ELK 日志分析系統集群部署
本文檔基于 Rocky Linux 9.4 系統,部署 ELK 7.17.16(長期支持版)集群
案例準備
1. 節點規劃
| IP | 主機名 | 部署組件 | 角色說明 |
|---|---|---|---|
| 192.168.100.150 | kafka01 | Elasticsearch、Kibana | 主節點(master)+ 可視化 |
| 192.168.100.151 | kafka02 | Elasticsearch、Logstash | 數據節點 + 日志收集 |
| 192.168.100.152 | kafka03 | Elasticsearch | 數據節點(僅存儲數據) |
2. 基礎環境要求
- 系統:Rocky Linux 9.4(Blue Onyx)
- 內存:每節點至少 2GB(Elasticsearch 建議 4GB 以上)
- 網絡:節點間互通,開放端口 9200(ES HTTP)、9300(ES 集群)、5601(Kibana)、9600(Logstash)
案例實施
1. 基礎環境配置(所有節點執行)
(1)修改主機名
# kafka01 節點
hostnamectl set-hostname kafka01 && bash# kafka02 節點
hostnamectl set-hostname kafka02 && bash# kafka03 節點
hostnamectl set-hostname kafka03 && bash
(2)配置主機名映射
vi /etc/hosts
添加以下內容(三個節點均需配置):
127.0.0.1 localhost
::1 localhost
192.168.100.150 kafka01
192.168.100.151 kafka02
192.168.100.152 kafka03
(3)安裝 JDK 環境
ELK 7.17.x 依賴 JDK 1.8 或 11,此處使用 OpenJDK 1.8:
# 安裝 OpenJDK 1.8
dnf install -y java-1.8.0-openjdk java-1.8.0-openjdk-devel# 驗證安裝
java -version
# 預期輸出:openjdk version "1.8.0_382" 或更高版本
2. 部署 Elasticsearch 集群(所有節點執行)
(1)下載并安裝 Elasticsearch 7.17.16
# 下載 RPM 包
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.17.16-x86_64.rpm# 安裝
rpm -ivh elasticsearch-7.17.16-x86_64.rpm
(2)節點配置(核心差異:7.x 新增主節點初始化參數)
配置文件路徑:/etc/elasticsearch/elasticsearch.yml
kafka01(主節點):
cluster.name: ELK-Cluster # 集群名稱(所有節點一致)
node.name: kafka01 # 節點名(與主機名一致)
node.master: true # 允許作為主節點
node.data: false # 不存儲數據(僅主節點)
network.host: 192.168.100.150 # 綁定當前節點 IP
http.port: 9200 # HTTP 端口
# 集群節點發現(7.x 用 discovery.seed_hosts 替代舊參數)
discovery.seed_hosts: ["kafka01", "kafka02", "kafka03"]
# 初始主節點列表(首次啟動時選舉主節點)
cluster.initial_master_nodes: ["kafka01"]
# 關閉內存交換(提升性能)
bootstrap.memory_lock: true
kafka02(數據節點):
cluster.name: ELK-Cluster
node.name: kafka02
node.master: false # 不參與主節點選舉
node.data: true # 存儲數據
network.host: 192.168.100.151
http.port: 9200
discovery.seed_hosts: ["kafka01", "kafka02", "kafka03"]
cluster.initial_master_nodes: ["kafka01"]
bootstrap.memory_lock: true
kafka03(數據節點):
cluster.name: ELK-Cluster
node.name: kafka03
node.master: false
node.data: true
network.host: 192.168.100.152
http.port: 9200
discovery.seed_hosts: ["kafka01", "kafka02", "kafka03"]
cluster.initial_master_nodes: ["kafka01"]
bootstrap.memory_lock: true
(3)內存鎖定配置(避免內存交換,提升性能)
-
修改系統限制:
vi /etc/security/limits.conf添加以下內容:
elasticsearch soft memlock unlimited elasticsearch hard memlock unlimited -
修改服務配置:
vi /usr/lib/systemd/system/elasticsearch.service確保包含以下行(默認已配置,驗證即可):
LimitMEMLOCK=infinity
(4)啟動 Elasticsearch
# 刷新配置并啟動
systemctl daemon-reload
systemctl enable --now elasticsearch# 驗證服務狀態(確保 9200/9300 端口監聽)
ss -ntpl | grep 9200
# 預期輸出:LISTEN 0 128 192.168.100.150:9200 ...
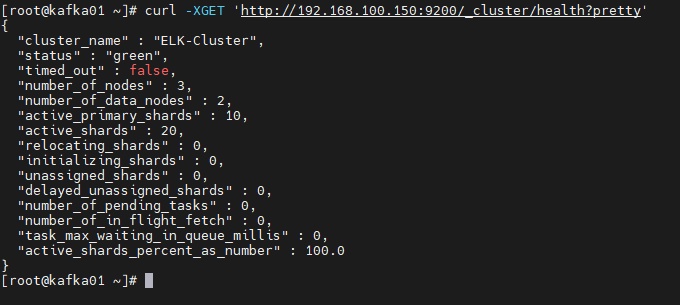
(5)驗證集群健康狀態(在 kafka01 執行)
curl -XGET 'http://192.168.100.150:9200/_cluster/health?pretty'
健康狀態輸出(status: green 表示正常):
{"cluster_name" : "ELK-Cluster","status" : "green","number_of_nodes" : 3,"number_of_data_nodes" : 2,"active_primary_shards" : 0,"active_shards" : 0,"relocating_shards" : 0,"initializing_shards" : 0,"unassigned_shards" : 0
}
3. 部署 Kibana(僅 kafka01 節點)
(1)下載并安裝 Kibana 7.17.16
# 下載 RPM 包
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.17.16-x86_64.rpm# 安裝
rpm -ivh kibana-7.17.16-x86_64.rpm
(2)配置 Kibana
配置文件路徑:/etc/kibana/kibana.yml
server.port: 5601 # 端口
server.host: "192.168.100.150" # 綁定 kafka01 IP
elasticsearch.hosts: ["http://192.168.100.150:9200"] # 關聯 Elasticsearch
kibana.index: ".kibana" # Kibana 存儲索引(默認)
(3)啟動 Kibana
systemctl enable --now kibana# 驗證端口
ss -ntpl | grep 5601
# 預期輸出:LISTEN 0 128 192.168.100.150:5601 ...
通過瀏覽器訪問 http://192.168.100.150:5601,出現 Kibana 界面即部署成功。
4. 部署 Logstash(僅 kafka02 節點)
(1)下載并安裝 Logstash 7.17.16
# 下載 RPM 包
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.17.16-x86_64.rpm# 安裝
rpm -ivh ./logstash-7.17.16-x86_64.rpm
(2)配置 Logstash
基礎配置(/etc/logstash/logstash.yml):
http.host: "192.168.100.151" # 綁定 kafka02 IP
path.config: /etc/logstash/conf.d/*.conf # 配置文件路徑
日志收集規則(收集系統日志):
創建配置文件 vi /etc/logstash/conf.d/syslog.conf:
input {file {path => "/var/log/messages" # Rocky Linux 系統日志路徑type => "systemlog"start_position => "beginning" # 從日志開頭收集stat_interval => "3" # 每 3 秒檢查日志更新}
}
output {if [type] == "systemlog" {elasticsearch {hosts => ["http://192.168.100.150:9200"] # 輸出到 kafka01 的 ESindex => "system-log-%{+YYYY.MM.dd}" # 按日期拆分索引}}
}
(3)驗證配置并啟動
修改日志目錄權限
# 確保日志目錄存在并修改所有者
sudo mkdir -p /var/log/logstash
sudo chown -R logstash:logstash /var/log/logstash
sudo chmod -R 755 /var/log/logstash # 目錄權限:所有者可讀寫執行,其他用戶可讀執行
修改數據目錄權限
# 確保隊列目錄及父目錄存在并修改所有者
sudo mkdir -p /var/lib/logstash/queue
sudo chown -R logstash:logstash /var/lib/logstash
sudo chmod -R 755 /var/lib/logstash # 同上,確保可寫
驗證配置文件目錄權限
額外檢查配置文件目錄權限:
sudo chown -R logstash:logstash /etc/logstash
sudo chmod -R 755 /etc/logstash
# 授權 Logstash 讀取日志文件
chmod 644 /var/log/messages# 驗證配置文件(7.x 命令調整)
/usr/share/logstash/bin/logstash --path.settings /etc/logstash -t# 啟動并設置開機自啟
systemctl enable --now logstash# 驗證 9600 端口(Logstash 監控端口)
ss -ntpl | grep 9600
# 預期輸出:LISTEN 0 128 192.168.100.151:9600 ...
5. Kibana 日志可視化(在瀏覽器操作)
(1)查看日志索引(在 kafka01 執行)
curl 'http://192.168.100.150:9200/_cat/indices?v'
# 預期輸出包含:system-log-2025.07.21(按實際日期)

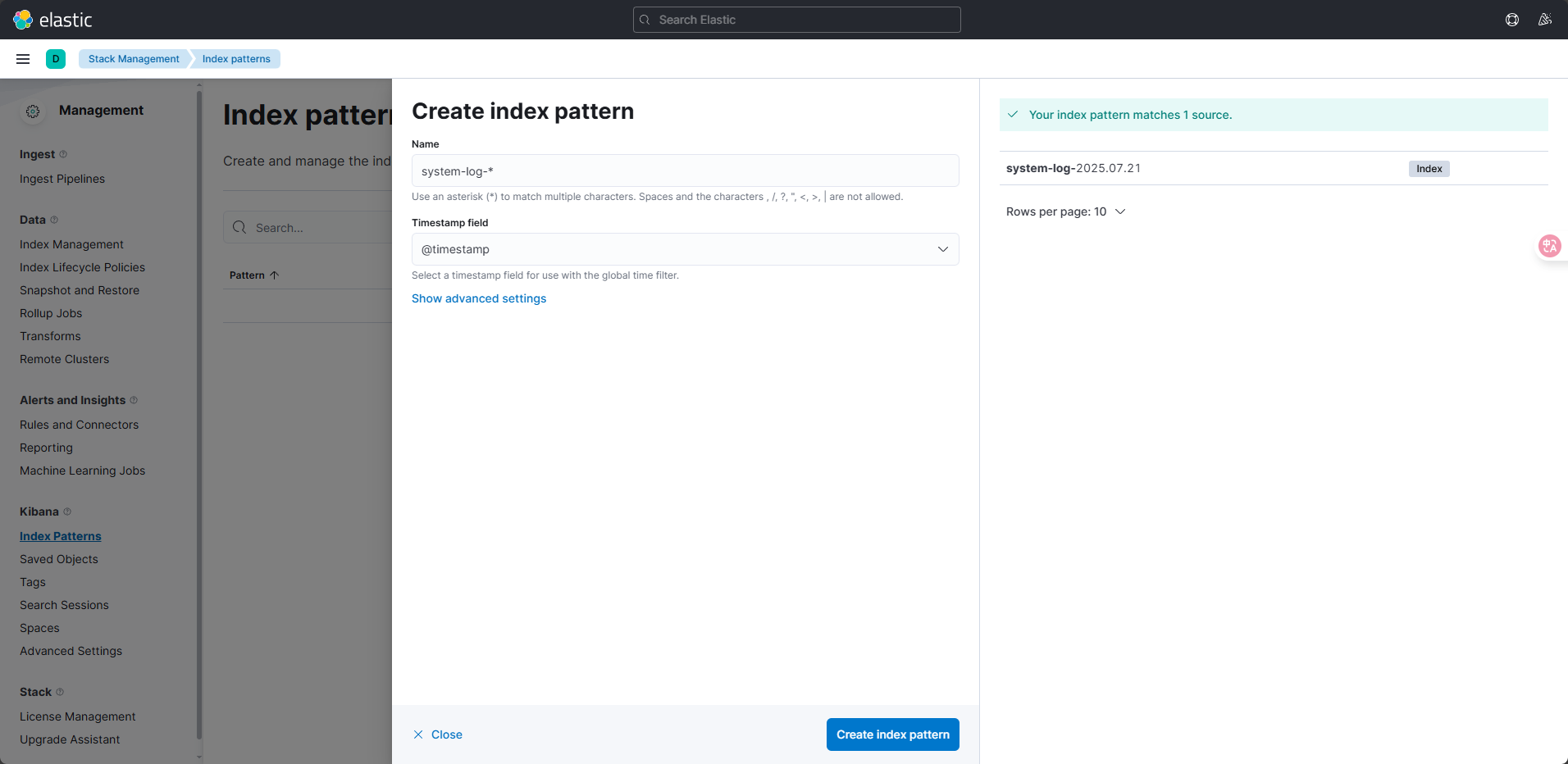
(2)配置 Kibana 索引模式
- 訪問 Kibana 頁面
http://192.168.100.150:5601,進入 Management → Stack Management → Index Patterns。 - 點擊 Create index pattern,輸入索引匹配規則
system-log-*,點擊 Next step。 - 時間字段選擇
@timestamp,點擊 Create index pattern。
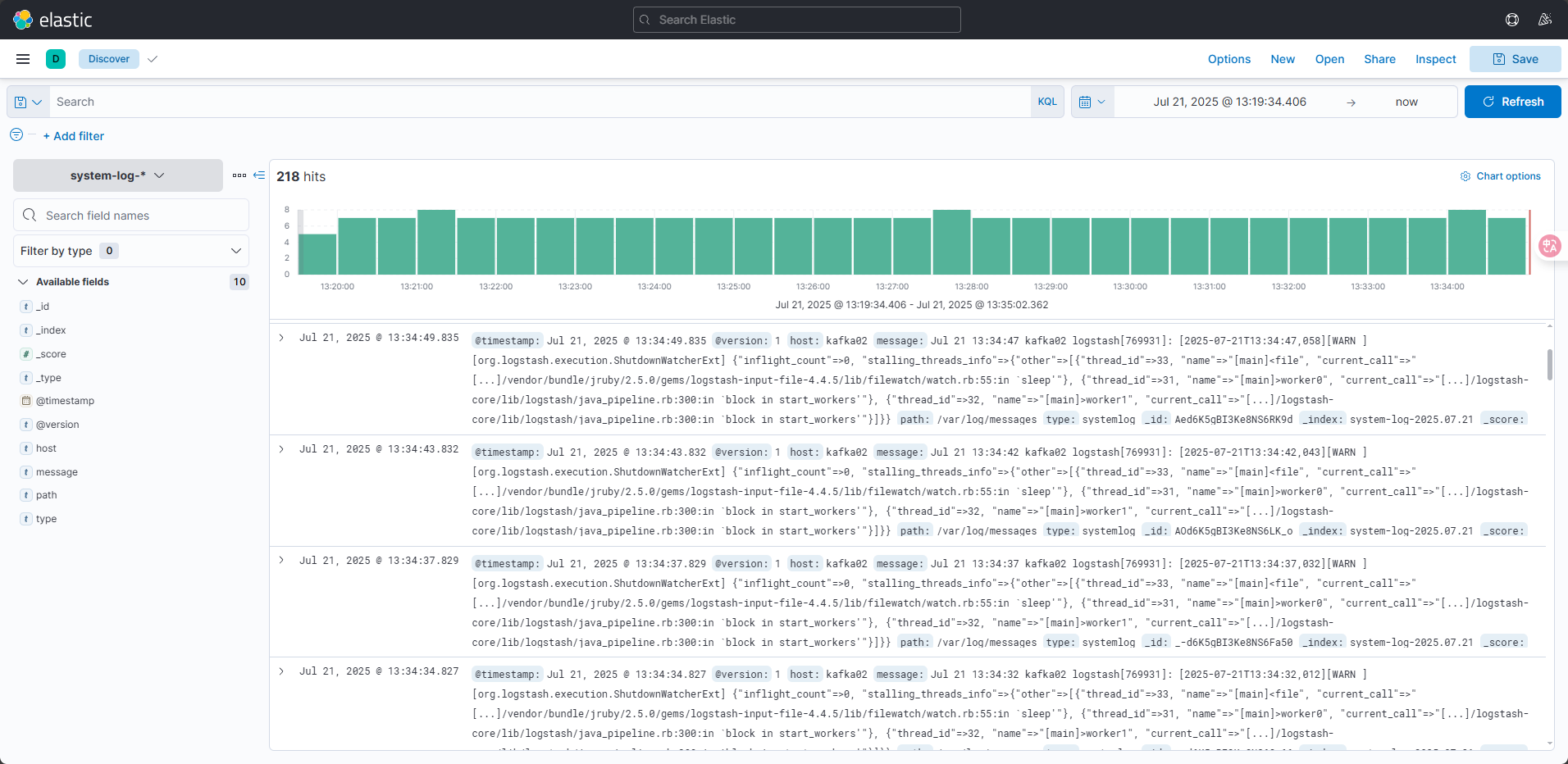
(3)查看日志
點擊左側 Discover,即可看到收集到的系統日志。若提示無數據,通過右上角時間選擇器切換為“Today”(當天)。
常見問題處理
-
Elasticsearch 啟動失敗:
查看日志:journalctl -u elasticsearch -f,常見原因是內存不足(調整jvm.options中的-Xms和-Xmx)。 -
Logstash 無輸出:
檢查日志權限:ls -l /var/log/messages,確保 logstash 用戶有讀取權限。 -
Kibana 無法連接 ES:
驗證elasticsearch.hosts配置是否正確,執行curl http://192.168.100.150:9200確認 ES 可訪問。
通過以上步驟,可在 Rocky Linux 9 上部署兼容且穩定的 ELK 7.17.16 集群,實現系統日志的收集、存儲與可視化分析。

)

的用法)


)

)





 支持控制各種容器,容器操作簡單化 降低容器門檻)




