PostgreSQL內核學習:WindowAgg 幀優化與節點去重
- 背景
- 關鍵詞解釋
- 本優化主要修改內容描述
- 提交信息
- 提交描述
- 源碼解讀
- optimize_window_clauses 函數
- 核心邏輯拆解
- 函數時序圖
- 新增結構體類型 SupportRequestOptimizeWindowClause
- 優化后的效果
- 幀優化 sql 用例
- 查詢計劃輸出
- 節點去重 sql 用例
- 查詢計劃輸出
- 限制與約束
- 結果不受 `frameOptions` 影響的窗口函數
- 其他窗口函數為何不可優化?
- 問題思考
- 解決方案思考
- 問題描述
- 方案一:支持函數中清空偏移量
- 方案二:在優化階段集中清空偏移量
- 方案三:修改去重條件以忽略偏移量差異
- 優化后執行結果
聲明:本文的部分內容參考了他人的文章。在編寫過程中,我們尊重他人的知識產權和學術成果,力求遵循合理使用原則,并在適用的情況下注明引用來源。
本文主要參考了 postgresql-18 beta2 的開源代碼和《PostgresSQL數據庫內核分析》一書
背景
??在 PostgreSQL 中,窗口函數(如 row_number()、rank() 等)是用于在查詢中對行集進行分區和排序計算的強大工具。然而,窗口函數的默認行為可能導致性能問題。具體來說,窗口函數的 WindowClause 默認使用 RANGE 模式,這要求執行器檢查“同行”(peer rows,即 ORDER BY 字段值相同的行),從而增加計算開銷。對于某些窗口函數(如 row_number()),RANGE 和 ROWS 模式的計算結果相同,但 ROWS 模式的執行效率更高,因為它無需檢查同行。
??通過對測試查詢的分析,發現使用 ROWS 模式替代 RANGE 模式可以帶來很大的性能提升。因此,此補丁通過允許窗口函數動態調整其 frameOptions(框架選項),優化查詢執行計劃,從而減少不必要的性能開銷。
關鍵詞解釋
- 窗口函數(Window Function):一種
SQL函數,用于在查詢中對行集進行分區(PARTITION BY)和排序(ORDER BY)計算,如row_number()、rank()等。- WindowClause:定義窗口函數的分區、排序和框架范圍的結構,包含
partitionClause、orderClause和frameOptions等字段。- frameOptions:指定窗口函數的框架范圍(
frame specification),包括模式(ROWS或RANGE)和邊界(如UNBOUNDED PRECEDING、CURRENT ROW)。- ROWS vs. RANGE:
- ROWS:基于行數定義框架范圍,效率較高,因為只考慮物理行位置。
- RANGE:基于值范圍定義框架范圍,需要檢查同行(值相同的行),開銷較大。
- SupportRequestOptimizeWindowClause:新引入的節點類型,用于支持窗口函數優化其 WindowClause 的框架選項。
- WindowAgg:查詢計劃中的節點,負責執行窗口函數計算。減少 WindowAgg 節點數量可提升性能。
- 去重(De-duplication):合并重復的
WindowClause,以減少執行計劃中的WindowAgg節點。
本優化主要修改內容描述
提交信息
??下面為本次優化的提交信息,hash值為:ed1a88ddaccfe883e4cf74d30319accfeae6cfe5
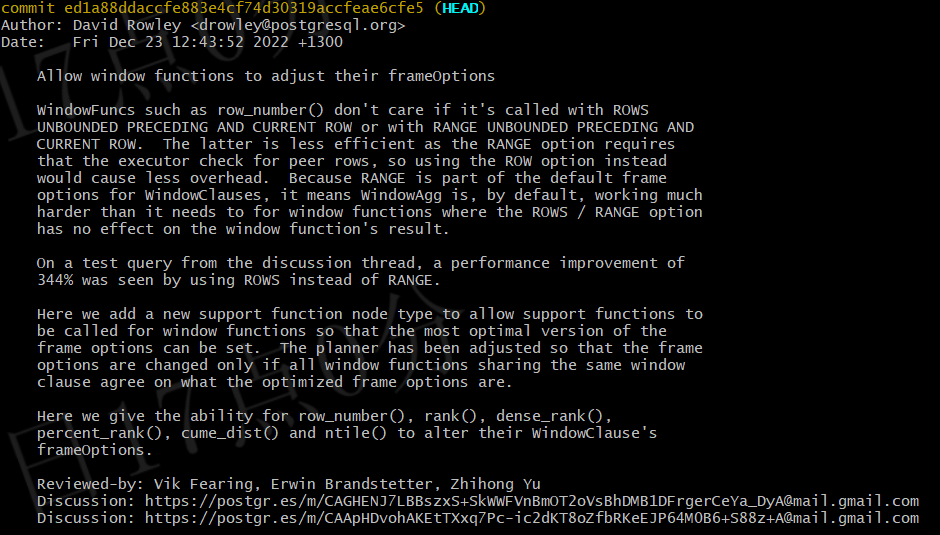
提交描述
??此補丁為 PostgreSQL 的查詢計劃器(planner)增加了對窗口函數框架選項的優化能力,允許窗口函數(如 row_number()、rank()、dense_rank()、percent_rank()、cume_dist()、ntile())通過支持函數(support function)調整其 WindowClause 的 frameOptions,以使用更高效的 ROWS 模式代替默認的 RANGE 模式。主要修改包括:
- 新支持函數節點類型:
- 在
supportnodes.h中引入了新的節點類型SupportRequestOptimizeWindowClause,允許窗口函數的支持函數指定優化的frameOptions。- 該節點為計劃器提供了一個機制,用于查詢每個窗口函數是否可以調整其框架選項。
- 計劃器優化邏輯:
- 在
planner.c中添加了optimize_window_clauses函數,遍歷所有WindowClause及其關聯的WindowFunc節點。- 對于每個
WindowClause,計劃器調用每個窗口函數的prosupport函數,檢查是否可以優化frameOptions(通常是將RANGE改為ROWS)。- 僅當同一
WindowClause下的所有窗口函數一致同意優化后的frameOptions時,才會應用更改。- 優化后,優化器檢查是否存在重復的
WindowClause,并通過合并減少WindowAgg節點的生成,從而進一步優化查詢計劃。- 窗口函數支持函數:
- 在
windowfuncs.c中為row_number()、rank()、dense_rank()、percent_rank()、cume_dist()和ntile()添加了支持函數(如window_row_number_support、window_rank_support等)。- 這些支持函數指定可以將
frameOptions設置為ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW,因為此模式對這些函數的結果無影響,且避免了同行檢查的開銷。- 測試與驗證:
- 在
window.sql和window.out中添加了回歸測試,驗證優化后的查詢計劃是否正確減少了WindowAgg節點數量,并確保結果正確。- 測試用例展示了當所有窗口函數支持優化時,查詢計劃只包含一個
WindowAgg節點;當某些窗口函數(如count(*))不支持優化時,其frameOptions保持不變。
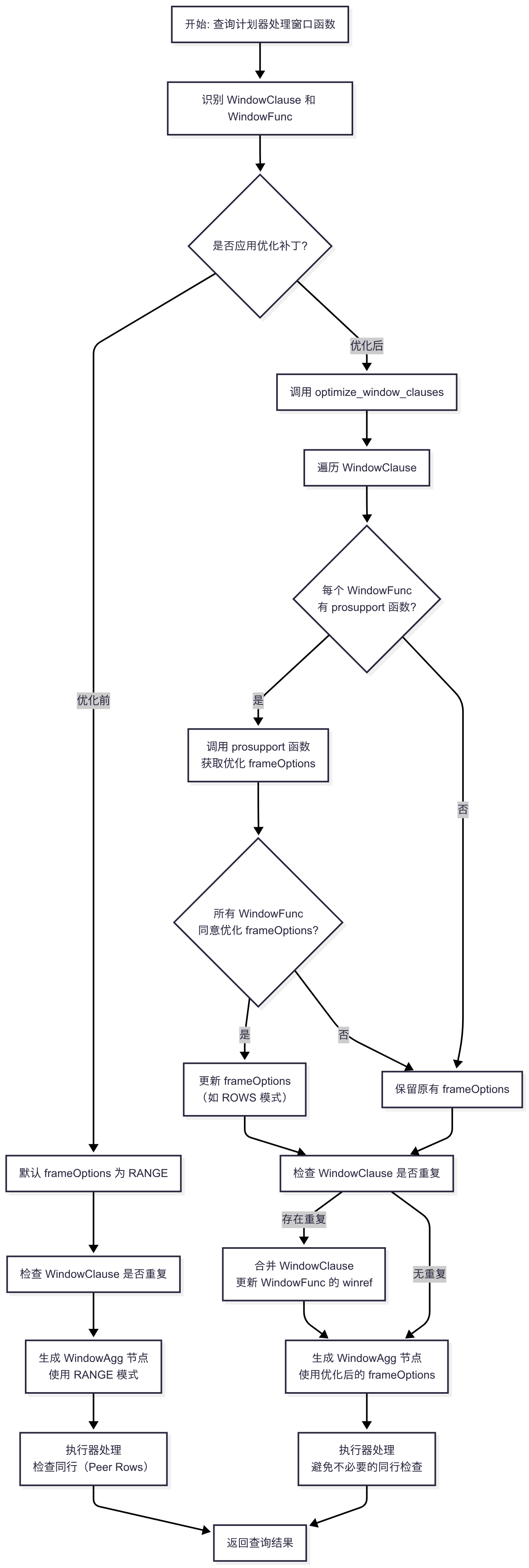
??以下是一個使用 Mermaid 語法編寫的流程圖代碼,展示 PostgreSQL 補丁 0001-Allow-window-functions-to-adjust-their-frameOptions.patch 優化前后查詢計劃器處理窗口函數的流程對比。流程圖通過一個圖中的兩個分支(優化前和優化后)來清晰展示差異,重點突出 frameOptions 優化和 WindowClause 去重的過程。
??優化前,計劃器直接使用默認的 RANGE 模式生成 WindowAgg 節點,導致執行器需檢查同行(peer rows),增加性能開銷。優化后,計劃器通過 optimize_window_clauses 調用窗口函數的支持函數,檢查是否可將 frameOptions 優化為更高效的 ROWS 模式,并在必要時合并重復的 WindowClause,減少 WindowAgg 節點,從而避免不必要的同行檢查,提升查詢性能。
注:代碼使用
Mermaid的graph TD語法,適合在支持 Mermaid 的環境中渲染。
??下面給出對應的作圖代碼,感興趣的小伙伴可以自取:
graph TDA[開始: 查詢計劃器處理窗口函數] --> B[識別 WindowClause 和 WindowFunc]B --> C{是否應用優化補丁?}%% 優化前分支C -->|優化前| D[默認 frameOptions 為 RANGE]D --> E[檢查 WindowClause 是否重復]E --> F[生成 WindowAgg 節點<br>使用 RANGE 模式]F --> G[執行器處理<br>檢查同行(Peer Rows)]G --> H[返回查詢結果]%% 優化后分支C -->|優化后| I[調用 optimize_window_clauses]I --> J[遍歷 WindowClause]J --> K{每個 WindowFunc<br>有 prosupport 函數?}K -->|是| L[調用 prosupport 函數<br>獲取優化 frameOptions]K -->|否| M[保留原有 frameOptions]L --> N{所有 WindowFunc<br>同意優化 frameOptions?}N -->|是| O[更新 frameOptions<br>(如 ROWS 模式)]N -->|否| MO --> P[檢查 WindowClause 是否重復]M --> PP -->|存在重復| Q[合并 WindowClause<br>更新 WindowFunc 的 winref]P -->|無重復| R[生成 WindowAgg 節點<br>使用優化后的 frameOptions]Q --> RR --> S[執行器處理<br>避免不必要的同行檢查]S --> H[返回查詢結果]
源碼解讀
optimize_window_clauses 函數
??optimize_window_clauses 是本次補丁的核心函數,位于 src/backend/optimizer/plan/planner.c,負責優化 WindowClause 的 frameOptions 并處理去重邏輯。以下是對其源碼的詳細解讀,結合補丁的上下文說明其實現。
/* * optimize_window_clauses* 調用每個 WindowFunc 的 prosupport 函數,檢查是否可以調整 WindowClause 的設置,* 以便執行器以更優化的方式執行窗口函數。** 目前僅允許調整 WindowClause 的 frameOptions。未來可能支持更多優化。*/
static void
optimize_window_clauses(PlannerInfo *root, WindowFuncLists *wflists)
{List *windowClause = root->parse->windowClause; // 獲取查詢解析樹中的 WindowClause 列表ListCell *lc; // 聲明用于遍歷 WindowClause 列表的單元指針foreach(lc, windowClause) // 遍歷 WindowClause 列表{WindowClause *wc = lfirst_node(WindowClause, lc); // 獲取當前 WindowClause 節點ListCell *lc2; // 聲明用于遍歷 WindowFunc 列表的單元指針int optimizedFrameOptions = 0; // 初始化優化后的 frameOptions,默認為 0Assert(wc->winref <= wflists->maxWinRef); // 斷言:確保 WindowClause 的 winref 不超過最大值/* 跳過沒有任何 WindowFunc 的 WindowClause */if (wflists->windowFuncs[wc->winref] == NIL)continue; // 如果當前 WindowClause 無關聯 WindowFunc,跳到下一個 WindowClauseforeach(lc2, wflists->windowFuncs[wc->winref]) // 遍歷當前 WindowClause 的 WindowFunc 列表{SupportRequestOptimizeWindowClause req; // 聲明支持優化請求的結構體SupportRequestOptimizeWindowClause *res; // 聲明指向優化結果的指針WindowFunc *wfunc = lfirst_node(WindowFunc, lc2); // 獲取當前 WindowFunc 節點Oid prosupport; // 聲明支持函數的 OIDprosupport = get_func_support(wfunc->winfnoid); // 獲取當前 WindowFunc 的支持函數 OID/* 檢查當前 WindowFunc 是否有支持函數 */if (!OidIsValid(prosupport))break; // 如果沒有支持函數,退出 WindowFunc 循環,無法優化此 WindowClausereq.type = T_SupportRequestOptimizeWindowClause; // 設置請求類型為優化 WindowClausereq.window_clause = wc; // 設置請求的 WindowClause 為當前 WindowClausereq.window_func = wfunc; // 設置請求的 WindowFunc 為當前 WindowFuncreq.frameOptions = wc->frameOptions; // 設置請求的 frameOptions 為當前 WindowClause 的 frameOptions/* 調用支持函數 */res = (SupportRequestOptimizeWindowClause *)DatumGetPointer(OidFunctionCall1(prosupport,PointerGetDatum(&req))); // 調用支持函數,獲取優化結果/** 如果支持函數不支持此請求類型,跳到下一個 WindowClause*/if (res == NULL)break; // 如果支持函數返回 NULL,退出 WindowFunc 循環,跳到下一個 WindowClause/** 對于當前 WindowClause 的第一個 WindowFunc,保存其優化后的 frameOptions*/if (foreach_current_index(lc2) == 0)optimizedFrameOptions = res->frameOptions; // 保存第一個 WindowFunc 的優化 frameOptions/** 對于后續 WindowFunc,如果 frameOptions 與第一個不同,* 則無法優化此 WindowClause 的 frameOptions*/else if (optimizedFrameOptions != res->frameOptions)break; // 如果 frameOptions 不一致,退出循環,跳到下一個 WindowClause}/* 如果所有 WindowFunc 一致同意優化 frameOptions,則調整 frameOptions */if (lc2 == NULL && wc->frameOptions != optimizedFrameOptions){ListCell *lc3; // 聲明用于遍歷 WindowClause 進行去重的單元指針/* 應用新的 frameOptions */wc->frameOptions = optimizedFrameOptions; // 更新當前 WindowClause 的 frameOptions/** 檢查更改 frameOptions 后是否導致此 WindowClause 與其他 WindowClause 重復。* 如果只有 1 個 WindowClause,無需檢查去重。*/if (list_length(windowClause) == 1)continue; // 如果只有 1 個 WindowClause,跳過去重檢查/** 執行去重檢查,如果找到重復的 WindowClause,則重用已有 WindowClause*/foreach(lc3, windowClause) // 遍歷所有 WindowClause 進行去重檢查{WindowClause *existing_wc = lfirst_node(WindowClause, lc3); // 獲取已有 WindowClause/* 跳過當前正在編輯的 WindowClause */if (existing_wc == wc)continue; // 如果是同一個 WindowClause,跳過比較/** 執行與 transformWindowFuncCall 中相同的去重檢查*/if (equal(wc->partitionClause, existing_wc->partitionClause) &&equal(wc->orderClause, existing_wc->orderClause) &&wc->frameOptions == existing_wc->frameOptions &&equal(wc->startOffset, existing_wc->startOffset) &&equal(wc->endOffset, existing_wc->endOffset)) // 檢查 partitionClause、orderClause 等是否相同{ListCell *lc4; // 聲明用于遍歷 WindowFunc 的單元指針/** 將 wc 的所有 WindowFunc 移動到 existing_wc。* 需要調整每個 WindowFunc 的 winref,并將 wc 的 WindowFunc 列表* 移動到 existing_wc 的 WindowFunc 列表。*/foreach(lc4, wflists->windowFuncs[wc->winref]) // 遍歷當前 WindowClause 的 WindowFunc{WindowFunc *wfunc = lfirst_node(WindowFunc, lc4); // 獲取當前 WindowFuncwfunc->winref = existing_wc->winref; // 更新 WindowFunc 的 winref 為 existing_wc 的 winref}/* 移動 WindowFunc 列表 */wflists->windowFuncs[existing_wc->winref] = list_concat(wflists->windowFuncs[existing_wc->winref],wflists->windowFuncs[wc->winref]); // 合并 WindowFunc 列表wflists->windowFuncs[wc->winref] = NIL; // 清空當前 WindowClause 的 WindowFunc 列表/** transformWindowFuncCall 應已確保沒有其他重復,* 因此無需繼續檢查其他 WindowClause*/break; // 找到重復后,退出去重循環}}}}
}
參數:
root:查詢計劃器的上下文,包含解析后的查詢樹(如windowClause)。wflists:WindowFuncLists結構,存儲每個WindowClause關聯的WindowFunc列表,wflists->windowFuncs[winref]按winref索引窗口函數。
作用:遍歷所有
WindowClause,為每個WindowClause檢查是否可優化frameOptions,并在優化后處理重復的WindowClause。
核心邏輯拆解
??函數通過以下步驟實現優化:
- 遍歷
WindowClause:
foreach(lc, windowClause)
{WindowClause *wc = lfirst_node(WindowClause, lc);ListCell *lc2;int optimizedFrameOptions = 0;...
}
- 使用
foreach宏遍歷windowClause列表,獲取每個WindowClause(wc)。 - 定義
optimizedFrameOptions變量,初始化為0,用于存儲支持函數建議的優化框架選項。
- 跳過無
WindowFunc的WindowClause:
Assert(wc->winref <= wflists->maxWinRef);
if (wflists->windowFuncs[wc->winref] == NIL)continue;
- 檢查
wc->winref是否有效(不大于wflists->maxWinRef)。 - 如果
WindowClause沒有關聯的WindowFunc(wflists->windowFuncs[wc->winref] == NIL),跳過處理。
- 檢查每個
WindowFunc的支持函數:
foreach(lc2, wflists->windowFuncs[wc->winref])
{SupportRequestOptimizeWindowClause req;SupportRequestOptimizeWindowClause *res;WindowFunc *wfunc = lfirst_node(WindowFunc, lc2);Oid prosupport;prosupport = get_func_support(wfunc->winfnoid);if (!OidIsValid(prosupport))break; /* can't optimize this WindowClause */...
}
- 遍歷當前
WindowClause的所有WindowFunc(通過wflists->windowFuncs[wc->winref])。 - 獲取每個
WindowFunc的支持函數OID(prosupport),通過get_func_support(wfunc->winfnoid)。 - 如果
WindowFunc沒有支持函數(prosupport無效),終止優化,跳到下一個WindowClause。
- 調用支持函數獲取優化
frameOptions:
req.type = T_SupportRequestOptimizeWindowClause;
req.window_clause = wc;
req.window_func = wfunc;
req.frameOptions = wc->frameOptions;res = (SupportRequestOptimizeWindowClause *)DatumGetPointer(OidFunctionCall1(prosupport, PointerGetDatum(&req)));
if (res == NULL)break; /* skip to next WindowClause */
- 初始化
SupportRequestOptimizeWindowClause結構(req),設置類型、當前WindowClause、窗口函數和當前frameOptions。 - 調用支持函數(
OidFunctionCall1),傳入req,獲取返回值res。 - 如果支持函數返回
NULL(不支持優化),終止優化,跳到下一個WindowClause。
- 驗證所有
WindowFunc的一致性:
if (foreach_current_index(lc2) == 0)optimizedFrameOptions = res->frameOptions;
else if (optimizedFrameOptions != res->frameOptions)break; /* skip to next WindowClause */
- 對于第一個
WindowFunc(foreach_current_index(lc2) == 0),記錄其建議的frameOptions到optimizedFrameOptions。 - 對于后續
WindowFunc,檢查其建議的frameOptions是否與第一個一致。如果不一致,終止優化,跳到下一個WindowClause。
- 應用優化后的
frameOptions:
if (lc2 == NULL && wc->frameOptions != optimizedFrameOptions)
{wc->frameOptions = optimizedFrameOptions;...
}
- 如果遍歷完成(
lc2 == NULL)且optimizedFrameOptions與當前frameOptions不同,更新wc->frameOptions為優化值(通常為ROWS模式)。
- 檢查和合并重復
WindowClause:
if (list_length(windowClause) == 1)continue;foreach(lc3, windowClause)
{WindowClause *existing_wc = lfirst_node(WindowClause, lc3);if (existing_wc == wc)continue;if (equal(wc->partitionClause, existing_wc->partitionClause) &&equal(wc->orderClause, existing_wc->orderClause) &&wc->frameOptions == existing_wc->frameOptions &&equal(wc->startOffset, existing_wc->startOffset) &&equal(wc->endOffset, existing_wc->endOffset)){ListCell *lc4;foreach(lc4, wflists->windowFuncs[wc->winref]){WindowFunc *wfunc = lfirst_node(WindowFunc, lc4);wfunc->winref = existing_wc->winref;}wflists->windowFuncs[existing_wc->winref] = list_concat(wflists->windowFuncs[existing_wc->winref],wflists->windowFuncs[wc->winref]);wflists->windowFuncs[wc->winref] = NIL;break;}
}
- 如果
windowClause列表長度為1,跳過去重檢查。 - 遍歷其他
WindowClause(existing_wc),檢查是否與當前wc重復(比較partitionClause、orderClause、frameOptions、startOffset和endOffset)。 - 如果找到重復:
- 將
wc的所有WindowFunc的winref更新為existing_wc->winref。 - 合并
wflists->windowFuncs[wc->winref]到wflists->windowFuncs[existing_wc->winref]。 - 清空
wflists->windowFuncs[wc->winref],標記為NIL。 - 終止檢查(假設
transformWindowFuncCall已確保無其他重復)。
- 將
函數時序圖
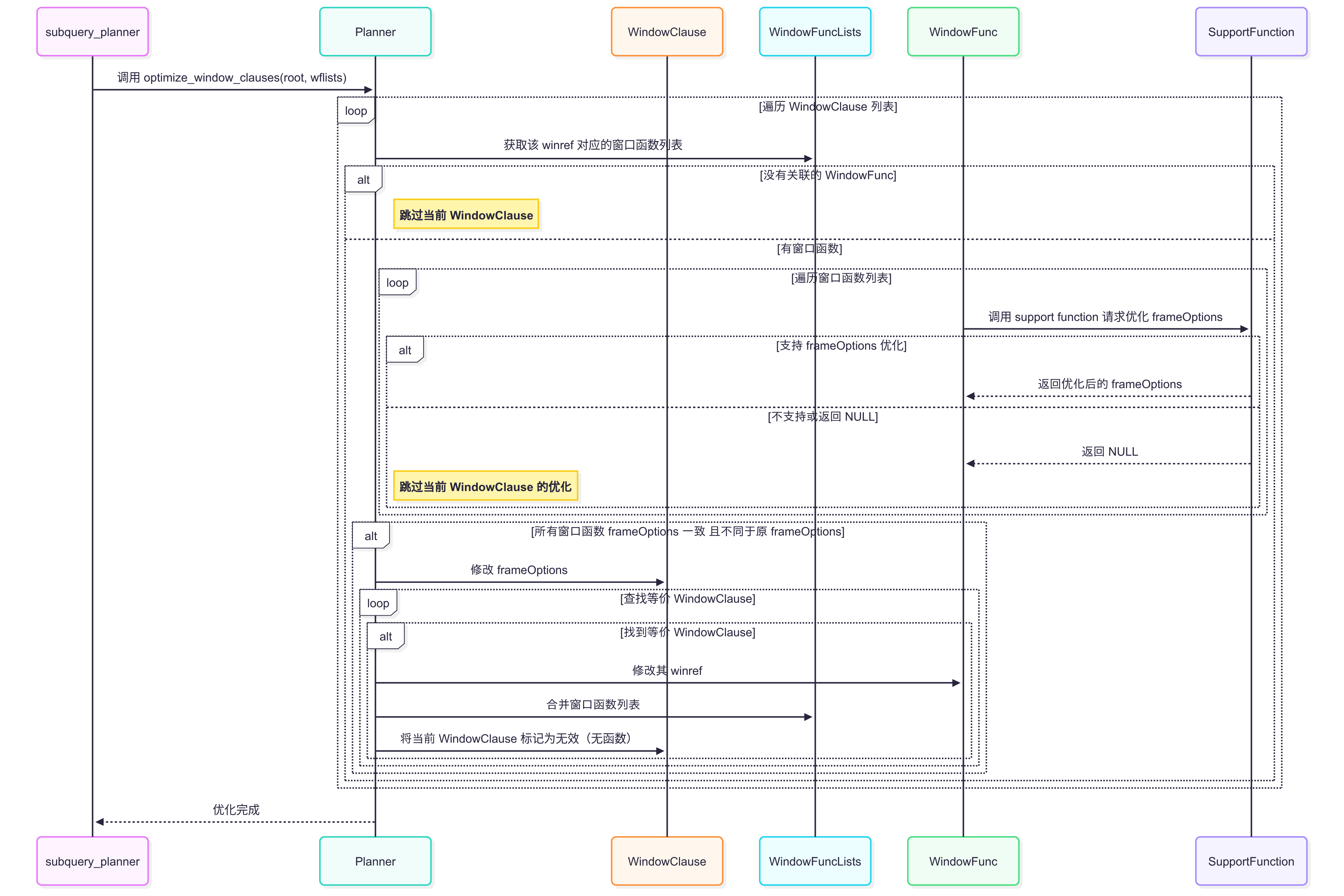
新增結構體類型 SupportRequestOptimizeWindowClause
??SupportRequestOptimizeWindowClause 是一個新引入的結構體,定義在 src/include/nodes/supportnodes.h 文件中,用于支持 PostgreSQL 查詢計劃器優化窗口函數的 frameOptions。該結構體是補丁的核心組件之一,提供了窗口函數支持函數(prosupport)與計劃器之間的接口,允許動態調整 WindowClause 的框架選項(如從 RANGE 切換到更高效的 ROWS 模式)。源碼定義如下:
typedef struct SupportRequestOptimizeWindowClause
{NodeTag type; // 節點類型標識,用于 PostgreSQL 的節點系統/* 輸入字段: */WindowFunc *window_func; // 指向當前窗口函數的數據結構struct WindowClause *window_clause; // 指向當前窗口子句的數據結構/* 輸入/輸出字段: */int frameOptions; // 新的 frameOptions 值,若無優化則保持不變
} SupportRequestOptimizeWindowClause;
??SupportRequestOptimizeWindowClause 的主要作用是為窗口函數的優化提供一個標準化的請求-響應機制,允許窗口函數的 prosupport 函數(例如 window_row_number_support)檢查并建議優化的 frameOptions,從而減少執行器的計算開銷(如避免同行檢查)。
優化后的效果
幀優化 sql 用例
CREATE TABLE t1 (c1 int, c2 int);
INSERT INTO t1 VALUES (1, generate_series(1, 100000));
CREATE INDEX t1_idx ON t1(c1);
EXPLAIN (COSTS OFF, ANALYZE)
SELECT * FROM (SELECT row_number() OVER (ORDER BY c1) rn, * FROM t1
) t WHERE rn < 20;
查詢計劃輸出
QUERY PLAN
-----------------------------------------------------------------------------------WindowAgg (actual time=0.079..0.100 rows=19.00 loops=1)Window: w1 AS (ORDER BY t1.c1 ROWS UNBOUNDED PRECEDING)Run Condition: (row_number() OVER w1 < 20)Storage: Memory Maximum Storage: 17kBBuffers: shared hit=1 read=2-> Index Scan using t1_idx on t1 (actual time=0.065..0.073 rows=20.00 loops=1)Index Searches: 1Buffers: shared hit=1 read=2Planning:Buffers: shared hit=39Planning Time: 0.361 msExecution Time: 0.149 ms
(12 rows)
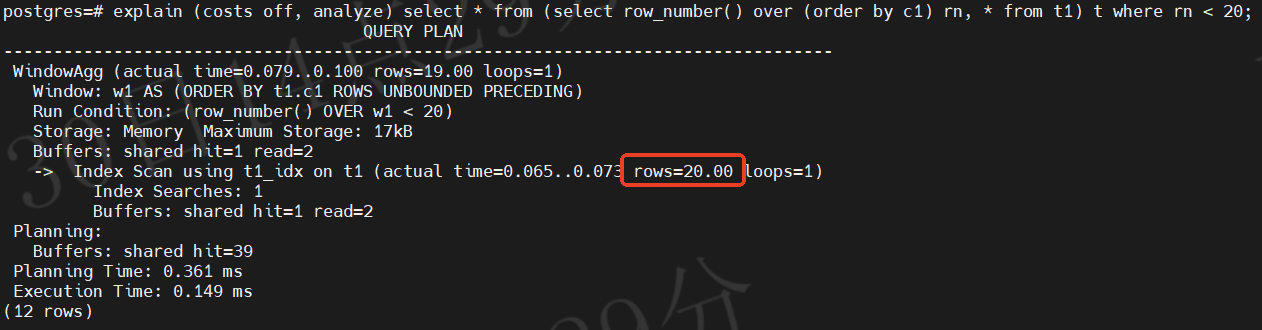
??由執行結果可以看出,通過支持函數將 frameOptions 自動修改為 ROWS,從而無需判斷是否屬于同一個同行組,只需按物理行號維護幀邊界即可,從而實現了提前終止掃描。底層 Index Scan 僅需讀取前 20 行,極大程度的減少了執行時間和資源消耗。
節點去重 sql 用例
CREATE TEMPORARY TABLE empsalary (depname varchar,empno bigint,salary int,enroll_date date
);INSERT INTO empsalary VALUES
('develop', 10, 5200, '2007-08-01'),
('sales', 1, 5000, '2006-10-01'),
('personnel', 5, 3500, '2007-12-10'),
('sales', 4, 4800, '2007-08-08'),
('personnel', 2, 3900, '2006-12-23'),
('develop', 7, 4200, '2008-01-01'),
('develop', 9, 4500, '2008-01-01'),
('sales', 3, 4800, '2007-08-01'),
('develop', 8, 6000, '2006-10-01'),
('develop', 11, 5200, '2007-08-15');-- Ensure WindowClause frameOptions are changed so that only a single
-- WindowAgg exists in the plan.
EXPLAIN (COSTS OFF, VERBOSE)
SELECTempno,depname,row_number() OVER (PARTITION BY depname ORDER BY enroll_date) rn,rank() OVER (PARTITION BY depname ORDER BY enroll_date ROWS BETWEENUNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) rnk,dense_rank() OVER (PARTITION BY depname ORDER BY enroll_date RANGE BETWEENCURRENT ROW AND CURRENT ROW) drnk
FROM empsalary;
查詢計劃輸出
QUERY PLAN
----------------------------------------------------------------------------------------------------------WindowAggOutput: empno, depname, row_number() OVER w1, rank() OVER w1, dense_rank() OVER w1, enroll_dateWindow: w1 AS (PARTITION BY empsalary.depname ORDER BY empsalary.enroll_date ROWS UNBOUNDED PRECEDING)-> SortOutput: depname, enroll_date, empnoSort Key: empsalary.depname, empsalary.enroll_date-> Seq Scan on pg_temp.empsalaryOutput: depname, enroll_date, empno
(8 rows)
??由以上執行計劃可以發現,PostgreSQL 在進行優化后,可以將多個兼容窗口的幀選項統一重寫為等效的 ROWS 模式。此時所有窗口函數共享同一個 WindowClause,從而合并為一個 WindowAgg 節點。最終執行計劃中僅保留一個窗口聚合節點,消除了冗余計算,顯著提升了執行效率并簡化執行計劃結構。
限制與約束
??補丁的優化僅適用于特定窗口函數(row_number()、rank()、dense_rank()、percent_rank()、cume_dist()、ntile()),因為這些函數的計算邏輯與 frameOptions 的 RANGE 或 ROWS 模式無關,可以安全切換而不改變結果。以下是詳細分析:
結果不受 frameOptions 影響的窗口函數
??以下六個窗口函數的語義僅依賴分區和排序順序,與框架范圍無關,因此可安全從 RANGE 優化為 ROWS 模式:
- row_number()
- 邏輯:為分區中的每一行分配遞增序號,僅依賴
PARTITION BY和ORDER BY定義的順序。- 補丁說明:在
src/backend/utils/adt/windowfuncs.c的window_row_number_support中,明確指出row_number()“總是逐行遞增 1”,無論frameOptions為RANGE或ROWS,結果相同。- 原因:
row_number()不考慮同行,僅按行序計數,ROWS模式避免了RANGE模式檢查同行的開銷。
- rank()
- 邏輯:為分區中具有相同排序鍵值的行分配相同的排名,依賴排序順序。
- 補丁說明:在
window_rank_support中,rank()等價于(COUNT(*) OVER (... RANGE UNBOUNDED PRECEDING) - COUNT(*) OVER (... RANGE CURRENT ROW) + 1),但結果與框架范圍無關,優化為ROWS模式不影響語義。- 原因:排名基于排序鍵的分組,
ROWS模式仍正確處理順序。
- dense_rank()
- 邏輯:類似
rank(),但排名無間隙,僅依賴排序鍵。- 補丁說明:
window_dense_rank_support指出dense_rank()不受框架選項影響,優化為ROWS模式與row_number()一致。- 原因:與
rank()類似,ROWS模式不改變排名邏輯。
- percent_rank()
- 邏輯:計算
(rank - 1) / (total_rows - 1),依賴rank()的邏輯。- 補丁說明:
window_percent_rank_support確認結果與框架范圍無關,優化為ROWS模式。- 原因:基于
rank(),僅需排序順序,ROWS模式適用。
- cume_dist()
- 邏輯:計算分區中排序鍵小于或等于當前行的行數比例
(rank / total_rows)。- 補丁說明:
window_cume_dist_support指出僅依賴排序順序,ROWS模式不影響結果。- 原因:比例計算基于排序鍵的分組,
ROWS模式仍有效。
- ntile(n)
- 邏輯:將分區劃分為
n個等份,依賴行數和分區大小。- 補丁說明:
window_ntile_support確認結果與框架范圍無關,優化為ROWS模式。- 原因:分組基于行序,
ROWS模式直接適用。
其他窗口函數為何不可優化?
??其他窗口函數(如 sum()、avg()、count()、lead()、lag()、first_value()、last_value())的結果直接依賴框架范圍,切換 RANGE 到 ROWS 可能改變語義:
- sum()、avg()、count()
- 邏輯:這些聚合函數計算框架范圍內的值(如
SUM() OVER (... RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) 計算從分區開始到當前行的總和)。- 問題:
RANGE模式包括所有同行(排序鍵值相同的行),而ROWS模式僅包括物理行,可能遺漏同行,導致結果不同。- 示例:若分區有
3行排序鍵值相同,RANGE模式對sum()包含所有3行,ROWS模式可能僅包含當前行,改變總和。
- lead()、lag()
- 邏輯:基于框架內的相對行位置訪問前后行。
- 問題:
RANGE和ROWS模式定義的框架范圍不同,可能導致訪問不同行,改變結果。
- first_value()、last_value()
- 邏輯:獲取框架范圍內的第一行或最后行的值。
- 問題:
RANGE模式可能包括更多同行,而ROWS模式僅考慮物理行,改變返回值。
問題思考
??觀察以下用例
CREATE TABLE sales (sale_id INTEGER,product TEXT,sale_date DATE,amount INTEGER
);INSERT INTO sales VALUES
(1, 'Laptop', '2023-01-01', 1000),
(2, 'Laptop', '2023-02-01', 1200),
(3, 'Laptop', '2023-03-01', 1100),
(4, 'Phone', '2023-01-15', 800),
(5, 'Phone', '2023-02-15', 900),
(6, 'Phone', '2023-03-15', 850);EXPLAIN (COSTS OFF, VERBOSE)
SELECTsale_id,product,sale_date,amount,row_number() OVER w1 AS row_num,rank() OVER w2 AS rank_in_window
FROM sales
WINDOWw1 AS (PARTITION BY product ORDER BY sale_dateROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW),W2 AS (PARTITION BY product ORDER BY sale_dateROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING);
??執行計劃
QUERY PLAN
------------------------------------------------------------------------------------------------------WindowAggOutput: sale_id, product, sale_date, amount, (row_number() OVER w1), rank() OVER w2Window: w2 AS (PARTITION BY sales.product ORDER BY sales.sale_date ROWS UNBOUNDED PRECEDING)-> WindowAggOutput: product, sale_date, sale_id, amount, row_number() OVER w1Window: w1 AS (PARTITION BY sales.product ORDER BY sales.sale_date ROWS UNBOUNDED PRECEDING)-> SortOutput: product, sale_date, sale_id, amountSort Key: sales.product, sales.sale_date-> Seq Scan on public.salesOutput: product, sale_date, sale_id, amount
(11 rows)
??從上面的執行計劃可以發現,存在的問題是對于語義相同的窗口定義(如示例查詢中的 w1 和 w2,均定義為 PARTITION BY product ORDER BY sale_date ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW),由于 optimize_window_clauses 的去重邏輯要求 startOffset 和 endOffset 完全相等(equal(wc->startOffset, existing_wc->startOffset)),當解析階段或支持函數導致偏移量不一致時(如一個為 NULL,另一個為非 NULL),本應合并為單個 WindowAgg 節點的兩個 WindowClause 未能合并,導致查詢計劃生成了兩個獨立的 WindowAgg 節點,增加了執行開銷。
解決方案思考
問題描述
??在 PostgreSQL 中,窗口函數(如 row_number()、rank() 和 dense_rank())的執行依賴 WindowClause 定義的幀框架(frameOptions)和偏移量(startOffset 和 endOffset)。對于某些窗口函數(如 row_number()),其計算結果與幀框架的偏移量值無關,只依賴分區(partitionClause)和排序(orderClause)。
??然而,在 optimize_window_clauses 函數中,原始去重邏輯要求 startOffset 和 endOffset 嚴格相等(equal(wc->startOffset, existing_wc->startOffset)),導致語義相同的窗口定義(如示例查詢中的 w1 和 w2,均定義為 PARTITION BY product ORDER BY sale_date ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)因偏移量差異無法合并。
??例如,一個窗口的 startOffset 為 NULL,另一個為非 NULL(如 Const 節點),會生成兩個 WindowAgg 節點,增加執行開銷。這種問題在 prosupport 函數未統一設置偏移量或解析階段(transformWindowFuncCall)保留非 NULL 偏移量時尤為明顯。為解決此問題,我們提出了三種優化方案,逐步改進偏移量管理和去重邏輯。
方案一:支持函數中清空偏移量
方案思考
??問題的核心是窗口函數(如 row_number())的結果與偏移量無關,應統一為 NULL 以促進去重。一種直接方法是在 prosupport 函數(如 window_row_number_support)中設置 startOffset 和 endOffset 為 NULL,并返回優化的 frameOptions(如 FRAMEOPTION_ROWS | FRAMEOPTION_START_UNBOUNDED_PRECEDING | FRAMEOPTION_END_CURRENT_ROW)。這可確保偏移量一致,允許合并 w1 和 w2。修改示例如下:
Datum
window_row_number_support(PG_FUNCTION_ARGS)
{SupportRequestOptimizeWindowClause *req = (SupportRequestOptimizeWindowClause *) PG_GETARG_POINTER(0);if (req->type == T_SupportRequestOptimizeWindowClause){req->frameOptions = FRAMEOPTION_NONDEFAULT |FRAMEOPTION_ROWS |FRAMEOPTION_START_UNBOUNDED_PRECEDING |FRAMEOPTION_END_CURRENT_ROW;req->window_clause->startOffset = NULL;req->window_clause->endOffset = NULL;PG_RETURN_POINTER(req);}PG_RETURN_NULL();
}
??但該方法在多個支持函數中重復偏移量邏輯,維護性差。為此,我們探索集中管理方案。
方案二:在優化階段集中清空偏移量
??方案一的分散邏輯降低了代碼內聚性,為此,我們考慮將偏移量管理集中到 optimize_window_clauses,在一致性檢查通過(lc2 == NULL)且 frameOptions 需要更新(wc->frameOptions != optimizedFrameOptions)時清空偏移量。這減少了支持函數的職責,提高維護性,同時確保偏移量與優化后的 frameOptions 一致。
??方案二修改 optimize_window_clauses,在 if (lc2 == NULL && wc->frameOptions != optimizedFrameOptions) 分支內,更新 wc->frameOptions 后,檢查是否包含 FRAMEOPTION_START_OFFSET 或 FRAMEOPTION_END_OFFSET,若不包含則清空對應偏移量。prosupport 函數僅設置 frameOptions。這集中管理偏移量,促進示例查詢中 w1 和 w2 的合并,生成單個 WindowAgg 節點。但未覆蓋 wc->frameOptions == optimizedFrameOptions 的情況,需進一步優化去重邏輯。修改示例如下:
if (lc2 == NULL && wc->frameOptions != optimizedFrameOptions)
{ListCell *lc3;wc->frameOptions = optimizedFrameOptions;if (!(wc->frameOptions & FRAMEOPTION_START_OFFSET)) {wc->startOffset = NULL;}if (!(wc->frameOptions & FRAMEOPTION_END_OFFSET)) {wc->endOffset = NULL;}/* 去重邏輯... */
}
方案三:修改去重條件以忽略偏移量差異
??方案三考慮修改 optimize_window_clauses 的去重邏輯,若 frameOptions 不含 FRAMEOPTION_START_OFFSET 或 FRAMEOPTION_END_OFFSET,忽略對應偏移量的比較。prosupport 函數僅設置 frameOptions,偏移量由解析階段管理。這促進示例查詢中 w1 和 w2 的合并,減少 WindowAgg 節點。但可能導致語義錯誤(如 1 PRECEDING 與 UNBOUNDED PRECEDING 合并),需結合方案二清空偏移量以確保一致性。修改示例如下:
foreach(lc3, root->parse->windowClause)
{WindowClause *existing_wc = (WindowClause *) lfirst(lc3);if (wc != existing_wc &&equal(wc->partitionClause, existing_wc->partitionClause) &&equal(wc->orderClause, existing_wc->orderClause) &&wc->frameOptions == existing_wc->frameOptions &&(!(wc->frameOptions & FRAMEOPTION_START_OFFSET) || equal(wc->startOffset, existing_wc->startOffset)) &&(!(wc->frameOptions & FRAMEOPTION_END_OFFSET) || equal(wc->endOffset, existing_wc->endOffset))){/* 合并邏輯 */}
}
優化后執行結果
QUERY PLAN
------------------------------------------------------------------------------------------------WindowAggOutput: sale_id, product, sale_date, amount, row_number() OVER w1, rank() OVER w1Window: w1 AS (PARTITION BY sales.product ORDER BY sales.sale_date ROWS UNBOUNDED PRECEDING)-> SortOutput: product, sale_date, sale_id, amountSort Key: sales.product, sales.sale_date-> Seq Scan on public.salesOutput: product, sale_date, sale_id, amount
(8 rows)
??優化后的執行計劃將示例查詢中的兩個 WindowAgg 節點合并為一個,窗口 w1(定義為 PARTITION BY product ORDER BY sale_date ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)同時處理 row_number() 和 rank(),輸出 sale_id、product、sale_date、amount 以及兩個窗口函數的結果。
??相比原始計劃的兩個 WindowAgg 節點,新計劃通過優化 optimize_window_clauses 的去重邏輯,統一 frameOptions 和偏移量(startOffset 和 endOffset),成功合并語義相同的 WindowClause,減少了執行開銷,提高了查詢性能。







)


Illustrator2025)

框架)


第2章 python基礎2.2編程基礎)

)

