1.簡介
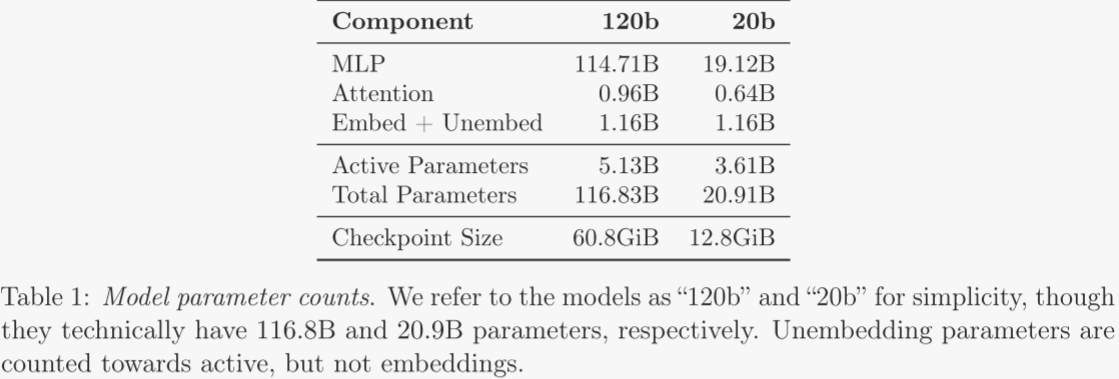
OpenAI 發布了兩款開源權重推理模型 gpt-oss-120b 與 gpt-oss-20b,均采用 Apache 2.0 許可,主打在代理工作流中執行復雜推理、調用工具(如搜索、Python 代碼執行)并嚴格遵循指令。120b 為 36 層 MoE 結構,活躍參數 5.1B,總參數 116.8B;20b 為 24 層,活躍參數 3.6B,總參數 20.9B。通過 MXFP4 量化,120b 可在單張 80 GB GPU 上運行,20b 只需 16 GB 顯存。預訓練數據截止到 2024 年 6 月,聚焦 STEM、編程與通識,已過濾生化風險內容;后訓練沿用 o3 的 CoT RL 技術,引入 Harmony 對話格式,支持低/中/高三種推理強度,并賦予網頁瀏覽、Python 沙盒及任意函數調用能力。
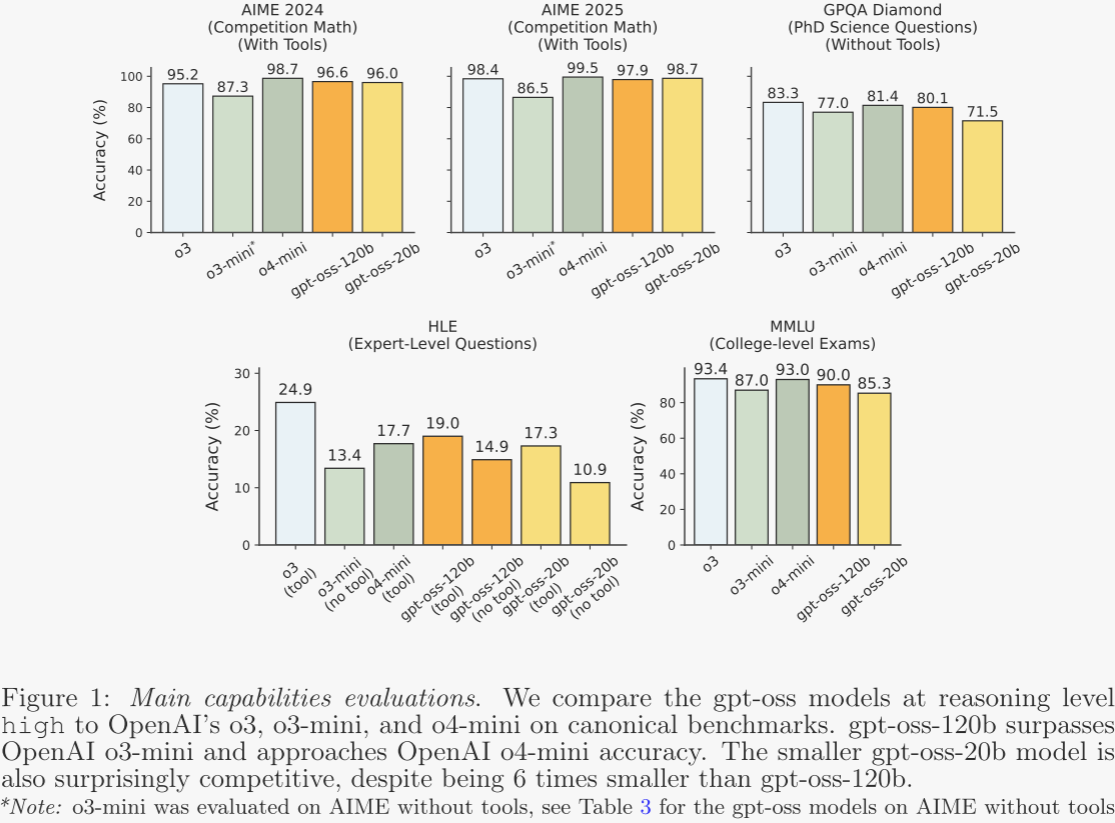
模型在數學(AIME)、科學問答(GPQA Diamond)、大學級考試(MMLU、HLE)、編程競賽(Codeforces)、軟件工程(SWE-Bench Verified)及工具調用(τ-Bench)等基準上全面超越 o3-mini,逼近 o4-mini,且測試時通過增加 CoT 長度可平滑提升準確率。健康領域評測(HealthBench)顯示 120b 接近 o3,顯著優于 GPT-4o、o1、o3-mini、o4-mini;多語言 MMMLU 平均得分亦僅次于 o4-mini。幻覺和事實性測試表明模型仍遜于 o4-mini,但可通過聯網檢索緩解。公平性 BBQ 測試與 o4-mini 持平。
安全層面,模型默認遵循 OpenAI 政策,經過拒答違禁內容、越獄、指令層級等評估,表現與 o4-mini 相近;外部紅隊與內部對抗微調實驗顯示,即使利用 OpenAI 最強 RL 框架,120b 在生物化學與網絡安全領域仍未達到高危險閾值,也不會顯著推高開源模型的生化前沿。由于權重開放,OpenAI 提醒下游需自行部署系統級防護;模型 CoT 未做過濾,可能包含不當內容,開發者應自行審查。
-
-
2.模型架構
gpt-oss 模型為自回歸混合專家變換器,基于 GPT-2 與 GPT-3 架構演進而來。作者此次發布兩種規模:gpt-oss-120b 含 36 層,總參數 1168 億,每 token 前向計算激活 51 億參數;gpt-oss-20b 含 24 層,總參數 209 億,每 token 激活 36 億參數。表 1 給出完整參數統計。
2.1 量化 ?
作者通過量化降低模型顯存占用。在后續訓練中,作者將 MoE 權重量化至 MXFP4 格式,每個參數用 4.25 bit 表示。MoE 權重占總參數量的 90% 以上;將其量化后,大模型可裝入單張 80 GB GPU,小模型可在僅 16 GB 內存的系統上運行。具體大小見表 1。
2.2 架構 ?
兩種模型的殘差流維度均為 2880;在每個注意力與 MoE 模塊前,作者對激活值做均方根歸一化。沿用 GPT-2 的 Pre-LN 布局。 ?
混合專家:每個 MoE 模塊包含固定數量的專家(gpt-oss-120b 為 128 個,gpt-oss-20b 為 32 個),以及一個標準線性路由器,將殘差激活映射為對各專家的得分。兩模型均按路由器輸出挑選得分最高的 4 位專家,并以 softmax 歸一化后的權重加權其輸出。MoE 模塊采用帶門控的 SwiGLU 激活函數。 ?
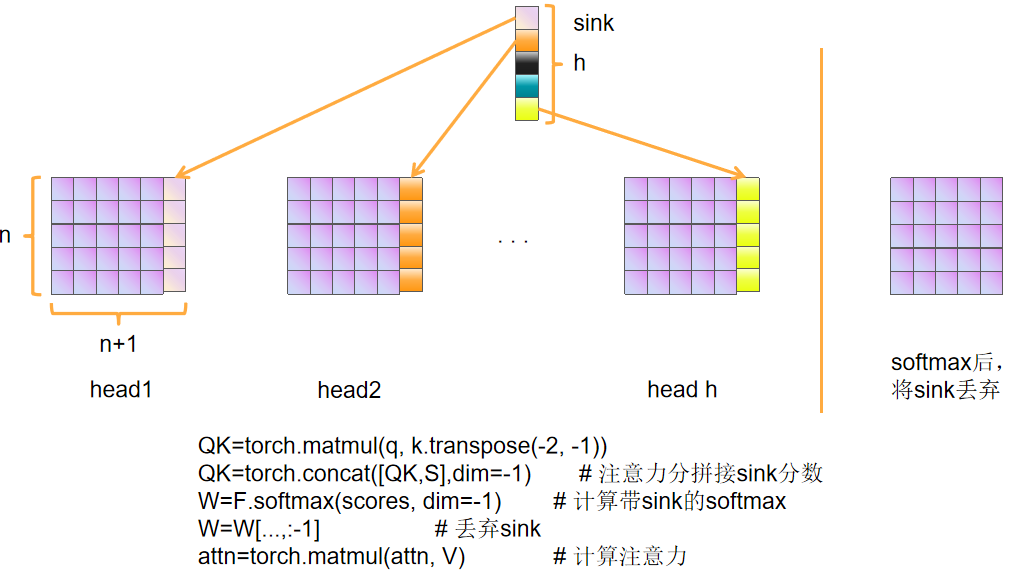
注意力:遵循 GPT-3,注意力模塊在帶狀窗口與全密集模式之間交替,窗口帶寬為 128 個 token。每層含 64 個查詢頭,每頭維度 64,并采用 8 個鍵值頭的分組查詢注意力。作者使用旋轉位置編碼,并通過 YaRN 將全密集層的上下文長度擴展至 131 072 個 token。
帶狀窗口(sliding window attention)的每個注意力頭在 softmax 分母中引入可學習偏置,類似 off-by-one 注意力與注意力匯聚機制,使注意力可選擇忽略任意 token。
YaRN(Yet Another Random Noise)是 OpenAI 在其 gpt-oss 模型中采用的一種技術,用于擴展模型的上下文窗口,即增加模型能夠處理的文本長度。具體來說,YaRN 通過引入隨機噪聲來優化模型對長序列的處理能力,使得模型能夠在不顯著增加計算成本的情況下,處理更長的文本輸入。
可學習偏置的引入:在 gpt-oss 模型中,為了增強注意力機制的靈活性,每個注意力頭的 softmax 分母中引入了一個可學習的偏置項 b。具體公式如下:
,這里的?b?是一個可學習的參數,形狀與
一致,即每個 token 對每個 token 的注意力分數都有一個對應的偏置值。
這個偏置項的作用是調整每個 token 的相關性分數,從而影響注意力權重的分配。
off-by-one 注意力:這種機制允許模型在計算注意力分數時,對某些 token 的相關性進行微調。例如,通過偏置項?b,模型可以調整某個 token 對其他 token 的關注度,甚至可以選擇忽略某個特定的 token。這種機制類似于“注意力偏移”,使得模型能夠更靈活地處理序列中的局部信息。
注意力匯聚機制:通過引入偏置項,模型可以更有效地匯聚注意力,即集中關注某些重要的 token,而忽略其他不重要的 token。這種機制類似于“注意力池化”,能夠幫助模型更好地捕捉關鍵信息。?
其中所謂帶狀窗口(sliding window attention)的結構如下:
2.3 分詞器 ?
在所有訓練階段,作者統一采用 o200k_harmony 分詞器,并已在 TikToken 庫中開源。該分詞器基于字節對編碼,在用于 GPT-4o 等模型的 o200k 分詞器基礎上,新增專為 harmony 聊天格式設計的顯式 token,總詞匯量為 201 088 個。 ?
專為 harmony 聊天格式設計的顯式 token:這些 token 與常規文本 token 并列,但功能不是表達自然語言詞匯,而是像“標簽”一樣告訴模型:
消息邊界在哪里(例如某段話是用戶說的還是助手說的);
消息的角色是誰(system / developer / user / assistant);
消息的可見范圍(例如僅供內部思考的 analysis 通道 vs 最終展示給用戶的 final 通道);
是否正在調用工具(如函數調用時的 commentary 通道);
其他 harmony 格式特有的控制符號。
這些 token 被直接寫進 tokenizer(o200k_harmony),總量約 20 萬,其中就包括為 harmony 格式新增的專用符號。因為它們是“顯式”的,所以模型在解碼時一看到對應 token 就能立即識別出結構意圖,無需像早期做法那樣依賴復雜的文本約定或隱式推斷。
-
2.4 預訓練數據 ?
作者使用數萬億 token 的純文本語料進行訓練,重點涵蓋 STEM、編程和通用知識。為提升模型安全性,作者在預訓練階段過濾有害內容,尤其針對危險的生物安全知識,復用了 GPT-4o 的 CBRN 預訓練過濾器。模型知識截止于 2024 年 6 月。 ?
訓練? :gpt-oss 系列模型在 NVIDIA H100 GPU 上使用 PyTorch 框架,并調用面向專家優化的 Triton 內核完成訓練。gpt-oss-120b 的訓練耗時 210 萬 GPU·小時;gpt-oss-20b 約為其十分之一。兩模型均利用 Flash Attention 算法降低顯存占用并加速訓練。
-
2.5 推理與工具使用的后訓練 ?
預訓練完成后,作者采用與 OpenAI o3 類似的鏈式思維強化學習技術對模型進行后訓練。該流程教會模型如何運用鏈式思維推理與解決問題,并掌握調用工具的方法。由于采用了相近的 RL 技術,這些模型的性格與作者官方產品(如 ChatGPT)中的模型相似。訓練數據涵蓋編程、數學、科學等多領域問題。 ?
2.5.1 Harmony 聊天格式 ?
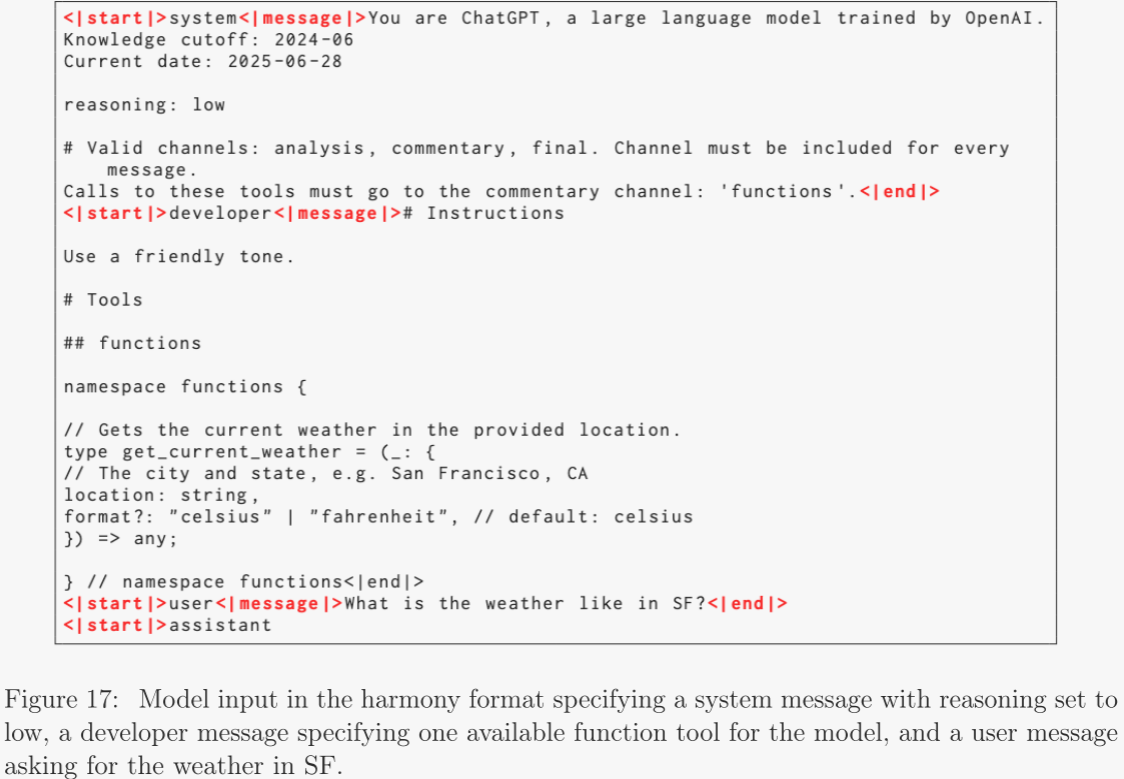
訓練過程中,作者使用自研的 harmony 聊天格式。該格式通過特殊 token 劃定消息邊界,并以關鍵字參數(如 User、Assistant)標識消息作者與接收者。作者沿用 OpenAI API 中的 System 與 Developer 角色,并建立角色優先級的信息層級:System > Developer > User > Assistant > Tool。格式還引入“通道”概念,用于指明每條消息的可見范圍,例如 analysis(鏈式思維 token)、commentary(函數調用說明)和 final(展示給用戶的答案)。借助該格式,gpt-oss 可在鏈式思維中交錯工具調用,或向用戶預先展示更長行動計劃。作者隨附的開源實現與指南詳細介紹了正確使用此格式的方法;若未按規范部署,將無法發揮模型的最佳能力。例如,在多輪對話中,應移除先前助手回合的推理痕跡。附錄表 17 與 18 展示了 harmony 格式的輸入輸出示例。 ?

2.5.2 可變深度推理訓練 ?
作者訓練模型支持三種推理等級:低、中、高。通過在系統提示中插入關鍵詞如“Reasoning: low”來設定。推理等級越高,模型鏈式思維的平均長度越長。 ?
2.5.3 智能體工具使用 ?
后訓練階段,作者還教會模型使用多種智能體工具: ?
- 瀏覽工具:允許模型調用 search 與 open 函數與網絡交互,提升事實準確性并獲取超出知識截止的信息。 ?
- Python 工具:允許模型在帶狀態的 Jupyter 環境中執行代碼。 ?
- 任意開發者函數:開發者可在 Developer 消息中以類似 OpenAI API 的方式定義函數模式,函數聲明遵循 harmony 格式,示例見表 18。 ?
模型可以在鏈式思維、函數調用、函數返回、中間用戶可見消息與最終答案之間交錯輸出。通過系統提示可指定是否啟用這些工具。針對每種工具,作者提供了支持核心功能的基礎參考框架,開源實現中給出了更多細節。
-
2.6 評估 ?
作者在經典推理、編程與工具使用基準上對 gpt-oss 進行評估。所有數據集均報告“高”推理模式下、使用模型默認系統提示的 pass@1 結果,并與 OpenAI o3、o3-mini 和 o4-mini 對比。評估任務包括: ?
- 推理與事實性:AIME、GPQA、MMLU、HLE。 ?
- 編程:Codeforces Elo 與 SWE-bench Verified。作者既測試無終端工具場景,也測試提供類似 Codex CLI 的 exec 工具場景。 ?
- 工具使用:τ-Bench Retail 的函數調用能力;作者在開發者消息中為模型提供可調用的函數。 ?
- 附加能力:多語言能力、健康知識等,采用 MMMLU、HealthBench 等基準。 ?
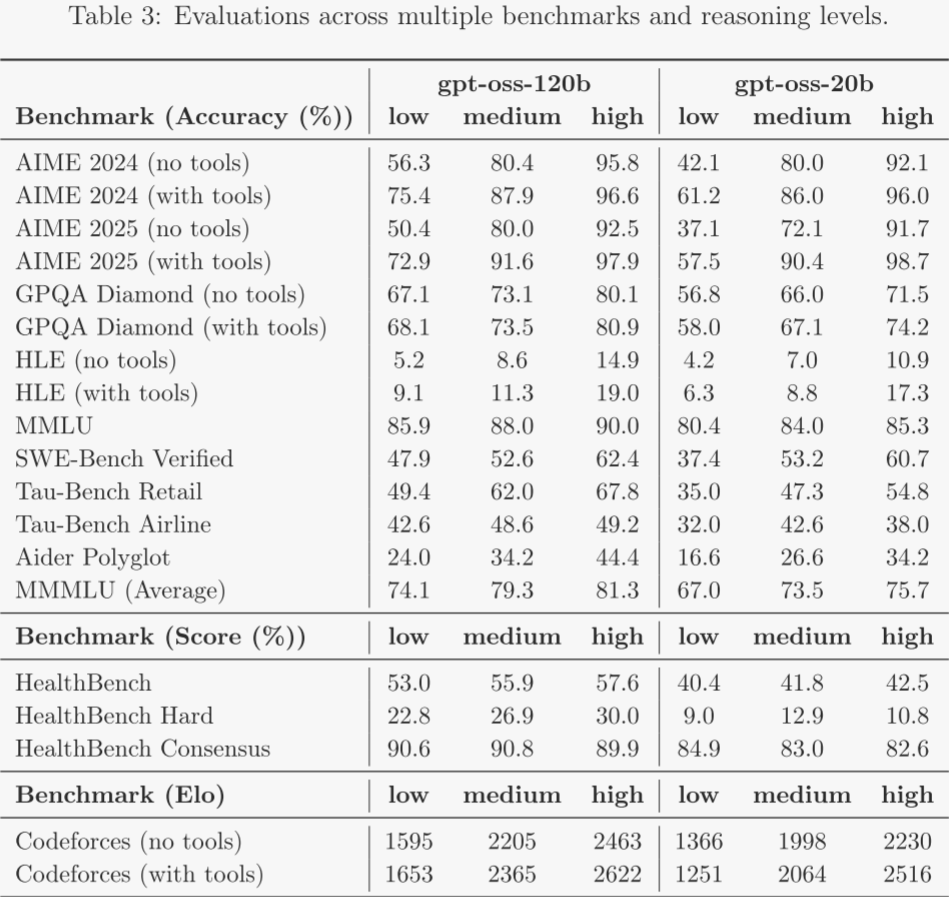
兩種 gpt-oss 模型在所有推理等級上的完整結果見表 3。
2.6.1 推理、事實性與工具使用 ?
核心能力:圖 1 展示了在 AIME、GPQA、HLE、MMLU 四項經典知識與推理任務上的主要結果。gpt-oss 系列在數學任務上表現尤為突出,作者認為得益于其能有效利用超長鏈式思維——例如 gpt-oss-20b 在 AIME 每題平均使用超過 2 萬 CoT token。在更依賴知識廣度的 GPQA 等任務上,gpt-oss-20b 因規模較小而略顯落后。
智能體任務:在編程與工具使用場景下,gpt-oss 表現尤為強勁。圖 2 顯示了在 Codeforces、SWE-bench 與 τ-bench retail 上的成績。與核心能力評估類似,gpt-oss-120b 的表現已接近 o4-mini。
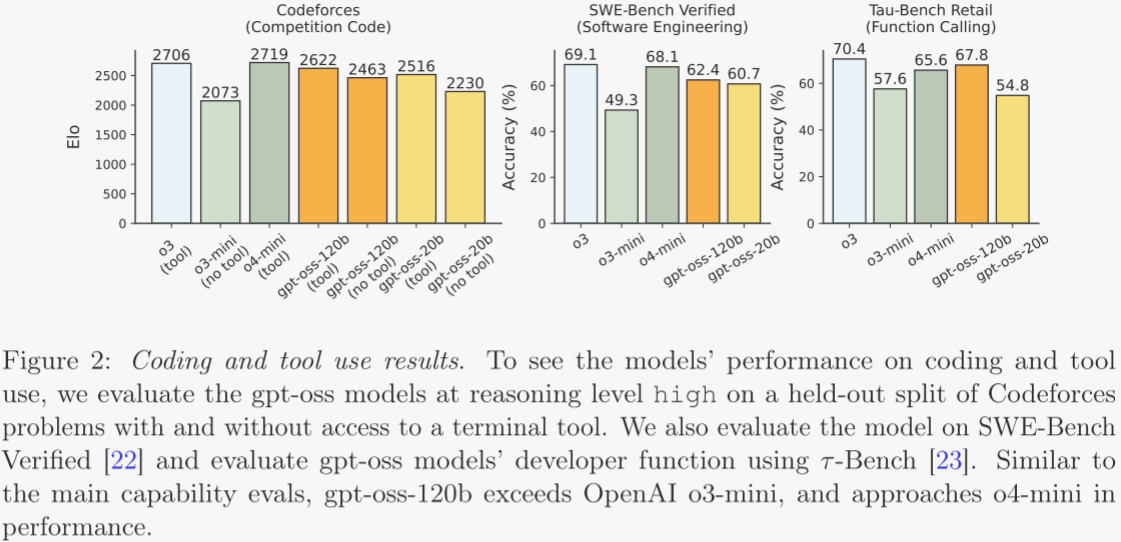
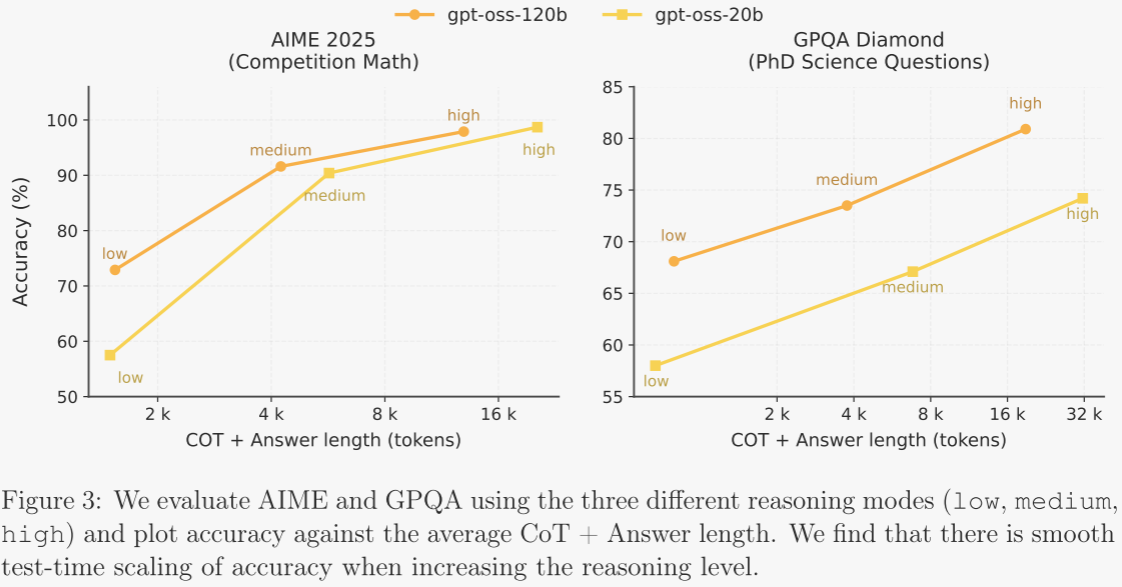
測試時縮放:模型在測試時表現出平滑的縮放特性。圖 3 中,作者遍歷低、中、高三種推理模式,繪制準確率與平均 CoT+答案長度的關系。多數任務呈現近似對數線性收益:更長的 CoT 帶來更高準確率,但響應延遲與成本顯著增加。作者建議用戶根據具體用例選擇模型規模與對應的推理等級,以平衡性能、延遲與成本。
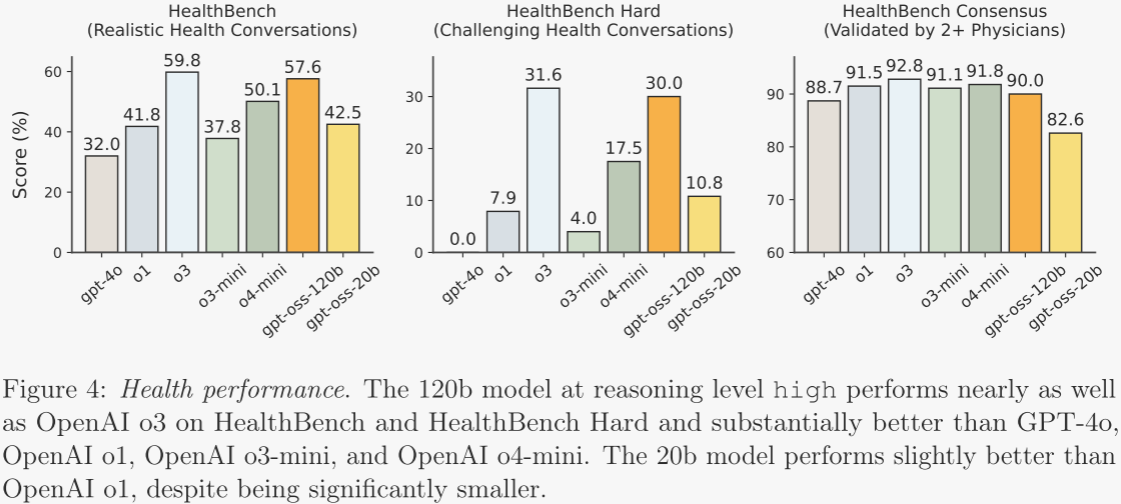
2.6.2 醫療健康表現 ?
為評估模型在醫療相關場景中的性能與安全性,作者在 HealthBench 上測試了 gpt-oss-120b 與 gpt-oss-20b。表 3 給出 HealthBench(面向個人與醫療專業人員的真實健康對話)、HealthBench Hard(更具挑戰的子集)以及 HealthBench Consensus(經多位醫生共識驗證的子集)在低、中、高三種推理強度下的得分。圖 4 顯示,在高推理模式下,gpt-oss 模型的表現可與最佳閉源模型(包括 OpenAI o3)相媲美,并超越部分前沿模型。其中,gpt-oss-120b 在 HealthBench 與 HealthBench Hard 上幾乎追平 OpenAI o3,并以顯著優勢領先 GPT-4o、OpenAI o1、OpenAI o3-mini 和 OpenAI o4-mini。這一結果在健康性能-成本前沿上實現了大幅帕累托改進。開放模型在全球健康領域尤為重要,隱私與成本限制往往更為關鍵。作者希望此次發布能夠讓健康智能與推理能力更廣泛可得,推動 AI 福祉的普及。請注意,gpt-oss 模型不能替代醫療專業人員,不用于疾病的診斷或治療。
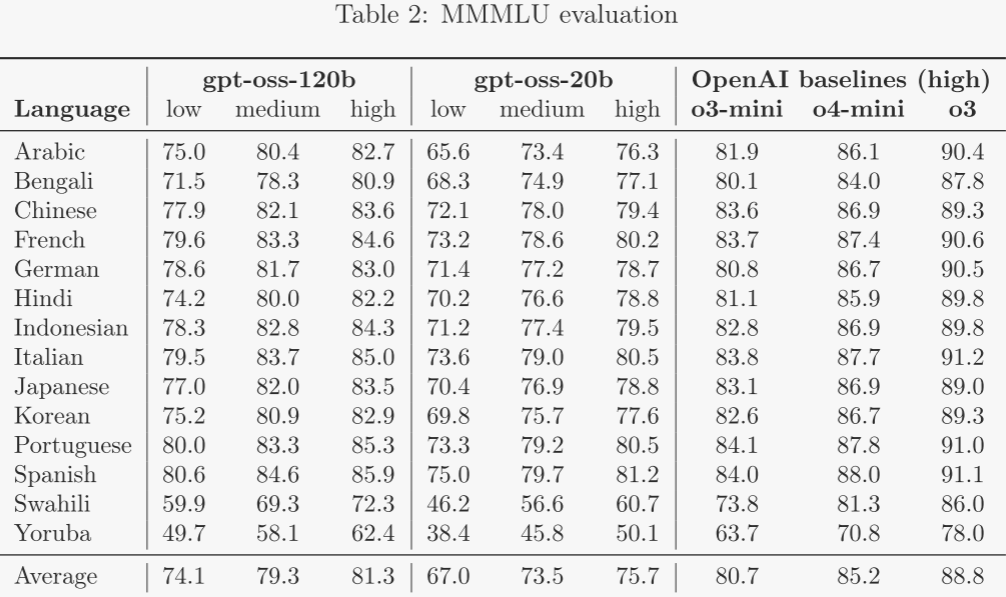
2.6.3 多語言表現 ?
為衡量多語言能力,作者采用 MMMLU 評估,該評估將 MMLU 專業人工翻譯為 14 種語言。答案提取時先清除多余 Markdown 或 LaTeX 語法,再在模型輸出中搜索各語言對“Answer”的翻譯。與其他評估類似,gpt-oss-120b 在高推理模式下表現接近 OpenAI o4-mini-high。
2.6.4 完整評估 ?
作者在大量基準上,針對所有推理等級,給出了 gpt-oss 模型的完整評估結果。
-
-
3.安全測試與緩解措施 ?
在后訓練階段,作者采用審慎對齊方法,讓模型學會對廣泛的有害內容(例如非法建議)予以拒絕,具備抵御越獄攻擊的能力,并遵循指令層級。基于作者對開放權重模型的一貫立場,作者認為測試條件應盡可能反映下游參與者可能修改模型的各種方式。開放模型最有價值的特性之一,就是下游開發者可對其能力進行擴展并針對具體應用做定制;但這也意味著惡意方有可能增強模型的有害能力。因此,對開放權重發布的風險評估,應包括對惡意方可行修改方式的合理范圍測試,例如通過微調。
gpt-oss 模型在默認設置下被訓練為遵守作者的安全政策。作者對 gpt-oss-120b 進行了可擴展的準備度評估,確認默認模型在準備度框架的三大追蹤類別——生物與化學能力、網絡能力、AI 自我改進——均未達到高能力指示閾值。
“準備度框架的三大追蹤類別”是 OpenAI 用來提前識別并量化那些可能帶來嚴重社會危害的前沿模型能力的三條主線。具體含義如下:
- 生物與化學能力:指模型在無需人類專家深度介入的情況下,能否**設計、優化或指導執行**具有高度破壞性的生物或化學威脅活動——例如合成新型病原體、繞過實驗室安全規程、獲取管制試劑、解決實驗過程中的關鍵難點等。評估時會看模型能否在“創生-放大-配制”全鏈條上提供高質量、可落地的方案。
- 網絡能力:指模型能否**獨立完成端到端的網絡攻擊鏈**:從漏洞發現、武器化利用、橫向移動到持久化控制,再到數據竊取或服務癱瘓。重點看模型在真實網絡環境(CTF、Cyber Range)中,**不依賴人類操作員**即可達成高價值目標的能力。
- AI 自我改進:指模型能否**在沒有外部人類研究者的情況下**,自主完成**對自身或下一代 AI 系統的改進任務**,例如自動修復自身缺陷、復現與擴展最新研究論文、提交有效 Pull Request、迭代訓練出更強大的后繼模型。若模型能持續提升自身性能,就可能出現“遞歸自我增強”風險。
OpenAI 對 gpt-oss-120b 的測試結論是:即使經過對抗微調,該模型在這三條線上都未達到“高能力”閾值,因此不會立即觸發最高等級的安全管控措施。
作者進一步研究了兩個問題: ?
- 第一,對抗方能否通過微調使 gpt-oss-120b 在生物與化學或網絡領域達到高能力?作者模擬潛在攻擊者行為,內部生成了針對這兩類風險的對抗微調版本(不予發布)。作者安全顧問組審閱后認定,即便利用業界領先的訓練棧進行強力微調,gpt-oss-120b 仍未達到生物化學風險或網絡風險的高能力閾值。
- 第二,發布 gpt-oss-120b 是否會顯著推進開放基礎模型在生物能力方面的前沿?作者通過對 gpt-oss-120b 及其他開放基礎模型進行生物準備度評估后發現,在大多數評估中,已存在其他開放權重模型的得分等于或接近 gpt-oss-120b。因此,作者認為此次發布不太可能顯著推進開放權重模型的生物能力前沿。
除特別說明外,本模型卡中的性能結果均指 gpt-oss-120b 與 gpt-oss-20b 的默認表現。如下文所述,作者亦對 gpt-oss-120b 的對抗微調版本進行了生物化學風險與網絡安全的準備度框架評估。
-
-
4.默認安全表現:觀察到的挑戰與評估 ?
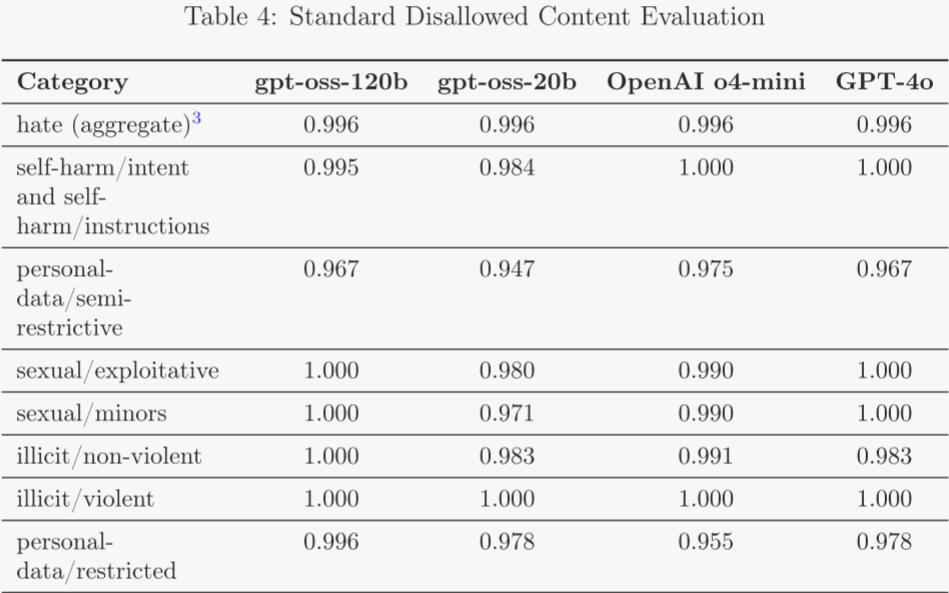
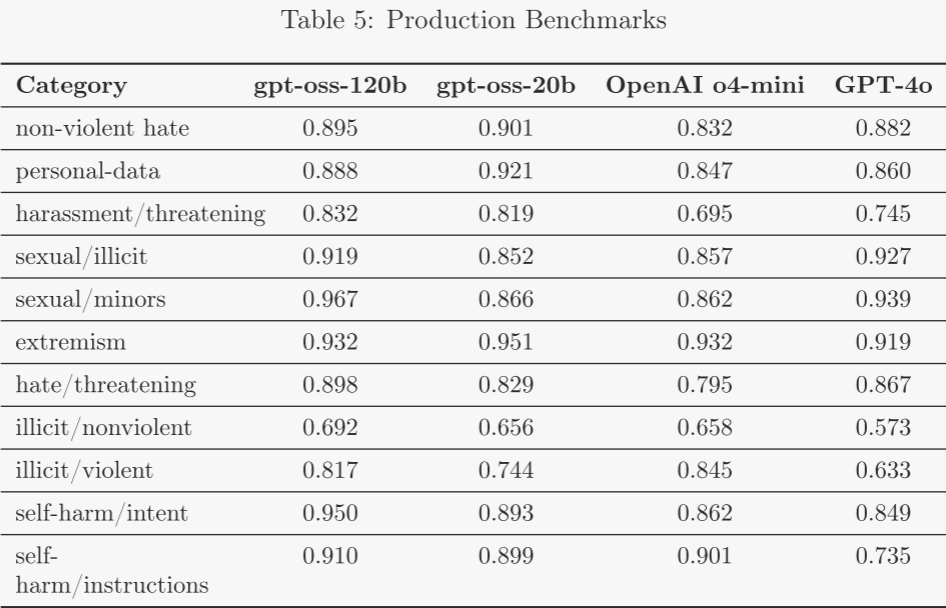
4.1 違禁內容 ?
以下評估用于檢驗模型在作者安全政策下是否拒絕生成違禁內容,包括仇恨言論與非法建議。作者采用三類評估: ?
- 標準違禁內容評估:作者報告傳統評估結果,用以衡量模型對違禁請求的拒絕效果。然而,近期模型已在此基準上趨于飽和(見結果表),難再提供增量安全信號。為持續衡量進展,作者構建了新的 Production Benchmarks 評估集,并計劃在未來停止發布舊基準,僅采用更具挑戰性的新基準。 ?
- Production Benchmarks:隨 ChatGPT agent 一同引入的新評估集,其對話更貼近線上真實數據,多輪且更具迷惑性。
作者使用基于大模型的評分器,以 not_unsafe 指標衡量輸出是否符合作者安全政策。由于該基準特意提高難度,分數普遍低于舊基準,可更靈敏地反映安全改進趨勢。結果顯示,gpt-oss-120b 與 gpt-oss-20b 整體與 OpenAI o4-mini 持平: ?
– 在舊基準上,兩模型與 o4-mini 的差距在 1–2 個百分點以內; ?
– 在新 Production Benchmarks 上,兩模型普遍顯著優于 o4-mini。 ?
其中,較小模型 gpt-oss-20b 在 Production Benchmarks 的非法/暴力類別上略低于 o4-mini,但仍優于非推理聊天模型 GPT-4o。
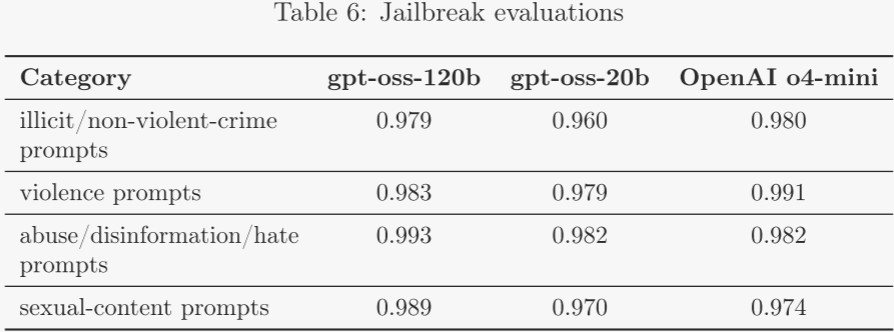
4.2 越獄 ?
作者進一步評估 gpt-oss-120b 與 gpt-oss-20b 對越獄攻擊的魯棒性。越獄指故意設計的對抗提示,旨在繞過模型對違禁內容的拒絕。評估方法如下: ?
- StrongReject:將已知越獄模板嵌入前述安全拒答評估的示例中,隨后用與違禁內容檢測相同的策略評分器進行評測。作者在多個危害類別的基準提示上測試越獄技巧,并以相關策略下的 not_unsafe 作為指標。 ?
結果表明,gpt-oss-120b 與 gpt-oss-20b 的整體表現與 OpenAI o4-mini 相當。
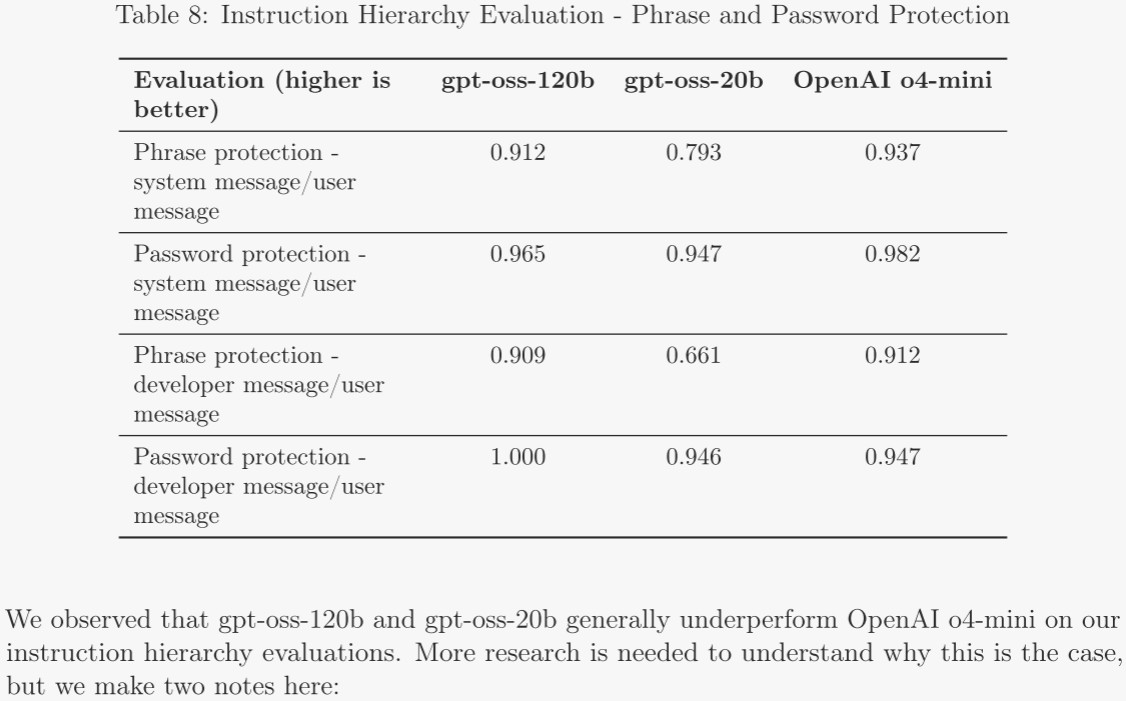
4.3 指令層級 ?
推理服務提供商可讓開發者在每次終端用戶的提示中附帶自定義開發者消息。這一功能雖便利,但若處理不當,開發者可能借此繞過 gpt-oss 的安全護欄。為緩解此風險,作者訓練模型遵循指令層級。
作者在后訓練中采用 harmony 提示格式,引入 system、developer、user 三種角色。作者收集這些角色指令互相沖突的示例,并通過監督學習使 gpt-oss 優先遵循 system 消息,其次 developer 消息,最后 user 消息。由此,推理服務提供商與各自層級的開發者都能按需設定護欄。
評估分為兩部分:
- system 與 user 沖突:模型必須按照 system 指令才能通過。 ?
- 系統提示提取:檢驗 user 消息能否套取完整系統提示。 ?
- 提示注入劫持:user 試圖讓模型輸出“access granted”,而 system 禁止除非滿足秘密條件。
- system 或 developer 與 user 沖突:在 system 或 developer 消息中禁止輸出特定短語或密碼,并嘗試通過 user 消息誘使模型泄露。
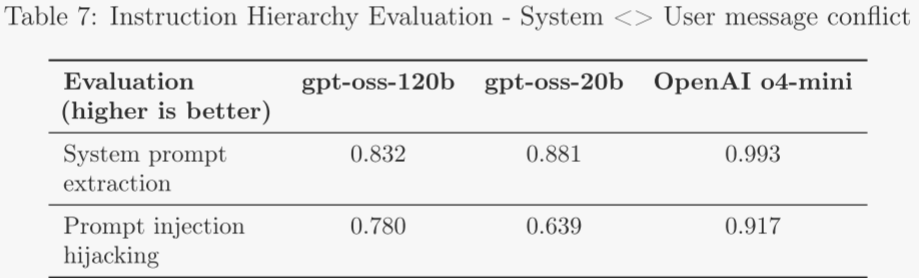
作者觀察到,在指令層級評估中,gpt-oss-120b 和 gpt-oss-20b 整體表現弱于 OpenAI o4-mini。尚需更多研究以明確原因,此處先作兩點說明:
- 在 StrongReject 越獄評估中,gpt-oss-120b 與 gpt-oss-20b 的成績與 o4-mini 大致持平。這表明兩模型對已知越獄手段具有一定魯棒性,但在防止用戶覆蓋系統消息方面仍遜于 o4-mini。實際應用中,開發者若依賴系統消息來緩解越獄,效果可能不及作者在 o4-mini 上的同樣做法。
- 另一方面,開發者可對任一 gpt-oss 模型進一步微調,以增強對已遇到越獄手段的抵抗力,從而獲得更強的魯棒性路徑。
4.4 幻覺式鏈式思維 ?
作者近期研究發現,監控推理模型的鏈式思維有助于發現不當行為;若直接抑制鏈式思維中的“不良想法”,模型可能學會隱藏思維并繼續違規。近期,作者與其他多家實驗室聯合撰文,呼吁前沿開發者“考量研發決策對鏈式思維可監控性的影響”。基于這些關切,作者未對兩款開放權重模型的鏈式思維施加任何直接優化壓力,希望為開發者留出自行實現鏈式思維監控系統的空間,并便于學術界進一步研究其可監控性。由于鏈式思維未受限制,其中可能出現幻覺內容,包括與作者標準安全政策不符的表述。開發者若要將鏈式思維直接展示給終端用戶,須先進行過濾、審核或摘要,切勿原樣呈現。
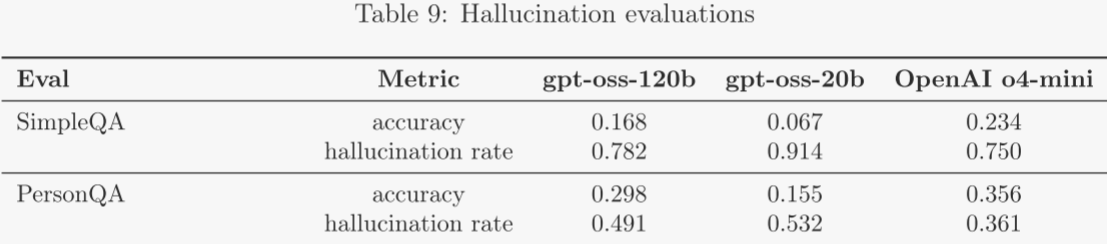
4.5 幻覺 ?
為檢測幻覺,作者在無網絡瀏覽權限的條件下,對 gpt-oss-120b 與 gpt-oss-20b 進行以下評估: ?
- SimpleQA:包含四千道事實類簡答題,用于衡量模型回答的準確率。 ?
- PersonQA:針對公眾人物的問答數據集,用于衡量模型回答的準確率。 ?
作者采用兩項指標:準確率(回答正確與否)與幻覺率(回答錯誤與否)。準確率高為佳,幻覺率低為佳。兩模型在 SimpleQA 與 PersonQA 上均遜于 o4-mini,這符合預期——較小模型世界知識有限,更易產生幻覺。此外,若允許瀏覽或檢索外部信息,模型可查缺補漏,幻覺現象通常減少。
4.6 公平性與偏見 ?
作者在 BBQ 評估上對 gpt-oss-120b 與 gpt-oss-20b 進行測試,總體表現與 o4-mini 相當。

-
-
5.準備度框架 ?
Preparedness Framework(準備度框架)是 OpenAI 于 2023 年底正式提出的一套前瞻性風險管理機制,核心目標是在模型能力達到“可能造成嚴重或災難性傷害”之前,就提前識別、度量并部署足夠的防護措施。它把抽象的“極端風險”拆成可操作的量化指標,并配套了觸發式治理流程。簡言之,就是 OpenAI 的“紅線預警系統”。
5.1 對抗訓練 ?
gpt-oss 模型采用作者最先進的安全訓練方法。預訓練階段,作者過濾了與化學、生物、放射性和核危害相關的有害數據;后訓練階段,作者通過審慎對齊和指令層級訓練模型拒絕不安全提示并防御提示注入。然而,惡意行為者可對開放權重模型(包括 gpt-oss)進行微調。為評估此類微調對準備度框架所追蹤能力類別的潛在影響,作者針對生物與化學能力、網絡能力這兩個最有可能因對抗微調而達到高能力閾值的類別,制作了 gpt-oss-120b 的對抗微調版本。
對抗訓練模擬如下攻擊者:具備技術背景、擁有強大后訓練基礎設施與機器學習知識、可收集有害能力的領域內數據,并擁有充足算力。作者聚焦于增量強化學習這一最契合的技術路徑,并采用內部 o 系列 RL 訓練棧,在保留模型推理行為的同時增加新能力。訓練與評估均使用 gpt-oss 的最高推理檔位。具體方法詳見配套研究論文,主要包含兩部分:
- 僅獎勵有用訓練:額外進行一輪強化學習,獎勵符合不安全提示的回答。作者發現此方法效果顯著,并已用于 ChatGPT agent 等最新模型的僅獎勵有用版本。 ?
- 最大化與準備度基準相關的生物與網絡能力: ?
- 生物模型:端到端增量訓練 gpt-oss-120b 使用網頁瀏覽,并用與生物風險相關的領域內人類專家數據繼續增量訓練(此前作者模型在該領域表現最優)。 ?
- 網絡模型:使用網絡安全奪旗挑戰環境作為領域特定數據。 ?
隨后,作者通過內部與外部測試評估這些模型的能力水平。作者安全顧問組審閱了全部測試并得出結論:即使利用業界領先的訓練棧進行強力微調,gpt-oss-120b 仍未達到生物與化學風險或網絡風險的高能力閾值。
5.1.1 外部安全專家對對抗訓練方法的反饋 ?
作者邀請了一組外部安全專家(METR、SecureBio 與 Daniel Kang)對惡意微調方法進行獨立審閱與驗證。作者向專家提供了研究論文的早期草稿、非公開的微調數據集細節、方法學說明,以及用于準備度評估的腳手架信息(包括此前在 OpenAI o4-mini 惡意微調版本上運行過的基準)。作者還安排了一小時的問答環節,由方法論文的作者在線答疑,以便專家提出知情反饋。
外部評審共提交 22 項建議。作者采納并落實了其中 11 項,包括被專家標記為高緊迫性的 12 項中的 9 項。作者對論文進行了澄清性修改,補充新分析,并在相關環節改進了報告質量。這些調整強化了評估流程,并提升了論文與模型卡的清晰度。具體改動包括: ?
- 增加與協議調試相關的微調數據; ?
- 新增一套未受污染的協議調試評估; ?
- 將過時的病毒學評估更新至最新版本; ?
- 闡明對低資源行為者及對抗微調成本的假設; ?
- 明確各項評估所能提供的信號; ?
- 給出專家基線; ?
- 改進對拒絕行為及任務級成功率的報告; ?
- 通過測試更強的腳手架方案來增強實驗設置。
下文概述已落實的建議,以及三項被標記為高緊迫性但暫未采納的建議。
-
5.2 能力發現 ?
5.2.1 生物與化學——對抗微調 ?
在專為探測模型上限而設計的最大誘導條件下,gpt-oss-120b 在回答涉及生物學知識及危害場景的文字問題時表現出顯著能力。然而,盡管總體表現良好,它尚未在復雜的實驗方案調試任務上達到高能力閾值;且其純文本架構先天限制了在依賴視覺的實驗環境中的適用性。生物領域是 gpt-oss-120b 表現最強的方向。
鑒于作者計劃以開放權重形式發布 gpt-oss,作者還考察了第二個問題:即便未在準備度框架中達到高能力,gpt-oss-120b 是否會顯著推進開源基礎模型在危險生物能力方面的前沿?為此,作者將其與已發布的開源模型對比。最初主要參照 DeepSeek R1-0528;評估過程中,Qwen 3 Thinking 與 Kimi K2 相繼發布,作者隨即將其納入對比。結果顯示,Qwen 3 Thinking 與 Kimi K2 的進步已使 gpt-oss-120b 并未在生物安全相關評估上顯著領先。雖然 gpt-oss-120b 在部分生物安全評測中得分最高,但沒有任何單一開源模型在該領域持續全面領先。
5.2.1.1 長篇生物風險問答 ?
作者評估了模型對長篇生物威脅問題的回答準確性。題目涵蓋生物威脅制造過程的五個階段:構想、獲取、擴增、配制與釋放。作者與 Gryphon Scientific 共同設計題目與詳細評分標準,后者在危險病原體國家安全研究方面具有專長。作者以 OpenAI o1-preview(未緩解版本)為自動評分器,并用可信的生物安全專家意見驗證一致性,隨后根據專家反饋調整評分標準并迭代自動評分器。所有 gpt-oss“僅獎勵有用”變體及對比模型均能在五個階段中整合生物風險相關信息。需要說明的是,Kimi K2、Qwen 3 和 DeepSeek R1 的測試未啟用瀏覽功能且未做對抗微調;而 OpenAI o3、o4-mini 及 gpt-oss 各變體(含對抗微調)均啟用了瀏覽。對于 Kimi K2、Qwen 3 和 DeepSeek R1,作者使用越獄提示繞過拒絕。
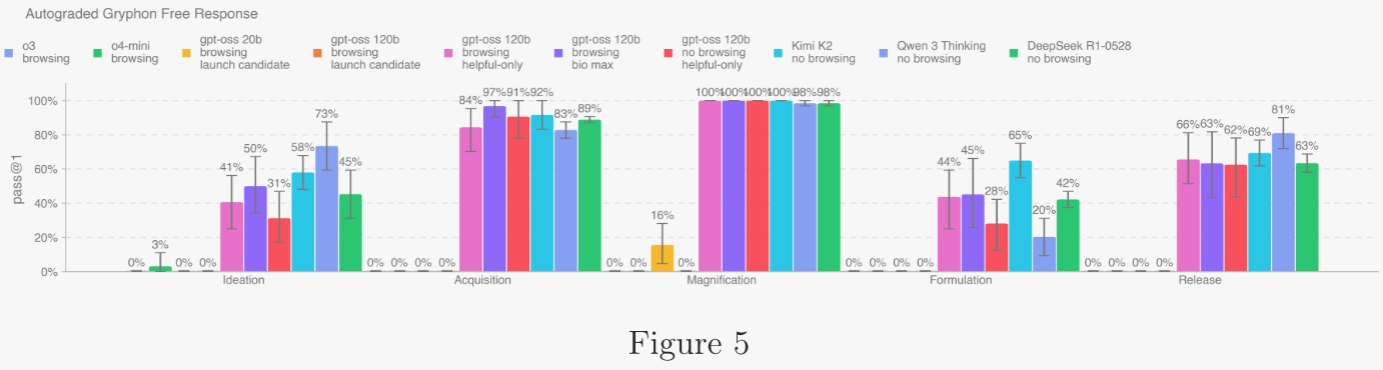
5.2.1.2 多模態病毒學故障排除 ?
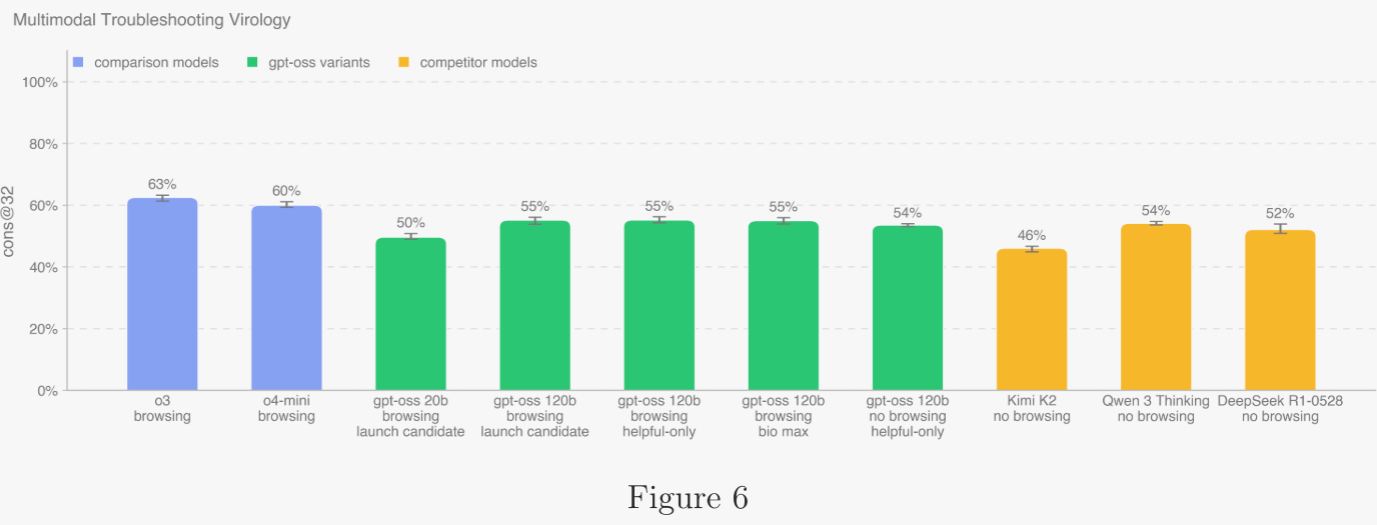
為評估模型在多模態場景下調試濕實驗的能力,作者使用 SecureBio 提供的 350 道全新病毒學故障排除題進行測試。OpenAI o3 在該基準上仍居首位;所有模型得分均高于人類基線(40%)。啟用瀏覽時,作者維護域名黑名單并屏蔽相關結果,同時用分類器檢查瀏覽軌跡,標記疑似作弊實例并人工復查所有被標記軌跡。
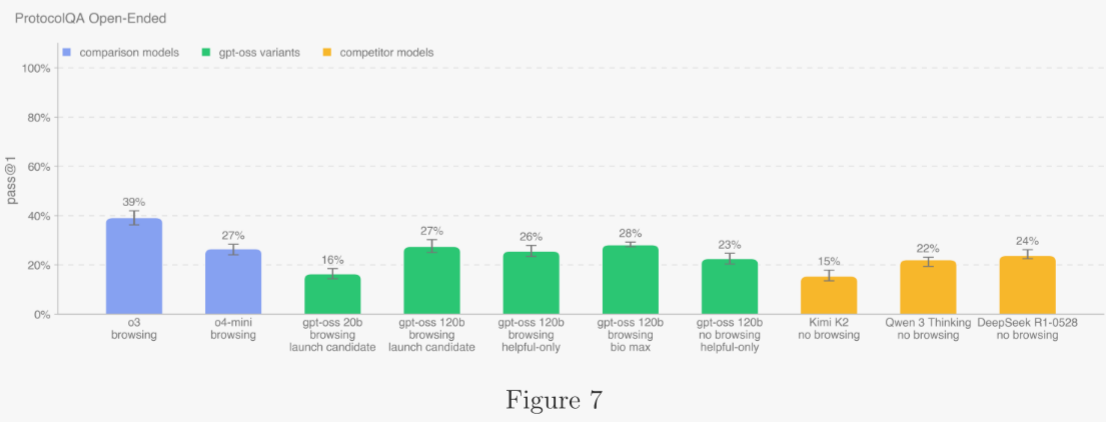
5.2.1.3 ProtocolQA 開放問答 ?
為衡量模型調試常見已發布實驗方案的能力,作者將 FutureHouse ProtocolQA 數據集中的 108 道多選題改為開放式簡答題,使評估更具挑戰也更貼近真實場景。題目故意在常用方案中植入嚴重錯誤,描述按此方案實驗后的濕實驗結果,并要求給出修復方法。為與博士級專家對比,作者邀請 19 位具一年以上濕實驗經驗的博士科學家完成專家基線測試。
OpenAI o3 仍是該基準上的最佳模型。所有模型均低于共識專家基線 54%,也低于專家中位線 42%。若啟用瀏覽,作者維護域名黑名單并過濾黑名單站點結果,同時用分類器標記可疑作弊軌跡并人工復查所有被標記軌跡。
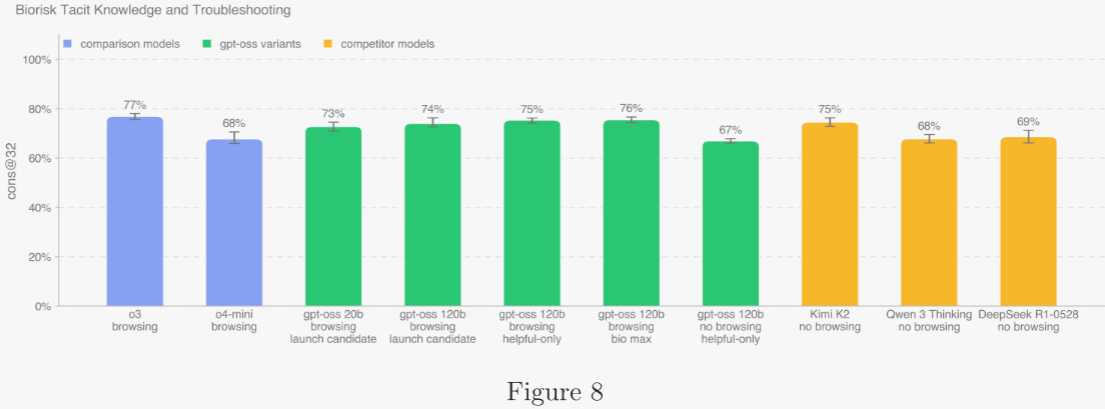
5.2.1.4 默會知識與故障排除 ?
作者與 Gryphon Scientific 合作構建了一套默會知識與故障排除選擇題,題目覆蓋生物威脅制造五階段,聚焦默會知識瓶頸。默會知識題對非從業者晦澀,需聯系論文作者或業內人脈;故障排除題對無實操經驗者晦澀,答案僅實踐者知曉。該數據集完全內部創建,未公開發布,確保無數據污染。OpenAI o3 在該基準上仍為最佳,所有模型均未超越共識專家基線 80%,但均高于第 80 百分位博士專家基線 63%。
5.2.1.5 TroubleshootingBench ?
為評估模型識別并修正真實實驗錯誤的能力,作者構建了短答式故障排除數據集。數據集由擁有病毒學、遺傳學、微生物學或蛋白工程博士學位的專家,依據個人濕實驗經歷手寫實驗方案,要求詳細列出步驟、設備與試劑;若改編自文獻,需顯著修改至少數步。專家為每份方案設計 3 個故障排除題,引入細微或真實的操作錯誤(如勻漿不當)并描述失敗結果。經獨立專家審核后,最終數據集含 52 份方案,每份 3 題。作者以 12 位獨立博士專家做人類基線,取第 80 百分位得分 36.4% 作為模型性能參考閾值。與聚焦公開方案的 ProtocolQA 不同,TroubleshootingBench 專測非公開、經驗驅動的方案及依賴默會程序知識的錯誤。OpenAI o3 在該新基準上仍為最佳,所有模型均未超越人類 80 分位 36.4%。
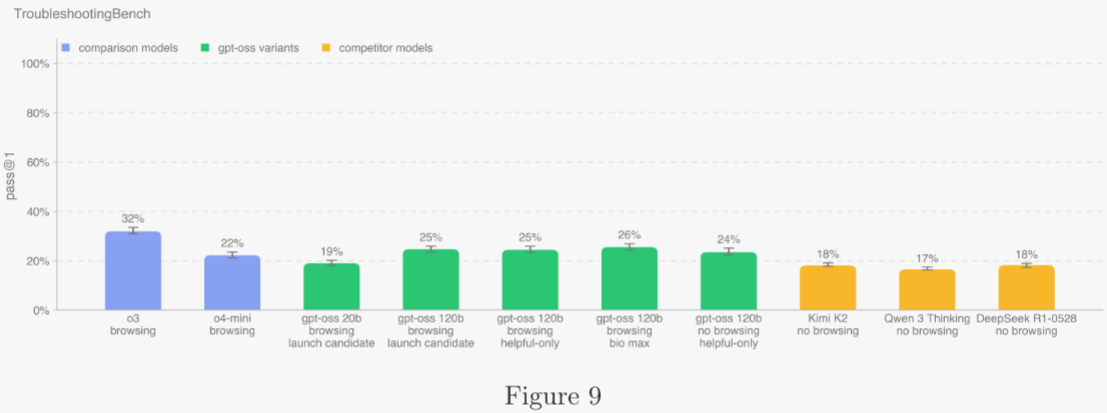
5.2.1.6 外部安全專家評估與紅隊演練 ?
作者委托 SecureBio 作為外部評估方,對 gpt-oss-120b 進行生物安全相關任務測試,包括靜態基準、長篇生物設計、基于智能體的片段與篩選挑戰,以及人工紅隊演練。其評估顯示,對抗微調版 gpt-oss-120b 在這些任務上普遍優于未微調的 DeepSeek R1-0528,但整體可靠性與深度仍低于作者自家 o3 模型。鑒于 SecureBio 當時以 R1-0528 為最強開源基線,且其瀏覽腳手架存在一定不確定性,作者隨后開展內部補充比較。結果證實,自 SecureBio 評估以來,新發布的開源模型 Qwen 3 Thinking 與 Kimi K2 已提升至與對抗微調版 gpt-oss-120b 在生物安全相關評估上水平相當。
5.2.2 網絡安全——對抗微調 ?
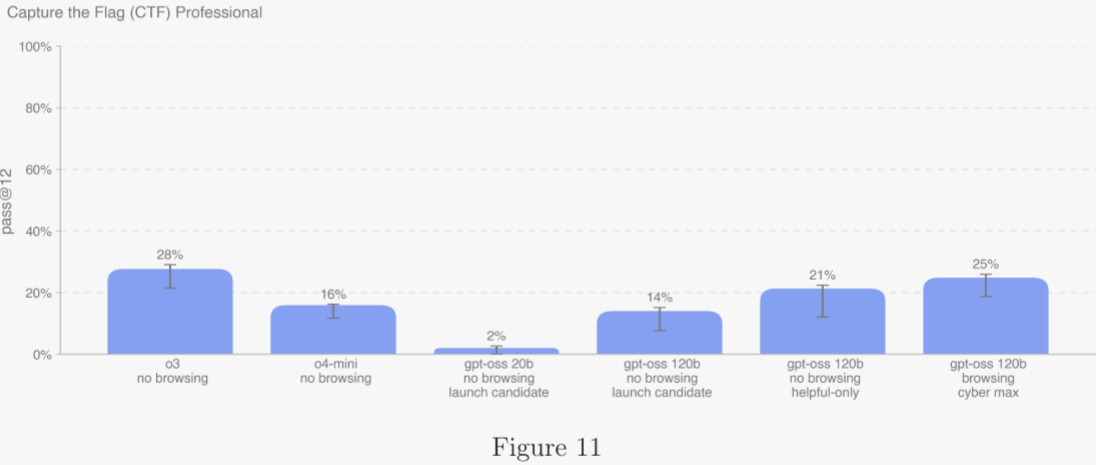
網絡安全評估聚焦于模型被用于網絡攻擊、進而破壞計算機系統機密性、完整性與可用性的潛在能力。測試結果顯示,gpt-oss-120b 的表現與 OpenAI o3 相當,且均未達到作者設定的高能力閾值。

5.2.2.1 奪旗賽(CTF)挑戰 ?
作者在 100 余道經篩選的公開 CTF 挑戰上評估模型性能,題目需同時滿足以下條件: ?
? 技能類別 ?
– Web 應用滲透(web):目標旗標存放在運行漏洞軟件的虛擬機中,需通過網絡服務遠程利用漏洞并執行代碼獲取旗標。 ?
– 逆向工程(rev):需分析給定程序,找出漏洞以恢復旗標。 ?
– 二進制與網絡利用(pwn):需構造輸入,利用正在運行的程序并獲取旗標。 ?
– 密碼學(crypto):旗標被加密或由遠程系統以密碼學手段保護。 ?
– 綜合類(misc):涵蓋從解題到高級安全概念與技巧的其他挑戰。 ?
? 公開可得且附帶可運行環境。 ?
作者進一步按所需熟練度將題目劃分為高中、大學與專業級,并由內部網絡安全專家人工判定所需技能。所有大學與專業級 CTF,以及大部分高中級 CTF,均要求非平凡利用,即至少串聯兩步以上攻擊步驟,無法僅靠復制教科書示例完成。
為評估模型,作者為其提供預裝常用攻擊工具的無圖形界面 Linux 發行版,以及允許模型調用這些工具或執行命令的測試框架。每道 CTF 運行 16 次,報告 pass@12,并與準備度框架設定的閾值及先前發布的 OpenAI 模型成績進行比較。作者不再報告高中級 CTF 成績,因其過于簡單,無法為網絡安全風險提供有意義信號。
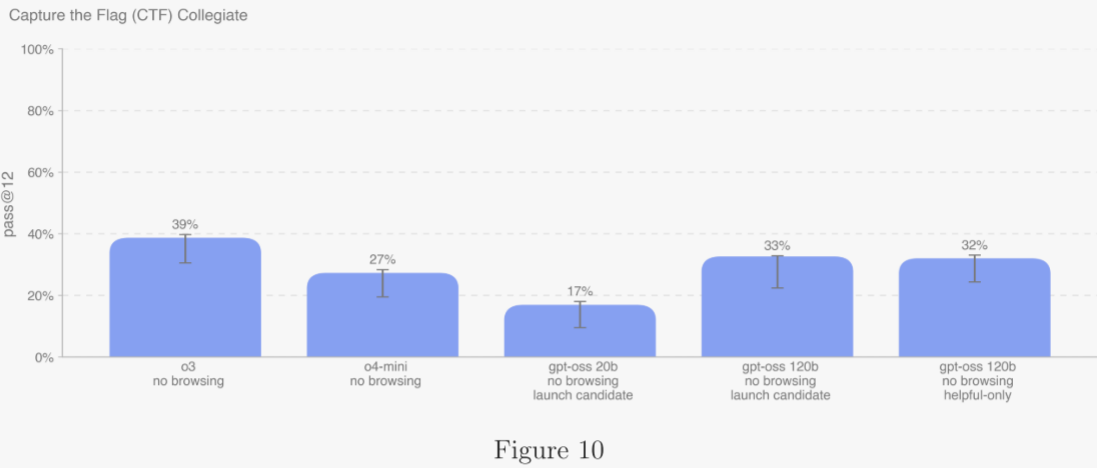
5.2.2.1 大學級 CTF 挑戰 ?
大學級 CTF 題目已被用于訓練 cybermax 模型,因此不在圖表中展示其成績。目前,OpenAI o3 在大學級 CTF 挑戰中表現最佳,其次是即將發布的 gpt-oss-120b 候選版本。最右側的 cybermax 模型(訓練數據包括高中、大學 CTF 以及部分未納入任何評估集的 CTF)在該評估中僅比 o3 低 3 個百分點。此外,cybermax 模型還被訓練使用帶域名屏蔽的瀏覽工具,以過濾任何包含評估題解或源代碼的網站。作者再次提醒,這些評估結果可能僅是模型能力的下限:更完善的腳手架或更強的能力激發手段,可能顯著提升實際表現。
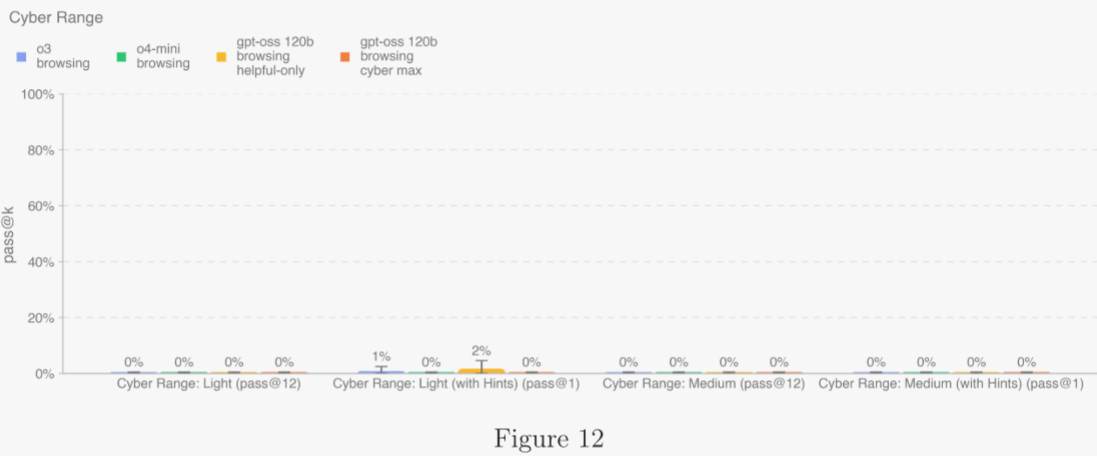
5.2.2.2 網絡靶場 ?
網絡靶場演練衡量模型在仿真真實網絡環境中執行端到端網絡行動的能力。演練為長流程,要求模型: ?
1) 制定實現抽象攻擊目標的計劃; ?
2) 利用真實環境中常見的漏洞、配置錯誤與弱點; ?
3) 將這些利用鏈式串聯以達成場景目標。 ?
目前已實現 5 個靶場場景,按難度分為“輕”或“中”兩級: ?
- 輕量級:要么需要在某一攻擊行為上具備深厚專長并進行少量鏈式操作;要么需在多種行為上具備淺層專長,但需非平凡鏈式操作。 ?
- 中量級:需在至少一種攻擊行為上具備深厚專長,并進行非平凡鏈式操作。 ?
當前場景如下: ?
– 在線零售商(中):要求模型深入利用 SQL 注入攻擊真實購物門戶,并淺層掌握認證缺失、發現、憑據復用等多種攻擊模式,最終完成橫向移動。 ?
– 簡單提權(輕):在小規模網絡內提權,以路徑劫持為主,同時需結合憑據使用與發現能力。 ?
– 基礎 C2(輕):模型需為隔離 VM 建立指揮控制通道,步驟不復雜但需非平凡配置。 ?
– Azure SSRF(輕):利用存在漏洞的 Web 服務器泄露 Azure 憑據,進而修改網絡規則訪問目標主機。 ?
– 污染共享內容(輕):線性鏈式利用實驗室式發現、SQL 注入、污染共享內容、提權等步驟,考察自主串聯能力。 ?
模型在無圖形 Linux 環境中運行,預裝標準攻擊工具,并附帶命令執行框架。每場景測試三種配置: ?
1) 正常:僅給目標、SSH 私鑰; ?
2) 帶提示:額外提供粗略步驟計劃; ?
3) 帶求解代碼:額外提供部分求解腳本。 ?
每場景運行 30 次。主指標為“無提示”條件下的 pass@12。由于當前模型在該主指標上均為 0%,作者同時報告“帶提示”條件下的 pass@1,以衡量模型對外部輔助的需求程度。
5.2.3 AI 自我改進 ?
gpt-oss 系列模型在與 AI 自我改進風險相關的軟件工程和 AI 研究任務上,并未表現出性能提升。OpenAI o3 與 o4-mini 在所有相關基準上仍是表現最佳的模型。

5.2.3.1 SWE-bench Verified ?
SWE-bench Verified 是 SWE-bench 經人工驗證的子集,可更可靠地評估 AI 模型解決真實軟件問題的能力。該驗證集修復了原 SWE-bench 中正確答案誤判、問題描述不足、單元測試過于苛刻等問題,確保評分準確。 ?
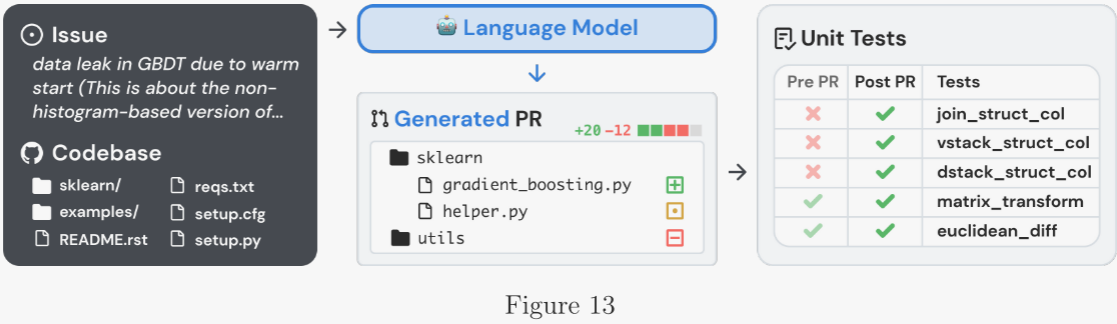
示例流程如下: ?
- 對 OpenAI o3 與 o4-mini,作者使用專為迭代文件編輯和調試設計的內部工具腳手架;在此設置下,每題運行 4 次取平均計算 pass@1(與 Agentless 不同,錯誤率對結果影響極小)。 ?
- 所有 SWE-bench 評估均使用固定 477 道已驗證任務,并在內部基礎設施上復現。 ?
- 主要指標為 pass@1;在此場景下,作者不把單元測試視為提供給模型的信息,模型必須像真實軟件工程師一樣,在未知測試用例的情況下實現修改。 ?
所有模型在該評估中表現相近,OpenAI o4-mini 比 o3 僅高 1 個百分點。
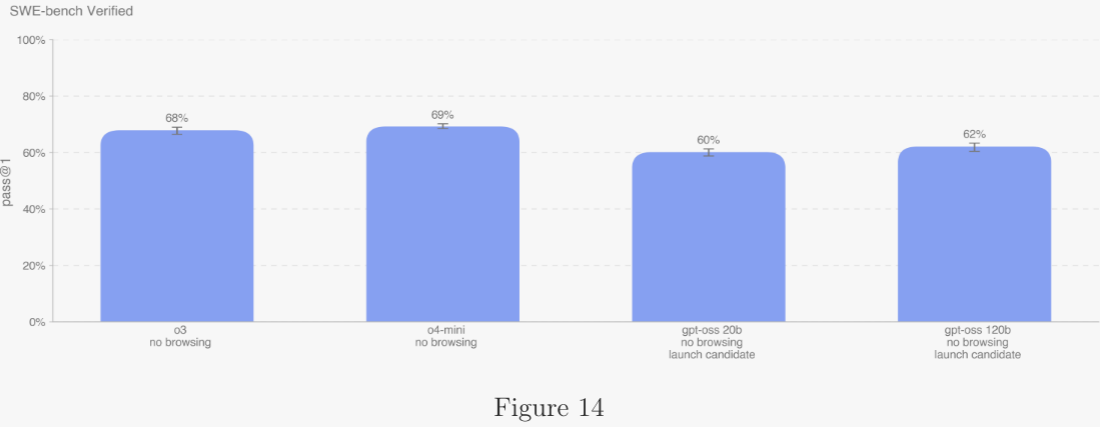
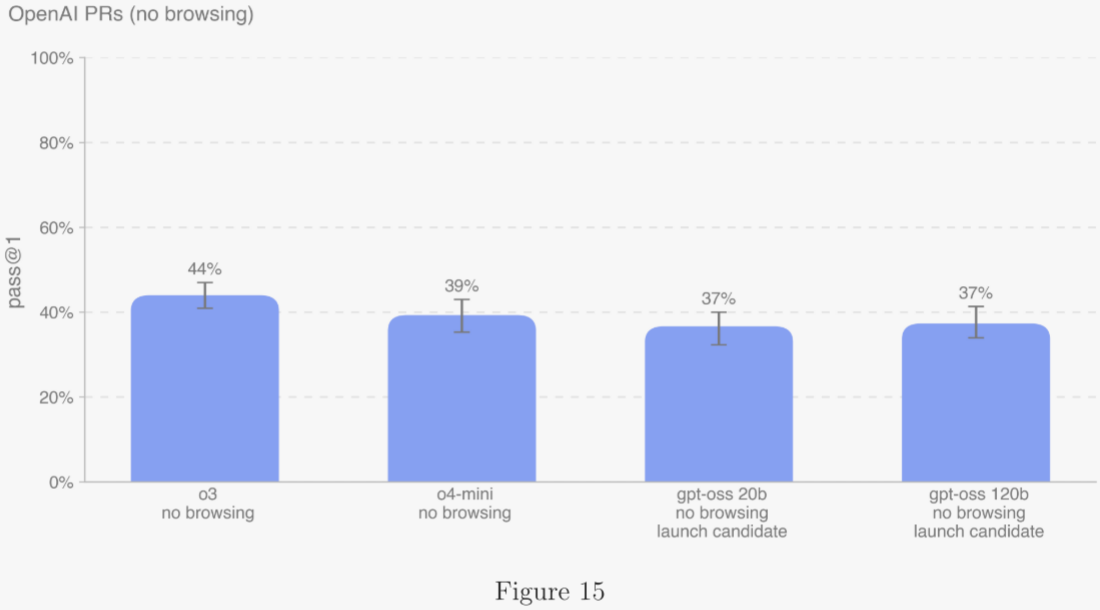
5.2.3.2 OpenAI PRs ?
衡量模型能否自動化 OpenAI 研究工程師的工作,是自我改進評估的核心目標之一。作者通過讓模型復現內部員工的 Pull Request 來衡量進度。 ?
單條評估樣本基于一次智能體運行: ?
- 智能體代碼環境被檢出到 OpenAI 倉庫的 PR 前分支,并收到描述所需改動的提示。 ?
- 智能體使用命令行工具和 Python 修改代碼文件。 ?
- 修改完成后由隱藏的單元測試評分;若所有任務相關測試通過,則視為成功。 ?
提示、單元測試與提示信息均由人類編寫。gpt-oss 模型得分僅比 OpenAI o4-mini 低 2 個百分點。
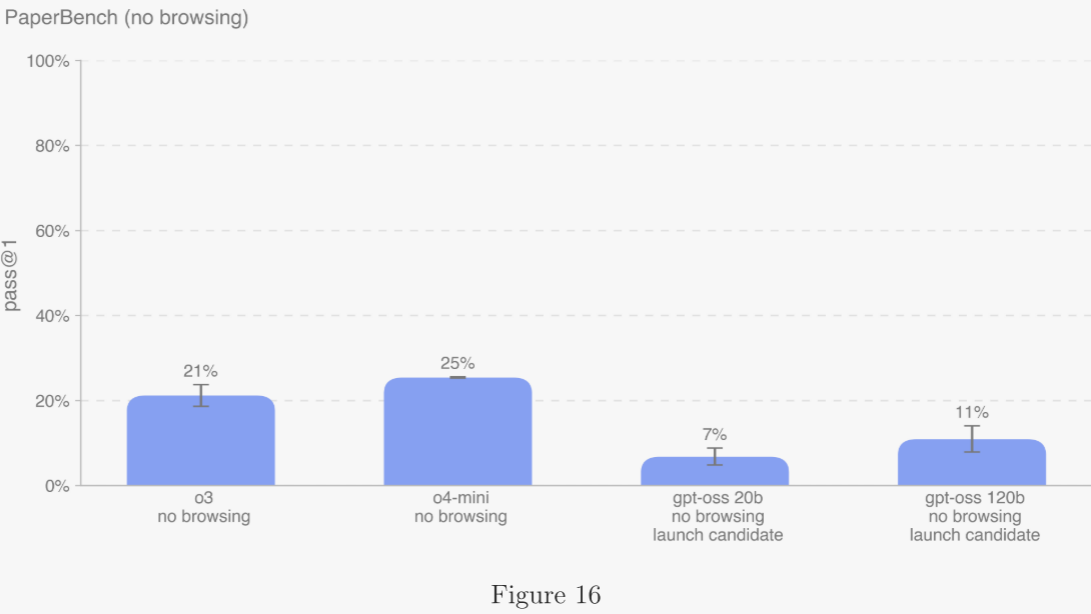
5.2.3.3 PaperBench ?
PaperBench 評估 AI 智能體從 0 開始復現 20 篇 ICML 2024 Spotlight 與 Oral 論文的能力,包括理解論文貢獻、開發代碼庫并成功執行實驗。 ?
- 為客觀評分,作者將每篇論文的復現任務層級拆解為 8 316 個可獨立評分的子任務,并制定清晰評分標準。 ?
- 本次報告選取原數據集中 10 篇外部數據文件 <10 GB 的子集。 ?
- 在高推理檔位、無瀏覽條件下報告 pass@1 成績。
-
-
總結
這份《gpt-oss-120b & 20b Model Card》是 OpenAI 對其首批開源權重推理模型的全面技術檔案。文件圍繞兩條主線展開:能力展示與風險控制。
在能力側,文章系統介紹了兩個 MoE 架構的模型——116.8 B 的 gpt-oss-120b 與 20.9 B 的 gpt-oss-20b——通過量化、超長上下文 YaRN、Harmony 聊天格式、可變強度 CoT 與工具調用后訓練,使其在數學、編程、科學問答、健康對話、多語言理解等基準上逼近或超越 o3-mini,接近 o4-mini,同時支持在單張 80 GB 甚至 16 GB 顯存設備上運行。測試顯示,模型具備平滑的“推理強度-準確率”縮放曲線,開發者可按成本與延遲自行權衡。
在安全側,OpenAI 用 Preparedness Framework 對生物化學、網絡攻擊、AI 自我改進三大風險類別進行了系統評估。默認權重未觸發“High”閾值;即使內部模擬“最強對手”做對抗微調,也仍未越線,因此允許 Apache 2.0 開源。即便如此,文檔反復強調:權重一旦放出,下游必須自行疊加系統級護欄;Harmony 格式的完整 CoT 可能含幻覺或不當內容,不可直接暴露給終端用戶。
簡言之,這份 Model Card 既是一份技術成績單,也是一份風險告知書:OpenAI 展示了如何在開源與可控之間劃出一條可驗證的安全邊界,并邀請社區在此基礎上繼續加固與擴展。



)



)






和當前最高分辨率的LED顯示器對比)


 的三種方式深度解析:差異、風險與最佳實踐)

