代碼來源
https://github.com/ZhengPeng7/BiRefNet
模塊作用
DIS 是一種旨在對高分辨率圖像中的目標物體進行精確分割的技術,尤其適用于具有復雜細微結構的物體,例如細長的邊緣或微小細節。傳統方法在處理這類任務時往往難以捕捉細微特征或恢復高分辨率細節,因此論文提出了一種新穎的網絡架構BiRefNet以解決這些挑戰。
模塊結構
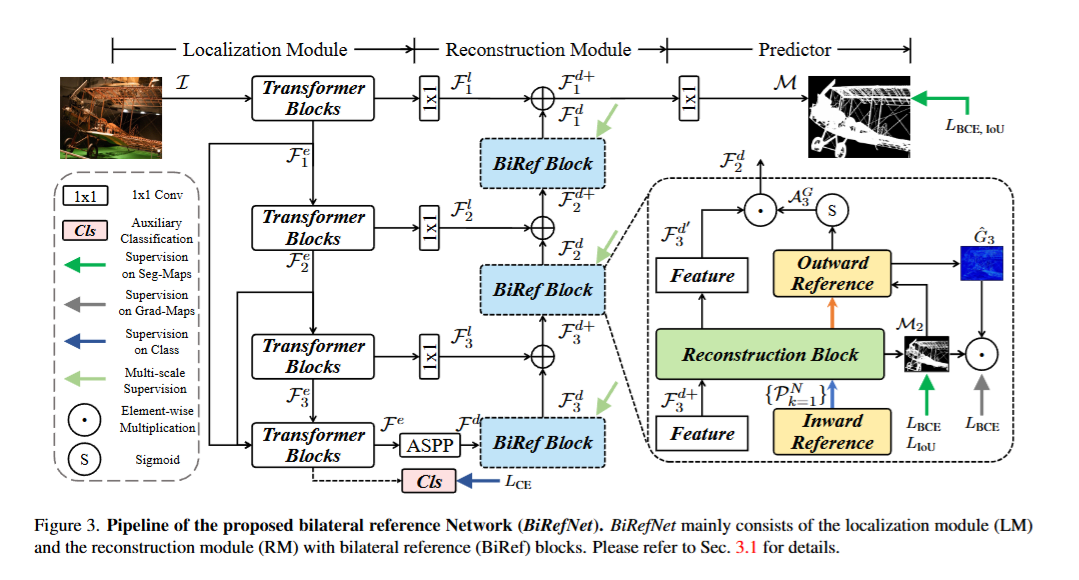
定位模塊(LM)
- 輸入高分辨率圖像至視覺變換器骨干網絡。
- 提取多尺度的層次特征,捕捉全局語義信息。
- 通過特征融合和壓縮,生成低分辨率的粗略預測圖。
- 原理:利用變換器的全局建模能力,在低分辨率下快速定位目標物體,避免直接處理高分辨率帶來的計算負擔。
重建模塊(RM)
- 接收定位模塊輸出的低分辨率粗略預測圖。
- 在解碼器的多個階段,逐步上采樣并結合雙邊參考信息。
- 輸出高分辨率的精細分割圖。
- 原理:通過將原始圖像的分塊輸入解碼器,提供高分辨率的細節參考,確保重建過程中細節不丟失。通過梯度圖的監督,引導模型聚焦于邊緣和細微結構,避免模糊或遺漏關鍵區域。從低分辨率到高分辨率的分階段上采樣,確保全局一致性和局部精確性的平衡。
代碼
class BiRefNet(nn.Module,PyTorchModelHubMixin,library_name="birefnet",repo_url="https://github.com/ZhengPeng7/BiRefNet",tags=['Image Segmentation', 'Background Removal', 'Mask Generation', 'Dichotomous Image Segmentation', 'Camouflaged Object Detection', 'Salient Object Detection']
):def __init__(self, bb_pretrained=True):super(BiRefNet, self).__init__()self.config = Config()self.epoch = 1self.bb = build_backbone(self.config.bb, pretrained=bb_pretrained)channels = self.config.lateral_channels_in_collectionif self.config.auxiliary_classification:self.avgpool = nn.AdaptiveAvgPool2d((1, 1))self.cls_head = nn.Sequential(nn.Linear(channels[0], len(class_labels_TR_sorted)))if self.config.squeeze_block:self.squeeze_module = nn.Sequential(*[eval(self.config.squeeze_block.split('_x')[0])(channels[0]+sum(self.config.cxt), channels[0])for _ in range(eval(self.config.squeeze_block.split('_x')[1]))])self.decoder = Decoder(channels)if self.config.ender:self.dec_end = nn.Sequential(nn.Conv2d(1, 16, 3, 1, 1),nn.Conv2d(16, 1, 3, 1, 1),nn.ReLU(inplace=True),)# refine patch-level segmentationif self.config.refine:if self.config.refine == 'itself':self.stem_layer = StemLayer(in_channels=3+1, inter_channels=48, out_channels=3, norm_layer='BN' if self.config.batch_size > 1 else 'LN')else:self.refiner = eval('{}({})'.format(self.config.refine, 'in_channels=3+1'))if self.config.freeze_bb:# Freeze the backbone...print(self.named_parameters())for key, value in self.named_parameters():if 'bb.' in key and 'refiner.' not in key:value.requires_grad = Falsedef forward_enc(self, x):if self.config.bb in ['vgg16', 'vgg16bn', 'resnet50']:x1 = self.bb.conv1(x); x2 = self.bb.conv2(x1); x3 = self.bb.conv3(x2); x4 = self.bb.conv4(x3)else:x1, x2, x3, x4 = self.bb(x)if self.config.mul_scl_ipt:B, C, H, W = x.shapex_pyramid = F.interpolate(x, size=(H//2, W//2), mode='bilinear', align_corners=True)if self.config.mul_scl_ipt == 'cat':if self.config.bb in ['vgg16', 'vgg16bn', 'resnet50']:x1_ = self.bb.conv1(x_pyramid); x2_ = self.bb.conv2(x1_); x3_ = self.bb.conv3(x2_); x4_ = self.bb.conv4(x3_)else:x1_, x2_, x3_, x4_ = self.bb(x_pyramid)x1 = torch.cat([x1, F.interpolate(x1_, size=x1.shape[2:], mode='bilinear', align_corners=True)], dim=1)x2 = torch.cat([x2, F.interpolate(x2_, size=x2.shape[2:], mode='bilinear', align_corners=True)], dim=1)x3 = torch.cat([x3, F.interpolate(x3_, size=x3.shape[2:], mode='bilinear', align_corners=True)], dim=1)x4 = torch.cat([x4, F.interpolate(x4_, size=x4.shape[2:], mode='bilinear', align_corners=True)], dim=1)elif self.config.mul_scl_ipt == 'add':x1_, x2_, x3_, x4_ = self.bb(x_pyramid)x1 = x1 + F.interpolate(x1_, size=x1.shape[2:], mode='bilinear', align_corners=True)x2 = x2 + F.interpolate(x2_, size=x2.shape[2:], mode='bilinear', align_corners=True)x3 = x3 + F.interpolate(x3_, size=x3.shape[2:], mode='bilinear', align_corners=True)x4 = x4 + F.interpolate(x4_, size=x4.shape[2:], mode='bilinear', align_corners=True)class_preds = self.cls_head(self.avgpool(x4).view(x4.shape[0], -1)) if self.training and self.config.auxiliary_classification else Noneif self.config.cxt:x4 = torch.cat((*[F.interpolate(x1, size=x4.shape[2:], mode='bilinear', align_corners=True),F.interpolate(x2, size=x4.shape[2:], mode='bilinear', align_corners=True),F.interpolate(x3, size=x4.shape[2:], mode='bilinear', align_corners=True),][-len(self.config.cxt):],x4),dim=1)return (x1, x2, x3, x4), class_predsdef forward_ori(self, x):########## Encoder ##########(x1, x2, x3, x4), class_preds = self.forward_enc(x)if self.config.squeeze_block:x4 = self.squeeze_module(x4)########## Decoder ##########features = [x, x1, x2, x3, x4]if self.training and self.config.out_ref:features.append(laplacian(torch.mean(x, dim=1).unsqueeze(1), kernel_size=5))scaled_preds = self.decoder(features)return scaled_preds, class_predsdef forward(self, x):scaled_preds, class_preds = self.forward_ori(x)class_preds_lst = [class_preds]return [scaled_preds, class_preds_lst] if self.training else scaled_preds總結
本文提出了一個配備雙邊參考的 BiRefNet 框架,該框架可在同一框架內執行二分圖像分割、高分辨率顯著目標檢測和隱藏目標檢測。通過全面的實驗,研究者發現未縮放的源圖像和對信息豐富區域的關注對于生成 HR 圖像中精細且細節豐富的區域至關重要。為此,研究者提出了雙邊參考來填充精細部分中缺失的信息(內向參考),并引導模型更加關注細節更豐富的區域(外向參考)。這顯著提升了模型捕捉微小像素特征的能力。為了降低 HR 數據訓練的高昂訓練成本,本文還提供了各種實用技巧,以實現更高質量的預測和更快的收斂速度。在 13 個基準測試中取得的優異結果證明了BiRefNet 的卓越性能和強大的泛化能力。




![[GESP202306 四級] 2023年6月GESP C++四級上機題超詳細題解,附帶講解視頻!](http://pic.xiahunao.cn/[GESP202306 四級] 2023年6月GESP C++四級上機題超詳細題解,附帶講解視頻!)














