
在 Doris 的數據存儲與查詢體系里,Compaction 是保障查詢效率、優化存儲結構的關鍵機制。如果你好奇 Doris 如何在高頻寫入后仍能高效響應查詢,或是想解決數據版本膨脹帶來的性能問題,這篇關于 Compaction 的深度解析值得收藏 👇
一、為什么需要 Compaction?
Doris 采用類 LSM - Tree 的存儲結構,每次數據導入會生成新的 Rowset(可理解為數據版本片段 ),每個rowset由0到n個sgement組成。segment實際對應這個磁盤上的一個文件。單個sgement文件是有序的。
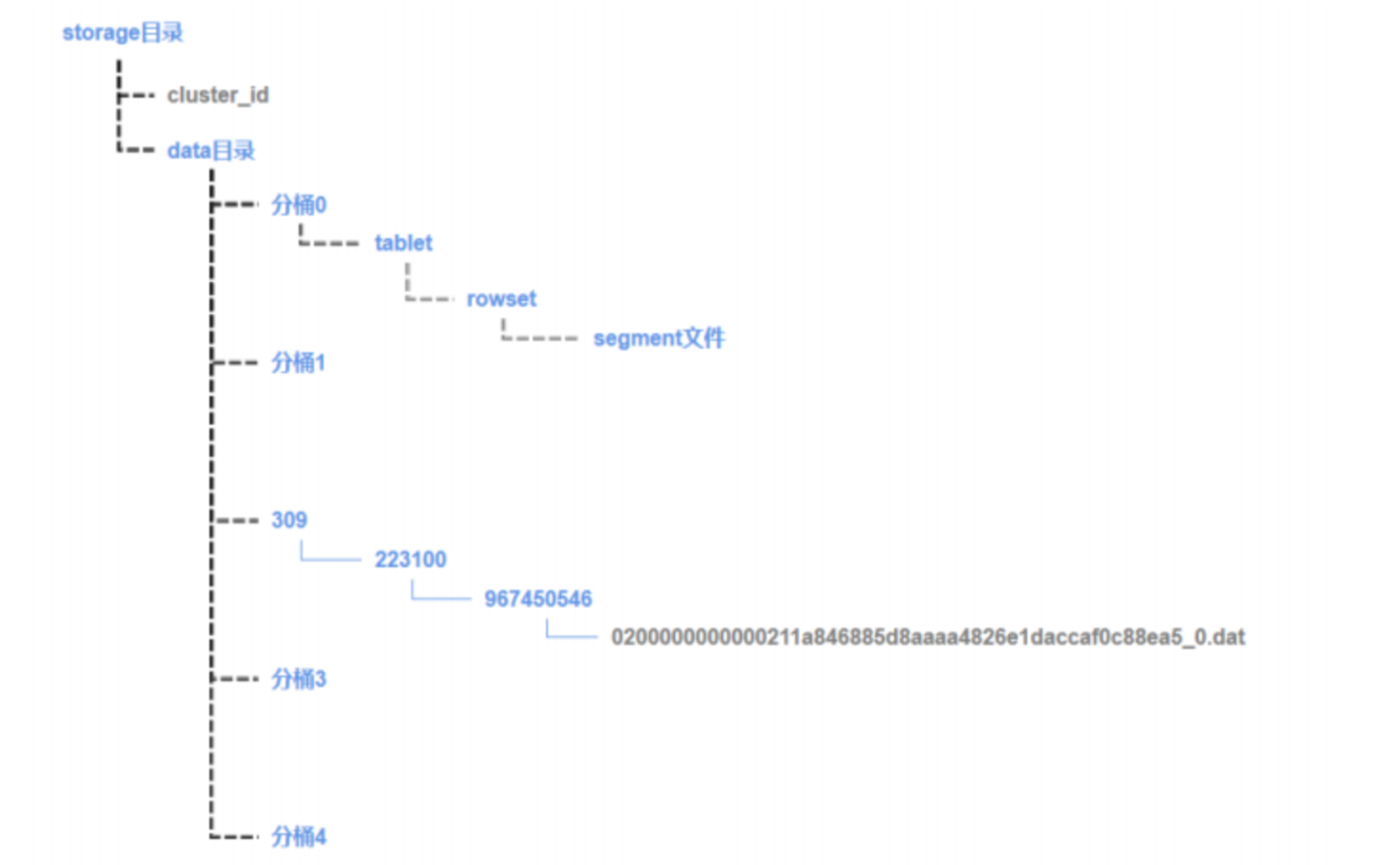
隨著導入操作增多,Rowset 數量不斷累積,會引發兩大核心問題:
(一)查詢效率下降
查詢時,Doris 需要對多個 Rowset 執行 “多路歸并” 操作來整合結果。Rowset 數量越多,歸并的路數就越多,查詢耗時呈幾何級增長。例如,若一個查詢需要合并 10 個 Rowset,歸并過程就像同時梳理 10 條雜亂的線,難度和耗時遠大于合并 2 - 3 個 Rowset。
(二)存儲成本上升
大量零散的 Rowset 會占用更多磁盤空間,還可能存儲重疊和無效數據。比如多次導入同一范圍的數據,會生成多個有重疊的 Rowset,不僅浪費存儲,還會讓查詢時的歸并邏輯更復雜。
Compaction 的核心目標
- 減少查詢歸并成本:將多個小 Rowset 合并為大 Rowset,降低查詢時的合并路數。
- 消除無效數據:將標記刪除(Delete)、更新(Update)的數據真正清理,避免查詢時的無效掃描。
- 優化存儲:在 Aggregate 模型中預聚合相同 Key 的數據,在 Unique 模型中保留最新版本,進一步提升查詢效率。
compaction的粒度是tablet,下圖是一個tablet compaction過程的示意圖
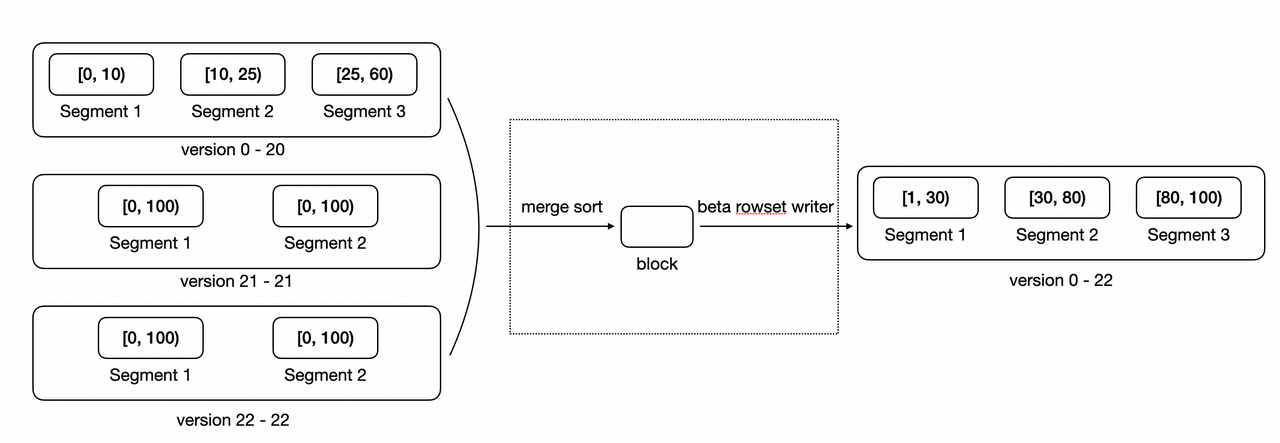
二、Compaction 關鍵概念解析
1. Compaction Score:優先級調度指標
Compaction Score 是 Doris 判斷 Tablet 做Compaction優先級的核心指標,值越高,優先級越高。
(一)本質
反映查詢時 Rowset 參與 “多路歸并” 的路數。路數越多,查詢效率越低,越需要優先compaction。
(二)計算邏輯
遍歷 Tablet 的 Rowset,根據其數據重疊情況統計歸并路數:
若某 Tablet 的 Rowset 分布如下:
"rowsets": ["[0-100] 3 DATA NONOVERLAPPING ...", // 無重疊,歸并占 1 路 "[101-101] 2 DATA OVERLAPPING ...", // 有重疊,歸并占 2 路 "[102-102] 1 DATA NONOVERLAPPING ..." // 無重疊,歸并占 1 路
]
-
無重疊 Rowset:如
[0-100]范圍的 Rowset 由 3 個Segment 組成,但是沒有但是沒有overlap,查詢歸并時僅占 1 路; -
有重疊 Rowset:如
[101-101]范圍的 Rowset 由 2 個Segment 組成,但是有但是有overlap,查詢歸并時占 2 路。
則 Compaction Score = 1(第一行) + 2(第二行) + 1(第三行) = 4。
2. Base & Cumulative Compaction:分層合并策略
為了平衡 “壓縮效率” 和 “數據合并成本”,Doris 采用分層壓縮思路:
(1)Cumulative Compaction
- 作用:優先合并新寫入的小 Rowset,避免直接與大 Rowset 合并導致效率低下。新導入的零散數據(如實時寫入的小批次數據 ),先通過Cumulative Compaction逐步 “攢大”,減少后續 Base Compaction 的壓力。
(2)Base Compaction
- 作用:當Cumulative Rowset 合并到一定規模后,再與 ** 歷史大 Rowset(Base Rowset)** 合并,最終形成更緊湊的大 Rowset,徹底優化查詢路數。
(3)Cumulative Point:分層 “臨界點”
用來劃分 “Cumulative Rowset” 和 “Base Rowset” 的邊界。比如某 Tablet 的 Cumulative Point 為 293,意味著:
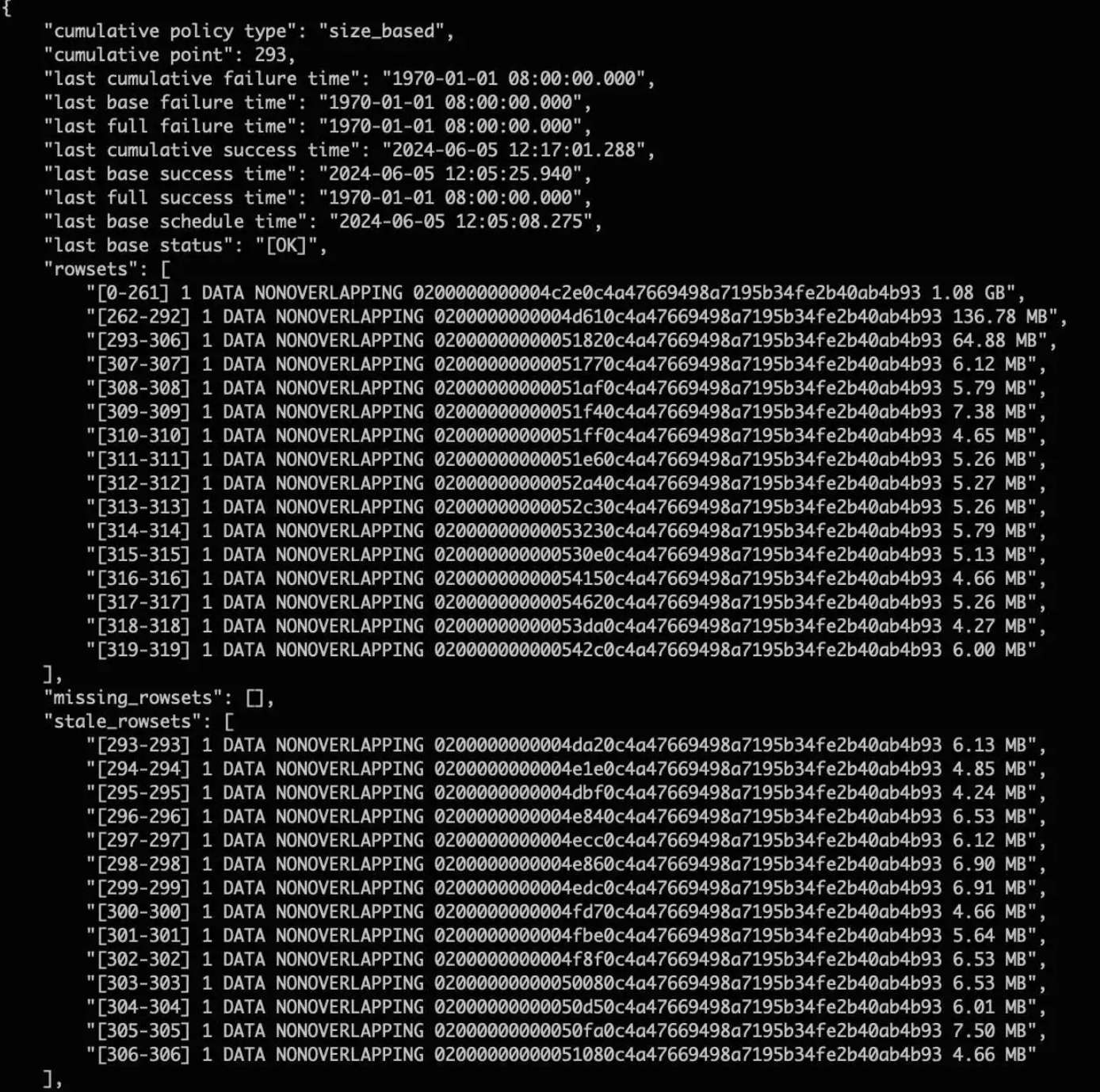
-
Rowset 范圍
293+做的是 Cumulative Compaction; -
Rowset 范圍
0-292做的是 Base Compaction。
三、Compaction 工作流程:生產者 - 消費者模式
Doris 的 Compaction 流程遵循生產者 - 消費者模型,可拆解為 4 大核心步驟,每個步驟都蘊含精細的設計邏輯:
1. 掃描與優先級計算(生產者線程)
BE 的 Compaction 生產者線程定時(可配置掃描間隔)掃描所有 Tablet,執行以下操作:
(一)計算 Compaction Score
遍歷 Tablet 的 Rowset,統計每個 Rowset 在查詢時的歸并路數,累加得到 Compaction Score,確定compaction優先級。
(二)分層任務調度
Doris 通過輪詢策略平衡 Base 和 Cumulative Compaction 的資源占用:
-
默認每 10 輪掃描選 1 次 Base Compaction 任務(處理歷史大 Rowset 合并 );
-
其余 9 輪選 Cumulative Compaction 任務(快速合并新寫入的小 Rowset )。
這樣設計的原因是:Base Compaction 通常涉及更大數據量,資源消耗更高,需控制執行頻率;而 Cumulative Compaction 處理小數據,可高頻執行以快速優化查詢。
2. 并發控制:避免磁盤過載
磁盤的 IO 帶寬和處理能力是有限的,若同時執行過多 Compaction 任務,會導致磁盤性能雪崩(比如磁盤 IO 利用率瞬間 100%,其他讀寫操作阻塞 )。因此,Doris 會:
(一)檢查當前任務數
查詢磁盤當前運行的 Compaction 任務數,與配置的compaction的線程數對比。
(二)動態跳過機制
若任務數已達閾值,跳過該 Tablet,等待下一輪掃描;若未超限,允許任務繼續,確保磁盤資源合理利用。
3. Rowset 篩選策略
并非所有 Rowset 都會被選中壓縮,篩選邏輯聚焦兩點,這直接影響 Compaction 的效率和效果:
(一)連續性優先
優先選擇連續的 Rowset(如按時間或數據范圍連續 ),因為零散的 Rowset 合并后,能減少查詢時歸并的 “碎片問題”。例如,連續的 Rowset 合并后,查詢時可一次性歸并,而零散 Rowset 可能需要多次跳轉磁盤讀取。
(二)數據量均衡
避免合并 “大小差距極大” 的 Rowset。在多路歸并排序中,若 Rowset 數據量差距過大,歸并時小 Rowset 會快速處理完,大 Rowset 仍需大量時間,整體效率會斷崖式下跌。因此,篩選時會優先選數據量相近的 Rowset,保證歸并過程的高效性。
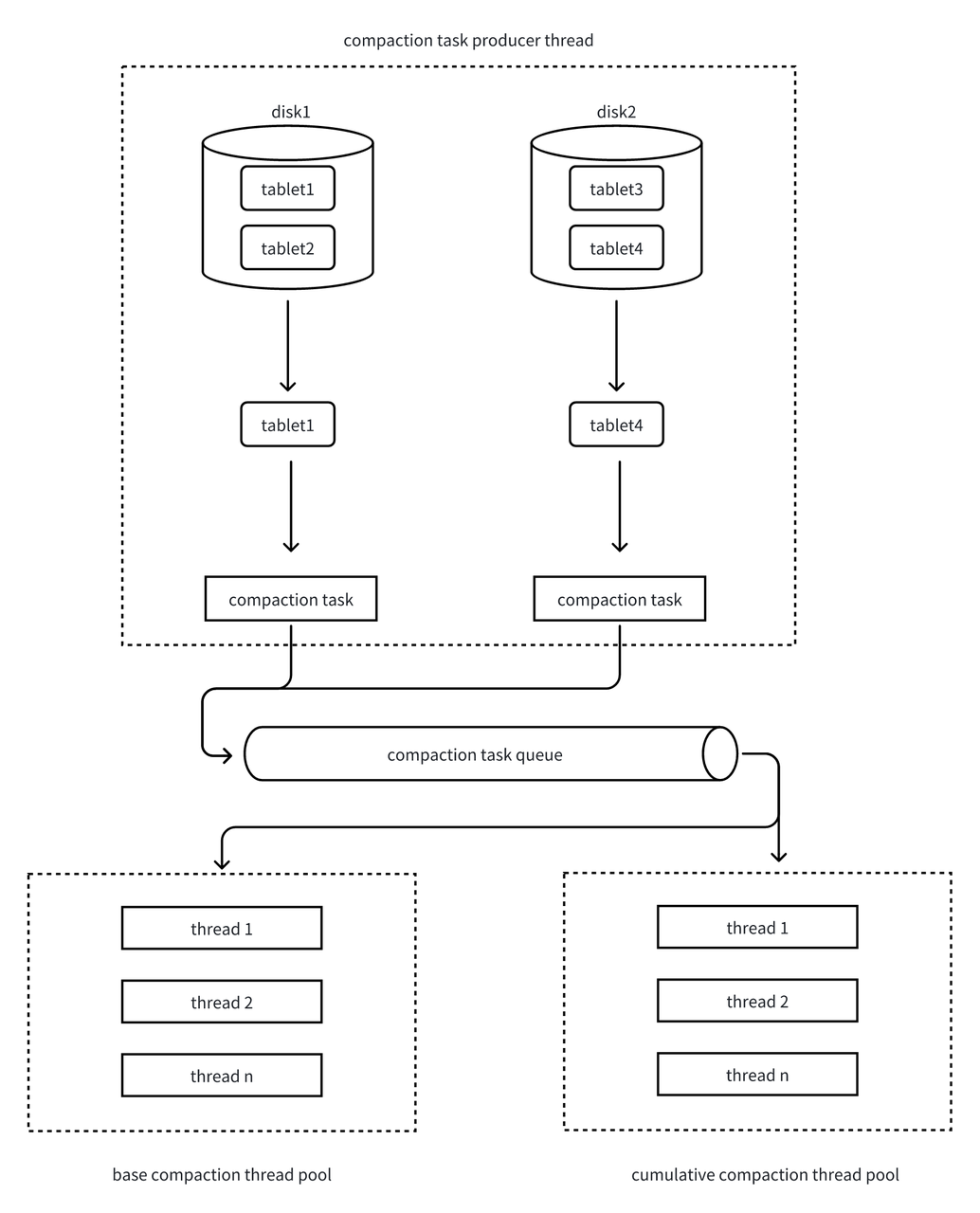
4. 任務分發:分線程池執行
為了隔離 Base Compaction ·和 Cumulative Compaction 的資源,Doris 設計了兩個獨立線程池。
Base compaction線程池和cumulative compaction線程池分別從隊列中取出compaction task任務后,執行多路歸并排序:將多個 Rowset 的數據按順序合并,生成一個新的大 Rowset。
四、總結:Compaction 是效率與成本的平衡藝術
理解 Compaction 的邏輯后,再面對 “查詢變慢”“存儲膨脹” 等問題時,就能從 “數據版本管理” 的視角切入,精準定位與解決。下次遇到 Doris 性能瓶頸,不妨先看看 Compaction 是否在 “默默加班”,是否因配置或數據模式問題導致其 “有心無力”~
如果覺得內容有幫助,歡迎點贊、在看、分享,讓更多人了解 Doris 性能優化的幕后邏輯~ 有疑問或補充,也可在評論區交流,一起深入了解 Doris 技術細節 🌱






C++類和類的方法(基礎教程)(與Python類的區別))
 視頻教程 - 微博文章數據可視化分析-文章分類下拉框實現)

)









