需要你對MHA、MQA、GQA有足夠了解,相信本文能幫助你對MLA有新的認識。
本文內容都來自https://www.youtube.com/watch?v=0VLAoVGf_74,如果閱讀本文出現問題,建議直接去看一遍。
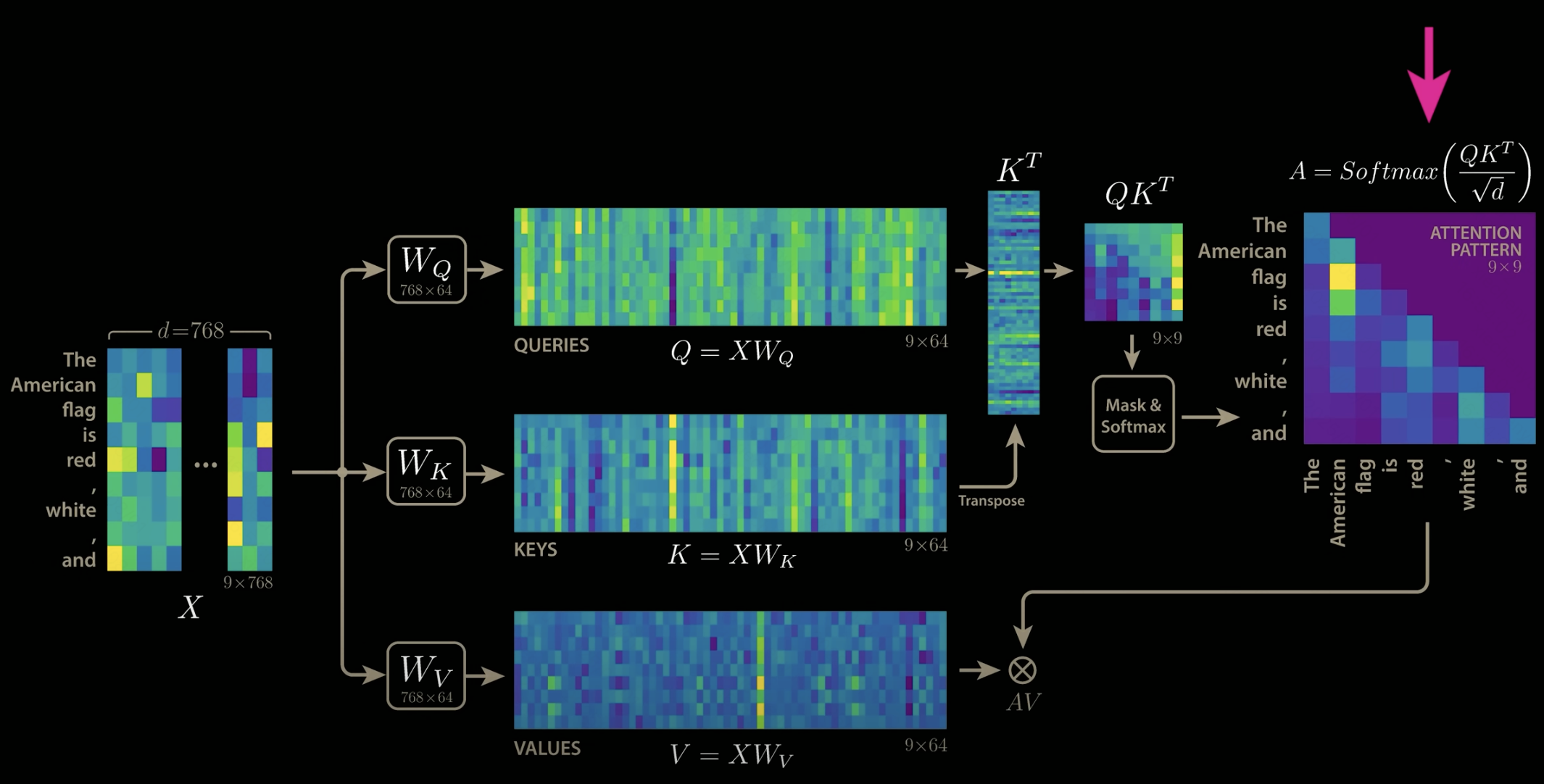
????????按照Deepseek設定一些參數值:輸入token長度n=10,注意力頭數目n_h=128,每個注意力頭的隱含層維度d_h=128,transformer block層數 l =61,使用fp16存儲參數。
????????先來看MHA的kv-cache計算:
(第一個2是因為要保存K和V,第二個2是因為fp16占2bit)
????????MQA和GQA的思路是通過不同注意力頭之間共享參數,減少注意力頭數目n_h來達到降低開銷的目的。
????????這樣的問題是參數的共享會導致模型效果下降,畢竟原本有128個頭,128份KV參數,每份KV參數都會計算出不一樣的注意力分布,讓模型能更好的根據所有的注意力分布去預測下一個詞,而現在128份參數變成了1份,預測效果下降是必然的。
????????如何解決這個問題?如何只保留1份參數,但又能計算出128個不同的注意力分布呢?
????????MLA給出的答案是,只保留原本128分參數中共有的部分,而每份參數獨有的部分則提取出來,不進行保存。
????????這里就碰到了MLA第一個比較難理解的點,就是怎么找出128個W_K的共有部分和獨有部分?(只以K為例,V也是一樣的)?
????????答案是不用去找,而是從一開始就用兩個矩陣,分別去學習共有部分和獨有部分。也就是下圖中的W_DKV和W_UK,其中W_DKV學習共有部分,W_UK學習獨有部分。也就是說128個注意力頭,會共用W_DKV,但是每個注意力頭的W_UK是獨有的,這樣保證了128個注意力頭能計算出128個不同的注意力分布。
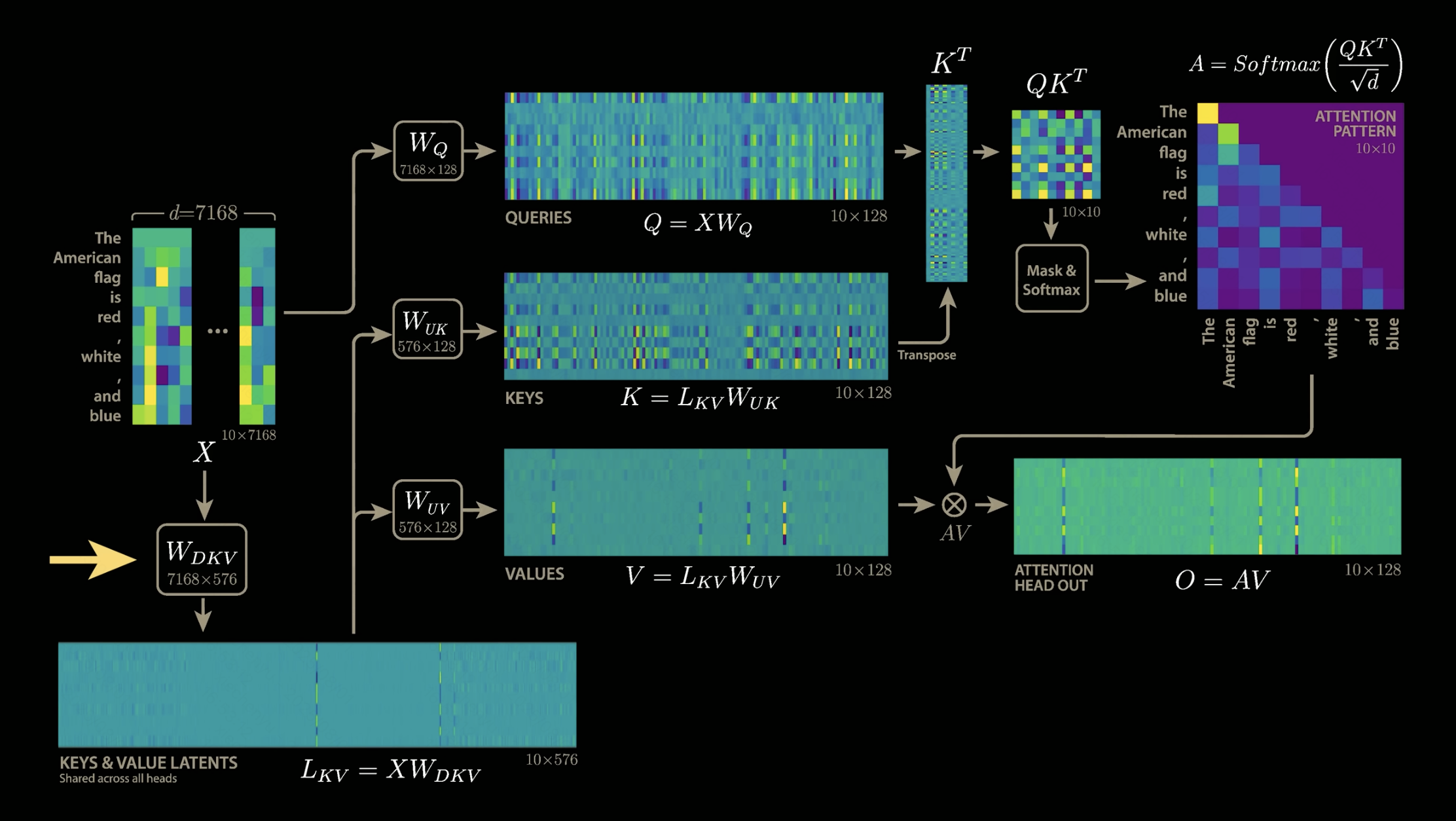
這里就會碰到MLA第二個比較難理解的點,為什么最后kv-cache只用保存L_KV,而不用保存K和V?
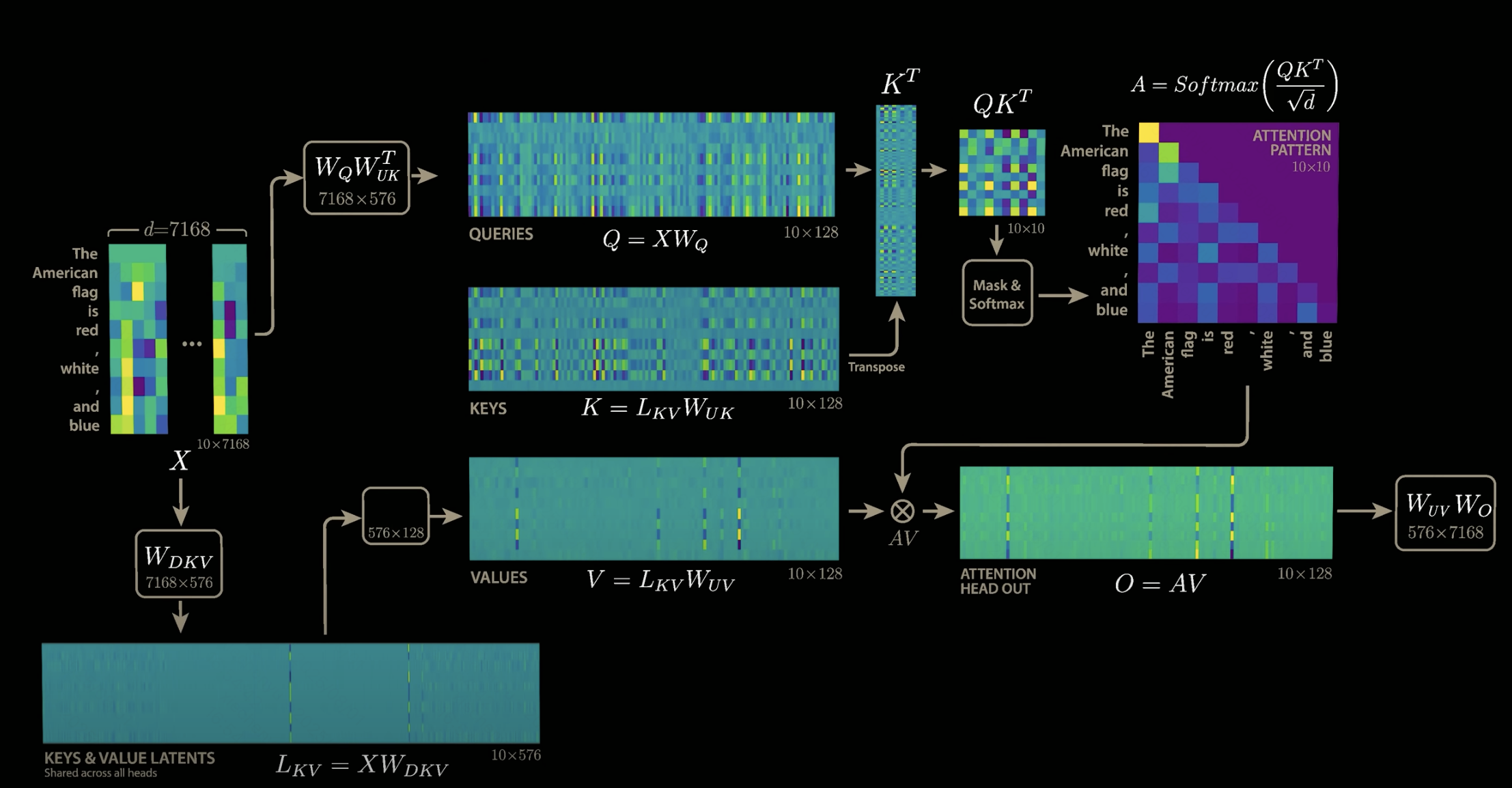
答案是根本就不存在K和V,MLA很巧妙的利用矩陣乘法,把W_UK與W_Q融合,把W_UV和W_O融合。至于為什么能這樣做,可以從公式中找出答案。
說不存在W_UK和W_UV其實并不嚴謹,但是這樣可以更方便去理解,其實這里所謂的把W_UK與W_Q融合是指輸入先經過W_Q,緊跟著就經過W_UK,從結果上來看,跟先把W_UK與W_Q相乘得到W_QUK,然后輸入經過W_QUK的效果是一樣的。
????????原本,加入W_DKV后,注意力的計算公式為:
?
????????按照矩陣運算,上述公式可以寫成下述形式:
????????我們完全可以將視作一個矩陣
,它和W_Q并沒有什么本質區別,只是維度需要調整(當然實際實現上還是兩個矩陣,分開來學習)。從上式中,我們發現注意力計算公式中的K消失了。
????????然后是最終輸出O的計算:
????????同理,這樣就能把W_V融進W_O中,我們能夠發現,最終輸出的計算公式中,V也消失了。
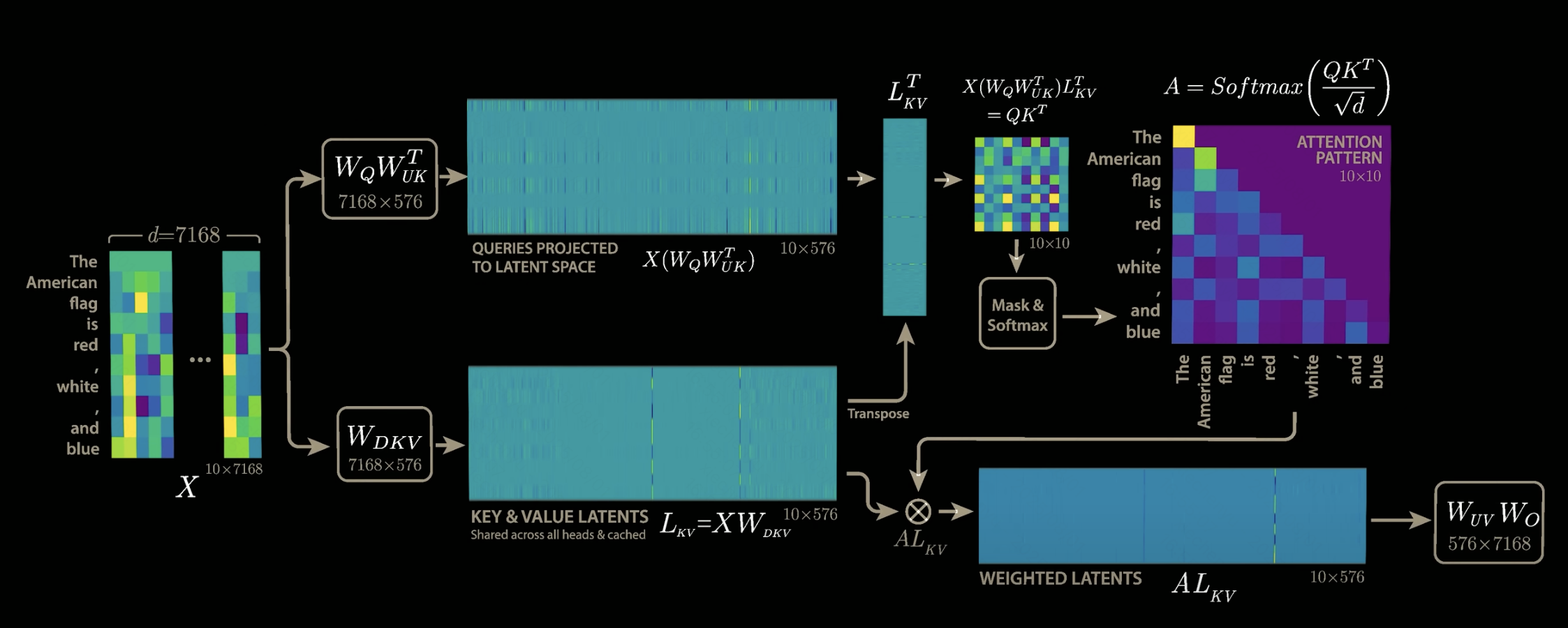
????????最后的效果如下圖,我們需要保存的只有L_KV,它是128個注意力頭共用的,所以只需要保存一份,存儲開銷計算如下,整個計算公式中完全不需要考慮注意力頭數目:
????????開銷降低40/0.7,約57倍,也就是deepseek技術報告中公布的壓縮倍數。?






--學習筆記15(分頁查詢PageHelper))


開源:AI智能體生態的技術革命)



)
)

![[python][selenium] Web UI自動化8種頁面元素定位方式](http://pic.xiahunao.cn/[python][selenium] Web UI自動化8種頁面元素定位方式)


)