
作者: Sausar Karaf, Mikhail Martynov, Oleg Sautenkov, Zhanibek Darush, Dzmitry Tsetserukou
單位:俄羅斯斯科爾科沃科學技術研究院智能空間機器人實驗室
論文標題:MorphoNavi: Aerial-Ground Robot Navigation with Object Oriented Mapping in Digital Twin
論文鏈接:https://arxiv.org/pdf/2504.16914
主要貢獻
提出了面向通用空地機器人的單目相機映射方法,能夠在無需針對特定環境微調的情況下檢測多種物體并估計其位置。
通過模擬搜索救援場景驗證了該方法的有效性,MorphoGear機器人成功定位到機器狗,為開發能夠在非結構化環境中運行的智能多模態機器人系統做出了貢獻。
該方法在保留物體語義信息的同時,減少了對高帶寬通信的需求,且與現有的機器人感知系統兼容,可作為低成本替代方案,適用于僅配備相機和有限計算資源的機器人。
研究背景
近年來,機器人領域發展迅速,尤其是基于RGB圖像的視覺語言模型(VLMs)成為執行任務的強大工具,其僅需圖像和文本提示輸入,無需昂貴的激光雷達和深度相機等傳感器。
傳統的映射技術(如點云、八叉樹和網格恢復技術)主要關注物體形狀的保留,而本研究提出的方法還保留了物體的語義信息,有助于實現更高層次的理解,例如推斷房間功能、規劃多階段任務等。
單目深度估計是機器人感知的關鍵部分,相關技術如ZoeDepth、Depth-Anything等在相對深度估計和度量深度估計方面取得了進展。同時,YOLO系列、Detectron2等模型在目標檢測方面表現出色,但存在類別限制,需要額外訓練。而零樣本和開放詞匯檢測器(如Grounding DINO 1.5 Pro、DINO X)以及基于變換器架構的模型(如OWL-ViT、OWLV2)為識別預訓練類別之外的物體提供了可能。
視覺語言模型(VLMs)如Molmo、ChatGPT等在整合視覺和文本數據方面取得了突破,但其訓練主要基于二維圖像-文本對應關系,缺乏三維空間推理或深度感知能力,限制了其在機器人導航等需要三維環境理解的應用中的使用。為解決這一問題,出現了視覺語言行動(VLA)模型,如RT-1、PaLM-E等,但它們依賴于大規模、特定任務的數據集,且數據收集成本高、適用范圍有限。
研究方法
系統由MorphoGear空地機器人、帶有控制界面的筆記本電腦以及配備定位系統的環境組成。所有計算在機器人(控制)或個人電腦(映射)上進行,使用Unity游戲引擎進行模擬和控制。
MorphoGear機器人

是一種具有地面移動、物體抓取和空中運動能力的無人空地車輛(AGV),其硬件包括OrangePi 5b伴生計算機、OrangeCube飛行控制器、基于STM32的自定義肢體控制器和ELP-USBFHD05H 2MP 2.8-12mm 1:1.4 1/2.7” MJPEG相機。軟件基于ROS2 Iron,包含用于高級命令的Python節點和mavros,ROS#用于生成肢體運動。
地面站

操作員使用配備Unity和Python的筆記本電腦作為地面站,開發了機器人的數字孿生模型,用于虛擬實驗和作為控制面板。機器人將狀態發送到Unity,Unity僅作為可視化工具。通過ROS-TCP-Connector將Unity中的命令發送到機器人。
環境
實驗在一個6x10x4米的房間內進行,工作空間由網限制,路徑規劃網格為5x8x3米,配備了VICON定位系統。
映射算法
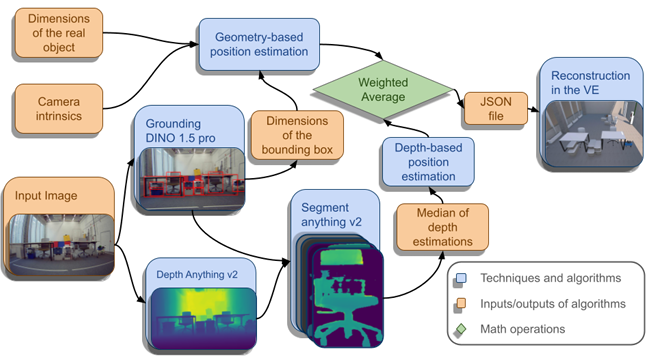
系統以單目RGB圖像作為輸入,通過檢測物體并根據其已知幾何尺寸估計其位置來導航。在開發過程中,評估了包括OWLv2、OWL-ViT和DINO-X在內的多種目標檢測模型,最終選擇了OWLv2和Grounding DINO 1.5 Pro模型。
基于已知的物體尺寸、相機內參和目標檢測器獲得的邊界框,利用公式估算物體距離,并結合Depth Anything v2和Segment Anything v2的深度估計結果,計算最終物體距離。處理后的物體數據被封裝成JSON文件并傳輸到基于Unity的模擬環境中。
實驗
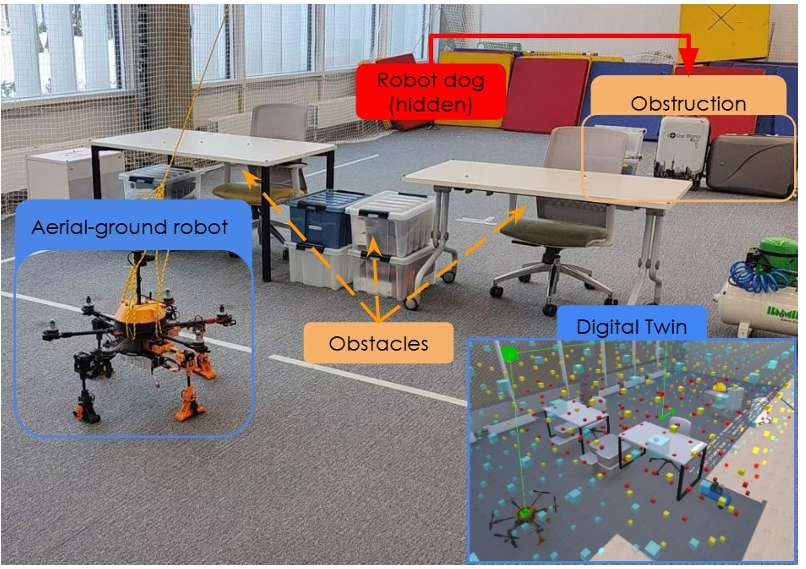
通過模擬搜索救援場景評估所提出的系統,設置了一個機器狗遇到問題需要外部干預的案例,MorphoGear機器人的任務是定位機器狗。
實驗設置
在測試環境中放置了桌子、箱子和椅子等障礙物,限制了機器人的初始視野,使全圖觀察變得困難。機器狗被放置在由堆疊箱子組成的障礙物后面,以驗證MorphoGear機器人在地面和空中運動模式之間的轉換能力。
實驗過程
任務開始時,空地車輛捕獲環境的初始圖像,該圖像被映射管道處理,計算物體位置并發送到Unity基礎的GUI進行可視化和規劃。使用生成的地圖和機器人的位置構建障礙物網格,并由A*算法為MorphoGear機器人規劃軌跡。
實驗結果
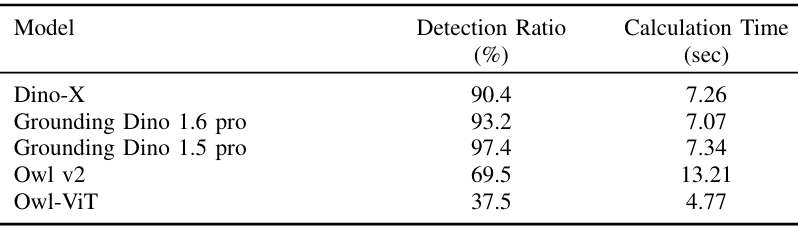
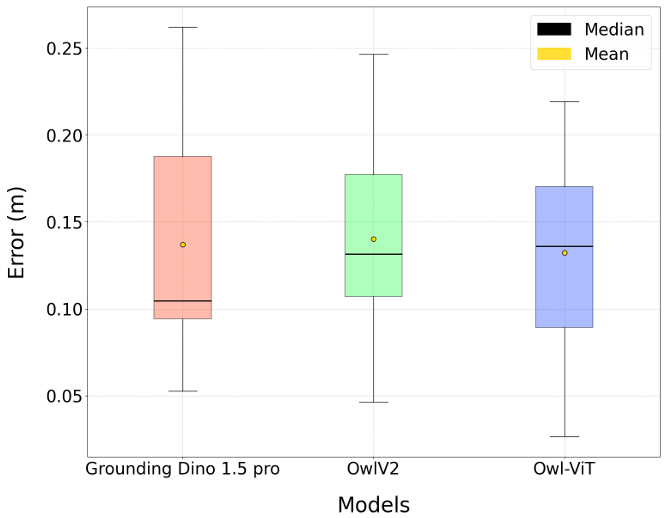
系統成功檢測并定位了場景中97.4%的目標物體,平均位置估計誤差為13.6厘米,平均每張圖像的處理時間為7.34秒。
盡管系統在受控實驗室條件下表現良好,但仍存在一些局限性,如遮擋問題導致物體位置精度下降,對于未知形狀和不同方向的物體,基于單目的距離估計算法不夠準確,且系統尚未實現實時處理。
結論與未來工作
- 結論:
論文提出了一種利用單目相機的通用空地機器人映射方法,能夠在復雜環境中檢測多種物體并估計其位置,無需針對特定環境進行微調。
通過模擬搜索救援場景驗證了該方法的有效性,MorphoGear機器人成功定位到機器狗,系統在目標檢測率、位置估計準確性和處理時間方面表現出色。
- 未來工作:
盡管如此,仍有一些需要改進的地方,如遮擋問題、未知形狀和不同方向物體的距離估計準確性以及實時處理能力。
未來的工作將探索層次化和基于深度學習的方法來解決這些問題,還將研究將該映射系統與視覺語言模型(VLMs)集成,以增強其空間理解和認知推理能力,并探索實時優化策略以減少處理延遲,使系統更適合動態搜索救援場景。


)

)
: 文件及系統參數變量說明及使用)



 協議介紹)










