傾向評分匹配(Propensity Score Matching,簡稱PSM)是一種統計學方法,用于處理觀察研究(Observational Study)的數據,在SCI文章中應用非常廣泛。在觀察研究中,由于種種原因,數據偏差(bias)和混雜變量(confounding variable)較多,傾向評分匹配的方法正是為了減少這些偏差和混雜變量的影響,以便對實驗組和對照組進行更合理的比較。
為什么需要做傾向評分匹配?
我們知道RCT的證據力度高,是因為對患者進行了嚴格的篩選。我們的回顧性研究都是過去的數據,很難像RCT一樣進行嚴格的篩選出兩組患者基線相近的基礎資料,但我們可以通過傾向評分匹配把回歸性的數據進行篩選,把基線資料相近的患者進行匹配,得到近似RCT的效果。
應用場景
? 1.基線資料不平
? 2.開展病例對照研究病陽性例數較少,如罕見病研究
? 3.將眾多混雜因素變為一個變量:傾向值
以下為一個實例,沒進行匹配前兩組患者基線資料相差很大,進行傾向評分匹配后,基線資料近似一致了

既往咱們已經介紹了Matching包進行傾向評分匹配,今天咱們來介紹nonrandom包進行傾向評分匹配,這個包需要在github上安裝,咱們先把這個包安裝上去
library(devtools) # Load devtools
install_github("cran/nonrandom")
安裝好后R導入R包自帶得stu1數據
library(nonrandom)
data(stu1)

我介紹幾個關鍵變量,pst是咱們得結局變量,therapie是等會咱們要進行匹配得變量,是兩種治療方法:1:乳房切除術;2:保乳 ,其他都是一些協變量
咱們可以先看下沒調整前協變量對模型得影響
rel.eff <- relative.effect(data = stu1,formula = pst~therapie+tgr+age)
summary(rel.eff)

剛才已經說了,我們是要對therapie兩種治療方法:1:乳房切除術;2:保乳進行匹配,好查看預后,先進行傾向評分
ps <- pscore(data = stu1,formula = therapie~tgr+age)
對根據PS數據分層
strata <- ps.makestrata(object = ps)
對分層數據進行傾向評分匹配,ratio = 1是1:1匹配,caliper
表示卡鉗
match <- ps.match(object = ps,ratio = 1,caliper = 0.5,givenTmatchingC = FALSE)
匹配好后可以從match中提取匹配好后得數據
data.matched<-match[["data.matched"]]

對匹配后得數據進行可視化
bal.plot1 <- dist.plot(object = strata,sel = c("tmass"))

bal.plot2 <- dist.plot(object = match,sel = c("alter"),plot.type = 2,compare = TRUE)
bal.plot2
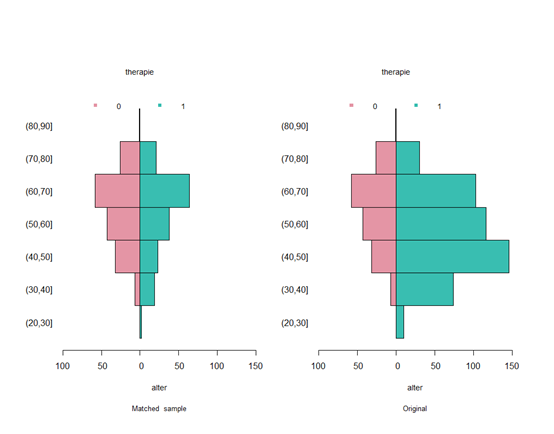
可以看出匹配前和匹配后差別很明顯,還可以比較標準化差異
bal.table <- ps.balance(object = match,sel = c("tgr","age"),method = "stand.diff",alpha = 20)
bal.table

還可以比較匹配前后對效應值得影響
ps.est <- ps.estimate(object = strata,resp = "pst",regr = pst~therapie+tgr+age)
ps.est


和bind_layer的應用)




 教程)


 案例詳解)









)