這段時間學習了 KNN,線性回歸,邏輯回歸,貝葉斯,聚類(K-means,DBSCAN),決策樹,集成學習(隨機森林,XGboost),SVM支持向量機, TF-IDF,詞向量轉化,PCA降維。這十一種算法。下面進行一一回顧。
KNN
????????這個又叫做K近鄰,大多用于分類,例如房價預測(這里可以預測房價的屬于什么類,如果預測房價價格,可以取范圍內房價的平均數)。
算法簡述:
????????通過計算特征之間的距離(歐式距離或者其他),然后通過距離內的存在的標簽進行投票,然后進行分類,去存在最多的那種標簽。
重要參數:
from sklearn.neighbors import KNeighborsClassifier
model=KNeighborsClassifier(n_neighbors=5)
model.fit(train_X,train_y)
result1=model.score(test_X,test_y)
print(result1)這里重要參數就一個n_neighbors,可以用來控制取周圍幾個最近的標簽點。
線性回歸
這個平時用來預測回歸問題,例如根據人體的各個指標來預測他們的血壓收縮。
算法簡述
? ? ? ? 通過擬合y=wx+b,這一條線來預測,這個過程中會有點偏離我們的線,然后引入了一個誤差項Q=y-(wx+b),同時這個誤差項滿足標準正態分布,也就是說把Q帶入標準正態分布表達式之后,這個正態分布的值越大,這個Q也就越小(具體看正態分布函數圖像),然后就通過最小二乘法,梯度下降來求出最優W值。
重要參數:
from sklearn.linear_model import LinearRegression
model=LinearRegression()
model.fit(X,y)
result1=model.score(X,y)
a=model.coef_[0]
b=model.intercept_這個沒什么重要參數,注意后面可以使用斜率和截距來預測結果。
邏輯回歸
這個和線性回歸很像,這個看著像是回歸算法,但其實這個是一個分類算法。
算法簡述
這個邏輯回歸就是在線性回歸的基礎上進行了改進,主要內容就是,在求出上面邏輯回歸的那條直線后,我們可以加一條z軸,然后引入一個sigmod激活函數,然后這個sigmod曲線在直線的正上方,然后我們把平面上的點映射到直線上,然后得出一個值,然后再帶入到sigmod曲線中,然后把值映射到0-1之間,判斷屬于這一類的概率。
重要參數
from sklearn.linear_model import LogisticRegression
model=LogisticRegression(max_iter=1000,C=1.0,penalty='l2')
model.fit(data_train,label_train)
print(model.score(data_test,label_test))正則化強度倒數C?(值越小,正則化越強,默認=1)是最重要的。這個可以控制權重的幅度,例如(1,0,0)和(0.3,0.3,0.3)顯然是第二種比較好,然后我們的懲罰系數在第一種的時候就比第二種大,就會選用第二種。
正則化方法panalty,主要有兩種L1正則化,L2正則化,L1和L2的區別就是L1是權重的絕對值之和,L2是權重的平方之和。這個C就是前面的系數
貝葉斯
這個算法主要用在語言處理上,在其他方面準確率表現比較低
算法簡述
這個算法原理比較簡單,就是根據已有數據,求出概率,然后帶入高斯貝葉斯,多項式貝葉斯,或者什么貝葉斯來計算,就行了。
重要參數
from sklearn.naive_bayes import BernoulliNB
model=BernoulliNB()
model.fit(train_X,train_y)
print(model.score(test_X,test_y))
這里沒什么重要參數
K-means
這個是一個聚類算法,無監督學習不需要標簽就可以進行
算法簡述
? ? ? ? 開始隨機選取K個點作為質心(可調,我們傳入的參數),然后計算每個點到質心的距離,選取離質心最近的幾個點分配給他。然后更新質心為分類簇的質心,逐漸迭代,到質心不發生變化為止。
重要參數
modle=KMeans(n_clusters=best_K)
modle.fit(X)
labels = modle.labels_
print('輪廓系數:',metrics.silhouette_score(X,labels))n_clusters,就是最初質心個數的選擇。
max_iter 迭代次數,如果迭代的不夠,模型結果可能不會那么準確
DBSCAN
????????這個與上面K-means算法差不多都是聚類,唯一不同就是聚類的方法不同。這個可以用于人臉識別,可以聚類出那種線性的類。
算法簡述
????????DBSCAN開始會隨機選一個點,開始傳染,找距離內的幾個點,然后就這樣一直傳染,最終變成一簇。每個簇都是這樣。也可以這么說,每個點就找自己距離內的那個點,然后作為一類,最終可以看出分為幾個類
重要參數
from sklearn.cluster import DBSCAN
dbscan = DBSCAN(eps=2.5, min_samples=5, metric='euclidean')
clusters = dbscan.fit_predict(X)
print(clusters)eps;用來控制距離,搜索周邊多少距離內的點
min_samples;用來表示搜索的時候距離內有多少點,才允許傳染。
決策樹
這個算法獨自用的比較少,主要用來結合起來一起用于后面的隨即森林。
算法簡述
決策樹有三種方法ID3,C4.5,CART,這三種算法。ID3是計算信息增益的,C4.5是在ID3的基礎上計算信息增益率,CART是計算基尼指數。
重要參數
from sklearn.tree import DecisionTreeClassifier
model=DecisionTreeClassifier(criterion="gini",max_depth=best[0],random_state=42,min_samples_split=best[1],min_samples_leaf=best[2],max_leaf_nodes=best[3])
model.fit(train_X,train_y)- ?**
criterion**?:分裂標準,可選?'gini'(基尼系數)或?'entropy'(信息增益)。 - ?**
max_depth**?:樹的最大深度(限制過擬合關鍵參數)。 - ?**
min_samples_split**?:節點分裂所需最小樣本數(值越大,樹越簡單)。 - ?**
min_samples_leaf**?:葉節點最小樣本數(控制葉子大小)
集成學習(隨機森林)
? ? ? ? 這個就是上面算法的究極形態了,這個就是并行訓練,這個還可以進行重要特征提取
算法簡述
????????這個算法就是前面決策數進行整合,創建許多決策樹模型,然后每個模型取百分之80的特征進行訓練,然后把訓練結果進行綜合得出一個最佳。因為部分特征可能會影響訓練結果。所以這選取0.8的特征就很有效果。
重要參數
from sklearn.ensemble import RandomForestClassifier
model=RandomForestClassifier(max_features='sqrt',n_jobs=-1,n_estimators=100,max_depth=10,min_samples_leaf=10,max_leaf_nodes=10)
model.fit(train_X,train_y)im = pd.DataFrame({'feature':train_X.columns,'importances': model.feature_importances_
})
im = im.sort_values(by=['importances'], ascending=False)[:10]
print(im)n_estimators=100?- 創建100棵決策樹組成的森林max_depth=5?- 限制每棵樹的最大深度,防止單個樹過擬合max_features='sqrt'?- 每次分裂時只考慮√(總特征數)個特征min_samples_split=2?- 節點至少需要2個樣本才能繼續分裂- model.feature_importances_這個可以獲取重要特征
集成學習(XGboost)
這個是串行訓練
算法簡述
針對一個訓練集,xgboost首先使用CART樹訓練得到一個模型,這樣針對每個樣本都會產生一個偏差值;然后將樣本偏差值作為新的訓練集,繼續使用CART樹訓練得到一個新模型;以此重復,直至達到某個退出條件為止。引入了正則化項(L1/L2)控制模型復雜度以防止過擬合,優化了特征選擇和分裂點算法(近似分位點、列采樣),支持并行計算,處理缺失值等。
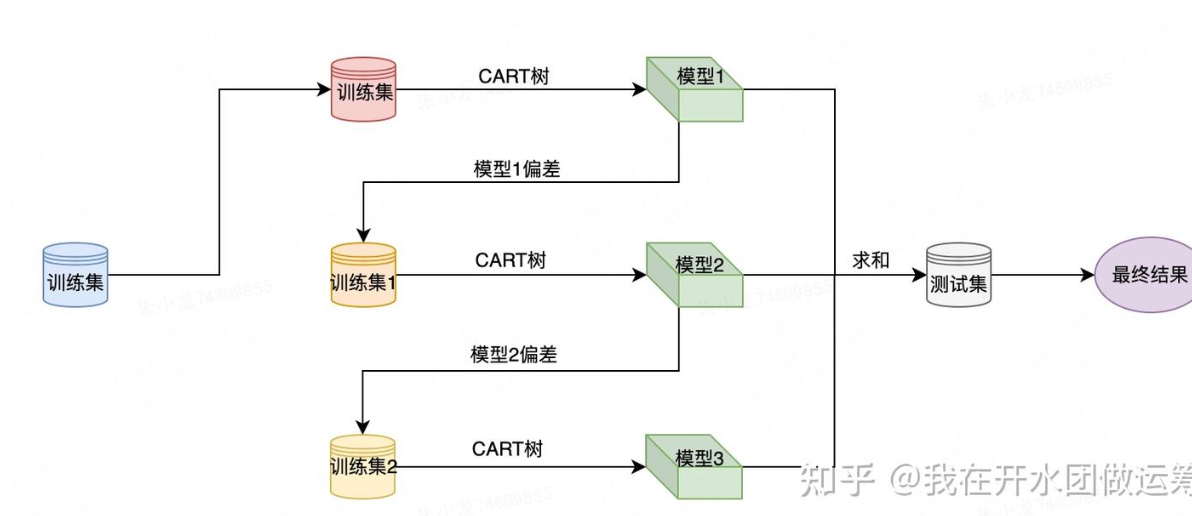
重要參數
from xgboost import XGBClassifier
xgb_model = XGBClassifier(# 樹結構參數max_depth=3, # 樹的最大深度min_child_weight=1, # 子節點樣本權重和的最小值# 正則化參數gamma=0.1, # 分裂所需最小損失減少量reg_lambda=1.0, # L2正則化權重# 學習控制learning_rate=0.1, # 學習率n_estimators=100, # 樹的數量# 抽樣策略subsample=0.8, # 訓練樣本采樣比例colsample_bytree=0.8, # 特征采樣比例# 其他參數random_state=42, # 確保結果可復現use_label_encoder=False # 避免警告
)SVM支持向量機
這個適用于小樣本的訓練
算法簡述
在一個線性可分的兩組數據中找到一個線(高維的兩組數據就是超平面),這個超平面的限制條件就是在兩組數據中夾著,并且距離相隔最大。如果線性不可分就映射到高維空間,映射到可分為止。這個映射函數就是核函數,核函數一般是高斯核函數或者其他核函數。
重要參數
from sklearn.svm import SVC
model = SVC(kernel='linear', C=float('inf'))
model.fit(X, y)kernel這是核函數(如?'linear'(線性)、'rbf'(高斯核)、'poly'(多項式核)),選取適當的核函數,事半功倍。
C是懲罰系數,這個的大小決定了我們是否容忍軟間隔。(值越大,對誤分類的容忍度越低,可能過擬合)
TF-IDF
這個算法是用來提取文本特征的,重要詞,和關鍵詞的
算法簡述
詞a在文章出現的次數/這個文章的總詞數? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? (TF)
------------------------------------------------------
log(文檔總數/包含詞a的文章數+1)? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?(IDF)
大致意思就是,先看在本文中重要不重要,再看這個詞普遍不普遍,如果很普遍那就不重要了。
重要參數
from sklearn.feature_extraction.text import TfidfVectorizer
model=TfidfVectorizer()
data=open('結果1.txt',encoding='utf-8')
jg=model.fit_transform(data)
print(jg)
wordlist=model.get_feature_names_out()
print(wordlist)
import pandas as pd
df=pd.DataFrame(jg.T.todense(),index=wordlist)
print(df)
# featurelist = df.iloc[:,5].tolist()
# print(featurelist)
這個我們要知道model.fit_transform(data)的結果是一個字典,其中第一列(n,n)表示第n篇文章第n個單詞,后面表示這個的重要指標。
model.get_feature_names_out()是一個列表。表示出現的所有詞的name
pd.DataFrame(jg.T.todense(),index=wordlist)這個就轉化為了一個表格,行為第幾篇文章,列為name
詞向量轉化
把單詞轉化為可訓練的數據
算法簡述
把每句話轉化為一個矩陣,首先先對每句話進行結巴分詞,然后分出多少次就有多少個特征,根據這個特征是否在文章中出現作為那個位置的特征為0/1,然后[0 1 1 1 1 1]這樣就是一句話的特征了。然后有了數據又有了標簽的化就可以訓練了,前面也說過貝葉斯比較適合文本訓練
重要參數
from sklearn.feature_extraction.text import CountVectorizer
texts=["dog cat fish","dog cat cat","fish bird",'bird']
model=CountVectorizer(max_features=6,ngram_range=(1,3))
model.fit(texts)
print(model.get_feature_names_out())
print(model.transform(texts))
print(model.transform(texts).toarray())
max_features=6表示要分出幾個特征(取全文出現頻率最多的幾個)
ngram_range=(1,3)表示每個特征的詞數控制在1-3個單詞
lowercase=False表示要不要全轉化為小寫,如果是中文的話就要寫成false
PCA降維
這個和隨機森林降維差不多,選取重要特征
算法簡述
這個通過把數據映射一下,到另一個坐標中,映射標準是映射的足夠離散,然后把數據量少的那一個維度去除。
重要參數
pca = PCA(n_components=20)
pca.fit(X)
X_pca = pca.fit_transform(X)n_components=20 用于控制降低到多少維度
X_pca = pca.fit_transform(X)這個就可以把訓練結果導出來了。
評價方式
回歸
準確率,召回率
分類
MSE,RMSE,MAE,R方

聚類
輪廓系數,衡量聚類緊密度和分離度。值在[-1,1]之間,越接近1表示聚類效果越好。
選取建議

數據處理
數據不均衡
過采樣
使用SMOTE來過采樣,這個算法的原理也是距離方法,例如這個有兩個點,然后過采樣我就把這兩個點連接,在這個線段內取出n個點作為過采樣的點。
from imblearn.over_sampling import SMOTE#imblearn這個庫里面調用,
oversampler =SMOTE(random_state=0)#保證數據擬合效果,隨機種子
train_X, train_y = oversampler.fit_resample(train_X,train_y)#人工擬合數據下采樣
pe=train_data[train_data['Class'] == 1]
ne=train_data[train_data['Class'] == 0]d1 = ne.sample(len(pe))train_data = pd.concat([d1,pe])就是把訓練集兩類特征分開,從多的那一個里面隨機取樣出少的那一個樣本的個數
數據異常值和空值
異常值
把異常值轉化為空值
for i in X.columns:X[i]=pd.to_numeric(X[i],errors='coerce')空值
空值可以選取中位數,平均數,眾數,或者用線性回歸預測來填充。





指南)


)










