目錄
一、fork函數初識
二、fork函數返回值
思考:
1. fork函數為何給子進程返回0,而給父進程返回子進程的PID?
2. 關于fork函數為何有兩個返回值這個問題
三、寫時復制機制
寫時拷貝(Copy-On-Write)機制解析
1. 必要性:為什么需要寫時拷貝?
2. 延遲拷貝的優勢:為何不立即拷貝?
3. 代碼段的寫時拷貝適用性
關鍵結論
四、fork函數的常規用法
五、fork調用失敗的原因:
一、fork函數初識
????????在Linux系統中,fork函數是一個關鍵的系統調用,它通過復制現有進程來創建新進程。被創建的進程稱為子進程,而原始進程則稱為父進程。
#include <unistd.h>
pid_t fork(void);
函數返回值:
- 子進程返回0
- 父進程返回子進程的PID
- 出錯時返回-1
當進程調用fork函數時,內核會執行以下操作:
- 為子進程分配新的內存空間和內核數據結構
- 將父進程的部分數據結構內容復制到子進程
- 將子進程添加到系統進程列表
- fork函數返回,由調度器開始進行進程調度
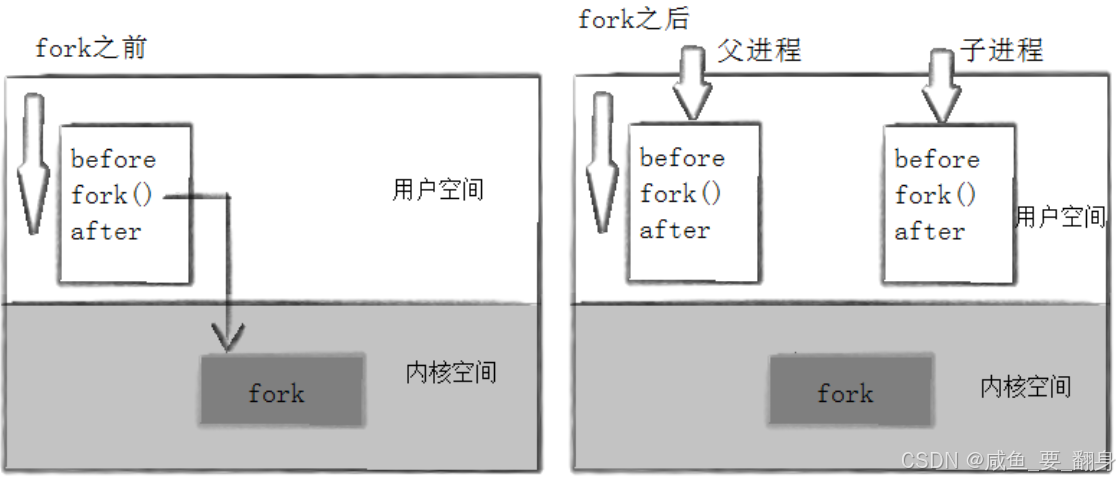
????????當進程調用fork()后,會生成兩個二進制代碼完全相同的子進程。這兩個進程會從相同的執行點繼續運行,但隨后各自進入獨立的執行流程。請看以下示例代碼:
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>int main(void)
{pid_t pid;printf("Before: pid is %d\n", getpid());if ((pid = fork()) == -1) {perror("fork()");exit(1);}printf("After: pid is %d, fork return %d\n", getpid(), pid);sleep(1);return 0;
}
運行結果:
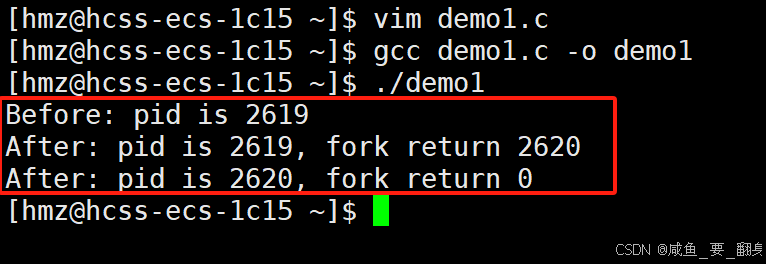
????????輸出內容分為三行:一行"Before"和兩行"After"。進程2619首先打印"Before"消息,隨后又打印了一條"After"消息。另一條"After"消息則是由進程2620打印的。值得注意的是,進程2620并未打印"Before"消息。為什么呢?如下圖所示:
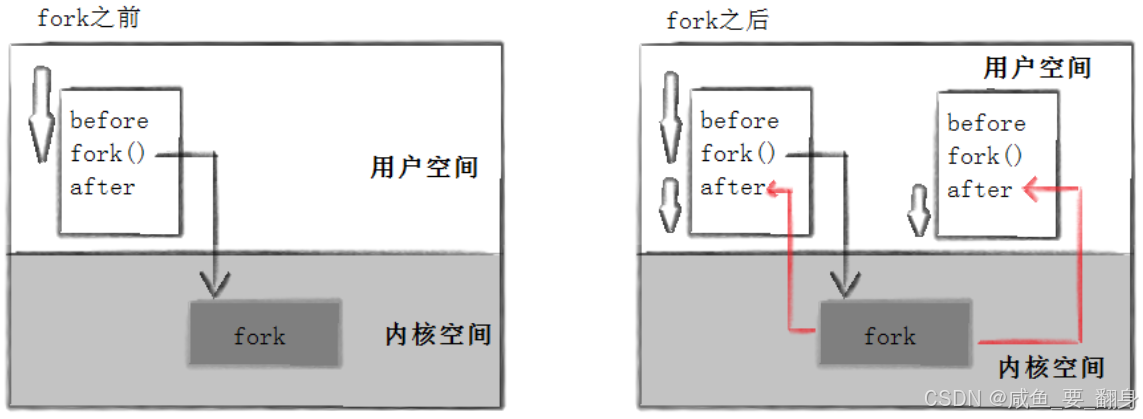
????????在fork調用之前,父進程獨立運行;調用之后,父進程和子進程將各自執行。需要注意的是,fork之后哪個進程先執行完畢,完全取決于系統調度器的安排。
二、fork函數返回值
- 子進程返回0
- 父進程返回子進程的PID
- 出錯時返回-1
思考:
1. fork函數為何給子進程返回0,而給父進程返回子進程的PID?
????????這種設計源于進程間的關系特性:一個父進程可以創建多個子進程,但每個子進程只能有一個父進程。對子進程而言,它無需識別父進程;而對父進程來說,必須明確每個子進程的標識。父進程需要獲取子進程的PID才能有效分配和管理任務。
2. 關于fork函數為何有兩個返回值這個問題
當父進程調用fork函數時,系統會執行一系列創建子進程的操作:
- 創建子進程的進程控制塊
- 建立子進程的進程地址空間
- 生成子進程對應的頁表完成這些步驟后,操作系統會將子進程的進程控制塊加入系統進程列表,此時子進程創建完成。
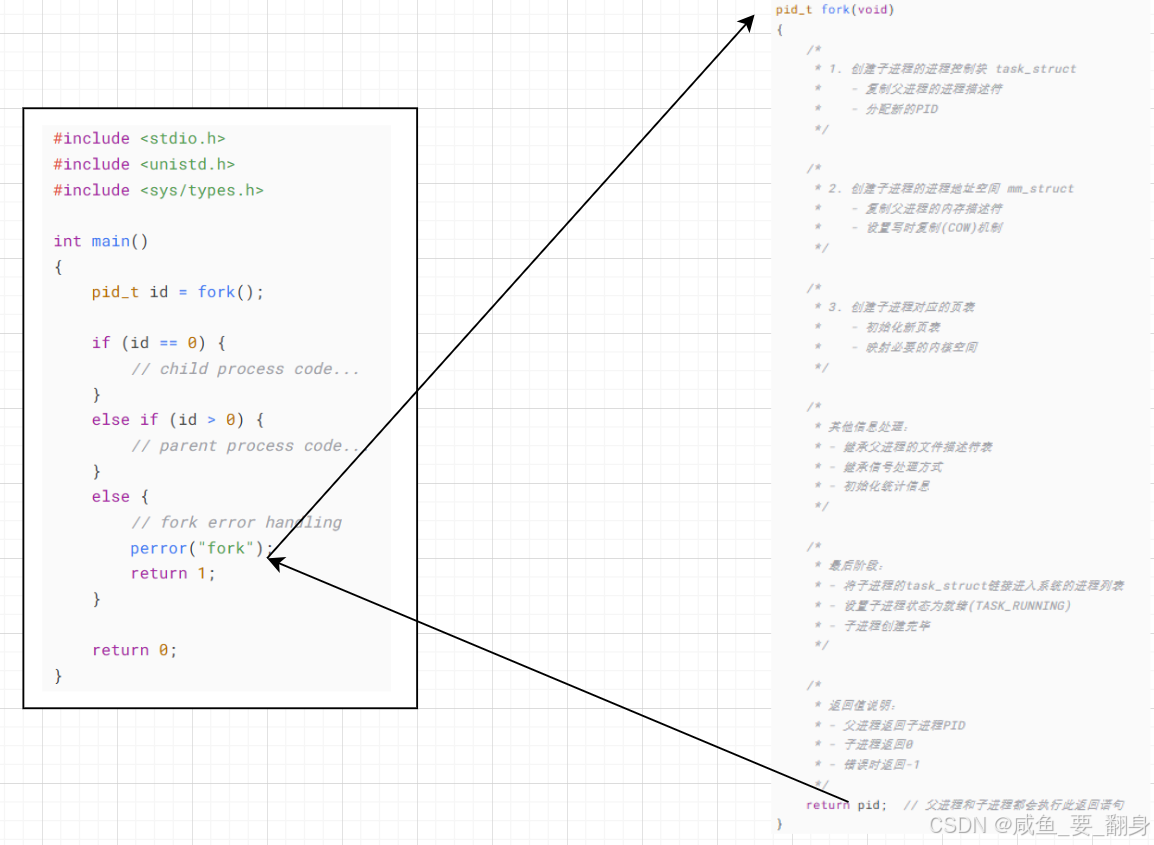
????????換句話說,當fork函數執行return語句時,子進程的創建已經完成。因此,后續的return語句不僅由父進程執行,子進程也會執行同樣的操作,這就解釋了為何fork函數會返回兩個值。
三、寫時復制機制
????????子進程剛創建時,與父進程共享相同的內存數據段和代碼段,兩者的頁表都指向同一塊物理內存區域。只有當父進程或子進程嘗試修改數據時,系統才會執行寫時復制操作,將原始數據復制一份供修改使用。
具體原理如下圖所示:
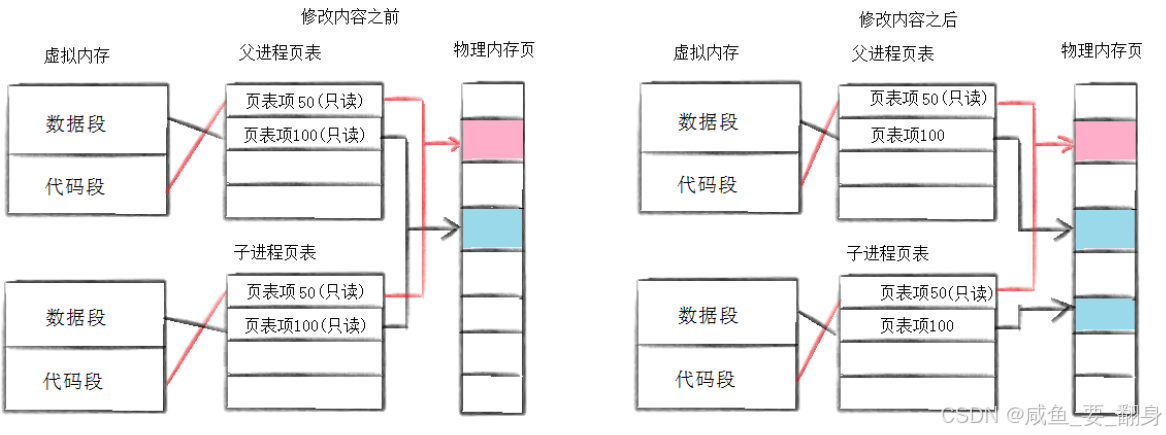
????????得益于寫時拷貝技術,父子進程得以完全分離,從而確保了進程的獨立性。寫時拷貝是一種延遲申請技術,可以有效提高系統內存的使用效率。
這種在需要進行數據修改時再進行拷貝的技術,稱為寫時拷貝技術。
寫時拷貝(Copy-On-Write)機制解析
1. 必要性:為什么需要寫時拷貝?
-
進程獨立性要求
多進程環境下,操作系統需確保各進程資源獨占性。寫時拷貝通過延遲拷貝策略,保證子進程修改數據時才會復制父進程資源,避免進程間數據干擾。 -
性能優化
直接拷貝父進程全部數據會帶來顯著開銷(如內存占用、CPU復制時間),而多數情況下子進程可能僅讀取數據或使用部分資源。
2. 延遲拷貝的優勢:為何不立即拷貝?
-
資源利用率
-
避免冗余拷貝:子進程可能僅訪問父進程部分數據(如只讀代碼段),立即全量拷貝會導致內存浪費。
-
按需分配:僅在子進程嘗試修改數據時觸發拷貝,減少無效的內存占用(例如
fork()后接exec()的場景無需拷貝父進程數據)。
-
-
效率提升
現代操作系統通過頁表映射共享父進程資源,寫時拷貝將實際拷貝操作推遲到最后一刻,顯著降低進程創建開銷。
3. 代碼段的寫時拷貝適用性
-
常規情況(90%以上)
代碼段通常是只讀的,父子進程可共享同一物理內存頁,無需觸發拷貝。 -
例外場景
-
進程替換(如
exec()):新程序加載會覆蓋原代碼段,此時需重新分配內存,本質上仍遵循"修改時拷貝"邏輯。 -
自修改代碼:極少見情況下程序動態修改代碼段內容,會觸發寫時拷貝機制。
-
關鍵結論
寫時拷貝通過共享只讀、延遲寫入的策略,在保證進程獨立性的同時,最大化內存和計算資源的利用率,是操作系統優化進程創建的核心機制。
四、fork函數的常規用法
- 父進程需要復制自身,使父子進程可以執行不同的代碼段。例如,父進程監聽客戶端請求,創建子進程來處理具體請求。
- 進程需要執行新程序。例如子進程在fork返回后調用exec函數。
五、fork調用失敗的原因:
fork函數創建子進程也可能會失敗,有以下兩種情況:
- 系統中有太多的進程,內存空間不足,子進程創建失敗。
- 實際用戶的進程數超過了限制,子進程創建失敗。






)







)


)

