目錄
結構推導
回到最原始的問題 —— 我們如何存數據?
第二步:我們來看看數組的限制?
第三步:那我們該怎么做呢??
第四步:我們推導鏈表的數據結構?
結構講解
什么是鏈表?
什么是節點??
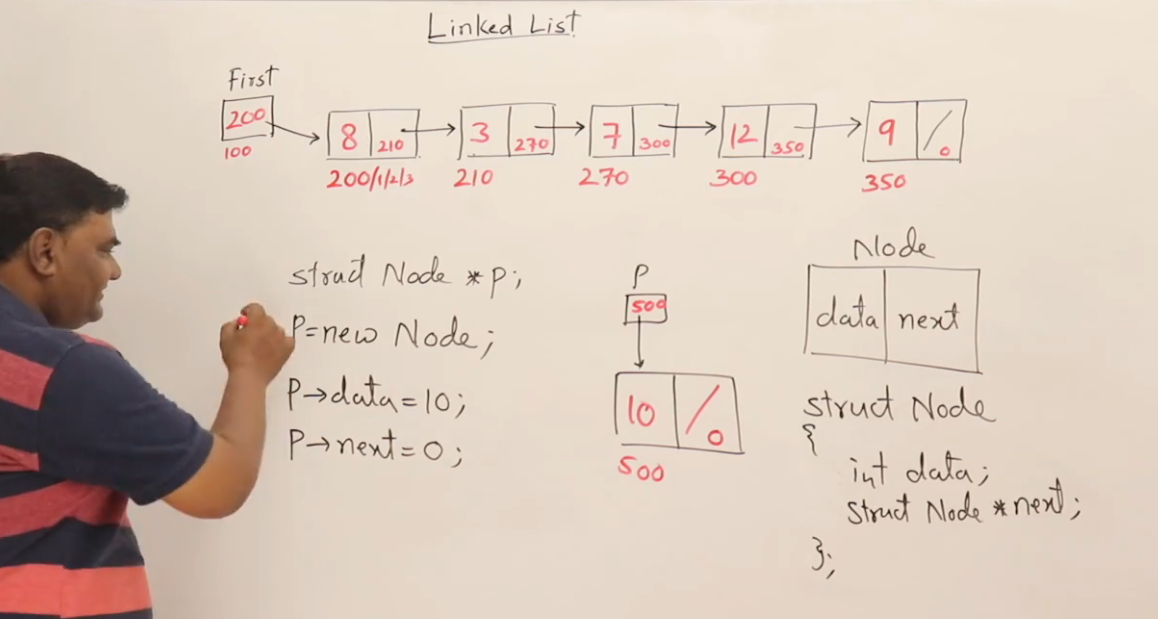
如何創建節點?
?如何訪問節點?
結構推導
🎯 目標:理解什么是鏈表(linked list),為什么我們需要它,以及它的結構從哪里來的。
回到最原始的問題 —— 我們如何存數據?
在 C 語言中,最基礎的存數據方式是:
int a[100];
也就是 數組(array)。它非常常見,我們從一開始就用。
那我們先從數組的“第一性”特征說起:
數組的本質是:
一塊連續的內存空間 + 索引訪問
舉個例子:
int a[5] = {10, 20, 30, 40, 50};
這個數組在內存里是這樣的(假設從地址 1000 開始):
| 地址 | 值 |
|---|---|
| 1000 | 10 |
| 1004 | 20 |
| 1008 | 30 |
| 1012 | 40 |
| 1016 | 50 |
它的特性:
-
地址連續
-
a[i] 的位置是:a + i × sizeof(int)
-
可以快速通過索引訪問:O(1)
詳細內容可以參考:數據結構:數組(Array)_array[1..50]-CSDN博客
第二步:我們來看看數組的限制?
情況1:大小固定
如果你定義了:
int a[100];
你就固定只能存最多 100 個元素。如果只用了前 5 個元素,空間也浪費。
如果你事先不知道需要多少個元素,就很難選大小。
情況2:插入麻煩
假設你已經有數組:
int a[5] = {10, 20, 30, 40, 50};
現在你想在 第 2 個位置插入 99,就得把后面的都搬一格:
for (int i = 5; i > 1; i--) {a[i] = a[i - 1];
}
a[1] = 99;
這會導致O(n) 的時間復雜度。
情況3:刪除也麻煩
類似的,如果你要刪掉 a[2],也得把后面的全往前搬一格。
總結數組的問題:
| 問題 | 描述 |
|---|---|
| 空間不靈活 | 空間必須一開始就定下來 |
| 插入慢 | 中間插入要整體移動元素 |
| 刪除慢 | 刪除某項也要移動后面的元素 |
| 空間浪費 | 有時只用一部分數組,但仍然占內存 |
第三步:那我們該怎么做呢??
我們思考一下:
能不能只在用到數據時,才開辟空間?
能不能插入一個元素,而不影響其它元素的位置?
這就引出了一個新的思維模型:
? 使用“分散空間 + 指針連接”的模型
如果我們不強求內存連續,而是:
-
每次添加一個節點時,就用
malloc單獨開一塊空間 -
每個節點都保存指向“下一個節點”的指針
我們就可以實現靈活的動態結構了。
這就是 鏈表(linked list) 的思想:
把所有的數據節點一個一個連起來,而不是排成連續數組
第四步:我們推導鏈表的數據結構?
我們要存一個元素,它需要什么?
-
數據本身,比如:一個整數
-
指向下一個節點的“線索”(指針)
所以我們設計一個節點結構:
struct Node {int data; // 當前節點的數據struct Node* next; // 指向下一個節點
};
那一個“鏈表”是什么?
一個鏈表是“若干個 Node 連起來”,只要有第一個節點(頭結點)的地址,就能找到整個鏈表。
所以我們定義:
struct Node* head; // 指向鏈表的起點
? 所以鏈表的基本單位是:節點 + 指針
[10 | *] --> [20 | *] --> [30 | NULL]
-
每個方塊是一個
Node -
*是next指針 -
最后一個節點的
next = NULL表示鏈表結束
結論:為什么我們需要鏈表?
| 問題 | 鏈表怎么解決 |
|---|---|
| 數組大小固定 | 鏈表可以動態增加節點(malloc) |
| 插入/刪除慢 | 鏈表插入刪除只需修改指針,不搬數據 |
| 空間浪費 | 用多少開多少,不多開 |
結構講解
什么是鏈表?
在數組中,所有元素都在一塊連續的內存空間中。你只能在一開始就分配好大小,插入/刪除不方便。那么:
有沒有一種數據結構,不要求數據連續存儲,但依然能一個接一個地串起來?
?這就是鏈表的本質:
鏈表是由若干個節點組成的線性結構,每個節點都知道下一個節點在哪里,只需要記住第一個節點就能訪問整個鏈表。
鏈表的核心思想是:
每個節點知道“誰在后面”,就像每一節車廂都知道后面那節車廂的位置。
整個鏈表就像是一列火車,每節車廂通過“掛鉤”(指針)串聯起來:
? 鏈表的特征:
-
節點之間不要求連續內存
-
每個節點都包含:
-
本節點的數據
-
指向下一個節點的指針
-
-
通過“指針”把節點連接起來
?通常我們用一個指針 head 來指向第一個節點:
struct Node* head;
什么是節點??
一個節點(Node)是鏈表的最基本組成單位,就是一個結構體,它包含:
-
一份數據(例如 int 類型)
-
一個指針,指向下一個節點
這就好比:
-
火車的每節車廂(節點)都有:
-
貨物(數據)
-
連接器(指針)去連下一節車廂
-
?用C語言表示:
struct Node {int data; // 節點中存的數據struct Node* next; // 指向下一個節點的指針
};
| 成員 | 含義 |
|---|---|
int data | 存儲數據,比如整數 10 |
Node* next | 保存下一個節點的地址,如果是最后一個就為 NULL |
如何創建節點?
為什么我們不能直接寫:
struct Node node1;
1. 這句代碼在 棧(stack)上 分配了一個 Node 類型的變量。它的特點是:
-
分配在棧上(函數調用結束后會被自動釋放)
-
內存大小在編譯時就已經確定
-
生命周期由作用域決定,作用域結束就失效
🔍 2. 鏈表是動態結構,不能預知節點個數
鏈表的本質是:
-
你不知道總共有多少個節點(比如根據用戶輸入構建)
-
每一個節點都需要“現用現開”,而不是提前一次性分配
所以我們需要在“運行時”動態分配空間:?
struct Node* newNode = (struct Node*) malloc(sizeof(struct Node));
這行代碼的含義是:
-
malloc(sizeof(struct Node))在堆(heap)上動態分配一塊內存,大小正好是一個 Node -
返回值是
void*,強制類型轉換成struct Node* -
newNode是一個指針,指向新建的節點
再從鏈表的設計需求來倒推
-
節點數是動態變化的(例如用戶輸入10個節點)
-
節點之間是用指針連接的
-
每個節點可能在任何時刻被插入或刪除
-
節點需要長期存在,甚至跨越函數作用域
?所以:必須用動態內存分配,也就是
malloc()。struct Node node1;是不能滿足上述需求的
?如何訪問節點?
假設我們已經創建了多個節點,并鏈接起來:
struct Node* head = (struct Node*) malloc(sizeof(struct Node));
head->data = 10;struct Node* second = (struct Node*) malloc(sizeof(struct Node));
second->data = 20;head->next = second;
second->next = NULL;
訪問鏈表節點的本質邏輯是沿著 next 指針走,這就叫做遍歷鏈表(traverse the linked list)。
舉個例子,假設你有一個鏈表,要訪問節點內容:
head → [10 | * ] → [20 | * ] → [30 | NULL]
你想訪問第二個節點的值 20:
你不能說 head[1],因為它不是數組。
你只能說:
head->next->data
這個表達式的意義是:
-
head是第一個節點的地址 -
head->next是第二個節點的地址 -
head->next->data就是第二個節點的值
訪問第二個節點的數據:?
printf("%d\n", head->next->data); // 輸出 20
遍歷就是:
從
head開始,沿著每個節點的next指針走,直到你走到 NULL(鏈表結尾)
struct Node* temp = head;
while (temp != NULL) {printf("%d ", temp->data);temp = temp->next;
}
printf("\n");
這段代碼會訪問每個節點的 data,直到遇到 NULL。?
![[RK3566-Android11] U盤頻繁快速插拔識別問題](http://pic.xiahunao.cn/[RK3566-Android11] U盤頻繁快速插拔識別問題)


)







--學習筆記15(分頁查詢PageHelper))


開源:AI智能體生態的技術革命)



)
)