? 書寫這篇博客的目的在于實踐并記錄《人工智能導論》(Pyhton版)微課視頻版這本書的內容,便于對人工智能有更深層次的理解。
參考文獻:姜春茂.人工智能導論(Python版)微課視頻版[M]. 北京:清華大學出版社,2021.

目錄
2.1 Python的安裝--省略
2.2 編程基礎
2.2.1 數據類型與變量
1.數據類型
1)數值
2)字符串
3)布爾值
4)列表
5)轉義字符
2.變量
2.2.2?字符串和編碼
1.Python的字符串
1)字符串的創建
2)字符串的截取
3)字符串的拼接
4)字符串的統計
5)字符串的切割
6)查找字符串下標
1.Python的編碼與轉換
1)ASCII
2.2.3?列表、元組及字典
1.列表
1)創建列表
2)訪問列表中的值
3)列表的切片
4)列表的相加
5)列表的擴展
6)列表的更新
7)列表的刪除
2.元組
3.字典
1)創建字典
2)訪問字典中的值
3)字典的修改
2.1 Python的安裝--省略
2.2 編程基礎
2.2.1 數據類型與變量
1.數據類型
Python一共有5種數據類型,分別是:數值、字符串、布爾值、列表和轉義字符。(該書只列舉了這5種類型,可能是因為面對初學者)
1)數值
只能存放一個值,定義之后不可更改,可以直接訪問。
Python的數值類型又分為整型(int)、長整型(long)、浮點型(float)、復數(complex)。
整型:整數,包括正整數與負整數,也可以用十六進制、十進制、八進制表示整數。
print(10)
print(oct(10)) # Octal:八進制
print(hex(10)) # Hexadecimal:十六進制
其中,八進制中的個位數表示8的0次方,也就是1;八進制中的十位數表示8的1次方也就是8。10是由1個8的1次方和2個8的0次方組成,因為其結果為0o12,其中“0o”這一前綴表示12是一個八進制的數字。
浮點型:小數,對于很大和很小的浮點數可以用科學計數法表示
例如,1.5e3是科學計數法表示1.5×10的三次方,既是1.5e3也是1500.0(浮點保留一位小數)
復數:數學中的復數,由實數和虛數兩部分組成。與數學復數不同的是:虛數部分用j表示,一般形式為x+yj,其中x是復數的實部,y是復數的虛部,x和y都是實數。
# 復數
c1 = 3 + 4j
print(c1) # 輸出: (3+4j)
print(c1.real) # 輸出實部: 3.0
print(c1.imag) # 輸出虛部: 4.0# 復數運算
c2 = 1 - 2j
print(c1 + c2) # 輸出: (4+2j)
print(c1 * c2) # 輸出: (11-2j)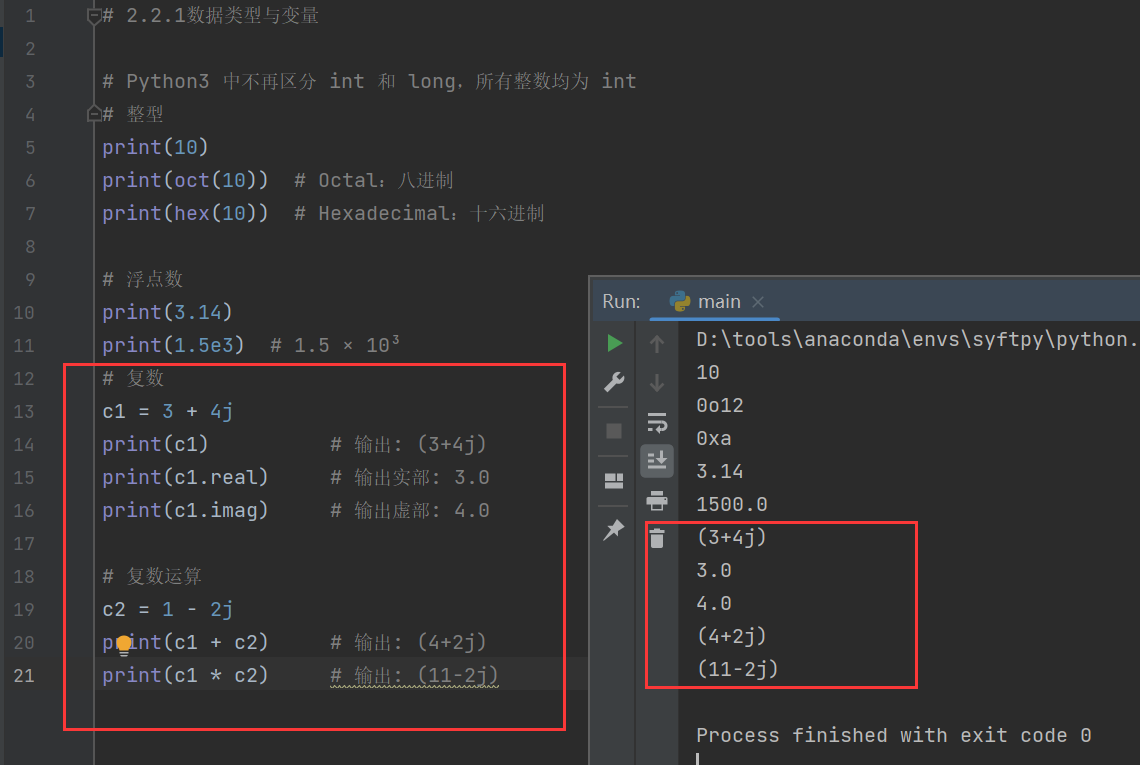
其中c1*c2的過程為:(3+4j)*(1-2j)=3*1+3*(-2j)+4j*1+4j*(-2j)=3-6j+4j-8(j*j)=8+3-2j=11-2j
備注:j*j=-1
2)字符串
一個有序的字符的集合,用于存儲和表示基本的文本信息,指的是單引號或雙引號括起來的文本部分。
s1 = 'Hello Python!'
s2 = '人工智能'
print(s1+s2)
print(s1[0])
print(s2[1])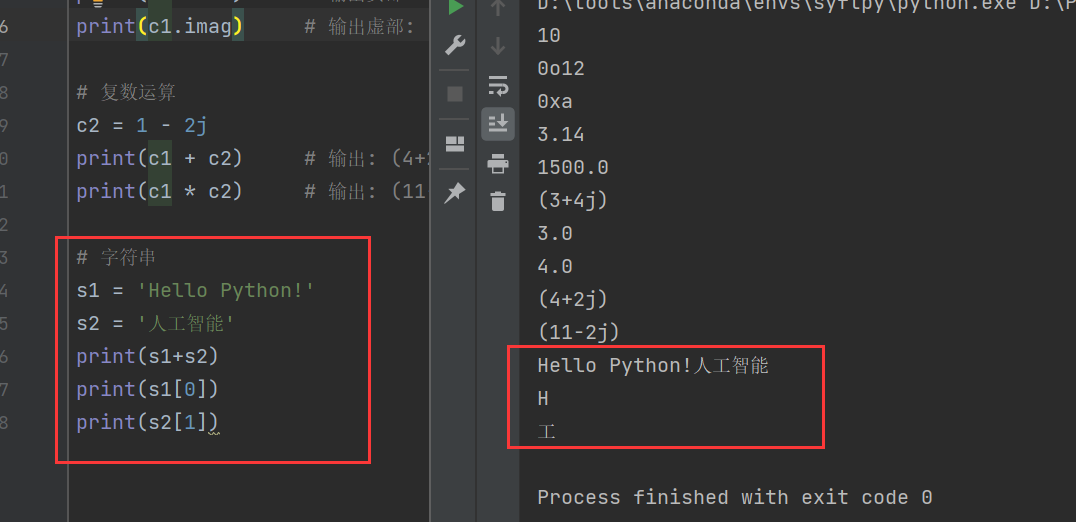
3)布爾值
布爾值只為True或False(首字母大寫),也就是對或錯。一些公式的計算結果也是布爾值
# 布爾值
print(True)
print(False)
print(3 > 1)
print(3 > 9)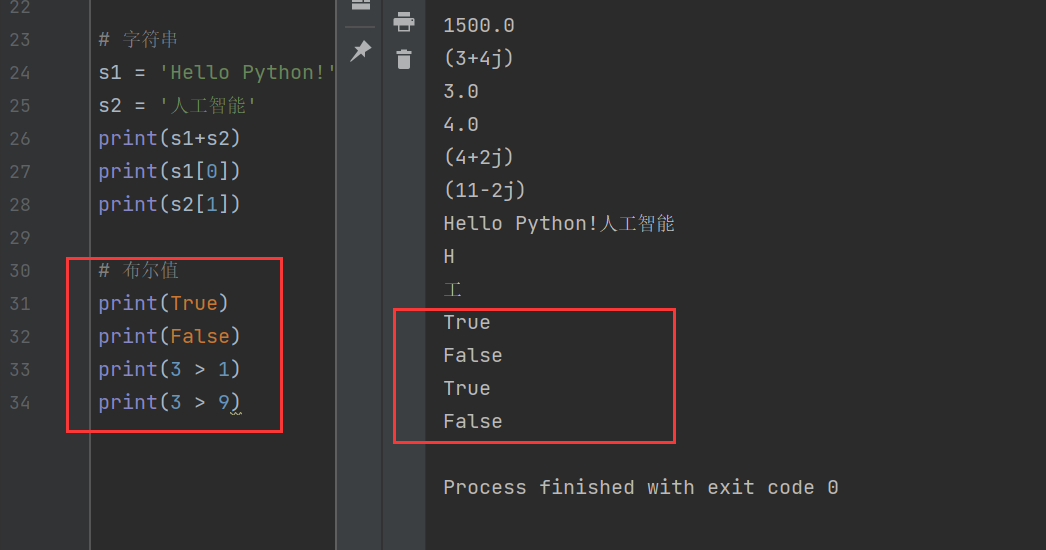
例如第34行代碼中,顯然3小于9,所以返回結果就是False。
同時,布爾值也可以使用與運算(and)、或運算(or)和非運算(not)進行運算,相當于邏輯運算。
print(True and True)
print(True and True and False)
print(False or True)
print(False or False)
print(not False)
print(not True)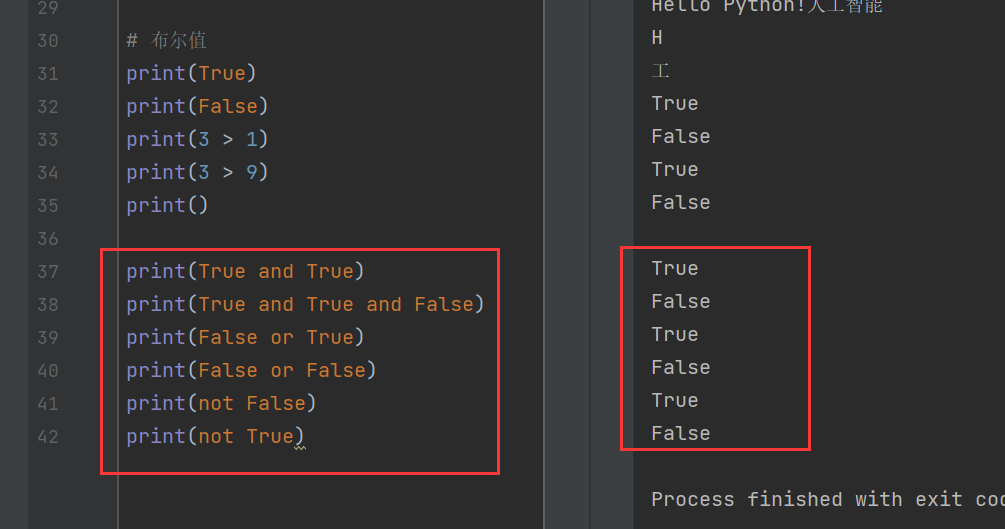
其中,and表示左右兩個公式都為真時才為真。那么真 and 假(True and False)有一個為假,所以返回值為假(False);
or表示或者,也就是左右兩個公式一個為真即為真。例如,假或真(False or True)只要有一個為真,其返回值就為真(True)。
4)列表
列表是Python中內置有序、可變的序列,可以存儲大多數集合類的數據結構,支持字符、數字、字符串,甚至可以包括列表。用[ ]標識,所有元素均放在方括號內部。
通過下面的代碼演示列表的有序性和可變性。
list = ["蘋果", "香蕉", "橙子"]
print(list)
list[1] = "藍莓"
print(list)
list.append("葡萄")
print(list)
list.remove("橙子")
print(list)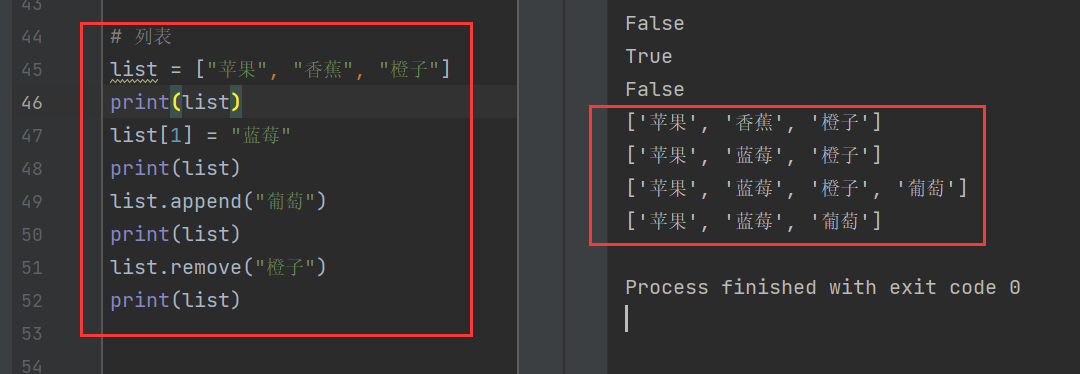
5)轉義字符
轉義字符是幫助機器理解一些存在歧義內容的字符。
例如,字符串s的內容為let's go!
s = 'let's go!'
在Python中會將s = 'let's go!' 標紅和加粗的單引號看作一對,這顯然發生了歧義,因此可以用s = 'let\'s go!' 來表示,“\”表示后面的引號只是一個普通字符。
| 轉義字符 | 描述 | 轉義字符 | 描述 |
| \ | 續行符 | \000 | 空 |
| \\ | 反斜杠符號 | \f | 換頁 |
| \' | 單引號 | \v | 縱向制表符 |
| \" | 雙引號 | \t | 橫向制表符 |
| \a | 響鈴 | \r | 回車 |
| \b | 退格 | \e | 轉義 |
| \n | 換行 |
接下來舉例說明不加轉義字符和加了轉義字符的代碼結果:
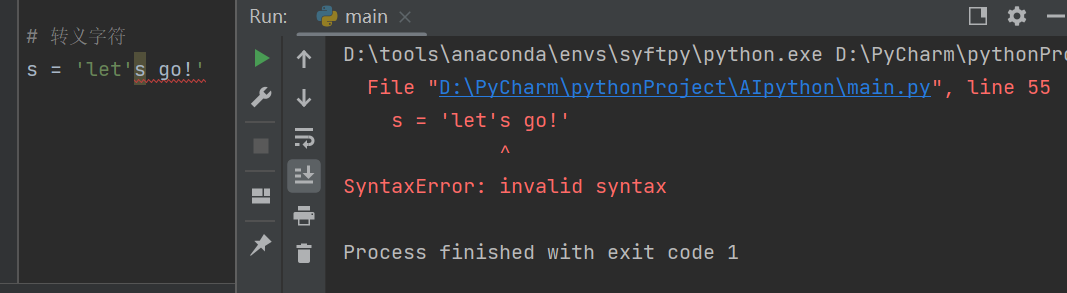
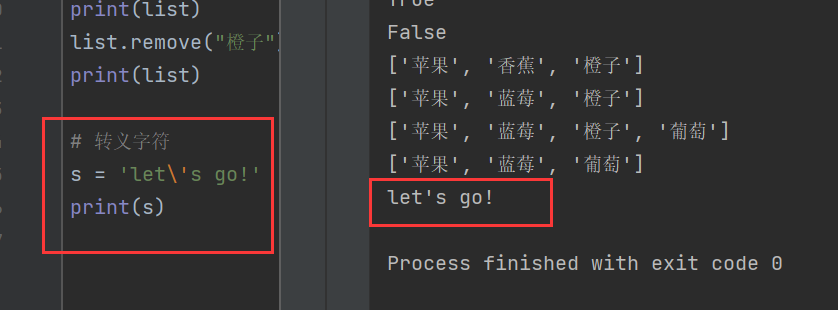
顯然,不加轉義字符就會出現錯誤。
2.變量
變量是存儲在內存中的值,創建變量時會在內存中開辟一個空間。
變量不僅可以是數字,還可以是任意數據類型。
變量名必須為大小寫英文字母、數字、下劃線的組合,且不能由數字開頭。
Python中的變量賦值不需要類型聲明(這一點與c語言不一樣),在變量使用前必須賦值,賦值后變量才會被創建。使用“=”給變量賦值,Python中可以同時對多個變量賦值。
變量中的賦值:
number = 125
distance = 123.4
city = "Beijing"
print(number)
print(distance)
print(city)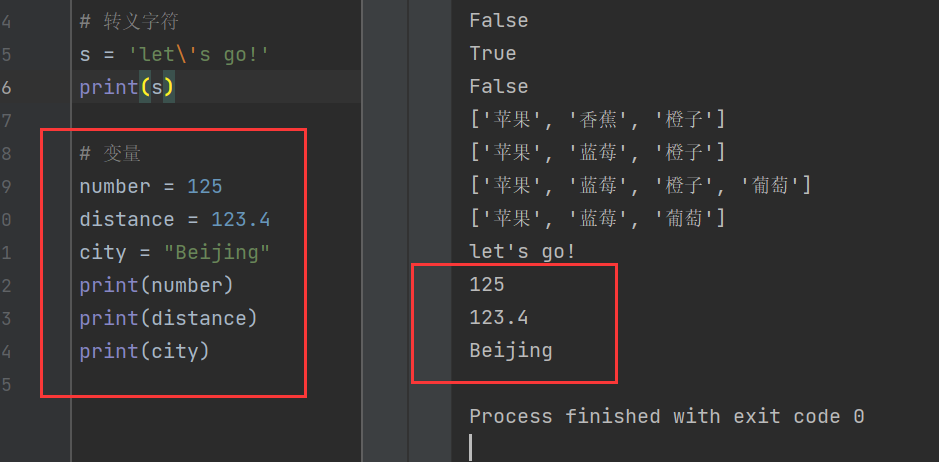
多個變量賦值:
a = b = c = 1
print(a,b,c)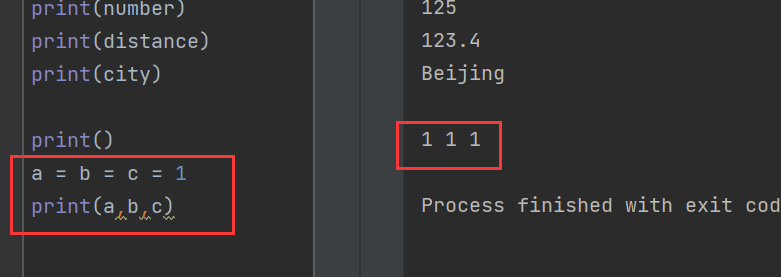
2.2.2?字符串和編碼
1.Python的字符串
1)字符串的創建
在2.2.1中已經簡單介紹了字符串,使用單引號(‘’)或雙引號(“”)創建字符串,字符串的創建只要為變量分配一個值即可
str1 = 'Where are you from?'
str2 = "你來自哪里?"
print(str1)
print(str2)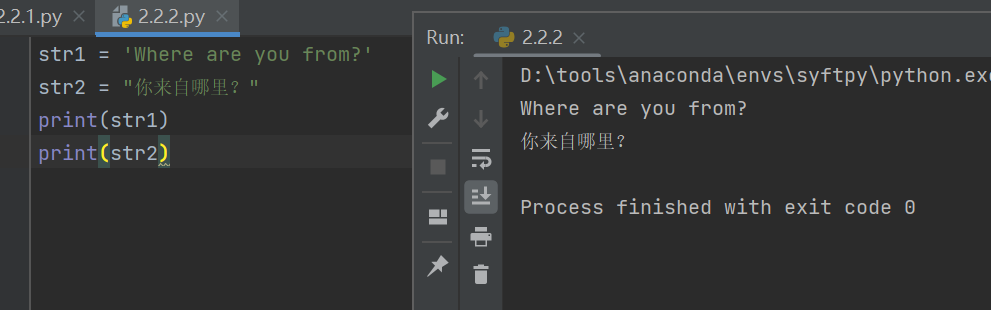
可以看到字符串是由引號所包裹而成的,那么如果存在多個引號,就需要特殊處理,其中錯誤例子已經在5)轉義字符中提到了。
有以下兩個解決方法,分別是使用不同引號和使用轉義字符。
使用不同引號:
str_name1 = "I'm Joy"
print(str_name1)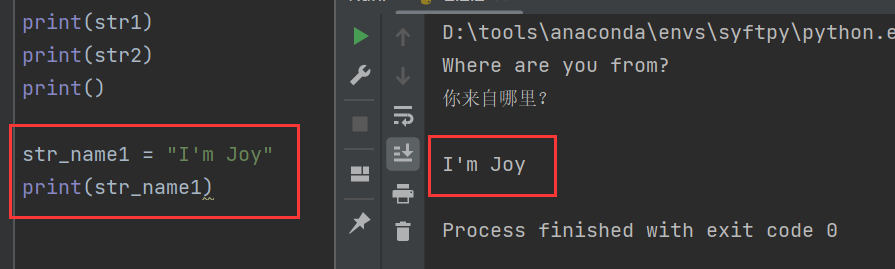
使用轉義字符:
PS:這里感覺教材寫錯了,教材中寫的是str3 = 'he said:" I\\'m Joy"'
str3 = 'he said:" I\'m Joy"'
print(str3)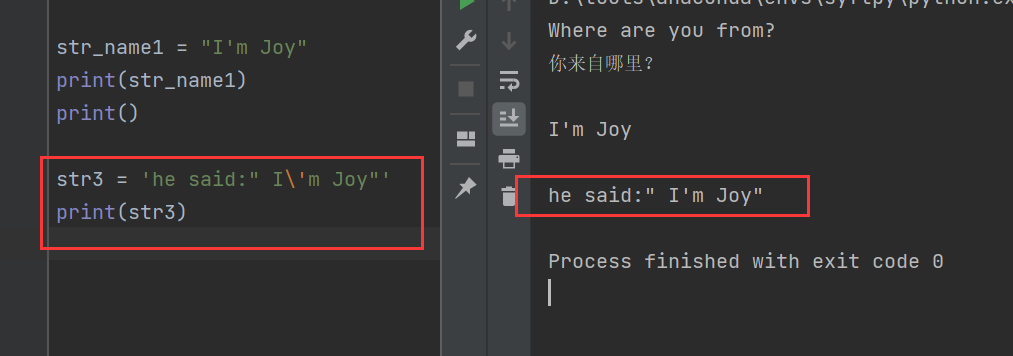
其中"\'"表示就是一個單引號,而不是創建一個字符串的意思。
2)字符串的截取
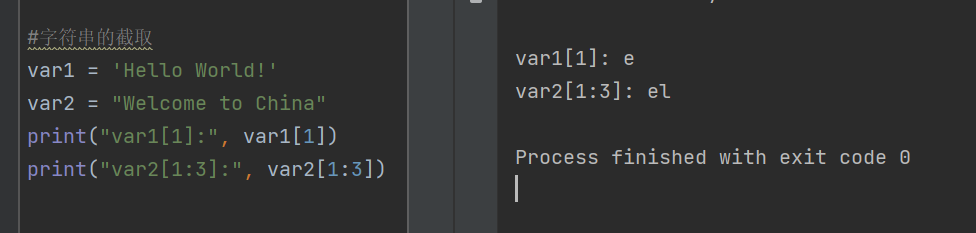
在Python中,使用方括號來截取字符串,遵循左閉右開的原則,字符串的索引值從0開始。
例如:var = "Python!",那么var[0]就是P,var[6]就是!,var[1,3]就是yt
var1 = 'Hello World!'
var2 = "Welcome to China"
print("var1[1]:", var1[1])
print("var2[1:3]:", var2[1:3])
指定元素截取方式:
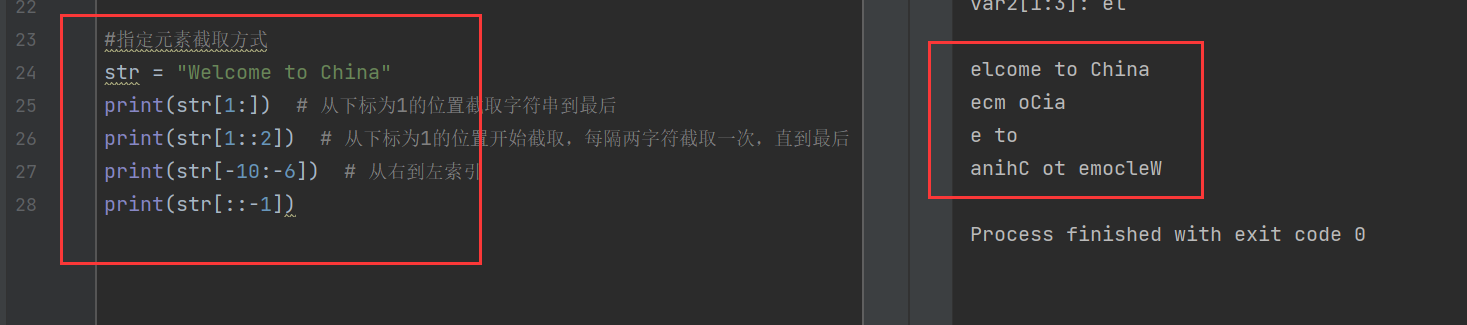
其中,str[1:]是從下標為1開始(e),一直到最后一個字符
str[1::2]是指從下標為1開始(e),每隔兩個字符(算開始字符)截取一次,一直到最后一個字符
帶負號的索引是指從右到左的索引,最右邊的字符的索引是-1,那么-6就是“C”前面的空格,-10就是“welcome”的最后一個“e”,所以從-10到-6應該是“e to”(左閉右開,不包括str[-6])
而str[::-1]則是翻轉,也就是前后置換,也就是翻轉
3)字符串的拼接
字符串有3種拼接方式,分別是:乘法重疊、加法拼接和使用join拼接
join()用于連接字符串數組,將序列中的元素以指定字符連接成新的字符串
str1 = "Hello" * 3
str2 = 'Hello' + 'World'
a = 'world'
str3 = ' '.join(a)
print(str1)
print(str2)
print(str3)
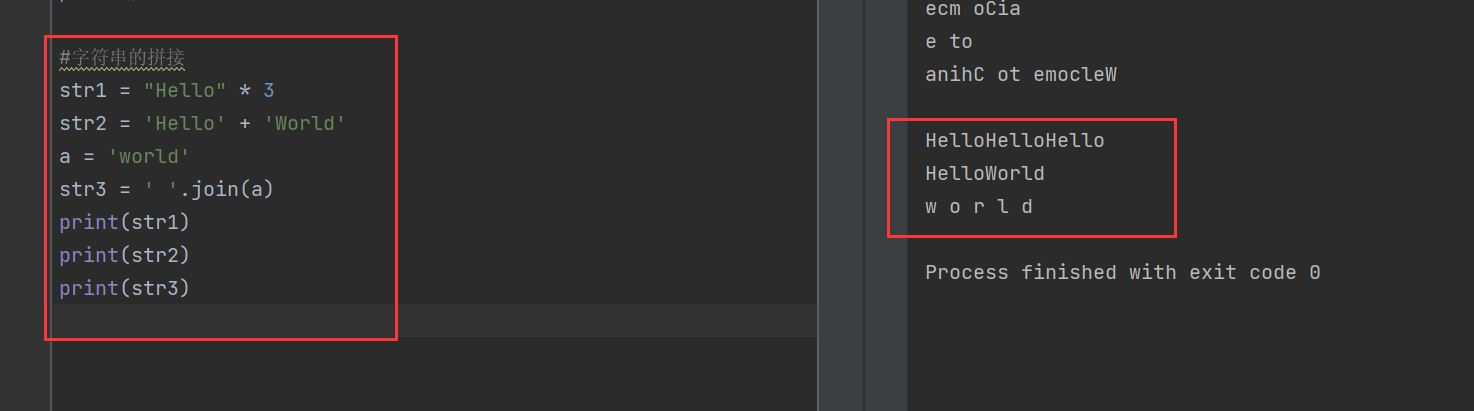
可以看到str1和str2都好理解,而str3使用了join函數,也就是讓字符串a中每兩個字符之間都用空格隔開
4)字符串的統計
在Python中,使用len()函數計算字符串的長度,空格也會被計算在內
str = "Hello World"
print(len(str))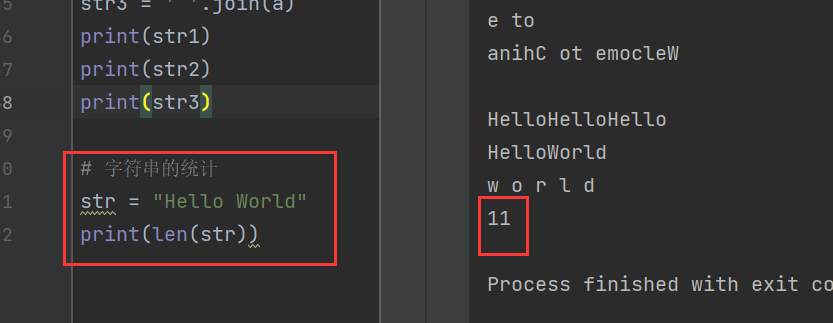
其中,Hello有5個字符,World也有5個,算上一個空格一共就是11個
5)字符串的切割
使用split()對字符串進行分割,有多種分割方式
str = "Aspring people have become a success"
print(str.split(" "))
print(str.split("e"))
print(str.split(" ", 2))
第一行是遇到空格就分割,顯然字符串中有5個空格,因此會分割成6個字符串
第二行是遇到e就分割,字符串中一共有6個e,因此會分割成7個字符串
Aspring people have become a success
第三行則是遇到空格就分割,最大分割次數為2(前兩行沒有寫分割次數的參數,因此就是無限次分割),因此會分割成3個字符串
6)查找字符串下標
使用find()函數查找字符串的下標位置,如果找不到則返回-1
find_str = "Aspiring people have become a success"
s1 = "become a success"
print(find_str.find(s1))
print(find_str.find("people"))
print(find_str.find('e', 11))
print(find_str.find('k'))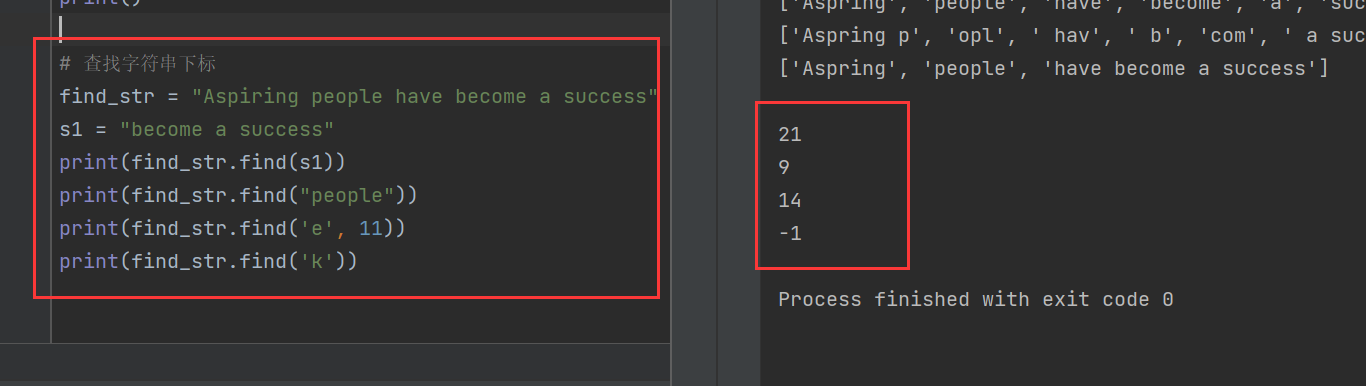
其中,Aspiring一共有7個字符,加上空格就是8個,之后就是people,因為索引從0開始計數,所以people的起始索引位置就是9,其他問題同理
第三個print不是很好理解,這里給出find()函數的說明
str.find(sub[, start[, end]])
- ?str?:待搜索的原字符串。
- ?sub?:必選參數,需要查找的子串。
- ?start?/?end?:可選參數,限定搜索范圍的起始和結束位置索引(左閉右開區間)
因此,print(find_str.find('e', 11))的意思是,從索引為11的位置開始找“e”字符,索引為11的字符是people的o,那么下一個“e”就是people的最后一個“e”,其索引為14.
1.Python的編碼與轉換
常見的編碼方式有以下5種
| 編碼 | 制定時間 | 作用 | 所占字符數 |
| ASCII | 1967年 | 表示英語及西歐語言 | 8/1B |
| GB 2312 | 1980年 | 國家簡體中文字符集,兼容ASCII | 2B |
| GBK | 1995年 | GB 2312的擴展字符集,支持繁體字,兼容GB 2312 | 2B |
| Unicode | 1991年 | 國際標準組織統一標準字符集 | 2B |
| UTF-8 | 1992年 | 不定長編碼 | 1~3B |
在7年計算機的求學過程中,個人認為ASCII碼的應用范圍更廣,因此只說明ASCII。
1)ASCII
ASCII的常見規則:
- 數字比字母小,如'9'<'A';
- 數字按從大到小順序遞增,如'8'<'9'
- 字母按從A到Z的大小順序遞增,如'B'<'H'
- 同一個字母的小寫字母比大寫字母大,如'e'>'E'
2.2.3?列表、元組及字典
1.列表
1)創建列表
使用[]創建列表, 用逗號分割不同數據項,列表的索引從0開始
list1 = ['KangKang', 18, 'Boy', 'Music']
list2 = [8, 9, 0, 2, 3, 1]
list3 = ['a', 1, 2, 3, 'b']
print(list1)
print(list2)
print(list3)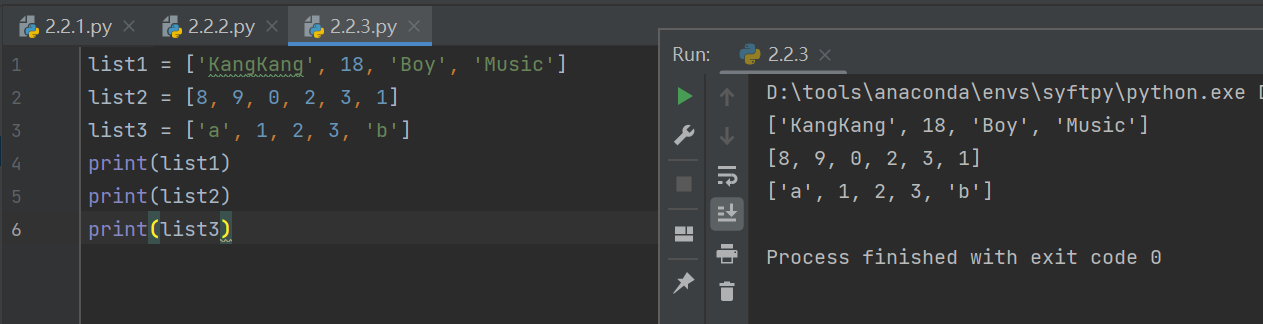
可以看到,數值類型的數據項不需要用引號,但是字符串需要
2)訪問列表中的值
可以把列表看成字符串,每一個數據項就相當于字符串中的一個字符。
list1 = ['KangKang', 18, 'Boy', 'Music']
print(list1[2])
print(list1[-1])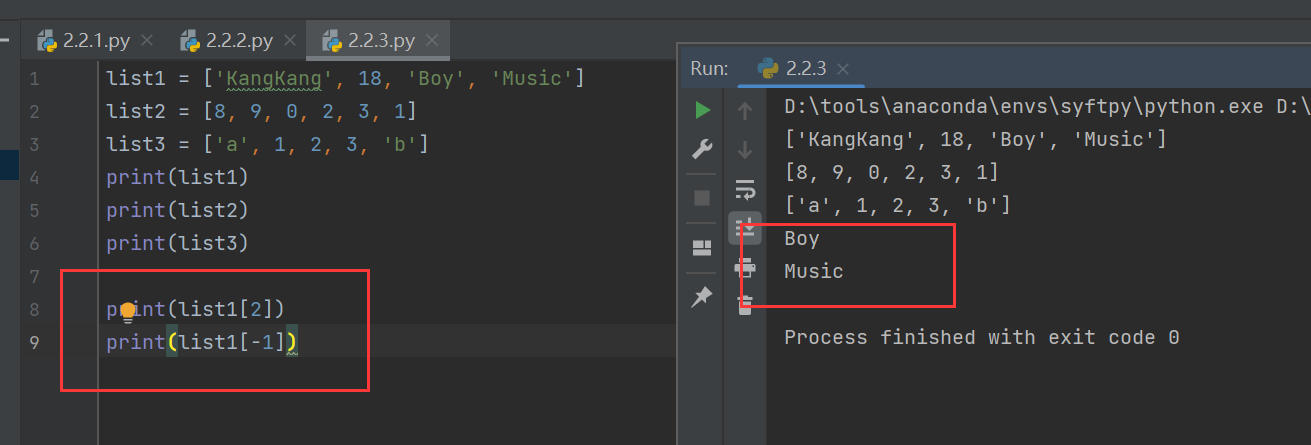 其中,-1代表從右到左的索引,因為最右邊的數據項是Music,就是-1對應著Music
其中,-1代表從右到左的索引,因為最右邊的數據項是Music,就是-1對應著Music
當索引超出位置時,程序就會報錯,例如:

3)列表的切片
切片可以實現一次性獲取多個元素,與字符串切割類似,但是列表不需要split()函數。操作規則為:[開始位置:結束位置:間隔],其中,間隔可以不寫,默認為1.同樣遵循左閉右開的原則
list1 = ['KangKang', 18, 'Boy', 'Music']
print(list1[:2])
print(list1[-2:])
print(list1[::2])
print(list1[:])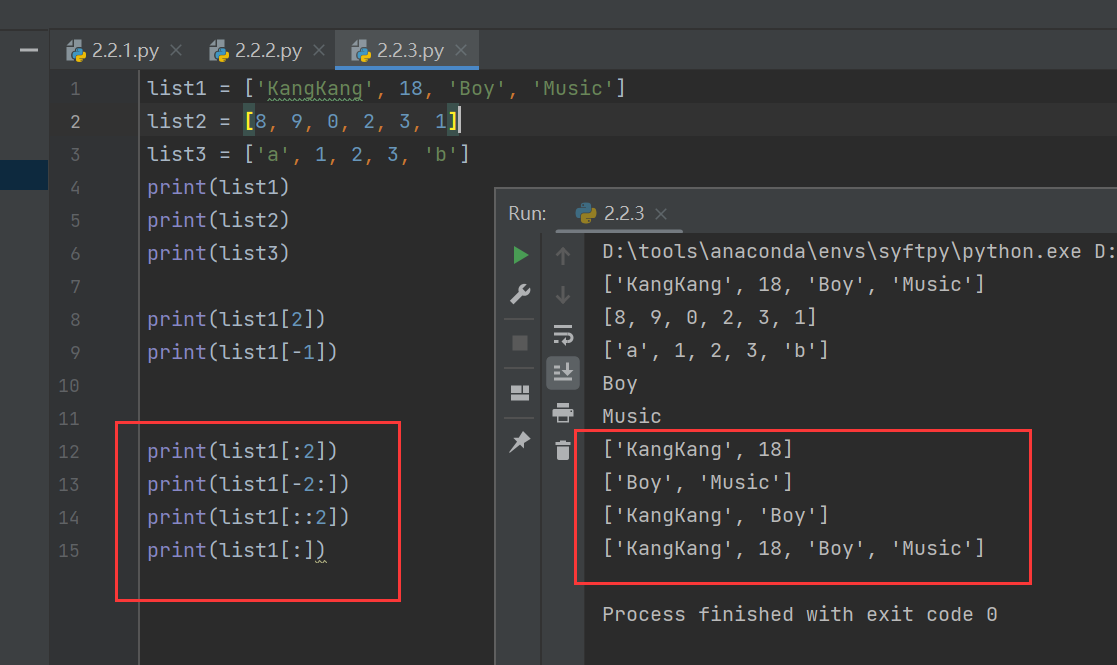
其中第12行的“2”表示結束位置,也就是只輸出索引為0和1的數據項
第13行的“-2”表示從右到左的索引位置,-2代表的數據項就是‘Boy’,也就是取出最后兩個元素,所以應該輸出'Boy', 'Music'
第14行的“2”代表間隔,每兩個數據項輸出一個數據項
第15行什么參數都沒有寫,也就是取出全部元素
4)列表的相加
用“+”即可實現列表的相加,其中,列表的相加并沒有改變原有列表的元素,兩個列表仍為最開始定義的值
# 列表的相加
list1 = ['KangKang', 18, 'Boy', 'Music']
list2 = ["186cm", "70kg"]
list3 = list1 + list2
print(list1)
print(list2)
print(list3)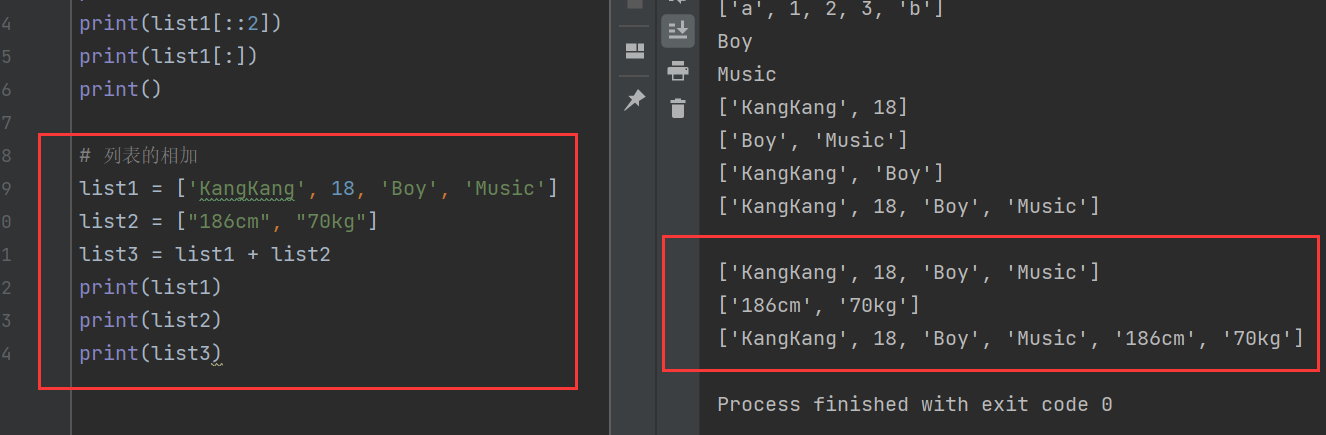
5)列表的擴展
使用extend()函數對列表進行擴展
list1 = ['KangKang', 18, 'Boy', 'Music']
list2 = ["186cm", "70kg"]
list1.extend(list2)
print(list1)
print(list2)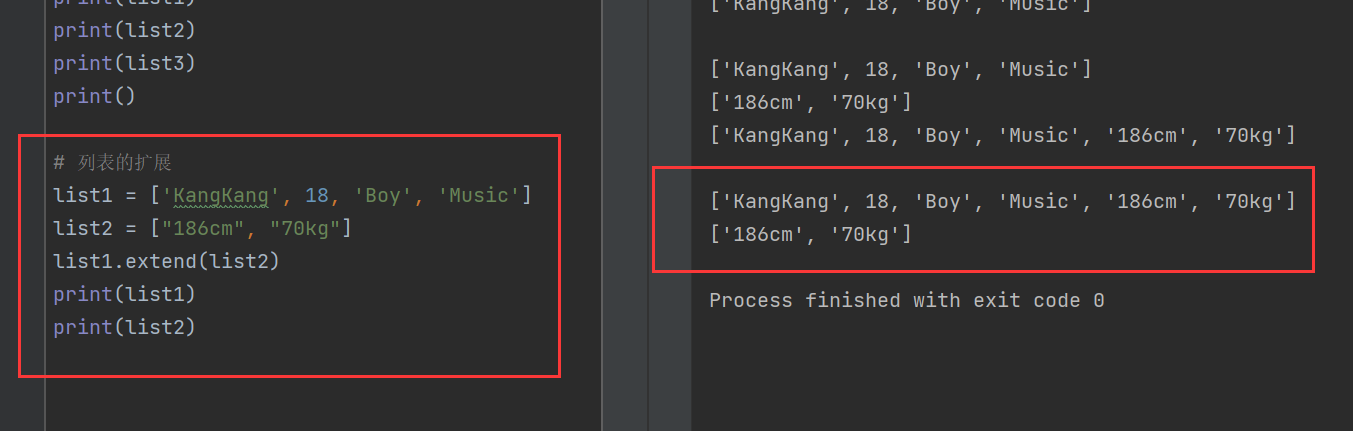 可以看到,extend()使list2的兩個數據項成為了list1中的第五個和第六個數據項。
可以看到,extend()使list2的兩個數據項成為了list1中的第五個和第六個數據項。
但是為什么不會讓列表成為第五個數據項呢?也就是['KangKang', 18, 'Boy', 'Music', ['186cm', '70kg']]
來看看extend()函數的定義:extend()?方法用于將一個可迭代對象(如列表、元組、字符串等)中的元素逐個添加到列表的末尾。添加后,列表的長度會增加可迭代對象中元素的數量。
也就是說,會把list2中的每個數據項而非列表添加在末尾。那么,怎么將列表添加在末尾呢,那就需要append()函數。
以下是append()函數的定義:append()?方法用于在列表的末尾添加一個元素。這個元素可以是任意類型的對象,如數字、字符串、列表等。添加后,列表的長度會增加1。
也就是說,append()會把加入的內容認為是一個整體,而不是像extend()那樣將元素進行分解。接下來,將append替換extend來看一下結果吧。
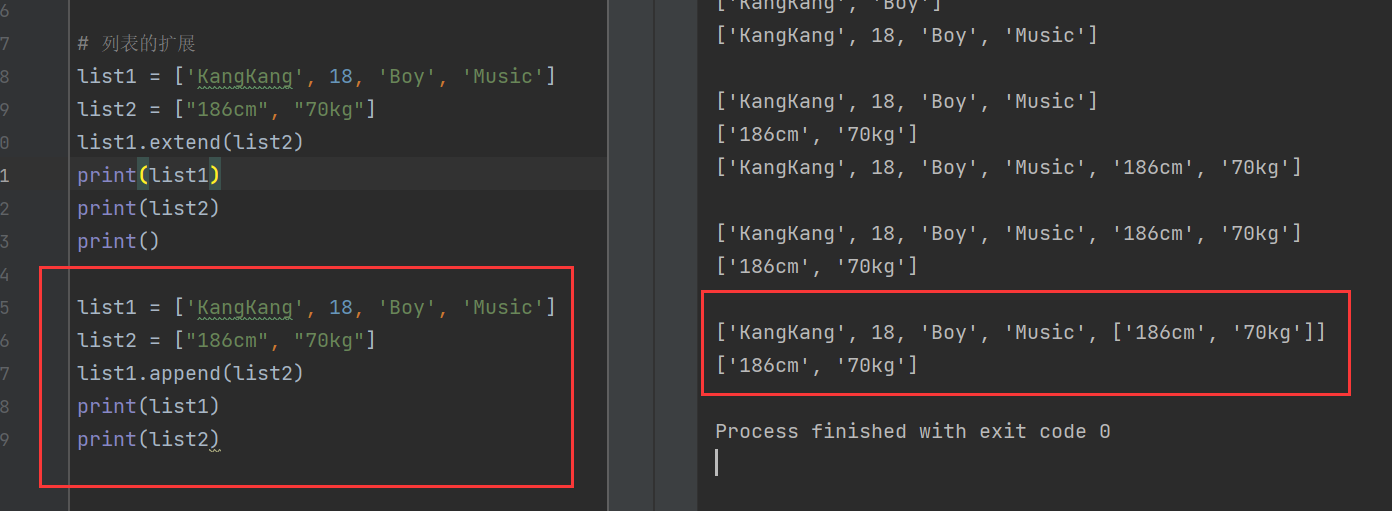
顯然,append()函數直接把列表["186cm", "70kg"]加在了尾端。
6)列表的更新
如果直接修改列表中對應索引的數據項,列表中原數據項的內容就會被替換掉
list1 = ['KangKang', 18, 'Boy', 'Music']
list1[0] = "186cm"
list1[1] = "70kg"
print(list1)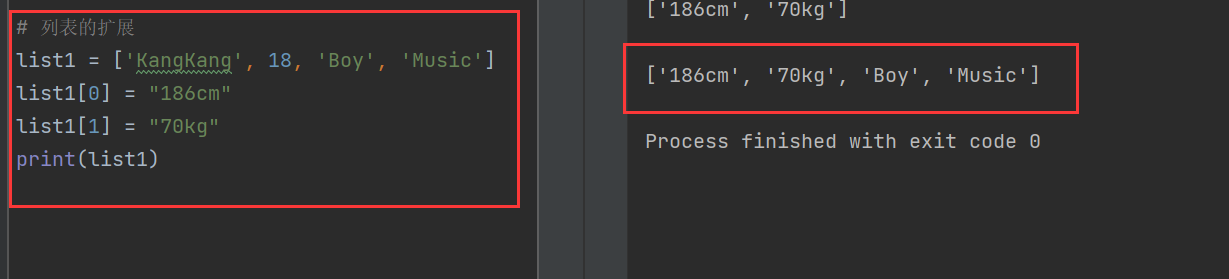
如果不想替換掉原有元素,可以用append()、insert()來添加新元素
list1 = ['KangKang', 18, 'Boy', 'Music']
list1.append("186cm")
print(list1)
list1.insert(1, "70kg")
print(list1)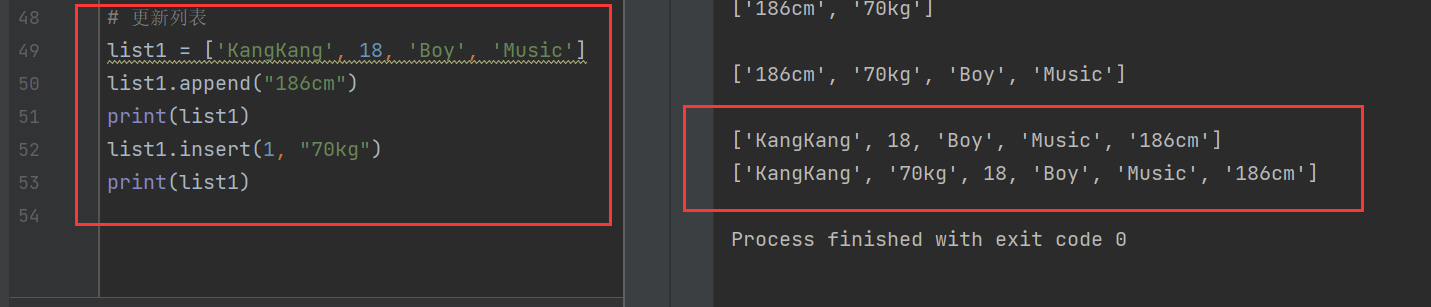
append()函數是將元素加在末尾,insert是將元素插入對應的索引位置
7)列表的刪除
有四種方法可以對列表進行刪除,分別是:
- 使用
pop()方法:需要刪除特定索引處的元素,并且需要在刪除后使用該元素的值時。 - 使用
del語句:需要刪除特定索引的元素,或者完全清空列表時。 - 使用
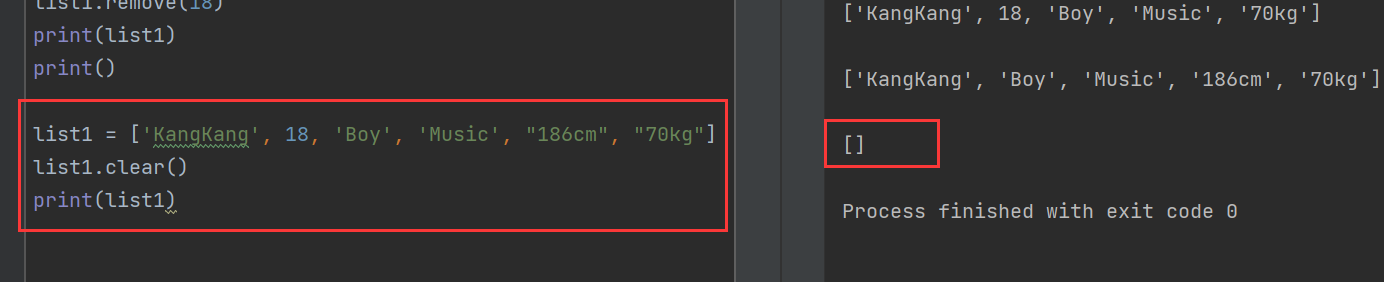
remove()方法:需要刪除列表中的特定元素名稱而非索引值。 - 使用clear()方法清空列表,將所有元素都刪除,但是仍存在空列表
pop():
list1 = ['KangKang', 18, 'Boy', 'Music', "186cm", "70kg"]
pop_item = list1.pop(2)
print(list1)
print(pop_item)
list1.pop()
print(list1)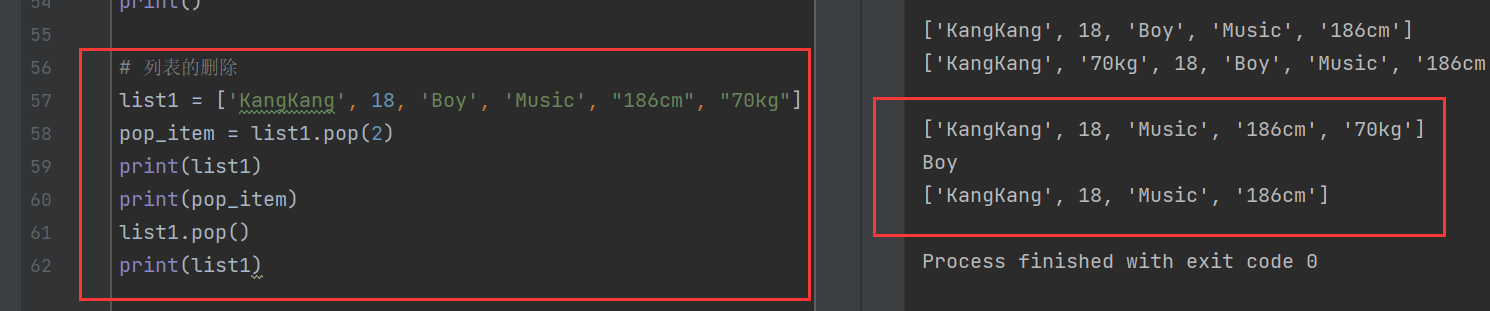
del():

remove():

clear():
2.元組
元組和列表類似,但是元組一旦初始化就不能修改,并且元組用小括號()表示,列表使用方括號[]表示
首先,先介紹一下列表、元組和字典的區別
- 列表(List)?:可變類型,支持增刪改元素
- ?元組(Tuple)?:不可變類型,創建后無法修改元素
- ?字典(Dict)?:可變類型,可增刪改鍵值對,但鍵必須為不可變類型
tup1 = ('KangKang', 18, 'Boy', 'Music')
print(tup1)
tup2 = ("186cm", "70kg")
print(tup2)
tup3 = tup1 + tup2
print(tup3)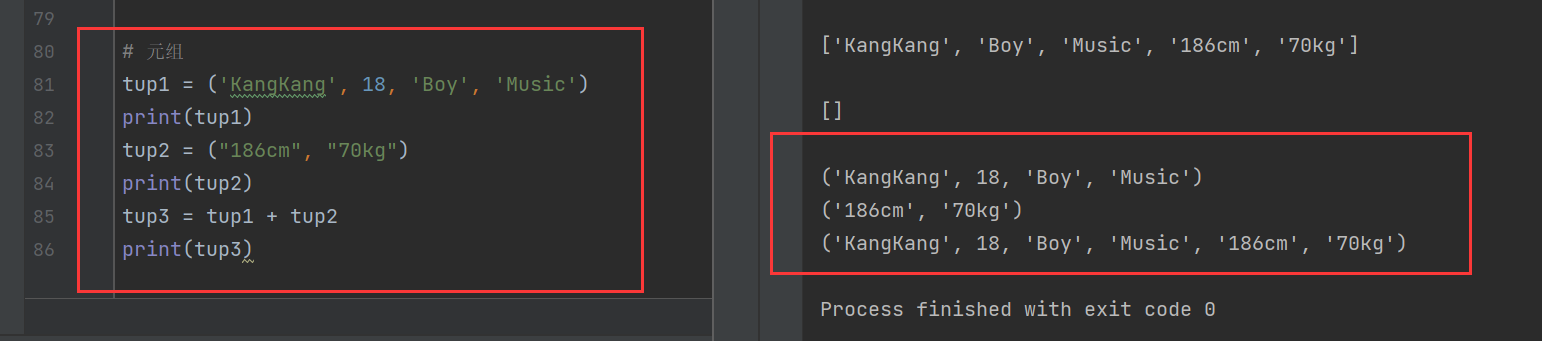
3.字典
字典包括兩部分,一部分是鍵(key),另一部分是值(value)。其中,鍵是唯一的屬性,如果重復了多個同樣的鍵,最后出現的鍵會替換掉前邊的,但是值是不唯一的。
1)創建字典
有兩種創建字典的方法:1.使用花括號{};2.使用dict()函數創建,字典的鍵與值使用冒號:分隔開,鍵與鍵使用逗號,分隔開。
除了上述方法初始化字典,還可以用fromkeys()對字典初始化,并用第二個參數作為字典的值
dict1 = {'a':'an', 'b':'be', 'c':'can'}
dict2 = dict()
dict3 = dict(d='defind')
dict4 = dict().fromkeys(['name1', 'name2'], 'KangKang')
print(dict1)
print(dict2)
print(dict3)
print(dict4)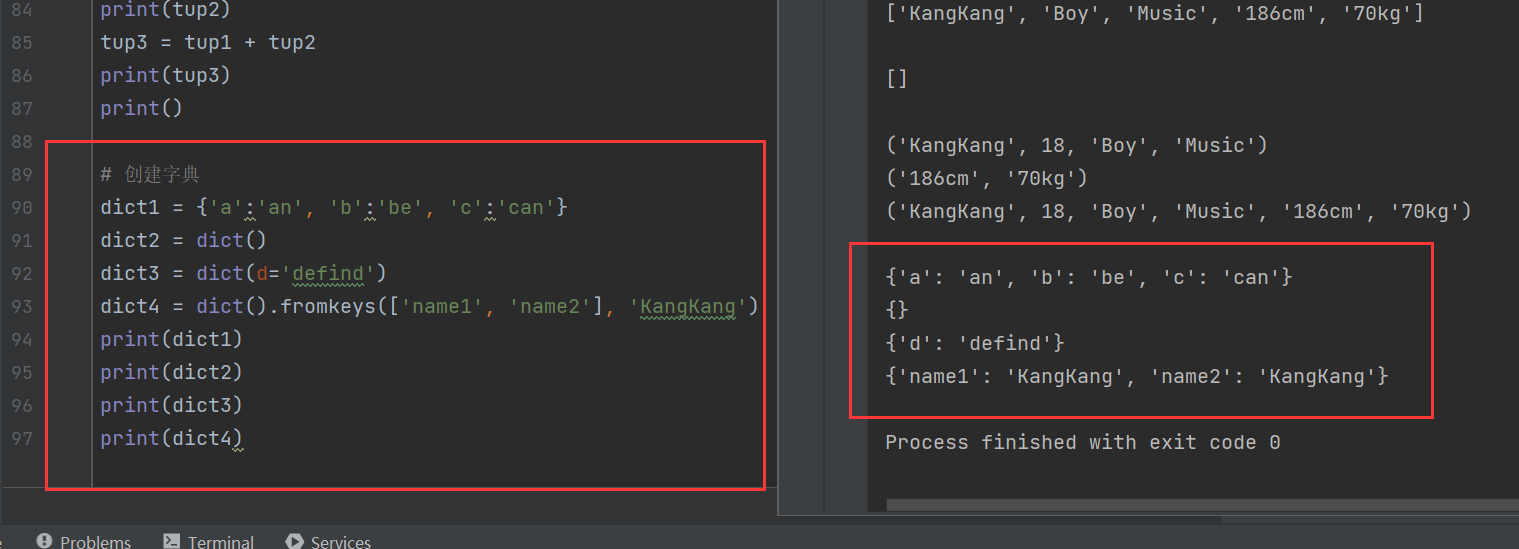
2)訪問字典中的值
字典中通過鍵來尋找值,可以用[]和get()函數的方法來獲取對應的值
在這里博主發現,材料中將年齡18也加上了單引號,但是之前的學習中數值類型的字符串可以不加引號,因此這個代碼中沒有加引號
dict1 = {'Name':'KangKang', 'Age':18, 'height':"186cm", 'weight':'70kg'}
print(dict1)
print(dict1['Age'])
print(dict1.get('Name'))
print(dict1.get('gender'))
3)字典的修改
可以直接通過鍵來修改值,也可以用update在字典尾端加入鍵值
dict1 = {'Name':'KangKang', 'Age':18, 'height':"186cm", 'weight':'70kg'}
dict1['Age'] = 20
print(dict1)
dict1.update({'gender': 'male', 'jobs': 'programmer'})
print(dict1)
del dict1['height']
print(dict1)
dict1.pop('Name')
print(dict1)
字典的其他使用方法如下所示:
| 方法 | 說明 | 方法 | 說明 |
| cmp(dict1, dict2) | 比較兩個字典元素 | len(dict) | 計算字典元素個數,即鍵的總數 |
| dict.clear() | 刪除字典內所有元素 | dict.copy() | 返回一個字典的淺復制 |
| dict.items() | 以列表返回可遍歷的(鍵,值)元組數組 | dict.keys() | 以列表返回一個字典所有的鍵 |
| dict.values() | 以列表返回字典中的所有值 | popitem() | 隨機返回并刪除字典中的一對鍵和值 |
| dict.has_key(key) | 如果鍵在字典dict中則返回True,否則返回False | dict.setdefault(key,default=None) | 和get()方法類似,但如果鍵不存在于字典中,將會添加鍵并將值設為默認值 |

)






)

)








)