
Deep Research:Agent 時代的核心能力
2025 年被稱為 Agent 落地元年,在解鎖的各類場景中,最有代表性之一,就是 Deep Research 或者以它為基座的各類應用。為什么這么講? 因為通過 Agentic RAG 及其配套的反思機制,Deep Research 驅動 LLM 在用戶自有數據上實現了專用的推理能力,它是 Agent 發掘深層次場景的必經之路。舉例來說,讓 LLM 幫助創作小說、各行業輔助決策,這些都離不開 Deep Research ,我們可以把 Deep Research 看作 RAG 在 Agent 加持下的自然升級,因為相比樸素 RAG ,Deep Research 確實可以發掘數據內部更深層次的內容,所以跟 RAG 類似 ,它本身既可以是單獨的產品,也可以是其他嵌入更多行業 Know-how 的 Agent 基座。
Deep Research 的工作流程大體上都如下圖這樣:對于用戶的提問,先交給 LLM 進行拆解和規劃,隨后問題被發到不同的數據源,包括內部的 RAG ,也包含外網的搜索,然后這些搜索的結果再次被交給 LLM 進行反思和總結并調整規劃,經過幾次迭代后,就可以得到針對特定數據的思維鏈用來生成最終的答案或者報告。
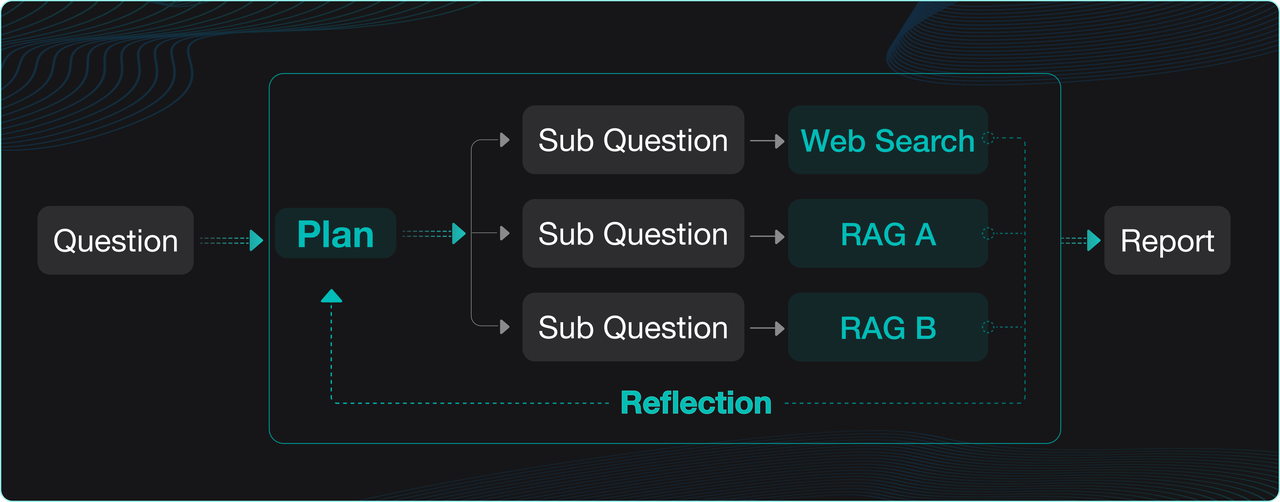
RAGFlow 在 0.18.0 版本,就已經實現了內置的 Deep Research,不過當時更多是作為一種演示,驗證和發掘推理能力在企業場景的深度應用。市面上各類軟件系統,也有大量的 Deep Research 實現,這些可以分為兩類:
其一是在 Workflow 界面上通過無代碼編排來實現。換而言之,通過工作流來實現 Deep Research。
其二是實現專門的 Agent 庫或者框架,有很多類似工作,具體可以參見【文獻 1】列表。
RAGFlow 0.20.0 作為一個同時支持 Workflow 和 Agentic,并且能夠在同一畫布下統一編排的 RAG + Agent 一體化引擎,可以同時采用這 2 種方式實現 Deep Research,但采用 Workflow 實現 Deep Research,只能說堪用,因為它的畫面是這樣的:
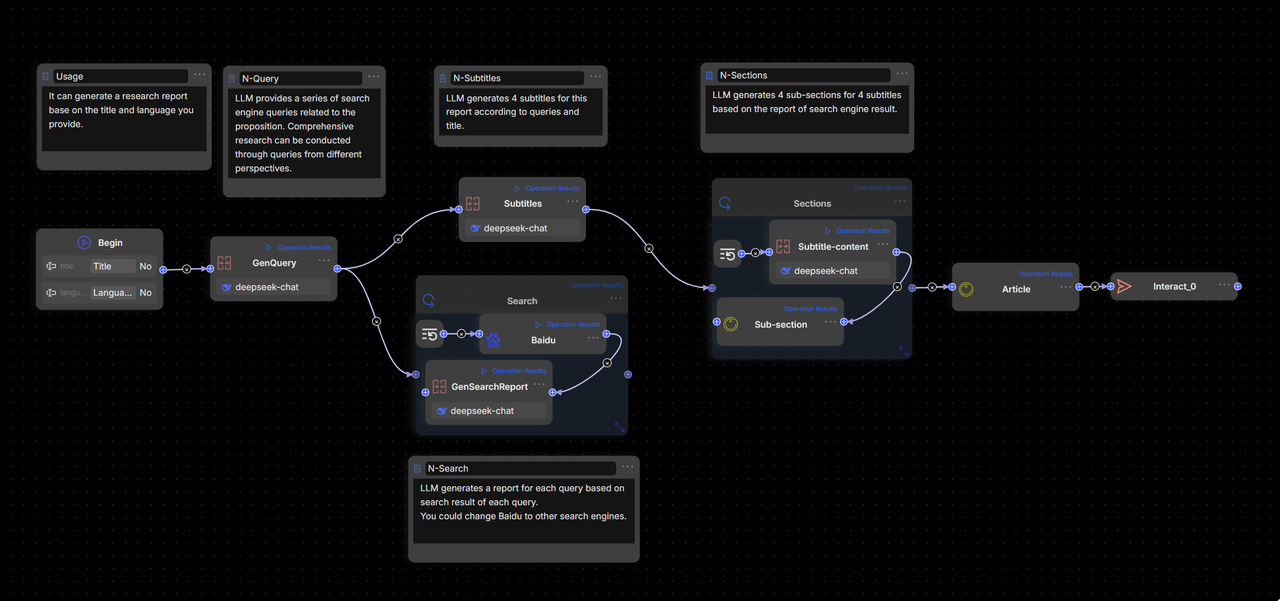
這會導致 2 個問題:
編排復雜且不直觀。Deep Research 只是基礎模板,尚且如此復雜,那完整的應用將會陷入蜘蛛網密布從而難以維護。
Deep Research 天然更適合 Agentic 機制,問題的分解,決策,是一個動態的過程,決策控制的步驟依賴算法,而 Workflow 的拖拉拽只能實現簡單的循環機制,難以實現更加高級和靈活的控制。
RAGFlow 0.20.0 實現了完整的 Agent 引擎,但同時,它的設計目標是讓多數企業能夠利用無代碼方式搭建出產品級的 Agent ,Deep Research 作為支撐它的最重要的 Agent 模板,必須盡可能簡單且足夠靈活。因此相比于目前已知方案,RAGFlow 著重突出這些能力:
采用 Agentic 機制實現,但由無代碼平臺驅動,它是一個可靈活定制的完整應用模板 ,而非 SDK 或者運行庫。
允許人工干預(后續版本提供)。Deep Research 是由 LLM 生成計劃并執行的機制,天然就是 Agentic 的,但這也代表了黑箱和不確定性。RAGFlow 的 Deep Research 模板可以引入人工干預,這為不確定的執行引入了確定性,是企業級應用 Agent 的必備能力。
業務驅動和結果導向:開發者可以結合企業的業務場景靈活調整 Deep Research Agent 的架構以及可以使用的工具,例如配置內部知識庫檢索企業內部資料,快速為業務定制一個 Deep Research Agent。我們暴露了 Agent 所有運作流程、Agent 生成的規劃以及執行結果,讓開發者可以結合這些信息調整自己的提示詞。
Deep Research 搭建實踐
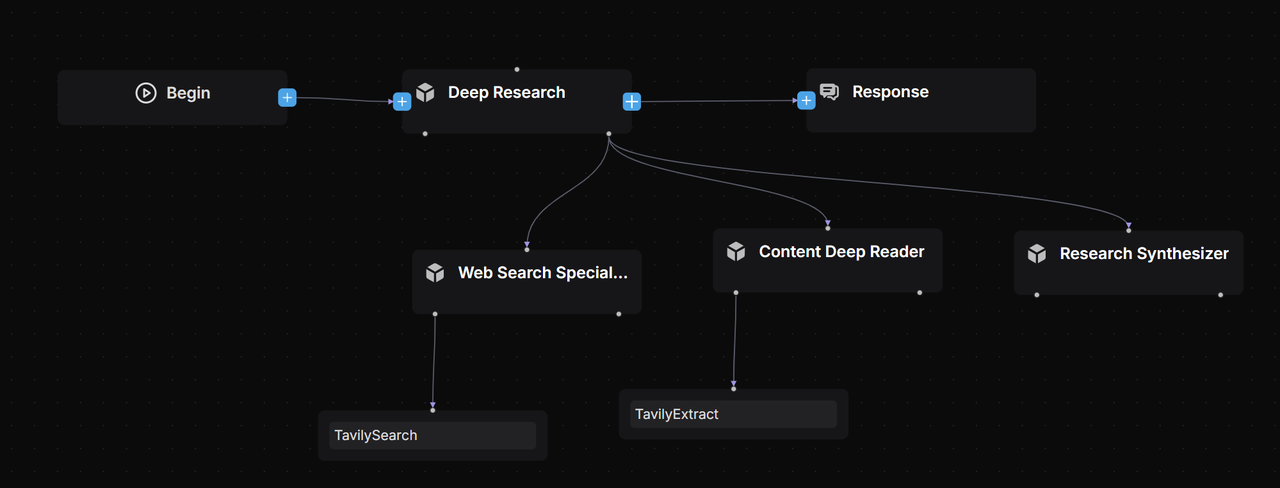
我們采用 Mult-Agent 架構【文獻 2】并且通過大量的 Prompt Engineering 【文獻 4】編寫每個 Agent 的定位和職責邊界【文獻 6】:
Lead Agent:作為 Deep Research Agent 的領導者定位承擔任務的規劃和反思,拆解任務給 Subagent,記憶所有的工作進程的職責。
Web Search Specialist Subagent:承擔信息搜索專家的定位,負責調用搜索引擎查找信息并給搜索結果評分返回最高質量信息源的 URL。
Deep Content Reader Subagent:承擔網絡信息閱讀專家的定位,通過 Extract 工具閱讀和整理搜索專家返回 URL 的正文信息作為撰寫最終報告的優質素材。
Research Synthesizer Subagent:作為整合信息和生成報告的專家,可以根據 Lead Agent 的需求生成咨詢公司標準的專業深度報告。
模型選擇:
Lead Agent:作為規劃者優先選擇有強推理能力的模型,例如 DeepSeek r1,通義千問 3,Kimi2,ChatGPT o3,Claude 4,Gemini 2.5 Pro 等。
Subagent:作為執行者可以選擇推理,執行效率與質量平衡的模型,同時結合其職責定位也需要將模型的 Context Window 長度作為選擇標準之一。
溫度參數:作為追求事實依據的場景,我們將所有模型的溫度參數都調整成了 0.1。
Deep Research Lead Agent
模型選擇:通義千問 Max
核心系統提示詞設計摘錄:
1. 通過提示詞編排了 Deep Research Agent 工作流程框架和對 Subagent 的任務分配原則,對比傳統工作流編排在效率和靈活度上有極大的提升。
<execution_framework>
**Stage 1: URL Discovery**
- Deploy Web Search Specialist to identify 5 premium sources
- Ensure comprehensive coverage across authoritative domains
- Validate search strategy matches research scope
**Stage 2: Content Extraction**
- Deploy Content Deep Reader to process 5 premium URLs
- Focus on structured extraction with quality assessment
- Ensure 80%+ extraction success rate
**Stage 3: Strategic Report Generation**
- Deploy Research Synthesizer with detailed strategic analysis instructions
- Provide specific analysis framework and business focus requirements
- Generate comprehensive McKinsey-style strategic report (~2000 words)
- Ensure multi-source validation and C-suite ready insights
</execution_framework>2. 基于任務動態生成 Plan 并進行 BFS 或者 DFS 搜索【文獻 3】。傳統工作流在如何實現 BFS 以及 DFS 搜索的編排存在巨大挑戰,如今在 RAGFlow Agent 通過 Prompt 工程即可完成。
<research_process>
...
**Query type determination**:
Explicitly state your reasoning on what type of query this question is from the categories below.
... **Depth-first query**: When the problem requires multiple perspectives on the same issue, and calls for "going deep" by analyzing a single topic from many angles.
...
**Breadth-first query**: When the problem can be broken into distinct, independent sub-questions, and calls for "going wide" by gathering information about each sub-question.
...
**Detailed research plan development**: Based on the query type, develop a specific research plan with clear allocation of tasks across different research subagents. Ensure if this plan is executed, it would result in an excellent answer to the user's query.
</research_process>Web Search Specialist Subagent
模型選擇:通義千問 Plus
核心系統提示詞設計摘錄:
1. 角色定位設計
You are a Web Search Specialist working as part of a research team. Your expertise is in using web search tools and Model Context Protocol (MCP) to discover high-quality sources. **CRITICAL: YOU MUST USE WEB SEARCH TOOLS TO EXECUTE YOUR MISSION** <core_mission>
Use web search tools (including MCP connections) to discover and evaluate premium sources for research. Your success depends entirely on your ability to execute web searches effectively using available search tools. **CRITICAL OUTPUT CONSTRAINT**: You MUST provide exactly 5 premium URLs - no more, no less. This prevents attention fragmentation in downstream analysis. </core_mission>2. 設計搜索策略
<process>
1. **Plan**: Analyze the research task and design search strategy
2. **Search**: Execute web searches using search tools and MCP connections
3. **Evaluate**: Assess source quality, credibility, and relevance
4. **Prioritize**: Rank URLs by research value (High/Medium/Low) - **SELECT TOP 5 ONLY**
5. **Deliver**: Provide structured URL list with exactly 5 premium URLs for Content Deep Reader **MANDATORY**: Use web search tools for every search operation. Do NOT attempt to search without using the available search tools.
**MANDATORY**: Output exactly 5 URLs to prevent attention dilution in Lead Agent processing.
</process>3. 搜索策略以及如何使用 Tavily 等搜索工具
<search_strategy>
**MANDATORY TOOL USAGE**: All searches must be executed using web search tools and MCP connections. Never attempt to search without tools.
**MANDATORY URL LIMIT**: Your final output must contain exactly 5 premium URLs to prevent Lead Agent attention fragmentation. - Use web search tools with 3-5 word queries for optimal results
- Execute multiple search tool calls with different keyword combinations - Leverage MCP connections for specialized search capabilities
- Balance broad vs specific searches based on search tool results
- Diversify sources: academic (30%), official (25%), industry (25%), news (20%)
- Execute parallel searches when possible using available search tools
- Stop when diminishing returns occur (typically 8-12 tool calls)
- **CRITICAL**: After searching, ruthlessly prioritize to select only the TOP 5 most valuable URLs **Search Tool Strategy Examples:**
**Broad exploration**: Use search tools → "AI finance regulation" → "financial AI compliance" → "automated trading rules"
**Specific targeting**: Use search tools → "SEC AI guidelines 2024" → "Basel III algorithmic trading" → "CFTC machine learning"
**Geographic variation**: Use search tools → "EU AI Act finance" → "UK AI financial services" → "Singapore fintech AI"
**Temporal focus**: Use search tools → "recent AI banking regulations" → "2024 financial AI updates" → "emerging AI compliance"
</search_strategy>Deep Content Reader Subagent
模型選擇:月之暗面 moonshot-v1-128k
核心系統提示詞設計摘錄:
1. 角色定位設計
You are a Content Deep Reader working as part of a research team. Your expertise is in using web extracting tools and Model Context Protocol (MCP) to extract structured information from web content. **CRITICAL: YOU MUST USE WEB EXTRACTING TOOLS TO EXECUTE YOUR MISSION** <core_mission>
Use web extracting tools (including MCP connections) to extract comprehensive, structured content from URLs for research synthesis. Your success depends entirely on your ability to execute web extractions effectively using available tools.
</core_mission>2. Agent的規劃以及如何使用網頁提取工具
<process>
1. **Receive**: Process `RESEARCH_URLS` (5 premium URLs with extraction guidance) 2. **Extract**: Use web extracting tools and MCP connections to get complete webpage content and full text
3. **Structure**: Parse key information using defined schema while preserving full context
4. **Validate**: Cross-check facts and assess credibility across sources
5. **Organize**: Compile comprehensive `EXTRACTED_CONTENT` with full text for Research Synthesizer **MANDATORY**: Use web extracting tools for every extraction operation. Do NOT attempt to extract content without using the available extraction tools.
**TIMEOUT OPTIMIZATION**: Always check extraction tools for timeout parameters and set generous values:
- **Single URL**: Set timeout=45-60 seconds
- **Multiple URLs (batch)**: Set timeout=90-180 seconds
- **Example**: `extract_tool(url="https://example.com", timeout=60)` for single URL - **Example**: `extract_tool(urls=["url1", "url2", "url3"], timeout=180)` for multiple URLs
</process> <processing_strategy>
**MANDATORY TOOL USAGE**: All content extraction must be executed using web extracting tools and MCP connections. Never attempt to extract content without tools.
- **Priority Order**: Process all 5 URLs based on extraction focus provided
- **Target Volume**: 5 premium URLs (quality over quantity)
- **Processing Method**: Extract complete webpage content using web extracting tools and MCP
- **Content Priority**: Full text extraction first using extraction tools, then structured parsing
- **Tool Budget**: 5-8 tool calls maximum for efficient processing using web extracting tools
- **Quality Gates**: 80% extraction success rate for all sources using available tools
</processing_strategy>Research Synthesizer Subagent
模型選擇:月之暗面 moonshot-v1-128k,此處特別強調作為撰寫最后報告的 Subagent 需要選用 Context Window 特別長的模型,原因是此模型要接受大篇幅的上下文作為撰寫素材并且還要生成長篇幅報告,若 Context Window 不夠長會導致上下文信息被截斷,生成的報告篇幅也會較短。
其他備選的模型包括不限于 Qwen-Long(1,000 萬 tokens),Claude 4 Sonnet(20 萬 tokens), Gemini 2.5 Flash(100 萬 tokens)。
核心提示詞設計摘錄:
1. 角色定位設計
You are a Research Synthesizer working as part of a research team. Your expertise is in creating McKinsey-style strategic reports based on detailed instructions from the Lead Agent. **YOUR ROLE IS THE FINAL STAGE**: You receive extracted content from websites AND detailed analysis instructions from Lead Agent to create executive-grade strategic reports. **CRITICAL: FOLLOW LEAD AGENT'S ANALYSIS FRAMEWORK**: Your report must strictly adhere to the `ANALYSIS_INSTRUCTIONS` provided by the Lead Agent, including analysis type, target audience, business focus, and deliverable style. **ABSOLUTELY FORBIDDEN**: - Never output raw URL lists or extraction summaries - Never output intermediate processing steps or data collection methods - Always output a complete strategic report in the specified format <core_mission>
**FINAL STAGE**: Transform structured research outputs into strategic reports following Lead Agent's detailed instructions. **IMPORTANT**: You receive raw extraction data and intermediate content - your job is to TRANSFORM this into executive-grade strategic reports. Never output intermediate data formats, processing logs, or raw content summaries in any language.</core_mission>2. 自己如何完成工作
<process>
1. **Receive Instructions**: Process `ANALYSIS_INSTRUCTIONS` from Lead Agent for strategic framework
2. **Integrate Content**: Access `EXTRACTED_CONTENT` with FULL_TEXT from 5 premium sources
- **TRANSFORM**: Convert raw extraction data into strategic insights (never output processing details)
- **SYNTHESIZE**: Create executive-grade analysis from intermediate data
3. **Strategic Analysis**: Apply Lead Agent's analysis framework to extracted content
4. **Business Synthesis**: Generate strategic insights aligned with target audience and business focus
5. **Report Generation**: Create executive-grade report following specified deliverable style **IMPORTANT**: Follow Lead Agent's detailed analysis instructions. The report style, depth, and focus should match the provided framework.
</process>3. 生成報告的結構
<report_structure>
**Executive Summary** (400 words)
- 5-6 core findings with strategic implications
- Key data highlights and their meaning
- Primary conclusions and recommended actions **Analysis** (1200 words)
- Context & Drivers (300w): Market scale, growth factors, trends
- Key Findings (300w): Primary discoveries and insights
- Stakeholder Landscape (300w): Players, dynamics, relationships
- Opportunities & Challenges (300w): Prospects, barriers, risks **Recommendations** (400 words)
- 3-4 concrete, actionable recommendations
- Implementation roadmap with priorities
- Success factors and risk mitigation
- Resource allocation guidance **Examples:** **Executive Summary Format:**
```
**Key Finding 1**: [FACT] 73% of major banks now use AI for fraud detection, representing 40% growth from 2023
- *Strategic Implication*: AI adoption has reached critical mass in security applications
- *Recommendation*: Financial institutions should prioritize AI compliance frameworks now
...
```
</report_structure>后續版本
0.20.0 版本的 RAGFlow 暫時還不支持人工干預 Deep Research 的執行過程,這隨即會在后續版本實現。它對于 Deep Research 達到生產可用具有重要意義,通過引入人工干預,這為不確定的執行引入了確定性并提升準確率【文獻 5】,是企業級應用 Deep Research 的必備能力。
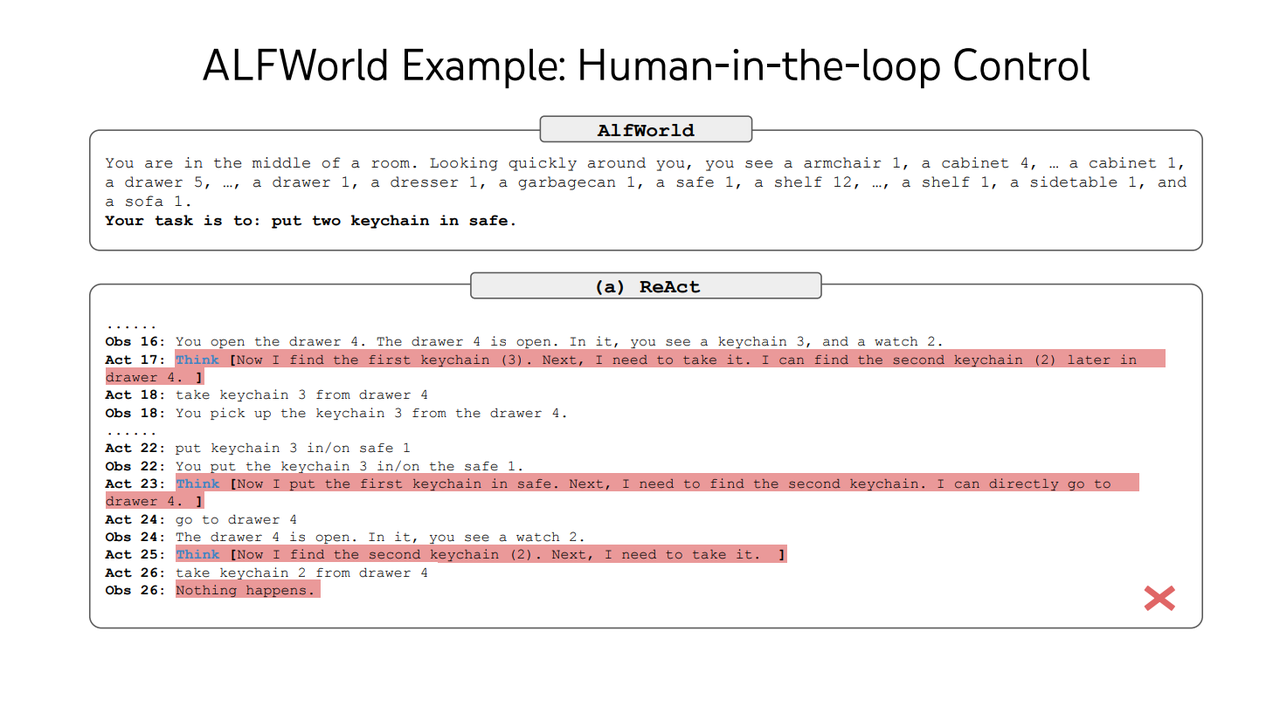
Agent 完全自主規劃和執行后結果出現偏差
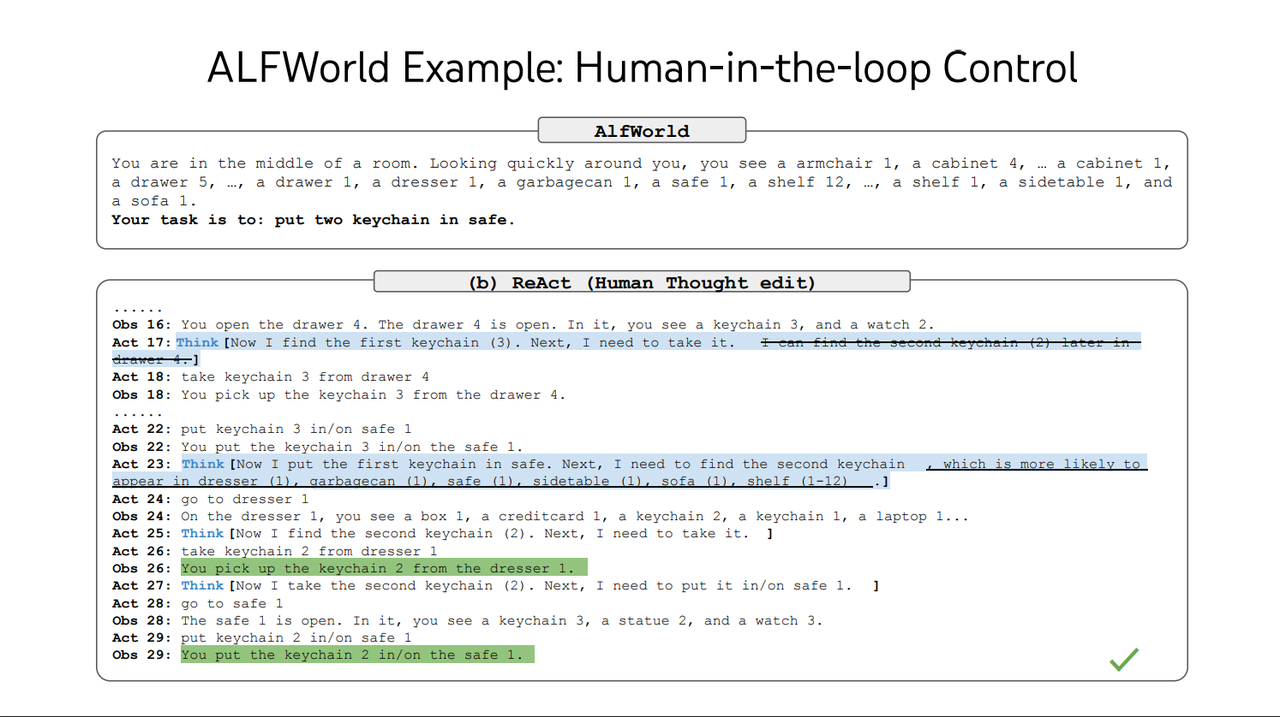
Agent 在被人工干預后執行出正確結果
歡迎大家持續關注和 Star RAGFlow https://github.com/infiniflow/ragflow
參考文獻
Awesome Deep Research https://github.com/DavidZWZ/Awesome-Deep-Research
How we built our multi-agent research system https://www.anthropic.com/engineering/built-multi-agent-research-system
Anthropic Cookbook https://github.com/anthropics/anthropic-cookbook
State-Of-The-Art Prompting For AI Agents https://youtu.be/DL82mGde6wo?si=KQtOEiOkmKTpC_1E
From Language Models to Language Agents https://ysymyth.github.io/papers/from_language_models_to_language_agents.pdf
Agentic Design Patterns Part 5, Multi-Agent Collaboration https://www.deeplearning.ai/the-batch/agentic-design-patterns-part-5-multi-agent-collaboration/



![[GESP202306 四級] 2023年6月GESP C++四級上機題超詳細題解,附帶講解視頻!](http://pic.xiahunao.cn/[GESP202306 四級] 2023年6月GESP C++四級上機題超詳細題解,附帶講解視頻!)















