Pytorch實現嬰兒哭聲檢測和識別
目錄
Pytorch實現嬰兒哭聲檢測識別
1. 項目說明
2. 數據說明
(1)嬰兒哭聲語音數據集
(2)自定義數據集
3. 模型訓練
(1)項目安裝
(2)準備Train和Test數據
(3)配置文件:?config.yaml?
(4)開始訓練
(5)可視化訓練過程
(6)一些優化建議
(7)一些運行錯誤處理方法
4. 模型測試效果
5. 項目源碼下載
1. 項目說明
嬰兒哭聲是其表達需求、不適或潛在健康問題的重要信號。在寶寶健康監護中,通過智能化的哭聲識別與分析技術,不僅可以提升育兒效率,還能為早期疾病篩查和健康預警提供關鍵依據。現代AI哭聲識別系統能夠精準檢測到寶寶的哭聲,準確率可達98%以上。即使父母外出時,也可通過手機APP接收實時警報,系統會自動分析哭聲特征并推送具體建議。更智能的系統還能聯動家庭攝像頭,讓家長遠程查看嬰兒狀態,或自動調節室內溫濕度、啟動搖籃等智能設備。這種全天候的智能監護,既減輕了育兒壓力,又能及時發現異常情況,為嬰幼兒健康保駕護航。

本項目基于深度學習Pytorch,開發一個嬰兒(寶寶、新生兒)哭聲檢測和識別的系統,可以精準檢測識別嬰兒哭聲;項目網絡模型支持CNN模型MobileNet和ResNet,也支持時延神經網絡TDNN、ECAPA-TDNN以及LSTM等常見的模型,用戶也可以自定義其他模型進行訓練和測試,語音特征支持MelSpectrogram(梅爾頻譜圖)、?Spectrogram(頻譜圖)、MFCC(Mel-Frequency Cepstral Coefficients,梅爾頻率倒譜系數)、Fbank(Filter Bank,濾波器組能量)等多種音頻特征。采用ECAPA-TDNN模型,在嬰兒哭聲語音數據集上,驗證集的準確率97.8295%,采用resnet18模型,準確率可以達到98.9147%。
關鍵詞:?嬰兒哭聲、嬰兒哭叫聲、寶寶哭叫聲、哭鬧聲、檢測識別、TDNN、MelSpectrogram梅爾頻譜
| 模型 | 準確率 |
| TDNN | 98.1395% |
| ECAPA-TDNN | 97.8295% |
| resnet18 | 98.9147% |
【尊重原創,轉載請注明出處】https://blog.csdn.net/guyuealian/article/details/149812361
2. 數據說明
(1)嬰兒哭聲語音數據集
項目數據主要來源于網上收集的嬰兒哭聲語音數據集,數據集名稱baby-cry,其中訓練集,正樣本數據(類別cry)共918個音頻樣本,主要通過手機或者監控錄制的寶寶哭叫聲,時長2秒~15秒不等,負樣本數據2202個音頻樣本(類別others),包含人說話聲,鳥叫聲、汽笛聲等非嬰兒哭叫聲。測試集共645個樣本,主要用于模型指標測試。
(2)自定義數據集
如果需要新增類別數據,或者需要自定數據集進行訓練,可以參考如下進行處理
- 收集Train和Test數據集:要求相同類別的數據,放在同一個文件夾下;且子目錄文件夾命名為類別名稱,如
- 如,
A、B、C、D四個類別,則數據文件結構如下
 ?
?
- 類別文件:一行一個列表:?class_name.txt?
(最后一行,請多回車一行)
A
B
C
D- 修改配置文件的數據路徑:?config.yaml?
train_data: # 可添加多個數據集- 'data/dataset/train1' - 'data/dataset/train2'
test_data: 'data/dataset/test'
class_name: 'data/dataset/class_name.txt'
...
...3. 模型訓練
(1)項目安裝
整套工程基本框架結構如下:
.
├── classifier? ? ? ? ? # 訓練模型核心代碼
├── configs? ? ? ? ? ? ? # 訓練配置文件
├── data? ? ? ? ? ? ? ? # 項目相關數據
├── libs? ? ? ? ? ? # 項目依賴的相關庫
├── demo.py? ? ? ? ? ? ? # 模型推理demo
├── README.md? ? ? ? ? ? # 項目工程說明文檔
├── requirements.txt? ? # 項目相關依賴包
└── train.py? ? ? ? ? ? ?# 訓練文件???項目依賴python包請參考requirements.txt,使用pip安裝即可:
# python3.10
albumentations==1.4.13
Cython==3.0.11
easydict==1.13
ffmpy==0.4.0
Flask==3.0.3
flask-babel==4.0.0
flatbuffers==24.3.25
imageio==2.34.2
insightface==0.7.3
ipython==8.29.0
kaldi-native-fbank==1.20.1
librosa==0.10.2.post1
loguru==0.7.2
matplotlib==3.9.1.post1
matplotlib-inline==0.1.7
numba==0.60.0
numpy==1.26.4
onnx==1.16.2
opencv-contrib-python==4.8.1.78
opencv-python==4.8.0.76
opencv-python-headless==4.10.0.84
pandas==2.2.3
pillow==10.4.0
playsound==1.3.0
PyAudio==0.2.14
pybaseutils
pycparser==2.22
pycryptodome==3.21.0
pydantic==2.8.2
pydantic_core==2.20.1
pydub==0.25.1
Pygments==2.18.0
pypandoc==1.14
pyparsing==3.1.2
PyQt5==5.13.2
PyQt5_sip==12.15.0
PySocks==1.7.1
python-dateutil==2.9.0.post0
pytz==2024.2
PyYAML==6.0.2
scikit-image==0.24.0
scikit-learn==1.5.1
scipy==1.14.0
soundfile==0.12.1
tensorboard==2.17.0
tensorboardX==2.6.2.2
toolz==0.12.1
torchinfo==1.8.0
# torch==2.0.0+cu117
# torchaudio==2.0.1+cu117
# torchvision==0.15.1+cu117
tqdm==4.66.4
typing_extensions==4.12.2
urllib3==2.2.2
visualdl==2.5.3
xmltodict==0.13.0
yeaudio==0.0.6
?項目安裝教程請參考(初學者入門,麻煩先看完下面教程,配置好開發環境):
- 項目開發使用教程和常見問題和解決方法
- 視頻教程:1 手把手教你安裝CUDA和cuDNN(1)
- 視頻教程:2 手把手教你安裝CUDA和cuDNN(2)
- 視頻教程:3 如何用Anaconda創建pycharm環境
- 視頻教程:4 如何在pycharm中使用Anaconda創建的python環境
(2)準備Train和Test數據
項目自帶訓練數據和測試數據,語音數據增強方式主要采用:音量增強、噪聲增強等處理方式
修改配置文件數據路徑:?config.yaml?
data_type: "folder"
# 訓練數據集,可支持多個數據集(不要出現中文路徑)
train_data:- '/home/user/dataset/baby-cry/train'
# 測試數據集(不要出現中文路徑)
test_data:- '/home/user/dataset/baby-cry/test'
# 類別文件
class_name: 'data/class_name.txt'
# 數據增強
augment_config: "configs/augmentation.yml"(3)配置文件:?config.yaml?
- 模型支持TDNN、EcapaTdnn、CAMPPlus以及mobilenet_v2、resnet18等模型
等模型,用戶也可以自定義模型,進行模型訓練和測試。- 語音特征:支持MelSpectrogram(梅爾頻譜圖)、?Spectrogram(頻譜圖)、MFCC(Mel-Frequency Cepstral Coefficients,梅爾頻率倒譜系數)、Fbank(Filter Bank,濾波器組能量)等多種音頻特征
- 訓練參數可以通過(configs/config.yaml)配置文件進行設置
- 損失函數支持交叉熵CrossEntropy,LabelSmooth以及FocalLoss等損失函數
?配置文件:?config.yaml?說明如下:
data_type: "folder"
# 訓練數據集,可支持多個數據集(不要出現中文路徑)
train_data:- '/home/user/dataset/baby-cry/train'
# 測試數據集(不要出現中文路徑)
test_data:- '/home/user/dataset/baby-cry/test'
# 類別文件
class_name: 'data/class_name.txt'
# 數據增強
augment_config: "configs/augmentation.yml"flag: ""
work_dir: "work_space" # 保存輸出模型的目錄
feature_method: "Fbank" # 語音特征:MelSpectrogram、Spectrogram、MFCC、Fbank
net_type: "TDNN" # 骨干網絡,支持:TDNN、EcapaTdnn、CAMPPlus、LSTM
width_mult: 1.0 # 模型寬度因子
input_size: [ 256,128 ] # (Depth,Time,FeatureSize) or (seq_size, dim_size) or (Time,n_mfcc)
batch_size: 64 # batch_size
lr: 0.01 # 初始學習率
optim_type: "Adam" # 選擇優化器,SGD,Adam
loss_type: "CrossEntropyLoss" # 選擇損失函數:支持CrossEntropyLoss,LabelSmooth
momentum: 0.9 # SGD momentum
num_epochs: 120 # 訓練循環次數
num_warn_up: 8 # warn-up次數
num_workers: 8 # 加載數據工作進程數
weight_decay: 0.0005 # weight_decay,默認5e-4
scheduler: "cosine" # 學習率調整策略
milestones: [ 60,100 ] # 下調學習率方式
gpu_id: [ 0 ] # GPU ID
log_freq: 50 # LOG打印頻率
progress: True # 是否顯示進度條
pretrained: True # 是否使用pretrained模型
finetune: False # 是否進行finetune(4)開始訓練
整套訓練代碼非常簡單操作,用戶只需要將相同類別的數據放在同一個目錄下,并填寫好對應的數據路徑,即可開始訓練了。
python train.py -c configs/config.yaml
訓練完成后,在嬰兒哭聲語音數據集baby-cry上,采用TDNN模型,驗證集的準確率98.1395%,采用resnet18模型,準確率可以達到98.9147%。下表給出TDNN,ECAPA-TDNN和resnet18等常用模型驗證集的準確率:
| 模型 | 準確率 |
| TDNN | 98.1395% |
| ECAPA-TDNN | 97.8295% |
| resnet18 | 98.9147% |
(5)可視化訓練過程
訓練過程可視化工具是使用Tensorboard,使用方法,可參考這里:項目開發使用教程和常見問題和解決方法(cuda cudnn安裝教程)
Tensorboard使用方法,需要在終端輸入:
# 基本方法
tensorboard --logdir=path/to/log/
# 例如
tensorboard --logdir=work_space/EcapaTdnn_Fbank_CrossEntropyLoss_20250730_193758_0316/log可視化效果?
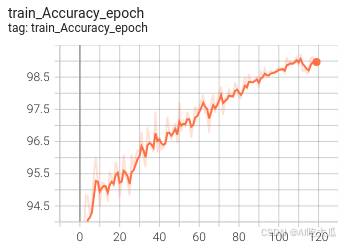
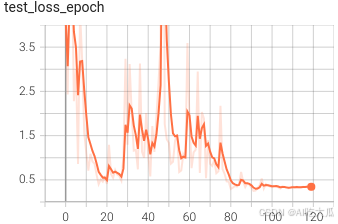
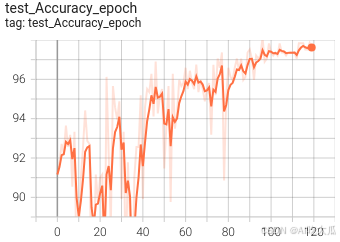
(6)一些優化建議
如果想進一步提高準確率,可以嘗試:
- 樣本均衡: 建議進行樣本均衡處理,避免長尾問題
- 調超參: 比如學習率調整策略,優化器(SGD,Adam等)
- 音頻特征:目前支持MelSpectrogram、Spectrogram、MFCC、Fbank等多種語音特征,可以嘗試不同的語音特征組合。
- 損失函數: 目前訓練代碼已經支持:交叉熵CrossEntropy,LabelSmoothing,可以嘗試FocalLoss等損失函數
(7)一些運行錯誤處理方法
-
項目不要出現含有中文字符的目錄文件或路徑,否則可能會出現很多異常!!!!!!!!
-
一些常見的錯誤和解決方法,請參考這里:項目開發使用教程和常見問題和解決方法
4. 模型測試效果
?demo.py文件用于推理和測試模型的效果,填寫好配置文件,模型文件以及測試數據即可運行測試了
#!/usr/bin/env bash
# Usage:
# python demo.py -c "path/to/config.yaml" -m "path/to/model.pth" --audio_dir "path/to/data_dir"python demo.py --config_file work_space/TDNN_Fbank_CrossEntropyLoss_20250730_171739_7128/config.yaml --model_file work_space/TDNN_Fbank_CrossEntropyLoss_20250730_171739_7128/model/best_model_096_98.1395.pth --audio_dir data/test_audio
運行測試結果:?
| 頻譜圖 | 預測結果 |
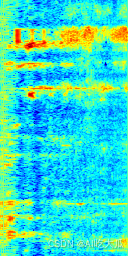 | file:data/test_audio/baby-cry01.wav name:['cry'],label:[0],score:[0.9999933242797852]
|
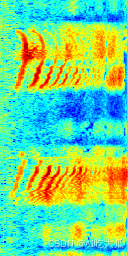 | file:data/test_audio/baby-cry02.wav name:['cry'],label:[0],score:[0.999161958694458] ? |
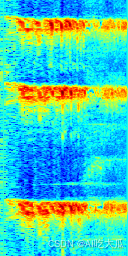 | file:data/test_audio/other02.wav name:['others'],label:[1],score:[0.9999972581863403] ? |
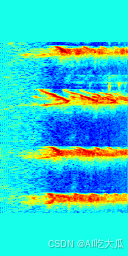 | file:data/test_audio/other03.wav name:['others'],label:[1],score:[0.9989004135131836] ? |
5. 項目源碼下載
整套項目源碼內容包含:
【源碼下載】請關注【AI吃大瓜】,回復關鍵字【嬰兒哭聲】
- 項目提供嬰兒哭聲語音數據集(baby-cry): 其中訓練集3120個語音樣本,測試集645個樣本
- 項目提供網絡模型支持CNN模型MobileNet和ResNet,也支持時延神經網絡TDNN、ECAPA-TDNN以及LSTM等常見的模型,用戶也可以自定義其他模型進行訓練和測試,
- 項目提供多種語音特征,支持MelSpectrogram、Spectrogram、MFCC、Fbank等多種音頻特征提取。
- 項目提供訓練代碼,損失函數支持交叉熵CrossEntropy,LabelSmoothing以及FocalLoss等損失函數,提供Log可視化等效果。
- 項目提供測試代碼,運行demo.py,可以直接測試音頻文件識別效果
- 項目提供已經訓練好的模型,無需重新訓練,配置好Pytorch環境,可運行demo.py測試效果



雙向鏈表)






京東云 JoyAgent介紹)

--windows篇詳解)






的范式躍遷與增長再想象)