ETLCloud批流一體化體現在哪
企業對數據處理的實時性、高效性和準確性的要求越來越高。批流一體化作為一種先進的數據處理理念,逐漸被企業所采用。
目前許多國產化ETL工具也裝配了十分強大的批流一體化能力,ETLCoud就是一個很好的代表,它能夠對靜態數據和實時流動的數據進行抽取、轉換和加載操作,實現對不同業務場景對數據處理的需求。
這篇文章,我們將具體為您講解,ETLCloud?的批流一體化能力究竟體現在哪些方面呢?
一、數據處理能力
批流一體(Unified?Stream?and?Batch?Processing)是將流式處理和批量處理的優勢結合在一個統一的框架中進行數據處理。其目標是通過一個系統同時支持實時數據流處理和離線數據處理,提供更加靈活和高效的數據處理能力。
ETLCloud?的實時數據集成支持通過?CDC(Change?Data?Capture)等技術對數據源進行實時數據同步以及流數據的實時處理。例如在實時訂單、銷售數據報表場景中,CDC?實時監聽銷售或訂單表數據的?LOG,形成流式數據。對于實時數據傳統做法是先讓數據入庫,再用?SQL?語句或?ETL?流程進行變換形成寬表數據,這樣會失去數據處理的時效性。而?ETLCloud?采用實時批流合并的方式,通過拉入實時輸入流節點接管流入的實時流式數據,再用多流合并節點將批數據拆分后的行數據進行合并,使后續節點拿到實時合并的寬表數據,避免了在?ODS?層的二次變換,直接傳輸給業務系統使用,滿足了業務對實時數據報表的需求。
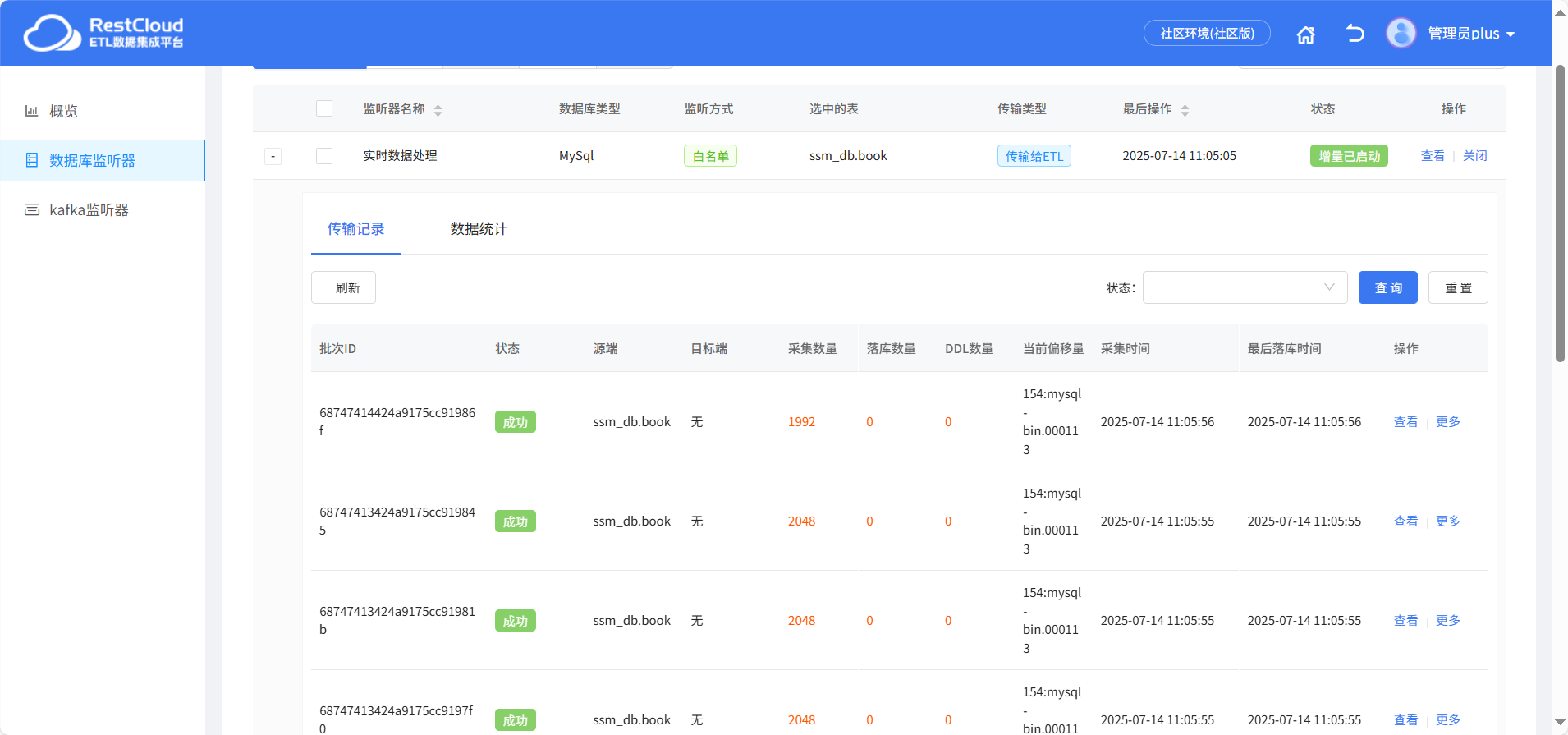
監聽器配置
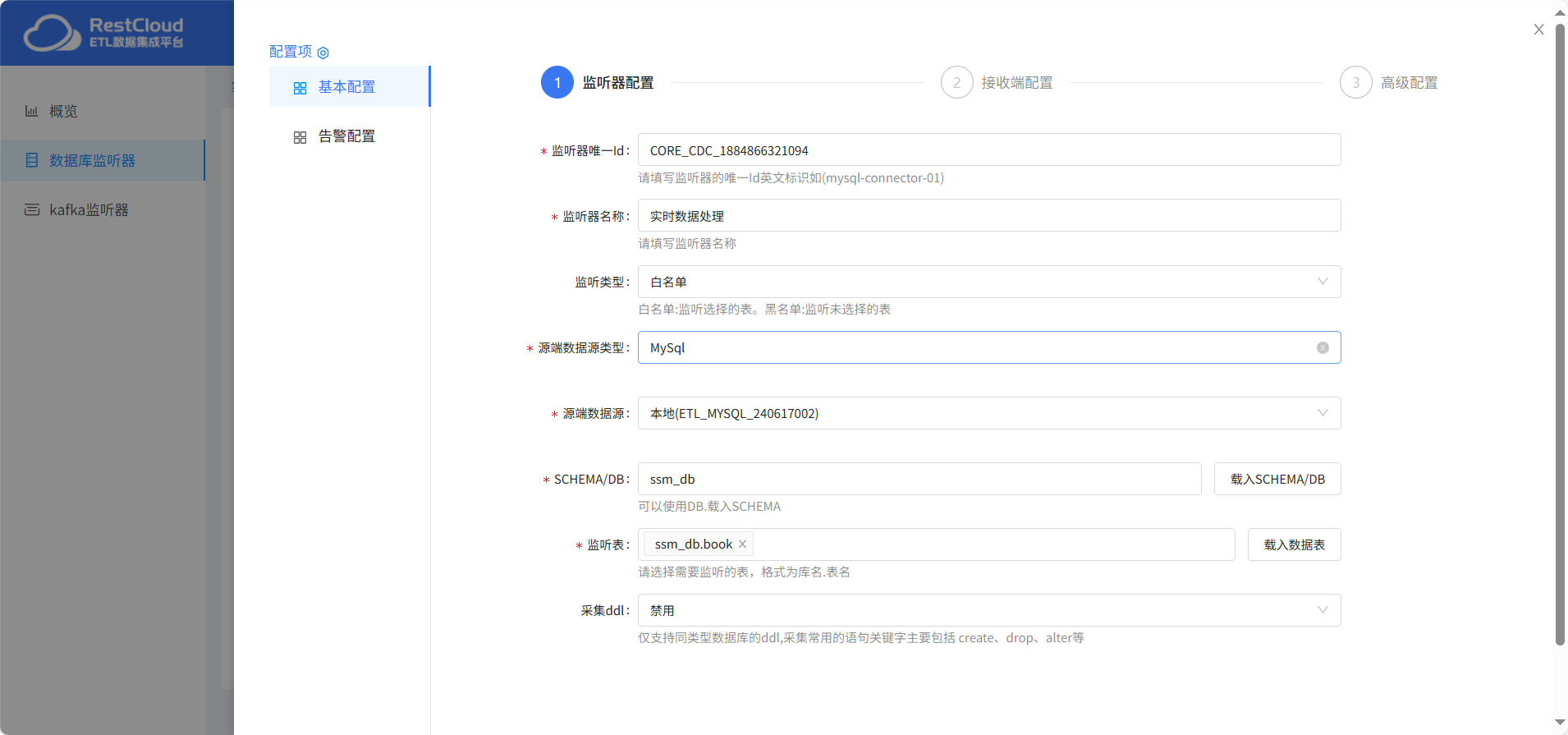
傳輸到流程中對實時流數據進行數據處理
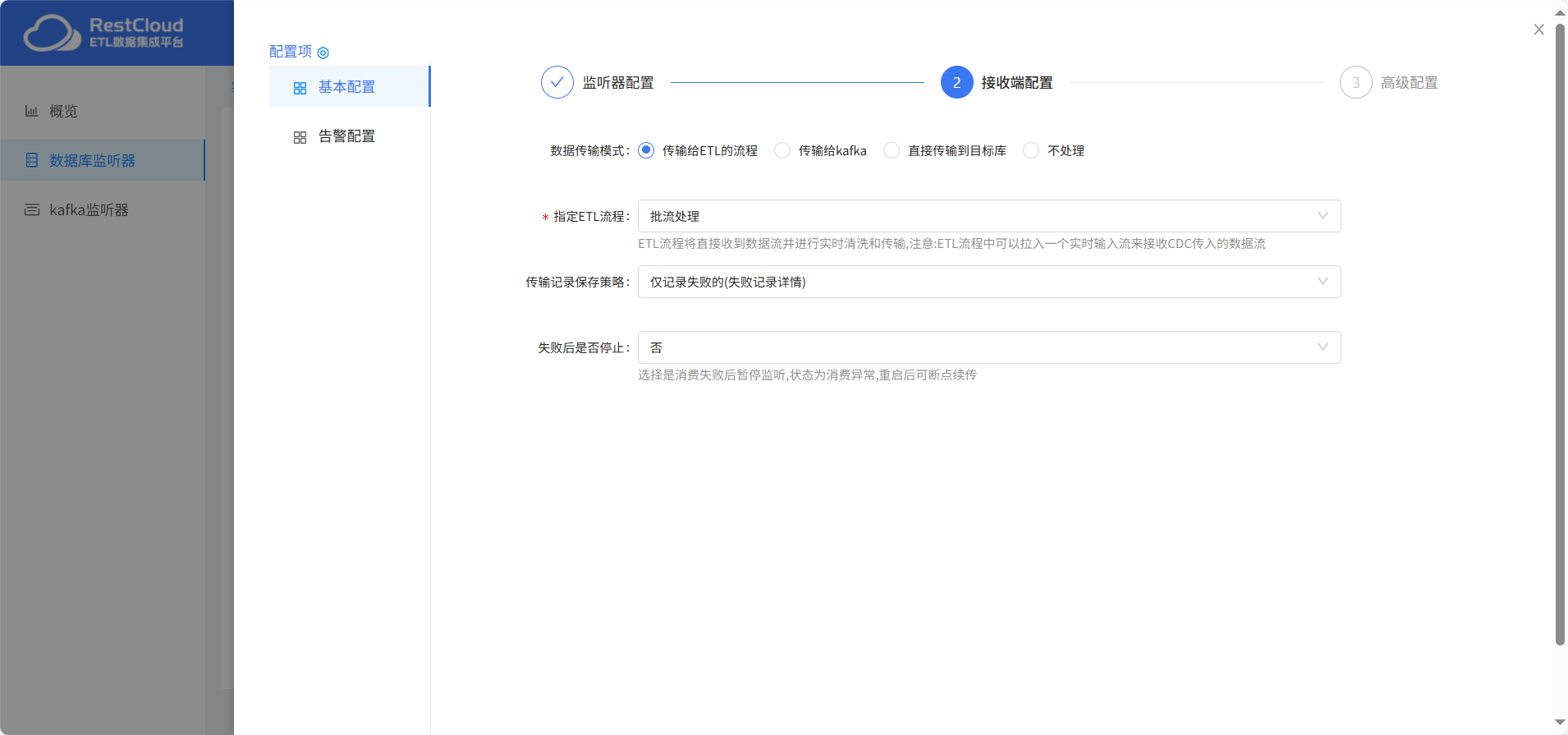
采集模式擁有全量+增量和增量兩種。全量+增量模式會在第一次啟動時全量同步所有數據,全量完成后則只同步增量數據。而增量模式只采集增量變更的數據不會全量同步數據。
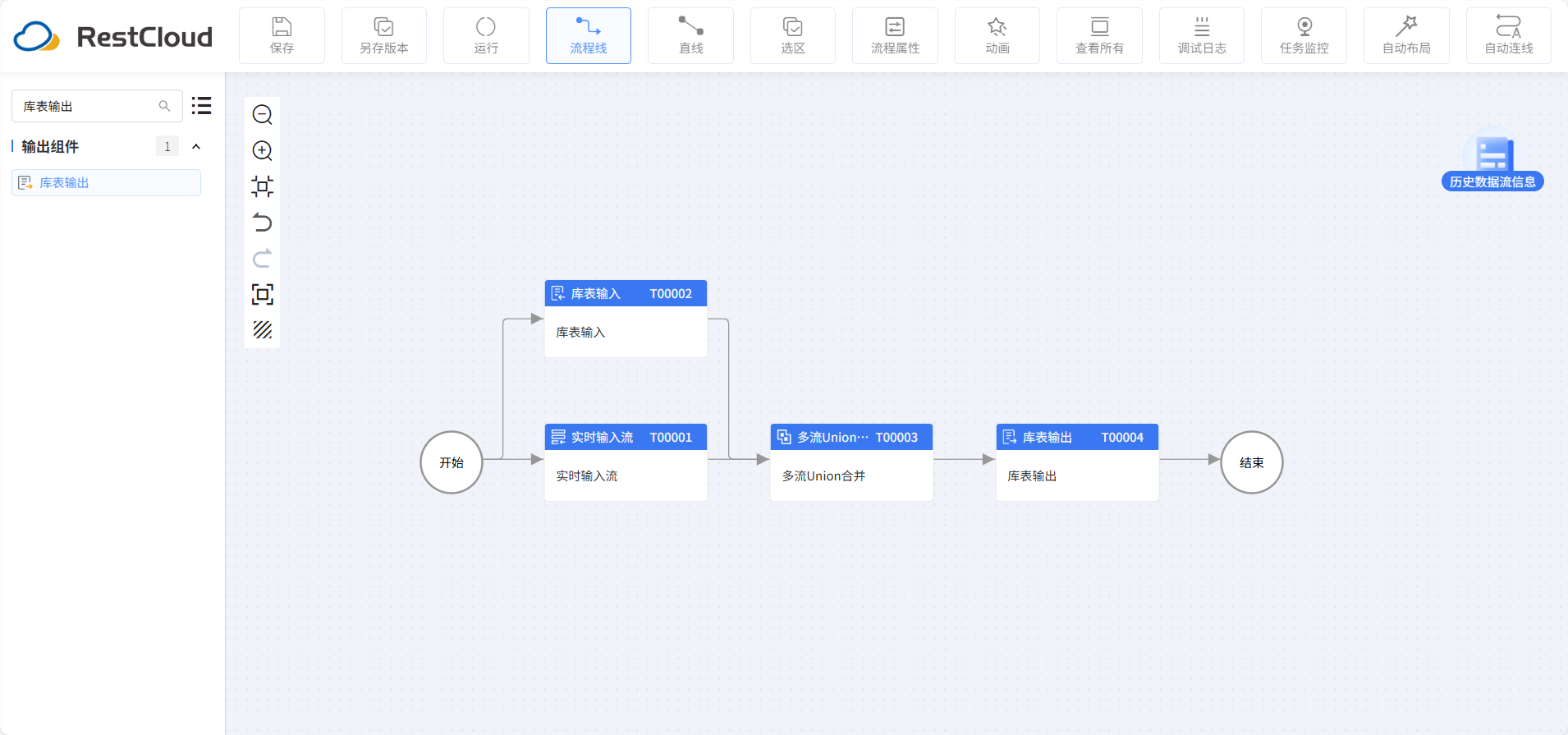
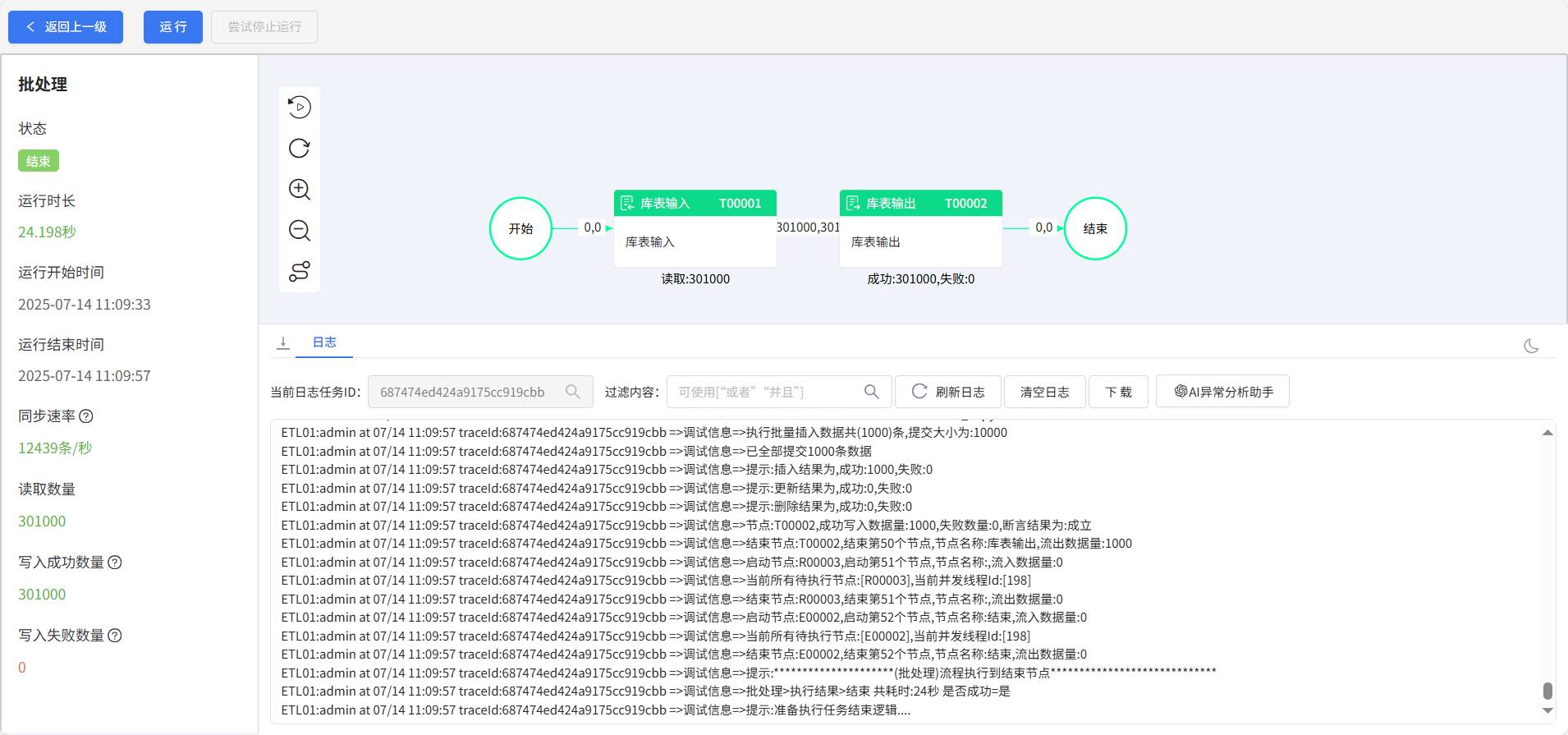
用于數據處理的ETL流程
運行結果
同時,對于批處理任務,ETLCloud?的離線數據集成也提供了強大的支持。用戶可以通過可視化的拖、拉、拽創建異構數據源之間的集成任務,對數據進行清洗、轉換、傳輸等操作。在處理海量歷史數據時,批處理任務能夠按照預定的規則和流程,高效地完成數據的抽取、轉換和加載,為實時數據分析提供豐富的歷史數據支撐。
二、豐富的數據源支持與組件拓展
為了進一步提高用戶的開發效率,ETLCloud?打造了數據集成組件生態,支持?100?多種數據庫、1000?多個組件、1500?多個數據處理模板。
在批流一體化處理中,用戶可以根據不同的數據源、數據處理需求和目標數據存儲,從豐富的組件庫中選擇合適的組件進行流程構建。
對于常見的數據處理場景,如數據清洗、數據轉換、數據聚合等,平臺提供了大量的預制模板,用戶只需根據實際情況進行簡單的參數配置,即可快速復用這些模板,完成復雜的數據處理任務。
數據源支持:

組件:


場景模板:

三、任務監控與預警
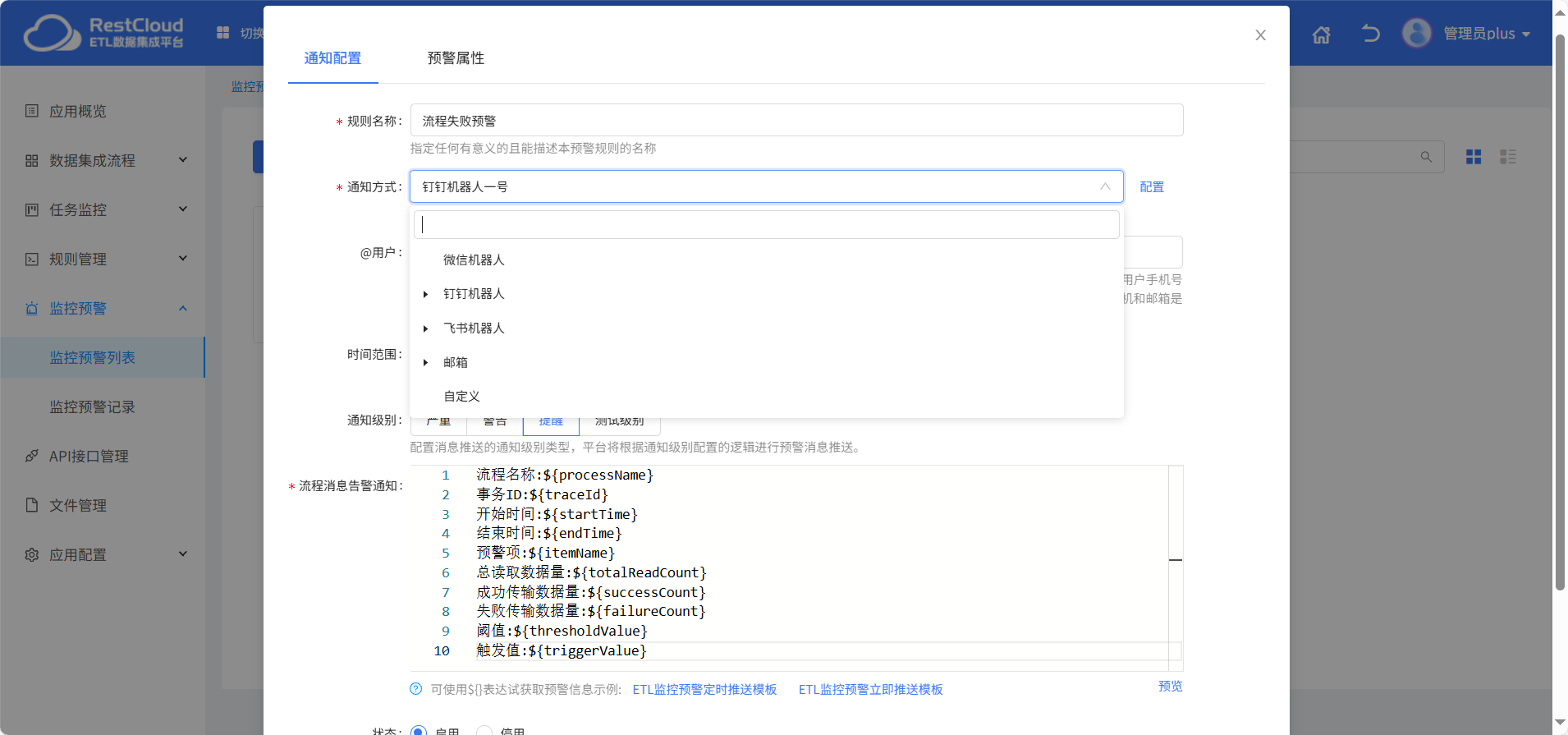
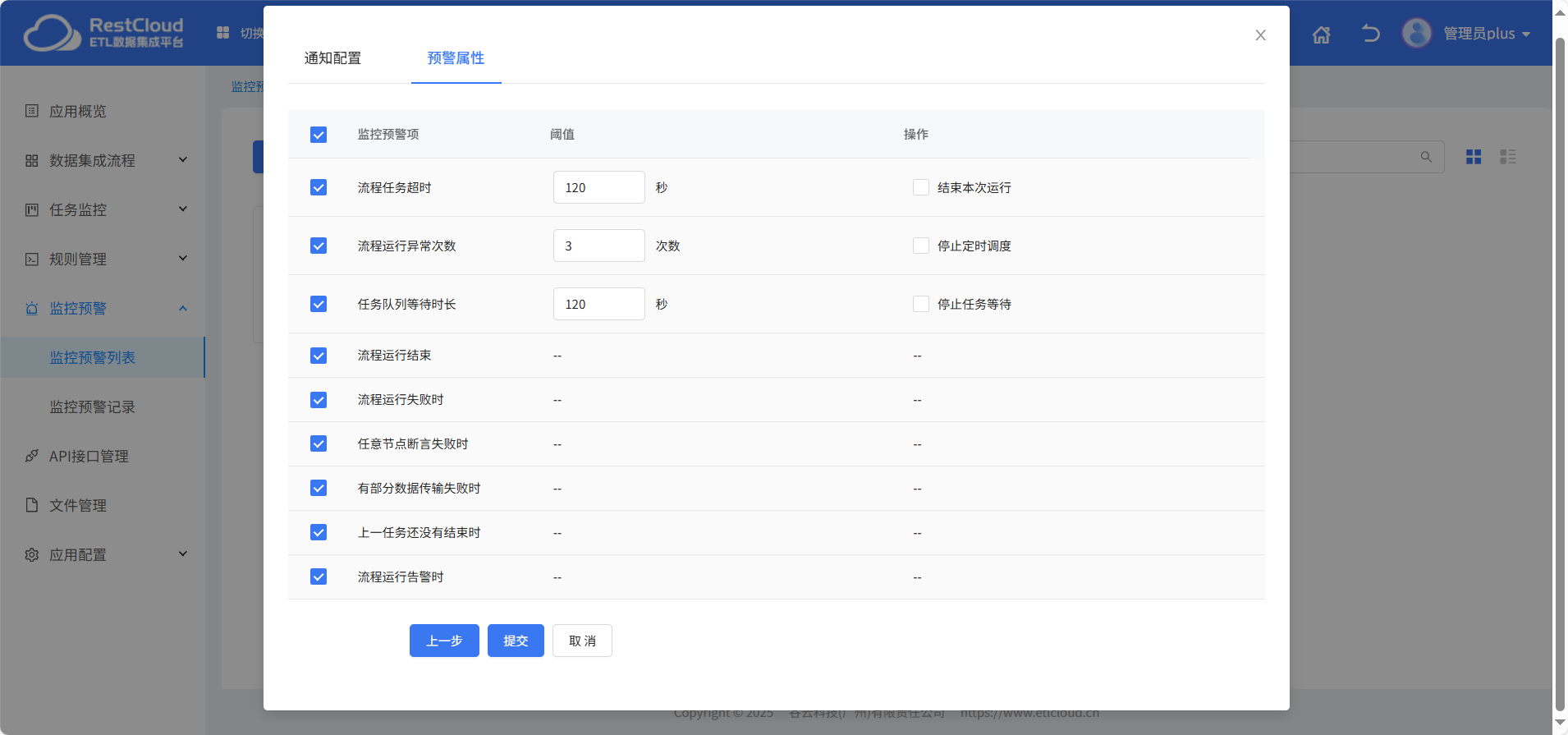
為了確保批流一體化任務的穩定運行,ETLCloud?提供了實時任務監控功能。用戶可以通過平臺的監控界面,實時查看任務的執行狀態、進度、資源使用情況等信息。對于正在運行的流處理任務,監控界面能夠實時展示數據的流入速率、處理速率、延遲情況等關鍵指標,幫助用戶及時發現潛在的性能問題。
對于批處理任務,監控界面則會顯示任務的開始時間、預計完成時間、當前完成進度等信息。一旦任務出現異常,如任務失敗、資源不足、數據傳輸中斷等,ETLCloud?會立即發送預警通知,通過郵件、短信、站內消息等多種方式告知相關人員,以便及時采取措施進行處理,保障數據處理的連續性和準確性。
總結:
ETLCloud?的批流一體化體現在數據處理能力、豐富的數據源支持與組件拓展以及任務監控與預警等多個方面。通過批流一體化的優勢,ETLCloud?能夠幫助企業更高效地整合和管理數據,加速數據價值的變現,為企業的數字化轉型提供有力支持。
隨著技術的不斷發展和創新,ETLCloud?將繼續在批流一體化領域深耕,為企業提供更先進、更智能的數據集成解決方案。
)
)



)




)








