背景意義
研究背景與意義
在計算機視覺領域,實例分割技術作為一種重要的圖像處理方法,近年來得到了廣泛的關注和應用。實例分割不僅能夠識別圖像中的物體類別,還能精確地分割出每個物體的輪廓,提供更為細致的視覺信息。這一技術在自動駕駛、醫療影像分析、工業檢測等多個領域展現出了巨大的潛力。隨著深度學習技術的快速發展,基于卷積神經網絡(CNN)的實例分割算法不斷涌現,其中YOLO(You Only Look Once)系列模型因其高效性和實時性而備受青睞。
本研究旨在基于改進的YOLOv11模型,構建一個專門針對火柴的實例分割系統。火柴作為一種日常生活中常見的物品,其在圖像識別中的應用相對較少,但其簡單的形狀和顏色特征使其成為實例分割研究的理想對象。通過構建一個包含2800張火柴圖像的數據集,研究將能夠深入探討YOLOv11在處理特定類別物體時的性能表現。該數據集的設計不僅考慮了樣本數量的豐富性,還通過多種數據增強技術提升了模型的泛化能力。
此外,火柴實例分割系統的研究具有重要的實際意義。隨著智能家居和自動化設備的普及,能夠精準識別和處理日常物品的計算機視覺系統將極大提升人機交互的智能化水平。通過對火柴的精確分割與識別,未來可以為相關領域的應用提供基礎,例如在智能廚房中識別火柴的使用情況,或在安全監控中檢測潛在的火災隱患。
綜上所述,基于改進YOLOv11的火柴實例分割系統不僅能夠推動實例分割技術的發展,還能為實際應用提供有力支持,具有重要的研究價值和應用前景。
圖片效果
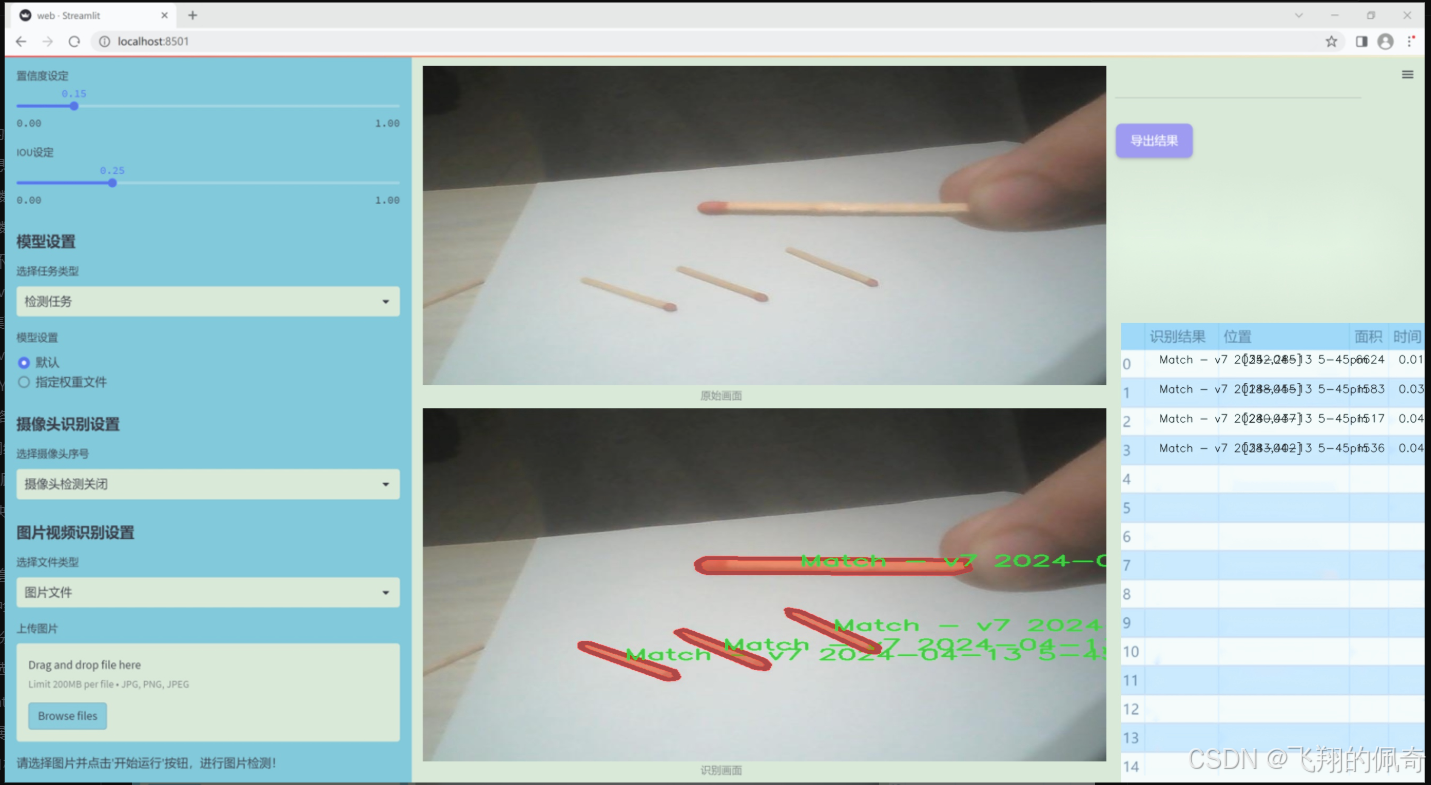
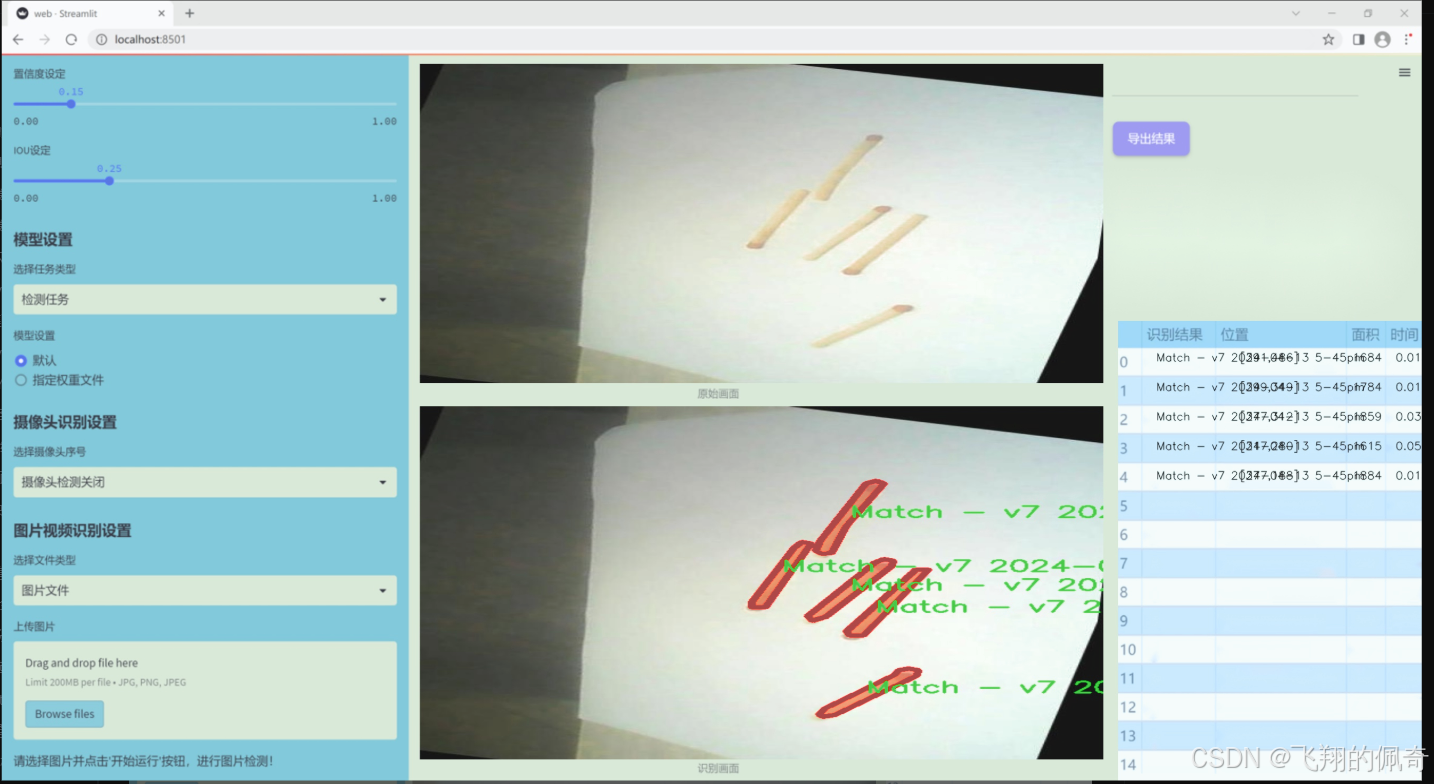
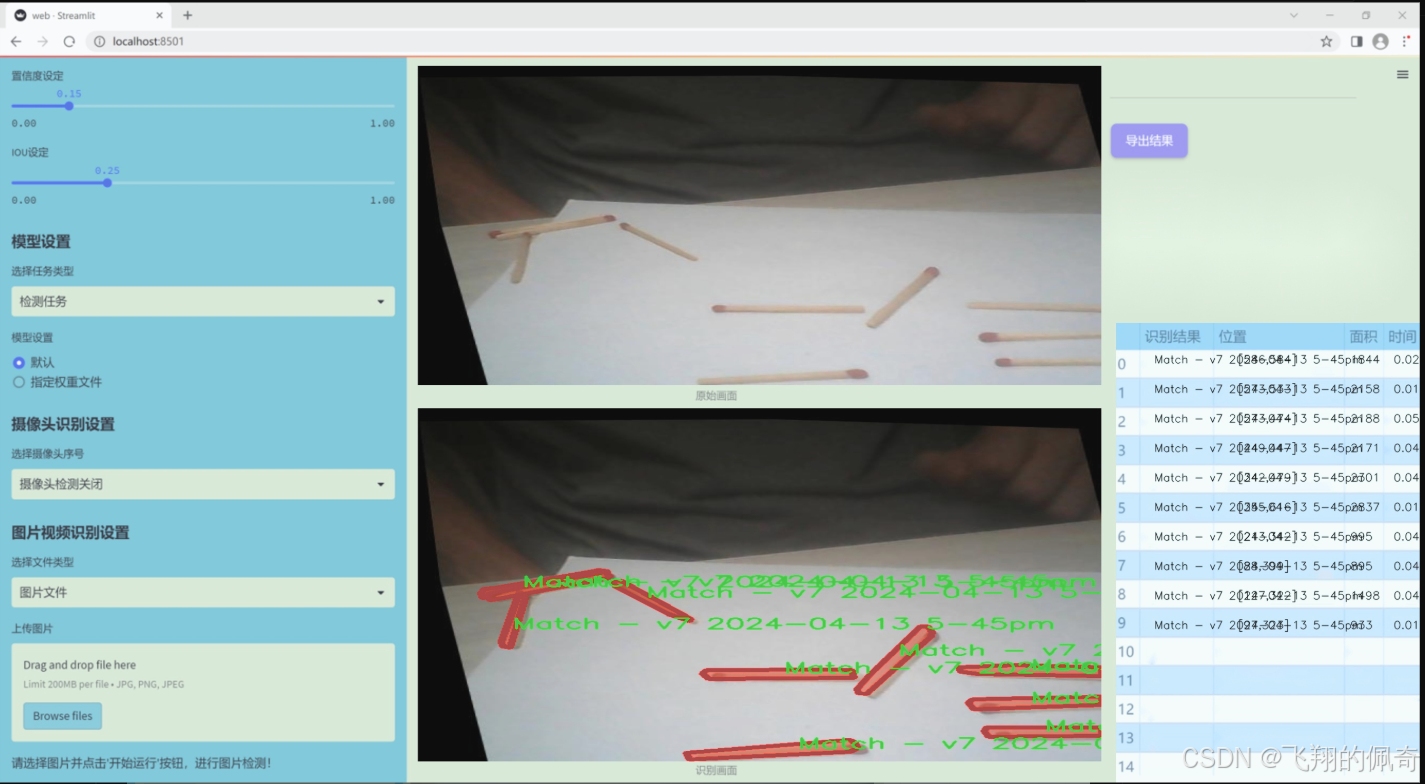
數據集信息
本項目數據集信息介紹
本項目所使用的數據集專注于“MatchSegmentation”主題,旨在為改進YOLOv11的火柴實例分割系統提供高質量的訓練數據。該數據集的設計旨在支持火柴圖像的精確分割,確保模型能夠有效識別和處理不同場景中的火柴實例。數據集中包含一個類別,具體為“Match - v7 2024-04-13 5-45pm”,這一類別的命名不僅反映了數據集的創建時間,也體現了其針對火柴實例的專門化特征。
數據集的構建過程經過精心設計,涵蓋了多種不同背景和光照條件下的火柴圖像,以確保模型在多樣化環境中的魯棒性。每個圖像都經過精確標注,確保火柴的輪廓和細節得以清晰呈現,這對于實例分割任務至關重要。通過這種方式,數據集不僅提供了豐富的視覺信息,還為模型的訓練提供了堅實的基礎,使其能夠在實際應用中實現更高的準確性和效率。
此外,數據集的多樣性和豐富性使其成為研究火柴實例分割的理想選擇。隨著YOLOv11的改進,研究人員能夠利用這一數據集進行深入的實驗和分析,從而推動火柴圖像處理技術的發展。通過對該數據集的深入挖掘和應用,項目團隊期望能夠在火柴實例分割領域取得突破性進展,為相關應用提供更為精準和高效的解決方案。總之,本項目的數據集不僅為模型訓練提供了必要的支持,也為未來的研究和應用奠定了堅實的基礎。





核心代碼
以下是經過簡化和注釋的核心代碼部分:
import torch
import torch.nn.functional as F
def selective_scan_easy(us, dts, As, Bs, Cs, Ds, delta_bias=None, delta_softplus=False, return_last_state=False, chunksize=64):
“”"
選擇性掃描函數,執行基于輸入的狀態和增量的遞歸計算。
參數:
us: 輸入狀態,形狀為 (B, G * D, L)
dts: 增量,形狀為 (B, G * D, L)
As: 權重矩陣,形狀為 (G * D, N)
Bs: 權重矩陣,形狀為 (B, G, N, L)
Cs: 權重矩陣,形狀為 (B, G, N, L)
Ds: 偏置項,形狀為 (G * D)
delta_bias: 可選的偏置調整,形狀為 (G * D)
delta_softplus: 是否對增量應用softplus函數
return_last_state: 是否返回最后的狀態
chunksize: 每次處理的序列長度返回:
輸出狀態,形狀為 (B, G * D, L) 或 (B, G * D, L) 和最后狀態
"""def selective_scan_chunk(us, dts, As, Bs, Cs, hprefix):"""處理一個塊的選擇性掃描,執行狀態更新和輸出計算。參數:us: 輸入狀態塊,形狀為 (L, B, G, D)dts: 增量塊,形狀為 (L, B, G, D)As: 權重矩陣,形狀為 (G, D, N)Bs: 權重矩陣,形狀為 (L, B, G, N)Cs: 權重矩陣,形狀為 (L, B, G, N)hprefix: 前一個狀態,形狀為 (B, G, D, N)返回:輸出狀態和更新后的狀態"""ts = dts.cumsum(dim=0) # 計算增量的累積和Ats = torch.einsum("gdn,lbgd->lbgdn", As, ts).exp() # 計算權重的指數rAts = Ats # 歸一化權重duts = dts * us # 計算增量與輸入狀態的乘積dtBus = torch.einsum("lbgd,lbgn->lbgdn", duts, Bs) # 計算加權增量hs_tmp = rAts * (dtBus / rAts).cumsum(dim=0) # 更新狀態hs = hs_tmp + Ats * hprefix.unsqueeze(0) # 加上前一個狀態ys = torch.einsum("lbgn,lbgdn->lbgd", Cs, hs) # 計算輸出return ys, hs# 數據類型設置
dtype = torch.float32
dts = dts.to(dtype) # 將增量轉換為指定數據類型
if delta_bias is not None:dts += delta_bias.view(1, -1, 1).to(dtype) # 應用偏置調整
if delta_softplus:dts = F.softplus(dts) # 應用softplus函數# 數據維度調整
B, G, N, L = Bs.shape
us = us.view(B, G, -1, L).permute(3, 0, 1, 2).to(dtype)
dts = dts.view(B, G, -1, L).permute(3, 0, 1, 2).to(dtype)
As = As.view(G, -1, N).to(dtype)
Bs = Bs.permute(3, 0, 1, 2).to(dtype)
Cs = Cs.permute(3, 0, 1, 2).to(dtype)
Ds = Ds.view(G, -1).to(dtype) if Ds is not None else Noneoys = [] # 存儲輸出
hprefix = us.new_zeros((B, G, D, N), dtype=dtype) # 初始化前一個狀態
for i in range(0, L, chunksize):ys, hs = selective_scan_chunk(us[i:i + chunksize], dts[i:i + chunksize], As, Bs[i:i + chunksize], Cs[i:i + chunksize], hprefix)oys.append(ys) # 添加輸出hprefix = hs[-1] # 更新前一個狀態oys = torch.cat(oys, dim=0) # 合并所有輸出
if Ds is not None:oys += Ds * us # 加上偏置項
return oys.permute(1, 2, 3, 0).view(B, -1, L) if not return_last_state else (oys, hprefix.view(B, G * D, N).float())
選擇性掃描函數的調用示例
result = selective_scan_easy(us, dts, As, Bs, Cs, Ds)
代碼說明:
函數定義:selective_scan_easy是主函數,執行選擇性掃描的邏輯。
參數說明:函數的參數包括輸入狀態、增量、權重矩陣等,具體的形狀要求在注釋中說明。
內部函數:selective_scan_chunk用于處理輸入的一個塊,計算輸出和更新狀態。
數據處理:對輸入數據進行類型轉換和維度調整,以適應后續計算。
循環處理:通過循環處理每個塊,更新輸出和狀態,最后合并結果。
以上是對核心代碼的簡化和詳細注釋,便于理解其功能和實現邏輯。
這個程序文件 test_selective_scan_easy.py 是一個用于實現和測試選擇性掃描(Selective Scan)算法的 PyTorch 代碼。選擇性掃描是一種用于處理序列數據的計算方法,通常用于遞歸神經網絡(RNN)和其他序列模型中。
代碼的開頭部分定義了一些導入的庫,包括數學運算、PyTorch、pytest 和 einops(用于張量重排的庫)。接著,定義了一個主要的函數 selective_scan_easy,該函數的目的是執行選擇性掃描操作。它的輸入包括多個張量,代表不同的參數和狀態,具體如下:
us: 輸入序列的張量,形狀為 (B, G * D, L),其中 B 是批量大小,G 是組數,D 是維度,L 是序列長度。
dts: 時間增量的張量,形狀與 us 相同。
As, Bs, Cs, Ds: 這些張量分別代表不同的線性變換矩陣,形狀和用途在函數注釋中有詳細說明。
delta_bias 和 delta_softplus: 可選的偏置和激活函數的標志。
return_last_state: 是否返回最后的狀態。
chunksize: 分塊大小,用于控制計算的并行度。
selective_scan_easy 函數內部定義了一個嵌套函數 selective_scan_chunk,用于處理每個塊的選擇性掃描邏輯。該函數實現了選擇性掃描的核心算法,包括計算中間狀態和輸出的邏輯。
接下來,函數對輸入數據進行了類型轉換和形狀調整,以確保它們適合后續的計算。然后,函數通過循環處理每個塊,調用 selective_scan_chunk 函數,并將結果存儲在列表中,最后將所有塊的結果合并。
在類 SelectiveScanEasy 中,定義了前向和反向傳播的方法,利用 PyTorch 的自動求導功能來計算梯度。這個類允許在訓練過程中使用選擇性掃描,并支持混合精度訓練。
代碼還包含了幾個版本的選擇性掃描實現(如 selective_scan_easyv2 和 selective_scan_easyv3),每個版本可能在實現細節上有所不同,以優化性能或內存使用。
最后,代碼中定義了一個測試函數 test_selective_scan,使用 pytest 框架對選擇性掃描的實現進行單元測試。測試涵蓋了不同的輸入配置,確保實現的正確性和穩定性。
整體來看,這個程序文件是一個復雜的深度學習模塊,旨在高效地實現選擇性掃描算法,并通過測試確保其功能的正確性。
10.4 val.py
以下是代碼中最核心的部分,并附上詳細的中文注釋:
class DetectionValidator(BaseValidator):
“”"
擴展自 BaseValidator 類的檢測模型驗證器。
用于驗證基于 YOLO 的目標檢測模型的性能。
“”"
def __init__(self, dataloader=None, save_dir=None, pbar=None, args=None, _callbacks=None):"""初始化檢測模型所需的變量和設置。"""super().__init__(dataloader, save_dir, pbar, args, _callbacks)self.metrics = DetMetrics(save_dir=self.save_dir, on_plot=self.on_plot) # 初始化檢測指標self.iouv = torch.linspace(0.5, 0.95, 10) # 生成用于計算 mAP 的 IoU 閾值self.niou = self.iouv.numel() # IoU 閾值的數量def preprocess(self, batch):"""對 YOLO 訓練的圖像批次進行預處理。"""# 將圖像移動到指定設備并進行歸一化處理batch["img"] = batch["img"].to(self.device, non_blocking=True)batch["img"] = (batch["img"].half() if self.args.half else batch["img"].float()) / 255for k in ["batch_idx", "cls", "bboxes"]:batch[k] = batch[k].to(self.device)return batchdef postprocess(self, preds):"""對預測輸出應用非極大值抑制(NMS)。"""return ops.non_max_suppression(preds,self.args.conf, # 置信度閾值self.args.iou, # IoU 閾值multi_label=True, # 允許多標簽agnostic=self.args.single_cls, # 是否單類檢測max_det=self.args.max_det, # 最大檢測數量)def update_metrics(self, preds, batch):"""更新檢測指標。"""for si, pred in enumerate(preds):self.seen += 1 # 記錄已處理的圖像數量pbatch = self._prepare_batch(si, batch) # 準備當前批次的真實標簽cls, bbox = pbatch.pop("cls"), pbatch.pop("bbox") # 獲取真實類別和邊界框if len(pred) == 0: # 如果沒有檢測到目標continuepredn = self._prepare_pred(pred, pbatch) # 準備預測結果# 計算真陽性(TP)等指標stat = self._process_batch(predn, bbox, cls)# 更新統計信息for k in self.stats.keys():self.stats[k].append(stat[k])def get_stats(self):"""返回指標統計信息和結果字典。"""stats = {k: torch.cat(v, 0).cpu().numpy() for k, v in self.stats.items()} # 轉換為 numpy 數組if len(stats) and stats["tp"].any():self.metrics.process(**stats) # 處理指標return self.metrics.results_dict # 返回結果字典def print_results(self):"""打印每個類別的訓練/驗證集指標。"""pf = "%22s" + "%11i" * 2 + "%11.3g" * len(self.metrics.keys) # 打印格式LOGGER.info(pf % ("all", self.seen, self.nt_per_class.sum(), *self.metrics.mean_results())) # 打印總體結果# 打印每個類別的結果if self.args.verbose and self.nc > 1 and len(self.stats):for i, c in enumerate(self.metrics.ap_class_index):LOGGER.info(pf % (self.names[c], self.seen, self.nt_per_class[c], *self.metrics.class_result(i)))def _process_batch(self, detections, gt_bboxes, gt_cls):"""返回正確的預測矩陣。參數:detections (torch.Tensor): 形狀為 [N, 6] 的檢測結果張量。gt_bboxes (torch.Tensor): 形狀為 [M, 5] 的真實標簽張量。返回:(torch.Tensor): 形狀為 [N, 10] 的正確預測矩陣,表示 10 個 IoU 閾值的結果。"""iou = box_iou(gt_bboxes, detections[:, :4]) # 計算 IoUreturn self.match_predictions(detections[:, 5], gt_cls, iou) # 匹配預測與真實標簽def save_one_txt(self, predn, save_conf, shape, file):"""將 YOLO 檢測結果保存到指定格式的 txt 文件中。"""gn = torch.tensor(shape)[[1, 0, 1, 0]] # 歸一化增益for *xyxy, conf, cls in predn.tolist():xywh = (ops.xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # 轉換為歸一化的 xywh 格式line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # 生成保存格式with open(file, "a") as f:f.write(("%g " * len(line)).rstrip() % line + "\n") # 寫入文件
代碼核心部分解釋:
DetectionValidator 類:這是一個用于驗證 YOLO 模型性能的類,繼承自 BaseValidator。
初始化方法:設置必要的變量和指標,包括檢測指標和 IoU 閾值。
預處理方法:對輸入的圖像批次進行歸一化和設備轉換。
后處理方法:應用非極大值抑制來過濾檢測結果。
更新指標方法:更新每個批次的檢測結果和真實標簽的統計信息。
獲取統計信息方法:計算并返回模型的性能指標。
打印結果方法:輸出模型在訓練/驗證集上的性能指標。
處理批次方法:計算 IoU 并返回正確的預測矩陣。
保存檢測結果方法:將檢測結果保存為指定格式的文本文件。
這個程序文件 val.py 是一個用于YOLO(You Only Look Once)目標檢測模型驗證的實現。它繼承自 BaseValidator 類,專注于通過檢測模型進行驗證。程序中導入了多個庫和模塊,包括 torch、numpy 和 ultralytics 的相關模塊,這些都是進行數據處理、模型評估和結果可視化所必需的。
在 DetectionValidator 類的初始化方法中,設置了一些必要的變量和參數,包括數據加載器、保存目錄、進度條、參數字典等。該類的主要功能是對YOLO模型的性能進行評估,計算各種指標,如mAP(mean Average Precision)等。初始化時還定義了一些與評估相關的變量,如 iouv(用于計算不同IoU閾值的向量)和 lb(用于自動標記)。
preprocess 方法負責對輸入的圖像批次進行預處理,包括將圖像轉換為適合模型輸入的格式,并根據需要進行歸一化處理。該方法還會根據配置決定是否保存混合標簽。
init_metrics 方法用于初始化評估指標,檢查數據集是否為COCO格式,并根據模型的類別名稱設置相應的參數。get_desc 方法返回一個格式化的字符串,用于描述各類指標。
postprocess 方法應用非極大值抑制(NMS)來處理模型的預測輸出,以減少重疊的邊界框。_prepare_batch 和 _prepare_pred 方法則分別用于準備真實標簽和模型預測的批次數據,以便后續的評估。
update_metrics 方法負責更新模型的評估指標,包括計算TP(True Positive)、FP(False Positive)等。該方法會根據模型的預測結果和真實標簽進行比較,并更新混淆矩陣。
finalize_metrics 方法在所有批次處理完成后設置最終的評估指標。get_stats 方法將統計信息整理為字典并返回。
print_results 方法用于打印訓練或驗證集的每類指標,包括每類的TP、FP等信息,并在需要時繪制混淆矩陣。
_process_batch 方法用于計算正確預測的矩陣,返回不同IoU閾值下的預測結果。build_dataset 和 get_dataloader 方法則用于構建YOLO數據集和返回數據加載器。
plot_val_samples 和 plot_predictions 方法用于可視化驗證樣本和模型預測結果,并將結果保存為圖像文件。
save_one_txt 方法將YOLO檢測結果保存為文本文件,格式化為特定的規范。pred_to_json 方法將預測結果序列化為COCO格式的JSON文件,以便后續評估。
最后,eval_json 方法用于評估YOLO輸出的JSON格式,并返回性能統計信息。它會檢查所需的文件是否存在,并使用pycocotools庫計算mAP指標。
整體來看,這個程序文件實現了YOLO模型驗證的完整流程,包括數據預處理、模型評估、結果可視化和性能統計,適用于目標檢測任務的評估和分析。
源碼文件

源碼獲取
歡迎大家點贊、收藏、關注、評論啦 、查看👇🏻獲取聯系方式👇🏻



單例模式)












詳解)


