目錄
8.1 個體與集成
8.2?Boosting
Ada(Adaptive)Boost
8.3?Bagging
8.4 隨機森林
8.5?結合策略
8.5.1 平均法
8.5.2 投票法
8.5.3 學習法
8.6 多樣性
8.6.1 誤差-分歧分解?error-ambiguity
8.6.2 多樣性度量
8.6.3 多樣性增強
8.1 個體與集成
?同質集成“基學習器” 如決策樹、神經網絡;異質集成中的個體學習器由不同的學習算法生成
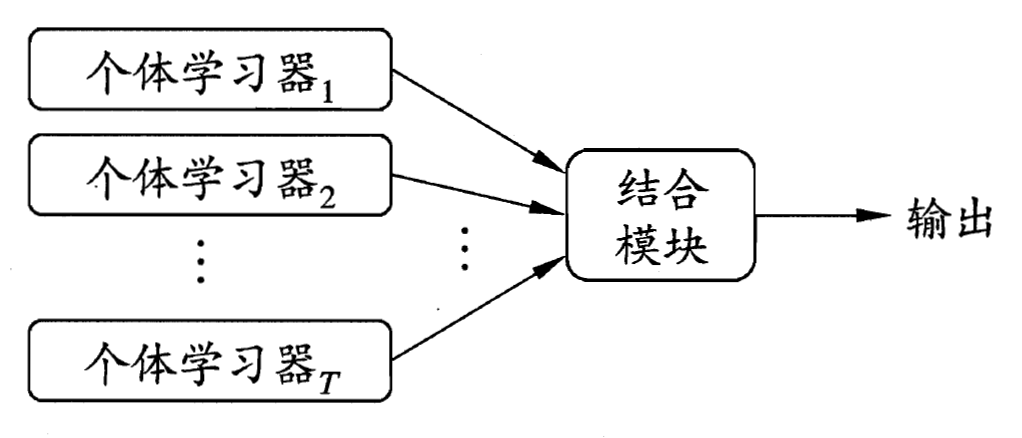
個體學習器的“準確性”和“多樣性”? ?對“好而不同”的個體學習器 投票“少數服從多數”
T 個基分類器 錯誤率為€? ? ? ? 整體錯誤率為錯半數以上 隨著T增大收斂到0
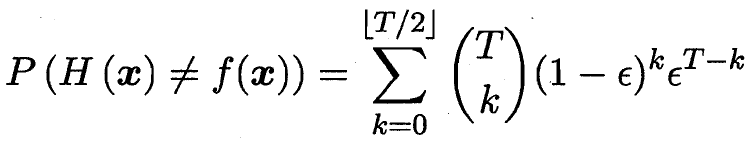
![]()
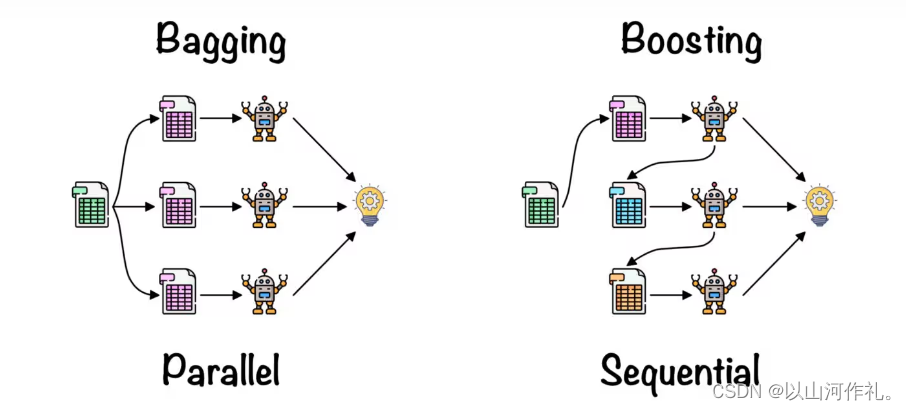
個體學習器間存在強依賴關系、必須串行生成的序列化方法?Boosting
間不存在強依賴關系、可同時生成的并行化方法?Bagging和“隨機森林"
8.2?Boosting
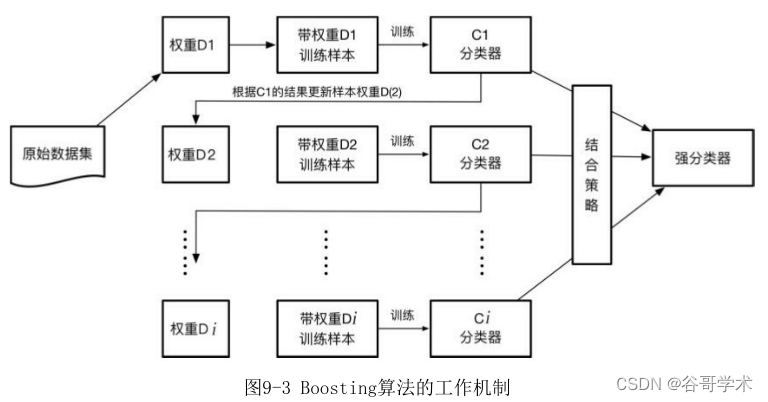
每輪樣本的權重不同? 上輪分類錯誤的樣本? 權重被調大? 在下一次學習中被關注? 進而調高準確度
Ada(Adaptive)Boost
?偽代碼如下 下方主要是對于樣本分布 D_t+1 調整的數學推導
訓練分類器h 算出誤差ε? ?更新樣本分布Dt+1和Dt 關系
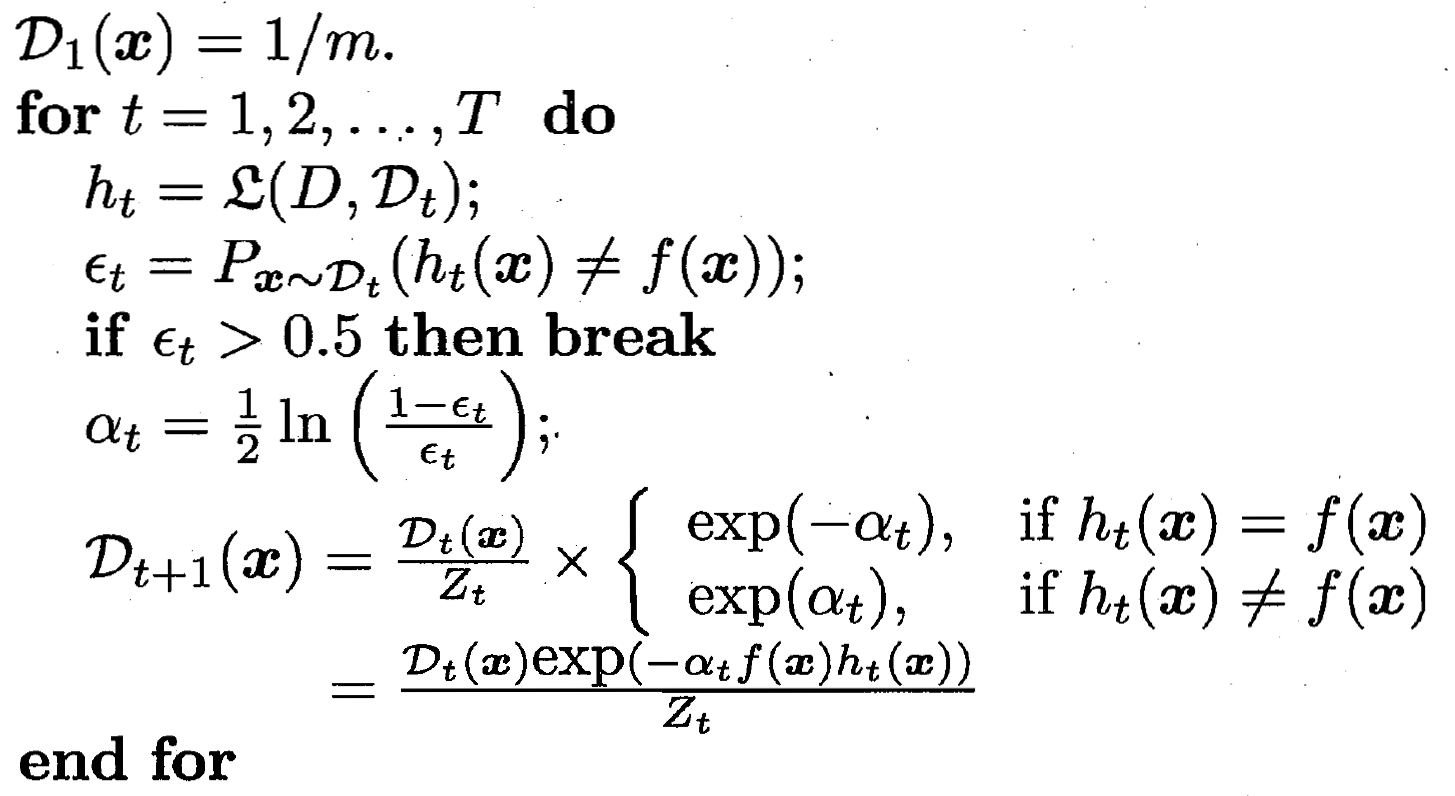
?![]() ??
??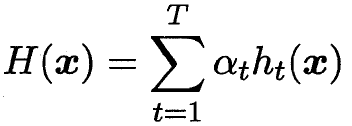
![]()

理想的基學習器? ![]() ?能糾正之前疊加形態分類器的所有錯誤
?能糾正之前疊加形態分類器的所有錯誤
(但如果新的分類錯誤多到超過一半 那也不合適)

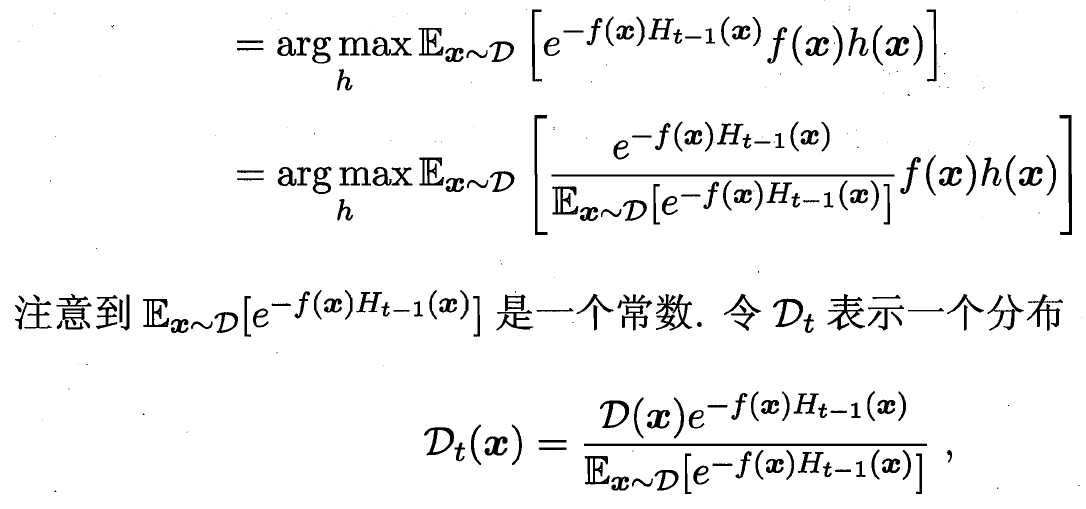
最后的分布調整 D_t+1 和 D_t的關系
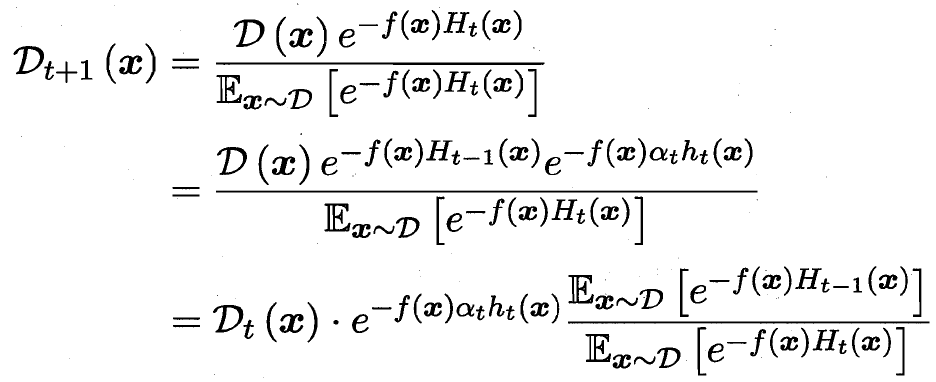
8.3?Bagging
重疊采樣思想
基學習器盡可能具有較大的差異 可使得訓練數據不同:
對訓練樣本進行采樣,產生出若干個不同的子集,每個子集訓練出一個基學習器.
希望個體學習器不能太差 使每個學習器使用更多數據:使用相互有交疊的采樣子集.
bootstrap sampling 自助采樣法? m個樣本采樣m次? 沒被采樣到的概率收斂為
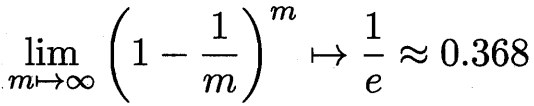
T輪采樣 每輪采m個數據作為訓練集 用基學習算法訓練出模型?
對這T個訓練出來的集成模型? 回歸問題則把T個結果平均一下? ?分類問題則把T個結果投票一下
包外估計:把沒被采樣到的數據作為驗證集
8.4 隨機森林
以決策樹為基學習器構建Bagging?在決策樹的訓練過程中
先隨機選取一些特征? 再選這幾個中最優的幾個 (數據隨機+特征隨機)
scikit-learn 隨機森林
class 參數的中文說明可參考這篇
8.5?結合策略
相對單學習器的優勢:
1.學習任務假設空間很大 若很多假設在訓練集效果相近
但單學習器不能確定在總體空間做的好不好
2.學習算法陷入局部最優解 泛化性不強? ? ? ?3.結合有利于擴大 原樣本的假設空間
8.5.1 平均法
?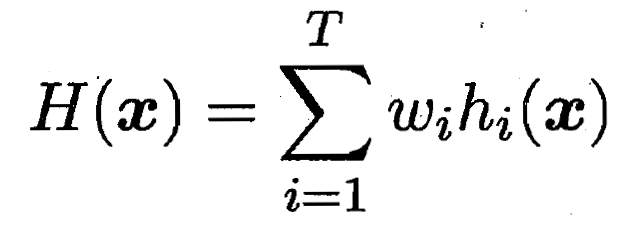 ? ? ?
? ? ?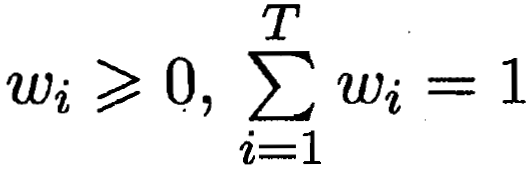
8.5.2 投票法
分類為N種中一種? ? 1.超過半數則確定? ? ? 2.選票最多的(票的權重 平均或加權)
8.5.3 學習法
Stacking 訓練出的學習器 生成一些樣本 與原樣本混合 訓練下一個學習器
8.6 多樣性
8.6.1 誤差-分歧分解?error-ambiguity
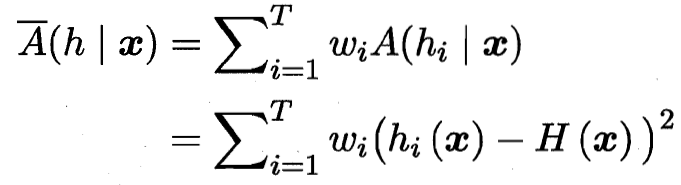 ?加權分歧
?加權分歧![]() ?加權誤差
?加權誤差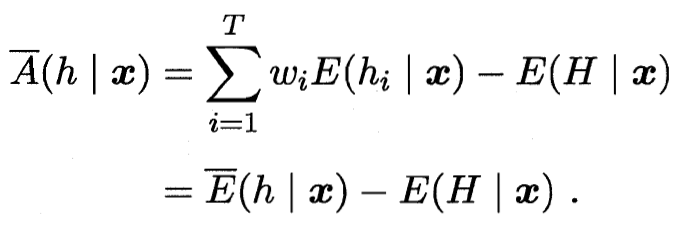 加權分歧=加權誤差-總誤差
加權分歧=加權誤差-總誤差
![]() 總誤差=加權誤差-加權分歧
總誤差=加權誤差-加權分歧
誤差越小 分歧(多樣性)越大? ? 總誤差越小
8.6.2 多樣性度量
兩兩的 相似/不相似性
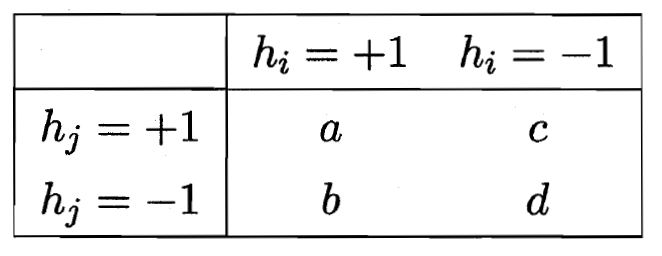
不合度量(b和c為結果不一樣的)?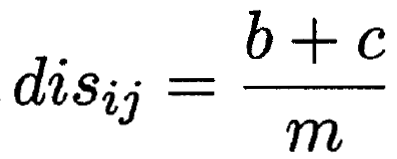 ?
?
相關系數??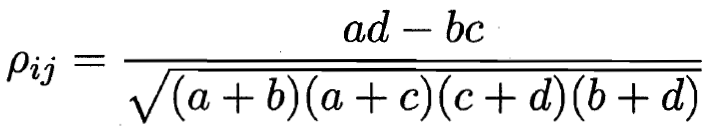

![]()
![]()
8.6.3 多樣性增強
1.數據樣本擾動(不同采樣方式)? ? ? 2.輸入屬性擾動(屬性集中選取使用屬性)
3.輸出表示擾動(把分類問題轉化為回歸問題? 拆解原問題)? ? 4.算法參數改動(調參)












中的應用探索)





)
