在pandas中讀取 Excel 表格后,有多種方式可以按列、按行提取數據,下面我將詳細介紹常見的方法。
0.聲明
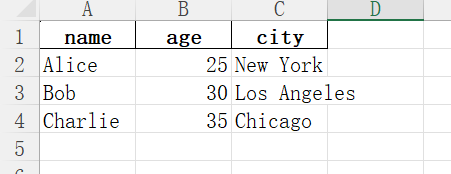
在本文中我使用的excel表內容如下:
1. 讀取 Excel 文件
首先,我們需要使用 pandas 的 read_excel 函數讀取 Excel 文件,示例代碼如下:
import pandas as pd# 讀取 Excel 文件
df = pd.read_excel(excel_file_path, sheet_name)
- excel_file_path為文件路徑
- sheet_name為工作表名稱
2. 按列提取數據
2.1 通過列名提取單列數據
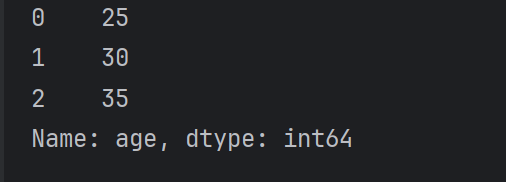
可以使用方括號 [] 并傳入列名來提取單列數據,提取后的數據類型為 pandas.Series。
# 提取名為 'age' 的列
column_data = df['age']
print(column_data)
2.2 通過列名提取多列數據
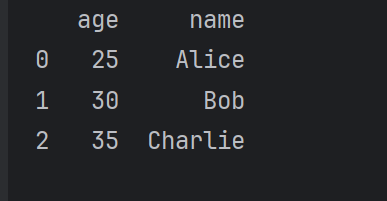
若要提取多列數據,可在方括號 [] 中傳入一個包含列名的列表,提取后的數據類型為 pandas.DataFrame。
# 提取 'age' 和 'name' 兩列
columns_data = df[['age', 'name']]
print(columns_data)
2.3 通過列索引提取單列數據
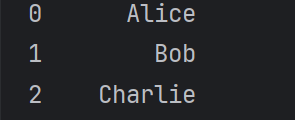
使用 iloc 方法,通過列的整數索引來提取單列數據。
# 提取第 0 列(索引從 0 開始)
first_column = df.iloc[:, 0]
print(first_column)
2.4 通過列索引提取多列數據
同樣使用 iloc 方法,通過指定列索引范圍來提取多列數據。
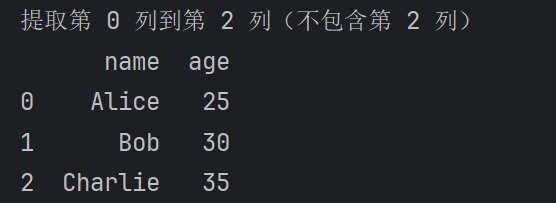
# 提取第 0 列到第 2 列(不包含第 2 列)
selected_columns = df.iloc[:, 0:2]
print(selected_columns)
3. 按行提取數據
3.1 通過行索引提取單行數據
使用 iloc 方法,通過行的整數索引來提取單行數據,提取后的數據類型為 pandas.Series。
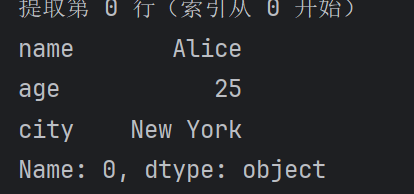
# 提取第 0 行(索引從 0 開始)
first_row = df.iloc[0]
print(first_row)
3.2 通過行索引提取多行數據
使用 iloc 方法,通過指定行索引范圍來提取多行數據,提取后的數據類型為 pandas.DataFrame。
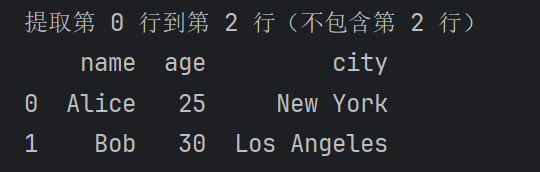
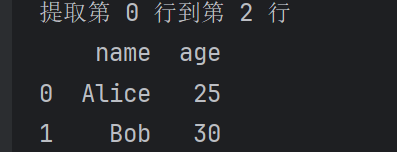
# 提取第 0 行到第 2 行(不包含第 2 行)
selected_rows = df.iloc[0:2]
print(selected_rows)
3.3 通過條件篩選提取行數據
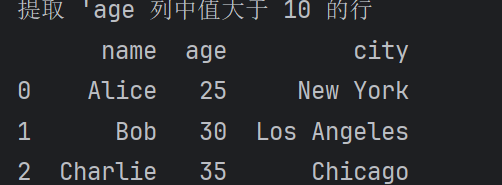
可以根據某列的條件來篩選出符合條件的行。
#提取 'age 列中值大于 10 的行
filtered_rows = df[df['age'] > 10]
print(filtered_rows)
4. 按行和列同時提取數據
4.1 使用 iloc 按行和列索引提取數據
# 提取第 0 行到第 2 行(不包含第 2 行)和第 0 列到第 2 列(不包含第 2 列)的數據
subset = df.iloc[0:2, 0:2]
print(subset)
5.總代碼
這是本文中所使用的代碼,大家可以復制下來自己運行一遍
import pandas as pdexcel_file_path="./data.xlsx"
sheet_name="Sheet1"
# 讀取 Excel 文件
df = pd.read_excel(excel_file_path, sheet_name)# 提取名為 'age' 的列
print("提取名為 'age' 的列")
column_data = df['age']
print(column_data)# 提取 'age' 和 'name' 兩列
print("提取 'age' 和 'name' 兩列")
columns_data = df[['age', 'name']]
print(columns_data)# 提取第 0 列(索引從 0 開始)
print("提取第 0 列(索引從 0 開始)")
first_column = df.iloc[:, 0]
print(first_column)# 提取第 0 列到第 2 列(不包含第 2 列)
print("提取第 0 列到第 2 列(不包含第 2 列)")
selected_columns = df.iloc[:, 0:2]
print(selected_columns)# 提取第 0 行(索引從 0 開始)
print("提取第 0 行(索引從 0 開始)")
first_row = df.iloc[0]
print(first_row)# 提取第 0 行到第 2 行(不包含第 2 行)
print("提取第 0 行到第 2 行(不包含第 2 行)")
selected_rows = df.iloc[0:2]
print(selected_rows)# 提取 'age 列中值大于 10 的行
print("提取 'age 列中值大于 10 的行")
filtered_rows = df[df['age'] > 10]
print(filtered_rows)# 提取第 0 行到第 2 行(不包含第 2 行)和第 0 列到第 2 列(不包含第 2 列)的數據
print("提取第 0 行到第 2 行")
subset = df.iloc[0:2, 0:2]
print(subset)
6.總結
通過學習以上代碼,你會掌握excel讀取數據的基本方法。在python中會將讀取的excel轉換為DataFrame格式。這是一個功能強大且靈活的數據結構,在數據處理、分析和可視化等領域都有廣泛的應用,你可以通過閱讀我的另一篇文章來了解DataFrame格式的常見用法,







-狀態欄)

)




實現方式詳解)

:線程封裝)


)