一、摘要
https://arxiv.org/pdf/2508.10104
自監督學習有望消除對人工數據標注的需求,使模型能夠輕松擴展到大規模數據集和更大規模的架構。由于不針對特定任務或領域進行定制,這種訓練范式具有從各種來源學習視覺表示的潛力,能夠使用單一算法處理從自然圖像到航空圖像的廣泛數據。本技術報告介紹了DINOv3,這是通過利用簡單而有效的策略實現這一愿景的重要里程碑。首先,我們通過精心的數據準備、設計和優化,充分利用了擴展數據集和模型規模的優勢。其次,我們引入了一種名為Gram錨定(Gram anchoring)的新方法,有效解決了在長時間訓練過程中密集特征圖退化的已知但未解決的問題。最后,我們應用了事后策略,進一步增強了模型在分辨率、模型大小和文本對齊方面的靈活性。因此,我們提出了一種多功能視覺基礎模型,在無需微調的情況下,在各種設置中超越了專業化的最先進模型。DINOv3生成高質量的密集特征,在各種視覺任務上取得了卓越的性能,顯著超越了先前的自監督和弱監督基礎模型。我們還分享了DINOv3視覺模型套件,旨在通過提供可擴展的解決方案來應對不同資源約束和部署場景,從而在廣泛的任務和數據上推進最先進技術。
二、引言
基礎模型已成為現代計算機視覺的核心構建模塊,通過單一可重用模型實現跨任務和領域的廣泛泛化。自監督學習(SSL)是一種訓練此類模型的強大方法,它直接從原始像素數據中學習,并利用圖像中模式的自然共現。與需要與高質量元數據配對的圖像的弱監督和全監督預訓練方法(Radford et al., 2021; Dehghani et al., 2023; Bolya et al., 2025)不同,SSL解鎖了在大規模原始圖像集合上的訓練。這尤其適用于訓練大規模視覺編碼器,這得益于幾乎無限的訓練數據可用性。DINOv2 (Oquab et al., 2024)體現了這些優勢,在圖像理解任務(Wang et al., 2025)中取得了令人印象深刻的成果,并為組織病理學等復雜領域(Chen et al., 2024)提供了預訓練支持。使用SSL訓練的模型展現出額外的理想特性:它們對輸入分布偏移具有魯棒性,提供強大的全局和局部特征,并生成有助于物理場景理解的豐富嵌入。由于SSL模型不是為任何特定下游任務訓練的,它們產生多功能且穩健的通用模型,需要針對特定任務進行微調,允許單個凍結的骨干網絡服務于多種用途。重要的是,自監督學習特別適合于訓練可用的大量觀測數據。
在組織病理學(Vorontsov et al., 2024)、生物學(Kim et al., 2025)、醫學成像(Pérez-Garcia et al., 2025)、遙感(Cong et al., 2022; Tolan et al., 2024)、天文學(Parker et al., 2024)或高能粒子物理(Dillon et al., 2022)等領域的應用中,這些領域通常缺乏元數據,并且已經證明可以從DINOv2等基礎模型中受益。最后,SSL不需要人工干預,非常適合在不斷增長的網絡數據中進行終身學習。
在實踐中,SSL的承諾——即通過利用大量無約束數據生成任意大而強大的模型——在大規模應用中仍然具有挑戰性。雖然Oquab等人(2024)提出的啟發式方法緩解了模型不穩定和崩潰的問題,但從進一步擴展中會出現更多問題。首先,如何從無標簽集合中收集有用數據尚不明確。其次,在通常的訓練實踐中,使用余弦調度意味著需要預先知道優化范圍,這在訓練大型圖像語料庫時很困難。第三,通過視覺檢查patch相似性圖可以確認,特征的性能在早期訓練后逐漸下降。這種現象出現在使用大于ViT-Large規模(300M參數)的模型進行長時間訓練時,降低了擴展DINOv2的實用性。
解決上述問題促成了這項工作——DINOv3,它推進了大規模SSL訓練。我們證明,單個凍結的SSL骨干網絡可以作為通用視覺編碼器,在具有挑戰性的下游任務上實現最先進的性能,超越監督和依賴元數據的預訓練策略。我們的研究由以下目標指導:(1)訓練一個跨任務和領域的多功能基礎模型;(2)改進現有SSL模型在密集特征方面的不足;(3)傳播可直接使用的模型家族。我們將在下文討論這三個目標。
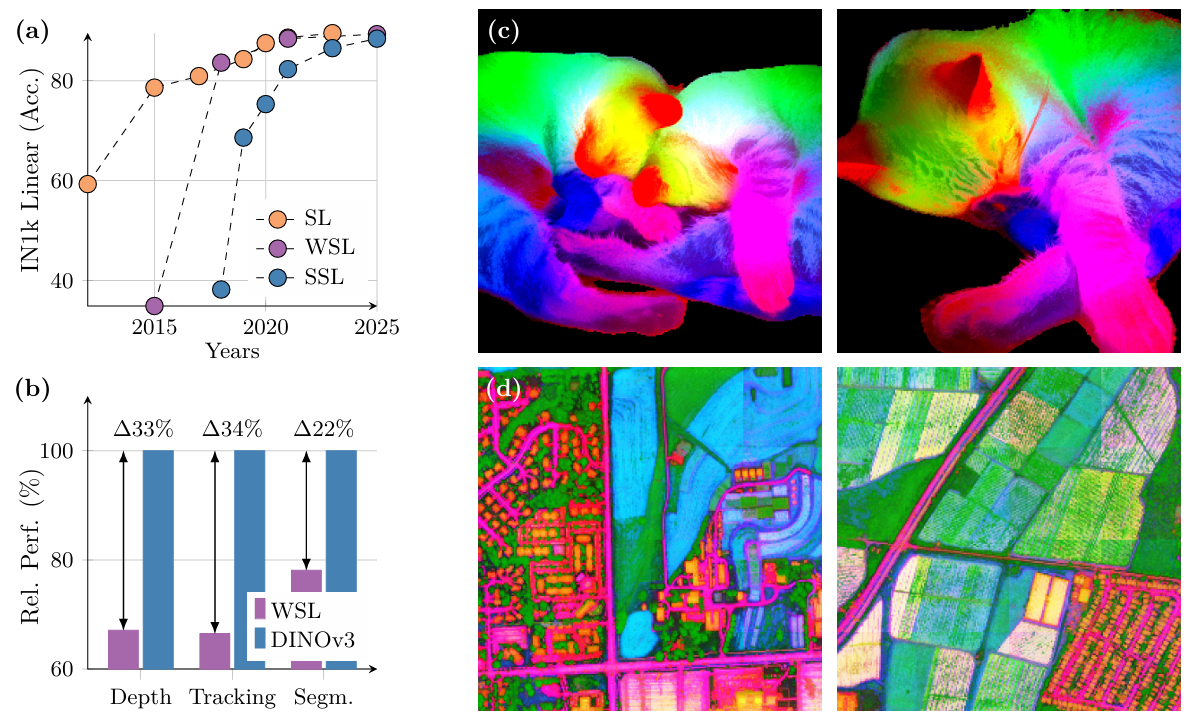
強大而多功能的基礎模型 ? DINOv3旨在在兩個方面提供高水平的多功能性,這是通過擴展模型規模和訓練數據實現的。首先,SSL模型的一個關鍵理想特性是在保持凍結狀態下實現卓越性能,理想情況下達到與專用模型相似的最先進結果。在這種情況下,單次前向傳遞可以提供跨多個任務的尖端結果,導致顯著的計算節省——這對于實際應用,特別是在邊緣設備上,是一個重要優勢。我們在第6節中展示了DINOv3可以成功應用于廣泛的任務。其次,不依賴元數據的可擴展SSL訓練流程解鎖了眾多科學應用。通過在各種圖像上進行預訓練,無論是網絡圖像還是觀測數據,SSL模型都能在大量領域和任務中泛化。如圖1(d)所示,從高分辨率航空圖像中提取的DINOv3特征的PCA清晰地區分了道路、房屋和綠地,突顯了模型的特征質量。
通過Gram錨定實現的卓越特征圖 ? DINOv3的另一個關鍵特性是其密集特征圖的顯著改進。DINOv3 SSL訓練策略旨在生成在高級語義任務上表現出色的模型,同時生成適合解決深度估計或3D匹配等幾何任務的優秀特征圖。特別是,這些模型應生成可直接使用或只需少量后處理的密集特征。在使用大量圖像訓練時,密集表示和全局表示之間的權衡特別難以優化,因為高級理解的目標可能與密集特征圖的質量相沖突。這些矛盾的目標導致大型模型和長時間訓練計劃中密集特征的崩潰。我們的新Gram錨定策略有效緩解了這種崩潰(見第4節)。因此,DINOv3獲得了比DINOv2顯著更好的密集特征圖,即使在高分辨率下也能保持清晰(見圖3)。
DINOv3模型家族 ? 通過Gram錨定解決密集特征圖退化問題,釋放了擴展的潛力。因此,使用SSL訓練更大規模的模型帶來了顯著的性能提升。在這項工作中,我們成功訓練了一個具有7B7B7B參數的DINO模型。由于如此大規模的模型需要大量資源才能運行,我們應用蒸餾將其知識壓縮到更小的變體中。因此,我們提出了DINOv3視覺模型家族,這是一套旨在解決廣泛計算機視覺挑戰的綜合套件。該模型家族旨在通過提供可擴展的解決方案來適應不同的資源約束和部署場景,從而推進最先進技術。蒸餾過程產生了多種規模的模型變體,包括Vision Transformer (ViT) Small、Base和Large,以及基于ConvNeXt的架構。值得注意的是,高效且廣泛采用的ViT-L模型在各種任務上實現了接近原始7B7B7B教師模型的性能。總體而言,DINOv3家族在廣泛基準測試中表現出色,在全局任務上匹配或超過競爭模型的準確性,同時在密集預測任務上顯著超越它們,如圖2所示。

圖3: 高分辨率密集特征。我們可視化了使用DINOv3輸出特征在標記為紅色十字的patch與所有其他patch之間獲得的余弦相似度圖。輸入圖像為4096×40964096\times40964096×4096。請放大查看,您同意DINOv3的結果嗎?
貢獻概述 在這項工作中,我們引入了多項貢獻來應對將SSL擴展到大型前沿模型的挑戰。我們基于自動數據整理的最新進展(Vo et al., 2024),獲取了一個大型"背景"訓練數據集,并將其與少量專用數據(ImageNet-1k)進行精心混合。這允許利用大量無約束數據來提高模型性能。這一關于數據擴展的貢獻(i)將在第3.1節中描述。
我們通過定義ViT架構的自定義變體,將主模型規模增加到7B7B7B參數。我們包含了現代位置嵌入(axial RoPE)并開發了一種正則化技術來避免位置偽影。與DINOv2中的多個余弦調度不同,我們使用恒定的超參數調度進行1M1M1M次迭代訓練。這使得能夠生成性能更強的模型。這一關于模型架構和訓練的貢獻(ii)將在第3.2節中描述。
通過上述技術,我們能夠按比例訓練遵循DINOv2算法的模型。然而,如前所述,擴展會導致密集特征的退化。為了解決這個問題,我們提出了管道的核心改進——Gram錨定訓練階段。這清除了特征圖中的噪聲,產生了令人印象深刻的相似度圖,并大幅提高了參數化和非參數化密集任務的性能。這一關于Gram訓練的貢獻(iii)將在第4節中描述。
遵循先前的做法,我們管道的最后步驟包括高分辨率后訓練階段,以及將模型蒸餾成一系列不同規模的高性能模型。對于后者,我們開發了一種新穎的方法,無縫訓練多個學生模型,從我們的旗艦7B7B7B模型中生成整個蒸餾模型家族。
我們在對象檢測(COCO檢測,mAPmAPmAP 66.166.166.1)和圖像分割(ADE20k mIoUmIoUmIoU 63.063.063.0)等計算問題上實現了最先進的性能,超越了專門的微調管道。此外,我們在第8節中通過將DINOv3算法應用于衛星圖像,提供了我們方法在各領域通用性的證據,超越了所有先前的方法。
二、相關工作
自監督學習 ? 無需標注的自監督學習需要人工設計學習任務來提供訓練監督。自監督學習(SSL)的藝術和挑戰在于精心設計這些所謂的預訓練任務,以便為下游任務學習強大的表示。語言領域由于其離散性質,提供了設置此類任務的直接方法,這導致了許多成功的預訓練方法用于文本數據。示例包括詞嵌入(Mikolov et al., 2013; Bojanowski et al., 2017)、句子表示(Devlin et al., 2018; Liu et al., 2019),以及純語言模型(Mikolov et al., 2010; Zaremba et al., 2014)。相比之下,由于信號的連續性質,計算機視覺提出了更大的挑戰。早期嘗試模仿語言方法,從圖像部分提取監督信號來預測其他部分,例如預測相對patch位置(Doersch et al., 2015)、patch重排序(Noroozi and Favaro, 2016; Misra and Maaten, 2020)或圖像修復(Patchak et al., 2016)。其他任務包括重新著色圖像(Zhang et al., 2016)或預測圖像變換(Gidaris et al., 2018)。
在這些任務中,基于圖像修復的方法由于基于patch的ViT架構的靈活性而引起了廣泛關注(He et al., 2021; Bao et al., 2021; El-Nouby et al., 2021)。該目標是重建圖像的損壞區域,可以看作是一種去噪自編碼,與BERT預訓練中的掩碼token預測任務(Devlin et al., 2018)在概念上相關。值得注意的是,He et al. (2021)證明了基于像素的掩碼自編碼器(MAE)可以用作下游任務微調的強初始化。隨后,Baevski et al. (2022; 2023)和Assran et al. (2023)表明,預測學習到的潛在空間而非像素空間可以導致更強大的高級特征,這種學習范式稱為JEPA:聯合嵌入預測架構’(LeCun, 2022)。最近,JEPAs也被擴展到視頻訓練(Bardes et al., 2024; Assran et al., 2025)。
第二類工作,與我們的工作更接近,利用圖像之間的判別信號來學習視覺表示。這類方法起源于早期的深度學習研究(Hadsell et al., 2006),但隨著實例分類技術的引入而流行起來(Dosovitskiy et al., 2016; Bojanowski and Joulin, 2017; Wu et al., 2018)。隨后的進展引入了對比目標和信息理論標準(Hénaff et al., 2019; He et al., 2020; Chen and He, 2020; Chen et al., 2020a; Grill et al., 2020; Bardes et al., 2021),以及基于自聚類的策略(Caron et al., 2018; Asano et al., 2020; Caron et al., 2020, 2021)。最近的方法,如iBOT (Zhou et al., 2021),將這些判別損失與掩碼重建目標結合起來。所有這些方法都展示了學習強特征并在ImageNet (Russakovsky et al., 2015)等標準基準上取得高性能的能力。然而,大多數方法在擴展到更大模型規模時面臨挑戰(Chen et al., 2021)。
視覺基礎模型 ? 深度學習革命始于AlexNet突破(Krizhevsky et al., 2012),這是一個在ImageNet挑戰賽上(Deng et al., 2009; Russakovsky et al., 2015)表現優于所有先前方法的深度卷積神經網絡。早在早期,在大型人工標注的ImageNet數據集上端到端學習的特征就被發現對廣泛的遷移學習任務高度有效(Oquab et al., 2014)。早期關于視覺基礎模型的工作隨后集中在架構開發上,包括VGG (Simonyan and Zisserman, 2015)、GoogleNet (Szegedy et al., 2015)和ResNets (He et al., 2016)。
鑒于擴展的有效性,后續工作探索了在大數據集上訓練更大的模型。Sun et al. (2017)通過包含3億標記圖像的專有JFT數據集擴展了監督訓練數據,取得了令人印象深刻的結果。JFT也為Kolesnikov et al. (2020)帶來了顯著的性能提升。同時,也探索了使用監督和無監督數據組合進行擴展。例如,ImageNet監督模型可用于為無監督數據生成偽標簽,然后用于訓練更大的網絡(Yalniz et al., 2019)。隨后,諸如JFT等大型監督數據集的可用性也促進了Transformer架構在計算機視覺中的應用(Dosovitskiy et al., 2020)。特別是,沒有JFT訪問權限的情況下達到與原始視覺Transformer (ViT)相當的性能需要大量努力(Touvron et al., 2020, 2022)。由于ViT的學習能力,Zhai et al. (2022a)進一步擴展了擴展工作,最終形成了非常大的ViT-22B編碼器(Dehghani et al., 2023)。
鑒于手動標注大型數據集的復雜性,弱監督訓練——其中標注是從與圖像關聯的元數據中派生的——為監督訓練提供了一種有效的替代方案。早在Joulin et al. (2016)就證明,網絡可以通過簡單地預測圖像標題中的所有單詞作為目標來進行預訓練。這一初始方法通過利用句子結構(Li et al., 2017)、結合其他類型的元數據和涉及整理(Mahajan et al., 2018),以及擴展(Singh et al., 2022)得到了進一步改進。然而,弱監督算法只有在引入對比損失和標題表示的聯合訓練后才達到其全部潛力,如Align (Jia et al., 2021)和CLIP (Radford et al., 2021)所示。
這一非常成功的方法啟發了許多開源復現和擴展工作。OpenCLIP (Cherti et al., 2023)是第一個通過在LAION數據集(Schuhmann et al., 2021)上訓練來復制CLIP的開源工作;后續工作通過以CLIP風格微調預訓練骨干網絡來利用它們(Sun et al., 2023, 2024)。認識到數據收集是CLIP訓練成功的關鍵因素,MetaCLIP (Xu et al., 2024)精確遵循原始CLIP流程以重現其結果,而Fang et al. (2024a)使用監督數據集來整理預訓練數據。其他工作專注于改進訓練損失,例如在SigLIP中使用sigmoid損失(Zhai et al., 2023),或利用預訓練的圖像編碼器(Zhai et al., 2022b)。然而,獲得尖端基礎模型最關鍵的要素是豐富的高質量數據和大量的計算資源。在這方面,SigLIP 2 (Tschannen et al., 2025)和感知編碼器(PE) (Bolya et al., 2025)在訓練超過400億圖像-文本對后取得了令人印象深刻的結果。最大的PE模型在860億樣本上訓練,全局批次大小為131K。最后,提出了各種更復雜且原生多模態的方法;這些包括對比字幕(Yu et al., 2022)、潛在空間中的掩碼建模(Bao et al., 2021; Wang et al., 2022b; Fang et al., 2023; Wang et al., 2023a)和自回歸訓練(Fini et al., 2024)。
相比之下,關于擴展無監督圖像預訓練的工作相對較少。早期努力包括Caron et al. (2019)和Goyal et al. (2019)利用YFCC數據集(Thomee et al., 2016)。通過關注更大的數據集和模型(Goyal et al., 2021, 2022a),以及SSL數據整理的初步嘗試(Tian et al., 2021),取得了進一步進展。仔細調整訓練算法、更大的架構和更廣泛的訓練數據導致了fDINOv2 (Oquab et al., 2024)的出色結果;首次,SSL模型在一系列任務上匹配或超過了開源CLIP變體。Fan et al. (2025)通過在沒有數據整理的情況下擴展到更大模型,或Venkataramanan et al. (2025)使用開放數據集和改進的訓練流程,進一步推動了這一方向。
密集Transformer特征 ? 現代視覺應用的廣泛范圍消耗了預訓練Transformer的密集特征,包括多模態模型(Liu et al., 2023; Beyer et al., 2024)、生成模型(Yu et al., 2025; Yao et al., 2025)、3D理解(Wang et al., 2025)、視頻理解(Lin et al., 2023a; Wang et al., 2024b)和機器人技術(Driess et al., 2023; Kim et al., 2024)。除此之外,檢測、分割或深度估計等傳統視覺任務需要準確的局部描述符。為了增強SSL訓練的局部描述符質量,大量工作致力于開發局部SSL損失。示例包括利用視頻中的時空一致性,例如使用點跟蹤循環作為訓練信號(Jabri et al., 2020),利用同一圖像不同裁剪之間的空間對齊(Pinheiro et al., 2020; Bardes et al., 2022),或強制相鄰patch之間的一致性(Yun et al., 2022)。Darcet et al. (2025)表明,預測聚類的局部patch可以改進密集表示。DetCon (Hénaff et al., 2021)和ORL (Xie et al., 2021)對區域提議執行對比學習,但假設存在此類提議,而ODIN (Hénaff et al., 2022)和SlotCon (Wen et al., 2022)等方法放寬了這一假設。
不改變訓練目標,Darcet et al. (2024)表明,在輸入序列中添加register tokens可以大大改善密集特征圖,最近的工作發現這可以在不進行模型訓練的情況下完成(Jiang et al., 2025; Chen et al., 2025)。
最近的趨勢是基于蒸餾的"聚合"方法,結合了使用不同級別監督訓練的具有不同全局和局部特征質量的多個圖像編碼器的信息(Ranzinger et al., 2024; Bolya et al., 2025):AM-RADIO (Ranzinger et al., 2024)將全監督SAM (Kirillov et al., 2023)、弱監督CLIP和自監督DINOv2的優勢結合到一個統一的骨干網絡中。感知編碼器(Bolya et al., 2025)類似地將SAM(v2)蒸餾成一個專門的密集變體,稱為PEspatial。他們使用一個目標,強制學生和教師patch之間的余弦相似度要高,其中他們的教師是使用掩碼注釋訓練的。類似損失在風格遷移背景下被證明是有效的,通過減少特征維度G cam矩陣之間的一致性(Gatys et al., 2016; Johnson et al., 2016; Yoo et al., 2024)。在本工作中,我們采用Gram目標來正則化學生和教師patch之間的余弦相似度,使它們彼此接近。在我們的情況下,我們使用ISS模型本身的早期迭代作為教師,證明早期階段的SSL模型有效地指導了全局和密集任務的SSL訓練。
其他工作專注于對SSL訓練模型的局部特征進行事后改進。例如,Ziegler and Asano (2022)通過密集聚類目標微調預訓練模型;類似地,Salehi et al. (2023)通過在時間上對齊patch特征進行微調,這兩種方法都提高了局部特征的質量。與我們更接近的是,Pariza et al. (2025)提出了一種基于patch排序的目標,以鼓勵學生和教師生成具有相同鄰居順序的特征。無需微調,STEGO (Hamilton et al., 2022)在凍結的SSL特征之上學習非線性投影,以形成緊湊的聚類并放大相關模式。或者,Simoncini et al. (2024)通過將不同自監督目標的梯度連接到凍結的SSL特征來增強自監督特征。最近,Wysoczanska et al. (2024)表明,通過patch的加權平均可以顯著改善噪聲特征圖。
相關但不特定于SSL的一些最近工作從ViT特征圖生成高分辨率特征圖(Fu et al., 2024),這些特征圖由于圖像的patch化而通常分辨率較低。與這項工作相比,我們的模型原生提供高質量的密集特征圖,這些特征圖在不同分辨率下保持穩定和一致,如圖4所示。
DINOv3是一個下一代模型,旨在通過推動自監督學習的邊界,產生迄今為止最強大且靈活的視覺表示。我們從大型語言模型(LLM)的成功中汲取靈感,在LLM中,擴大模型容量會帶來出色的涌現特性。通過利用規模大一個數量級的模型和訓練數據集,我們尋求釋放ISS的全部潛力,并為計算機視覺帶來類似的范式轉變,不受傳統監督或特定任務方法局限性的束縛。特別是,SSL產生豐富、高質量的視覺特征,這些特征不會偏向任何特定的監督或任務,從而為廣泛的下游應用提供了多功能的基礎。雖然之前嘗試擴展SSL模型受到不穩定性問題的阻礙,但本節描述了我們如何通過仔細的數據準備、設計和優化來利用擴展的好處。我們首先描述數據集創建過程(第3.1節),然后介紹用于DINOv3第一訓練階段的自監督SSL配方(第3.2節)。這包括架構、損失函數和優化技術的選擇。第二訓練階段,專注于密集特征,將在第4節中描述。
3.1 數據準備
數據擴展是大型基礎模型成功的關鍵因素之一(Touvron et al., 2023; Radford et al., 2021; Xu et al., 2024; Oquab et al., 2024)。然而,簡單地增加訓練數據的規模并不一定轉化為更高的模型質量和下游基準測試的更好性能(Goyal et al., 2021; Oquab et al., 2024; Vo et al., 2024):成功的數據擴展工作通常涉及仔細的數據整理管道。這些算法可能有不同的目標:要么專注于提高數據多樣性和平衡性,要么關注數據有用性——即數據對常見實際應用的相關性。對于DINOv3的開發,我們結合了兩種互補的方法來提高模型的泛化能力和性能,在兩個目標之間取得平衡。
數據收集與整理 ? 我們通過利用從Instagram公共帖子收集的大型網絡圖像數據池來構建大規模預訓練數據集。這些圖像已經通過平臺級內容審核,以幫助防止有害內容,我們獲得了一個約170億圖像的初始數據池。使用這個原始數據池,我們創建了三個數據集部分。我們通過應用Vo et al. (2024)提出的基于分層k-means的自動整理方法構建第一部分。我們使用DINOv2作為圖像嵌入,并使用5級聚類,從最低到最高級別的聚類數量分別為2億、800萬、80萬、10萬和2.5萬。在構建聚類層次結構后,應用Vo et al. (2024)提出的平衡采樣算法。這產生了一個包含16.89億圖像的整理子集(命名為LVD-1689M),確保了網絡中出現的所有視覺概念的平衡覆蓋。對于第二部分,我們采用類似于Oquab et al. (2024)提出的基于檢索的整理系統。我們從數據池中檢索與選定種子數據集中的圖像相似的圖像,創建一個涵蓋與下游任務相關的視覺概念的數據集。對于第三部分,我們使用原始的公開可用計算機視覺數據集,包括ImageNet1k (Deng et al., 2009)、ImageNet22k (Russakovsky et al., 2015)和Mapillary Street-level Sequences (Warburg et al., 2020)。最后一部分使我們能夠優化模型性能,遵循Oquab et al. (2024)的方法。
數據采樣? 在預訓練期間,我們使用采樣器將不同數據部分混合在一起。混合上述數據組件有幾種不同的選項。一種是在每次迭代中使用來自單個隨機選擇組件的同質批次數據進行訓練。或者,我們可以使用從所有組件中選擇的、使用特定比例組裝的異質批次來優化模型。受Charton and Kempe (2024)的啟發,他們觀察到擁有由小型數據集中高質量數據組成的同質批次是有益的,我們在每次迭代中隨機采樣:
表1:通過下游任務性能展示訓練數據對特征質量的影響。我們將使用聚類(Vo et al., 2024)和檢索(Oquab et al., 2024)整理的數據集與原始數據和我們的數據混合進行比較。此消融研究使用較短的20萬次迭代計劃進行。
| 數據集 | IN1k k-NN | IN1k Linear | ObjectNet | iNaturalist 2021 | Paris Retrieval |
|---|---|---|---|---|---|
| Raw | 80.1 | 84.8 | 70.3 | 70.1 | 63.3 |
| Clustering | 79.4 | 85.4 | 72.3 | 81.3 | 85.2 |
| Retrieval | 84.0 | 86.7 | 70.7 | 86.0 | 82.7 |
| LVD-1689M (ours) | 84.6 | 87.2 | 72.8 | 87.0 | 85.9 |
來自ImageNet1k的同質批次,或由所有其他組件數據混合而成的異質批次。在我們的訓練中,來自ImageNet1k的同質批次占訓練的10%。
數據消融 ? 為了評估我們的數據整理技術的影響,我們進行了一項消融研究,將我們的數據混合與單獨使用聚類或基于檢索的方法整理的數據集以及原始數據池進行比較。為此,我們在每個數據集上訓練一個模型,并比較它們在標準下游任務上的性能。為了提高效率,我們使用較短的20萬次迭代計劃而不是100萬次迭代。在表1中,可以看出沒有單一的整理技術在所有基準測試中表現最佳,而我們的完整管道使我們能夠獲得兩全其美的效果。
3.2 大規模自監督訓練
雖然用SSL訓練的模型已經展示了有趣的特性(Chen et al., 2020b; Caron et al., 2021),但大多數SSL算法尚未擴展到更大的模型規模。這要么是由于訓練穩定性問題(Darcet et al., 2025),要么是過于簡單的解決方案無法捕捉視覺世界的全部復雜性。當在大規模上訓練時(Goyal et al., 2022a),用SSL訓練的模型不一定表現出令人印象深刻的表現。一個顯著的例外是DINOv2,這是一個在整理數據上訓練的11億參數模型,其性能與CLIP等弱監督模型(Radford et al., 2021)相匹配。最近將DINOv2擴展到70億參數的努力(Fan et al., 2025)在全局任務上展示了有希望的結果,但在密集預測上結果令人失望。在這里,我們的目標是擴大模型和數據規模,并獲得具有改進的全局和局部屬性的更強大的視覺表示。
學習目標 我們使用判別性自監督策略訓練模型,該策略是具有全局和局部損失項的幾種自監督目標的混合。遵循DINOv2 (Oquab et al., 2024),我們使用圖像級目標(Caron et al., 2021) LDINO\mathcal{L}_{\mathrm{DINO}}LDINO?,并將其與patch級潛在重建目標(Zhou et al., 2021) LiBOT\mathcal{L}_{\mathrm{iBOT}}LiBOT? 平衡。我們還用SwAV (Caron et al., 2020)中的Sinkhorn-Knopp替換了DINO中的中心化方法,應用于兩個目標。每個目標使用骨干網絡頂部專用頭的輸出計算,允許在計算損失之前對特征進行一些專業化。此外,我們對局部和全局裁剪的骨干網絡輸出應用了專用的層歸一化。從經驗上,我們發現這種變化穩定了訓練后期的ImageNet kNN分類(+0.2準確率)并提高了密集性能(+0.2,例如ADE20k分割上+1 mIoU,NYUv2深度估計上-0.02 RMSE)。此外,添加了一個Koleo正則化器 LKoleo\mathcal{L}_{\mathrm{Koleo}}LKoleo?,以鼓勵批次內的特征在空間中均勻分布(Sablayrolles et al., 2018)。我們使用:
LPre=LDINO+LiBOT+0.1?LDKoleo\mathcal{L}_{\mathrm{Pre}}=\mathcal{L}_{\mathrm{DINO}}+\mathcal{L}_{\mathrm{iBOT}}+0.1*\mathcal{L}_{\mathrm{DKoleo}}LPre?=LDINO?+LiBOT?+0.1?LDKoleo?
我們的初始訓練階段通過優化以下損失進行。
更新的模型架構 ? 對于這項工作的模型擴展方面,我們將模型大小增加到70億參數,并在表2中提供了與DINOv2工作中訓練的11億參數模型相應的超參數比較。我們還采用RoPE的自定義變體:我們的基本實現為每個patch分配歸一化的[?1,1][-1,1][?1,1]框中的坐標,然后根據兩個patch的相對位置在多頭注意力操作中應用偏置。為了提高模型對分辨率、比例和縱橫比的魯棒性,我們采用RoPE-box抖動。坐標框[?1,1][-1,1][?1,1]被隨機縮放到[?s,s][-s,s][?s,s],其中s∈[0.5,2]s\in[0.5,2]s∈[0.5,2]。這些變化共同使DINOv3能夠更好地學習詳細和魯棒的視覺特征,提高其性能和可擴展性。
優化 ?在非常大的數據集上訓練大型模型代表了一個復雜的實驗工作流程。由于模型容量和訓練數據復雜性之間的相互作用很難先驗評估,因此不可能猜測正確的優化范圍。為了克服這一點,我們摒棄了所有參數調度,使用恒定的學習率、權重衰減和教師EMA動量進行訓練。這有兩個主要好處。首先,只要下游性能繼續改善,我們就可以繼續訓練。其次,優化超參數的數量減少,使其更容易正確選擇它們。為了讓訓練正常開始,我們仍然對學習率和教師溫度使用線性預熱。遵循常見做法,我們使用AdamW (Loshchilov and Hutter, 2017),并將總批次大小設置為4096張圖像,分布在256個GPU上。我們使用多裁剪策略(Caron et al., 2020),每張圖像取2個全局裁剪和8個局部裁剪來訓練我們的模型。我們對全局/局部裁剪使用邊長為256/112像素的方形圖像,這與改變patch大小一起,導致每張圖像的有效序列長度與DINOv2相同,每批次總序列長度為370萬tokens。其他超參數可以在附錄C和代碼發布中找到。
表2:比較DINOv2和DINOv3模型中使用的教師架構。我們將模型保持40層深,并將嵌入維度增加到4096。重要的是,我們使用16像素的patch大小,改變給定分辨率的有效序列長度。
| 教師模型 | DINOv2 | DINOv3 |
|---|---|---|
| 骨干網絡 | ViT-giant | ViT-7B |
| #參數 | 1.1B | 6.7B |
| #塊 | 40 | 40 |
| patch大小 | 14 | 16 |
| 位置嵌入 | 可學習 | RoPE |
| 注冊 | 4 | 4 |
| 嵌入維度 | 1536 | 4096 |
| FFN類型 | SwiGLU | SwiGLU |
| FFN隱藏維度 | 4096 | 8192 |
| 注意力頭 | 24 | 32 |
| 注意力頭維度 | 64 | 128 |
| DINO頭MLP | 4096-4096-256 | 8192-8192-512 |
| DINO原型 | 128k | 256k |
| iBOT頭MLP | 4096-4096-256 | 8192-8192-384 |
| iBOT原型 | 128k | 96k |
四、Gram錨定:密集特征的正則化
為了充分利用大規模訓練的好處,我們的目標是長時間訓練70億參數模型,認為它可能無限期地訓練。正如預期的那樣,長時間訓練會導致全局基準測試的改進。然而,隨著訓練的進行,密集任務的性能會下降(圖5b和5c)。這種現象是由于特征表示中patch級不一致性的出現,削弱了長時間訓練的興趣。在本節中,我們首先分析patch級一致性的損失,然后提出一種新的目標來緩解它,稱為Gram錨定。最后,我們討論我們的方法對訓練穩定性和模型性能的影響。
4.1 訓練過程中patch級一致性的損失
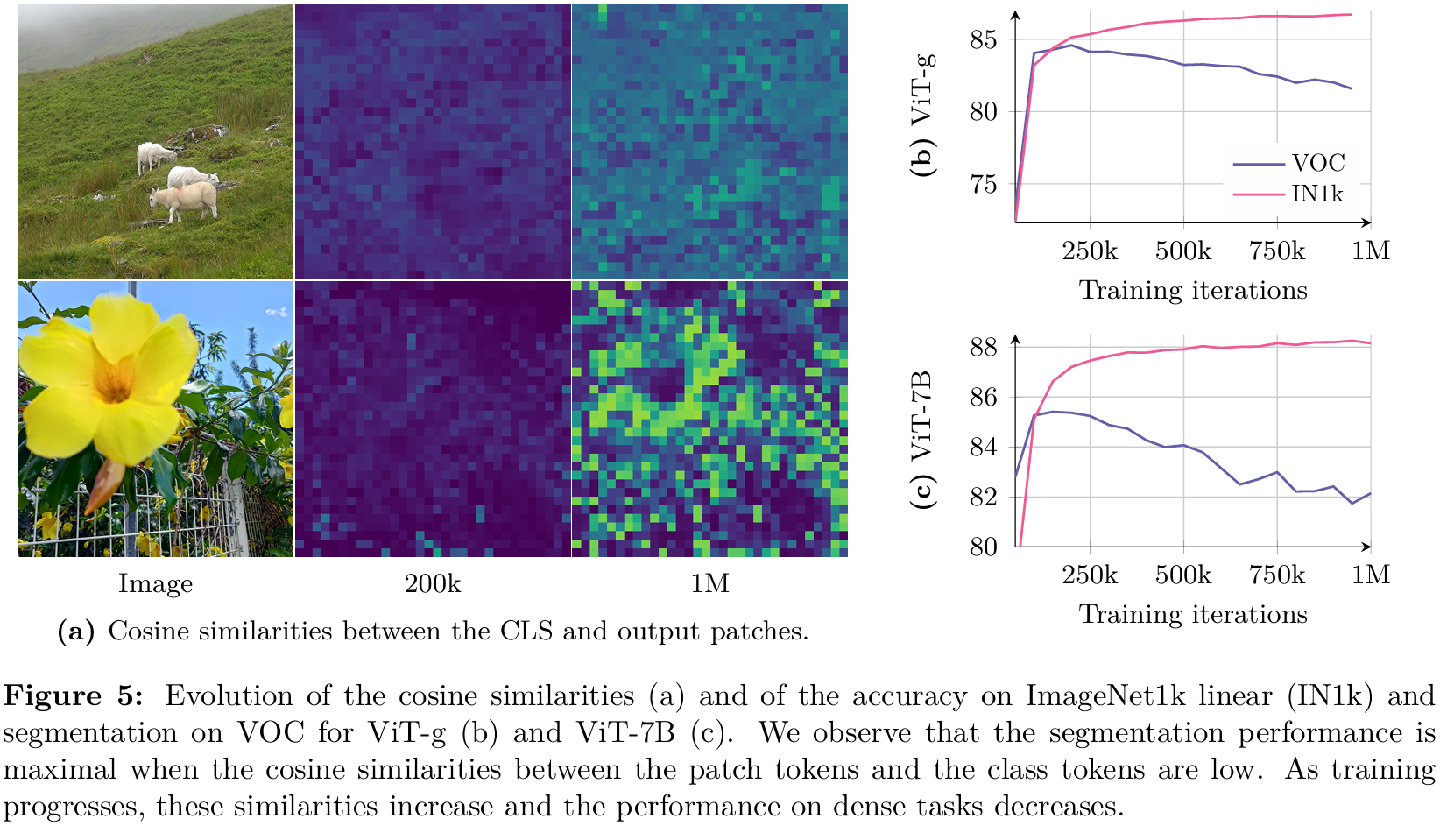
在長時間訓練期間,我們觀察到全局指標的一致改進,但在密集預測任務上的性能顯著下降。這種行為在DINOv2的訓練過程中曾被觀察到,盡管程度較輕,并在Fan et al. (2025)的擴展努力中也進行了討論。然而,據我們所知,它至今仍未解決。我們在圖5b和5c中說明了這一現象,展示了模型在圖像分類和分割任務上的迭代性能。對于分類,我們使用CLS token在ImageNet-1k上訓練線性分類器并報告top-1準確率。對于分割,我們在從Pascal VOC提取的patch特征上訓練線性層并報告平均交并比(mIoU)。我們觀察到,對于ViT-g和ViT-7B,分類準確率在整個訓練過程中單調提高。然而,在大約20萬次迭代后,兩種情況下的分割性能都會下降,在ViT-7B的情況下,分割性能降至早期水平以下。
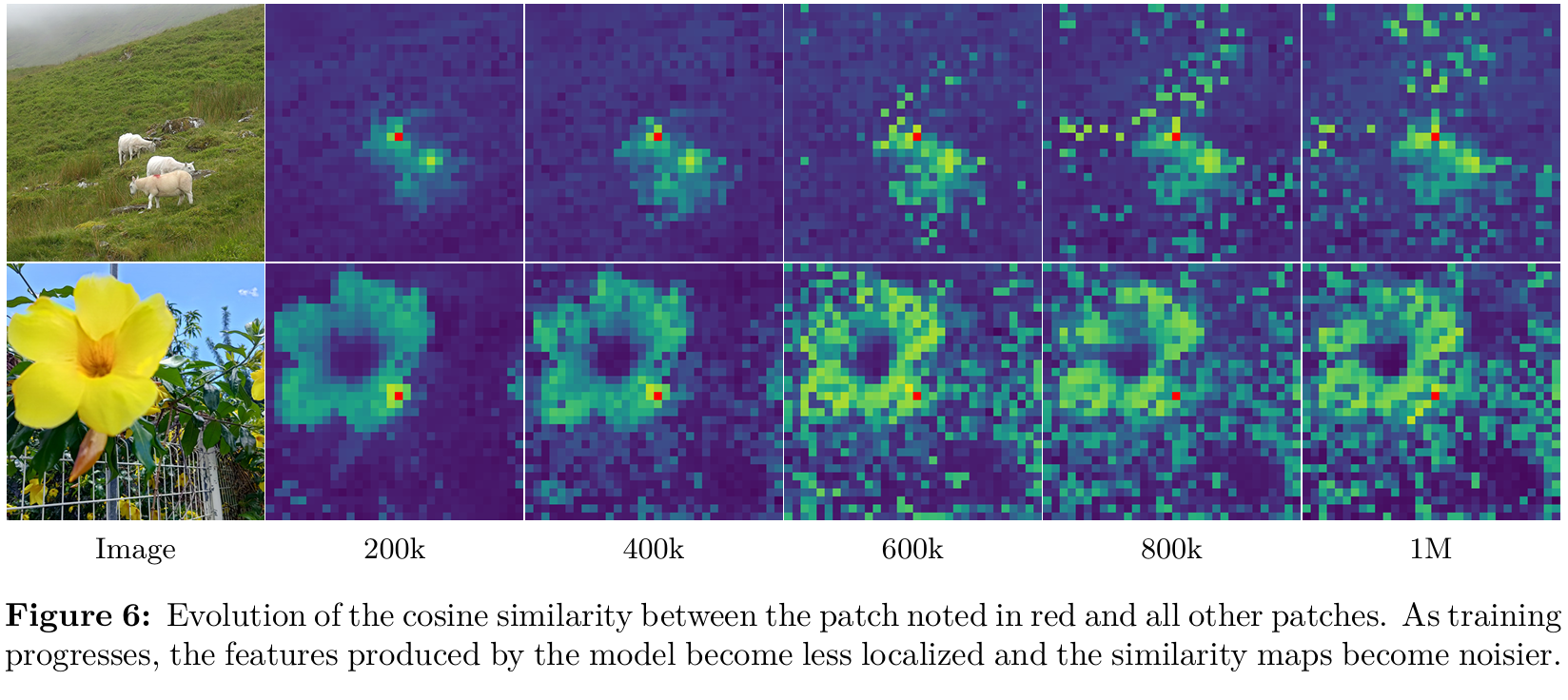
為了更好地理解這種退化,我們通過可視化patch之間的余弦相似性來分析patch特征的質量。圖6顯示了骨干網絡輸出patch特征與P參考patch(紅色突出顯示)之間的余弦相似性圖。在20萬次迭代時,相似性圖平滑且定位良好,表明patch級表示一致。然而,在60萬次迭代及以后,地圖大幅退化,與參考patch具有高相似性的不相關patch數量增加。這種patch級一致性的損失與密集任務性能的下降相關。
這些patch級不規則與Darcet et al. (2024)中描述的高范數patch異常值不同。具體來說,隨著register tokens的集成,patch范數在整個訓練過程中保持穩定。然而,我們注意到CLS token和patch輸出之間的余弦相似性在訓練過程中逐漸增加。這是預期的,但它意味著patch特征的局部性減弱。我們在圖5a中可視化了這一現象,該圖描繪了20萬次和100萬次迭代時的余弦圖。為了緩解密集任務上的下降,我們提出了一種新的目標,專門設計用于正則化patch特征并確保良好的patch級一致性,同時保持較高的全局性能。
4.2 Gram錨定目標
在我們的實驗中,我們確定了學習強判別特征和保持局部一致性之間的相對獨立性,這在全局和密集性能之間缺乏相關性中得到觀察。雖然將全局DINO損失與局部iBOT損失結合起來已經開始解決這個問題,但我們觀察到這種平衡是不穩定的,隨著訓練的進行,全局表示占據主導地位。基于這一見解,我們提出了一種利用這種獨立性的新解決方案。
我們引入了一個新的目標,通過強制patch級一致性的質量來緩解patch級一致性的退化,而不影響特征本身。這個新的損失函數作用于Gram矩陣:圖像中patch特征的所有成對點積的矩陣。我們希望將學生的Gram矩陣推向早期模型的Gram矩陣,稱為Gram教師。我們通過取教師網絡的早期迭代來選擇Gram教師,該教師表現出優越的密集特性。通過在Gram矩陣上操作而不是特征本身,局部特征可以自由移動,只要相似性結構保持不變。假設我們有一個由P個patch組成的圖像,并且一個在維度d上操作的網絡。讓我們用XS\mathbf{X}_SXS?(分別XG\mathbf{X}_GXG?)表示學生(分別Gram教師)的L2L2L2歸一化局部特征的P×dP\times dP×d矩陣。我們將損失LGram\mathcal{L}_{\mathrm{Gram}}LGram?定義如下:
LGram=∥XS?XS??XG?XG?∥F2.\mathcal{L}_{\mathrm{Gram}}=\left\|\mathbf{X}_{S}\cdot\mathbf{X}_{S}^{\top}-\mathbf{X}_{G}\cdot\mathbf{X}_{G}^{\top}\right\|_{\mathrm{F}}^{2}.LGram?=?XS??XS???XG??XG???F2?.
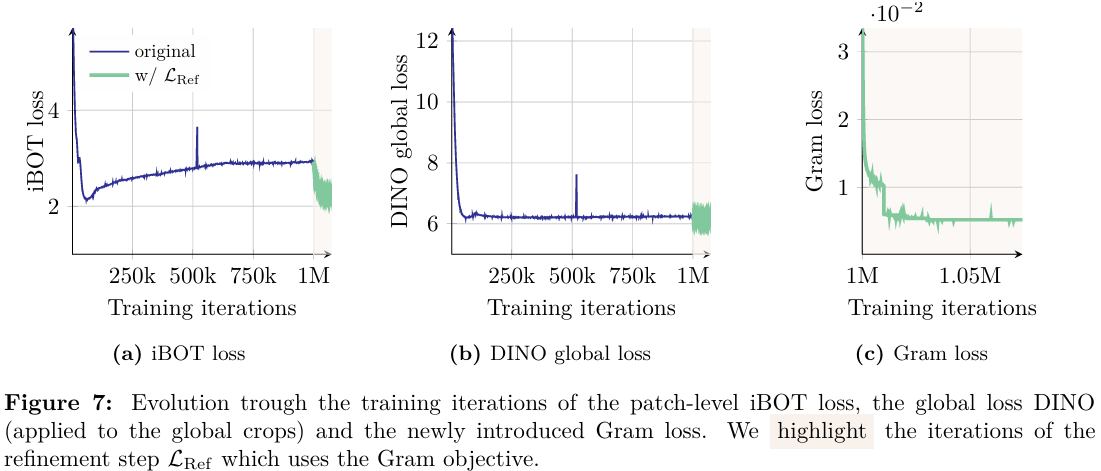
我們僅在全局裁剪上計算此損失。盡管可以在訓練早期應用它,但為了提高效率,我們只在100萬次迭代后開始應用。有趣的是,我們觀察到LGram\mathcal{L}_{\mathrm{Gram}}LGram?的后期應用仍然能夠"修復"非常退化的局部特征。為了進一步提高性能,我們每1萬次迭代更新一次Gram教師,此時Gram教師變得與主EMA教師相同。我們將訓練的這一第二階段稱為細化階段,它優化目標LRef\mathcal{L}_{\mathrm{Ref}}LRef?,其中:
LRef=wDLDINO+LiBOT+wDKLDKoleo+wGramLGram.\mathcal{L}_{\mathrm{Ref}}=w_{\mathrm{D}}\mathcal{L}_{\mathrm{DINO}}+\mathcal{L}_{\mathrm{iBOT}}+w_{\mathrm{DK}}\mathcal{L}_{\mathrm{DKoleo}}+w_{\mathrm{Gram}}\mathcal{L}_{\mathrm{Gram}}.LRef?=wD?LDINO?+LiBOT?+wDK?LDKoleo?+wGram?LGram?.
我們在圖7中可視化了不同損失的演變,并觀察到應用Gram目標顯著影響iBOT損失,導致它更快地下降。這表明穩定的Gram教師引入的穩定性對iBOT目標產生積極影響。相比之下,Gram目標對DINO損失沒有顯著影響。這一觀察表明Gram和iBOT目標以類似的方式影響特征,而DINO損失則以不同的方式影響它們。
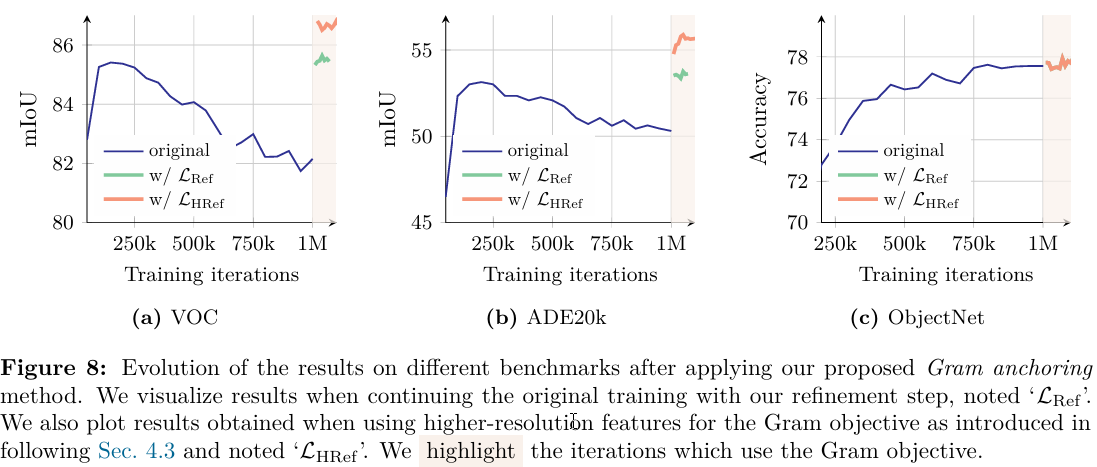
關于性能,我們觀察到新損失的影響幾乎是立竿見影的。如圖8所示,結合Gram錨定在最初的1萬次迭代內就導致密集任務上的顯著改進。我們還看到在Gram教師更新后ADE20k基準測試上的顯著增益。此外,更長時間的訓練進一步提高了ObjectNet基準測試的性能,其他全局基準測試顯示新損失的輕微影響。
4.3 利用更高分辨率的特征
最近的工作表明,patch特征的加權平均可以通過平滑異常patch并增強patch級一致性來產生更強的局部表示(Wysoczanska et al., 2024)。另一方面,將更高分辨率的圖像輸入骨干網絡會產生更精細、更詳細的特征圖。我們利用這兩種觀察的好處來為Gram教師計算高質量特征。具體來說,我們首先將分辨率是正常兩倍的圖像輸入Gram教師,然后使用雙三次插值對生成的特征圖進行2倍下采樣,以獲得與學生輸出大小匹配的所需平滑特征圖。圖9a可視化了以256和512分辨率以及512分辨率下采樣后(標記為’downsamp.')獲得的patch特征的Gram矩陣。我們觀察到更高分辨率特征中的優越patch級一致性通過下采樣得以保留,從而產生更平滑、更連貫的patch級表示。順便提一下,由于采用了Su et al. (2024)提出的旋轉位置嵌入(RoPE),我們的模型可以無縫處理不同分辨率的圖像,無需進行適應。
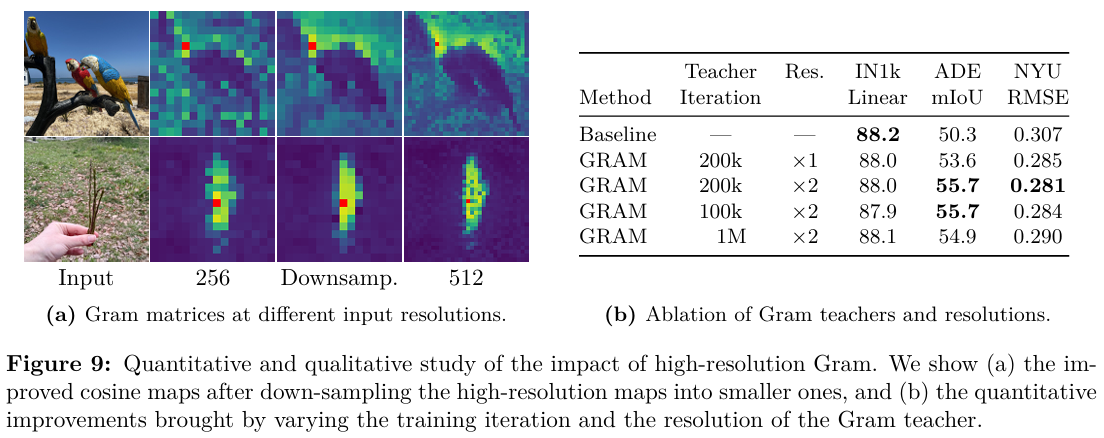
我們計算下采樣特征的Gram矩陣,并使用它替換目標LGram\mathcal{L}_{\mathrm{Gram}}LGram?中的XG\mathbf{X}_GXG?。我們將新的結果細化目標記為LHRef\mathcal{L}_{\mathrm{HRef}}LHRef?。這種方法使Gram目標能夠有效地將平滑高分辨率特征的改進patch一致性蒸餾到學生模型中。如圖8和圖9b所示,這種蒸餾轉化為密集任務上的更好預測,在LRef\mathcal{L}_{\mathrm{Ref}}LRef?帶來的好處之上獲得額外增益(ADE20k上+222 mIoU)。我們還在圖9b中對Gram教師的選擇進行了消融。有趣的是,選擇10萬或20萬次迭代的Gram教師對結果沒有顯著影響,但使用更晚的Gram教師(100萬次迭代)是有害的,因為該教師的patch級一致性較差。
最后,我們在圖10中定性地說明了Gram錨定對patch級一致性的影響,該圖可視化了初始訓練和高分辨率Gram錨定細化后獲得的patch特征的Gram矩陣。我們觀察到特征相關性的巨大改進,這是我們的高分辨率細化過程帶來的。
表:Gram教師和分辨率的消融
| 方法 | 教師迭代次數 | 分辨率 | IN1k線性 | ADE mIoU | NYU RMSE |
|---|---|---|---|---|---|
| 基線 | 88.2 | 50.3 | 0.307 | ||
| GRAM | 200k | ×1 | 88.0 | 53.6 | 0.285 |
| GRAM | 200k | ×2 | 88.0 | 55.7 | 0.281 |
| GRAM | 100k | ×2 | 87.9 | 55.7 | 0.284 |
| GRAM | 1M | ×2 | 88.1 | 54.9 | 0.290 |

圖10:Gram錨定的定性效果。我們可視化了使用細化目標LHRef\mathcal{L}_{\mathrm{HRef}}LHRef?前后的余弦圖。圖像的輸入分辨率為1024×10241024\times10241024×1024像素。
五、后訓練階段
本節介紹了后訓練階段。這包括使模型能夠在不同輸入分辨率下有效推斷的高分辨率適應階段(第5.1節)、產生高質量高效小型模型的模型蒸餾(第5.2節),以及為DINOv3添加零樣本能力的文本對齊(第5.3節)。
5.1 分辨率縮放
我們在相對較小的256分辨率下訓練模型,這在速度和效果之間提供了良好的權衡。對于16像素的patch大小,此設置導致與DINOv2相同的輸入序列長度,而DINOv2是使用224分辨率和14像素patch大小訓練的。然而,許多現代計算機視覺應用需要處理顯著更高分辨率的圖像,通常為512×512512\times512512×512像素或更大,以捕獲復雜的空間信息。推斷圖像分辨率在實踐中也不是固定的,而是根據特定用例而變化。為了解決這個問題,我們通過高分辨率適應步驟擴展了我們的訓練方案(Touvron et al., 2019)。為確保在各種分辨率下都有高性能,我們使用混合分辨率,在每個小批次中采樣不同大小的全局和局部裁剪對。具體來說,我們考慮全局裁剪大小為{512,768}\{512,768\}{512,768},局部裁剪大小為{112,168,224,336}\{112,168,224,336\}{112,168,224,336},并額外訓練10k10k10k次迭代。
與主要訓練類似,此高分辨率適應階段的一個關鍵組成部分是添加Gram錨定,使用7B教師作為Gram教師。我們發現此組件至關重要:沒有它,模型在密集預測任務上的性能會顯著下降。Gram錨定鼓勵模型在空間位置之間保持一致和穩健的特征相關性,這在處理高分辨率輸入的增加復雜性時至關重要。
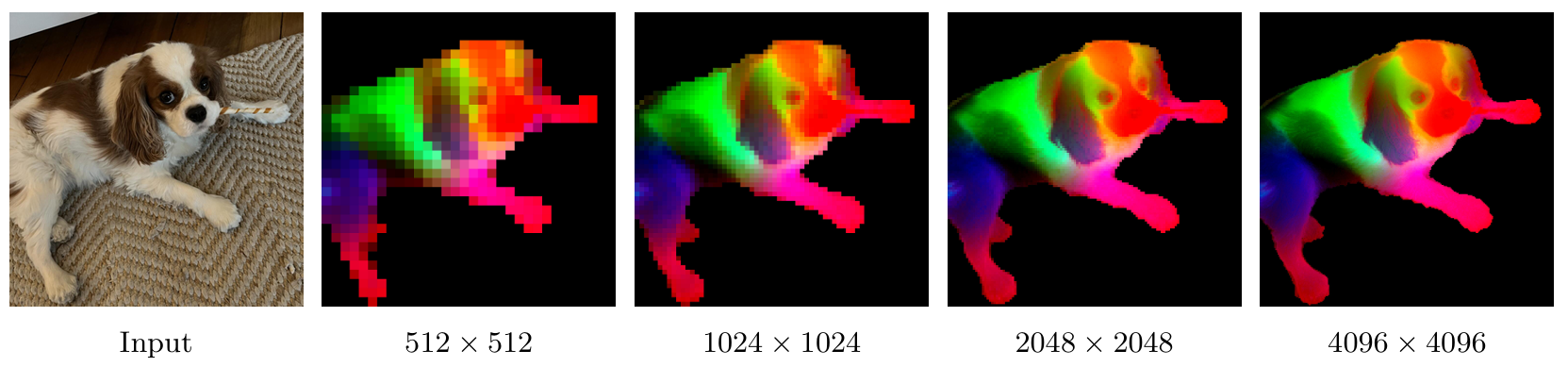
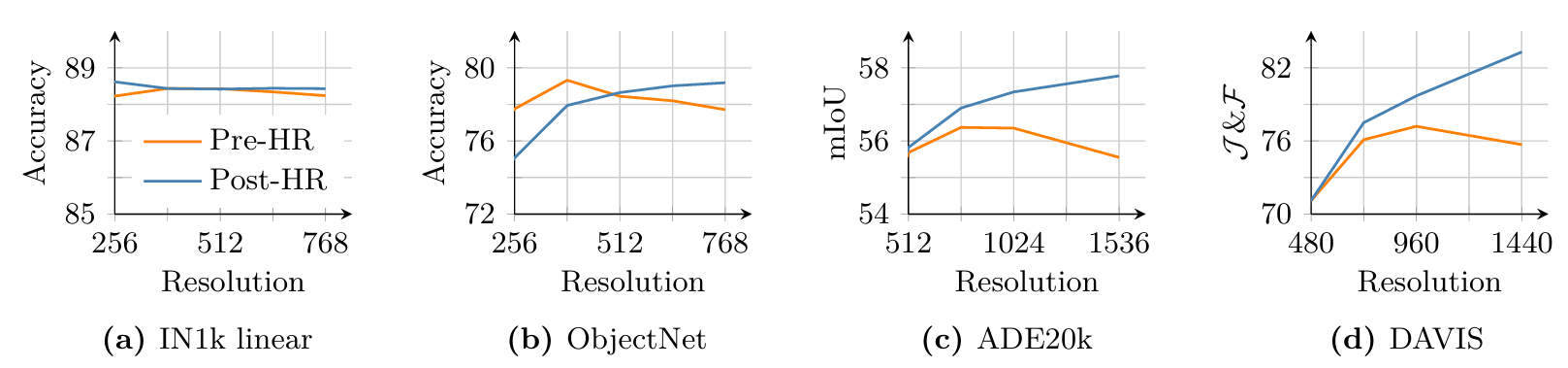
從經驗上看,我們觀察到這種相對簡短但有針對性的高分辨率步驟顯著提高了模型的整體質量,并使其能夠泛化到各種輸入尺寸,如圖4所示。在圖11中,我們比較了7B模型在適應前(“Pre-HR”)和適應后(“Post-HR”)的結果。我們發現分辨率縮放在ImageNet分類(a)上帶來了小幅提升,且相對于分辨率性能相對穩定。然而,在ObjectNet OOD遷移(b)中,我們觀察到較低分辨率的性能略有下降,而較高分辨率的性能有所提升。這在很大程度上被高分辨率下局部特征質量的提高所補償,如ADE20k(c)上的分割和DAVIS(d)上的跟蹤所顯示的積極趨勢。適應導致局部特征隨圖像尺寸的增大而改善,利用更大分辨率下可用的更豐富空間信息,有效實現高分辨率推斷。有趣的是,適應后的模型支持遠超最大訓練分辨率768的分辨率,我們在圖4中直觀地觀察到在4k4k4k以上分辨率的穩定特征圖。
5.2 模型蒸餾
適用于多種用例的模型家族 我們將ViT-7B模型蒸餾成更小的Vision Transformer變體(ViT-S、ViT-B和ViT-L),這些變體因其改進的可管理性和效率而受到社區的高度評價。我們的蒸餾方法使用與第一訓練階段相同的訓練目標,確保學習信號的一致性。然而,我們不依賴于模型權重的指數移動平均(EMA),而是直接使用7B模型作為教師來指導較小的學生模型。在這種情況下,教師模型是固定的。我們沒有觀察到patch級一致性問題,因此不應用Gram錨定技術。這種策略使蒸餾模型能夠繼承大型教師的豐富表示能力,同時更適用于部署和實驗。
我們的ViT-7B模型被蒸餾成一系列覆蓋廣泛計算預算的ViT模型,允許與并發模型進行適當比較。它們包括標準ViT-S(2100萬參數)、ViT-B(8600萬)、ViT-L(0.3B),以及自定義的ViT-S+(2900萬)和ViT-H+(0.8B)模型,以縮小與自蒸餾7B教師模型之間的性能差距。事實上,我們在DINOv2中觀察到,較小的學生模型可以通過蒸餾達到與其教師相當的性能。因此,蒸餾模型以推理計算的一小部分提供前沿級別的性能,如表14所示。我們訓練模型1M1M1M次迭代,然后按照余弦調度進行250k250k250k次迭代的學習率冷卻,再應用上文第5.1節中描述的高分辨率階段(不使用Gram錨定)。
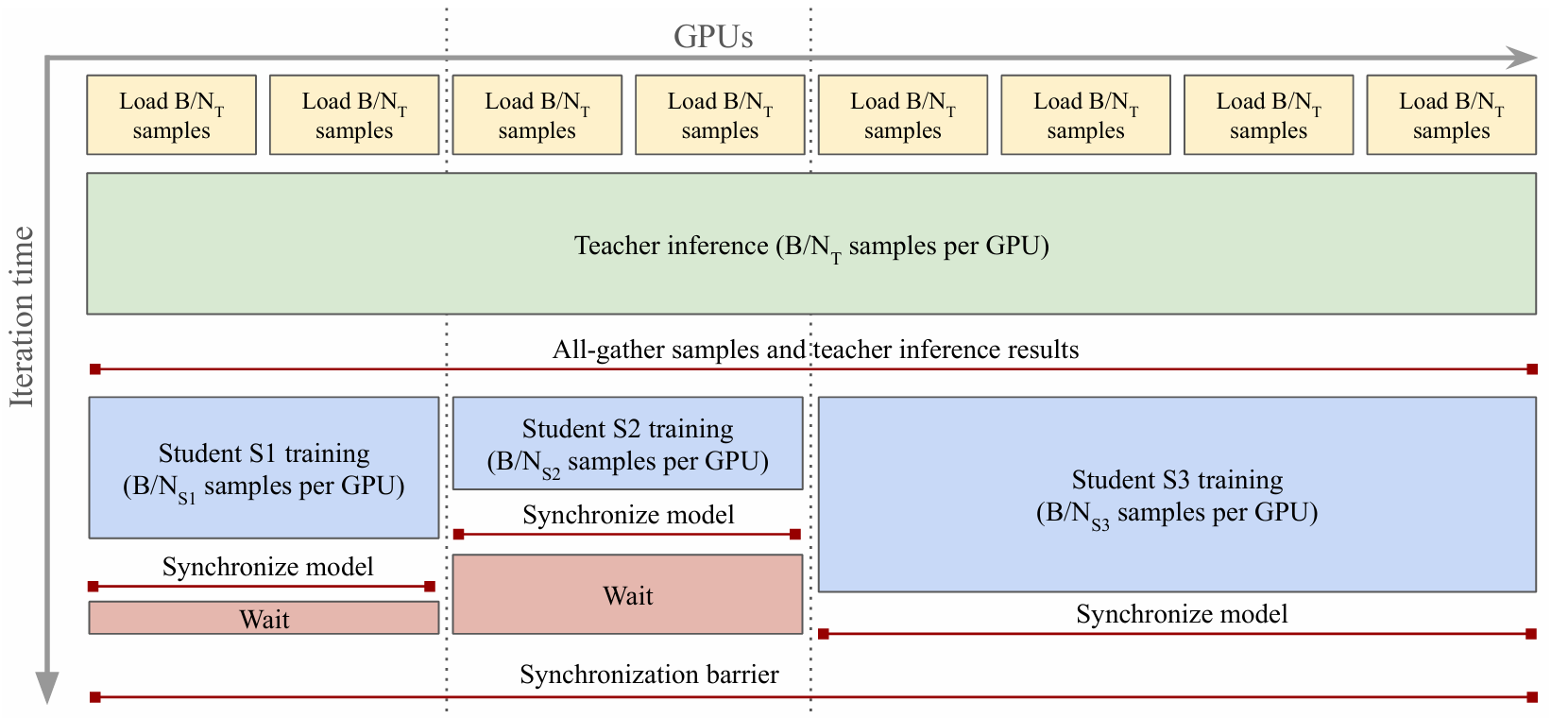
高效多學生蒸餾 ? 由于大型教師的推理成本可能比學生高出幾個數量級(見圖16a),我們設計了一個并行蒸餾管道,允許同時訓練多個學生,并在訓練所涉及的所有節點之間共享教師推理(圖12為示意圖)。設CTC_TCT?和CSC_SCS?分別為在單個樣本上運行教師推理和學生訓練的成本,在單教師/單學生蒸餾中,批量大小為BBB,其中NNN個GPU中的每個處理數據的B/NB/NB/N切片,教師推理成本為B/N×CTB/N\times C_TB/N×CT?,學生訓練成本為B/N×CSB/N\times C_SB/N×CS?每GPU。在多學生蒸餾中,我們按如下方式進行。每個學生SiS_iSi?被分配一組NSiN_{S_i}NSi?? GPU用于訓練,所有NT=∑NSiN_T=\sum N_{S_i}NT?=∑NSi?? GPU都是全局推理組的一部分。在每次迭代中,我們首先在全局組上運行教師推理,每GPU計算成本為B/NT×CTB/N_T\times C_TB/NT?×CT?。然后,我們運行all-gather集體操作,與所有計算節點共享輸入數據和推理結果。最后,每個學生組分別執行學生訓練,成本為B/NSi×CSiB/N_{S_i}\times C_{S_i}B/NSi??×CSi??。
上述計算表明,向蒸餾管道添加額外的學生將(1)(1)(1)降低每次迭代的每GPU計算量,從而整體提高蒸餾速度,(2)(2)(2)僅通過新學生的訓練成本增加總計算量,因為總教師推理成本現在是固定的。該實現只需要仔細設置GPU進程組,調整數據加載器和教師推理,以確保輸入和輸出使用NCCL集體操作在組之間同步。由于組在每次迭代中同步,為了最大化速度,我們調整每個學生的GPU數量,使其迭代時間大致相同。通過此過程,我們無縫訓練多個學生,并從我們的旗艦7B模型生成一整套蒸餾模型。
5.3 將DINOv3與文本對齊
開放詞匯圖像-文本對齊已受到研究社區的廣泛關注和熱情,這得益于其在實現靈活和可擴展的多模態理解方面的潛力。大量工作集中在改進CLIP(Radford et al., 2021)的質量,CLIP最初僅學習了圖像和文本表示之間的全局對齊。雖然CLIP展示了令人印象深刻的零樣本能力,但其對全局特征的關注限制了其捕獲細粒度、局部對應關系的能力。最近的研究(Zhai et al., 2022b)表明,可以使用預訓練的自監督視覺骨干網絡實現有效的圖像-文本對齊。這使得在多模態環境中利用這些強大模型成為可能,促進超越全局語義的更豐富和更精確的文本到圖像關聯,同時由于視覺編碼已經學習,也降低了計算成本。
我們通過采用Jose et al. (2025)先前提出的訓練策略,將文本編碼器與我們的DINOv3模型對齊。該方法遵循LiT訓練范式(Zhai et al., 2022b),從頭訓練文本表示,以通過對比目標將圖像與其標題匹配,同時保持視覺編碼器凍結。為了在視覺方面提供一些靈活性,在凍結的視覺骨干網絡之上引入了兩個Transformer層。該方法的一個關鍵增強是在匹配到文本嵌入之前,將平均池化的patch嵌入與輸出CLS token連接起來。這使得能夠將全局和局部視覺特征與文本對齊,從而在不需額外啟發式方法或技巧的情況下,提高密集預測任務的性能。此外,我們使用與Jose et al. (2025)中建立的相同數據整理協議,以確保一致性和可比性。
六、結果
在本節中,我們評估旗艦DINOv3 7B模型在各種計算機視覺任務上的表現。在我們的實驗中,除非另有說明,我們保持DINOv3凍結狀態并僅使用其表示。我們證明,使用DINOv3,無需微調即可獲得強大的性能。本節組織如下:首先,我們使用輕量級評估協議探測DINOv3的密集特征(第6.1節)和全局圖像表示(第6.2節),并與最強大的可用視覺編碼器進行比較。我們證明DINOv3學習了卓越的密集特征,同時提供了穩健且多功能的全局圖像表示。然后,我們考慮將DINOv3作為開發更復雜的計算機視覺系統(第6.3節)的基礎。我們展示了在DINOv3基礎上只需少量努力,就能在目標檢測、語義分割、3D視圖估計或相對單目深度估計等多樣化任務上取得與最先進水平相當甚至超越的結果。
6.1 DINOv3提供卓越的密集特征
我們首先使用多種輕量級評估方法探究DINOv3密集表示的原始質量。在所有情況下,我們利用最后一層的凍結patch特征,并通過以下方式評估:(1)定性可視化(第6.1.1節);(2)密集線性探測(第6.1.2節:分割、深度估計);(3)非參數方法(第6.1.3節:3D對應估計,第6.1.4節:對象發現,第6.1.5節:跟蹤);以及(4)輕量級注意力探測(第6.1.6節:視頻分類)。
基線? 我們將DINOv3的密集特征與最強大的公開可用圖像編碼器(包括弱監督和自監督的)進行比較。我們考慮使用CLIP風格的圖像-文本對比學習的弱監督編碼器:感知編碼器(PE) Core (Bolya et al., 2025)和SigLIP 2 (Tschannen et al., 2025)。我們還將與最強大的自監督方法進行比較:DINOv3的前身DINOv2 (Oquab et al., 2024)(含register tokens)(Darcet et al., 2024)、Web-DINO (Fan et al., 2025)(DINO的近期擴展努力)以及Franca (Venkataramanan et al., 2025)(最佳開源數據ISS模型)。最后,與聚合模型AM-RADIOv2.5 (Heinrich et al., 2025)(從DINOv2、CLIP (Radford et al., 2021)、DFN (Fang et al., 2024a)和Segment Anything (SAM) (Kirillov et al., 2023)蒸餾而來)以及PEspatial(將SAM 2 (Ravi et al., 2025)蒸餾到PEcore中)進行比較。對于每個基線,我們報告可用的最強模型性能,并在表格中指定架構。
6.1.1 定性分析
我們首先定性地分析DINOv3的密集特征圖。為此,我們使用主成分分析(PCA)將密集特征空間投影到3維,并將生成的3D空間映射到RGB。由于PCA中的符號模糊性(八種變體)以及主成分與顏色之間的任意映射(六種變體),我們探索所有組合并報告視覺上最具說服力的一個。結果可視化如圖13所示。與其他視覺骨干網絡相比,可以看出DINOv3的特征更加清晰,包含的噪聲更少,并顯示出優越的語義一致性。

6.1.2 密集線性探測
我們對兩個任務的密集特征進行線性探測:語義分割和單目深度估計。在這兩種情況下,我們在DINOv3的凍結patch輸出之上訓練線性變換。對于語義分割,我們在ADE20k (Zhou et al., 2017)、Cityscapes (Cordts et al., 2016)和PASCAL VOC 2012 (Everingham et al., 2012)數據集上進行評估,并報告平均交并比(mIoU)指標。對于深度估計,我們使用NYUv2 (Silberman et al., 2012)和KITTI (Geiger et al., 2013)數據集,并報告均方根誤差(RMSE)。
表3:使用凍結骨干網絡進行語義分割和單目深度估計的密集線性探測結果。我們報告ADE20k、Cityscapes和VOC分割基準的平均交并比(mIoU)指標。我們報告NYUv2和KITTI深度基準的均方根誤差(RMSE)指標。對于分割,所有模型都在適應1024個patch tokens的輸入分辨率下進行評估(即patch大小為14時為448×448,patch大小為16時為512×512)。
| 方法 ViT | 分割 ADE20k | 分割 Citysc. | 分割 VOC | 深度 NYUv2 ↓ | 深度 KITTI ↓ |
|---|---|---|---|---|---|
| 聚合骨干網絡 | |||||
| AM-RADIOv2.5 | g/14 | 49.3 | 73.2 | 82.7 | 0.362 |
| PEspatial | G/14 | 42.7 | 68.3 | 76.1 | 0.466 |
| 弱監督骨干網絡 | |||||
| SigLIP 2 | g/16 | 64.8 | 72.7 | 85.4 | 0.340 |
| PEcore | G/14 | 38.9 | 61.1 | 69.2 | 0.590 |
| 自監督骨干網絡 | |||||
| Franca | g/14 | 46.3 | 82.9 | 83.1 | 0.445 |
| DINOv2 | g/14 | 49.5 | 83.1 | 86.6 | 0.309 |
| Web-DINO | 7B/14 | 42.7 | 68.3 | 76.1 | 0.466 |
| DINOv3 | 7B/16 | 55.9 | 81.1 | 86.6 | 0.309 |
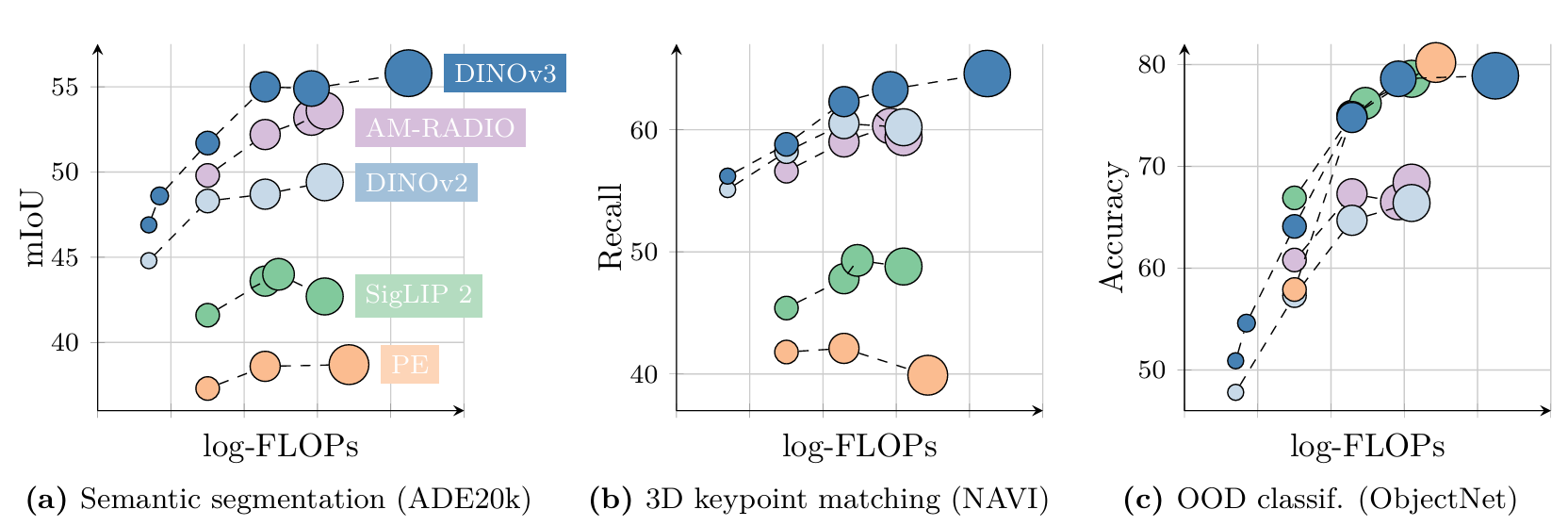
結果(表3) ?分割結果展示了我們密集特征的卓越質量。在通用ADE20k數據集上,DINOv3比自監督基線高出6 mIoU以上,比弱監督基線高出13分以上。此外,DINOv3比PEspatial高出6分以上,比AM-RADIOv2.5高出近3分。這些結果令人矚目,因為兩者都是強大的基線,是從嚴重監督的分割模型SAM (Kirillov et al., 2023)蒸餾而來的。在自動駕駛基準Cityscapes上也觀察到類似結果,DINOv3達到了81.1的最高mIoU,比AM-RADIOv2.5高出2.5分,比所有其他骨干網絡至少高出5.5分。
在單目深度估計方面,DINOv3再次以顯著優勢超越所有其他模型:弱監督模型PEcore和SigLIP 2仍然落后,DINOv2和從SAM派生的更先進模型是最接近的競爭對手。有趣的是,雖然PEspatial和AM-RADIO在NYU上表現強勁,但它們在KITTI上的性能低于DINOv2。即使在那里,DINOv3也比其前身DINOv2提高了0.278 RMSE。
這兩組評估顯示了DINOv3密集特征的卓越表示能力,并反映了圖13的視覺結果。僅使用線性預測器,DINOv3就能穩健地預測對象類別和掩碼,以及場景的物理測量(如相對深度)。這些結果表明,特征不僅視覺上清晰且正確定位,而且以線性可分離的方式表示底層觀測的許多重要屬性。最后,在ADE20k上使用線性分類器獲得的絕對性能(55.9 mIoU)本身令人印象深刻,因為它離該數據集的最先進水平(63.0 mIoU)并不遙遠。
6.1.3 3D對應估計
理解3D世界一直是計算機視覺的重要目標。圖像基礎模型通過提供3D感知特征,最近推動了3D理解研究。在本節中,我們評估DINOv3的多視圖一致性——即,對象在不同視圖中同一關鍵點的patch特征是否相似——遵循Probe3D (Banani et al., 2024)定義的協議。我們區分幾何對應估計和語義對應估計。前者指匹配同一對象實例的關鍵點,而后者指匹配同一對象類別的不同實例的關鍵點。我們在NAVI數據集(Jampani et al., 2023)上評估幾何對應,在SPair數據集(Min et al., 2019)上評估語義對應,并在兩種情況下使用對應召回率來衡量性能。更多實驗細節請參見附錄D.3。
表4:密集表示的3D一致性評估。我們按照Probe3D (Banani et al., 2024)的評估協議估計跨視圖的關鍵點對應關系。為了衡量性能,我們報告對應召回率,即落在指定距離內的對應百分比。
| 方法 ViT | 幾何 NAVI | 語義 SPair |
|---|---|---|
| 聚合骨干網絡 | ||
| AM-RADIOv2.5 | g/14 | 59.4 |
| PEspatial | G/14 | 53.8 |
| 弱監督骨干網絡 | ||
| SigLIP 2 | g/16 | 49.4 |
| PEcore | G/14 | 39.9 |
| 自監督骨干網絡 | ||
| Franca | g/14 | 54.6 |
| DINOv2 | g/14 | 60.1 |
| Web-DINO | 7B/14 | 55.0 |
| DINOv3 | 7B/16 | 64.4 |
結果(表4) ?對于幾何對應,DINOv3優于所有其他模型,比第二好的模型(DINOv2)提高了4.3%的召回率。其他SSL擴展努力(Franca和WebSSL)落后于DINOv2,表明它仍然是一個強大的基線。弱監督模型(PEcore和AM-RADIO)幾乎達到DINOv2的性能,但PEspatial仍然落后(-11.6%召回率),甚至落后于Franca(-0.8%召回率)。這表明自監督學習是該任務取得強勁表現的關鍵組成部分。對于語義對應,同樣的結論適用。DINOv3表現最佳,優于其前身(+2.6%召回率)和AM-RADIO(+1.9%召回率)。總體而言,這些在關鍵點匹配上的出色表現對DINOv3在其他3D密集應用中的下游使用是非常有希望的信號。
6.1.4 無監督對象發現
強大的自監督特征有助于在無需任何標注的情況下發現圖像中的對象實例(Vo et al., 2021; Siméoni et al., 2021; Seitzer et al., 2023; Wang et al., 2023c; Siméoni et al., 2025)。我們通過無監督對象發現任務測試不同視覺編碼器的這一能力,該任務需要對圖像中的對象進行類別無關的分割(Russell et al., 2006; Tuytelaars et al., 2010; Cho et al., 2015; Vo et al., 2019)。特別是,我們使用基于非參數圖的TokenCut算法(Wang et al., 2023c),該算法在各種骨干網絡上表現出色。我們在三個廣泛使用的數據集上運行它:VOC 2007、VOC 2012 (Everingham et al., 2015)和COCO-20k (Lin et al., 2014; Vo et al., 2020)。我們遵循Siméoni et al. (2021)定義的評估協議,并報告CorLoc指標。為了正確比較具有不同特征分布的骨干網絡,我們對TokenCut的主要超參數(即在構建用于分區的patch圖時應用的余弦相似度閾值)進行搜索。最初,使用DINO (Caron et al., 2021)時,通過使用最后一層注意力的鍵獲得了最佳對象發現結果。然而,這種手工選擇并不能一致地推廣到其他骨干網絡。為簡化起見,我們對所有模型始終使用輸出特征。
結果(圖14) ?原始DINO為這項任務設定了非常高的標準。有趣的是,雖然DINOv2在像素級密集任務上表現出色,但在對象發現上卻失敗了。這部分可歸因于密集特征中存在的偽影(參見圖13)。DINOv3憑借其干凈精確的輸出特征圖,優于其兩個前身,在VOC 2007上提高了5.9 CorLoc,并優于所有其他骨干網絡,無論是自監督、弱監督還是聚合的。這一評估證實了DINOv3的密集特征既具有語義強度又定位良好。我們相信這將為更多類別無關的對象檢測方法鋪平道路,特別是在標注成本高或不可用,且相關類別集不限于預定義子集的場景中。
| 方法 | ViT | VOC07 | VOC12 | COCO |
|---|---|---|---|---|
| 聚合骨干網絡 | ||||
| AM-RADIOv2.5 | g/14 | 55.0 | 59.7 | 45.9 |
| PEspatial | G/14 | 51.2 | 56.0 | 43.9 |
| 弱監督骨干網絡 | ||||
| SigLIPv2 | g/16 | 20.5 | 24.7 | 18.6 |
| PEcore | G/14 | 14.2 | 18.2 | 13.5 |
| 自監督骨干網絡 | ||||
| DINO | S/16 | 61.1 | 66.0 | 48.7 |
| DINO | B/16 | 60.1 | 64.4 | 50.5 |
| DINOv2 | g/14 | 55.6 | 60.4 | 45.4 |
| Web-DINO | 7B/14 | 26.1 | 29.7 | 20.9 |
| DINOv3 | 7B/16 | 66.1 | 69.5 | 55.1 |
 |
6.1.5 視頻分割跟蹤
除了靜態圖像外,視覺表示的一個重要屬性是其時間一致性,即特征是否隨時間穩定演變。為了測試這一屬性,我們在視頻分割跟蹤任務上評估DINOv3:給定視頻第一幀中的真實實例分割掩碼,目標是將這些掩碼傳播到后續幀。我們使用DAVIS 2017 (Pont-Tuset et al., 2017)、YouTube-VOS (Xu et al., 2018)和MOSE (Ding et al., 2023)數據集。我們使用標準的J&F-mean指標評估性能,該指標結合了區域相似性(J)和輪廓準確性(F) (Perazzi et al., 2016)。按照Jabri et al. (2020),我們使用非參數標簽傳播算法,該算法考慮幀之間patch特征的相似性。我們在三種輸入分辨率下進行評估,對patch大小為14/16的模型使用短邊長度420/480(S)、840/960(M)和1260/1440(L)像素(匹配patch tokens的數量)。J&F分數始終在視頻的原生分辨率下計算。更多詳細實驗設置請參見附錄D.5。
表5:視頻分割跟蹤評估。我們報告在DAVIS、YouTube-VOS和MOSE上多分辨率的J&F-mean。對于patch大小為14/16的模型,小、中、大分辨率分別對應視頻短邊為420/480、840/960、1260/1140像素。
| DAVIS | DAVIS | DAVIS | YouTube-VOS | YouTube-VOS | YouTube-VOS | MOSE | MOSE | MOSE | |
|---|---|---|---|---|---|---|---|---|---|
| 方法 ViT | S | M | L | S | M | L | S | M | L |
| 聚合骨干網絡 | |||||||||
| AM-RADIOv2.5 | g/14 | 54.3 | 68.4 | 74.5 | 70.5 | 68.5 | 67.5 | 55.6 | 39.3 |
| PEspatial | G/14 | 34.0 | 66.5 | 77.3 | 81.4 | 70.1 | 78.1 | 79.2 | 44.0 |
| 弱監督骨干網絡 | |||||||||
| SigLIP 2 | g/16 | 56.1 | 52.0 | 57.3 | |||||
| PEcore | G/14 | 48.2 | 62.3 | 53.1 | 55.1 | 30.3 | |||
| 自監督骨干網絡 | |||||||||
| Franca | g/14 | 61.8 | 66.9 | 66.5 | 67.3 | 70.5 | 67.9 | 40.3 | 42.6 |
| DINOv2 | g/14 | 63.9 | 73.6 | 76.6 | 65.6 | 73.5 | 67.9 | 40.4 | 42.6 |
| Web-DINO | 7B/14 | 57.2 | 65.8 | 69.5 | 43.9 | 49.6 | 50.9 | 24.9 | 29.9 |
| DINOv3 | 7B/16 | 71.1 | 79.7 | 83.3 | 74.1 | 80.2 | 80.7 | 46.0 | 53.9 |
結果(表5)?與之前所有結果一致,弱監督骨干網絡未能提供令人信服的性能。PEspatial(從視頻模型SAMv2蒸餾而來)提供了令人滿意的性能,在較小分辨率上超越DINOv2,但在較大分辨率上表現不佳。在各種分辨率下,DINOv3都優于所有競爭對手,在DAVIS-L上達到驚人的83.3 J&F,比DINOv2高出6.7分。此外,性能隨分辨率的變化呈現健康趨勢,證實我們的模型能夠利用更多輸入像素輸出精確的高分辨率特征圖(參見圖3和圖4)。相比之下,SigLIP 2和PEcore在更高分辨率下的性能幾乎保持不變,而PEspatial的性能則下降。有趣的是,我們的圖像模型無需對視頻進行任何調整,就能在時間上正確跟蹤對象(參見圖15)。這使其成為嵌入視頻的理想候選者,允許在其上構建強大的視頻模型。

6.1.6 視頻分類
先前的結果展示了DINOv3表示的低級時間一致性,使其能夠在時間上準確跟蹤對象。更進一步,我們在本節評估其密集特征用于高級視頻分類的適用性。類似于V-JEPA 2 (Assran et al., 2025)的設置,我們在從每幀提取的patch特征之上訓練一個注意力探測器——一個淺層4層基于Transformer的分類器。這使得能夠對時間和空間維度進行推理,因為特征是每幀獨立提取的。在評估期間,我們要么每視頻取一個片段,要么通過平均來自多個片段的預測概率應用測試時增強(TTA)。更多實驗細節請參見附錄D.6。我們在三個數據集上進行此評估:UCF101 (Soomro et al., 2012)、Something-Something V2 (Goyal et al., 2017)和Kinetics-400 (Kay et al., 2017),并報告top-1準確率。作為額外基線,我們報告V-JEPA v2的性能,這是視頻理解的最先進的SSL模型。
表6:使用注意力探測器進行視頻分類評估。我們報告在UCF101、Something-Something V2 (SSv2)和Kinetics-400 (K400)上的top-1準確率。對于每個模型,我們報告每視頻評估單個片段或應用測試時增強(TTA)的性能。
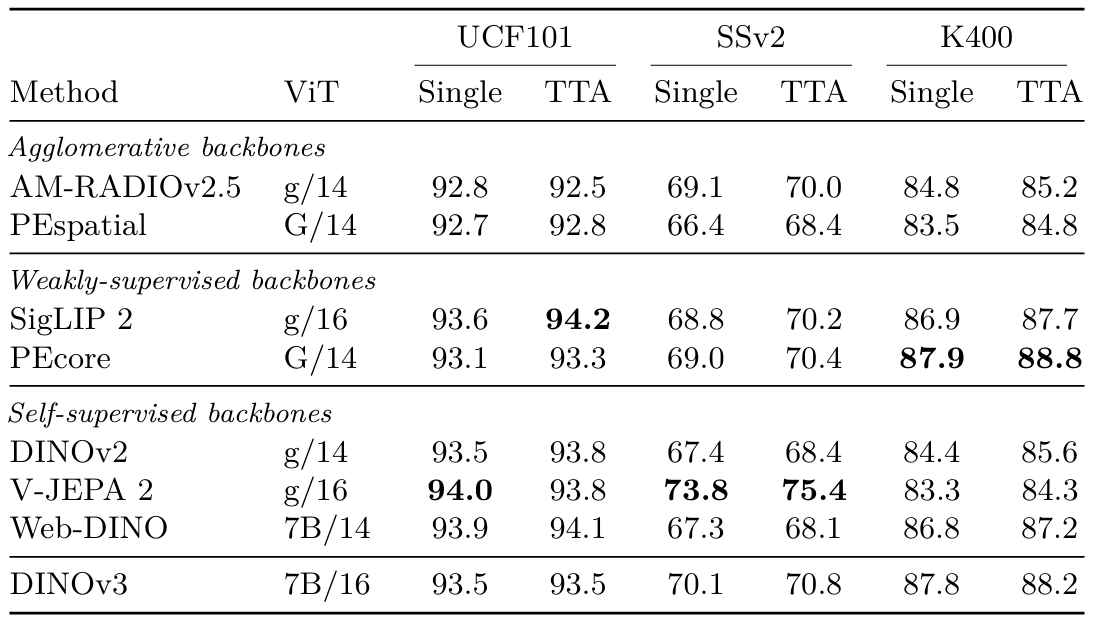
結果(表6)?與先前實驗的結論一致,我們發現DINOv3可以成功用于提取強大的視頻特征。由于此評估涉及訓練幾層自注意力,模型之間的差異不太明顯。然而,DINOv3與PEcore和SigLIP 2處于同一水平,并在所有數據集上明顯優于其他模型(DINOv2、AM-RADIO)。UCF101和K400注重外觀,其中對象的強類別級理解提供了大部分性能。另一方面,SSv2需要更好地理解運動——專用視頻模型V-JEPA v2在此數據集上表現出色。有趣的是,DINOv3與弱監督模型之間的差距在此數據集上略大。這再次證實了DINOv3對視頻任務的適用性。
6.2 DINOv3具有穩健和多功能的全局圖像描述符
在本節中,我們評估DINOv3捕獲全局圖像統計信息的能力。為此,我們考慮使用線性探測的經典分類基準(第6.2.1節)和實例檢索基準(第6.2.2節)。同樣,我們將與最強大的公開可用圖像編碼器進行比較。除了前一節中的模型外,我們還評估了兩個弱監督模型AIMv2 (Fini et al., 2024),該模型使用聯合自回歸像素和文本預測進行訓練,以及大規模EVA-CLIP-18B (Sun et al., 2024)。
6.2.1 使用線性探測的圖像分類
我們在DINOv3的輸出CLS token之上訓練線性分類器,以評估模型在分類基準上的表現。我們考慮ImageNet1k (Deng et al., 2009)數據集及其變體來評估分布外魯棒性,并考慮來自不同領域的數據集套件,以了解DINOv3區分細粒度類別的能力。評估細節請參見附錄D.7。
ImageNet的領域泛化(表7)在本實驗中,我們在ImageNet-train上進行訓練,使用ImageNet-val作為驗證集來選擇超參數,并將找到的最佳分類器轉移到不同的測試數據集:ImageNet-V2 (Recht et al., 2019)和ReaL (Beyer et al., 2020)是ImageNet的替代圖像和標簽集,用于測試對ImageNet驗證集的過擬合;Rendition (Hendrycks et al., 2021a)和Sketch (Wang et al., 2019)展示了ImageNet類別的風格化和人工版本;Adversarial (Hendrycks et al., 2021b)和ObjectNet (Barbu et al., 2019)包含特意選擇的困難樣本;Corruptions (Hendrycks and Dietterich, 2019)衡量對常見圖像損壞的魯棒性。作為參考,我們還列出了Dehghani et al. (2023)使用在大規模JFT數據集(30-40億圖像)上訓練的監督分類ViT獲得的線性探測結果。請注意,這些結果遵循略有不同的評估協議,與我們的結果不可直接比較。
DINOv3顯著超越了之前所有的自監督骨干網絡,在ImageNet-R上提高了+10%,在-Sketch上提高了+6%,在ObjectNet上比之前最強的SSL模型DINOv2提高了+13%。我們注意到,在ImageNet-A和ObjectNet等困難的分布外任務上,最強的弱監督模型SigLIP 2和PE現在比最強的監督模型(ViT-22B)表現更好。DINOv3在ImageNet-R和-Sketch上達到了可比較的結果,在困難任務ImageNet-A和ObjectNet上,它緊隨PE之后,同時超過了SigLIPv2。在ImageNet上,雖然驗證分數比SigLIPv2和PE低0.7-0.9分,但在"更干凈"的測試集-V2和-ReaL上的性能幾乎相同。值得注意的是,DINOv3在損壞魯棒性(ImageNet-C)方面表現最佳。總的來說,這是首次SSL模型達到了與弱監督和監督模型在圖像分類上可比的結果——這一領域曾是(弱)監督訓練方法的強項。考慮到像ViT-22B、SigLIP 2和PE這樣的模型是使用大量人工標注數據集訓練的,這是一個顯著的結果。相比之下,DINOv3純粹從圖像中學習,這使得在未來進一步擴展/改進該方法成為可能。
表7:在ImageNet1k上訓練的線性探測器的分類準確率,使用凍結的骨干網絡。弱監督和自監督模型在適應1024個patch tokens的圖像分辨率下進行評估(即patch大小為14時為448×448,patch大小為16時為512×512)。作為參考,我們還列出了Dehghani et al. (2023)使用不同評估協議的結果(用*標記)
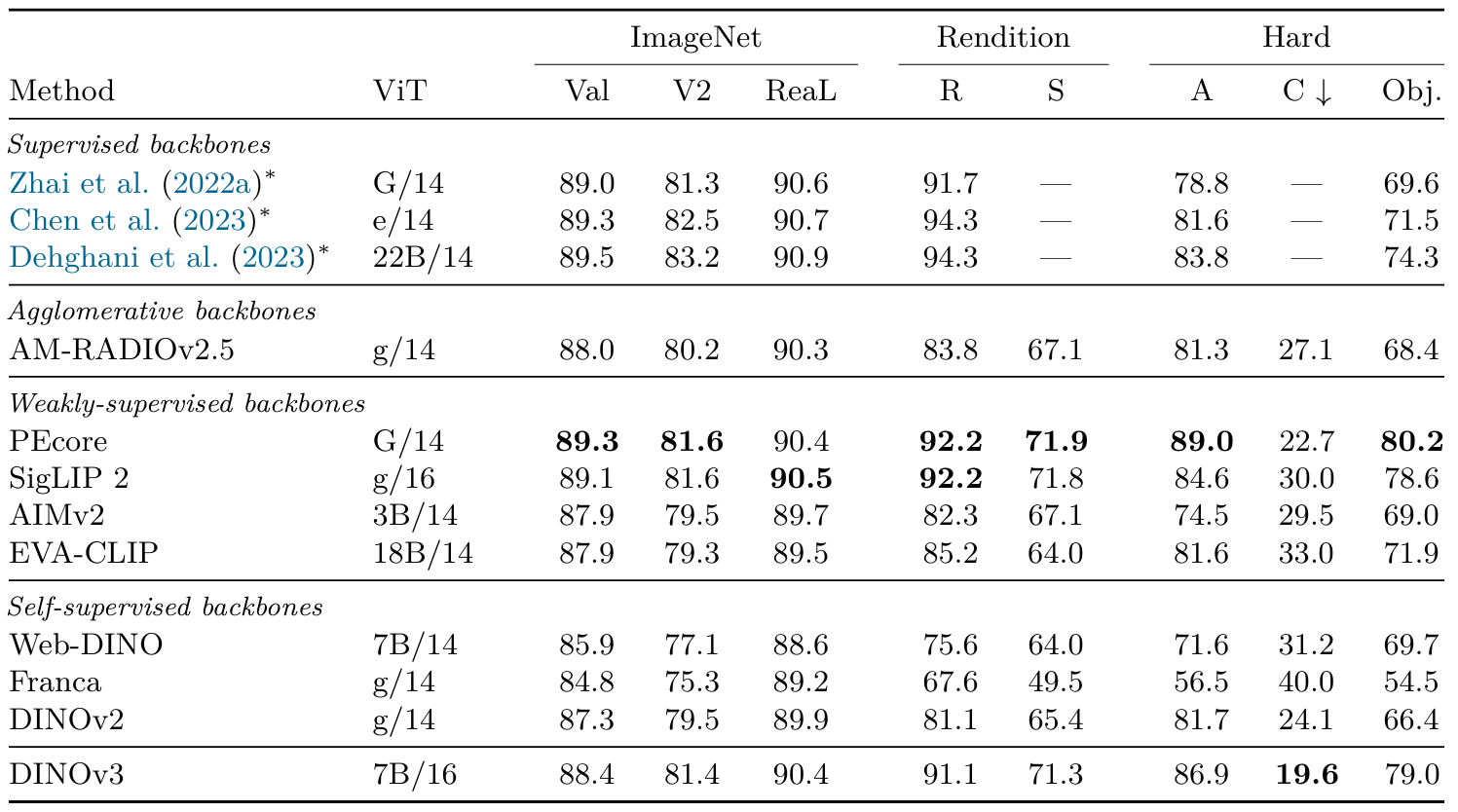
表8:細粒度分類基準。Fine-S是對12個數據集的平均值,完整結果請參見表22。
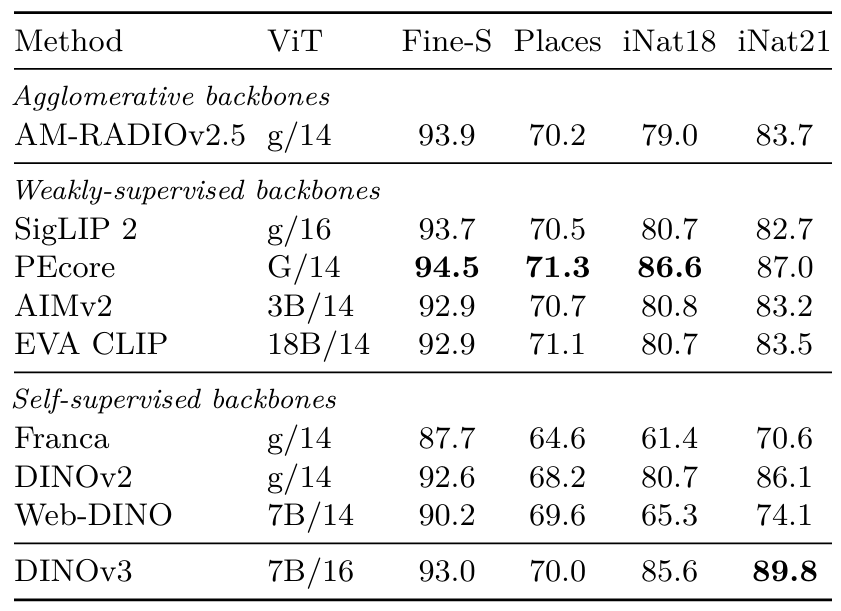
細粒度分類(表8) ?我們還測量了DINOv3在多個數據集上訓練線性探測器進行細粒度分類時的性能。特別是,我們報告了3個大型數據集上的準確率,即用于場景識別的Places205 (Zhou et al., 2014),以及用于詳細植物和動物物種識別的iNaturalist 2018 (Van Horn et al., 2018)和iNaturalist 2021 (Van Horn et al., 2021),還有覆蓋場景、對象和紋理的12個較小數據集的平均結果(如Oquab et al. (2024)中所述,此處稱為Fine-S)。有關這些數據集上的單獨結果,請參見表22。
我們發現,DINOv3再次超越了之前所有的SSL方法。與弱監督方法相比,它也顯示出具有競爭力的結果,表明其在各種細粒度分類任務中具有魯棒性和泛化能力。值得注意的是,DINOv3在困難的iNaturalist21數據集上達到了89.8%的最高準確率,甚至超過了最佳弱監督模型PEcore的87.0%。
6.2.2 實例識別
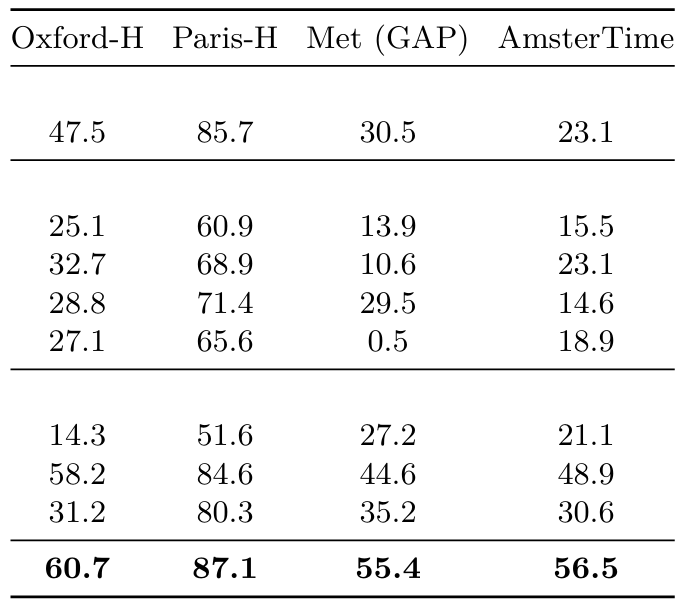
為了評估我們模型的實例級識別能力,我們采用了非參數檢索方法。在這里,使用輸出CLS token,通過查詢圖像與其之間的余弦相似度對數據庫圖像進行排序。我們在幾個數據集上評估性能:用于地標識別的Oxford和Paris數據集(Radenovic et al., 2018),包含來自大都會博物館的藝術作品的Met數據集(Ypsilantis et al., 2021),以及由現代街景圖像與阿姆斯特丹歷史檔案圖像匹配組成的AmsterTime (Yildiz et al., 2022)。使用Oxford、Paris和AmsterTime的平均精度以及Met的全局平均精度來量化檢索效果。更多評估細節請參見附錄D.8。
結果(表9和23)在所有評估的基準上,DINOv3都以很大優勢取得了最強的性能,例如在Met上比第二好的模型DINOv2提高了+10.8分,在AmsterTime上提高了+7.6分。在此基準上,弱監督模型遠遠落后于DINOv3,AM-RADIO除外,它是從DINOv2特征蒸餾而來的。這些發現突顯了DINOv3在實例級檢索任務中的魯棒性和多功能性,涵蓋了傳統地標數據集和更具挑戰性的領域,如藝術和歷史圖像檢索。
表9:實例識別基準。更多指標請參見表23。
6.3、DINOv3是復雜計算機視覺系統的基礎
前兩節已經為DINOv3在密集任務和全局任務中的質量提供了堅實的信號。然而,這些結果是在"模型探測"實驗協議下獲得的,使用輕量級線性適配器甚至非參數算法來評估特征質量。雖然這種簡單的評估允許從復雜的實驗協議中去除混雜因素,但不足以評估DINOv3作為更大計算機視覺系統基礎組件的全部潛力。因此,在本節中,我們擺脫輕量級協議,轉而訓練更復雜的下游解碼器,并考慮更強的、特定任務的基線。具體來說,我們將DINOv3用作以下任務的基礎:(1)使用Plain-DETR進行目標檢測(第6.3.1節);(2)使用Mask2Former進行語義分割(第6.3.2節);(3)使用Depth Anything進行單目深度估計(第6.3.3節);以及(4)使用視覺幾何基礎Transformer進行3D理解(第6.3.4節)。這些任務僅旨在探索DINOv3可能實現的功能。盡管如此,我們發現基于DINOv3構建的模型在各種任務上都表現出色。
6.3.1 目標檢測
作為第一個任務,我們解決了計算機視覺中長期存在的目標檢測問題。給定一張圖像,目標是為預定義類別的所有對象實例提供邊界框。此任務需要精確的定位和良好的識別能力,因為邊界框需要匹配對象邊界并對應正確的類別。雖然在COCO (Lin et al., 2014)等標準基準上的性能已基本飽和,但我們提出使用凍結的骨干網絡來解決此任務,僅在頂部訓練一個小解碼器。
數據集和指標 我們使用COCO數據集 (Lin et al., 2014) 評估DINOv3的目標檢測能力,在COCO-VAL2017分割上報告結果。此外,我們在COCO-O評估數據集 (Mao et al., 2023) 上評估分布外性能。該數據集包含相同的類別,但在六種分布偏移設置下提供輸入圖像。對于兩個數據集,我們報告IoU閾值在[0.5:0.05:0.95][0.5:0.05:0.95][0.5:0.05:0.95]范圍內的平均精度(mAP)。對于COCO-O,我們還報告有效魯棒性(ER)。由于COCO是一個小型數據集,僅包含118k訓練圖像,我們利用更大的Objects365數據集 (Shao et al., 2019) 對解碼器進行預訓練,這是常見做法。
表10:與最先進系統在目標檢測上的比較。我們在凍結的DINOv3骨干網絡之上訓練檢測適配器。我們在COCO和COCO-O數據集的驗證集上顯示結果,并報告跨IoU閾值的mAP以及有效魯棒性(ER)。基于DINOv3的檢測系統建立了新的最先進技術。由于InternImage-G檢測模型尚未發布,我們無法重現其結果或計算COCO-O分數。
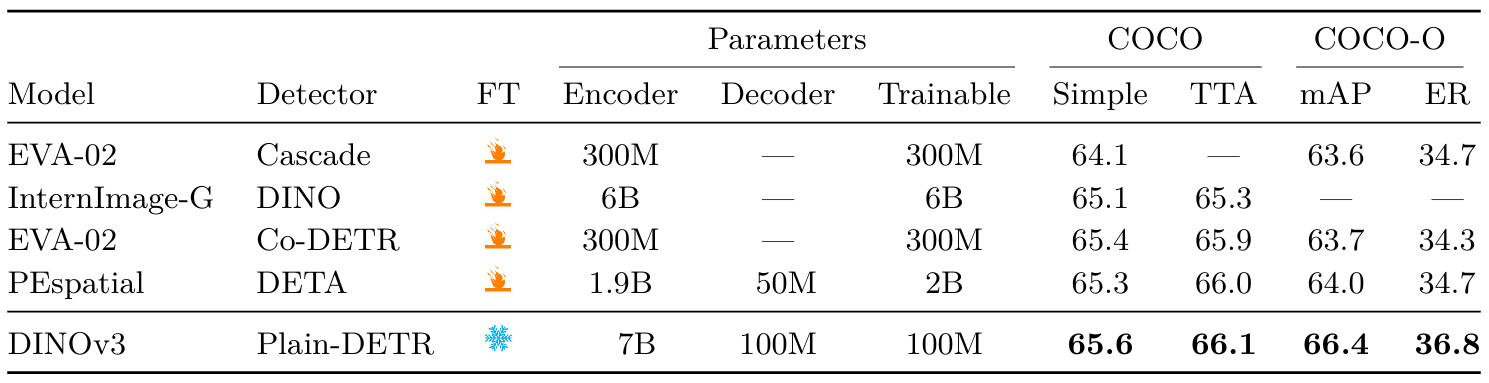
實現? 我們基于Plain-DETR (Lin et al., 2023b)構建,但進行了以下修改:我們不將Transformer編碼器融合到骨干網絡中,而是將其保持為獨立模塊,類似于原始DETR (Carion et al., 2020),這使我們能夠在訓練和推理期間完全凍結DINOv3骨干網絡。據我們所知,這使其成為首個使用凍結骨干網絡的競爭性檢測模型。我們在Objects365數據集上以1536分辨率訓練Plain-DETR檢測器22個周期,然后以2048分辨率訓練1個周期,接著在COCO數據集上進行12個周期的訓練。在推理時,我們在2048分辨率下運行。可選地,我們還通過在多個分辨率(從1536到2880)轉發圖像來應用測試時增強(TTA)。完整實驗細節請參見附錄D.9。
結果(表10)?我們將我們的系統與四個模型進行比較:EVA-02與Cascade檢測器(Fang et al., 2024b)、EVA-02與Co-DETR (Zong et al., 2023)、InternImage-G與DINO (Wang et al., 2023b)以及PEspatial與DETA (Bolya et al., 2025)。我們發現,在凍結的DINOv3骨干網絡之上訓練的輕量級檢測器(1億參數)能夠達到最先進性能。對于COCO-O,差距尤為明顯,表明檢測模型可以有效利用DINOv3的魯棒性。有趣的是,我們的模型以少得多的訓練參數超越了所有先前的模型,最小的比較點仍使用超過3億可訓練參數。我們認為,不專門定制骨干網絡就能實現如此強大的性能,為各種實際應用提供了便利:單次骨干網絡前向傳播可以提供支持多個任務的特征,減少計算需求。
6.3.2 語義分割
繼上一個實驗之后,我們現在評估語義分割,這是另一個長期存在的計算機視覺問題。該任務也需要強大的、定位良好的表示,并期望進行密集的逐像素預測。然而,與目標檢測相反,模型不需要區分同一對象的實例。與檢測類似,我們在凍結的DINOv3模型之上訓練解碼器。
數據集和指標 我們將評估重點放在ADE20k數據集 (Zhou et al., 2017) 上,該數據集包含20k訓練圖像和2k驗證圖像中的150個語義類別。我們使用平均交并比(mIoU)來衡量性能。為了訓練分割模型,我們還使用了COCO-Stuff (Caesar et al., 2018)和Hypersim (Roberts et al., 2021)數據集。它們分別包含164k張具有171個語義類別的圖像和77k張具有40個類別的圖像。
實現 ?為了構建將DINOv3特征映射到語義類別的解碼器,我們結合了ViT-Adapter (Chen et al., 2022)和Mask2Former (Cheng et al., 2022),類似于先前的工作(Wang et al., 2022b; 2023b; 2023a)。然而,在我們的情況下,DINOv3骨干網絡在訓練期間保持凍結。為了避免改變骨干網絡特征,我們通過移除注入器組件進一步修改了原始ViT-Adapter架構。與基線相比,我們還將嵌入維度從1024增加到2048,以支持處理DINOv3骨干網絡的4096維輸出。我們首先在COCO-Stuff上預訓練分割解碼器80k次迭代,然后在Hypersim (Roberts et al., 2021)上訓練10k次迭代。最后,我們在ADE20k的訓練分割上訓練20k次迭代,并在驗證分割上報告結果。所有訓練都在896的輸入分辨率下完成。在推理時,我們考慮兩種設置:單尺度,即我們在訓練分辨率下轉發圖像,或多尺度,即我們在原始訓練分辨率的×0.9到1.1之間的多個圖像比例上平均預測。更多實驗細節請參見附錄D.10。
表11:ADE20k上語義分割的最先進系統比較。我們在單尺度或多尺度設置(分別稱為Simple和TTA)下評估模型。按照慣例,我們在896分辨率下運行此評估并報告mIoU分數。BEIT3、ONE-PEACE和DINOv3使用Mask2Former與ViT-Adapter架構,解碼器參數同時考慮兩者。我們在表24中報告了在其他數據集上的結果
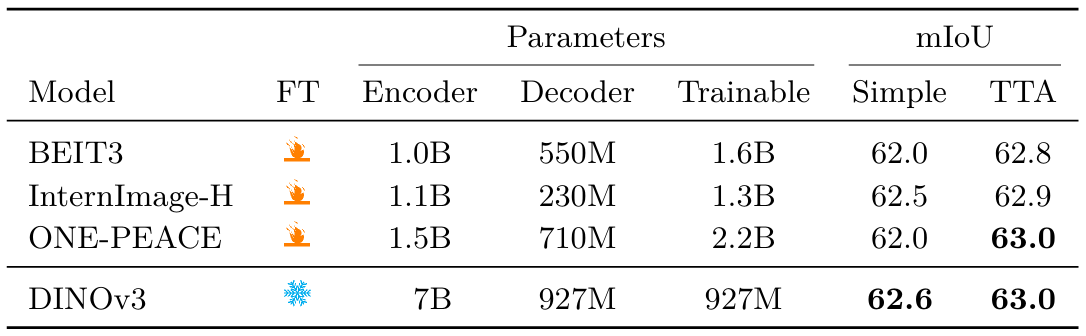
結果(表11)我們將我們的模型性能與幾個最先進的基線進行比較,包括BEIT-3 (Wang et al., 2022b)、InternImage-H (Wang et al., 2023b)和ONE-PEACE (Wang et al., 2023a),并在表24中報告了在其他數據集上的結果。基于凍結DINOv3骨干網絡的分割模型達到了最先進性能,與ONE-PEACE持平(63.0 mIoU)。它還在COCO-Stuff (Caesar et al., 2018)和VOC 2012 (Everingham et al., 2012)數據集上超越了所有先前的模型。由于語義分割需要精確的逐像素預測,視覺Transformer骨干網絡提出了一個基本問題。實際上,16像素寬的輸入patch使預測的粒度相對粗糙——這鼓勵了像ViT-Adapter這樣的解決方案。另一方面,我們已經證明我們可以獲得高質量的特征圖,即使在高達4096的非常高分辨率下(參見圖3和圖4);這對應于512個token寬的密集特征圖。我們希望未來的工作能夠利用這些高分辨率特征,在不依賴像ViT-Adapter與Mask2Former這樣的重型解碼器的情況下達到最先進性能。
6.3.3 單目深度估計
我們現在考慮構建一個用于單目深度估計的系統。為此,我們遵循Depth Anything V2 (DAv2) (Yang et al., 2024b)的設置,這是一種最新的最先進方法。DAv2的關鍵創新是使用大量帶有真實深度標注的合成生成圖像。關鍵的是,這依賴于DINOv2作為特征提取器,能夠彌合模擬到現實(sim-to-real)的差距,而其他視覺骨干網絡如SAM (Kirillov et al., 2023)則不具備這種能力 (Yang et al., 2024b)。因此,我們在DAv2管道中將DINOv2替換為DINOv3,以查看是否能獲得類似的結果。
實現 與DAv2類似,我們使用密集預測Transformer (DPT) (Ranftl et al., 2021)來預測像素級深度場,使用DINOv3四個等間距層的特征作為輸入。我們在DAv2的合成數據集上使用DAv2的損失集訓練模型,將訓練分辨率提高到1024×7681024\times7681024×768,以利用DINOv3的高分辨率能力。與DAv2不同,我們保持骨干網絡凍結,而不是對其進行微調,測試DINOv3的開箱即用能力。我們還發現擴大DPT頭部有助于獲得DINOv3 7B更大特征的全部潛力。更多細節請參見附錄D.11。
數據集和指標 我們在5個真實世界數據集上評估我們的模型(NYUv2 (Silberman et al., 2012)、KITTI (Geiger et al., 2013)、ETH3D (Sch?ps et al., 2017)、ScanNet (來自Ke et al. (2025))和DIODE (Vasiljevic et al., 2019)),采用零樣本尺度不變深度設置,類似于Ranftl et al. (2020);Ke et al. (2025)。我們報告標準指標絕對相對誤差(ARel)(越低越好)和δ1\delta_1δ1?(越高越好)。有關這些指標的描述,請參見Yang et al. (2024a)。
表12:相對單目深度估計的最先進系統比較。通過將DINOv3與Depth Anything V2 (Yang et al., 2024b)結合,我們獲得了相對深度估計的最先進模型。
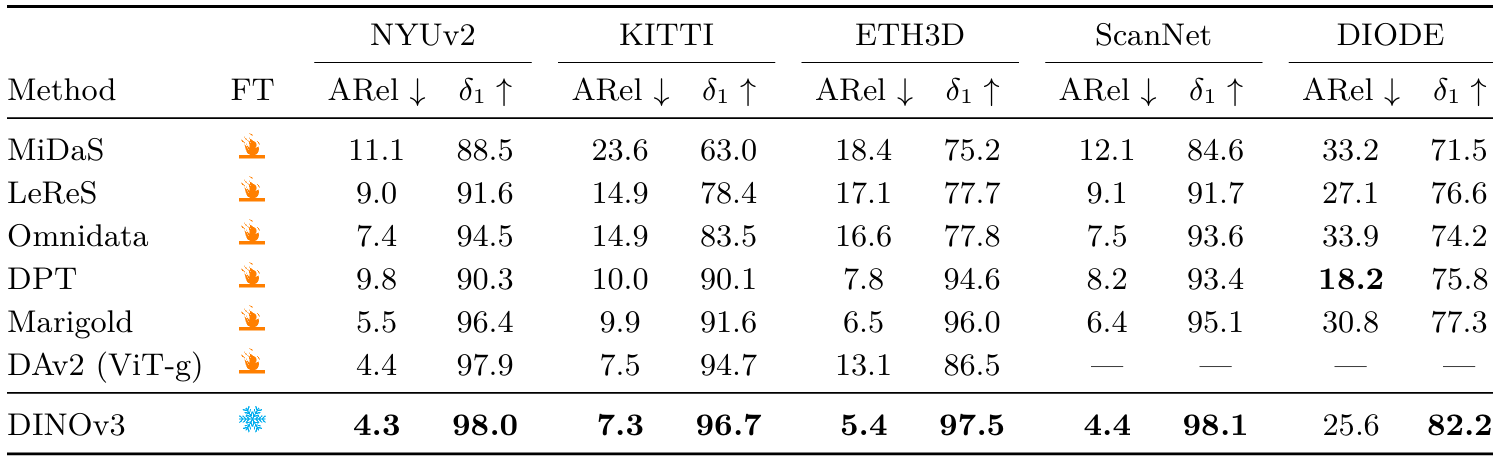
結果(表12) ?我們將我們的模型與相對深度估計的最先進技術進行比較:MiDaS (Ranftl et al., 2020)、LeReS (Yin et al., 2021)、Omnidata (Eftekhar et al., 2021)、DPT (Ranftl et al., 2021)、集成版本的Marigold (Ke et al., 2025)和DAv2。我們的深度估計模型在所有數據集上達到了新的最先進水平,僅在DIODE的ARel上略遜于DPT。值得注意的是,這使用了凍結的骨干網絡,而所有其他基線都需要對骨干網絡進行微調以進行深度估計。此外,這驗證了DINOv3繼承了DINOv2強大的模擬到現實能力,這是一種理想特性,為下游任務使用合成生成的訓練數據打開了可能性。
6.3.4 與DINOv3結合的視覺幾何基礎Transformer
最后,我們考慮使用最近的視覺幾何基礎Transformer (VGGT) (Wang et al., 2025)進行3D理解。在大量3D標注數據上訓練,VGGT學習在單次前向傳播中估計場景的所有重要3D屬性,如相機內參和外參、點圖或深度圖。使用簡單、統一的管道,它在許多3D任務上達到最先進結果,同時比專用方法更高效——這構成了3D理解領域的重大進展。
實現 VGGT使用DINOv2預訓練骨干網絡來獲取場景不同視圖的表示,然后與Transformer融合。在這里,我們簡單地將DINOv2骨干網絡替換為DINOv3,使用我們的ViT-L變體(見第7節)來匹配原始工作中的DINOv2 ViT-L/14。我們運行與VGGT相同的訓練管道,包括對圖像骨干網絡的微調。我們將圖像分辨率從518×518518\times518518×518改為592×592592\times592592×592,以適應DINOv3的patch大小16,并保持結果與VGGT可比。我們還采用了少量超參數更改,詳見附錄D.12。
數據集和指標? 按照Wang et al. (2025),我們在Rel0K (Zhou et al., 2018)和CO3Dv2 (Reizenstein et al., 2021)數據集上評估相機姿態估計,在DTU (Jensen et al., 2014)上評估密集多視圖估計,在ScanNet-1500 (Dai et al., 2017)上評估兩視圖匹配。對于相機姿態估計和兩視圖匹配,我們報告標準曲線下面積(AUC)指標。對于多視圖估計,我們報告預測到真實值的最小L2距離作為"準確性(Accuracy)“,真實值到預測的最小L2距離作為"完整性(Completeness)”,以及它們的平均值作為"總體(Overall)"。有關方法和評估的詳細信息,請參見Wang et al. (2025)。
表13:使用視覺幾何基礎Transformer (VGGT) (Wang et al., 2025)進行3D理解。僅通過在VGGT管道中將DINOv2替換為DINOv3 ViT-L作為圖像特征提取器,我們就能夠在各種3D幾何任務上獲得最先進結果。我們重現了Wang et al. (2025)的基線結果。我們還報告了使用真實相機信息的方法,用*標記。相機姿態估計結果以AUC@30報告。
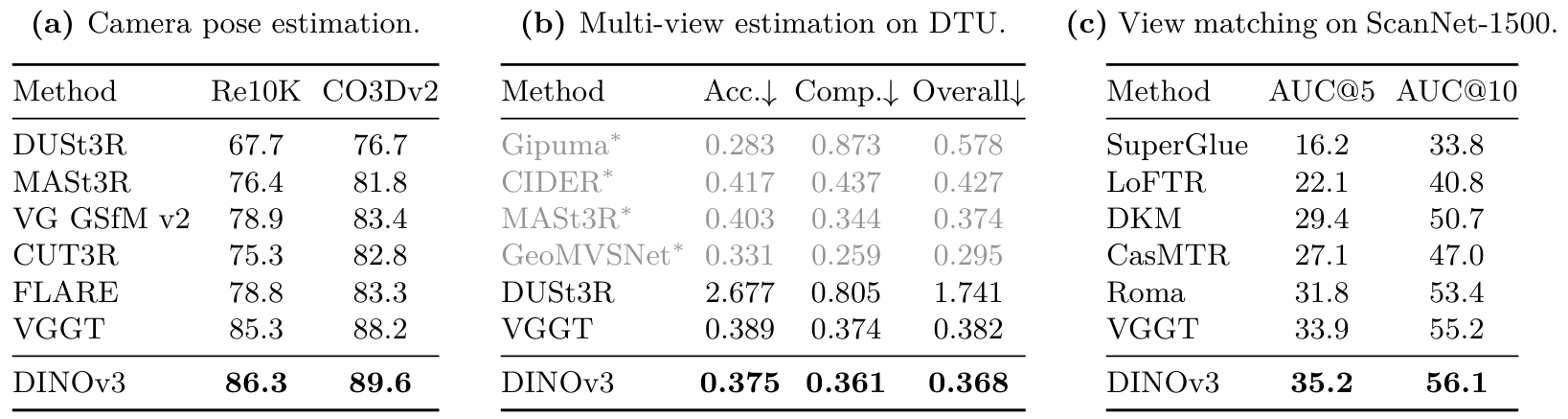
結果(表13) ?我們發現,配備DINOv3的VGGT在所有三個考慮的任務上進一步改進了VGGT設定的先前最先進水平——使用DINOv3帶來了清晰且一致的增益。考慮到我們僅對DINOv3應用了最小調整,這是令人鼓舞的。這些任務涵蓋了不同層次的視覺理解:場景內容的高級抽象(相機姿態估計)、密集幾何預測(多視圖深度估計)和細粒度像素級對應(視圖匹配)。結合之前在對應估計(第6.1.3節)和深度估計(第6.3.3節)上的結果,我們將此視為DINOv3作為3D任務基礎的強適用性的進一步實證證據。此外,我們預計使用更大的DINOv3 7B模型會帶來進一步的改進。
七、評估完整的DINOv3模型家族
在本節中,我們提供了對我們從70億參數模型蒸餾出的模型家族的定量評估(見第5.2節)。該家族包括基于視覺Transformer (ViT)和ConvNeXt (CNX)架構的變體。我們在圖16a中提供了所有模型的詳細參數計數和推理FLOPs。這些模型覆蓋了廣泛的計算預算,以適應各種用戶和部署場景。我們對所有ViT(第7.1節)和ConvNeXt變體進行了全面評估,以評估它們在各種任務上的性能。
圖2提供了DINOv3家族與其他模型集合的概覽比較。DINOv3家族在密集預測任務上顯著優于所有其他模型。這包括從監督骨干網絡(如AM-RADIO和PEspatial)蒸餾出的專用模型。同時,我們的模型在分類任務上取得了類似的結果,使其成為各種計算預算下的最佳選擇。
在第7.1節中,我們詳細介紹了我們的ViT模型,并將其與其他開源替代方案進行比較。然后,在第7.2節中,我們討論了ConvNeXt模型。最后,按照第5.3節,我們訓練了一個與我們的ViT-L模型輸出對齊的文本編碼器。我們在第7.3節中展示了該模型的多模態對齊結果。
7.1 適用于各種用例的視覺Transformer
我們的ViT家族涵蓋了從緊湊型ViT-S到大型8.4億參數ViT-H+模型的架構。前者設計用于在資源受限的設備(如筆記本電腦)上高效運行,后者則為更苛刻的應用提供最先進性能。我們將我們的ViT模型與相應規模的最佳開源圖像編碼器進行比較,即DINOv2 (Oquab et al., 2024)、SigLIP 2 (Tschannen et al., 2025)和感知編碼器(Bolya et al., 2025)。為了公平比較,我們確保所有模型的輸入序列長度相同。具體來說,對于patch大小為16的模型,我們輸入大小為512×512512\times512512×512的圖像,而當模型使用patch大小14時,輸入大小為448×448448\times448448×448。
我們的實證研究清楚地表明,DINOv3模型在密集預測任務上始終優于其對應模型。最值得注意的是,在ADE20k基準測試中,DINOv3 ViT-L模型比最佳競爭對手DINOv2提高了超過6 mIoU點。ViT-B變體比次佳競爭對手提高了約3 mIoU點。這些顯著的改進突顯了DINOv3局部特征在捕獲細粒度空間細節方面的有效性。此外,在深度估計任務上的評估也顯示出比競爭方法持續的性能提升。
表14:將我們的模型家族與同等規模的開源替代方案進行比較。我們在一組代表性的全局和密集基準測試上展示了我們的ViT-{S、S+、B、L、H+}模型:分類(IN-ReaL、IN-R、ObjectNet)、檢索(Oxford-H)、分割(ADE20k)、深度(NYU)、跟蹤(DAVIS,960px)和關鍵點匹配(NAVI、SPair)。我們匹配不同patch大小模型的patch token數量,以確保公平比較。
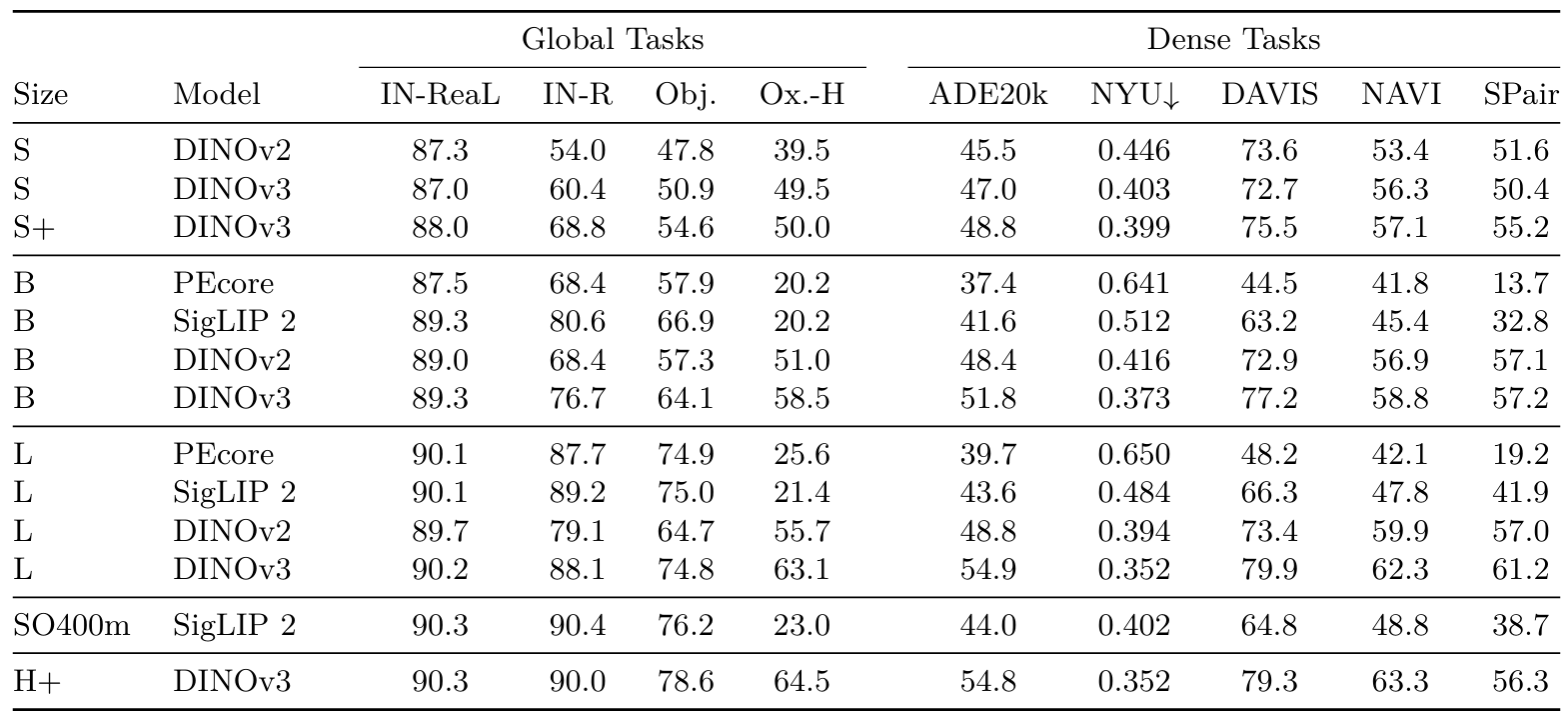
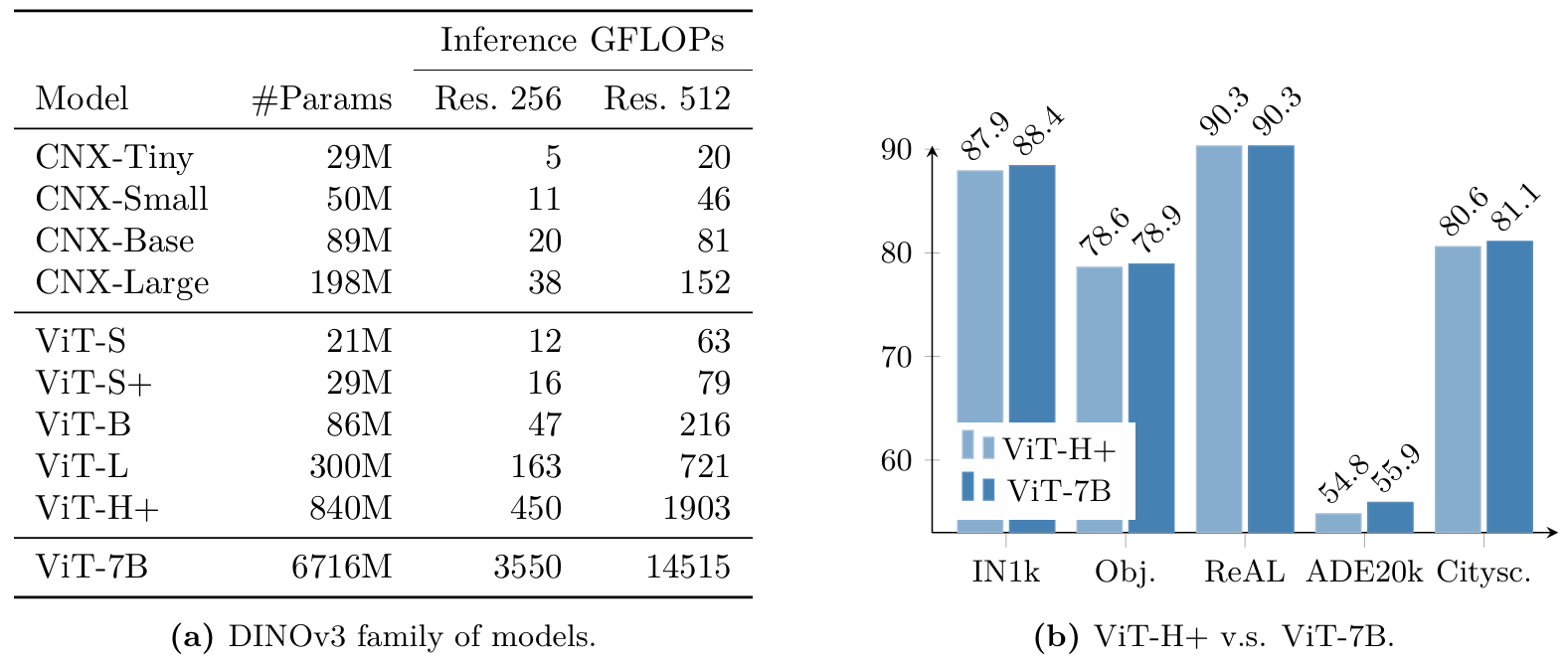
圖16: (a) 蒸餾模型特性的展示。CNX代表ConvNeXT。我們展示了每個模型的參數數量和在256×256256\times256256×256和512×512512\times512512×512大小圖像上估計的GFLOPs。(b) 我們將DINOv3 ViT-H+與其70億參數大小的教師進行比較;盡管參數少近10倍,ViT-H+在性能上接近DINOv3 7B。
這突顯了DINOv3家族在不同密集視覺問題上的多功能性。重要的是,我們的模型在ObjectNet和ImageNet-1k等全局識別基準測試上取得了具有競爭力的結果。這表明增強的密集任務性能不會以犧牲全局任務準確性為代價。這種平衡證實了DINOv3模型提供了穩健且全面的解決方案,在密集和全局視覺任務上均表現出色,沒有妥協。
另一方面,我們還想驗證我們蒸餾的最大模型是否捕獲了教師的所有信息。為此,我們將最大的ViT-H+與7B教師進行了比較。如圖16b所示,最大的學生模型達到了與大8倍的ViT-7B模型相當的性能。
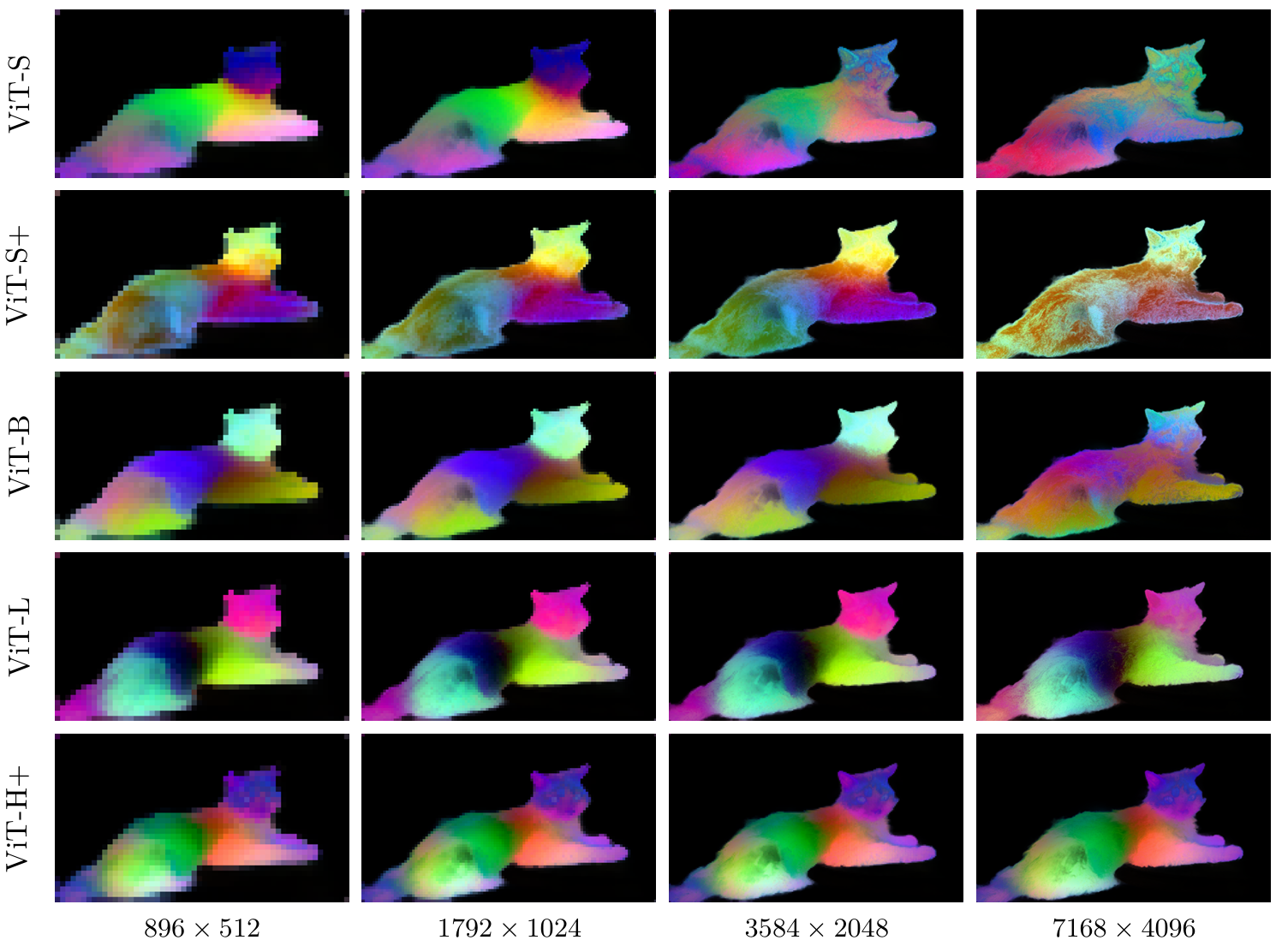
圖17: DINOv3 ViT模型家族在多分辨率下的特征穩定性。從上到下:ViT-S、S+、B、L、H+。我們在多個分辨率下對圖像進行推理,然后對在1792×10241792\times10241792×1024圖像(112×64圖像tokens)上計算的特征進行主成分分析。然后,我們將所有分辨率的特征投影到我們映射到RGB空間進行可視化的主成分5-7上。雖然模型在所有分辨率下都可用,但我們觀察到特征在大范圍分辨率內保持一致,然后才開始漂移:例如,ViT-S+特征在896×512896\times512896×512和3584×20483584\times20483584×2048輸入之間保持穩定,而ViT-L在最大分辨率7168×40967168\times40967168×4096下才開始輕微漂移。ViT-H+在整個測試范圍內保持穩定。
這一結果不僅驗證了我們蒸餾過程的有效性,還表明在高質量教師的指導下,較小的模型可以學習提供相當水平的性能。這一發現強化了我們的信念,即訓練非常大的模型有利于更廣泛的社區。較大模型的優勢可以成功蒸餾到更高效、更小的模型中,而質量幾乎沒有或沒有損失。
7.2 適用于資源受限環境的高效ConvNeXt
在本節中,我們評估了從7B教師蒸餾出的ConvNeXt (CNX)模型的質量。ConvNeXt模型在FLOPs方面非常高效,非常適合在針對卷積計算優化的設備上部署。此外,Transformer模型通常不適合量化(Bondarenko et al., 2021),而卷積網絡的量化是一個被廣泛研究的主題。我們蒸餾了T、S、B和L規模的CNX架構(見圖16a),并將它們與原始ConvNeXt模型(Liu et al., 2022)進行比較。這些基線模型在ImageNet-1k上實現了高性能,因為它們使用ImageNet-22k標簽以監督方式訓練,因此代表了一個強有力的競爭對手。對于此實驗,我們在輸入分辨率256和512下提供全局任務的結果,在ADE20k上使用分辨率512,在NYU上使用分辨率640。
表15:評估我們的蒸餾DINOv3 ConvNeXt模型。我們將我們的模型與在ImageNet-22k上監督訓練的現成ConvNeXt (Liu et al., 2022)進行比較。對于全局任務,我們在輸入分辨率256和512下提供結果,因為我們發現監督模型在分辨率512下顯著退化。
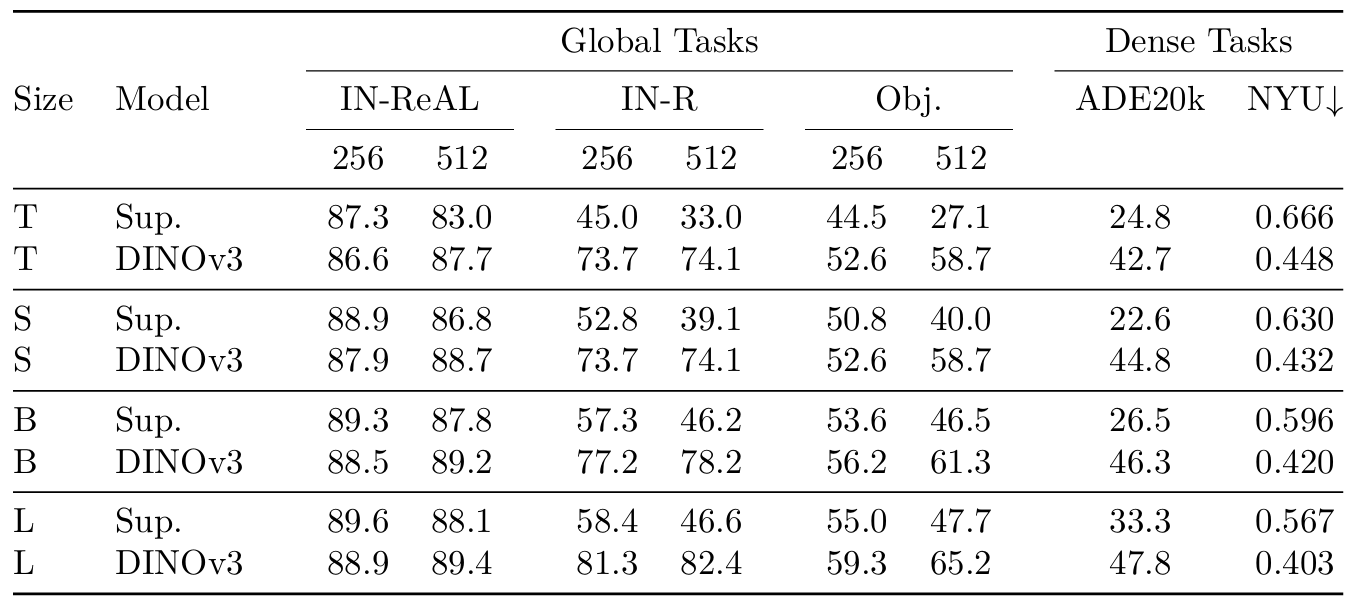
結果(表15)?我們發現,在分布內圖像分類上,我們的模型在分辨率256下略遜于監督模型(例如,CNX-T的IN-ReaL低-O.7)。然而,在分辨率512下趨勢逆轉,監督ConvNeXt顯著退化,而我們的模型隨著輸入分辨率的增加而擴展。對于分布外分類(IN-R、ObjectNet),兩個模型家族在所有規模上都存在顯著差距——這證明了DINOv3 CNX模型的魯棒性。此外,DINOv3模型在密集任務上提供了非常大的改進。實際上,對于CNX-T,我們的模型產生了+17.9 mIoU(42.7對24.8)的改進,對于CNX-L,我們的模型獲得了+14.5 mIoU(47.8對33.3)的改進。高性能和計算效率的結合使蒸餾的ConvNeXt模型在資源約束至關重要的實際應用中特別有前景。除此之外,將ViT-7B模型蒸餾成更小的ConvNeXt模型特別令人興奮,因為它連接了兩種根本不同的架構。雖然ViT-7B基于帶有CLS token的Transformer塊,但ConvNeXt依賴于沒有CLS token的卷積操作,使得這種知識轉移并非易事。這一成就突顯了我們蒸餾過程的多功能性和有效性。
7.3 基于DINOv3的dino.txt的零樣本推理
如第5.3節所述,我們訓練了一個文本編碼器,以將蒸餾的DINOv3 ViT-L模型的CLS token和輸出patch與文本對齊,遵循dino.txt (Jose et al., 2025)的配方。我們在標準基準測試上評估全局和patch級別對齊的質量。我們使用CLIP協議(Radford et al., 2021)報告在ImageNet-1k、ImageNet-Adversarial、ImageNet-Rendition和ObjectNet基準測試上的零樣本分類準確率。對于圖像-文本檢索,我們在COCO2017數據集(Tsung-Yi et al., 2017)上進行評估,并報告圖像到文本(I→T\mathrm{I}\rightarrow\mathrm{T}I→T)和文本到圖像(T→I\mathrm{T}\rightarrow\mathrm{I}T→I)任務的Recall@1。為了探測patch級對齊的質量,我們在開放詞匯分割任務上評估我們的模型,使用常見基準測試ADE20k和Cityscapes,我們報告mIoU指標。
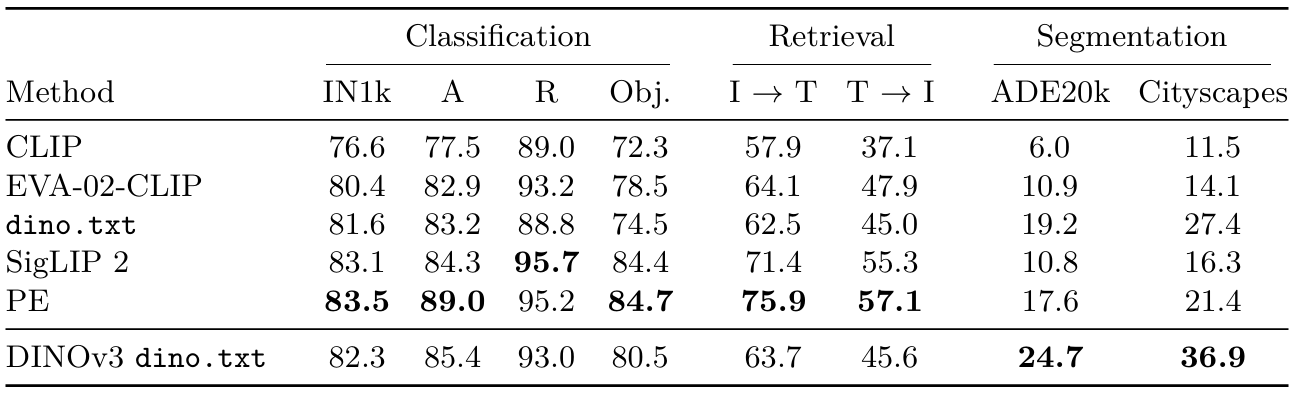
結果(表16)?我們將我們的文本對齊DINOv3 ViT-L與同規模的競爭對手進行比較。與Jose et al. (2025)相比,后者將DINOv2與文本對齊,DINOv3在所有基準測試上都帶來了顯著更好的性能。在全局對齊任務上,我們的表現優于原始CLIP (Radford et al., 2021)和EVA-02-CLIP (Sun et al., 2023)等強大基線,但略遜于SigLIP2 (Tschannen et al., 2025)和感知編碼器(Bolya et al., 2025)。在密集對齊任務上,由于DINOv3的干凈特征圖,我們的文本對齊模型在兩個具有挑戰性的基準測試ADE20k和Cityscapes上表現出色。
表16:將我們的文本對齊DINOv3 ViT-L與最先進技術進行比較。我們的模型在密集對齊任務上實現了出色的性能,同時在全局對齊任務上保持競爭力。所有比較模型都是ViT-L大小,并在相同的576序列長度上運行。
八、DINOv3在地理空間數據上的應用
我們的自監督學習配方是通用的,可以應用于任何圖像領域。在本節中,我們通過為衛星圖像構建DINOv3 7B模型來展示這種通用性,衛星圖像具有與DINOv3最初開發所使用的網絡圖像非常不同的特征(例如對象紋理、傳感器噪聲和焦距視圖)。
8.1 預訓練數據和基準測試
我們的衛星DINOv3 7B模型在SAT-493M上進行預訓練,這是一個由4.93億張從Maxar RGB正射校正影像中隨機采樣的512×512512\times512512×512圖像組成的數據集,分辨率為0.6米。我們使用與網絡DINOv3 7B模型完全相同的超參數集,除了針對衛星圖像調整的RGB均值和標準差歸一化,以及訓練長度。與網絡模型類似,我們的衛星模型訓練流程包括10萬次迭代的初始預訓練(使用全局裁剪,256×256256\times256256×256),隨后是1萬次迭代的Gram正則化,最后以分辨率512進行8千步的高分辨率微調。與網絡模型類似,我們將7B衛星模型蒸餾成更易于管理的ViT-Large模型,以促進其在低預算環境中的使用。
我們在多個地球觀測任務上評估DINOv3衛星和網絡模型。對于全球樹冠高度映射任務,我們使用附錄D.13中描述的Satlidar數據集,該數據集包含一百萬張具有LiDAR真實值的512×512512\times512512×512圖像,按8:1:1的比例分為訓練/驗證/測試集。這些分割包括Tolan et al. (2024)使用的Neon和Sao Paulo數據集。對于國家級樹冠高度映射,我們在Open-Canopy (Fogel et al., 2025)上進行評估,該數據集結合了法國87,000平方公里范圍內的SPOT 6-7衛星圖像和航空LiDAR數據。由于該數據集中的圖像有4個通道(包括額外的紅外(IR)通道),我們通過取patch嵌入模塊權重中三個通道的平均值并將其作為第四個通道添加到權重中來調整我們的骨干網絡。我們在調整為1667大小的512×512512\times512512×512圖像裁剪上訓練了一個DPT解碼器,以匹配Maxar地面采樣分辨率。
語義地理空間任務通過GEO-Bench (Lacoste et al., 2023)進行評估,該基準包含六個分類任務和六個分割任務,涵蓋各種空間分辨率和光學波段。GEO-Bench任務多種多樣,包括檢測屋頂安裝的光伏系統、分類局部氣候區、測量森林砍伐驅動因素以及檢測樹冠。對于高分辨率語義任務,我們考慮土地覆蓋分割數據集LoveDA (Wang et al., 2022a)、對象分割數據集iSAID (Zamir et al., 2019)和水平檢測數據集DIOR (Li et al., 2020)。
8.2 樹冠高度估計
從衛星圖像估計樹冠高度是一項具有挑戰性的度量任務,需要在存在坡度、視角幾何、太陽角度、大氣散射和量化偽影的隨機變化的情況下準確恢復連續的空間結構。這項任務對于全球碳監測以及森林和農業管理至關重要(Harris et al., 2021)。繼Tolan et al. (2024)之后,他們是首個利用SSL骨干網絡在衛星圖像上進行此任務的工作,我們在SatLidarlM訓練集上在凍結的DINOv3上訓練DPT頭部,然后在SatLidarlM驗證集上的i.i.d.樣本以及包括SatLidarlM測試集、Neon和Sao Paulo在內的分布外測試集上進行評估。我們還在Open-Canopy數據集上進行訓練和評估。
表17:不同骨干網絡在高分辨率樹冠高度預測中的評估。所有模型都使用DPT解碼器進行訓練。結果要么是解碼器在SatLidar上訓練并在IID樣本(SatLidar Val)和OOD測試集(SatLidar Test、Neon和Sao Paulo)上評估的實驗,要么是解碼器在Open-Canopy數據集上訓練和評估的實驗。我們列出平均絕對誤差(MAE)和Tolan et al. (2024)的塊R2指標。為完整性起見,我們還評估了Tolan et al. (2024)的原始解碼器,該解碼器在Neon數據集上訓練(由*表示)
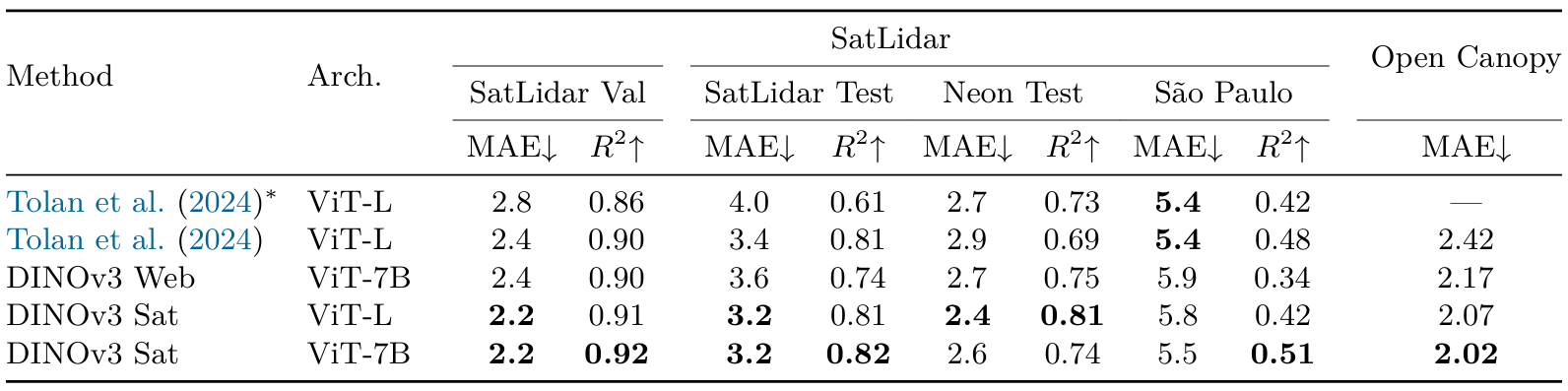
結果(表17)?我們比較了不同的SSL骨干網絡,用"DINOv3 Sat"表示在SAT-493M數據集上訓練的模型,用"DINOv3 Web"表示在LVD-1689M上訓練的模型(見第3.1節)。可以看出,DINOv3衛星模型在大多數基準測試上取得了最先進的性能。我們的7B衛星模型在SatLidar1M驗證集、SatLidar1M測試集和Open-Canopy上建立了新的最先進技術,將MAE分別從2.4降至2.2、從3.4降至3.2、從2.42降至2.02。這些結果表明DINOv3訓練配方是通用的,可以有效地直接應用于其他領域。有趣的是,我們蒸餾的ViT-L衛星模型與其7B對應模型表現相當,在SatLidar1M和Open-Canopy上取得可比結果,而在Neon測試集上表現意外地更好,達到最低MAE為2.4,相比之下7B模型為2.6,Tolan et al. (2024)為2.9。我們的DINOv3 7B網絡模型在基準測試上達到了不錯的性能,在SatLidar1M驗證集、Neon和Open-Canopy上優于Tolan et al. (2024),但落后于衛星模型。這突顯了特定領域預訓練對于樹冠高度估計等物理基礎任務的優勢,其中傳感器特定先驗和輻射一致性很重要。
8.3 與地球觀測最先進技術的比較
我們在表18和表19中比較了不同方法在地球觀測任務上的性能。凍結的DINOv3衛星和網絡模型在15個分類、分割和水平對象檢測任務中的12個上建立了新的最先進技術成果。我們的Geo-Bench結果超過了先前的模型,包括Prithvi-v2 (Szwarcman et al., 2024)和DOFA (Xiong et al., 2024),這些模型對Sentinel-2和Landsat任務使用6+波段以及特定任務的微調(表18)。盡管使用僅RGB輸入的凍結骨干網絡,DINOv3衛星模型在三個未飽和分類任務和六個分割任務中的五個上優于先前方法。有趣的是,DINOv3 7B網絡模型在這些基準測試上非常有競爭力。它在許多GEO-Bench任務以及大規模、高分辨率遙感分割和檢測基準測試上取得了相當或更強的性能。如表18和表19所示,凍結的DINOv3網絡模型在Geo-Bench任務以及LoveDA和DIOR數據集上的分割和檢測任務上建立了新的領先結果。
這些發現對地理空間基礎模型的設計具有更廣泛的意義。最近的研究強調了啟發式技術,如多時相聚合、多傳感器融合或結合衛星特定元數據(Brown et al., 2025; Feng et al., 2025)。我們的結果表明,通用SSL可以匹配或超過依賴精確對象邊界(分割或對象檢測)任務的衛星特定方法。這支持了新興的證據,即領域無關的預訓練即使在特定下游領域也能提供強大的泛化能力(Lahrichi et al., 2025)。
總體而言,我們的結果表明了特定領域預訓練的任務相關優勢。DINOv3衛星模型在深度估計等度量任務上表現出色,利用了衛星特定先驗。相比之下,DINOv3網絡模型通過多樣化、通用的表示在語義地理空間任務上取得了最先進成果。兩種模型的互補優勢展示了DINOv3 SSL范式的廣泛適用性和有效性。
表18:將我們的DINOv3模型與Geo-Bench任務中的強大基線DOFA (Xiong et al., 2024)、Prithvi-v2 (Szwarcman et al., 2024)和Tolan et al. (2024)進行比較。雖然Prithvi-v2和DOFA利用所有可用光學波段,但我們的模型僅使用RGB輸入就取得了顯著更好的性能。
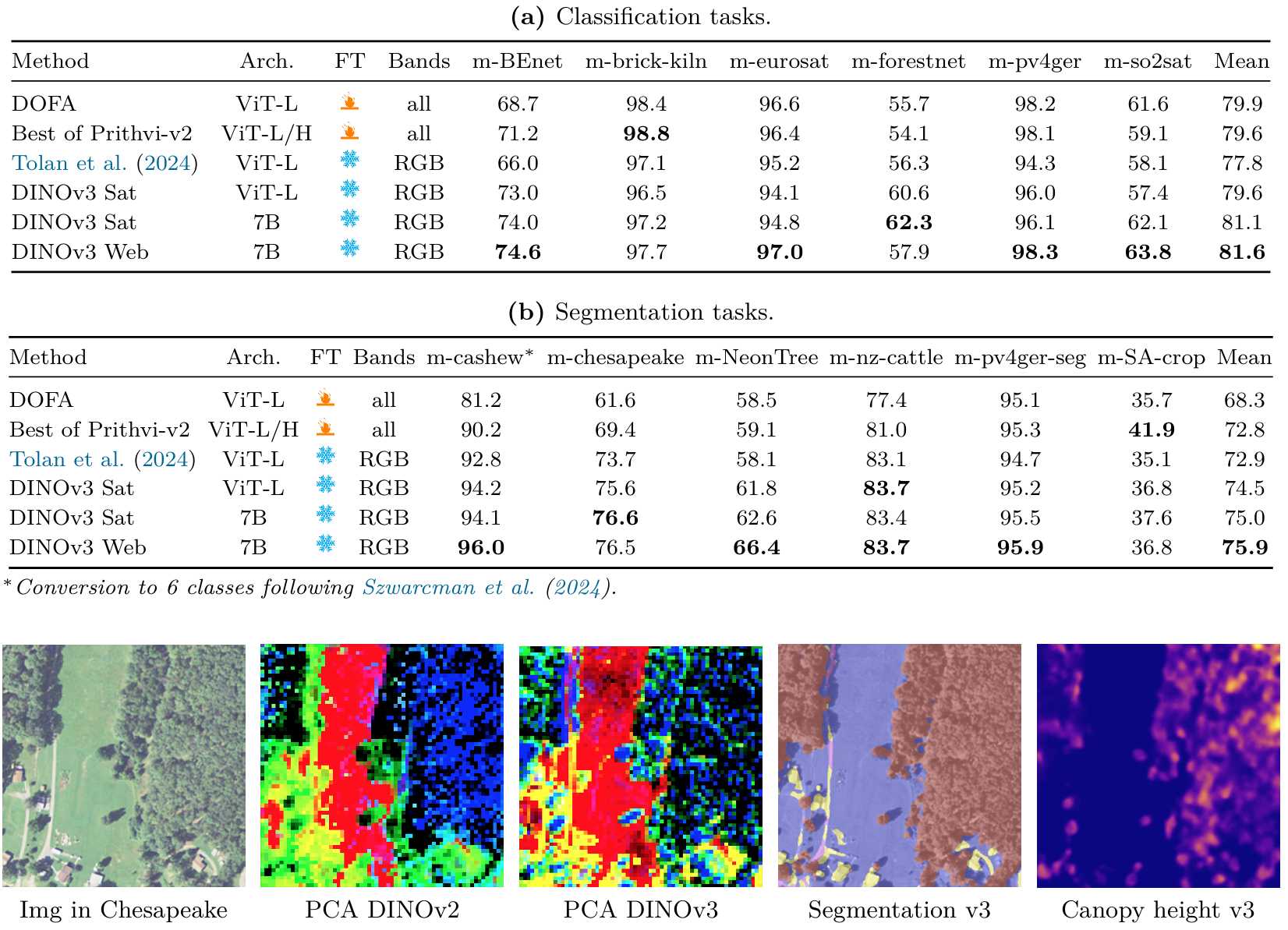
表19:我們將DINOv3與Prithvi-v2 (Szwarcman et al., 2024)、BillionFM (Cha et al., 2024)和SkySense V2 (Zhang et al., 2025)在高分辨率語義地理空間任務上的最先進模型進行比較。我們報告LoveDA(1024×1024\times1024×)和iSAID(896×896\times896×)分割數據集的mIoU,以及DIOR(800×800\times800×)檢測數據集的mAP。
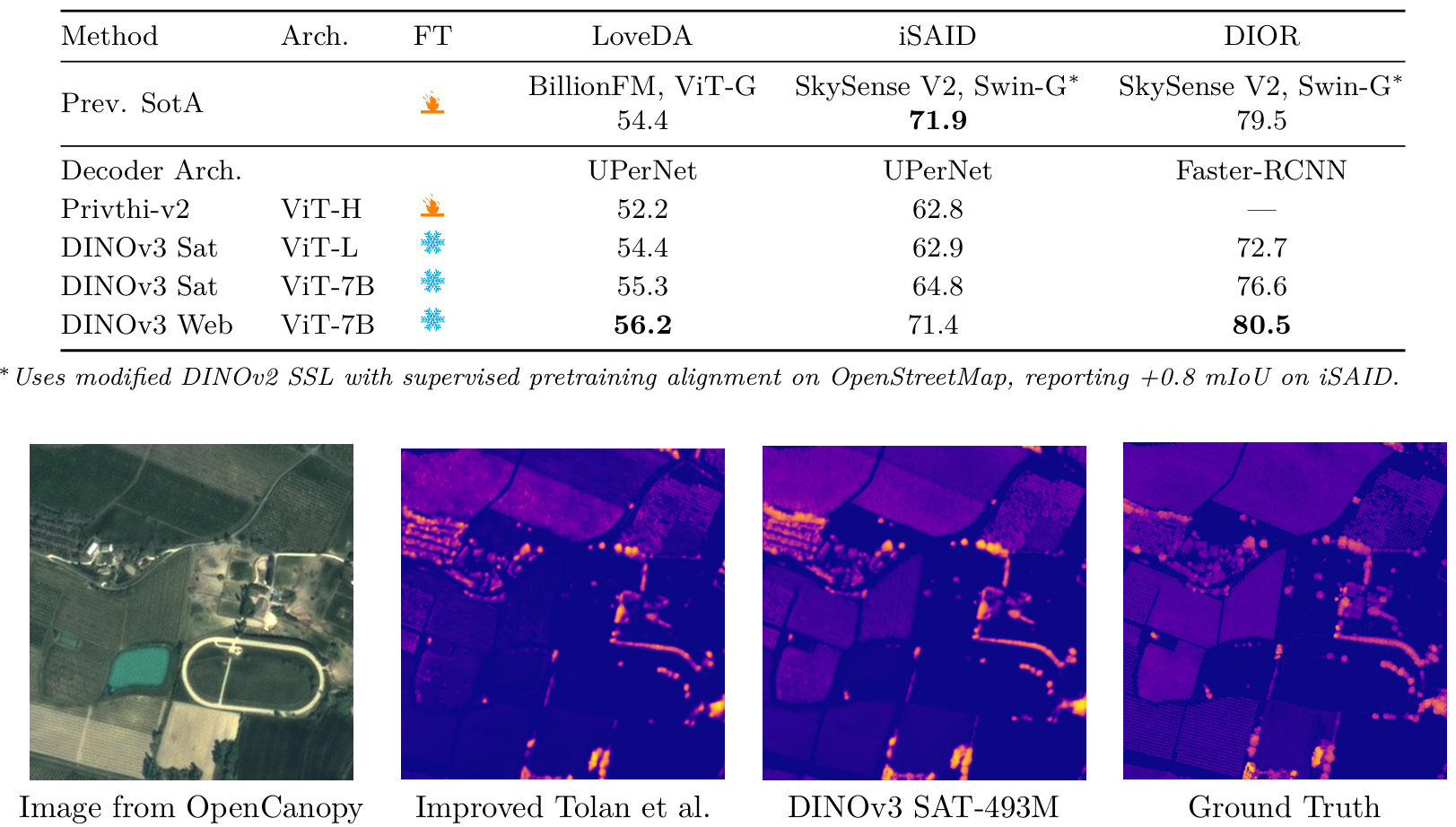
圖19: DINOv3 7B衛星模型與Tolan et al. (2024)在Open Canopy數據集上的定性比較。對于兩個模型,解碼器都在448×448448\times448448×448輸入圖像上訓練。可以看出,DINOv3生成了更準確的地圖,例如田地樹木的準確高度。
九、環境影響
為了估計我們預訓練的碳排放,我們遵循先前在自然語言處理(Strubell et al., 2019; Touvron et al., 2023)和SSL (Oquab et al., 2024)工作中使用的方法。我們固定所有外生變量的值,即電源使用效率(PUE)和電網的碳強度因子,使用與Touvron et al. (2023)相同的值,即我們假設PUE為1.1,美國平均碳強度因子為0.385 kg CO?eq/KWh。對于GPU的功耗,我們采用其熱設計功耗:A100 GPU為400W,H100 GPU為700W。我們在表20中報告了ViT-7B預訓練的計算細節。作為參考,我們提供了DINOv2和MetaCLIP的類似數據。作為另一個比較點,訓練一個DINOv3模型所需的能量(47 MWh)大致相當于普通電動車行駛240,000公里所需的能量。
整個項目的碳足跡? 為了計算整個項目的碳足跡,我們使用了總計900萬GPU小時的粗略估計。使用上述相同的電網參數,我們估計總足跡約為2600 tCO?eq。相比之下,巴黎和紐約之間的波音777往返航班對應約560 tCO?eq。假設每天12次這樣的航班,我們項目的環境影響代表了這兩個城市之間一天所有航班的一半。此估計僅考慮為GPU供電的電力,忽略了其他排放,如冷卻、制造和處置。
表20:模型訓練的碳足跡。我們報告了重現完整模型預訓練的潛在碳排放,使用1.1的PUE和0.385 kg CO?eq/KWh的碳強度因子計算。

十、結論
DINOv3代表了自監督學習領域的重大進步,展示了徹底改變跨各種領域學習視覺表示方式的潛力。通過精心的數據準備、設計和優化來擴展數據集和模型規模,DINOv3展示了自監督學習消除對手工標注依賴的能力。Gram錨定方法的引入有效地緩解了長時間訓練過程中密集特征圖的退化問題,確保了穩健可靠的性能。
結合事后優化策略的實施,如高分辨率后訓練和蒸餾,我們在無需對圖像編碼器進行微調的情況下,在廣泛視覺任務上實現了最先進的性能。DINOv3視覺模型套件不僅設定了新的基準,還為各種資源約束、部署場景和應用用例提供了多功能解決方案。DINOv3取得的進展證明了自監督學習在推進計算機視覺及更廣泛領域的最先進技術方面的承諾。
附錄
A 大規模訓練中的偽影和異常值
本節討論了在大規模語言模型(LLM)(An et al., 2025)和視覺領域(Darcet et al., 2024)的大模型訓練中最近觀察到的偽影和異常值的出現。借鑒An等人(2025)的定義,異常值通常被定義為網絡激活值,其值顯著偏離其分布的平均值。在DINOv3的訓練過程中,我們識別出不同層次的此類異常值:一些出現在補丁級別,而另一些則出現在訓練和結果中。我們還討論了我們嘗試修復它們的不同方法以及初步結論。
A.1 高范數補丁異常值
Darcet等人(2024)發現補丁異常值對DINOv2的性能有負面影響。這些異常值主要表現為高范數標記(token),通常位于圖像的低信息背景區域。這些標記被觀察到在補丁與CLS標記之間的內部通信中起關鍵作用。此外,這種現象也影響其他模型,無論是否經過監督訓練,例如CLIP (Radford et al., 2021)。當擴展到7B模型時,我們觀察到此類高范數補丁的出現,主要集中在背景區域。在本節中,我們展示了針對訓練了15萬次迭代的7B模型的結果,盡管有限,但為我們提供了指導決策的初步信號。我們在圖2Oa的"O"列中繪制了輸出補丁范數(在層歸一化之前),高范數補丁以黃色顯示,出現在天空和其他低信息區域。
標記寄存器 為了緩解此類標記異常值的出現,(Darcet et al., 2024)提出了一種簡單而有效的解決方案:在ViT的輸入序列中引入額外的標記,稱為寄存器(registers)。它們的作用是接管補丁與CLS之間的內部通信。根據結論,我們使用了4個寄存器,并且由于實驗成本高,未進行進一步的消融實驗。圖2Oa展示了該策略的實際應用示例,我們觀察到高范數異常值被消除,這通過相應的范數分布直方圖得到進一步證實。此外,我們在圖2Ob中定量觀察了在ImageNet-1k (IN1k)基準測試中引入額外寄存器標記的好處。
在注意力機制中整合偏置 An等人(2025)的最新工作研究了在LLM領域中不同模型和架構中出現的異常值。作者分析了不同類型的異常值,這些異常值被觀察到與注意力機制有內在聯系。這些方法似乎相關且只需對注意力進行最小改動,特別是顯式的固定偏置,我們稱之為"值門控"(value gating),以及注意力偏置策略。值門控策略相當于向注意力輸出添加一個可學習的值偏置v′∈Rd\mathbf{v}^{\prime}\in\mathbb{R}^{d}v′∈Rd,具體通過重新定義注意力機制為:
Attn(Q,K,V;k′,v′)=softmax(Q[KT]d)V+v′,\mathrm{Attn}(Q,K,V;\mathbf{k}^{\prime},\mathbf{v}^{\prime})=\mathrm{softmax}(\frac{Q[K^{T}]}{\sqrt{d}})V+\mathbf{v}^{\prime},Attn(Q,K,V;k′,v′)=softmax(d?Q[KT]?)V+v′,
其中Q,K,V∈RT×dQ,K,V\,\in\,\mathbb{R}^{T\times d}Q,K,V∈RT×d分別為查詢、鍵和值矩陣,d為隱藏空間的維度。或者,注意力偏置(定義在公式5中)包括在鍵和值矩陣中分別整合兩個可學習的偏置項k′,v′∈Ra\mathbf{k}^{\prime},\mathbf{v}^{\prime}\in\mathbb{R}^{a}k′,v′∈Ra。其定義如下:
Attn(Q,K,V;k′,v′)=softmax(Q[KTk′]d)[Vv′].\mathrm{Attn}(Q,K,V;\mathbf{k}^{\prime},\mathbf{v}^{\prime})=\mathrm{softmax}(\frac{Q[K^{T}\mathbf{k}^{\prime}]}{\sqrt{d}})\left[V\atop\mathbf{v}^{\prime}\right].Attn(Q,K,V;k′,v′)=softmax(d?Q[KTk′]?)[v′V?].
我們在圖2Oa中觀察到,值門控策略顯著改變了補丁范數的分布,導致總體范數值更高并消除了明顯的異常值。雖然注意力機制減輕了高范數標記的存在,但并未完全解決問題,因為與使用寄存器標記的結果相比,仍有一些高范數補丁持續存在——如頂行圖像所示。值得注意的是,最佳性能是通過引入寄存器標記實現的,這就是為什么我們在本文報告的所有實驗中采用此策略。
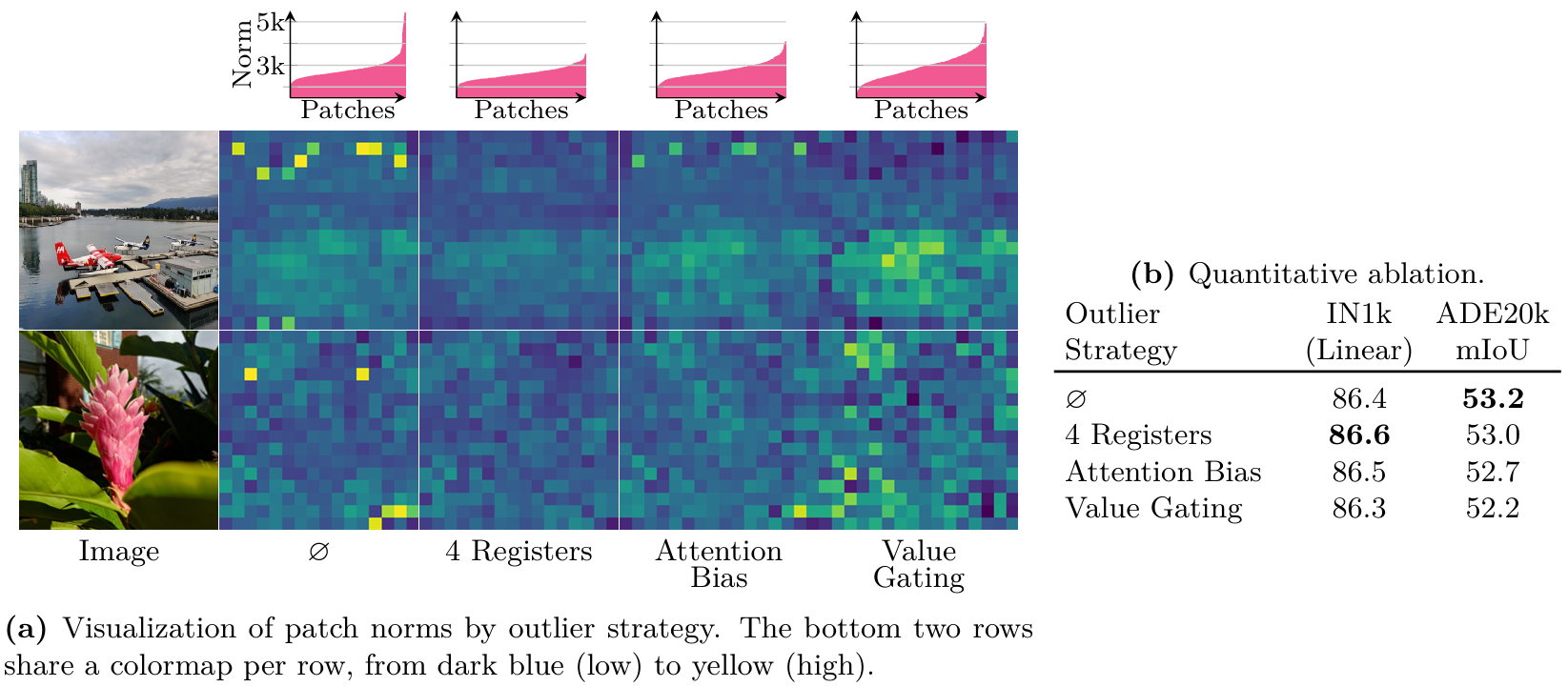
圖20:不同策略對高范數補丁異常值影響的定性和定量評估。我們使用按照我們的配方訓練了15萬次迭代的7B模型生成結果,無任何高范數處理策略"O",使用四個寄存器標記(Darcet et al., 2024),或使用注意力偏置和值門控策略(An et al., 2025)。在(a, 第一行)中,我們繪制了為三張圖像計算的輸出補丁范數的分布(按升序排列)。我們還可視化了每張圖像的輸出補丁范數(底部兩行),使用相同的顏色映射——最小值和最大值是針對不同異常值策略在每張圖像上計算的。
A.2 特征維度異常值
將額外的寄存器引入模型架構有效地解決了高范數補丁異常值問題。然而,在訓練7B模型時,我們觀察到一種不同類型的異常值,它不是跨補丁出現的,而是出現在學習表示的特征(通道)維度中。具體來說,對跨Transformer層和訓練迭代的補丁激活的分析顯示,一小部分特征維度達到異常大的幅度,即使跨補丁的范數保持穩定。有趣的是,這些特征維度異常值在不同補丁和圖像中表現出一致的高值,這種行為與(An et al., 2025)中報告的觀察結果形成對比。此外,這些異常維度在給定模型的各層中持續存在,隨著深度增加而增大,并在輸出層達到最大值。它們在整個訓練過程中也逐漸增大。
我們進行了實驗,嘗試在訓練和推理過程中中和這些維度。我們的發現表明,這些維度在訓練過程中起著重要作用,因為應用L2正則化來抑制它們會導致性能下降。然而,在推理時移除這些維度不會導致顯著的性能變化,這表明它們主要攜帶平凡或非信息性信號。此外,我們觀察到最終的層歸一化被訓練為大幅縮小這些異常維度。因此,我們建議對最終層的特征應用最終層歸一化以用于下游任務。或者,應用批歸一化也可以抑制這些特征維度異常值,因為它們的高值在不同補丁和圖像中是一致的。
對使用早期層特征需要謹慎。如上所述,這些早期層也受到特征維度異常值的影響,可能導致特征條件不良。雖然最終層歸一化非常適合歸一化最終特征的分布,但其學習的參數可能不適合應用于早期層的特征。事實上,我們觀察到這樣做會導致某些任務的性能下降。在這些情況下,我們發現標準特征縮放技術(例如使用批歸一化或主成分分析進行歸一化)在處理特征維度異常值方面是有效的。
例如,對于我們的語義分割(第6.3.2節)和深度估計實驗(第6.3.3節),我們對中間層特征應用了批歸一化。
B 附加結果
B.1 年度演變
在圖1中,我們提供了沿年份發展的最先進性能的粗略演變。這里,我們提供了在圖中報告的精確參考文獻和性能。請參見表21。
B.2 每層分析
在本節中,我們評估了DINOv3 7B模型各層特征的質量。具體來說,我們展示了五個代表性任務的結果:分類(IN-1k val, ImageNet-ReAL和ObjectNet)、分割(ADE20k)、深度估計(NYU)、跟蹤(DAVIS)和3D對應估計(NAVI)。對于前3個基準測試,像第6.1.2節和6.2.1節中那樣,在每個骨干網絡層的輸出上訓練一個線性層以評估特征性能。對于跟蹤和對應估計,我們使用第6.1.3節和6.1.5節中的非參數方法。
結果如圖21所示。我們發現,對于分類和密集任務,性能隨著各層平穩提升。深度估計、跟蹤和3D對應估計在第32層左右達到峰值,表明對于幾何起重要作用的任務,通過考慮更早的層可以提高DINOv3的下游性能。另一方面,中間層的性能僅比最后一層略有提升,使其成為一個良好的默認選擇。
B.3 主要結果部分的附加結果
我們提供補充第6節主要結果的附加實驗結果。在表22中,我們展示了使用線性探針對小數據集進行細粒度分類的每個數據集結果(Fine-S,見第6.2.1節)。在表23中,我們為實例識別評估(第6.2.2節)提供完整結果,添加了更多指標。
最后,在表24中,我們為我們在COCO-Stuff (Caesar et al., 2018)、PASCAL VOC 2012 (Everingham et al., 2012)和Cityscapes (Geiger et al., 2013)數據集上的最先進語義分割模型(第6.3.2節)提供補充結果。
B.4 OCR密集型數據集上的分類
在本實驗中,我們在需要某種形式的字符識別的分類任務上評估DINOv3。這些任務包括街道標志、徽標和產品分類。我們將我們的模型與最佳自監督模型(DINOv2 g)和最佳弱監督模型(PE-core G)進行比較。我們以512分辨率對我們的模型運行此評估,并調整其他模型的補丁大小以匹配序列長度。我們在表25中報告此實驗的結果。
我們看到,我們的新模型DINOv3大幅優于其前身DINOv2。然而,與弱監督模型的差距仍然很大。由于我們的模型在訓練期間不利用圖像-文本對數據,因此在學習字形關聯方面面臨更大挑戰。Fan等人(2025)的最新工作暗示了訓練數據對這類任務性能的影響。由于我們工作的重點是改進密集特征,因此縮小這一差距留待未來工作。
B.5 公平性分析
我們按照Goyal等人(2022b)的協議,評估DINOv3 7B模型在不同收入等級和地區間的地理公平性和多樣性。作為參考,我們包括了DINOv2和SEERv2獲得的結果。結果表明,DINOv3在收入類別間提供了一致的性能,盡管與最高收入等級相比,低收入等級的性能下降了23%。中等和高收入等級表現出相當的性能。在地區方面,DINOv3在不同地區取得了相對較好的分數;然而,歐洲和非洲之間觀察到超過14%的相對差異,這比DINOv2中觀察到的超過17%的相對差異有所改善。
I 實現細節
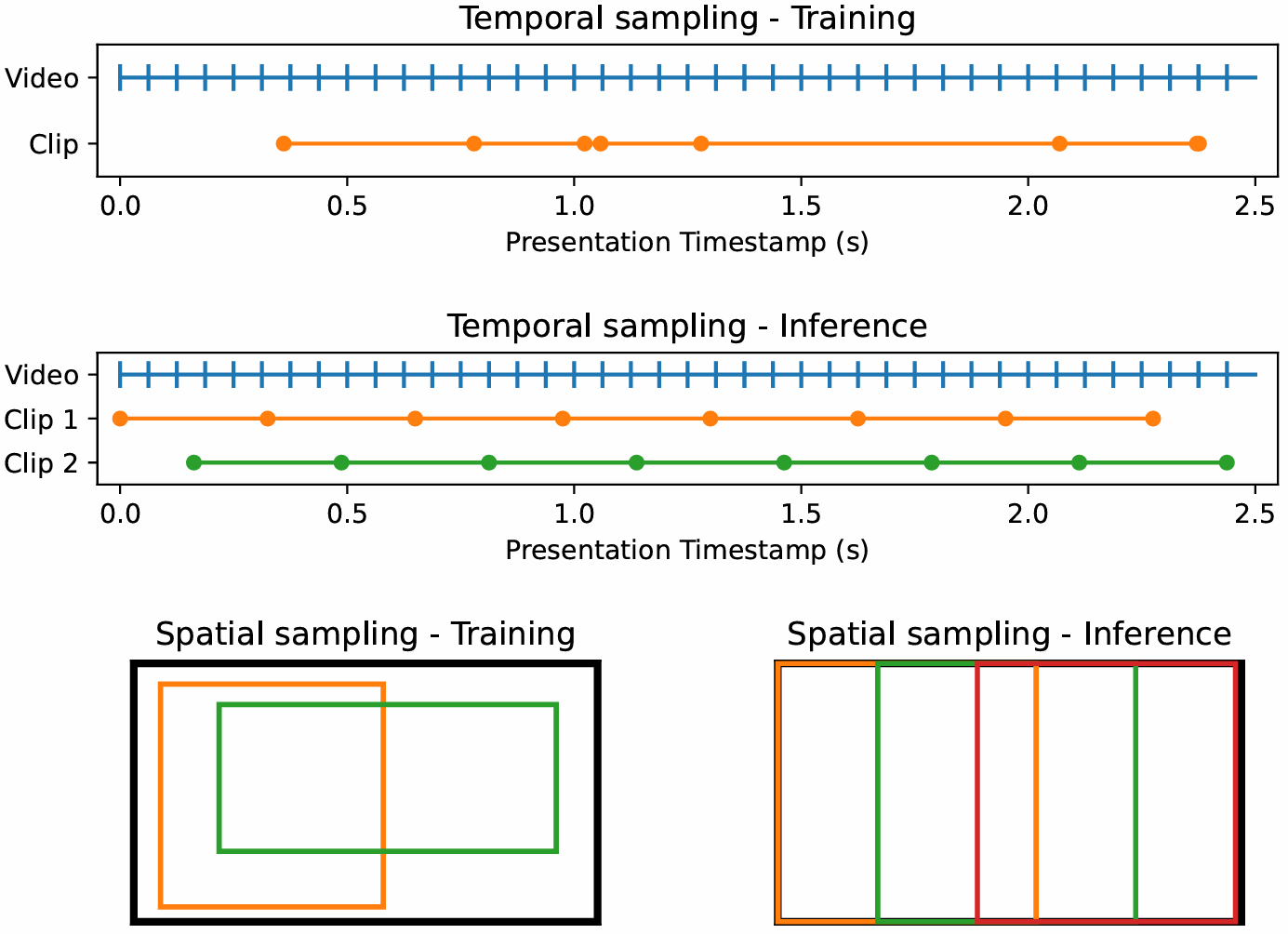
我們使用多裁剪(Caron et al., 2020),包含2個全局裁剪(256×256像素)和8個局部裁剪(112×112像素),這些裁剪被學生模型看到,導致總序列長度為3.7M個標記。教師EMA(學生的指數移動平均)僅處理全局裁剪。我們將LDINO\mathcal{L}_{\mathrm{DINO}}LDINO?損失應用于學生所有局部裁剪和教師兩個全局裁剪的類標記,并在兩個模型的不同全局裁剪對之間應用。以[0.1,0.5]的隨機比例對學生看到的全局裁剪補丁標記進行掩碼,概率為50%,我們在這些標記與教師EMA看到的可見標記之間應用LiBOT\mathcal{L}_{\mathrm{iBOT}}LiBOT?損失。我們將LDKoleo\mathcal{L}_{\mathrm{DKoleo}}LDKoleo?損失應用于學生看到的第一個全局裁剪的16個類標記的小批次。我們使用PyTorch中的全分片數據并行設置進行100萬次迭代訓練,使用bfloat16和8位浮點矩陣乘法。我們使用0.0004的恒定學習率,10萬次迭代的預熱,0.04的權重衰減,每層0.98的學習率衰減因子,0.4的隨機深度(層丟棄)值,以及教師的0.999 EMA因子。其余超參數可以在代碼發布中的配置文件中找到。
對于Gram錨定步驟,我們使用損失權重wGram=2w_{\mathrm{Gram}}\;=\;2wGram?=2,并每10k步更新Gram教師,最多更新三次。對于高分辨率適應(第5.1節),我們從以下全局/局部/Gram教師裁剪分辨率對中采樣,概率如下:(512, 112, 768)概率為p=0.3p=0.3p=0.3,(768, 112, 1152)概率為p=0.3p=0.3p=0.3,(768, 168, 1152)概率為p=0.3p=0.3p=0.3,(768, 224, 1152)概率為p=0.05p=0.05p=0.05,以及(768, 336, 1152)概率為p=0.05p=0.05p=0.05。這些值是通過經驗獲得的。

D 實驗細節
在本節中,我們提供了本文中所有基準測試所使用的數據集和評估指標的詳細描述。
D.1 語義分割:線性探針
數據集和指標 我們通過在三個基準數據集上進行線性探針來評估DINOv3的語義分割性能:ADE20k (Zhou et al., 2017)、VOC12 (Everingham et al., 2012)和Cityscapes (Cordts et al., 2016)。報告的評估指標是標準的平均交并比(mIoU)。
評估協議 ?為了評估密集特征的質量,我們在每個基準的訓練集上訓練一個線性分類器。該線性層應用于凍結骨干網絡的補丁輸出特征(在層歸一化之后)之上,特征進一步使用訓練的批歸一化層進行歸一化。對于所有骨干網絡,我們使用AdamW優化器執行超參數搜索,將學習率在{1×10?4,3×10?4,1×10?3}\{1\times10^{-4},3\times10^{-4},1\times10^{-3}\}{1×10?4,3×10?4,1×10?3}范圍內變化,權重衰減在{1×10?4,1×10?3}\{1\times10^{-4},1\times10^{-3}\}{1×10?4,1×10?3}范圍內變化。
D.2 深度估計:線性探針
數據集和指標 ?我們在深度基準數據集NYUv2 (Silberman et al., 2012)和KITTI (Geiger et al., 2013)上評估DINOv3特征在幾何任務中的質量。結果使用均方根誤差(RMSE)指標報告。
評估協議 ?為了評估密集特征的質量,我們在每個基準的訓練集上訓練一個線性分類器。該線性層應用于凍結骨干網絡的補丁輸出特征(在層歸一化之后)之上,特征進一步使用訓練的批歸一化層進行歸一化。對于所有骨干網絡,我們使用AdamW優化器執行超參數搜索,將學習率在{1×10?4,3×10?4,1×10?3}\{1\times10^{-4},3\times10^{-4},1\times10^{-3}\}{1×10?4,3×10?4,1×10?3}范圍內變化,權重衰減在{1×10?4,1×10?3}\{1\times10^{-4},1\times10^{-3}\}{1×10?4,1×10?3}范圍內變化。
D.3 3D關鍵點匹配
數據集和指標 ?幾何對應關系在NAVI數據集(Jampani et al., 2023)上進行評估,語義對應關系在SPair數據集(Min et al., 2019)上進行評估。對于NAVI,我們使用調整為邊長為448/512像素的圖像,適用于補丁大小為14/16的模型。對于SPair,我們使用調整為邊長為896/1024像素的圖像,適用于補丁大小為14/16的模型。為了衡量性能,我們報告對應召回率,即落在指定距離內的對應關系的百分比。
評估協議 ?對于NAVI,我們遵循Probe3D (Banani et al., 2024)定義的協議。具體來說,我們對1/4的對象視圖進行子采樣,對于每個源視圖,選擇另一個最大旋轉角度為120度的目的地視圖,以創建一對圖像(源,目的地)進行補丁匹配。對于每對圖像,源(在對象內)的每個補丁與目的地中的一個補丁匹配。保留具有最高余弦相似度的前1000個匹配用于評估,并基于已知的相機姿態和兩個圖像的深度圖為每個匹配計算3D距離誤差。這允許計算具有不同閾值的召回誤差,我們使用1厘米、2厘米和5厘米的閾值。然后我們計算跨閾值的平均召回率作為對應召回率。
對于每個評估的骨干網絡,我們使用最后一層的特征,并在應用和不應用最終層歸一化的情況下進行評估。這是因為我們注意到某些模型在應用最終層歸一化時性能不佳。我們報告兩種結果中的最大值。
D.4 無監督對象發現
數據集和指標 ?對于此任務,目標是為每張圖像生成一個突出顯示場景中描繪的任何對象的邊界框。我們遵循Siméoni等人(2021)的無監督對象發現協議,并在檢測基準VOC07 (Everingham et al., 2007)、VOC12 (Everingham et al., 2012)和COCO20K (Lin et al., 2014; Vo et al., 2020)上評估所有骨干網絡。COCO20K是COCO2014 trainval數據集(Lin et al., 2014)的子集,包含19,817張隨機選擇的圖像,如(Vo et al., 2020)中所提議,通常用于此任務。對于每張圖像,生成一個邊界框。對于評估,我們使用正確定位(CorLoc)指標,該指標計算正確定位的邊界框的百分比。如果預測框與任何真實邊界框的交并比(IoU)超過0.5,則認為該預測框是正確的。
評估協議 ?為了評估圖像編碼器的質量,我們采用TokenCut策略(Wang et al., 2023c)。該方法將圖像補丁組織成一個全連接圖,其中邊表示使用Transformer學習的骨干特征計算的補丁對之間的相似度分數。通過應用歸一化切割算法來識別顯著對象補丁,該算法解決圖切割問題。然后將邊界框擬合到生成的顯著對象掩碼上。所有圖像以其全分辨率輸入編碼器,我們使用所有圖像編碼器的補丁輸出特征。為了考慮模型之間特征分布的差異,我們對TokenCut的唯一超參數進行搜索:圖構建中使用的相似度閾值。具體來說,我們將閾值在0到0.4之間以0.05的增量變化。
D.5 視頻分割跟蹤
數據集和指標 ?對于此任務,我們使用DAVIS 2017 (Pont-Tuset et al., 2017)、YouTube-VOS (Xu et al., 2018)和MOSE (Ding et al., 2023)數據集。DAVIS為訓練集定義了60個視頻和30個驗證視頻,所有幀都用真實實例分割掩碼進行標注。對于YouTube-VOS,只有訓練集被標注并公開可用,而驗證集被限制在評估服務器后面。為了模擬DAVIS設置,我們隨機選取2758個標注視頻(80%)作為訓練集,其余690個視頻(20%)作為驗證集。類似地,我們將MOSE數據集分為1206個視頻用于驗證,301個用于測試。對于所有數據集,我們使用標準J&F-mean指標(Perazzi et al., 2016)評估性能,該指標結合了區域相似性(J)和輪廓準確性(F)分數。僅跟蹤和評估第一幀中標注的對象,而視頻后期出現的對象被忽略,即使它們的真實掩碼被標注。
評估協議 ?類似于Rajasegaran等人(2025),我們實現了一種基于補丁相似度的非參數標簽傳播協議,該相似度通過從凍結的DINOv3骨干網絡提取的特征之間的余弦相似度計算。我們假設視頻的第一幀用實例分割掩碼標注,我們將這些掩碼表示為每個補丁的one-hot向量。對于每一幀,我們計算其所有補丁特征與第一幀所有補丁以及少量過去幀所有補丁之間的余弦相似度。專注于當前幀中的單個補丁,我們考慮空間鄰域內最相似的k個補丁,并計算它們標簽的加權平均值以獲得當前補丁的預測。處理完一幀后,我們移動到下一幀,將先前的預測視為軟實例分割標簽。當通過骨干網絡轉發單個幀時,我們調整圖像大小,使最短邊匹配特定大小,保持縱橫比直到最接近補丁大小的倍數。補丁相似度和標簽傳播在生成特征的分辨率下計算,然后掩碼概率通過雙線性調整到原生分辨率以計算J&F。我們考慮幾種超參數組合,例如用作上下文的過去幀數量、鄰居數量k和空間鄰域的大小,如表27中總結的那樣。我們在DAVIS的訓練集上執行超參數選擇,然后將最佳組合應用于所有數據集的測試分割。
D.6 視頻分類
數據集和指標? 我們使用UCF101 (Soomro et al., 2012)、Something-Something V2 (Goyal et al., 2017)和Kinetics-400 (Kay et al., 2017)數據集評估DINOv3的視頻分類。從高層次來看,我們從每個視頻中提取固定數量的幀,使用凍結的骨干網絡對其進行編碼,將所有補丁特征收集到一個扁平序列中,然后將其輸入到基于淺層Transformer的分類器中,該分類器在一組標記視頻上進行常規監督訓練。在以前的工作中,例如(Assran et al., 2025),此協議被稱為注意力探針(attentive probe),暗示了用于圖像分類的線性探針。在下面的段落中,我們描述了我們對該協議的實現。
訓練 ?在訓練時,我們從每個視頻中隨機選擇16個時間位置的幀,跟蹤相應的時戳。我們還采樣覆蓋40%到100%面積的空間裁剪參數——這些參數將在視頻的所有幀中共享,以避免抖動。然后我們使用DINOv3將每幀作為獨立的256×256圖像處理,提取16×16補丁特征并丟棄CLS標記。對于每個補丁,我們跟蹤其在[0,1]2框上定義的空間坐標。所有幀的補丁特征線性投影到1024維,連接成長度為16×16×16=409616\times16\times16=409616×16×16=4096的扁平序列,然后輸入到四個自注意力塊中,這些塊建模補丁之間的空間和時間關系。為了確保模型能夠訪問位置信息,我們在塊之前將每個補丁的時戳和空間坐標作為加性正弦-余弦嵌入注入(Vaswani et al., 2017),并在每個注意力頭中作為具有隨機空間旋轉的3D分解RoPE。
推理? 在推理時,我們遵循確定性策略為每個視頻采樣單個片段:我們取第一幀、最后一幀和它們之間均勻間隔的幀,總共16幀。從每幀中,我們裁剪最大的中心正方形并將其調整為256×256像素,可能會丟失矩形視頻側面的信息。然后我們將這些幀輸入到DINOv3和分類器中,以獲得視頻的預測。或者,我們遵循Assran等人(2025)并執行測試時增強(TTA),通過選擇多個幀序列和多個空間裁剪,獨立處理它們,然后對類別概率進行平均以獲得最終預測。片段采樣如圖22所示。
基線 ?對于選定的基線模型,我們使用相同的評估協議,即特征提取、分類器架構、訓練程序和推理協議,但有一些差異。輸入分辨率為256×256像素,適用于使用補丁大小為16的模型,224×224像素適用于補丁大小為14的模型。這樣,所有骨干網絡產生相同數量的標記,因此在分類器中提供相同數量的計算。所有模型獨立地逐幀處理視頻,因為它們是在圖像上訓練的。唯一的例外是V-JEPA 2,我們向其輸入整個片段以提取時間感知特征。由于V-JEPA 2將時間軸減少兩倍,例如給定16幀輸入產生8個時間步,我們復制每個補丁標記以匹配其他模型的序列長度。
D.7 使用線性探針的圖像分類
數據集和指標 我們使用廣泛采用的線性探針評估來評估DINOv3模型的全局質量。我們在ImageNet-1k (Deng et al., 2009)訓練集上訓練線性變換,并在val集上評估結果。我們通過評估轉移到分類測試集來評估模型的泛化質量:ImageNet-V2 (Recht et al., 2019)和ImageNet-ReaL (Beyer et al., 2020),它們為ImageNet提供替代的圖像和標簽集,旨在測試對原始ImageNet驗證集的過擬合。此外,我們考慮Rendition (Hendrycks et al., 2021a)和Sketch (Wang et al., 2019)數據集,它們呈現ImageNet類別的風格化和人工版本;Adversarial (Hendrycks et al., 2021b)和ObjectNet (Barbu et al., 2019)數據集,包含故意設計的挑戰性示例;以及Corruptions (Hendrycks and Dietterich, 2019)數據集,用于測量對常見圖像損壞的魯棒性。對于除ImageNet-C以外的所有數據集,我們報告top-1分類準確率作為評估指標,對于ImageNet-C,我們報告平均損壞誤差(mCE,參見(Hendrycks and Dietterich, 2019))。
對于細粒度數據集,我們考慮Oquab等人(2024)的相同12個數據集集合,我們在此稱為Fine-S:Food-101 (Bossard et al., 2014)、CIFAR-10 (Krizhevsky et al., 2009)、CIFAR-100 (Krizhevsky et al., 2009)、SUN397 (Xiao et al., 2010)、StanfordCars (Krause et al., 2013)、FGVC-Aircraft (Maji et al., 2013)、VOC 2007 (Everingham et al., 2007)、DTD (Cimpoi et al., 2014)、Oxford Pets (Parkhi et al., 2012)、Caltech101 (Fei-Fei et al., 2004)、Flowers (Nilsback and Zisserman, 2008)和CUB200 (Welinder et al., 2010),以及更大的數據集Places205 (Zhou et al., 2014)、iNaturalist 2018 (Van Horn et al., 2018)和iNaturalist 2021 (Van Horn et al., 2021)。
評估協議 ?對于較大的數據集ImageNet、Places205、iNaturalist 2018和iNaturalist 2021,我們使用以下程序。對于每個基線,我們使用ImageNet-1k訓練集(Deng et al., 2009)在CLS標記的最終特征上(在層歸一化之后)訓練一個線性層。具體來說,我們使用動量為0.9的SGD,并使用1024的批量大小訓練10個周期。我們對學習率{1×10?4,2×10?4,5×10?4,1×10?3,2×10?3,5×10?3,1×10?2,2×10?2,5×10?2,1×10?1,2×10?1,5×10?1,1×100,2×100,5×100}\{1\times10^{-4},2\times10^{-4},5\times10^{-4},1\times10^{-3},2\times10^{-3},5\times10^{-3},1\times10^{-2},2\times10^{-2},5\times10^{-2},1\times10^{-1},2\times10^{-1},5\times10^{-1},1\times10^{0},2\times10^{0},5\times10^{0}\}{1×10?4,2×10?4,5×10?4,1×10?3,2×10?3,5×10?3,1×10?2,2×10?2,5×10?2,1×10?1,2×10?1,5×10?1,1×100,2×100,5×100}和權重衰減值{0,1e?5}\{0,1e-5\}{0,1e?5}進行搜索,并使用ImageNet-1k的驗證集選擇最佳組合。在訓練期間,我們使用具有標準Inception裁剪參數的隨機調整大小裁剪增強。對于Fine-S中的數據集,遵循Oquab等人(2024),我們使用scitkit-learn的LogisticRegression實現和L-BFGS求解器進行較輕量級的評估。
在這兩種情況下,我們都在產生1024個補丁標記的分辨率下評估模型,即對于補丁大小14為448×448,對于補丁大小16為512×512。圖像被調整大小,使較短邊匹配所選邊長,然后取中心方形裁剪。
D.8 實例識別
數據集和指標? 我們使用Oxford和Paris數據集進行地標識別(Radenovic et al., 2018),Met數據集包含來自大都會博物館的藝術品(Ypsilantis et al., 2021),以及AmsterTime,它由現代街景圖像與阿姆斯特丹歷史檔案圖像匹配組成(Yildiz et al., 2022)。在表9中,我們報告Oxford-Hard、Paris-Hard和AmsterTime的平均平均精度(mAP),以及Met的全局平均精度(GAP)。在表23中,我們額外提供Oxford-Medium和Paris-Medium的mAP,以及額外指標GAP-和準確率(參見(Ypsilantis et al., 2021))。對于Oxford和Paris,我們將所有圖像調整大小,使較長邊為224像素長,保持縱橫比,然后取全中心裁剪,得到分辨率為224×224的圖像。對于AmsterTime,我們將所有圖像調整大小,使較短邊為256像素長,保持縱橫比,然后取224×224的中心裁剪。對于Met,我們在接近其原始分辨率的情況下評估所有圖像,將兩個尺寸調整為補丁大小的最近倍數(對于補丁大小14/16,長邊為508/512)。
評估協議 ?圖像相似度使用查詢和目標圖像計算的CLS標記之間的余弦距離計算。我們遵循(Radenovic et al., 2018)對Oxford和Paris、(Yildiz et al., 2022)對AmsterTime以及Ypsilantis et al. (2021)對Met的評估協議。對于Met,這包括使用網格搜索調整超參數k和T,在Met的驗證集上優化GAP,并使用在Met訓練集上估計的PCA對特征進行白化。
D.9 對象檢測
數據集和指標 ?我們在COCO (Lin et al., 2014)和COCO-O (Mao et al., 2023)數據集上評估DINOv3的對象檢測。COCO是對象檢測的標準基準,涵蓋80個對象類別,包含118k訓練圖像和5k驗證圖像。COCO-O是一個僅用于評估的數據集,具有與COCO相同的類別,但在更具挑戰性的視覺條件下,例如具有顯著遮擋、雜亂背景和變化光照條件的場景。為了訓練對象檢測模型,我們還利用Objects365 (Shao et al., 2019)數據集,該數據集包含2.5M圖像并涵蓋365個對象類別,其中一部分直接映射到COCO類別。對于COCO和COCO-O,我們報告在IoU閾值[0.5:0.05:0.95][0.5:0.05:0.95][0.5:0.05:0.95]下計算的平均平均精度(mAP)。
架構 ?我們的方法基于Plain-DETR (Lin et al., 2023b)實現,進行了幾項修改。我們不將Transformer編碼器融合到骨干網絡中,而是將其保持為單獨的模塊,類似于原始DETR (Carion et al., 2020)。這使我們能夠在訓練和推理期間保持DINOv3骨干網絡完全凍結,使其成為第一個這樣做的有競爭力的檢測模型。從DINOv3 ViT-7B/16骨干網絡中,我們從四個中間層提取特征,即[10, 20, 30, 40]。對于每個補丁,我們按通道連接中間特征,得到4×4096=16384的特征維度,通過下面描述的窗口策略進一步增加。骨干網絡特征輸入到編碼器,編碼器是由6個自注意力塊組成的堆棧,嵌入維度為768。解碼器是由6個交叉注意力塊組成的堆棧,具有相同的嵌入維度,其中1500個"一對一"查詢和1500個"一對多"查詢關注編碼器的補丁標記以預測邊界框和類別標簽。
圖像預處理 ?訓練分三個階段進行,如下所述,一個階段的基礎圖像分辨率為1536像素,兩個階段為基礎分辨率為2048。遵循DETR,我們應用隨機水平翻轉(p=0.5)(p=0.5)(p=0.5),然后進行(i)隨機調整大小,其中最短邊在920像素(或1228)和階段的基礎分辨率(1536或2048)之間均勻采樣,或(ii)保留60-100%原始圖像區域的隨機裁剪,然后按(i)中所述調整大小。在評估時,圖像被調整大小,使最短邊為2048,不進行額外增強,兩邊都向上舍入到補丁大小的最近倍數。
窗口策略 ?然后我們應用一種窗口策略,將圖像的全局視圖與較小視圖結合,以允許骨干網絡處理所有尺度的對象。窗口數量固定為3×33\times33×3,其大小根據輸入分辨率而變化。例如,對于1536×2304大小的圖像:
-
圖像被劃分為3×3個不重疊的512×768大小的窗口。每個窗口通過骨干網絡轉發,產生維度為16384的32×48補丁標記。所有窗口的特征在空間上重新組裝成一個?(3×32)×(3×48)?\lfloor(3\times32)\times(3\times48)\rfloor?(3×32)×(3×48)?特征圖。
-
整個圖像被調整為512×768并通過骨干網絡轉發,產生維度為16384的32×48補丁標記的特征圖。然后這些特征通過雙線性上采樣到96×144,與窗口化特征圖的大小匹配。
-
最后,步驟1和2中的特征圖按通道連接,產生維度為2×16384=327682\times16384=327682×16384=32768的96×144特征圖。然后將此特征圖展平為96×144個標記的序列并饋送到編碼器。
訓練 ?我們遵循三階段的訓練課程,使用Objects365數據集(Shao et al., 2019)和COCO數據集(Lin et al., 2014),分辨率逐漸提高。在整個訓練過程中,我們使用AdamW優化器(Loshchilov and Hutter, 2017),權重衰減為0.05。遵循DETR,我們使用Focal Loss (Lin et al., 2018)作為分類損失,權重為2,L1損失作為邊界框損失,權重為1,輔以GIoU (Rezatofighi et al., 2019)損失,權重為2。各階段如下:
-
我們首先在Objects365上以1536像素的基礎分辨率開始訓練。我們在32個GPU上以32的全局批量大小訓練22個周期。在初始預熱1000步后,學習率設置為5×10^-5,并在第20個周期后除以10。
-
然后我們在Objects365上以2048像素的基礎分辨率繼續訓練。我們以2.5×10^-5的學習率訓練4個周期。
-
我們通過在COCO上以2048的基礎分辨率進行12個周期的訓練來完成訓練。在2000次迭代的線性預熱后,學習率遵循余弦衰減計劃,從2.5×10-5開始,在第8個周期達到2.5×10-6。在此部分,我們使用IA-BCE分類損失(Cai et al., 2024)而不是DETR的簡單Focal Loss。我們觀察到此損失在遷移時間提高模型性能,但在預訓練時間沒有。由于此損失混合了類別和框信息,如果框預測已經很好地初始化,它將發揮其全部潛力。在此部分,GIoU損失權重設置為4,以鼓勵更好的框對齊。
測試時增強 ?在測試時,我們遵循上述推理程序,將圖像調整大小,使短邊為1536或2048。在這些分辨率下,COCO mAP分別為65.4和65.6。或者,我們可以應用Bolya等人(2025)的測試時增強(TTA)策略,該策略包括翻轉和將圖像調整為多個分辨率,并使用SoftNMS (Bodla et al., 2017)合并預測。具體來說,每個圖像在[1536,1728,1920,2112,2304,2496,2688,2880]的分辨率下處理,產生66.1的mAP。
D.10 語義分割
數據集和指標 我們在ADE20k (Zhou et al., 2017)、Cityscapes (Cordts et al., 2016)、COCO-Stuff (Caesar et al., 2018)上評估DINOv3的語義分割性能。
















指南)


)