一、為什么需要激活函數?
神經網絡本質上是多個線性變換(矩陣乘法)疊加。如果沒有激活函數,即使疊加多層,整體仍等價于一個線性函數:
這樣的網絡無法學習和擬合現實世界中復雜的非線性關系。
激活函數的作用:
- 在每一層加入非線性變換,使得網絡具有逼近任意非線性函數的能力。
- 激活神經元,產生“信息通過/抑制”的門控效果。
二、常見激活函數列表與直覺圖示
| 名稱 | 公式 | 輸出范圍 | 圖像形狀 | 是否中心對稱 | 使用場景 | |
| Sigmoid | (0,1) | S型 | 否 | 概率輸出,二分類 | ||
| Tanh | (-1,1) | 中心對稱S型 | 是 | RNN隱藏層 | ||
| ReLU | [0,+∞) | 截斷線性 | 否 | 默認隱藏層函數 | ||
| Leaky ReLU | 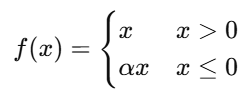 | (-∞,+∞) | 左側帶緩坡 | 否 | 緩解ReLU死神經元問題 | |
| ELU/GELU | Smooth ReLU變體 | (-1,∞) | 平滑曲線 | 否 | 深層網絡(如BERT) | |
| Softmax | (0,1)且總和=1 | 多維映射 | 否 | 多分類輸出層 |
三、每種激活函數詳細講解
3.1 Sigmoid函數(邏輯激活)
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
特性:
- 輸出范圍在(0,1),可理解為概率
- 單調遞增,飽和區梯度小(梯度消失問題嚴重)
- 在0附近比較線性,但遠離0時趨近于平穩
優點:
- 直觀表示“激活程度”(介于0與1之間)
- 在早期神經網絡和輸出層應用廣泛
缺點:
- ?梯度消失問題:遠離0時梯度趨近于0
- 輸出非中心對稱:導致后一層神經元輸入偏向正方向
使用建議:
- 不推薦用于隱藏層
- 可用于輸出為“概率”的任務(如二分類輸出層)?
3.2 Tanh函數(雙曲正切)
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ??
特性:
- 輸出范圍(-1,1),是中心對稱的S型函數
- 在0附近幾乎線性,表現比Sogmoid更好。
優點:
- 零均值輸出,收斂速度通常比Sigmoid快。
?缺點:
- 也存在梯度消失問題(在±2左右開始飽和)
使用建議:
- 在RNN等早期模型中較為常見。
- 若模型對“負激活”有需求,可以使用Tanh。
3.3 ReLU(Rectified Linear Unit)?
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ??
?特性:
- 最常用的激活函數,非線性強,計算簡單。
- 在x>0區域內導數為1,在x≤0區域內導數為0。
優點:
- 計算快,易于優化,不易發生梯度消失。
- 會產生稀疏激活(部分神經元輸出為0),提高泛化能力。
缺點:
- 死亡神經元問題:一旦某個神經元進入負區間并梯度為0,則該神經元永遠不會激活。
使用建議:
- 深度神經網絡的隱藏層默認激活函數。
- 若出現大量“死神經元”,可以使用Leaky ReLU或ELU替代。
3.4? Leaky ReLU
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ??? ? ?α通常為0.01?
特性:
- 為ReLU的改進版本,在負區間保留少量梯度。
優點:
- 緩解了ReLU的“死亡神經元”問題。
- 在某些任務上收斂更穩定。
缺點:
- 依賴于α超參數,需調參。
使用建議:
- 如果ReLU網絡中出現大量神經元輸出恒為0,可嘗試替換為Leaky ReLU
3.5 GELU(Gaussian Error Linear Unit)
? ? ? ? ? ? ? ? ? ? ? ? ? ? ?,
是標準正態分布的累積分布函數
?特性:
- 是ReLU與Sigmoid的混合形式。
- 表現為平滑的非線性函數。
優點:
- 在Transformer,BERT,ViT中廣泛使用 。
- 理論上更優,經驗上在大模型中性能更好。
使用建議:
- 在使用Transformer,BERT,T5等模型,默認激活就是GELU。?
3.6 Softmax(用于輸出層)
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
特性:
- 將向量轉換為“概率分布”:每個值在(0,1),總和為1。
- 常用于多分類任務的輸出層。
使用建議:
- 不用于隱藏層,僅用于輸出層。
- 通常與交叉熵損失函數一起使用。?
?
四、總結對比表
| 函數 | 是否線性 | 輸出范圍 | 是否對稱 | 梯度問題 | 使用推薦 |
|---|---|---|---|---|---|
| Sigmoid | 否 | (0, 1) | 否 | 易梯度消失 | 輸出層(二分類) |
| Tanh | 否 | (-1, 1) | 是 | 易梯度消失 | RNN、需要對稱時 |
| ReLU | 否 | [0, ∞) | 否 | 死神經元 | 默認隱藏層 |
| Leaky ReLU | 否 | (-∞, ∞) | 否 | 有梯度 | 替代 ReLU |
| GELU | 否 | (-∞, ∞) | 否 | 平滑收斂好 | BERT等大模型 |
| Softmax | 否 | (0, 1) 且和為1 | 否 | N/A | 多分類輸出 |
五、激活函數的三大核心指標
| 指標 | 含義 | 重要性 |
| 非線性能力 | 是否能打破線性疊加 | 所有激活函數的基本功能 |
| 是否有梯度 | 梯度在輸入范圍內是否為0 | 決定反向傳播是否可行 |
| 零中心性 | 輸出是否以0為中心 | 有助于加速收斂,避免梯度偏移 |
六、隱藏層和輸出層的激活函數選擇原則
| 層類型 | 推薦激活函數 | 原因 |
| 隱藏層 | ReLU/Leaky ReLU/GELU | 快速收斂,低計算開銷,有效抑制梯度問題 |
| 輸出層-二分類 | Sigmoid | 輸出概率,可與BCE Loss配合 |
| 輸出層-多分類 | Softmax | 輸出概率分布,可與CrossEntropyLoss配合 |
| 輸出層-回歸 | 無激活/Linear | 輸出連續值(如房價) |
?
七、ReLU系列變體的擴展圖譜
1.Leaky ReLU:緩解死神經元問題
2.PReLU(Parametric ReLU):負斜率α可學習
3.RReLU(Randomized ReLU):訓練時負斜率為隨機數
4.ELU(Exponential Linear Unit):負區間指數形狀,避免輸出偏正
5.SELU(Scaled ELU):自歸一化網絡(Self-Normalizing NN)
八、實際工程中激活函數的選型建議
| 場景 | 推薦函數 | 理由 |
| 默認情況 | ReLU | 簡單快速,表現好 |
| 出現大量死神經元 | Leaky ReLU/PReLU | 保持梯度 |
| 大模型(Transformer等) | GELU | 平滑非線性,更強表征能力 |
| 醫療/金融等數據對稱 | Tanh | 輸出中心對稱,利于穩定性 |
| 多標簽任務輸出層 | Sigmoid | 與BCE loss搭配使用 |
| 多分類任務輸出層 | Softmax | 與交叉熵搭配使用 |
九、激活函數與神經網絡結構的關系?
激活函數不是孤立使用的,而是與網絡層數,歸一化方法,損失函數等協同設計:
| 網絡結構 | 建議激活函數 | 原因 |
| MLP(多層感知機) | ReLU/LeakyReLU | 層數少,避免梯度消失即可 |
| CNN(卷積網絡) | ReLU/LeakyReLU | 圖像任務中默認激活,訓練快 |
| RNN/LSTM | Tanh/Sigmoid(門控) | RNN天然處理時序信息,Tanh為主,Sigmoid用于控制門結構 |
| Transformer | GELU/ReLU | BERT,GPT中使用GELU收斂更平穩,ReLU計算更快 |
| 自歸一化網絡(SNN) | SELU | 與特殊初始化+dropout配合,自動歸一化每層輸出 |
| GAN生成器 | ReLU/LeakyReLU | 生成端需非線性表達能力強 |
| GAN判別器 | LeakyReLU | 判別器中避免ReLU死神經元影響判別能力 |
?
十、訓練中因激活函數導致的典型問題與解決方案
| 問題 | 可能原因 | 解決方案 |
| 訓練不收斂 | Sigmoid/Tanh導致梯度消失 | 改用ReLU/GELU |
| 大量神經元恒為0 | ReLU死神經元問題 | 改用LeakyReLU/PReLU |
| loss起伏大 | 梯度爆炸 or 梯度不穩定 | 嘗試使用平滑激活函數(GELU/Swish) |
| 模型準確率震蕩 | 輸出分布不均衡 | 檢查是否中心兌成(可嘗試Tanh/SELU) |
十一、激活函數與歸一化層的順序問題
在使用BatchNorm/LayerNorm時,激活函數的位置非常關鍵。
| 順序類型 | 建議順序 | 說明 |
| CNN(BatchNorm) | Conv?BN?ReLU | 主流做法,BN規范分布后再非線性激活 |
| Transformer(LayerNorm) | LN?Linear?GELU | 大模型默認順序(PreNorm) |
| ResNet殘差結構 | ReLU放在跳躍前還是后? | 大多在殘差和主路路徑相見之后ReLU |
十二、激活函數的梯度可視化
| 激活函數 | 導數(梯度) | 梯度圖像直覺 |
|---|---|---|
| Sigmoid | σ′(x)=σ(x)(1?σ(x))\sigma'(x) = \sigma(x)(1 - \sigma(x)) | 梯度最大在 x=0,越遠越趨近于0(易梯度消失) |
| Tanh | tanh?′(x)=1?tanh?2(x)\tanh'(x) = 1 - \tanh^2(x) | 梯度范圍比 Sigmoid 更廣,但仍有飽和問題 |
| ReLU | f′(x)=1?if?x>0;0?elsef'(x) = 1 \text{ if } x>0; 0 \text{ else} | 梯度恒定,簡單高效 |
| Leaky ReLU | f′(x)=1?if?x>0;α?elsef'(x) = 1 \text{ if } x>0; \alpha \text{ else} | 保留負區間小梯度 |
| GELU | 近似導數為高斯變換 | 平滑過渡,梯度分布均衡(大模型表現好) |
十三、激活函數的數學本質:非線性特征空間映射
從數學角度來看,激活函數在整個神經網絡中充當非線性特征映射角色:
網絡每一層執行的是
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
其中?是激活函數
本質上是將低維空間的線性表示映射到高維非線性空間,從而可以更好地學習復雜關系(類似SVM的核函數思想)
十四、小結
| 場景 | 首選激活函數 | 替代備選 |
|---|---|---|
| 圖像分類 | ReLU | Leaky ReLU / GELU |
| 序列建模 | Tanh / GELU | ReLU |
| 大型Transformer | GELU | Swish |
| 輸出為概率(二分類) | Sigmoid | 無 |
| 多分類輸出層 | Softmax | 無 |
| GAN 判別器 | Leaky ReLU | ReLU |
| 出現死神經元 | Leaky ReLU | PReLU |


)


一種在路徑規劃和圖搜索中廣泛使用的啟發式搜索算法)










)
行為型:訪問者模式詳解)

![P4568 [JLOI2011] 飛行路線](http://pic.xiahunao.cn/P4568 [JLOI2011] 飛行路線)