到文件,本質是拷貝函數,把數據從用戶空間拷貝到對應文件的內核緩沖區
- 什么時候刷新到磁盤文件中,由OS決定
- 讀數據也只能從文件內核緩沖區中讀,如果文件內核緩沖區沒有內容,需要等待磁盤刷新到磁盤中
- 我們進行任何文件內容的增刪查改都必須把文件的內容提前預加載到該文件的文件內核緩沖區
六、文件繼承
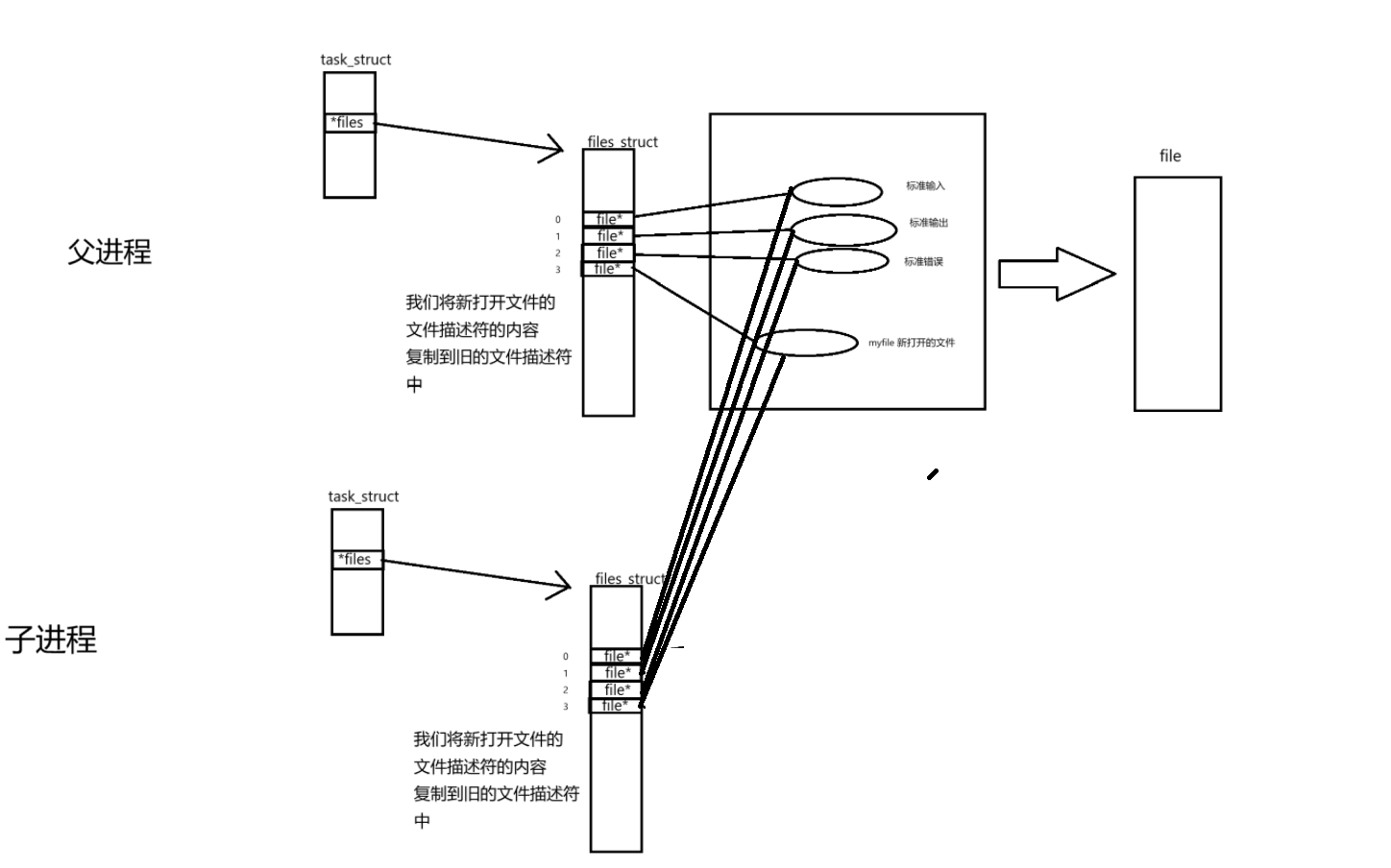
- 所以父子printf的時候,會同時向同一個顯示器文件,進行打印
- 對于子進程來講,他繼承了父的進程,所以子進程默認打開標準輸入,標準輸出,標準錯誤
- file(struct)有一個引用計數,表示改文件由多少struct_file指向我,當引用計數為1的時候才能真正關閉文件

七、理解一切皆文件(硬件方向)
- 我們知道操作系統對硬件會進行管理(描述在組織)形成對應的鏈表,他們每一個都有對應的實現讀寫的方法
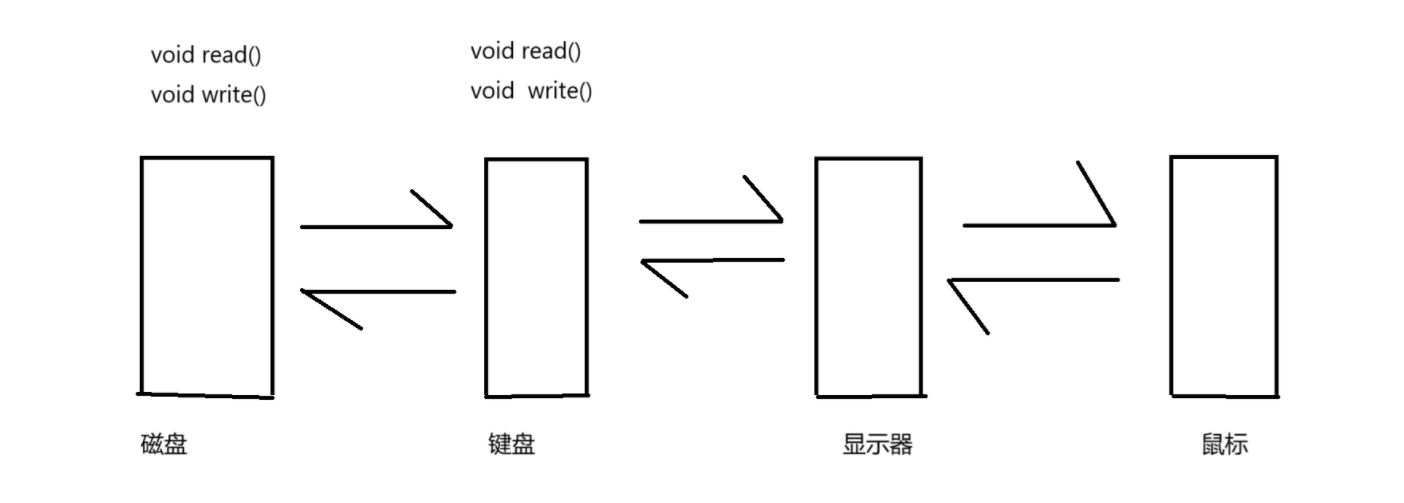 ?在打開一個文件的時候,會為我們創建struct_file 包含屬性集合,,文件內核緩沖區,還會有一些方法集合指向對應硬件的實現方法,在將stuct_file的地址寫入到struct file_struct的表中,所以站在進程視角下,就是一切皆文件
?在打開一個文件的時候,會為我們創建struct_file 包含屬性集合,,文件內核緩沖區,還會有一些方法集合指向對應硬件的實現方法,在將stuct_file的地址寫入到struct file_struct的表中,所以站在進程視角下,就是一切皆文件
八、文件緩沖區
1、緩沖區的理解
- 緩沖區的本質,其實就是一段內存空間
例
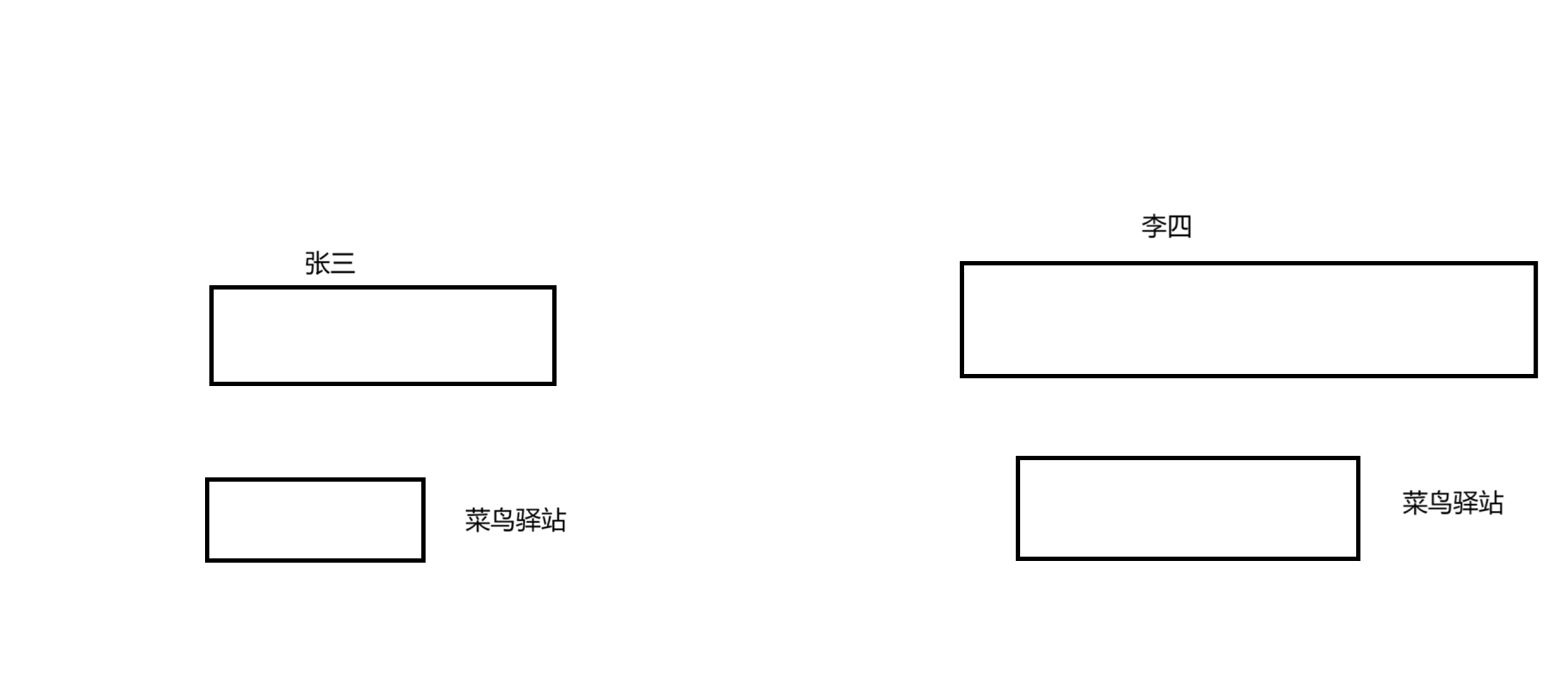
- 如上圖張三如果像給李四送一個禮物,如果張三自己去把禮物給李四,那么會花費大量張三的時間,但是如果將禮物給菜鳥驛站,站在張三的視角下禮物已經給了出去,且節省了他的時間,緩存的數據就是禮物,禮物給菜鳥驛站就等于write
- 緩存最大的意義:是提高使用緩存的進程效率,允許進程單位時間內做更多的工作,變相的提高了使用者的效率
- 在菜鳥驛站的角度下來看,他不可能收到一件商品就給他寄出去,所以緩沖區允許數據積壓,以一次,就可以刷新多次數據,變相的減少IO的次數)
2、緩沖區的刷新策略
三種形式:
- 無緩沖,立即刷新? ?
- 有緩沖,行刷新 (顯示器中使用)?
- 有緩沖,寫滿刷新(普通文件采用者這種方式)
兩種情況 :
- 進程退出,主動刷新?
- 進程強制刷新fflush
3、FILE緩沖區
(1)引入
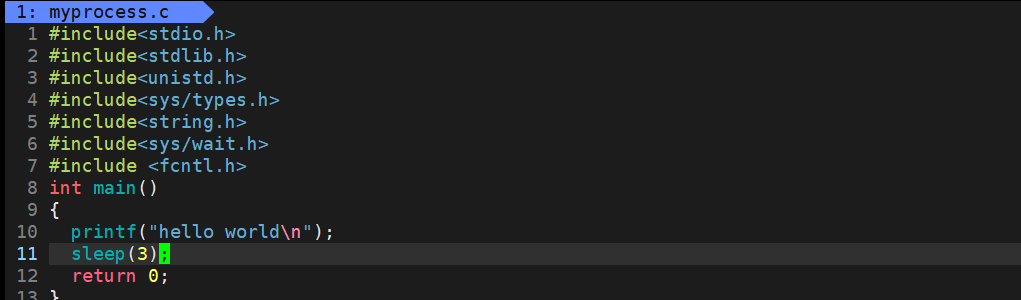
- 上圖的代碼執行的時候先執行的是printf但是當我們運行起來的時候會發現是先暫停的3,然后屏幕上在出現的hello world,,這是因為printf的打印先開始是打印到文件緩沖區中的等到進程結束的時候才刷新出來的,這里的緩沖區是FILE緩沖區,不是內核文件緩沖區
(2)本質
- struct FILE本質是一個結構體,包含文件描述符
- C語言上,輸入輸出格式化
- C訪問文件,都是通過FILE訪問的,包括stdin stdout stderr
- FILE結構體內部為我們維護語言級別的緩沖區

?過程
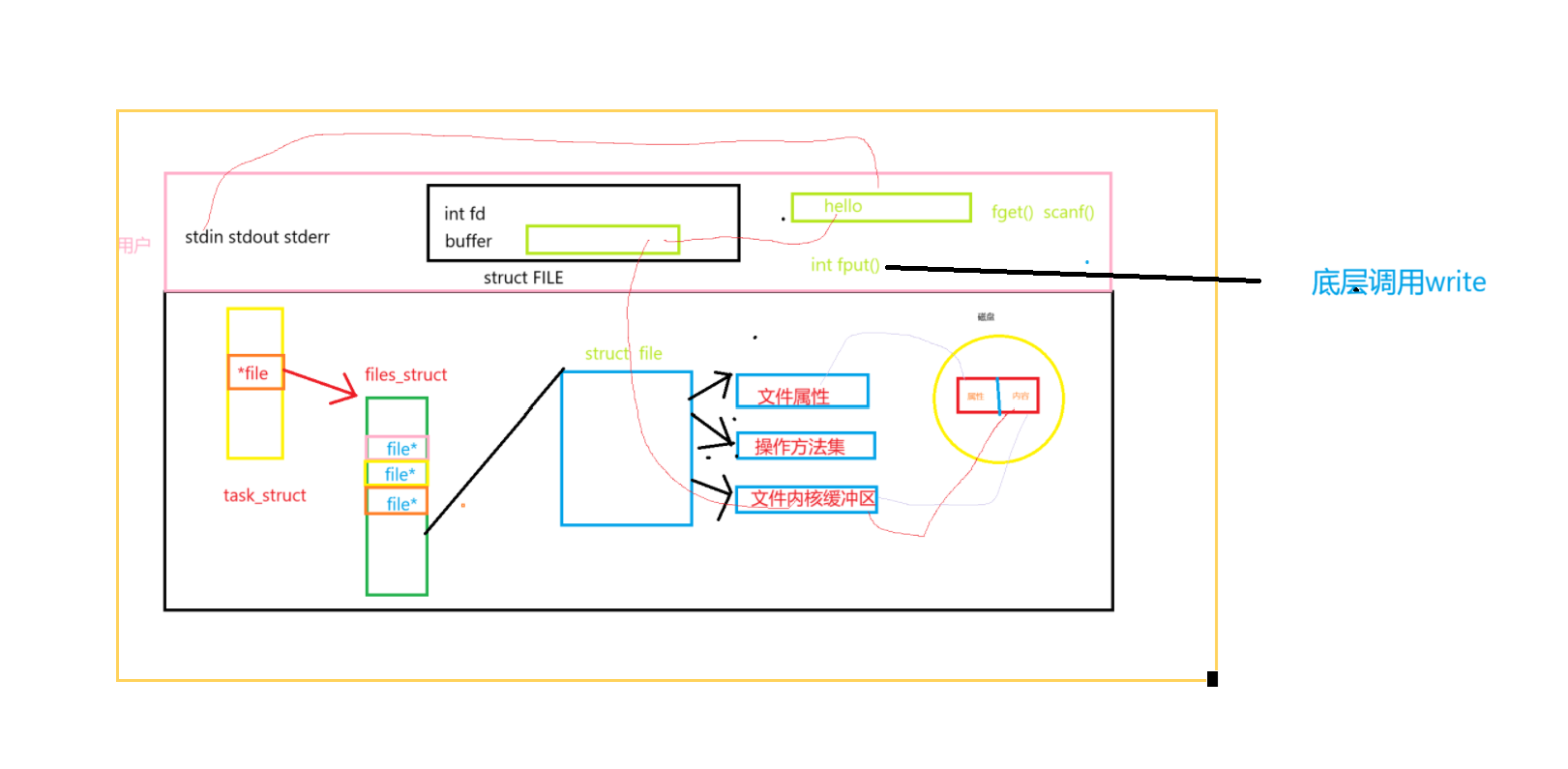
- 如上圖首先通過fget(),scanf() 將鍵盤中輸入的內容獲取,在通過fput() (底層調用write)將獲取的內容拷貝到struct FILE文件緩沖區中,通過刷新將內容刷新到文件內核緩沖區中,同過操作方法集刷新到磁盤中
(3)FILE刷新方式(緩沖區到內核緩沖區)
- 無,立即刷新
- 行,行刷新(顯示器文件)
- 滿,全刷新
緩沖區在哪?
FILE內部
為什么要用語言級別緩沖區?
調用系統調用是用成本的
C語言為什么要提供語言級別的緩沖區
加速IO函數的調用效率 (加快使用C語言IO接口的效率,單位時間內執行C代碼的行數,就多了)
?如何理解printf scanf的格式化過程? ?
1、格式化? ? ? 2、格式化結果寫入到FILE緩沖區中? ?3、檢測是否需要刷新? 4、 如果需要刷新調用write
例:
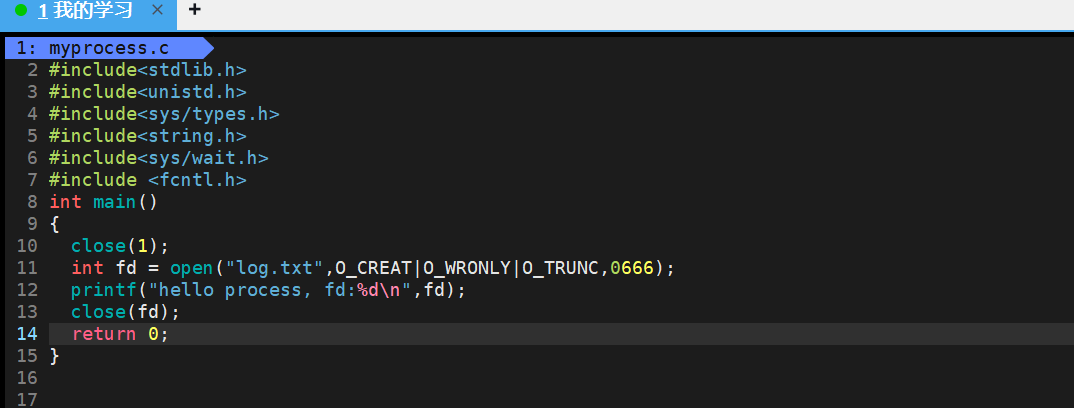
- 如上的代碼,我們會發現log.txt中沒有內容,因為當我們關閉文件描述符1,在打開log.txt他的文件描述符默認就是為1,printf()是向stdout中進程打印,stdout 中默認封裝了文件描述符1,所以printf()回向log.txt中打,但是他有文件緩沖區不會立即刷新到log.txt,默認文件關閉的時候刷新到內核緩沖區,但是這時候我們關閉了文件。 所以他會刷新到log.txt
(4)一個現象
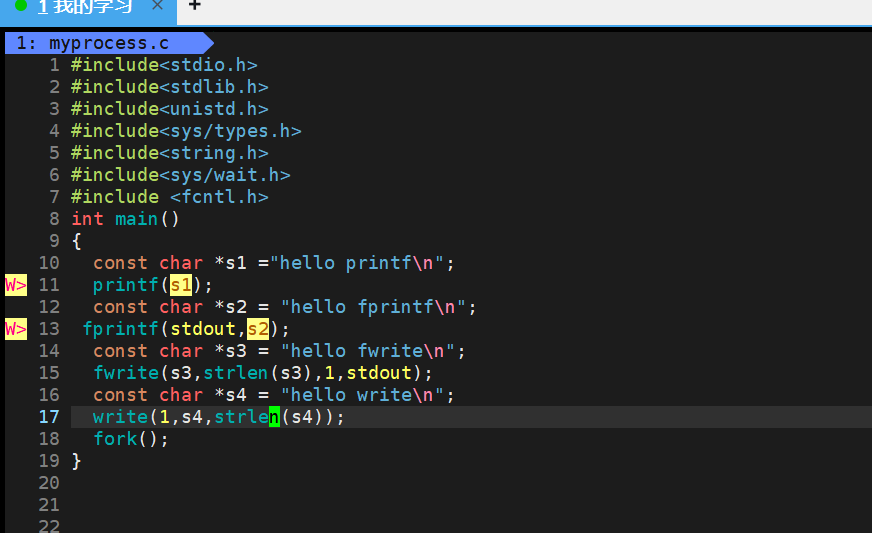
?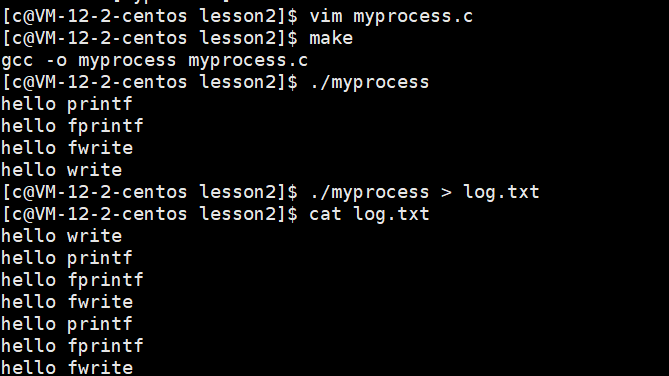
- 我們能發現上面的接口我們打印到顯示器上,只會打印一次,但是我們重定向到文件中write,打印一次,其他的都會打印二次
- 首先打印到顯示器中有\n他按行刷新,?所以他每一個都只打印一個
- 當他打印到文件中他的刷新規則變成了寫滿刷新,所以只有退出的時候才會刷新,write是直接寫到內核中的,所以他是第一個打印的,其他的都在內核緩沖區中,當退出的時候fork()父子進程都有自己的stdout,指向同一個緩沖區,當要進行清空緩沖區的時候,就是要進行改數據,會發生寫時拷貝,從而打印兩次
九、內核文件區
(1)內核文件緩沖區的刷新方式
- 一般而言:全刷新
- 顯示器:行刷新
- 單獨的執行流,根據內存的使用方式來動態刷新,即使刷新條件不滿足
(2)接口
int fsync(int fd)
強制從內核 ——》外設












)




—— PyTorch 轉 ONNX 詳解)

