作者:來自 Elastic?Alessandro Brofferio

學習如何使用 Elasticsearch 構建 RAG 應用,輕松排查你的家電問題。
想要獲得 Elastic 認證嗎?來看看下一次 Elasticsearch 工程師培訓什么時候開始吧!
Elasticsearch 擁有大量新功能,可以幫助你根據使用場景構建最佳搜索解決方案。深入學習我們的示例筆記本,了解更多信息,開啟免費的云試用,或者現在就在本地機器上嘗試 Elastic。
RAG(Retrieval Augmented Generation)通過使用外部知識庫來豐富生成的答案,從而增強了 LLM 的能力。這篇博客詳細介紹了一個基于 Elasticsearch 構建的簡單 RAG 應用的實現。該應用旨在幫助用戶排查家電問題,回答常見問題,比如 “如何將我的洗碗機恢復到出廠設置?”
我們將一步步指導你,涵蓋以下內容:
-
使用 Eland 庫上傳嵌入模型,并在 Elastic 中設置推理 API 來使用上傳的模型進行文本嵌入
-
創建一個使用 semantic_text 類型來存儲 PDF 正文內容的 Elasticsearch 索引
-
設置一個 LLM completion 推理端點,用來與所選的 LLM 交互
-
使用 semantic_text 查詢類型,根據用戶查詢檢索相關文檔
-
將所有內容結合在一起,構建一個出色的原型
你需要:
-
一個至少更新到 Elastic 8.18.x 的 Elastic Cloud 部署
-
一個 LLM API 服務(我使用的是 OpenAI Azure)
該應用基于一個簡單的 Flask 應用構建,可以無縫集成 Elasticsearch API 來執行 RAG。同時配有一個簡單的前端,允許用戶上傳用戶手冊進行處理。完整代碼在這里可以獲取。
這個 RAG 應用接收你選擇的家電 PDF 手冊。上傳后,它會智能地逐頁解析 PDF 文檔,并將每一頁提取的文本內容發送到 Elasticsearch。在那里,會依靠導入 Elasticsearch 的推理模型為內容創建文本嵌入,并將其存儲為 dense_vectors。一旦手冊處理完成,用戶就可以輸入查詢,利用這些知識快速找到家電問題的解決方案。
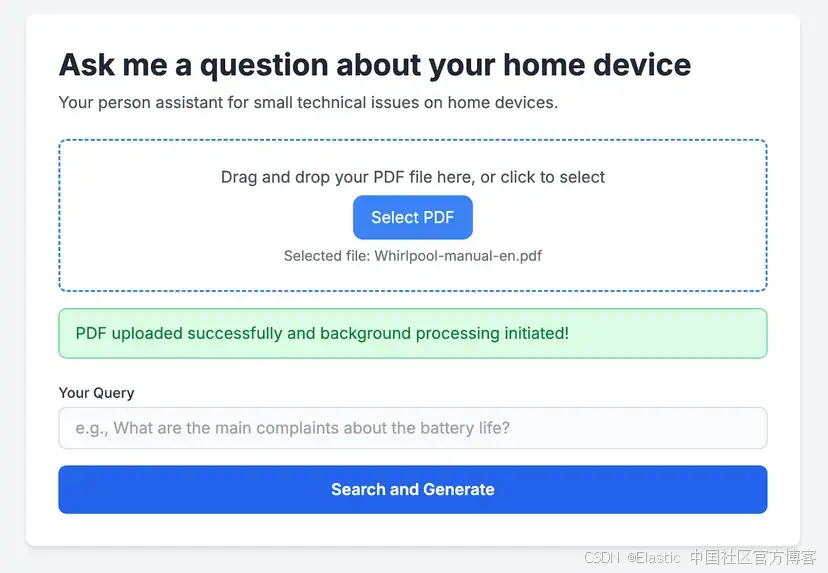
數據收集
如上所述,我們在 Elastic Cloud 部署上運行了一個 Elasticsearch 實例。Elasticsearch 集群請求受配置設置控制,包括 http:max_content_length。這個網絡 HTTP 設置會限制 HTTP 請求體的最大大小,默認值為 100MB,在 Elastic Cloud 中目前不可配置。
為了繞過這一限制來處理更大的文檔,我實現了一個簡單的 Python 函數,將提供的 PDF 拆分為單獨的頁面,并存儲在一個單獨的文件夾中。
下面是該函數的部分代碼示例:
def split_pdf(input_pdf_path, output_folder, filename_prefix=''):"""Splits a PDF file into individual pages and saves them to an output folder.Args:input_pdf_path (str): The full path to the input PDF file.output_folder (str): The directory where split pages will be saved.filename_prefix (str): A prefix to use for the output filenames (e.g., "manual_")."""logging.info(f"[{time.strftime('%H:%M:%S')}] Splitting PDF: {input_pdf_path}")try:# Open the PDF filewith open(input_pdf_path, 'rb') as file:pdf_reader = PdfReader(file)# Iterate through each pagefor page_num in range(len(pdf_reader.pages)):pdf_writer = PdfWriter()pdf_writer.add_page(pdf_reader.pages[page_num])# Generate the output file name# Uses the original filename (without extension) as part of the prefixoriginal_filename_base = os.path.splitext(os.path.basename(input_pdf_path))[0]output_filename = f'{filename_prefix}{original_filename_base}_pg_{page_num + 1}.pdf'output_path = os.path.join(output_folder, output_filename)# Save the page as a new PDFwith open(output_path, 'wb') as output_file:pdf_writer.write(output_file)logging.info(f'[{time.strftime("%H:%M:%S")}] Saved split page: {output_filename}')logging.info(f"[{time.strftime('%H:%M:%S')}] Finished splitting PDF: {input_pdf_path}")except Exception as e:logging.error(f"[{time.strftime('%H:%M:%S')}] Error during PDF splitting for {input_pdf_path}: {e}")為你的 PDF 內容創建嵌入
文本嵌入是指將文本(或其他數據類型)轉換為數值向量表示的過程 —— 具體來說,就是稠密向量。這是現代搜索和機器學習應用中的關鍵技術,特別適用于語義搜索、相似性搜索和生成式 AI。
Elastic 提供了多種依賴文本嵌入模型的方式:
-
內置模型:這些模型在 Elasticsearch 中即可使用,開箱即用并已預訓練,這意味著你不需要在自己的數據上進行微調,使它們能夠適應各種使用場景。例如,你可以使用:
-
ELSER:生成文本的稀疏向量表示,僅支持英文文檔。
-
E5:通過稠密向量表示實現多語言語義搜索。
-
-
導入 HuggingFace 模型:用戶可以從 HuggingFace 等平臺導入預訓練模型。這個過程依賴 Eland,它是一個 Python 客戶端,提供與 Pandas 兼容的 API,用于在 Elasticsearch 中進行數據探索和分析。
在本項目中,我們將上傳一個 HuggingFace 模型。你可以通過以下方式安裝 Eland:
python -m pip install eland現在,打開 Bash 編輯器并創建一個 .sh 腳本,正確填寫每個參數:
MODEL_ID="sentence-transformers/all-MiniLM-L6-v2"
CLOUD_URL='<<YOUR_CLOUD_URL>>'
ELASTIC_API_KEY='<<YOUR_API_KEY>>'
eland_import_hub_model \--url "$CLOUD_URL" \--es-api-key "$ELASTIC_API_KEY" \--hub-model-id "$MODEL_ID" \--insecure \--task-type text_embedding\--startMODEL_ID 指的是從 HuggingFace 獲取的模型。我們將使用 all-MiniLM-L6-v2,因為它體積小,可以輕松在 CPU 上運行,并且性能優異,尤其適合本次演示。
運行這個 Bash 腳本后,你的模型會出現在 Elastic 部署中的 Machine Learning -> Model Management -> Trained Models 下。

創建推理端點
從 8.11 版本開始,Elastic 已經普遍提供了推理 API 服務(inference API service)。該功能允許用戶創建推理端點,使用 Elastic 服務執行各種推理任務。
在本次演示中,我們將創建一個名為 minilm-l6 的端點,用來使用通過 Eland 上傳的模型。這個端點會傳遞與剛剛上傳模型對應的正確 model_id。
PUT _inference/text_embedding/minilm-l6
{"service": "elasticsearch","service_settings": {"num_allocations": 1,"num_threads": 1,"model_id": "sentence-transformers__all-minilm-l6-v2" }
}創建存儲 PDF 內容的索引
接下來,我們將創建一個索引,并使用默認映射,其中包含 semantic_text 字段。此設置需要你指定之前創建的端點 ID。該端點定義了在攝取過程中為 body 字段內容生成嵌入的推理服務。
作為背景說明,semantic_text 是在 Elasticsearch 8.15 中引入的,它簡化了語義搜索。若要深入了解我們的方法,建議查看我們的原始博客文章和 Elasticsearch 文檔。
PUT pdf-documentation-reader
{"mappings": {"properties": {"body": {"type": "semantic_text","inference_id": "minilm-l6"}}}
}設置 completion 端點
在生成主要組件后,一個關鍵步驟是創建 Elasticsearch 中的推理完成端點(inference completion endpoint)。該端點可以通過生成提示與所選的 Large Language Model (LLM) 進行交互,并提供必要的認證密鑰。
具體來說,你將使用名為 completion 的 completion 任務類型(更多細節請參考 Elasticsearch 文檔)。
PUT _inference/completion/openai_chat_completions
{"service": "openai","service_settings": {"api_key": "<<Your API KEY>>","model_id": "<<Chosen Model>>","url": "<<Your Service URL>>"}
}創建完成后,你可以通過發送一個簡單問題來測試 LLM 集成,如下面的示例所示。
POST _inference/completion/openai_chat_completions
{"input": "When Elasticsearch was created ?"
}輸出:
{"completion": [{"result": "**Elasticsearch** was first released in **2010**. It was created by Shay Banon, who began working on the project in 2009, and released the first version (0.4) in February **2010**. Elasticsearch is a distributed, open-source search and analytics engine built on top of Apache Lucene."}]
}搜索你的數據
當用戶通過界面提交查詢時,它會在現有內容中啟動語義搜索,以識別相關的 PDF 段落。與用戶輸入語義相似的段落隨后會被整合到提示中,由 LLM 生成最終答案。語義查詢使用之前介紹的 semantic_text 字段來簡化處理。
"query": {"semantic": {"field": "body","query": "How long does the ECO program last ?"}}雖然我們的示例提供了一個簡化的方法,但關于查詢 semantic_text 字段的更多細節可以在這里找到。對于需要增強相關性和精確度的高級應用,可以實現一種混合搜索方法,將經典詞匯搜索(BM25)與語義搜索結合起來。
整合所有內容:基于 Elasticsearch 的家電手冊 RAG 應用
構建故障排查應用的最后一步是將文檔檢索過程與 LLM 無縫集成,以提供智能、具上下文感知的響應。
下圖的系統概覽展示了各個組件的交互,并對所涉及的步驟進行了高層次的回顧。
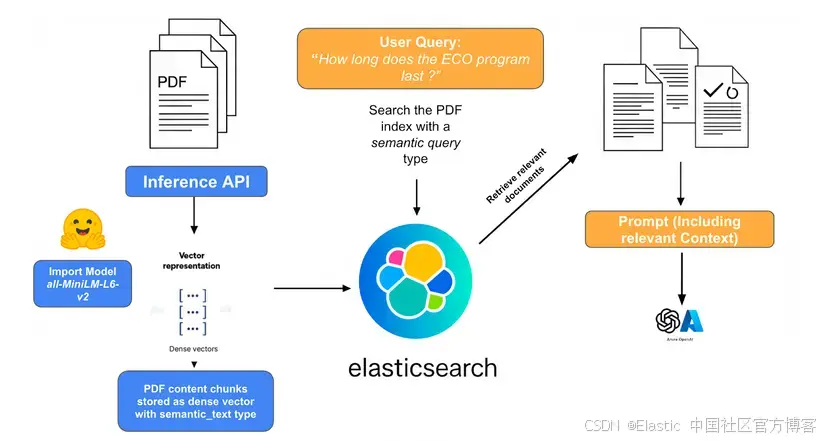
1)PDF 攝取、嵌入與存儲:
- 該過程從原始 PDF 家電手冊開始,這些手冊包含大量文本、圖像和復雜布局。每個 PDF 手冊被拆分為單獨的頁面,然后將每頁提取的文本攝取到 Elasticsearch 中。使用解析庫提取文本內容和元數據(如型號、制造商和文檔類型),并識別關鍵章節或圖表。
- 從每頁 PDF 提取的文本被仔細劃分為較小的、語義連貫的 “塊”。這些塊作為 dense_vectors 存儲在 Elasticsearch 索引中,利用 semantic_text 字段類型,并依賴為 text_embedding 任務創建的 inference_endpoint。
2)用戶查詢與上下文檢索:
當用戶提出故障排查問題(例如,“How long does the ECO Program last?”)時,這作為起點。用戶的查詢使用與攝取的文檔塊相同的嵌入模型轉換為稠密向量嵌入。這確保查詢向量與文檔塊向量處于相同語義空間,從而允許進行有意義的相似性比較。然后使用嵌入的用戶查詢在 Elasticsearch 文檔存儲中執行相似性搜索。這些文檔塊最可能包含回答問題所需的相關信息。
3)提示構建與 LLM 輸入:
- 上下文化:檢索到的文檔塊(原始文本)被動態插入到一個構建好的提示中,該提示將發送給 LLM。提示通常包括:
-
LLM 的指令:關于如何使用提供的信息、期望的輸出格式以及任何約束的明確指南。
-
用戶的原始查詢:用戶實際提出的問題。
-
檢索到的上下文:最相關塊的文本內容,通常明確標注為 “Context” 或 “Relevant Documents”。
-
- 示例提示結構:
You are an expert appliance troubleshooter. Using *only* the following context, answer the user's question. If the information is not in the context, state that you cannot answer based on the provided information.**Context:**
[Retrieved Chunk 1 Text]
[Retrieved Chunk 2 Text]
[Retrieved Chunk 3 Text]
...**User Question:** [User's Original Query]4)LLM 生成:
- 答案綜合:完整構建的提示,包括用戶查詢和相關檢索到的上下文,然后發送給 LLM。LLM 處理該輸入,并基于提供的信息生成連貫、上下文準確且類人化的響應。它綜合檢索到的文檔塊中的信息,為用戶的問題提供直接答案。
以下是對我們之前問題 How long does the ECO program last?” 的輸出示例:
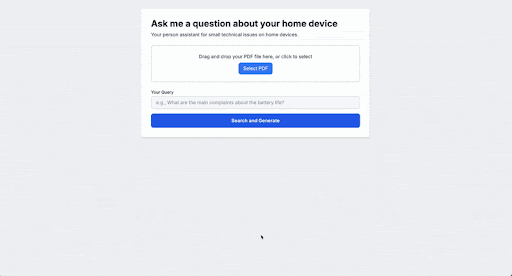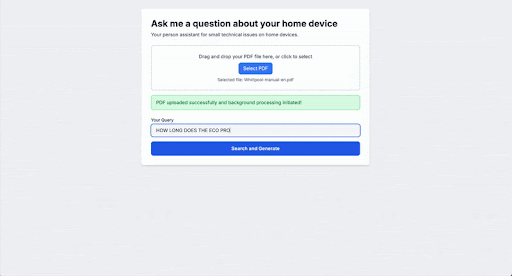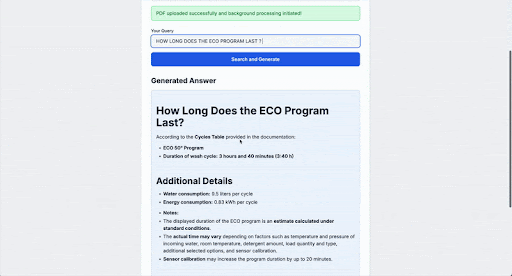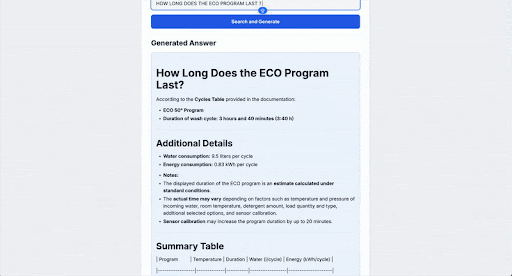
結論
在本文中,我們演示了如何利用 Elasticsearch 構建 RAG 應用,通過使用 semantic_text 映射等功能。這簡化了數據攝取過程,使你可以輕松開始使用語義搜索,同時提供合理的默認設置。它還讓你專注于搜索,而不必擔心如何索引、生成或查詢嵌入。
此外,我們還展示了如何利用最新的 inference_API,它簡化了在數據上使用機器學習模型的過程。例如,你可以用它執行推理操作(如為語義搜索生成嵌入),并將其與 LLM 集成進行提示回答。
希望這個應用也能幫助你解決技術問題,而不必額外花錢請技術人員上門。
在本文中,我們可能使用了第三方生成式 AI 工具,這些工具由各自的所有者擁有和運營。Elastic 對這些第三方工具沒有控制權,也不對其內容、操作或使用承擔任何責任,也不對你使用這些工具可能產生的任何損失或損害負責。在使用 AI 工具處理個人、敏感或機密信息時,請謹慎操作。你提交的任何數據可能會被用于 AI 訓練或其他用途。無法保證你提供的信息會被安全或保密地保存。使用前,你應熟悉任何生成式 AI 工具的隱私政策和使用條款。
原文:Turbocharge your troubleshooting: Building a RAG application for appliance manuals with Elasticsearch - Elasticsearch Labs


 一棵 AVL 樹)


--------從混淆矩陣到分類報告全面解析?)













