1.MLP
多層感知機MLP(Multilayer Perceptron),也是人工神經網絡(ANN,Artificial Neural Network),是一種全連接
多層感知機(Multilayer Perceptron, MLP)是一種前饋神經網絡,它由輸入層、若干隱藏層和輸出層組成。每一層都由多個神經元(或稱為節點)組成。
輸入層(Input Layer):輸入層接收外部輸入的數據,將其傳遞到下一層。每個輸入特征都對應一個神經元。
隱藏層(Hidden Layer):隱藏層是位于輸入層和輸出層之間的一層或多層神經元。每個隱藏層的神經元接收上一層傳來的輸入,并通過權重和激活函數進行計算,然后將結果傳遞到下一層。隱藏層的存在可以使多層感知機具備更強的非線性擬合能力。
輸出層(Output Layer):輸出層接收隱藏層的輸出,并產生最終的輸出結果。輸出層的神經元數目通常與任務的輸出類別數目一致。對于分類任務,輸出層通常使用softmax激活函數來計算每個類別的概率分布;對于回歸任務,輸出層可以使用線性激活函數。
多層感知機的各層之間是全連接的,也就是說,每個神經元都與上一層的每個神經元相連。每個連接都有一個與之相關的權重和一個偏置。
2.LeNet簡介
LeNet-5模型是由楊立昆(Yann LeCun)教授于1998年在論文Gradient-Based Learning Applied to Document Recognition中提出的,是一種用于手寫體字符識別的非常高效的卷積神經網絡,其實現過程如下圖所示。
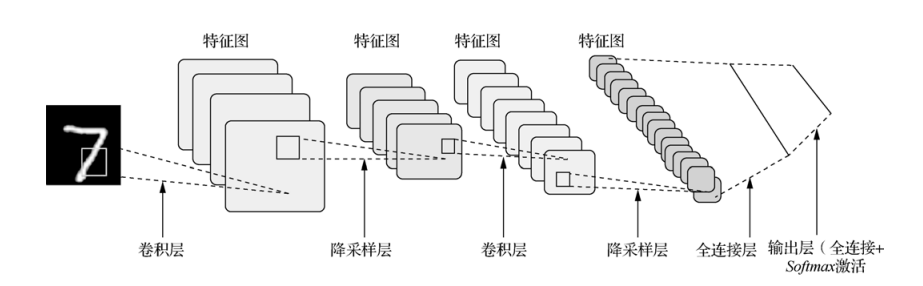
原論文的經典的LeNet-5網絡結構如下:
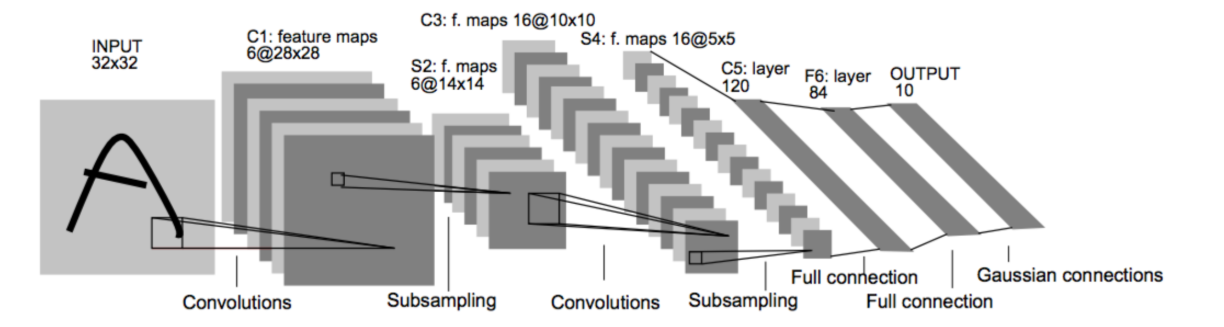
各個結構作用:
卷積層:提取特征圖的特征,淺層的卷積提取的是一些紋路、輪廓等淺層的空間特征,對于深層的卷積,可以提取出深層次的空間特征。
池化層: 1、降低維度 2、最大池化或者平均池化,在本網絡結構中使用的是最大池化。
全連接層: 1、輸出結果 2、位置:一般位于CNN網絡的末端。 3、操作:需要將特征圖reshape成一維向量,再送入全連接層中進行分類或者回歸。
下來我們使用代碼詳解推理一下各卷積層參數的變化:
import torch
import torch.nn as nnx = torch.randn([1,1,32,32])conv1 = nn.Conv2d(in_channels=1,out_channels=6,kernel_size=5)
c1 = conv1(x)
print(c1.shape)pool = nn.MaxPool2d(2)s1 = pool(c1)
print(s1.shape)conv2 = nn.Conv2d(in_channels=6,out_channels=16,kernel_size=5)c2 = conv2(s1)
print(c2.shape)
s2 = pool(c2)
print(s2.shape)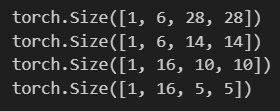
pytorch實現最簡單的LeNet模型
import torch
import torch.nn as nn
import torch.nn.functional as Fclass LeNet(nn.Module):def __init__(self):super(LeNet, self).__init__()self.conv1 = nn.Conv2d(1, 6, 5,stride=1)self.conv2 = nn.Conv2d(6, 16, 5,stride=1)self.fc1 = nn.Linear(16 * 5 * 5, 120)self.fc2 = nn.Linear(120,84)self.fc3 = nn.Linear(84,10)self.relu = nn.ReLU()def forward(self,x):x = self.relu(self.conv1(x))x = F.avg_pool2d(x,kernel_size=2,stride=2)s = self.relu(self.conv2(x))x = F.avg_pool2d(s,kernel_size=2,stride=2)x = torch.flatten(x,1)x = self.relu(self.fc1(x))x = self.relu(self.fc2(x))x = self.fc3(x)return xmodel = LeNet()print(model)
?3.Mnist數據集
3.1MNIST數據集簡介
該數據集包含60,000個用于訓練的示例和10,000個用于測試的示例。
數據集包含了0-9共10類手寫數字圖片,每張圖片都做了尺寸歸一化,都是28x28大小的灰度圖。
MNIST數據集包含四個部分: 訓練集圖像:train-images-idx3-ubyte.gz(9.9MB,包含60000個樣本) 訓練集標簽:train-labels-idx1-ubyte.gz(29KB,包含60000個標簽) 測試集圖像:t10k-images-idx3-ubyte.gz(1.6MB,包含10000個樣本) 測試集標簽:t10k-labels-idx1-ubyte.gz(5KB,包含10000個標簽)
3.2 MNIST數據集的預處理
import torch
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
import structtransform = transforms.Compose([transforms.ToTensor(),transforms.Lambda(lambda x: x.view(-1,1))
])train_dataset = datasets.MNIST(root = "./dataset",train = True,transform = transform,download = True
)
test_dataset = datasets.MNIST(root = "./dataset",train = False,transform = transform,download = True
)train_loader = DataLoader(dataset = train_dataset,batch_size = 64,shuffle = True,
)
test_loader = DataLoader(dataset = test_dataset,batch_size = 64,shuffle = False,
)print(F"訓練集樣本數量:{len(train_dataset)}")
print(F"測試集樣本數量:{len(test_dataset)}")print("=" * 140)
print("圖像矩陣的十六進制表示(非0用紅色表示):")
data = train_dataset[0][0].squeeze().numpy()
rows = 28
colums = 28
counter = 0
# for i in range(rows):
# row = data[i * colums:(i + 1) * colums]
# for value in row:
# integer_part = int(value * 100)
# integer_part = max(0,min(65535,integer_part))
# hex_bytes = struct.pack("H", integer_part)
# hex_string = hex_bytes.hex()
# if hex_string == '0000':
# print(' ', end='')
# else:
# print(F"\033[31m{hex_string}\033[0m", end="")
# counter += 1
# if counter % 28 == 0: print()
print("=" * 140)
for images,labels in train_loader:print("Batch Image Shape:",images.shape)print("Batch Label Shape:",labels.shape)#輸出三張圖片,我想把四張圖輸出在一個圖中for i in range(4):plt.subplot(2,2,i+1)img = images[i].reshape(28,28).numpy()plt.imshow(img,cmap='gray')plt.title(F"Label:{labels[i].item()}")plt.show()print(labels[i])# img = images[0].reshape(28,28).numpy()# plt.imshow(img,cmap='gray')# plt.title(F"Label:{labels[0].item()}")# plt.axis('off')# plt.show()break?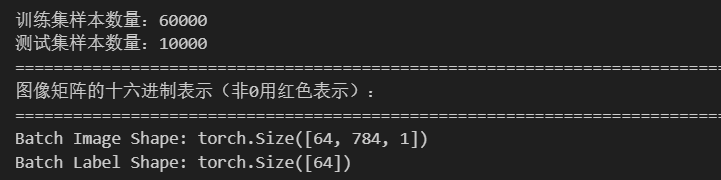





![[數據庫]Neo4j圖數據庫搭建快速入門](http://pic.xiahunao.cn/[數據庫]Neo4j圖數據庫搭建快速入門)






)






