大家讀完覺得有幫助記得關注和點贊!!!
抽象。
數值黑盒優化中的自動算法性能預測通常依賴于問題特征,例如探索性景觀分析特征。這些特征通常用作機器學習模型的輸入,并以表格格式表示。然而,這種方法往往忽略了算法配置,而算法配置是影響性能的關鍵因素。算法運算符、參數、問題特征和性能結果之間的關系形成了一個復雜的結構,最好用圖表表示。
這項工作探索了異構圖數據結構和圖神經網絡的使用,通過捕獲問題、算法配置和性能結果之間的復雜依賴關系來預測優化算法的性能。我們重點介紹兩個模塊化框架 modCMA-ES 和 modDE,它們分解了兩種廣泛使用的無導數優化算法:協方差矩陣適應進化策略 (CMA-ES) 和差分進化 (DE)。我們在 6 個運行預算和 2 個問題維度上評估了 24 個 BBOB 問題的 324 個 modCMA-ES 和 576 個 modDE 變體。
在M?S?E與傳統的基于表格的方法相比,這項工作突出了幾何學習在黑盒優化中的潛力。
CCS:?計算方法連續空間搜索CCS:?計算方法通過回歸進行監督學習CCS:?計算方法神經網絡
1.介紹
數值黑盒優化長期以來一直是一個活躍的研究領域,導致開發了許多優化算法。因此,自動算法性能預測等元學習任務(Trajanov?等人,2021)、算法配置(Schede 等人,2022)和算法選擇(Kerschke 等人,2019)對于確定最適合給定問題的算法變得越來越重要。
多年來,已經引入了許多新穎的算法思想,以及對眾所周知的無導數優化算法的逐步改進,例如協方差矩陣適應進化策略 (CMA-ES)(Hansen 和 Ostermeier,1996)和差分進化 (DE)(斯托恩和普萊斯,1997).這些進步進一步使優化算法的前景多樣化,使得系統地比較和選擇它們更具挑戰性。
為了解決這個問題,模塊化優化框架(如 modCMA-ES(de Nobel?等人,2021)和 modDE(Vermetten 等人,2023)將 CMA-ES 和 DE 分解為模塊化組件,使研究人員能夠分析不同的配置和參數設置如何影響性能。通過捕獲有關算法結構和交互的詳細信息,這些框架為算法分析提供了豐富的資源。然而,盡管它們具有潛力,但它們在元學習任務中仍然沒有得到充分利用。
傳統的算法性能預測方法通常依賴于問題特征的表格表示,例如探索性景觀分析 (ELA)(Mersmann 等人,2011).雖然有效,但這些方法無法捕捉問題、算法、配置和性能結果之間復雜的相互依賴關系。將這些實體表示為圖形中的節點,邊緣捕獲它們的關系,自然地反映了數據的關系結構,并支持更豐富的建模。
幾何學習,機器學習的一個分支,用于處理非歐幾里得域(如圖和流形)中的數據(Bronstein?等人,2017)為這項任務提供了合適的框架。它的方法范圍從淺節點嵌入到更高級的圖形神經網絡 (GNN),所有這些都利用數據中的關系和拓撲信息。
此概念的早期演示涉及將性能預測建模為鏈接預測任務。具體來說,在我們之前的工作中(Kostovska 等人,2023b),我們采用淺節點嵌入來推斷模塊化優化算法和黑盒問題之間的“缺失”性能鏈接,如果算法在固定的函數評估預算內達到預定義的精度閾值,則將鏈接標記為已解決。雖然有效,但這種方法將性能預測視為二元分類任務,而不是更具表現力的回歸問題。此外,淺層嵌入將框架限制在轉導學習上,將泛化限制在看不見的問題上。
GNN 通過捕獲高階依賴關系和實現歸納學習來解決這些限制。雖然尚未應用于模塊化優化算法,但 GNN 已成功應用于相關領域。例如,Lukasik 等人。(Lukasik 等人,2021)使用 GNN 預測 NAS-Bench-101 上的神經架構性能(Ying 等人,2019 年b)和 Singh 等人。(Singh 等人,2021)將深度網絡建模為圖形以改進運行時預測。Chai 等人。(Chai 等人,2023)提出了 PerfSAGE,這是一種基于 GNN 的模型,用于預測邊緣設備上神經網絡的推理延遲、能耗和內存占用。
我們的貢獻:在這項研究中,我們應用 GNN 來預測模塊化優化算法的性能。首先,我們提出了一種異構圖表示,對來自?modCMA-ES?和?modDE?的數據進行編碼,在統一的圖結構中捕獲問題、算法組件、參數和性能。其次,基于這種表示形式,我們引入了一個消息傳遞 GNN 框架,該框架旨在對異構圖進行作,在性能節點上執行節點回歸,以預測算法在給定問題上的性能。最后,我們提出了實驗,表明與傳統的表格方法相比,通過基于圖形的模型合并關系結構可以提高預測性能。
大綱:本文的其余部分結構如下:第 2?節詳細介紹了我們研究中采用的方法,包括圖形構造和 GNN 設計。第?3?節概述了實驗設置。第?4?節介紹了研究的結果,第?5?節總結了對未來工作的見解和方向。
代碼和數據:本研究中使用的所有相關代碼和數據均可在以下網址獲得:https://github.com/KostovskaAna/GNN4PerformancePrediction。
2.方法論
本節概述了我們在模塊化優化框架的基準測試數據上使用 GNN 預測算法性能的方法。我們描述了異構圖表示,然后是 GNN 模型架構。

圖 1.異構圖的元圖。
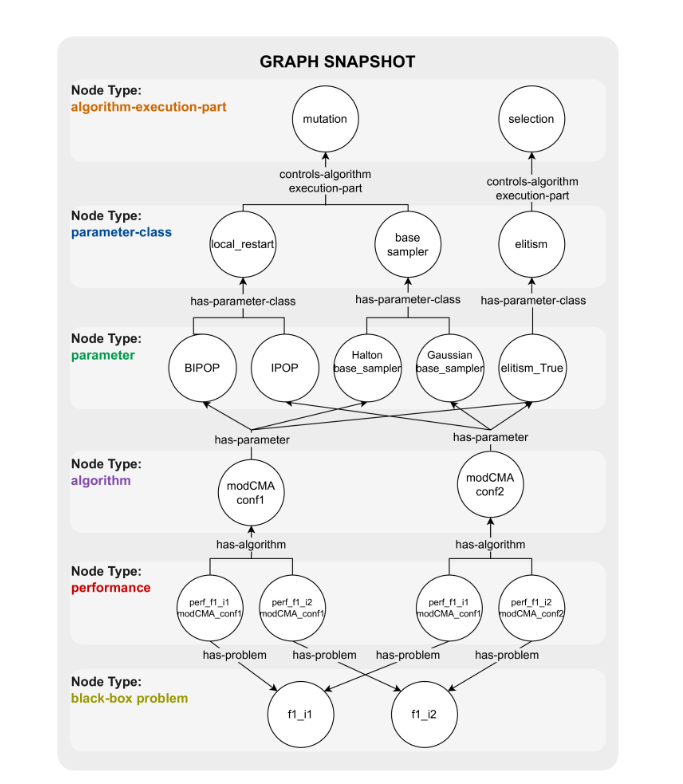
圖 2.元圖實例化的圖示,顯示異構圖的快照。
2.1.圖形表示
我們使用異構圖來捕獲黑盒優化問題、模塊化優化算法、它們的配置和相應的性能分數。
異構圖?(HG) 定義為圖形H?G={𝒱,?,?,𝒯}哪里𝒱表示節點集,?表示邊集,?表示關系類型的集合,并且𝒯表示節點類型的集合。每個節點v∈𝒱通過映射函數與節點類型關聯T?(v):𝒱→𝒯和每條邊e∈?通過映射函數與關系類型關聯R?(e):?→?.要使圖形被視為異構圖形,不同節點和關系類型的和必須大于 2,即|𝒯|+|?|>2.除了類型映射之外,每個節點v∈𝒱與特征向量關聯𝐱v∈?d哪里d表示特征空間的維數。這些節點功能對節點的屬性進行編碼。
在圖?1?中,我們說明了我們提出的異構圖的元圖。這個元圖是我們的H?G代表𝒯(節點類型集)作為節點,將?(關系類型的集合)作為它們之間的邊。它包括參數、參數類、算法執行部分、算法、性能、黑盒優化問題六種節點類型,以及五種邊(關系)類型:has-parameter、has-parameter-class、controls-algorithm-execution-part、has-algorithm?和?has-problem。
在圖?2?中,我們說明了𝒱和?,提供相應異構圖的快照。它顯示了兩個黑盒問題、兩個算法變體及其關聯的性能節點和參數。這些參數屬于?local_restart、?base_sampler?和?elitism?類,影響算法執行的不同部分。我們根據問題維度、運行時間預算和算法類型的獨特組合構建一個圖,從而產生多個圖實例。
2.2.GNN 架構設計
我們采用異構消息傳遞 GNN 架構來處理圖中的多個節點和關系類型。從本質上講,GNN 中的消息傳遞涉及每個節點從其鄰居那里收集“消息”,并對其進行轉換和組合以更新自己的表示形式。在異構設置中,不同的節點和邊緣類型需要不同的消息傳遞函數或聚合過程,這是文獻中公認的方法(Zhang 等人,2019).因此,每種關系類型r指示消息如何從tu到類型為tv.在聚合每個關系的消息后,我們整合所有相關關系類型的輸出,以形成更新的節點嵌入。在多個層上重復此過程使節點能夠從圖形中越來越遠的部分捕獲信息。
我們的架構支持堆疊多個消息傳遞層(參見圖?3)。我們使用 GraphSAGE(Hamilton?等人,2017)的歸納功能,盡管其他消息傳遞層也兼容。每一層都執行特定于關系的聚合,然后執行交叉關系聚合,通過激活函數引入非線性,并應用隨機失活以防止過擬合。
學習任務是節點回歸,其目標是預測算法在特定問題實例上的性能。每個性能節點都與一個數字分數相關聯,GNN 通過利用異構圖的結構和特征來學習預測它。最終的 GNN 嵌入通過線性層來預測性能值y^.
請注意,這種經過訓練的模型能夠跨不同的算法變體進行泛化,預測給定運行時預算和問題維度下所有模塊化算法變體的性能。此外,盡管輸入圖(圖?2)是有向的,但我們添加了反向邊緣,有效地將圖視為無向圖。這實現了雙向信息流并改進了表示學習。

圖 3.用于使用異構圖預測算法性能的消息傳遞 GNN 架構概述。
3.實驗裝置
3.1.數據采集
3.1.1.問題實例組合和態勢數據。
我們使用了 COCO 環境中 BBOB 基準測試套件中的 24 個單目標、無噪聲、連續黑盒問題(Hansen 等人,2020).每個問題都包含通過轉換(如 offsets 和 scalings)生成的多個實例。我們為維度D=5和D=30.為了表示問題態勢,我們使用了?OPTION KB?中提供的 46 個 ELA 功能?(Kostovska 等人,2023 年一).
3.1.2.算法實例和配置。
我們考慮兩種模塊化算法:?CMA-ES?和?DE。對于 CMA-ES,我們使用 modCMA-ES 框架(de Nobel?等人,2021),其中包括采樣分布、加權方案和重啟策略的變化。對于 DE,我們使用 modDE 軟件包(Vermetten 等人,2023),它支持一系列突變運算符、堿基選擇選項、交叉策略和受最先進的 DE 變體啟發的更新機制。有關模塊和參數空間的完整詳細信息,請參閱(Kostovska 等人,2023b),此數據已從中重復使用。
我們總共分析了 324 個 modCMA-ES 和 576 個 modDE 變體。每個都根據六個功能評估預算進行評估,B∈{50?D,100?D,300?D,500?D,1000?D,1500?D}哪里D∈{5,30}.記錄在每個預算下實現的最佳精度(即與最佳精度的距離)。
本研究中使用的所有數據均重復使用自 Kostovska 等人。(Kostovska 等人,2023b)并通過?OPTION KB?訪問(Kostovska 等人,2023 年一).
3.2.模型訓練和評估
我們使用深度圖庫 (DGL) 實現 GNN 架構(王,2019)預測模塊化優化算法的性能。該模型使用基于 GraphSAGE 算法的?SageConv?層(Hamilton?等人,2017),用于按關系消息聚合。然后使用?HeteroConv?層將這些嵌入進行組合以進行交叉關系聚合。均值聚合應用于關系內,而求和則用于關系。
我們使用 4 層 GNN 來捕獲所有相關的算法信息。問題節點由 46 個 ELA 特征表示,而其他節點類型的特征使用 Kaim 均勻分布進行初始化。我們使用 GELU(Hendrycks 和 Gimpel,2016)to 引入非線性。
我們執行嵌套交叉驗證以調整輟學率 (0.1、0.2、0.3) 和嵌入大小 (32、64、128),每個實驗重復 10 次。使用 L1 損失訓練模型 200 個 epoch,并使用 Adam 進行優化(Kingma 和 Ba,2014)(學習率 0.1,每 20 個停滯 epoch 減半)。我們采用與之前工作相同的?leave-instance-out 嵌套交叉驗證協議(Kostovska 等人,2024),我們在其中訓練 46 個 ELA 特征的隨機森林 (RF) 回歸器。這些是評估我們的 GNN 模型的基線。
4.結果
在上述設置的基礎上,我們進行了實驗來預測模塊化算法的性能。表?1?顯示了兩個維度和六個預算的 MSE 分數,僅使用 Kostovska 等人的表格 ELA 特征將 GraphSAGE 模型與射頻基線進行了比較。(Kostovska 等人,2024).
GNN 在所有設置下通常都優于 RF。對于 modCMA 和5?D問題維度,GNN 將 MSE 提高0.03–0.06對于較低的預算 (50?D,100?D),而對于較大的預算(例如5.19→4.57在1500?D).在30?D問題維度,中高預算的收益更為明顯,例如,在100?D,MSE 從0.27自0.19和1000?D,則相對改進達到36.6%.
對于 modDE 在5?D,對于大多數預算,GNN 的 MSE 低于 RF,其中改善最大,為300?D和500?D.在30?D,GNN 的性能始終優于 RF。最佳增益在100?D,其中 MSE 從0.25自0.19,則相對提高24%.在500?D,則增益為15.8%.
表 1.這M?S?EGNN 和 RF 回歸模型的分數,用于預測 5 維和 30 維 BBOB 問題實例的模塊化算法變體的性能。
| 預算? | CMA-ES 5D 顯示器 | 電子產品 CMA-ES 30D | DE 5D | DE 30D 餐廳 | ||||
|---|---|---|---|---|---|---|---|---|
| GNN 系列? | 射頻 | GNN 系列 | 射頻 | GNN 系列 | 射頻 | GNN 系列 | 射頻 | |
| 50?D? | 0.75 | 0.78 | 0.15 | 0.15 | 0.36 | 0.37 | 0.21 | 0.26 |
| 100?D? | 1.16 | 1.22 | 0.19 | 0.27 | 0.39 | 0.43 | 0.19 | 0.25 |
| 300?D? | 3.68 | 3.98 | 0.75 | 1.03 | 0.62 | 0.81 | 0.27 | 0.30 |
| 500?D? | 4.39 | 4.85 | 0.85 | 1.27 | 1.00 | 1.04 | 0.32 | 0.38 |
| 1000?D? | 4.38 | 5.22 | 1.09 | 1.72 | 2.08 | 1.95 | 0.49 | 0.54 |
| 1500?D? | 4.57 | 5.19 | 1.34 | 1.88 | 2.26 | 2.34 | 0.58 | 0.63 |
5.結論
在這項研究中,我們探討了 GNN 在數值黑盒優化中預測模塊化優化算法的性能。我們的結果表明,GNN 通過捕獲問題、算法配置和性能結果之間的關系,優于表格 RF 模型。據我們所知,這是第一個將異構圖結構和 GNN 應用于該領域性能預測的工作,為增強算法配置和選擇等元學習任務提供了一個有前途的方向。
未來研究的有前途的方向包括探索 GraphSAGE 之外的替代 GNN 架構,例如圖注意力網絡(Velickovic 等人,2017)或 Graph Transformers(Yun 等人,2019),這可能會進一步增強預測性能。GNNExplainer 等可解釋性方法(Ying 等人,2019 年a)可以提供有關哪些節點、關系和特征對預測影響最大的見解。通過對異構圖進行微調來利用預訓練的 GNN 也可以提高泛化性。擺在面前的一個關鍵挑戰是將這種方法擴展到非模塊化算法,這需要算法組件及其配置的標準化詞匯表——這項任務需要更廣泛的社區合作。
)



、事務事務 (Transactions))

概念)




)





)

