導讀:
基于深度學習的推薦算法已成為推薦系統領域的研究趨勢。然而,大多數現有工作僅考慮單一的用戶與物品交互數據,限制了算法的預測性能。本文提出一種畫像約束的編碼方式,并融合隱因子模型中的潛在特征,豐富了推薦算法的輸入以提升評分預測的準確性。該算法利用矩陣分解得到潛在特征初始化用戶與物品的嵌入,然后通過線性注意力機制增強模型對畫像特征的敏感度,最后結合深度神經網絡進行評分預測。通過本文算法與其他基線算法在MovieLens與Netflix數據集上進行對比,該算法與基線算法相比顯著提高了評分預測的精度,并在推薦列表排序性能等方面表現出色。本文的研究揭示了加入用戶與物品的畫像約束和潛在特征,可以有效提升推薦系統的性能。
關注漢斯,獲取更多論文資訊,如您需要論文原文,歡迎私信獲取~
作者信息:
艾 均,?柏光耀,?蘇 湛,?馬菀言:上海理工大學光電信息與計算機工程學院,上海
正文
推薦算法的發展呈現出以下幾個主要趨勢:基于隱因子模型的推薦算法、基于用戶畫像的推薦算法、基于深度學習的推薦算法。
推薦系統發展至今仍面臨一些問題:1) 大多數推薦算法僅依賴用戶對物品的顯式反饋,如用戶–物品評分數據,往往忽視了用戶的興趣或隱式偏好,導致推薦效果難以達到最佳。2) 如何從復雜的用戶–物品交互數據中有效提取并利用用戶與物品的特征,是提升個性化推薦算法準確性的重要挑戰。3) 當遇到新用戶或新物品時,由于缺乏歷史數據,推薦系統難以提供準確的推薦,進而面臨冷啟動問題。針對如何利用用戶的興趣或隱式偏好以及如何從復雜的交互數據中提取并利用用戶和物品的特征,本文提出一種融合畫像約束和潛在特征的深度推薦算法(Deep Portrait Feature and Latent Embedding Algorithm, DPFLE)。
大多數基于深度學習的推薦算法僅依賴于用戶–物品評分數據,且普遍存在可解釋性不足的問題,本文提出的DPFLE使用矩陣分解初始化用戶和物品的嵌入向量,利用物品標簽信息構建細粒度的畫像向量,并通過線性注意力機制增強模型對畫像特征的敏感度,豐富算法輸入的同時還改善了算法的可解釋性。
算法設計
整體算法如圖1所示。首先對用戶–物品評分矩陣,使用矩陣分解技術,得到用戶和物品的潛在特征,利用預先計算的潛在特征來初始化用戶嵌入層以及物品嵌入層。隨后,利用物品的標簽信息并結合評分信息計算出用戶和物品的畫像向量,經過portrait_encoder層編碼得到用戶畫像約束以及物品畫像約束,對這個四個特征進行融合,之后利用深度神經網絡進行評分預測。
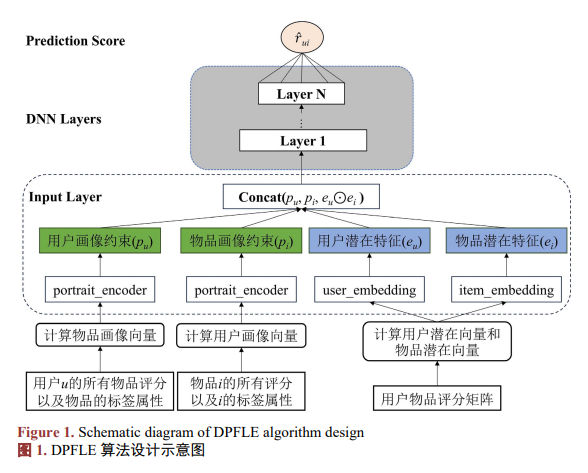
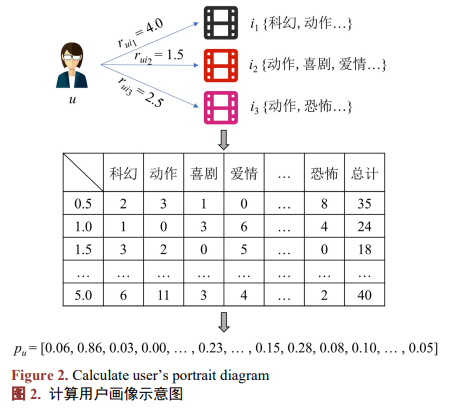
在電影推薦領域,電影標簽作為電影的抽象表示,蘊含了豐富的用戶隱式信息,合理利用電影標簽數據,可以有效提升推薦算法的性能,具有重要的應用價值。?通過統計用戶對不同標簽的物品在不同評分下的評分次數,并除以相同評分下的評分總次數最后進行拼接操作得到用戶的畫像向量。具體過程如圖2所示。
?實驗設計與分析
1. 數據集
本文使用經典數據集MovieLens以及Netflix來驗證提出的方法。MovieLens25M記錄了16萬位用戶對6萬部電影的2500萬余條評分數據,評分的范圍為0.5到5,間隔為5,電影的類型有動作片、恐怖片、喜劇片等等,一共有19種類型。Netflix記錄了48萬位用戶對1萬余部電影的10000萬余條評分數據,評分的范圍為1到5,間隔為1。本文分別從兩個數據集中隨機選取1500位用戶的所有數據進行實驗,以節省計算資源和時間。需要注意的是,由于Netflix數據集中不包含電影類型的信息,因此本文通過電影標題在MovieLens數據集中查找其相應的類型。本文將數據集按照90%,10%的比例將數據集劃分為訓練集和測試集,每個算法僅基于訓練集預測每個測試集中的所有評分,并進行折十驗證,最終結果取所有實驗的平均值。
2. 評價指標
本文使用平均絕對誤差(Mean Absolute Error, MAE)?、均方根誤差(Root Mean Square Error, RMSE)?來評估評分預測的誤差。MAE反映了算法預測評分與用戶實際評分之間的偏差,RMSE表示預測用戶評分與實際評分之間偏差的均方根值。使用歸一化折損累計增益(Normalized Discounted Cumulative Gain, NDCG)?來評估推薦列表的排序性能。
3. 基線算法
為了評估本文提出的DPFLE的性能,本文將其與其他基線算法進行了上述評價指標的比較。所有算法均取其論文中的最優指標。
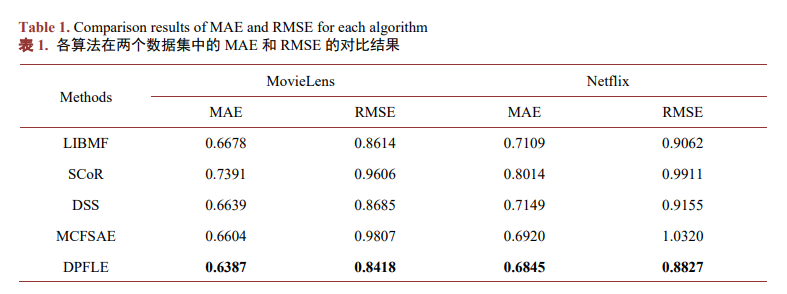
在MovieLens數據集和Netflix數據集中的MAE和RMSE結果對比如表1所示,其中表現最佳的值以黑體加粗標出,后續也用此形式表示最優值。DPFLE的MAE值和RMSE值在兩個數據集上相較于其他對比算法均達到了最優。
表2顯示了NDCG和Diversity在兩個數據集上的結果對比。?
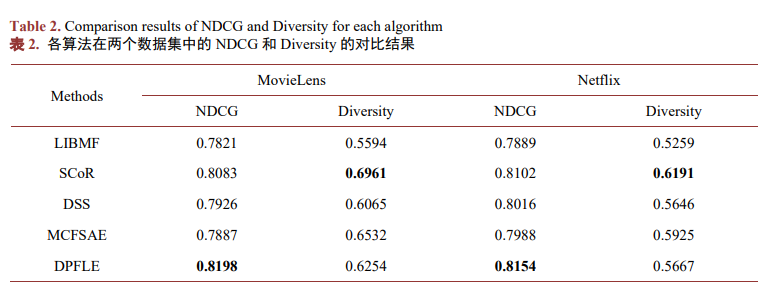
表3顯示了各個算法的Accuracy,Precision以及Recall在兩個數據集上的表現。?
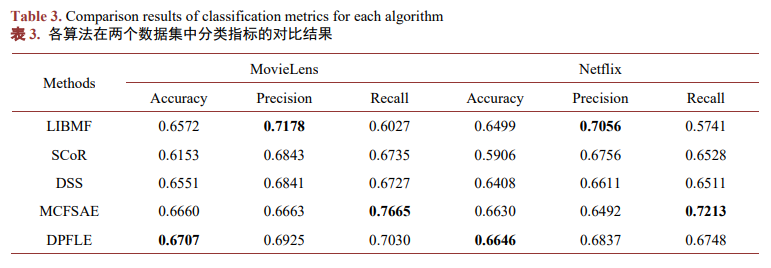
在MovieLens與Netflix數據集中,各算法的總體實驗結果表現如圖4,其中本文提出的DPFLE在MAE、RMSE、NDCG、Accuracy這四個指標上均取得了最好的效果。由上述實驗結果可知,將畫像約束與潛在特征相融合并利用深度學習進行評分預測,能夠有效降低推薦系統中的誤差,并且在推薦列表的排序性能方面也有顯著提升。然而,在推薦列表的多樣性方面,本文提出的DPFLE表現并不出色。由于將用戶與物品的畫像約束加入算法中,推薦結果往往集中于用戶已經喜歡的物品,而忽視了其他潛在的、有趣的選項。?
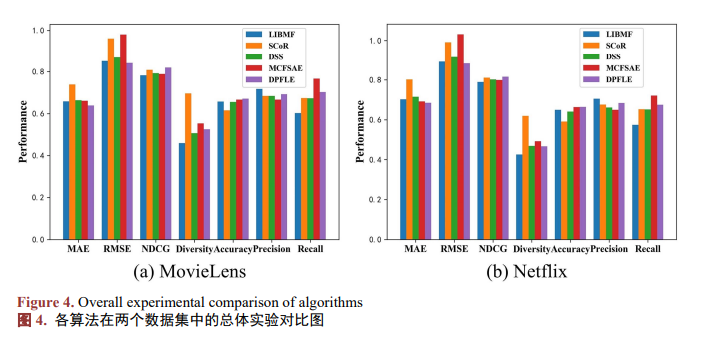
為了探究潛在特征的大小對實驗的影響,本文將k分別設置為50、100、200、300,并在兩個數據集上進行實驗。表4顯示了在不同的潛在特征大小下,DPFLE在兩個數據集中的MAE和RMSE的表現。當k大于300時,MAE和RMSE的實驗結果變化非常小,但是算法的執行時間會更長。為了節省計算資源和時間,本文沒有過多探究更大的k對實驗的影響。?
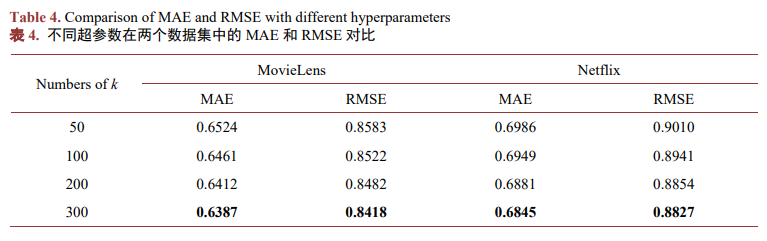
表5顯示了去掉AFTSimple注意力模塊后與原始算法的比較,其中DPFLE-AFT表示去除注意力模塊后的模型,經比較可以得出DPFLE在兩個數據集中的MAE平均降低了2.11%,RMSE平均降低了1.16%,說明通過線性注意力機制對畫像特征進行加權計算能夠更好地捕捉用戶和物品之間復雜的關系并提升模型的預測精度。?
總結與展望
本文在兩個真實世界的數據集中進行了驗證,實驗結果顯示,在預測精度與推薦列表的排序方面,本文所提出的方法相較于一些先進的算法有明顯的提升。
在未來的工作中,本文將考慮圖神經網絡替代傳統的多層感知機,利用用戶與物品之間的復雜關系構建交互圖,挖掘更深層次的特征關聯,以提高推薦系統的性能,為用戶提供更加個性化和精準的推薦服務。
基金項目:
國家自然科學基金項目(61803264)
原文鏈接:https://doi.org/10.12677/mos.2025.144298
?
路徑屬性)
)









 視頻教程 - 微博輿情數據可視化分析-熱詞情感趨勢樹形圖)

單鏈表專題2.單鏈表的應用)

)
)


