前言
還在為機器翻譯模型從理論到落地卡殼?系列博客第三彈——模型訓練篇強勢登場,手把手帶你走完Transformer中日翻譯項目的最后關鍵一步!
前兩期我們搞定了數據預處理(分詞、詞表構建全流程)和模型搭建(詞嵌入、位置編碼、編碼器解碼器核心結構),而這一篇,將聚焦讓模型“學會翻譯”的核心秘籍:
- 如何設計損失函數,讓模型精準捕捉中日語言差異?
- 優化器參數怎么調,才能讓訓練更穩定、收斂更快?
從數據到模型,再到訓練全流程,一套代碼跑通Transformer翻譯任務。
本篇主要介紹機器翻譯項目中模型訓練部分是如何處理的,延續之前篇章預處理篇,模型篇的內容。
系列博客第一彈——基于Transformer的機器翻譯——預處理篇
系列博客第二彈——基于Transformer的機器翻譯——模型篇
系列博客第三彈——基于Transformer的機器翻譯——訓練篇
1.模型介紹
1.1模型參數配置
參數主要有源語言與目標語言詞表大小、詞嵌入維度、多頭注意力頭數、前饋神經網絡隱藏層維度、編碼器與解碼器層數、批量大小等,這些均屬于超參數,需要在訓練中不斷調整,考慮到自身硬件條件,超參數設置如下:
# 模型參數配置
SRC_VOCAB_SIZE = len(ja_vocab) # 源語言(日語)詞匯表大小
TGT_VOCAB_SIZE = len(ch_vocab) # 目標語言(中文)詞匯表大小
EMB_SIZE = 512 # 詞嵌入維度(與Transformer的d_model一致)
NHEAD = 8 # 多頭注意力的頭數
FFN_HID_DIM = 512 # 前饋網絡隱藏層維度
BATCH_SIZE = 16 # 批量大小(每次輸入的樣本數)
NUM_ENCODER_LAYERS = 3 # 編碼器層數
NUM_DECODER_LAYERS = 3 # 解碼器層數
NUM_EPOCHS = 16 # 訓練輪數(完整遍歷數據集的次數)
接著初始化網絡模型:
transformer = Seq2SeqTransformer(NUM_ENCODER_LAYERS,NUM_DECODER_LAYERS,EMB_SIZE,SRC_VOCAB_SIZE,TGT_VOCAB_SIZE,FFN_HID_DIM
)
1.2模型結構
可以直接打印模型,查看模型結構,如下:
transformer
輸出結果:
Seq2SeqTransformer((transformer_encoder): TransformerEncoder((layers): ModuleList((0-2): 3 x TransformerEncoderLayer((self_attn): MultiheadAttention((out_proj): NonDynamicallyQuantizableLinear(in_features=512, out_features=512, bias=True))(linear1): Linear(in_features=512, out_features=512, bias=True)(dropout): Dropout(p=0.1, inplace=False)(linear2): Linear(in_features=512, out_features=512, bias=True)(norm1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)(norm2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)(dropout1): Dropout(p=0.1, inplace=False)(dropout2): Dropout(p=0.1, inplace=False))))(transformer_decoder): TransformerDecoder((layers): ModuleList((0-2): 3 x TransformerDecoderLayer((self_attn): MultiheadAttention((out_proj): NonDynamicallyQuantizableLinear(in_features=512, out_features=512, bias=True))(multihead_attn): MultiheadAttention((out_proj): NonDynamicallyQuantizableLinear(in_features=512, out_features=512, bias=True))(linear1): Linear(in_features=512, out_features=512, bias=True)(dropout): Dropout(p=0.1, inplace=False)(linear2): Linear(in_features=512, out_features=512, bias=True)(norm1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)(norm2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)(norm3): LayerNorm((512,), eps=1e-05, elementwise_affine=True)(dropout1): Dropout(p=0.1, inplace=False)(dropout2): Dropout(p=0.1, inplace=False)(dropout3): Dropout(p=0.1, inplace=False))))(generator): Linear(in_features=512, out_features=26854, bias=True)(src_tok_emb): TokenEmbedding((embedding): Embedding(24058, 512))(tgt_tok_emb): TokenEmbedding((embedding): Embedding(26854, 512))(positional_encoding): PositionalEncoding((dropout): Dropout(p=0.1, inplace=False))
)
1.3參數初始化
一般主要有兩種初始化模型參數的方法,包括He初始化(即一般默認的初始化方法)和Xavier初始化方法。
- He初始化:適用于使用
ReLU或其變種Leaky ReLU這類激活函數的神經網絡。 - Xavier初始化:適用于
tanh、sigmoid等這類對稱激活函數。
這里采用Xavier初始化,代碼如下:
# 參數初始化(Xavier均勻初始化,緩解梯度消失/爆炸)
for p in transformer.parameters():if p.dim() > 1: # 僅初始化非標量參數nn.init.xavier_uniform_(p)
為了加快模型的訓練速度,這里使用GPU加速,即將模型遷移至GPU上進行訓練。
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
transformer = transformer.to(device)
如果未配置GPU環境,此處會默認使用CPU。
2.訓練策略
2.1損失函數
因為該問題最終是一個分類問題,預測詞表中的一個單詞。而分類問題,一般采用交叉熵損失函數。同時,因為此前我們填充<PAD_IDX>字符使輸入句子長度保持一致,所以在計算交叉熵的時候,應該將該字符產生的損失忽略。
代碼如下:
loss_fn = torch.nn.CrossEntropyLoss(ignore_index=PAD_IDX)
2.2優化器
優化器大都會選用自適應優化器Adam,相對于常規的SGD(隨機梯度下降方法),避免了頻繁調整參數,同時能夠更快的收斂。代碼如下:
optimizer = torch.optim.Adam(transformer.parameters(), # 待優化的模型參數lr=0.0001, # 學習率(控制參數更新步長)betas=(0.9, 0.98), # 動量參數(控制歷史梯度的衰減)eps=1e-9 # 數值穩定性參數(防止除零)
)
2.3訓練過程
整體的訓練過程主要包括五個步驟:
- 梯度清零
- 計算模型輸出
- 計算損失
- 方向傳播
- 參數更新
模型輸入包括兩部分,輸入的源語言,和目標語言已經生成的部分,分別對應于編碼器的輸入和解碼器的輸入。
因為是逐個token進行預測,所以編碼器的輸入不包括句子的最后一個token即EOS_IDX,模型預測輸出到EOS_IDX即結束,相應的監督標簽為目標語言不包括第一個token即BOS_IDX。
相應代碼為:
src = src.to(device) # 將源序列移動到GPU/CPUtgt = tgt.to(device) # 將目標序列移動到GPU/CPUtgt_input = tgt[:-1, :] # 目標輸入去掉最后一個詞tgt_output = tgt[1:, :] # 目標輸出去掉第一個詞
因為模型在進行訓練時,不能關注到目標輸入后續的token,因此需要掩碼注意力機制
2.3.1順序掩碼
采用下三角掩碼,防止模型在預測第i個詞時關注到第i+1、i+2… 個詞(即 “未來信息”)
- 通過
torch.triu(torch.ones((3,3)))生成上三角矩陣(對角線及以上為 1,其余為 0) ==1轉為布爾矩陣(True 表示原位置為 1),再transpose(0,1)轉置(行變列,列變行)masked_fill填充:True 位置(有效)填 0.0,False 位置(無效,未來信息)填-inf
本案例主要通過函數generate_square_subsequent_mask函數實現,代碼如下:
def generate_square_subsequent_mask(sz):# 1. 生成上三角矩陣(對角線及以上為1,其余為0)mask = (torch.triu(torch.ones((sz, sz), device=device)) == 1).transpose(0, 1)# 2. 將0的位置填充為-inf(無效位置),1的位置填充為0(有效位置)mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))return mask
2.3.2完整掩碼組合
這里主要4 種掩碼,分別用于源序列和目標序列的注意力計算。
2.3.2.1源序列自注意力掩碼
源序列是輸入,無需掩蓋 “未來信息”,因此全為 0(允許關注所有位置)。
2.3.2.2目標序列自注意力掩碼
可以通過調用 generate_square_subsequent_mask實現。
2.3.2.3源序列填充掩碼
標記源序列中PAD的位置,讓模型在注意力計算時忽略這些無效位置。
2.3.2.4目標序列填充掩碼
類似源序列,標記目標序列中PAD的位置。
2.3.2.5完整代碼
上述四種掩碼的生成代碼可表述為以下代碼:
def create_mask(src, tgt):src_seq_len = src.shape[0] # 源序列長度(seq_len)tgt_seq_len = tgt.shape[0] # 目標序列長度(seq_len)# 目標序列的注意力掩碼(下三角掩碼,防止關注未來詞)tgt_mask = generate_square_subsequent_mask(tgt_seq_len)# 源序列的注意力掩碼(全0,允許關注所有位置)src_mask = torch.zeros((src_seq_len, src_seq_len), device=device).type(torch.bool)# 源序列的填充掩碼(標記<pad>的位置)src_padding_mask = (src == PAD_IDX).transpose(0, 1)# 目標序列的填充掩碼(標記<pad>的位置)tgt_padding_mask = (tgt == PAD_IDX).transpose(0, 1)return src_mask, tgt_mask, src_padding_mask, tgt_padding_mask
2.3.3訓練代碼
由上述代碼可得,訓練過程可表述為以下代碼:
- 獲取當前批量的輸入與目標輸出序列
- 生成掩碼
- 計算模型預測輸出
- 清空梯度
- 計算預測輸出與目標輸出之間的損失
- 方向傳播
- 更新梯度
for idx, (src, tgt) in enumerate(train_iter): # 遍歷訓練數據迭代器src = src.to(device) # 將源序列移動到GPU/CPUtgt = tgt.to(device) # 將目標序列移動到GPU/CPUtgt_input = tgt[:-1, :] # 目標輸入去掉最后一個詞tgt_output = tgt[1:, :] # 目標輸出去掉第一個詞# 生成掩碼(注意力掩碼+填充掩碼)src_mask, tgt_mask, src_padding_mask, tgt_padding_mask = create_mask(src, tgt_input)# 前向傳播:模型預測logits = model(src, tgt_input, src_mask, tgt_mask,src_padding_mask, tgt_padding_mask, src_padding_mask)optimizer.zero_grad() # 清空優化器梯度tgt_out = tgt[1:, :] # 目標輸出(去掉第一個詞,與預測對齊)loss = loss_fn( # 計算損失logits.reshape(-1, logits.shape[-1]), # 展平預測結果([seq_len*batch_size, vocab_size])tgt_out.reshape(-1) # 展平真實標簽([seq_len*batch_size]))loss.backward() # 反向傳播計算梯度optimizer.step() # 更新模型參數losses += loss.item() # 累加單批損失
為了減小梯度抖動,采用當前iter內所有損失的平均和,同時為了可視化損失折線圖,加入了tensorboard可視化,并加入進度條來顯示訓練過程,當前訓練過程。代碼如下:
def train_epoch(model, train_iter, optimizer):model.train() # 開啟訓練模式(啟用Dropout等)losses = 0 # 累計損失值for idx, (src, tgt) in enumerate(train_iter): # 遍歷訓練數據迭代器src = src.to(device) # 將源序列移動到GPU/CPUtgt = tgt.to(device) # 將目標序列移動到GPU/CPUtgt_input = tgt[:-1, :] # 目標輸入去掉最后一個詞tgt_output = tgt[1:, :] # 目標輸出去掉第一個詞# 生成掩碼(注意力掩碼+填充掩碼)src_mask, tgt_mask, src_padding_mask, tgt_padding_mask = create_mask(src, tgt_input)# 前向傳播:模型預測logits = model(src, tgt_input, src_mask, tgt_mask,src_padding_mask, tgt_padding_mask, src_padding_mask)optimizer.zero_grad() # 清空優化器梯度tgt_out = tgt[1:, :] # 目標輸出(去掉第一個詞,與預測對齊)loss = loss_fn( # 計算損失logits.reshape(-1, logits.shape[-1]), # 展平預測結果([seq_len*batch_size, vocab_size])tgt_out.reshape(-1) # 展平真實標簽([seq_len*batch_size]))# 寫入tensorboardwriter.add_scalar('train_loss',loss.item(),idx)loss.backward() # 反向傳播計算梯度optimizer.step() # 更新模型參數losses += loss.item() # 累加單批損失train_bar.set_postfix({'loss': '{:.6f}'.format(loss.item())})train_bar.update()return losses / len(train_iter) # 返回平均訓練損失
為了避免長時間等待,因此使用當前數據集的10%,其中9%作為訓練集,1%作為測試集。代碼如下:
train_iter = DataLoader(train_data[:int(len(train_data)*0.09)], batch_size=BATCH_SIZE,shuffle=True, collate_fn=generate_batch)
test_iter = DataLoader(train_data[int(len(train_data)*0.09):int(len(train_data)*0.1)], batch_size=BATCH_SIZE,shuffle=True, collate_fn=generate_batch)
3.訓練結果
假如此時按照每個iter來進行記錄損失(上述代碼就是如此),結果會出現劇烈波動,整體還是會保持下降趨勢,結果如下:
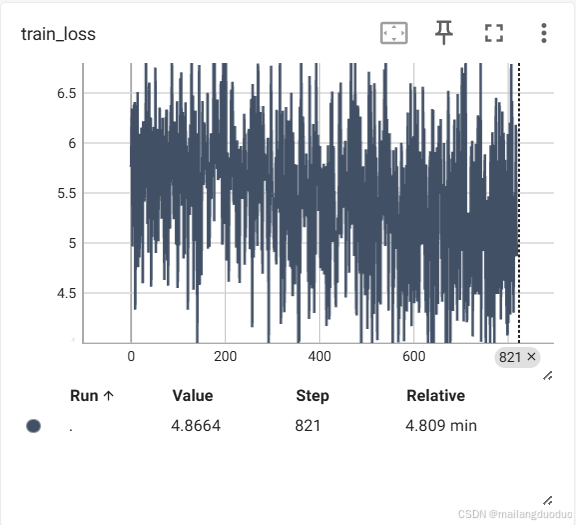
此時將其改成每個epoch來記錄損失,取當前epoch的平均值,結果如下:
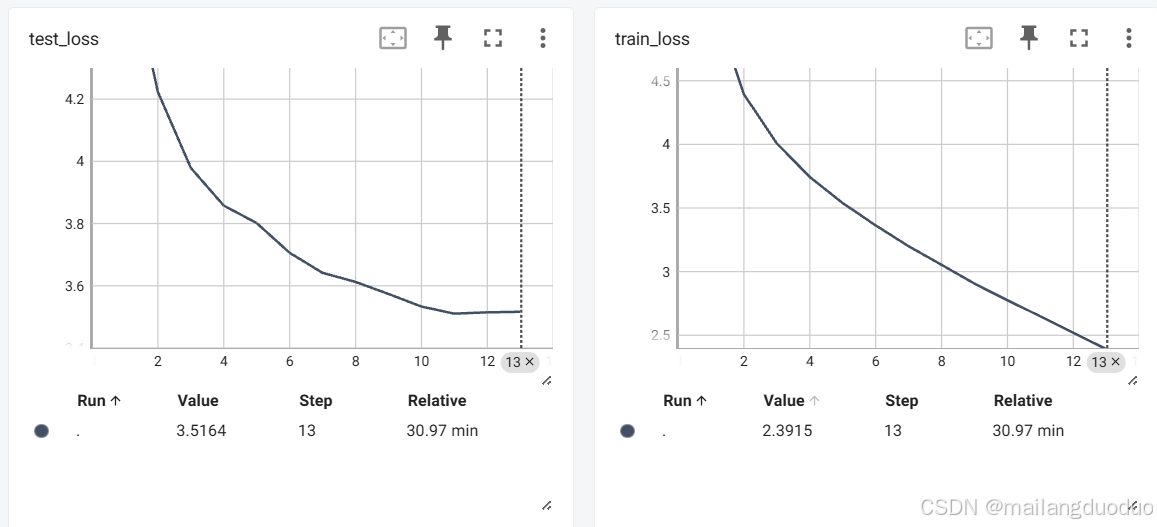
此時只統計了12個點,當然你可以通過增加epoch輪數來增加統計的點數,但是曲線的變化趨勢往往是判斷模型過擬合和欠擬合的關鍵,因此一般采用每多個iter內的加權值來統計一次損失。這里為了方便起見,采用的仍是按照epoch進行統計的。
同時為了可視化訓練進度,此處加入了進度條來實時展示訓練的進度。統計損失使用tensorboard進行可視化。
完整訓練過程代碼為:
訓練函數:
writer=SummaryWriter('./logs')
def train_epoch(model, train_iter, optimizer,epoch):model.train() # 開啟訓練模式(啟用Dropout等)losses = 0 # 累計損失值for idx, (src, tgt) in enumerate(train_iter): # 遍歷訓練數據迭代器src = src.to(device) # 將源序列移動到GPU/CPUtgt = tgt.to(device) # 將目標序列移動到GPU/CPUtgt_input = tgt[:-1, :] # 目標輸入去掉最后一個詞tgt_output = tgt[1:, :] # 目標輸出去掉第一個詞# 生成掩碼(注意力掩碼+填充掩碼)src_mask, tgt_mask, src_padding_mask, tgt_padding_mask = create_mask(src, tgt_input)# 前向傳播:模型預測logits = model(src, tgt_input, src_mask, tgt_mask,src_padding_mask, tgt_padding_mask, src_padding_mask)optimizer.zero_grad() # 清空優化器梯度tgt_out = tgt[1:, :] # 目標輸出(去掉第一個詞,與預測對齊)loss = loss_fn( # 計算損失logits.reshape(-1, logits.shape[-1]), # 展平預測結果([seq_len*batch_size, vocab_size])tgt_out.reshape(-1) # 展平真實標簽([seq_len*batch_size]))loss.backward() # 反向傳播計算梯度optimizer.step() # 更新模型參數losses += loss.item() # 累加單批損失train_bar.set_postfix({'loss': '{:.6f}'.format(loss.item())})train_bar.update()# 寫入tensorboardwriter.add_scalar('train_loss',losses / len(train_iter),epoch)return losses / len(train_iter) # 返回平均訓練損失
驗證函數:
def evaluate(model, test_iter,epoch):model.eval()losses = 0for src, tgt in test_iter:src = src.to(device)tgt = tgt.to(device)tgt_input = tgt[:-1, :]tgt_output = tgt[1:, :]src_mask, tgt_mask, src_padding_mask, tgt_padding_mask = create_mask(src, tgt_input)logits = model(src, tgt_input, src_mask, tgt_mask, src_padding_mask, tgt_padding_mask, src_padding_mask)tgt_out = tgt[1:, :]loss = loss_fn(logits.reshape(-1, logits.shape[-1]), tgt_out.reshape(-1))losses += loss.item()test_bar.set_postfix({'loss': '{:.6f}'.format(loss.item())})test_bar.update()writer.add_scalar('test_loss',losses / len(test_iter),epoch)return losses / len(test_iter)
調用函數:
from tqdm.notebook import tqdm
epoch_bar = tqdm(desc='training routine',total=NUM_EPOCHS,position=0)train_bar = tqdm(desc='split=train',total=len(train_iter),position=0,leave=True)
test_bar=tqdm(desc='split=test',total=len(test_iter),position=0,leave=True)
best_loss = float('inf')
for epoch in range(1, NUM_EPOCHS+1):start_time = time.time()train_loss = train_epoch(transformer, train_iter, optimizer,epoch)test_loss = evaluate(transformer, test_iter,epoch)if test_loss < best_loss:best_loss = test_loss# 保存時分開保存torch.save(transformer.state_dict(), './share/model_weights.pth') # 只保存權重torch.save({'ja_vocab': ja_vocab, 'ch_vocab': ch_vocab}, './share/vocab.pth') # 保存詞表print(f"Epoch: {epoch}, Train loss: {train_loss:.3f}, Model saved.")epoch_bar.set_postfix({'train_loss': '{:.6f}'.format(train_loss)})epoch_bar.update()train_bar.n = 0test_bar.n=0end_time = time.time()print((f"Epoch: {epoch}, Train loss: {train_loss:.3f}, "f"Epoch time = {(end_time - start_time):.3f}s"))
訓練結果:
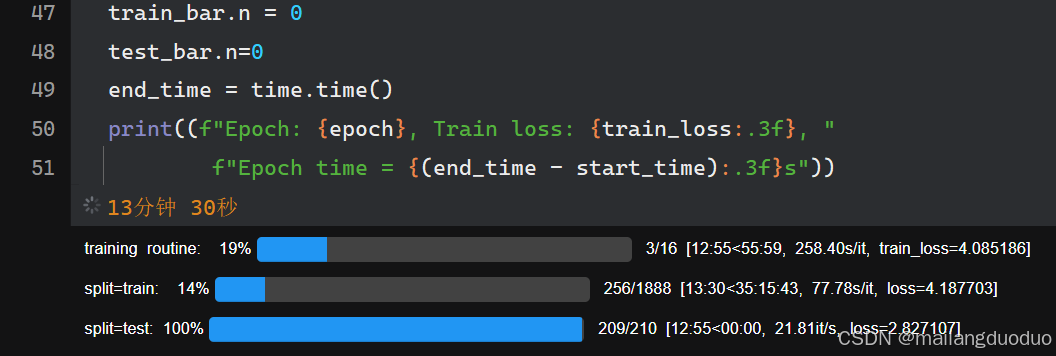
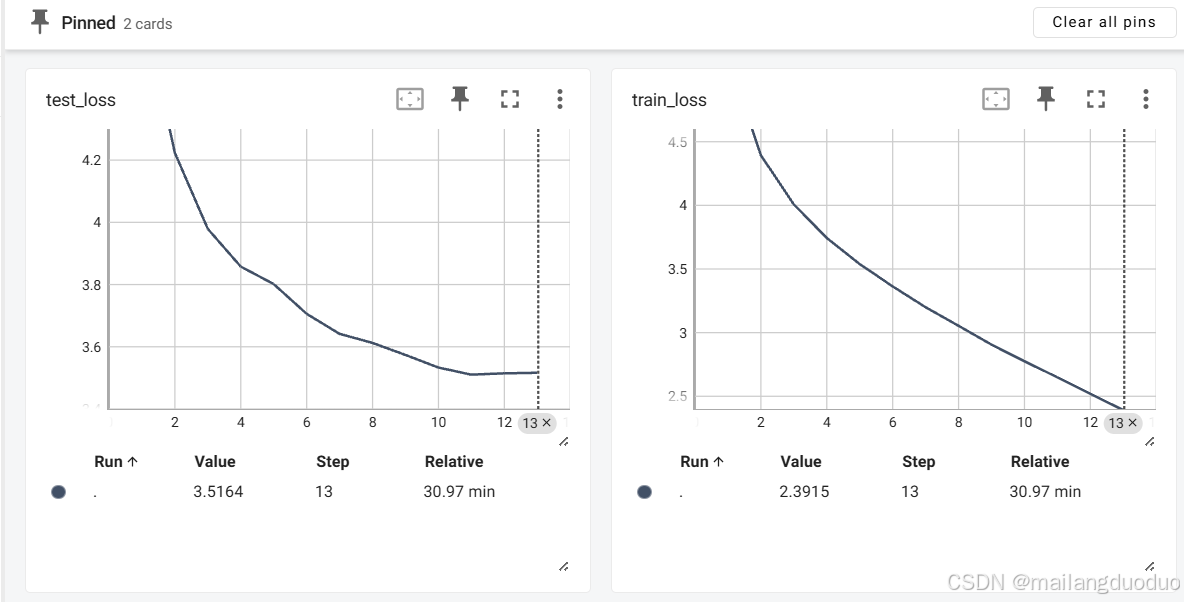
結語
至此,基于Transformer的機器翻譯任務就介紹完畢了,至于模型性能的評價指標如BLEU并未做介紹,感興趣的可以自行探索,希望本案例,能夠對你有所幫助,感謝支持!
系列博客第一彈——基于Transformer的機器翻譯——預處理篇
系列博客第二彈——基于Transformer的機器翻譯——模型篇
系列博客第三彈——基于Transformer的機器翻譯——訓練篇





)





 一棵 AVL 樹)


--------從混淆矩陣到分類報告全面解析?)




