第二章:LLM 交互層
在上一章中,我們學習了作為"項目總控"的管道協調器,它負責協調 RAG 系統中各個功能模塊。
其中最重要的協調對象之一,便是負責與大型語言模型(LLM)進行智能交互的LLM 交互層!
LLM 交互層解決的核心問題
假設我們有一個需要調用多模態 AI “大腦” 來解答復雜問題的智能助手系統,將面臨以下挑戰:
多供應商支持:可能需要使用 OpenAI 的 GPT-4o、Google 的 Gemini 或 IBM 的 WatsonX 等不同廠商的模型差異化接口規范:不同 LLM 服務提供商具有各異的 API 格式要求密鑰管理復雜性:每個服務需要獨立的 API 密鑰認證體系流量控制需求:需處理不同服務的速率限制(Rate Limiting)策略響應格式多樣性:各廠商 API 返回的數據結構存在差異
若在主系統中直接處理這些差異,將導致代碼臃腫和維護困難。這正是LLM 交互層要解決的核心架構問題。
LLM集成&處理,前文傳送:
[AI-video] 數據模型與架構 | LLM集成
[BrowserOS] LLM供應商集成 | 更新系統 | Sparkle框架 | 自動化構建系統 | Generate Ninja
LLM 交互層:智能模型的萬能翻譯官與外交官
LLM 交互層如同連接 RAG 系統與各大 AI 模型的協議轉換中樞,其核心價值在于:
| 功能角色 | 類比 | 技術實現 |
|---|---|---|
| 多協議轉換器 | 語言翻譯官 | 將統一輸入轉換為 OpenAI/Gemini/WatsonX 等各廠商 API 要求的格式 |
| 密鑰外交官 | 安全通行證管理 | 通過環境變量隔離存儲 API 密鑰,動態注入認證信息 |
| 流量調度器 | 高速公路收費站 | 內置速率限制感知與自適應重試機制,防止觸發 API 調用限制 |
| 數據整形師 | 格式標準化專家 | 將異構 API 響應轉換為統一數據結構,支持 JSON 等結構化輸出 |
如何使用 LLM 交互層
在RAG-Challenge-2項目中,通過APIProcessor類實現與各類 LLM 的交互。以下展示兩種典型使用場景:
場景一:基礎問答交互
from src.api_requests import APIProcessor# 初始化 OpenAI 處理器
llm_connector = APIProcessor("openai")# 執行問答交互
response = llm_connector.send_message(human_content="法國的首都是哪里?",system_content="你是一個知識豐富的助手"
)print(response) # 預期輸出:"法國首都是巴黎"(或類似表述)
執行流程解析:
- 實例化
APIProcessor并指定服務商(“openai”) - 通過
send_message發送用戶問題(human_content)與角色定義(system_content) - 交互層自動處理協議轉換、密鑰注入等底層細節
- 返回標準化響應內容
場景二:結構化數據獲取
from src.api_requests import APIProcessor
from pydantic import BaseModel# 定義預期數據結構
class CapitalAnswer(BaseModel):city: str # 城市字段country: str # 國家字段# 初始化處理器
llm_connector = APIProcessor("openai")# 請求結構化響應
response_dict = llm_connector.send_message(human_content="法國的首都是哪里?",system_content="請以JSON格式返回首都信息",is_structured=True, # 啟用結構化模式response_format=CapitalAnswer # 綁定數據模型
)print(response_dict) # 預期輸出:{'city': '巴黎', 'country': '法國'}
關鍵技術亮點:
- 采用
pydantic.BaseModel定義數據契約 is_structured標志位觸發JSON響應解析- 自動校驗響應結構與數據模型的一致性
底層架構
?適配器模式
APIProcessor類(位于src/api_requests.py)是交互層的核心實現,其設計采用"適配器模式"來兼容多廠商API。
前文傳送:
10.STL中stack和queue的基本使用(附習題)

適配器模式就像電源轉接頭,讓不兼容的接口能一起工作。如何實現的呢?再套一層😋
協議適配器工作流
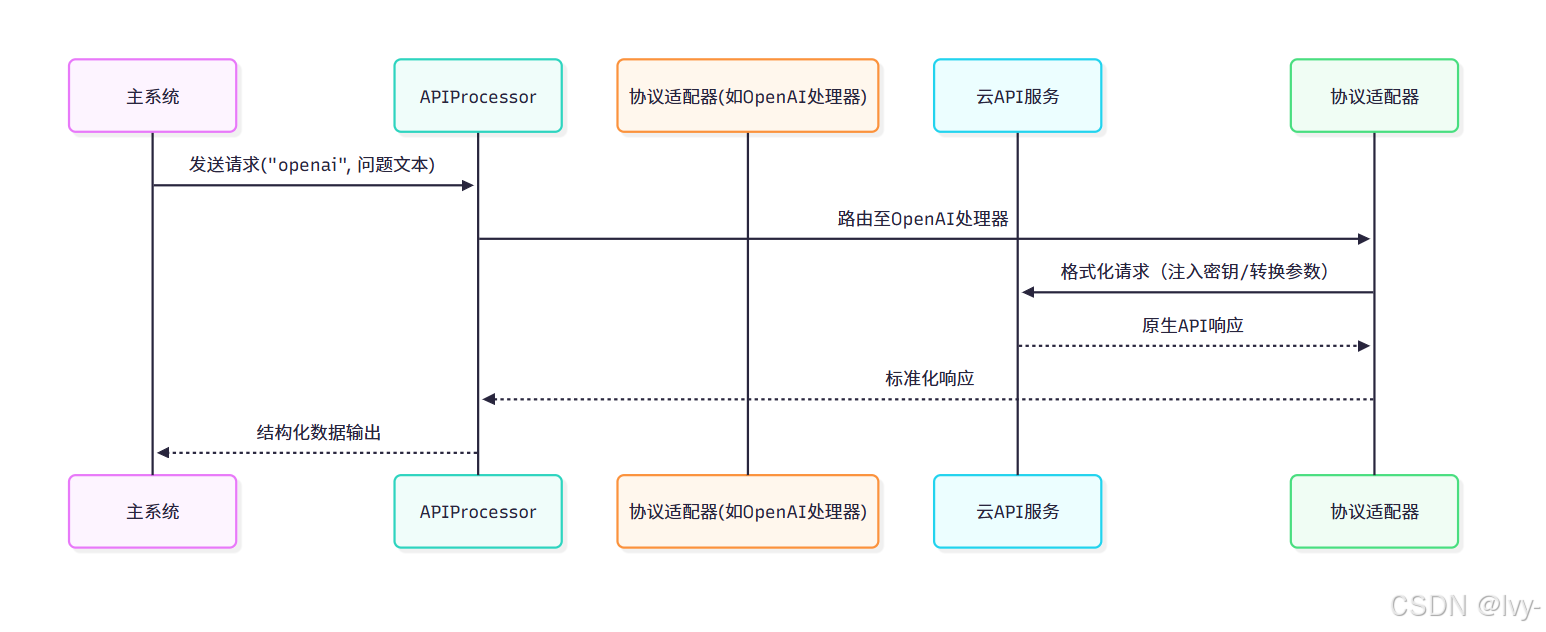
核心組件實現
- 多廠商適配器基類
# 來源:src/api_requests.py(簡化版)
import os
from dotenv import load_dotenv
from openai import OpenAIclass APIProcessor:"""統一交互入口"""def __init__(self, provider="openai"):self.provider = provider.lower()self.processor = self._init_processor() # 動態加載適配器def _init_processor(self):if self.provider == "openai":return BaseOpenaiProcessor()elif self.provider == "ibm":return BaseIBMAPIProcessor()# 支持其他廠商擴展...def send_message(self, **kwargs):"""消息轉發入口"""return self.processor.send_message(**kwargs)class BaseOpenaiProcessor:"""OpenAI協議適配器"""def __init__(self):load_dotenv() # 加載環境變量self.llm = OpenAI(api_key=os.getenv("OPENAI_API_KEY")) # 密鑰注入self.default_model = 'gpt-4o-mini-2024-07-18' # 默認模型版本def send_message(self, model=None, **kwargs):"""OpenAI專用請求封裝"""params = {"model": model or self.default_model,"messages": [{"role": "system", "content": kwargs.get("system_content")},{"role": "user","content": kwargs.get("human_content")}]}# 執行API調用completion = self.llm.chat.completions.create(**params)return completion.choices[0].message.content # 響應解析
實現了一個支持多AI廠商API調用的適配器系統,核心是通過
統一接口屏蔽不同廠商API的差異。
核心組件
APIProcessor類(主入口)
- 初始化時通過
provider參數指定廠商(如openai/ibm) - 自動創建對應的廠商適配器實例(如
BaseOpenaiProcessor) - 提供統一的
send_message方法轉發請求
BaseOpenaiProcessor類(廠商實現)
- 專屬OpenAI的初始化流程:
- 加載環境變量獲取API密鑰
- 預置默認模型版本
- 請求處理邏輯:
- 組裝符合OpenAI規范的請求結構
- 包含system/user角色的消息體
- 自動選擇默認模型(可覆蓋)
- 解析返回結果的第一條消息
設計特點
- 開閉原則:新增廠商只需添加新適配器類,無需修改主入口代碼
- 環境隔離:各廠商的密鑰管理和請求邏輯相互獨立
- 默認配置:
內置常用模型版本降低調用復雜度
?調用示例
processor = APIProcessor("openai")
response = processor.send_message(system_content="你是一個翻譯助手",human_content="Hello world"
)
- 高級功能實現
- 密鑰安全管理:通過
.env文件隔離敏感信息,防止密鑰硬編碼 - 流量控制:集成
api_request_parallel_processor模塊實現:- 自動重試機制(網絡波動容錯)
- 動態速率調節(基于API反饋實時調整QPS)
- 批量請求優化(提升吞吐量)
- 結構化校驗:利用
pydantic模型實現響應數據的模式校驗與自動修復
總結
LLM交互層作為RAG系統的"外交中樞",通過:
- 協議抽象:統一不同廠商API的調用差異
- 安全隔離:集中管理敏感認證信息
- 彈性通信:內置智能重試與流量整形
- 數據契約:強化結構化數據可靠性
(我們會發現,如果抽象的好的話,許多想實現的小功能,都有對應的庫或者方案可以直接像適配器一樣調用,我們只需要 改一些參數即可)
使上層業務邏輯能夠專注于知識處理流程,而不必深陷多廠商API的兼容性泥潭。
這種分層設計顯著提升了系統的可維護性與可擴展性。
下一章:文檔解析器
第三章:文檔解析器
在上一章中,我們了解了LLM交互層——與強大AI模型對話的通用翻譯器。
但在系統能夠提出智能問題并獲得答案之前,它需要理解源文檔中的信息。想象我們擁有一個裝滿珍貴書籍(PDF)的大型圖書館,但它們都是原始的紙質文檔!我們無法搜索、用計算機輕松閱讀或提取具體數據。
這正是文檔解析器大顯身手的時刻。
向量檢索重要性在前文有提到:
[Andrej Karpathy] 大型語言模型作為新型操作系統
文檔解析器解決的核心問題
假設我們有一批來自不同公司的PDF報告,這些報告包含豐富的信息:常規文本、詳細表格和說明性圖片。要構建能夠回答"根據財務報告,X公司2023年的營收是多少?"這類問題的智能系統,首先需要讀取并理解這些PDF文檔。
PDF文檔存在天然復雜性:
- 格式混雜性:混合文本、圖像和表格的復雜排版
- 結構模糊性:簡單復制粘貼可能導致結構丟失或表格錯位
- 數據非標性:顯示優化的布局不利于機器解析
文檔解析器的核心使命是:
- 全要素提取:完整獲取文本、表格和圖像
- 語義結構理解:識別段落歸屬、表格邊界和圖片關聯
- 數字格式重構:將異構數據轉換為系統可處理的標準化格式
?文檔解析器:智能數字檔案員
文檔解析器如同精通多模態的檔案管理員。
當輸入原始PDF時,它不僅拍攝頁面快照,而是深度解析每個元素:
| 功能角色 | 技術實現 |
|---|---|
| 智能掃描儀 | 采用docling庫實現PDF深度解析,支持OCR光學字符識別 |
| 數據萃取器 | 將復雜表格轉換為Markdown結構化數據,保留表格行列關系 |
| 內容整合器 | 按頁面組織文本塊,識別標題層級,建立跨頁面引用關系 |
| 數字歸檔系統 | 輸出標準化JSON格式,支持后續向量化處理 |
之后會在py相關專欄,探索這個庫(🕳+1)
如何使用文檔解析器
通過管道協調器觸發文檔解析流程:
python main.py parse-pdfs
核心代碼邏輯如下:
# 來源:src/pipeline.py(簡化版)
from src.pdf_parsing import PDFParserclass Pipeline:def parse_pdf_reports(self):"""PDF解析總控方法"""pdf_dir = self.paths.raw_reports_path # 原始PDF存儲路徑output_dir = self.paths.parsed_reports_path # 解析結果輸出路徑parser = PDFParser(output_dir=output_dir,csv_metadata_path=self.paths.subset_path # 可選元數據關聯)parser.parse_and_export(doc_dir=pdf_dir) # 啟動解析流程
執行流程解析:
- 路徑初始化:通過
_initialize_paths方法建立輸入/輸出目錄結構 - 解析器配置:加載
docling文檔轉換器,啟用表格檢測和OCR功能([11]) - 批量處理:遍歷指定目錄下的所有PDF文件進行異步解析([18])
- 結果序列化:將結構化數據保存為JSON文件,保留原始文檔SHA1哈希作為文件名
輸出示例(data/debug/parsed_reports/xxx.json):
{"metainfo": {"sha1_name": "f5d2...a89c","pages_amount": 42,"company_name": "TechCorp"},"content": [{"page": 1,"blocks": [{"type": "heading", "text": "2023年度財務報告"},{"type": "paragraph", "text": "本年度總收入..."}]}],"tables": [{"table_id": 0,"markdown": "| 季度 | 營收(百萬) |\n|------|-------------|\n| Q1 | 120 |","page": 5}]
}
底層架構
文檔解析器采用分層處理架構:
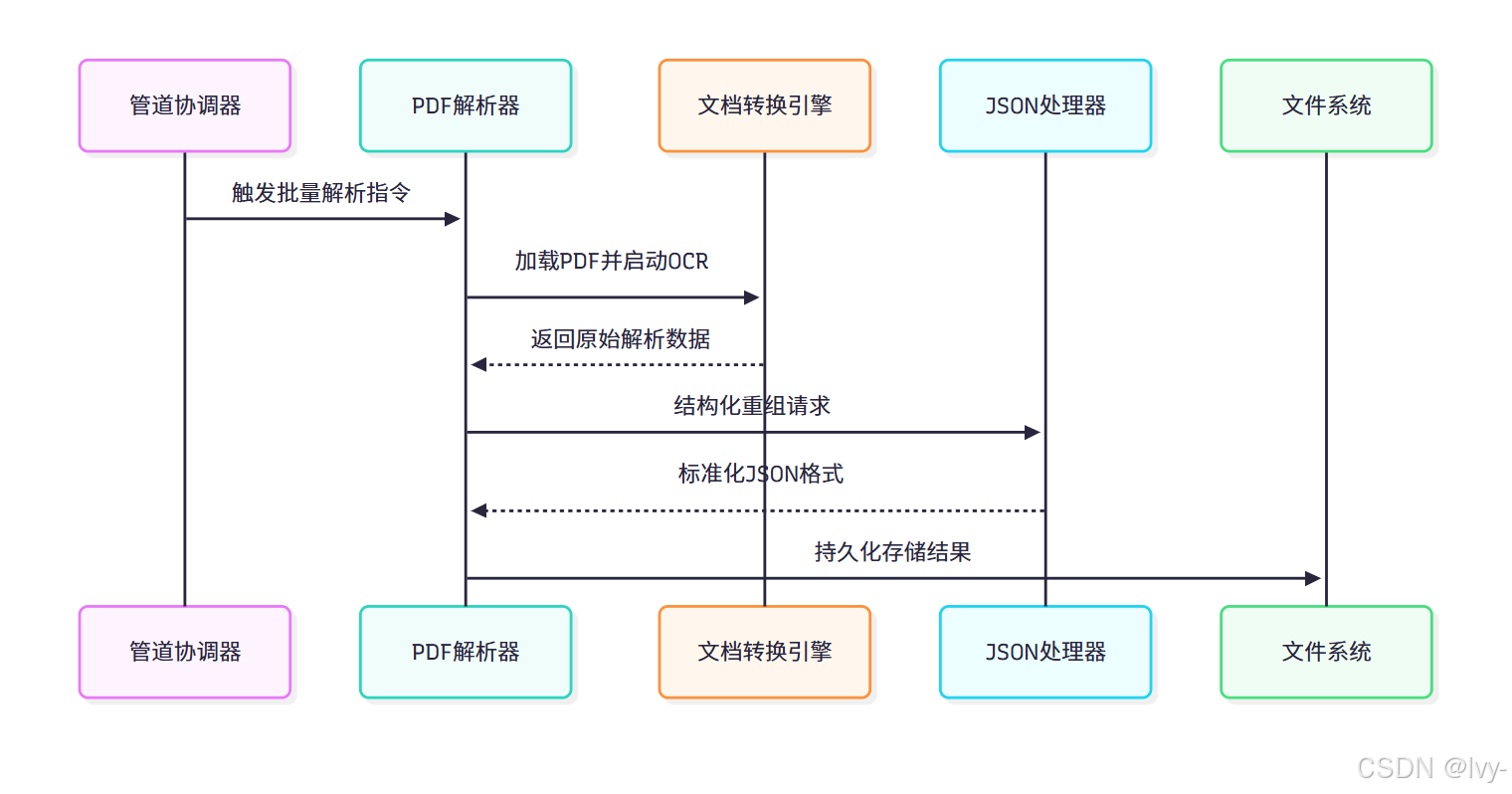
核心組件詳解:
1. PDFParser 類
class PDFParser:def __init__(self, output_dir: Path, csv_metadata_path: Path = None):self.doc_converter = self._create_document_converter() # 初始化轉換引擎self.metadata_lookup = self._parse_csv_metadata(csv_metadata_path) # 加載元數據def _create_document_converter(self):"""配置文檔轉換引擎"""return DocumentConverter(enable_ocr=True, # 啟用圖像文字識別table_detection_mode=2 # 增強表格檢測)
2. ?文檔轉換引擎
- 基于
docling庫實現多線程解析 - 支持PDF/Word格式轉換
- 表格檢測采用CNN神經網絡識別表格邊界
CNN神經網絡
一種模仿人眼視覺原理的深度學習模型,通過局部感知和層次化提取特征(如邊緣→紋理→物體部分→整體),自動識別圖像中的模式。
CNN神經網絡識別表格邊界,就像用放大鏡掃描表格圖片,通過局部感知自動找到橫豎線條的交匯處,最終框出表格的外框和內部格子。
3. JsonReportProcessor 類
class JsonReportProcessor:def assemble_tables(self, tables_raw_data, data):"""表格結構化處理"""for table in tables_raw_data:# 轉換復雜表格為Markdowntable_md = self._table_to_md(table)# 建立表格與頁面的映射關系yield {"table_id": idx,"markdown": table_md,"page_ref": data['tables'][idx]['prov'][0]['page_no']}
關鍵技術突破:
- 版面分析算法:采用計算機視覺技術識別
文檔元素空間關系 - 增量式OCR:僅在檢測到圖像文本時
觸發識別,優化處理速度 - 表格重建引擎:通過
行列檢測算法還原復雜合并單元格
增量式OCR
一種動態識別技術,僅對文檔中新修改或新增的部分進行文字識別,避免全量重復處理,類似"只掃描最新添加的筆跡"。
行列檢測算法是一種用于在圖像中識別并定位表格、表單等行列結構的計算機視覺技術。其核心思想是通過分析圖像中的水平或垂直線條分布,將像素按行或列分組,從而提取結構化數據。
行列檢測算法
通過邊緣檢測或投影分析找到密集的水平/垂直直線群,根據直線聚類結果劃分行列區域。
常用霍夫變換或投影直方圖峰值檢測實現。
代碼(Python+OpenCV)
import cv2
import numpy as npdef detect_grid(image_path):# 讀取圖像并轉為灰度img = cv2.imread(image_path)gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)# 二值化處理_, thresh = cv2.threshold(gray, 240, 255, cv2.THRESH_BINARY_INV)# 霍夫線變換檢測直線lines = cv2.HoughLinesP(thresh, 1, np.pi/180, 100, minLineLength=100, maxLineGap=10)# 繪制檢測結果for line in lines:x1,y1,x2,y2 = line[0]cv2.line(img, (x1,y1), (x2,y2), (0,255,0), 2)return img
使用示例:
result = detect_grid("table.png")
cv2.imwrite("result.jpg", result)
應用場景:
- 文檔掃描中的表格識別
- 票據數據提取
- 答題卡自動閱卷
- 財務報表數字化
霍夫變換
通過投票機制在圖像中找出直線、圓等幾何形狀的方法,比如讓所有可能的直線“投票”給最可能存在的形狀。
投影直方圖峰值檢測
將圖像像素按方向(如水平/垂直)投影統計,通過找直方圖的最高點定位目標位置(如文字行或物體邊緣)。
詳見之后的opencv專欄~
總結
文檔解析器作為RAG系統的數據入口,通過:
- 多模態解析:融合文本、圖像和表格處理能力
- 智能重構:將印刷文檔轉化為機器可讀的語義網絡
- 彈性擴展:支持插件式集成新文檔格式
為后續的向量化存儲和語義檢索奠定了高質量數據基礎。這種精細化的預處理機制,使得原始文檔中的隱性知識得以顯性化表達,極大提升了系統的事實性回答能力。
下一章:文檔準備與格式化




:多叉樹)
中的節能控制(一))





![[Mysql] Connector / C++ 使用](http://pic.xiahunao.cn/[Mysql] Connector / C++ 使用)





)

