目錄
1、分布式ID介紹
什么是 ID?
什么是分布式 ID?
分布式 ID 需要滿足哪些要求?
2、分布式 ID 常見解決方案
1、數據庫
示例使用2:
2、數據庫號段模式
使用示例2:
一、核心設計思路
二、實現代碼
1. 數據庫表設計(MySQL)
2. 實體類(IdGeneratorDO)
3. Mapper 接口(IdGeneratorMapper)
4. Mapper XML 實現(IdGeneratorMapper.xml)
5. ID 生成器核心類(IdGenerator)
三、使用示例
3、NoSQL
使用示例2:
一、核心設計思路
二、實現代碼
1. 依賴配置(Spring Boot)
2. Redis 分布式 ID 生成器實現
3. 使用示例
三、核心優勢與注意事項
優勢
注意事項
四、擴展優化
五、適用場景
4、算法
4.1、UUID
4.2、Snowflake(雪花算法)
4.3 開源框架
UidGenerator(百度)
Leaf(美團)
Tinyid(滴滴)
IdGenerator(個人)
總結
1、數據庫
2、算法
3、開源框架
1、分布式ID介紹
什么是 ID?
日常開發中,我們需要對系統中的各種數據使用 ID 唯一表示,比如用戶 ID 對應且僅對應一個人,商品 ID 對應且僅對應一件商品,訂單 ID 對3應且僅對應一個訂單。
我們現實生活中也有各種 ID,比如身份證 ID 對應且僅對應一個人、地址 ID 對應且僅對應一個地址。
簡單來說,ID 就是數據的唯一標識。
什么是分布式 ID?
分布式 ID 是分布式系統下的 ID。分布式 ID 不存在與現實生活中,屬于計算機系統中的一個概念。
我簡單舉一個分庫分表的例子。
比如有一個項目,使用的是單機 MySQL 。但是,沒想到的是,項目上線一個月之后,隨著使用人數越來越多,整個系統的數據量將越來越大。單機 MySQL 已經沒辦法支撐了,需要進行分庫分表(推薦 Sharding-JDBC)。
在分庫之后, 數據遍布在不同服務器上的數據庫,數據庫的自增主鍵已經沒辦法滿足生成的主鍵唯一了。我們如何為不同的數據節點生成全局唯一主鍵呢?
這個時候就需要生成分布式 ID了。
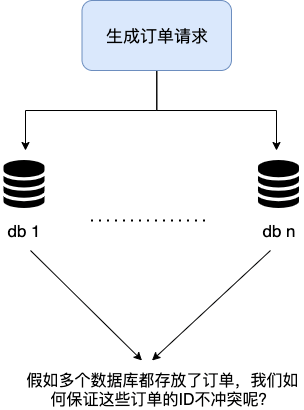
分布式 ID 需要滿足哪些要求?
分布式 ID 作為分布式系統中必不可少的一環,很多地方都要用到分布式 ID。
一個最基本的分布式 ID 需要滿足下面這些要求:
????????●全局唯一:ID 的全局唯一性肯定是首先要滿足的!
????????●高性能:分布式 ID 的生成速度要快,對本地資源消耗要小。
????????●高可用:生成分布式 ID 的服務要保證可用性無限接近于 100%。
????????●方便易用:拿來即用,使用方便,快速接入!
除了這些之外,一個比較好的分布式 ID 還應保證:
????????●安全:ID 中不包含敏感信息。
????????●有序遞增:如果要把 ID 存放在數據庫的話,ID 的有序性可以提升數據庫寫入速度。并且,很多時候 ,我們還很有可能會直接通過 ID 來進行排序。
????????●有具體的業務含義:生成的 ID 如果能有具體的業務含義,可以讓定位問題以及開發更透明化(通過 ID 就能確定是哪個業務)。
????????●獨立部署:也就是分布式系統單獨有一個發號器服務,專門用來生成分布式 ID。這樣就生成 ID 的服務可以和業務相關的服務解耦。不過,這樣同樣帶來了網絡調用消耗增加的問題。總的來說,如果需要用到分布式 ID 的場景比較多的話,獨立部署的發號器服務還是很有必要的。
2、分布式 ID 常見解決方案
1、數據庫
數據庫主鍵自增
這種方式就比較簡單直白了,就是通過關系型數據庫的自增主鍵產生來唯一的 ID。
以 MySQL 舉例,我們通過下面的方式即可。
1.創建一個數據庫表。
CREATE TABLE `sequence_id` (`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,`stub` char(10) NOT NULL DEFAULT '',PRIMARY KEY (`id`),UNIQUE KEY `stub` (`stub`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
stub 字段無意義,只是為了占位,便于我們插入或者修改數據。并且,給 stub 字段創建了唯一索引,保證其唯一性。
2.通過 replace into 來插入數據。
BEGIN;
REPLACE INTO sequence_id (stub) VALUES ('stub');
SELECT LAST_INSERT_ID();
COMMIT;
插入數據這里,我們沒有使用 insert into 而是使用 replace into 來插入數據,具體步驟是這樣的:
????????●第一步:嘗試把數據插入到表中。
????????●第二步:如果主鍵或唯一索引字段出現重復數據錯誤而插入失敗時,先從表中刪除含有重復關鍵字值的沖突行,然后再次嘗試把數據插入到表中。
這種方式的優缺點也比較明顯:
????????●優點:實現起來比較簡單、ID 有序遞增、存儲消耗空間小
????????●缺點:支持的并發量不大、存在數據庫單點問題(可以使用數據庫集群解決,不過增加了復雜度)、ID 沒有具體業務含義、安全問題(比如根據訂單 ID 的遞增規律就能推算出每天的訂單量,商業機密啊! )、每次獲取 ID 都要訪問一次數據庫(增加了對數據庫的壓力,獲取速度也慢)
解決上面的問題:
設置起始值和自增步長
MySQL_1 配置:
set @@auto increment offset =1; -- 起始值
set @@auto increment increment=2; -- 步長
MySQL_2 配置:
set @@auto increment offset =2; -- 起始值
set @@auto increment increment=2; -- 步長
這樣兩個MySQL實例的自增ID分別就是:
1、3、5、7、9
2、4、6、8、10
但是如果兩個還是無法滿足咋辦呢?增加第三臺MySQL實例需要人工修改一、二兩臺MySQL實例的起始值和步長,把第三臺機器的ID起始生成位置設定在比現有最大自增ID的位置遠一些,但必須在一、二兩臺MySQL實例ID還沒有增長到第三臺MySQL實例的起始ID值的時候,否則自增ID就要出現重復了,必要時可能還需要停機修改。
優點:解決DB單點問題
缺點:不利于后續擴容,而且實際上單個數據庫自身壓力還是大,依舊無法滿足高并發場景。
示例使用2:
當我們需要一個ID的時候,向表中插入一條記錄返回主鍵ID,
CREATE DATABASE `SEQ_ID`;
CREATE TABLE SEQID.SEQUENCE_ID (id bigint(20) unsigned NOT NULL auto_increment, value char(10) NOT NULL default '',PRIMARY KEY (id),
) ENGINE=MyISAM;insert into SEQUENCE_ID(value) VALUES ('values');
2、數據庫號段模式
數據庫主鍵自增這種模式,每次獲取 ID 都要訪問一次數據庫,ID 需求比較大的時候,肯定是不行的。
如果我們可以批量獲取,然后存在在內存里面,需要用到的時候,直接從內存里面拿就舒服了!這也就是我們說的 基于數據庫的號段模式來生成分布式 ID。
數據庫的號段模式也是目前比較主流的一種分布式 ID 生成方式。像滴滴開源的Tinyid 就是基于這種方式來做的。不過,TinyId 使用了雙號段緩存、增加多 db 支持等方式來進一步優化。
以 MySQL 舉例,我們通過下面的方式即可。
1. 創建一個數據庫表。
CREATE TABLE `sequence_id_generator` (`id` int(10) NOT NULL,`current_max_id` bigint(20) NOT NULL COMMENT '當前最大id',`step` int(10) NOT NULL COMMENT '號段的長度',`version` int(20) NOT NULL COMMENT '版本號',`biz_type` int(20) NOT NULL COMMENT '業務類型',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
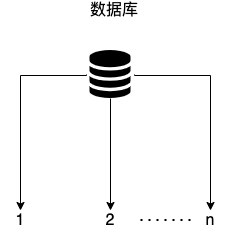
current_max_id 字段和step字段主要用于獲取批量 ID,獲取的批量 id 為:current_max_id ~ current_max_id+step。
version 字段主要用于解決并發問題(樂觀鎖),biz_type 主要用于表示業務類型。
2. 先插入一行數據。
INSERT INTO `sequence_id_generator` (`id`, `current_max_id`, `step`, `version`, `biz_type`)
VALUES(1, 0, 100, 0, 101);
3. 通過 SELECT 獲取指定業務下的批量唯一 ID
SELECT `current_max_id`, `step`,`version` FROM `sequence_id_generator` where `biz_type` = 101
結果:
id current_max_id step version biz_type
1 0 100 0 101
4. 不夠用的話,更新之后重新 SELECT 即可。
UPDATE sequence_id_generator SET current_max_id = 0+100, version=version+1 WHERE version = 0 AND `biz_type` = 101;
SELECT `current_max_id`, `step`,`version` FROM `sequence_id_generator` where `biz_type` = 101
結果:
id current_max_id step version biz_type
1 100 100 1 101
相比于數據庫主鍵自增的方式,數據庫的號段模式對于數據庫的訪問次數更少,數據庫壓力更小。
另外,為了避免單點問題,你可以從使用主從模式來提高可用性。
數據庫號段模式的優缺點:
????????●優點:ID 有序遞增、存儲消耗空間小
????????●缺點:存在數據庫單點問題(可以使用數據庫集群解決,不過增加了復雜度)、ID 沒有具體業務含義、安全問題(比如根據訂單 ID 的遞增規律就能推算出每天的訂單量,商業機密啊! )
使用示例2:
基于數據庫的號段模式是生成分布式 ID 的常用方案,其核心思想是從數據庫批量獲取一段連續的 ID(號段),在本地內存中分配使用,減少數據庫訪問次數。以下是一個完整的實現示例:
一、核心設計思路
- 數據庫表:存儲每個業務的號段信息(當前最大 ID、號段步長)。
- 號段獲取:當本地號段用盡時,從數據庫申請下一段 ID(通過
UPDATE加鎖保證并發安全)。 - 本地分配:在內存中維護當前號段的起始 ID 和結束 ID,逐次遞增分配,直到用盡后再次申請。
二、實現代碼
1. 數據庫表設計(MySQL)
CREATE TABLE `id_generator` (`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主鍵',`biz_type` varchar(50) NOT NULL COMMENT '業務類型(如order、user)',`max_id` bigint(20) NOT NULL DEFAULT 0 COMMENT '當前最大ID',`step` int(11) NOT NULL DEFAULT 1000 COMMENT '號段步長(每次申請的ID數量)',`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新時間',PRIMARY KEY (`id`),UNIQUE KEY `uk_biz_type` (`biz_type`) COMMENT '業務類型唯一索引'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT '分布式ID生成器';-- 初始化業務號段(示例:訂單業務)
INSERT INTO `id_generator` (`biz_type`, `max_id`, `step`) VALUES ('order', 0, 1000);
2. 實體類(IdGeneratorDO)
import lombok.Data;import java.util.Date;@Data
public class IdGeneratorDO {private Long id;private String bizType; // 業務類型private Long maxId; // 當前最大IDprivate Integer step; // 號段步長private Date updateTime; // 更新時間
}
3. Mapper 接口(IdGeneratorMapper)
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import org.apache.ibatis.annotations.Param;public interface IdGeneratorMapper extends BaseMapper<IdGeneratorDO> {/*** 批量獲取號段(核心方法:通過UPDATE加鎖,保證并發安全)* @param bizType 業務類型* @param step 號段步長* @return 受影響的行數(1表示成功,0表示失敗)*/int updateMaxId(@Param("bizType") String bizType, @Param("step") int step);/*** 獲取當前業務的號段信息*/IdGeneratorDO selectByBizType(@Param("bizType") String bizType);
}
4. Mapper XML 實現(IdGeneratorMapper.xml)
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.mapper.IdGeneratorMapper"><!-- 更新max_id,獲取下一個號段 --><update id="updateMaxId">UPDATE id_generatorSET max_id = max_id + #{step},update_time = NOW()WHERE biz_type = #{bizType}</update><!-- 查詢業務對應的號段信息 --><select id="selectByBizType" resultType="com.example.entity.IdGeneratorDO">SELECT id, biz_type, max_id, step, update_timeFROM id_generatorWHERE biz_type = #{bizType}</select>
</mapper>
5. ID 生成器核心類(IdGenerator)
import cn.hutool.core.util.StrUtil;
import com.example.entity.IdGeneratorDO;
import com.example.mapper.IdGeneratorMapper;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.locks.ReentrantLock;/*** 基于數據庫號段模式的分布式ID生成器*/
@Component
public class IdGenerator {@Autowiredprivate IdGeneratorMapper idGeneratorMapper;/*** 本地緩存:存儲每個業務的當前號段信息* key: 業務類型(bizType)* value: 號段對象(Section)*/private final ConcurrentHashMap<String, Section> sectionCache = new ConcurrentHashMap<>();/*** 獲取下一個ID* @param bizType 業務類型(如"order")* @return 分布式ID*/public Long nextId(String bizType) {if (StrUtil.isEmpty(bizType)) {throw new IllegalArgumentException("業務類型不能為空");}// 從本地緩存獲取號段,若不存在或已用盡,則申請新號段Section section = sectionCache.get(bizType);if (section == null || section.is用盡()) {// 加鎖防止并發申請號段ReentrantLock lock = new ReentrantLock();lock.lock();try {// 雙重檢查:避免重復申請section = sectionCache.get(bizType);if (section == null || section.is用盡()) {section = applyNewSection(bizType); // 從數據庫申請新號段sectionCache.put(bizType, section);}} finally {lock.unlock();}}// 從當前號段獲取下一個IDreturn section.nextId();}/*** 從數據庫申請新號段*/private Section applyNewSection(String bizType) {// 1. 查詢該業務的當前號段配置IdGeneratorDO config = idGeneratorMapper.selectByBizType(bizType);if (config == null) {throw new RuntimeException("業務類型[" + bizType + "]未配置號段信息");}int step = config.getStep();// 2. 申請新號段:通過UPDATE將max_id增加step(數據庫層面加鎖,保證并發安全)int updateRows = idGeneratorMapper.updateMaxId(bizType, step);if (updateRows != 1) {// 并發沖突時重試(最多重試3次)for (int i = 0; i < 3; i++) {updateRows = idGeneratorMapper.updateMaxId(bizType, step);if (updateRows == 1) {break;}try {Thread.sleep(10); // 短暫休眠后重試} catch (InterruptedException e) {Thread.currentThread().interrupt();}}if (updateRows != 1) {throw new RuntimeException("申請號段失敗,業務類型:" + bizType);}}// 3. 重新查詢最新的max_id(申請后的值)IdGeneratorDO newConfig = idGeneratorMapper.selectByBizType(bizType);long newMaxId = newConfig.getMaxId();// 號段范圍:[newMaxId - step + 1, newMaxId]long startId = newMaxId - step + 1;long endId = newMaxId;return new Section(startId, endId);}/*** 號段內部類:維護當前號段的起始ID、結束ID和當前ID*/private static class Section {private final long startId; // 號段起始IDprivate final long endId; // 號段結束IDprivate long currentId; // 當前分配到的IDpublic Section(long startId, long endId) {this.startId = startId;this.endId = endId;this.currentId = startId - 1; // 初始化為起始ID的前一個}/*** 獲取下一個ID*/public synchronized Long nextId() {if (is用盡()) {throw new RuntimeException("號段已用盡,startId=" + startId + ", endId=" + endId);}currentId++;return currentId;}/*** 判斷號段是否用盡*/public boolean is用盡() {return currentId >= endId;}}
}
三、使用示例
import com.example.service.IdGenerator;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;@SpringBootTest
@RunWith(SpringRunner.class)
public class IdGeneratorTest {@Autowiredprivate IdGenerator idGenerator;@Testpublic void testNextId() {// 生成訂單業務的IDfor (int i = 0; i < 5; i++) {Long orderId = idGenerator.nextId("order");System.out.println("生成訂單ID:" + orderId);}}
}
輸出結果(首次運行):
生成訂單ID:1
生成訂單ID:2
生成訂單ID:3
生成訂單ID:4
生成訂單ID:53、NoSQL
一般情況下,NoSQL 方案使用 Redis 多一些。我們通過 Redis 的 incr 命令即可實現對 id 原子順序遞增。
127.0.0.1:6379> set sequence_id_biz_type 1
OK
127.0.0.1:6379> incr sequence_id_biz_type
(integer) 2
127.0.0.1:6379> get sequence_id_biz_type
"2"
為了提高可用性和并發,我們可以使用 Redis Cluster。Redis Cluster 是 Redis 官方提供的 Redis 集群解決方案(3.0+版本)。
Redis 方案的優缺點:
????????●優點:性能不錯并且生成的 ID 是有序遞增的
????????●缺點:和數據庫主鍵自增方案的缺點類似
注意:
????????用redis實現需要注意一點,要考慮到redis持久化的問題。redis有兩種持久化方式RDB和AOF
RDB會定時打一個快照進行持久化,假如連續自增但redis沒及時持久化,而這會Redis掛掉了,重啟Redis后會出現ID重復的情況。AOF會對每條寫命令進行持久化,即使Redis掛掉了也不會出現ID重復的情況,但由于incr命令的特殊性,會導致Redis重啟恢復的數據時間過長。
除了 Redis 之外,MongoDB ObjectId 經常也會被拿來當做分布式 ID 的解決方案。

MongoDB ObjectId 一共需要 12 個字節存儲:
????????●0~3:時間戳
????????●3~6:代表機器 ID
????????●7~8:機器進程 ID
????????●9~11:自增值
MongoDB 方案的優缺點:
????????●優點:性能不錯并且生成的 ID 是有序遞增的
????????●缺點:需要解決重復 ID 問題(當機器時間不對的情況下,可能導致會產生重復 ID)、有安全性問題(ID 生成有規律性)
使用示例2:
基于 Redis 生成分布式 ID 是一種高性能方案,利用 Redis 的原子操作(如INCR)保證 ID 的唯一性和遞增性。以下是完整的實現示例:
一、核心設計思路
- 原子遞增:使用 Redis 的
INCR命令對每個業務類型的 ID 鍵進行原子遞增,確保分布式環境下 ID 唯一。 - 前綴區分業務:為不同業務(如訂單、用戶)設置獨立的 Redis 鍵(如
id:order、id:user),避免 ID 沖突。 - ID 結構優化:可組合 “時間戳 + 自增數 + 機器標識” 等信息,使 ID 具備趨勢遞增性和可追溯性。
- 緩存與容錯:本地緩存 Redis 生成的 ID 段,減少 Redis 訪問次數;當 Redis 不可用時,使用備用方案避免服務中斷。
二、實現代碼
1. 依賴配置(Spring Boot)
pom.xml?引入 Redis 依賴:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
application.yml?配置 Redis:
spring:redis:host: localhostport: 6379password: # 若有密碼請填寫database: 0timeout: 3000mslettuce:pool:max-active: 16 # 連接池最大連接數max-idle: 8 # 連接池最大空閑連接數
2. Redis 分布式 ID 生成器實現
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.ReentrantLock;@Component
public class RedisIdGenerator {private final RedisTemplate<String, Long> redisTemplate;// Redis鍵前綴(區分不同業務)private static final String ID_KEY_PREFIX = "distributed:id:";// 本地緩存的ID段大小(減少Redis訪問次數)private static final int BATCH_SIZE = 1000;// 本地緩存:key=業務類型,value=ID段信息private final LocalIdCache localCache = new LocalIdCache();public RedisIdGenerator(RedisTemplate<String, Long> redisTemplate) {this.redisTemplate = redisTemplate;}/*** 生成分布式ID(帶業務前綴)* @param bizType 業務類型(如"order"、"user")* @return 分布式ID*/public Long generateId(String bizType) {// 從本地緩存獲取ID,若緩存不足則從Redis批量獲取IdSegment segment = localCache.getSegment(bizType);if (segment == null || segment.isExhausted()) {ReentrantLock lock = new ReentrantLock();lock.lock();try {// 雙重檢查,避免并發重復申請segment = localCache.getSegment(bizType);if (segment == null || segment.isExhausted()) {// 從Redis申請新的ID段segment = fetchIdSegmentFromRedis(bizType);localCache.setSegment(bizType, segment);}} finally {lock.unlock();}}return segment.nextId();}/*** 從Redis批量獲取ID段(原子操作)*/private IdSegment fetchIdSegmentFromRedis(String bizType) {String redisKey = ID_KEY_PREFIX + bizType;// 原子遞增,一次獲取BATCH_SIZE個ID(返回遞增后的結果)Long end = redisTemplate.opsForValue().increment(redisKey, BATCH_SIZE);if (end == null) {throw new RuntimeException("Redis生成ID失敗,key=" + redisKey);}// ID段范圍:[end - BATCH_SIZE + 1, end]long start = end - BATCH_SIZE + 1;return new IdSegment(start, end);}/*** 生成帶時間戳的復合ID(如:1717234567890 + 12345 → 171723456789012345)* 適用于需要ID包含時間信息的場景*/public Long generateTimestampId(String bizType) {long timestamp = System.currentTimeMillis(); // 時間戳(毫秒級)long sequence = generateId(bizType) % 100000; // 取5位自增數(避免ID過長)// 組合:時間戳(13位) + 自增數(5位) → 18位IDreturn timestamp * 100000 + sequence;}/*** 本地ID段緩存:減少Redis訪問次數*/private static class LocalIdCache {private final java.util.Map<String, IdSegment> cache = new java.util.HashMap<>();public IdSegment getSegment(String bizType) {return cache.get(bizType);}public void setSegment(String bizType, IdSegment segment) {cache.put(bizType, segment);}}/*** ID段內部類:維護批量獲取的ID范圍*/private static class IdSegment {private final long start; // 起始IDprivate final long end; // 結束IDprivate long current; // 當前分配到的IDpublic IdSegment(long start, long end) {this.start = start;this.end = end;this.current = start - 1; // 初始化為起始ID的前一個}/*** 獲取下一個ID*/public synchronized long nextId() {if (isExhausted()) {throw new RuntimeException("ID段已用盡,start=" + start + ", end=" + end);}return ++current;}/*** 判斷ID段是否用盡*/public boolean isExhausted() {return current >= end;}}
}
3. 使用示例
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;@SpringBootTest
@RunWith(SpringRunner.class)
public class RedisIdGeneratorTest {@Autowiredprivate RedisIdGenerator idGenerator;@Testpublic void testGenerateId() {// 生成訂單業務IDfor (int i = 0; i < 5; i++) {Long orderId = idGenerator.generateId("order");System.out.println("訂單ID:" + orderId);}// 生成帶時間戳的用戶IDfor (int i = 0; i < 5; i++) {Long userId = idGenerator.generateTimestampId("user");System.out.println("用戶ID(帶時間戳):" + userId);}}
}
輸出結果:
訂單ID:1
訂單ID:2
訂單ID:3
訂單ID:4
訂單ID:5
用戶ID(帶時間戳):171723456789000001
用戶ID(帶時間戳):171723456789000002
用戶ID(帶時間戳):171723456789000003
用戶ID(帶時間戳):171723456789000004
用戶ID(帶時間戳):171723456789000005
三、核心優勢與注意事項
優勢
- 高性能:Redis 單線程原子操作 + 本地緩存,支持高并發(每秒可達 10 萬 + ID 生成)。
- 唯一性:
INCR命令保證分布式環境下 ID 絕對唯一,無重復風險。 - 趨勢遞增:ID 單調遞增,適合數據庫索引優化(B + 樹索引對有序數據更友好)。
- 輕量易用:無需復雜的數據庫表設計,通過 Redis 命令即可實現。
- 可擴展性:支持多業務類型隔離,通過鍵前綴區分不同場景。
注意事項
- Redis 可用性:依賴 Redis 服務,需確保 Redis 高可用(如主從 + 哨兵 / 集群模式)。
- ID 連續性:服務重啟后,本地緩存的 ID 段會丟失,可能導致 ID 不連續(但不影響唯一性)。
- 步長設置:
BATCH_SIZE(批量獲取的 ID 數量)需根據業務并發調整:- 高并發場景設大(如 10000),減少 Redis 訪問次數;
- 低并發場景設小(如 100),減少 ID 浪費。
- 數據持久化:Redis 需開啟 RDB/AOF 持久化,避免重啟后 ID 從 0 開始導致重復。
- ID 長度控制:復合 ID(如時間戳 + 自增數)需注意長度,避免超出數據庫字段限制(如 MySQL 的 BIGINT 最大支持 19 位)。
四、擴展優化
-
容錯降級:當 Redis 不可用時,切換到本地自增 ID(需保證機器標識唯一,避免分布式重復)。
// 簡化示例:本地降級方案 private Long fallbackGenerateId(String bizType) {// 機器標識(如IP后兩位)+ 時間戳 + 本地自增數String machineId = "10"; // 實際應動態獲取long timestamp = System.currentTimeMillis() / 1000; // 秒級時間戳long localSeq = localSequence.getAndIncrement();return Long.parseLong(machineId + timestamp + localSeq); } -
過期清理:為 Redis 鍵設置過期時間(如 1 年),避免長期積累無效鍵。
// 生成ID時同步設置過期時間 redisTemplate.expire(redisKey, 365, TimeUnit.DAYS); -
預加載 ID 段:當本地 ID 段剩余不足 20% 時,異步提前從 Redis 獲取新號段,避免生成 ID 時的阻塞。
-
自定義 ID 格式:根據業務需求擴展 ID 結構,例如:
- 多機房場景:
機房ID(2位)+ 時間戳(13位)+ 自增數(4位) - 分庫分表場景:
表標識(3位)+ 自增數(16位)
- 多機房場景:
五、適用場景
- 高并發業務(如秒殺、電商訂單):依賴 Redis 的高性能。
- 需要 ID 趨勢遞增的場景:如數據庫分庫分表、日志排序。
- 跨服務 ID 生成:如分布式系統中多個微服務共享 ID 生成器。
通過 Redis 生成分布式 ID,既能保證唯一性和性能,又能靈活擴展 ID 格式,是分布式系統的優選方案之一。
4、算法
4.1、UUID
UUID 是 Universally Unique Identifier(通用唯一標識符) 的縮寫。UUID 包含 32 個 16 進制數字(8-4-4-4-12)。
JDK 就提供了現成的生成 UUID 的方法,一行代碼就行了。
//輸出示例:cb4a9edefa5e4585b9bbd60bce986eaa
UUID.randomUUID().tostring().replaceA11("-","");
RFC 4122 中關于 UUID 的示例是這樣的:
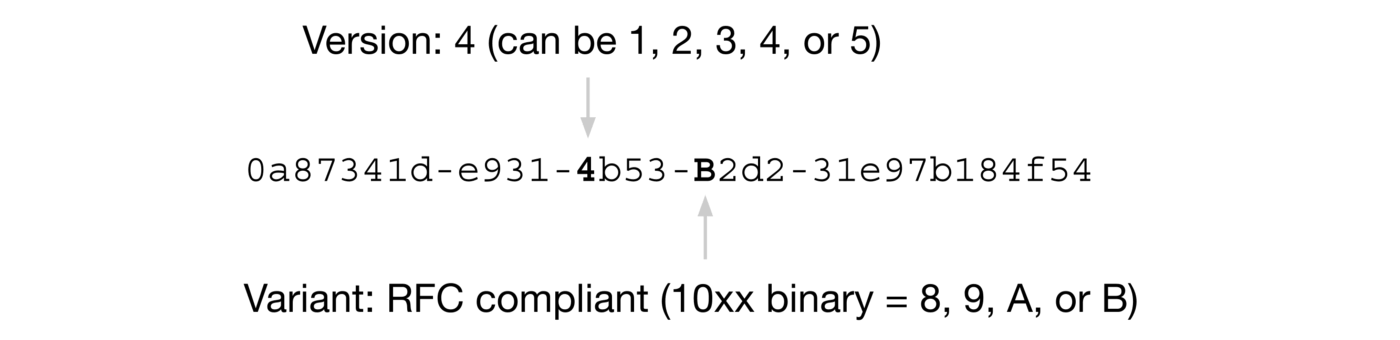
我們這里重點關注一下這個 Version(版本),不同的版本對應的 UUID 的生成規則是不同的。
5 種不同的 Version(版本)值分別對應的含義(參考維基百科對于 UUID 的介紹):
????????●版本 1 : UUID 是根據時間和節點 ID(通常是 MAC 地址)生成;
????????●版本 2 : UUID 是根據標識符(通常是組或用戶 ID)、時間和節點 ID 生成;
????????●版本 3、版本 5 : 版本 5 - 確定性 UUID 通過散列(hashing)名字空間(namespace)標識符和名稱生成;
????????●版本 4 : UUID 使用隨機性或偽隨機性生成。
下面是 Version 1 版本下生成的 UUID 的示例:

JDK 中通過 UUID 的 randomUUID() 方法生成的 UUID 的版本默認為 4。
UUID uuid = UUID.randomUUID();
int version = uuid.version();// 4
從上面的介紹中可以看出,UUID 可以保證唯一性,因為其生成規則包括 MAC 地址、時間戳、名字空間(Namespace)、隨機或偽隨機數、時序等元素,計算機基于這些規則生成的 UUID 是肯定不會重復的。
雖然,UUID 可以做到全局唯一性,但是,我們一般很少會使用它。
比如使用 UUID 作為 MySQL 數據庫主鍵的時候就非常不合適:
????????●數據庫主鍵要盡量越短越好,而 UUID 的消耗的存儲空間比較大(32 個字符串,128 位)。
????????●UUID 是無順序的,InnoDB 引擎下,數據庫主鍵的無序性會嚴重影響數據庫性能。
最后,我們再簡單分析一下 UUID 的優缺點
????????●優點:生成足夠簡單,本地生成無網絡消耗,具有唯一性
????????●缺點:存儲消耗空間大(32 個字符串,128 位)、 不安全(基于 MAC 地址生成 UUID 的算法會造成 MAC 地址泄露)、無序(非自增)、沒有具體業務含義、需要解決重復 ID 問題(當機器時間不對的情況下,可能導致會產生重復 ID)
4.2、Snowflake(雪花算法)
Snowflake 是 Twitter 開源的分布式 ID 生成算法。Snowflake 由 64 bit 的二進制數字組成,這 64bit 的二進制被分成了幾部分,每一部分存儲的數據都有特定的含義:

????????●sign(1bit):符號位(標識正負),始終為 0,代表生成的 ID 為正數。
????????●timestamp (41 bits):一共 41 位,用來表示時間戳,單位是毫秒,可以支撐 2 ^41 毫秒(約 69 年)
????????●datacenter id + worker id (10 bits):一般來說,前 5 位表示機房 ID,后 5 位表示機器 ID(實際項目中可以根據實際情況調整)。這樣就可以區分不同集群/機房的節點。
????????●sequence (12 bits):一共 12 位,用來表示序列號。 序列號為自增值,代表單臺機器每毫秒能夠產生的最大 ID 數(2^12 = 4096),也就是說單臺機器每毫秒最多可以生成 4096 個 唯一 ID。
在實際項目中,我們一般也會對 Snowflake 算法進行改造,最常見的就是在 Snowflake 算法生成的 ID 中加入業務類型信息。
我們再來看看 Snowflake 算法的優缺點:
????????●優點:生成速度比較快、生成的 ID 有序遞增、比較靈活(可以對 Snowflake 算法進行簡單的改造比如加入業務 ID)
????????●缺點:需要解決重復 ID 問題(ID 生成依賴時間,在獲取時間的時候,可能會出現時間回撥的問題,也就是服務器上的時間突然倒退到之前的時間,進而導致會產生重復 ID)、依賴機器 ID 對分布式環境不友好(當需要自動啟停或增減機器時,固定的機器 ID 可能不夠靈活)。
4.3 開源框架
UidGenerator(百度)
UidGenerator 是百度開源的一款基于 Snowflake(雪花算法)的唯一 ID 生成器。
不過,UidGenerator 對 Snowflake(雪花算法)進行了改進,生成的唯一 ID 組成如下:

????????●sign(1bit):符號位(標識正負),始終為 0,代表生成的 ID 為正數。
????????●delta seconds (28 bits):當前時間,相對于時間基點"2016-05-20"的增量值,單位:秒,最多可支持約 8.7 年
????????●worker id (22 bits):機器 id,最多可支持約 420w 次機器啟動。內置實現為在啟動時由數據庫分配,默認分配策略為用后即棄,后續可提供復用策略。
????????●sequence (13 bits):每秒下的并發序列,13 bits 可支持每秒 8192 個并發。
可以看出,和原始 Snowflake(雪花算法)生成的唯一 ID 的組成不太一樣。并且,上面這些參數我們都可以自定義。
UidGenerator 官方文檔中的介紹如下:

自 18 年后,UidGenerator 就基本沒有再維護了
Leaf(美團)
Leaf 是美團開源的一個分布式 ID 解決方案 。這個項目的名字 Leaf(樹葉) 起源于德國哲學家、數學家萊布尼茨的一句話:“There are no two identical leaves in the world”(世界上沒有兩片相同的樹葉) 。這名字起得真心挺不錯的,有點文藝青年那味了!
Leaf 提供了 號段模式 和 Snowflake(雪花算法) 這兩種模式來生成分布式 ID。并且,它支持雙號段,還解決了雪花 ID 系統時鐘回撥問題。不過,時鐘問題的解決需要弱依賴于 Zookeeper(使用 Zookeeper 作為注冊中心,通過在特定路徑下讀取和創建子節點來管理 workId) 。
Leaf 的誕生主要是為了解決美團各個業務線生成分布式 ID 的方法多種多樣以及不可靠的問題。
Leaf 對原有的號段模式進行改進,比如它這里增加了雙號段避免獲取 DB 在獲取號段的時候阻塞請求獲取 ID 的線程。簡單來說,就是我一個號段還沒用完之前,我自己就主動提前去獲取下一個號段
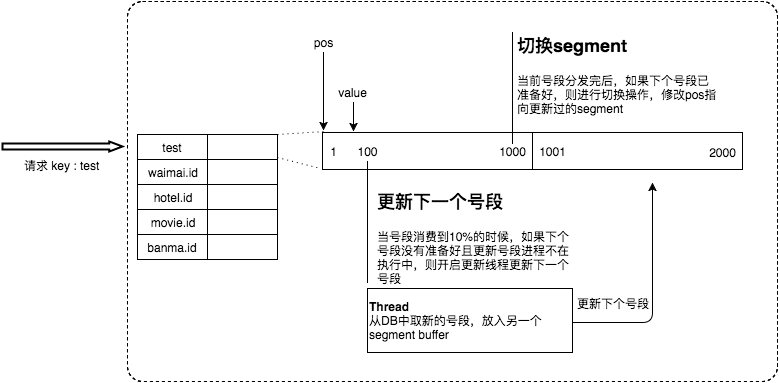
根據項目 README 介紹,在 4C8G VM 基礎上,通過公司 RPC 方式調用,QPS 壓測結果近 5w/s,TP999 1ms。
Tinyid(滴滴)
Tinyid 是滴滴開源的一款基于數據庫號段模式的唯一 ID 生成器。
數據庫號段模式的原理我們在上面已經介紹過了。Tinyid 有哪些亮點呢?
為了搞清楚這個問題,我們先來看看基于數據庫號段模式的簡單架構方案。(圖片來自于 Tinyid 的官方 wiki:《Tinyid 原理介紹》)
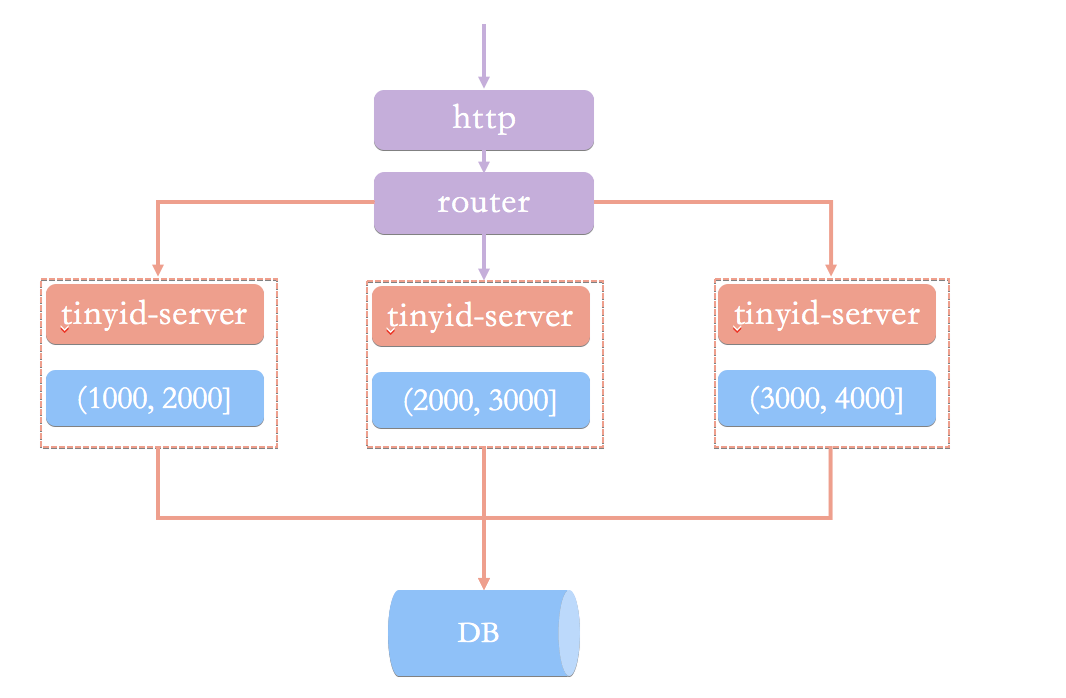
在這種架構模式下,我們通過 HTTP 請求向發號器服務申請唯一 ID。負載均衡 router 會把我們的請求送往其中的一臺 tinyid-server。
這種方案有什么問題呢?在我看來(Tinyid 官方 wiki 也有介紹到),主要由下面這 2 個問題:
????????●獲取新號段的情況下,程序獲取唯一 ID 的速度比較慢。
????????●需要保證 DB 高可用,這個是比較麻煩且耗費資源的。
除此之外,HTTP 調用也存在網絡開銷。
Tinyid 的原理比較簡單,其架構如下圖所示:
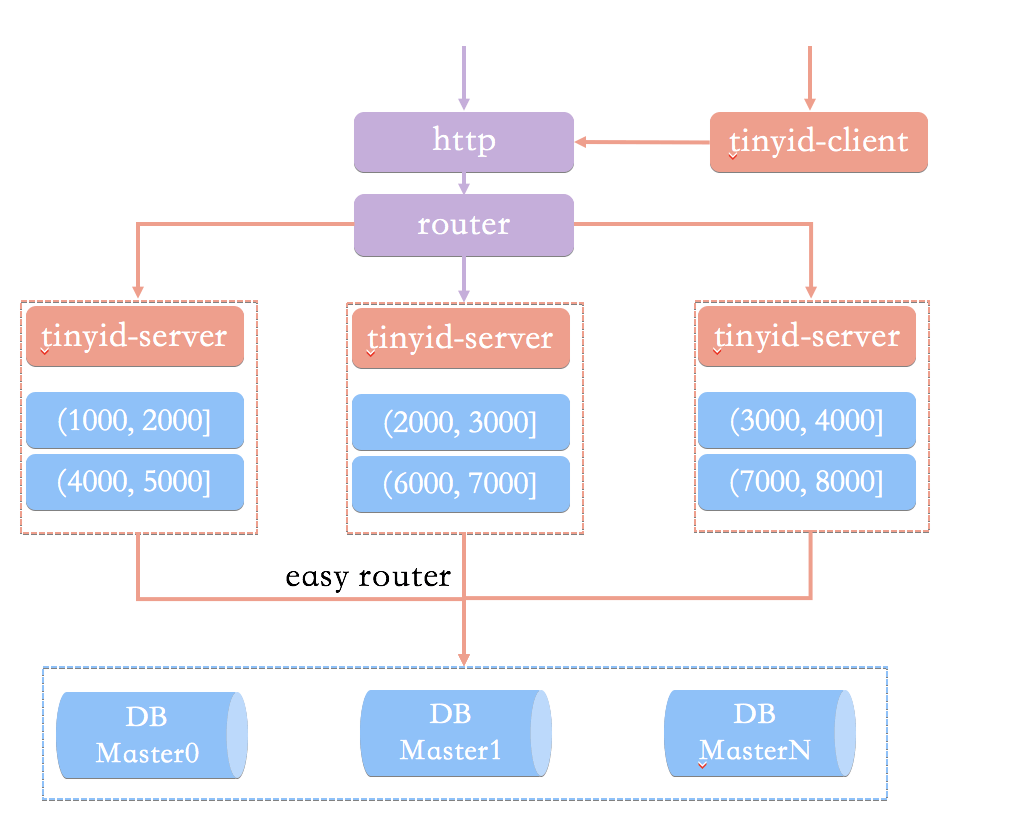
相比于基于數據庫號段模式的簡單架構方案,Tinyid 方案主要做了下面這些優化:
????????●雙號段緩存:為了避免在獲取新號段的情況下,程序獲取唯一 ID 的速度比較慢。 Tinyid 中的號段在用到一定程度的時候,就會去異步加載下一個號段,保證內存中始終有可用號段。
????????●增加多 db 支持:支持多個 DB,并且,每個 DB 都能生成唯一 ID,提高了可用性。
????????●增加 tinyid-client:純本地操作,無 HTTP 請求消耗,性能和可用性都有很大提升。
Tinyid 的優缺點這里就不分析了,結合數據庫號段模式的優缺點和 Tinyid 的原理就能知道。
?
IdGenerator(個人)
和 UidGenerator、Leaf 一樣,IdGenerator 也是一款基于 Snowflake(雪花算法)的唯一 ID 生成器。IdGenerator 有如下特點:
????????●生成的唯一 ID 更短;
????????●兼容所有雪花算法(號段模式或經典模式,大廠或小廠);
????????●原生支持 C#/Java/Go/C/Rust/Python/Node.js/PHP(C 擴展)/SQL/ 等語言,并提供多線程安全調用動態庫(FFI);
????????●解決了時間回撥問題,支持手工插入新 ID(當業務需要在歷史時間生成新 ID 時,用本算法的預留位能生成 5000 個每秒);
????????●不依賴外部存儲系統;
????????●默認配置下,ID 可用 71000 年不重復。
IdGenerator 生成的唯一 ID 組成如下:

????????●timestamp (位數不固定):時間差,是生成 ID 時的系統時間減去 BaseTime(基礎時間,也稱基點時間、原點時間、紀元時間,默認值為 2020 年) 的總時間差(毫秒單位)。初始為 5bits,隨著運行時間而增加。如果覺得默認值太老,你可以重新設置,不過要注意,這個值以后最好不變。
????????●worker id (默認 6 bits):機器 id,機器碼,最重要參數,是區分不同機器或不同應用的唯一 ID,最大值由 WorkerIdBitLength(默認 6)限定。如果一臺服務器部署多個獨立服務,需要為每個服務指定不同的 WorkerId。
????????●sequence (默認 6 bits):序列數,是每毫秒下的序列數,由參數中的 SeqBitLength(默認 6)限定。增加 SeqBitLength 會讓性能更高,但生成的 ID 也會更長。
Java 語言使用示例:https://github.com/yitter/idgenerator/tree/master/Java。
總結
1、數據庫
????????a、主鍵自增
????????????????■優點:實現起來比較簡單、ID 有序遞增、存儲消耗空間小。
????????????????■缺點:支持的并發量不大、存在數據庫單點問題(可以使用數據庫集群解決,不過增加了復雜度)、ID 沒有具體業務含義、安全問題(比如根據訂單 ID 的遞增規律就能推算出每天的訂單量,商業機密啊! )、每次獲取 ID 都要訪問一次數據庫(增加了對數據庫的壓力,獲取速度也慢)
????????b、號段模式
????????????????■優點:ID 有序遞增、存儲消耗空間小
????????????????■缺點:存在數據庫單點問題(可以使用數據庫集群解決,不過增加了復雜度)、ID 沒有具體業務含義、安全問題(比如根據訂單 ID 的遞增規律就能推算出每天的訂單量,商業機密啊!)
????????c、NoSQL,比如Redis
????????????????■優點:性能不錯并且生成的 ID 是有序遞增的
????????????????■缺點:和數據庫主鍵自增方案的缺點類似
2、算法
????????a、UUID
????????????????■優點:生成速度比較快、簡單易用
????????????????■缺點:存儲消耗空間大(32 個字符串,128 位)、 不安全(基于 MAC 地址生成 UUID 的算法會造成 MAC 地址泄露)、無序(非自增)、沒有具體業務含義、需要解決重復 ID 問題(當機器時間不對的情況下,可能導致會產生重復 ID)
????????b、Snowflake(雪花算法)
????????????????■優點:生成速度比較快、生成的 ID 有序遞增、比較靈活(可以對 Snowflake 算法進行簡單的改造比如加入業務 ID)
????????????????■缺點:需要解決重復 ID 問題(ID 生成依賴時間,在獲取時間的時候,可能會出現時間回撥的問題,也就是服務器上的時間突然倒退到之前的時間,進而導致會產生重復 ID)、依賴機器 ID 對分布式環境不友好(當需要自動啟停或增減機器時,固定的機器 ID 可能不夠靈活)。
3、開源框架
????????a、UidGenerator(百度):基于Snowflake(雪花算法)做了改進
????????b、Leaf(美團): 支持號段模式 和 Snowflake(雪花算法) 來生成分布式 ID,增加了雙號段避免獲取 DB 在獲取號段的時候阻塞請求獲取 ID 的線程
????????c、Tinyid(滴滴)
????????????????■雙號段緩存:為了避免在獲取新號段的情況下,程序獲取唯一 ID 的速度比較慢。 Tinyid 中的號段在用到一定程度的時候,就會去異步加載下一個號段,保證內存中始終有可用號段。
????????????????■增加多 db 支持:支持多個 DB,并且,每個 DB 都能生成唯一 ID,提高了可用性。
????????????????■增加 tinyid-client:純本地操作,無 HTTP 請求消耗,性能和可用性都有很大提升。
????????d、IdGenerator(個人)
????????????????■生成的唯一 ID 更短;
????????????????■兼容所有雪花算法(號段模式或經典模式,大廠或小廠);
????????????????■原生支持 C#/Java/Go/C/Rust/Python/Node.js/PHP(C 擴展)/SQL/ 等語言,并提供多線程安全調用動態庫(FFI);
????????????????■解決了時間回撥問題,支持手工插入新 ID(當業務需要在歷史時間生成新 ID 時,用本算法的預留位能生成 5000 個每秒);
????????????????■不依賴外部存儲系統;
????????????????■默認配置下,ID 可用 71000 年不重復。

)





創建型:原型模式詳解)

)







)

