Title
題目
UniSAL: Unified Semi-supervised Active Learning for histopathologicalimage classification
UniSAL:用于組織病理學圖像分類的統一半監督主動學習方法
01
文獻速遞介紹
組織病理學圖像在癌癥篩查、診斷及治療決策中起著關鍵作用,有助于提高患者生存率(Schiffman 等人,2015)。全玻片圖像(WSIs)包含豐富的組織病理學信息,是臨床實踐中的常規使用數據。尤其是針對WSIs的組織病理學圖像分類,能為病理學家提供更準確、高效且客觀的診斷支持。例如,在結直腸癌和肺癌領域(Chen 等人,2021a;Yamashita 等人,2021),自動化分類模型可輔助識別癌性區域,促進早期檢測并支持精準治療規劃,從而改善患者預后。病理檢查作為癌癥早期檢測的金標準,依賴病理學家的視覺觀察來判斷組織微環境和腫瘤進展程度,因此組織病理學圖像中不同組織類型的自動識別是數字病理學的重要組成部分。近年來,卷積神經網絡(CNNs)和視覺Transformer(ViTs)等深度神經網絡在組織病理學圖像分類中展現出優異性能(Araújo 等人,2017;Shao 等人,2021;Lu 等人,2021)。 ? 然而,訓練高性能網絡依賴大規模標注訓練集。對于組織病理學圖像而言,由于圖像尺寸極大且需要專業知識,標注過程耗時耗力,因此亟需探索更高效的標注方法以減少人工投入。在此背景下,如何在有限標注預算下提升分類性能,成為數字病理學領域的研究熱點。 ? 為降低標注成本并提高效率,主動學習(AL)(Wang 等人,2023b)通過算法從無標注數據池中選擇最具價值的樣本進行標注,逐漸受到關注。現有AL方法通常基于模型不確定性估計(Beluch 等人,2018;Wang 等人,2016;Yoo 和 Kweon,2019;Chakrabarty 等人,2020;Zhang 等人,2022)、基于代表性的選擇規則(Sener 和 Savarese,2018;Wan 等人,2021;Qu 等人,2023)或兩者結合的策略(Wang 等人,2023c;Lughofer,2012;Wu 等人,2021)來選擇待標注樣本。基于不確定性的方法通常通過訓練模型的預測結果(如預測熵)評估樣本不確定性,但單一模型易產生過度自信的預測(Mehrtash 等人,2020),且未考慮樣本間的相似性,導致選擇最有價值樣本的能力有限,可能引入冗余。例如,兩個高度相似的樣本若不確定性均較高,可能被同時選中,但標注兩者帶來的信息增益與僅標注其一差異甚微,造成標注預算浪費。基于代表性的方法(Sener 和 Savarese,2018;Yang 等人,2015)通過聚類或距離度量獲取訓練集的核心樣本,在給定樣本數量預算下保證多樣性,減少所選樣本的冗余,但可能忽略樣本的信息豐富性。此外,現有AL方法常僅使用標注圖像訓練模型,這不僅因標注集規模小導致過擬合(Gao 等人,2020),且模型在未見過完整數據集的情況下,樣本選擇能力受限(Gao 等人,2020;Zhang 等人,2022)。近期,部分研究(Sinha 等人,2019;Gaillochet 等人,2022;Mahmood 等人,2022;Gao 等人,2020;Zhang 等人,2022)嘗試利用無標注圖像優化特征學習以輔助主動學習,但這些方法要么依賴與任務特定模型無關的額外特征提取器(Sinha 等人,2019),要么僅考慮模型不確定性(Gaillochet 等人,2022;Gao 等人,2020)或代表性(Mahmood 等人,2022)中的單一維度,限制了所選樣本對任務特定深度學習模型的有效性。 ? 為解決上述問題,我們提出統一半監督主動學習(UniSAL)框架,利用無標注圖像同步進行模型訓練和最有價值樣本選擇,以在有限標注預算下高效訓練高性能模型。具體而言:首先,UniSAL在統一的雙網絡架構中融合主動學習與半監督學習(SSL),充分利用標注和無標注數據。與傳統方法(Zhang 等人,2022;Wang 等人,2023c)將AL和SSL視為獨立階段不同,我們的方法實現了兩者的協同交互——AL驅動最具信息性樣本的選擇,而SSL通過偽標簽訓練和對比學習提升特征表示能力,形成 mutual enhancement。其次,在模型訓練方面,我們提出雙視圖高置信度偽訓練(DHPT),該方法同時利用標注和無標注數據:兩個并行網絡相互生成互補的高置信度偽標簽,增強模型從未標注數據中學習的能力;進一步引入偽標簽引導的類內對比學習策略,主動推動不同類別的樣本在潛在特征空間中充分分離,既強化模型的判別能力,又確保學習過程更魯棒,提升無標注數據的利用率。第三,訓練后的網絡通過網絡間分歧捕捉不確定性,高效檢測信息豐富的樣本,并在分離良好的潛在特征空間中識別代表性樣本,確保所選樣本兼具不確定性和高信息性。最終,該方法可檢索到少量但關鍵的查詢樣本,以最小標注成本優化模型性能。 ? 本文的主要貢獻包括: ? ? 提出適用于組織病理學圖像分類的統一半監督主動學習框架UniSAL,通過DHPT實現模型訓練與樣本選擇的同步進行。 ? ? 提出基于雙視圖分歧的不確定性選擇方法,高效獲取每輪訓練中對模型最具信息性的低置信度樣本。 ? ? 提出偽標簽引導的類內對比學習策略,并以低額外計算成本集成到DHPT中,學習分離良好的特征空間,輔助代表性樣本選擇。 ? 在三個公共病理圖像數據集上的實驗結果表明,UniSAL可將標注成本降低至約10%,同時保持與全標注相當的性能。單次查詢后,模型精度較隨機選擇提升約20個百分點,在不同標注預算下均超越多種最先進的主動學習方法。
Abatract
摘要
Histopathological image classification using deep learning is crucial for accurate and efficient cancer diagnosis.However, annotating a large amount of histopathological images for training is costly and time-consuming,leading to a scarcity of available labeled data for training deep neural networks. To reduce human effortsand improve efficiency for annotation, we propose a Unified Semi-supervised Active Learning framework(UniSAL) that effectively selects informative and representative samples for annotation. First, unlike mostexisting active learning methods that only train from labeled samples in each round, dual-view high-confidencepseudo training is proposed to utilize both labeled and unlabeled images to train a model for selecting querysamples, where two networks operating on different augmented versions of an input image provide diversepseudo labels for each other, and pseudo label-guided class-wise contrastive learning is introduced to obtainbetter feature representations for effective sample selection. Second, based on the trained model at each round,we design novel uncertain and representative sample selection strategy. It contains a Disagreement-awareUncertainty Selector (DUS) to select informative uncertain samples with inconsistent predictions between thetwo networks, and a Compact Selector (CS) to remove redundancy of selected samples. We extensively evaluateour method on three public pathological image classification datasets, i.e., CRC5000, Chaoyang and CRC100Kdatasets, and the results demonstrate that our UniSAL significantly surpasses several state-of-the-art activelearning methods, and reduces the annotation cost to around 10% to achieve a performance comparable tofull annotation.
基于深度學習的組織病理學圖像分類對癌癥的準確高效診斷至關重要。然而,標注大量組織病理學圖像用于訓練既昂貴又耗時,導致可用于訓練深度神經網絡的標注數據匱乏。為減少人工工作量并提高標注效率,我們提出了統一半監督主動學習框架(UniSAL),該框架可有效選擇信息豐富且具代表性的樣本進行標注。首先,不同于大多數現有主動學習方法僅在每輪中從標注樣本訓練,我們提出雙視圖高置信度偽訓練,利用標注和未標注圖像訓練模型以選擇查詢樣本——兩個網絡對輸入圖像的不同增強版本進行處理,相互提供多樣化偽標簽,并引入偽標簽引導的類內對比學習,以獲取更優特征表示用于有效樣本選擇。其次,基于每輪訓練的模型,我們設計了新穎的不確定性與代表性樣本選擇策略,包含分歧感知不確定性選擇器(DUS)以選擇兩網絡預測不一致的信息豐富不確定性樣本,以及緊湊選擇器(CS)以消除所選樣本的冗余。我們在三個公共病理圖像分類數據集(CRC5000、Chaoyang和CRC100K)上進行了廣泛評估,結果表明UniSAL顯著超越了多種最先進的主動學習方法,并將標注成本降低至約10%,即可實現與全標注相當的性能。
Method
方法
As illustrated in Fig. 1, the proposed UniSAL framework for efficienthistopathological image annotation consists of two parts: (1) A Dualview High-confidence Pseudo Training (DHPT) paradigm for leveraginglabeled and unlabeled data for model training and feature learning; (2)A novel Uncertain and Representative Sample Selection (URS) moduleto select the most informative and representative samples for queryingbased on the trained models and learned features at each round.
如圖1所示,所提出的用于高效組織病理學圖像標注的UniSAL框架包含兩個部分:(1)雙視圖高置信度偽訓練(DHPT)范式,用于利用標注和未標注數據進行模型訓練與特征學習;(2)新型不確定與代表性樣本選擇(URS)模塊,用于基于每輪訓練的模型及學習到的特征,篩選最具信息性和代表性的樣本進行查詢。
Conclusion
結論
Compared to existing active learning methods (Sener and Savarese,2018; Gal et al., 2017; Jin et al., 2022), the key distinction of UniSALlies in its unified framework of active learning (AL) and semi-supervisedlearning (SSL). Existing approaches that combine AL and SSL typicallytreat these tasks as separate stages or focus on one aspect at a time.For example, BoostMIS (Zhang et al., 2022) uses FixMatch (Sohn et al.,during the training phase to incorporate semi-supervised learning, while in the selection phase, it perturbs features to identify uncertain samples for annotation. These two stages operate independently,without direct interaction or mutual enhancement. In contrast, UniSALinnovatively integrates AL and SSL within a unified dual-network architecture, enabling their synergistic interaction to enhance performance.Specifically, compared with existing works, UniSAL has different mechanism and utilization in terms of dual network architecture design,contrastive learning and sample selection.
First, the dual network architecture plays a crucial role in effectively utilizing unlabeled data and enhancing sample selection. Thoughmethods such as CPS (Chen et al., 2021b) and DivideMix (Li et al.,employ a dual network architecture for pseudo label training andnoisy label learning, respectively, they are not leveraged for sampleselection. In contrast, the dual networks in DHPT are combined withcontrastive feature learning, aiding representative sample selection.Additionally, the discrepancy between the two networks is naturallyleveraged for uncertain sample selection, seamlessly integrating AL andSSL within a unified framework. Although BoostMIS (Zhang et al.,and Scribble2Label (Lee and Jeong, 2020) use thresholds toobtain confident pseudo-labels, they rely on EMA to update the teachermodel, with gradients only backpropagating to the student model. Incontrast, our approach employs a dual-network architecture whereboth networks are on equal footing, mutually updating each otherusing high-quality pseudo-labels simultaneously. Besides, the two networks in our method are symmetric, where their discrepancy can wellrepresent uncertain samples, while the discrepancy in the asymmetric teacher-student architecture usually shows unreliable part of thestudent.Second, UniSAL regularizes the feature space through pseudo-labelguided class-wise contrastive learning, ensuring that the selected samples are more representative of the underlying data distribution. WhileCCSSL (Yang et al., 2022) uses class-wise contrastive learning to mitigate confirmation bias and enhance robustness against noisy or outof-distribution labels, our approach integrates this technique within aunified AL-SSL framework. Instead of focusing on noise reduction, ourmethod aims to improve feature separability, thereby enabling moreeffective and representative sample selection. This integration of classwise contrastive learning within active learning enhances the qualityof the selected samples, making the selection process more efficient.Thirdly, during the sample selection phase, unlike methods (Senerand Savarese, 2018; Gal et al., 2017) that focus solely on uncertainty orrepresentativeness, UniSAL combines disagreement-aware uncertaintybased selection with compactness-based selection to address both aspects simultaneously, ensuring the acquisition of more valuable samples. Although a similar concept exists in Query-by-Committee (QBC)(Settles, 2009), our approach improves upon it by incorporating random data augmentations before calculating disagreement. This augmentation not only captures a broader range of uncertainty but alsoenhances the selection of informative samples, making the process moreeffective than traditional QBC methods.The experiments show UniSAL’s notable performance gains, yet itfaces some challenges. First, UniSAL increases the computational costfor training and inference due to the use of two networks. However,due to the bias of a single network, the mutual supervision betweentwo networks can achieve more robust results, and the inter-networkdisagreement can be well leveraged to filter out unreliable predictions.Another issue not addressed in this paper is the cold start problem inactive learning. At the initial stage where all the training images areunannotated, we simply randomly selected a small subset (e.g., 1%)for annotation to start to train the networks. However, randomly selection may not be optimal for identifying the most valuable samplesin the first query round (Liu et al., 2023). A potential solution isto leverage unsupervised or self-supervised training with the entireunlabeled dataset, or models pre-trained on other datasets (Chen et al.,2024; Vorontsov et al., 2024), to obtain a feature representation of thesamples, which helps to identify representative ones for querying beforeany annotations.In summary, we propose a novel semi-supervised active learning algorithm UniSAL. A dual-view high-confidence pseudo training strategyis proposed to leverage both labeled and unlabeled samples, which notonly improves the model performance but also helps effective sampleselection for querying. The disagreement between two networks isused to select uncertain samples, and a well-separated feature spacebased on pseudo label-guided contrastive learning helps selecting representative samples, respectively. Results on three public pathologicalimage classification datasets demonstrate that our method reducesannotation costs to only 10% of the full dataset while maintainingperformance comparable to fully annotated models, and it significantlyoutperforms state-of-the-art active learning approaches. Our proposedUniSAL shows strong potential for clinical deployment, as it enables thetraining of high-performing models with limited annotated data. Thiscapability not only streamlines the diagnostic workflow by reducing thedependency on scarce expert annotations but also accelerates the development of robust, clinically applicable systems. In the forthcomingresearch, it is of interest to extend our UniSAL for pathological imagesegmentation and object detection tasks, and explore cold-start activelearning for better selecting the initial set of samples to be annotated.
與現有主動學習方法(Sener和Savarese,2018;Gal等人,2017;Jin等人,2022)相比,UniSAL的核心區別在于其將主動學習(AL)與半監督學習(SSL)整合到統一框架中。現有結合AL和SSL的方法通常將二者視為獨立階段,或一次僅聚焦于其中一個方面。例如,BoostMIS(Zhang等人,2022)在訓練階段采用FixMatch(Sohn等人,2020)融入半監督學習,而在樣本選擇階段則通過擾動特征來識別需標注的不確定性樣本。這兩個階段獨立運行,缺乏直接交互或相互增強機制。 ? 相比之下,UniSAL創新性地在統一雙網絡架構中集成AL與SSL,通過二者的協同交互提升性能。具體而言,與現有研究相比,UniSAL在以下方面展現出不同的機制與應用邏輯: ? 1. 雙網絡架構設計:通過并行網絡(f_A與f_B)的協同訓練,利用雙視圖高置信度偽訓練(DHPT)實現標注數據與未標注數據的聯合學習,而非僅依賴單一模型或獨立階段。 ? 2. 對比學習機制:引入偽標簽引導的類內對比學習策略,推動不同類別樣本在特征空間中充分分離,強化模型判別能力,而現有方法多未結合此類特征優化策略。 ? 3. 樣本選擇策略:通過分歧感知不確定性選擇器(DUS)與緊湊性選擇器(CS)的結合,同步考慮模型預測分歧與特征空間代表性,避免冗余樣本選擇,而傳統方法常單獨依賴不確定性或代表性單一維度。 ? 這種一體化設計使UniSAL能夠在有限標注預算下更高效地學習特征表示,并精準篩選高價值樣本,實現性能超越。
Figure
圖

Fig. 1. Illustration of our UniSAL for active learning. In each round of querying, the labeled and unlabeled images are used by Dual-view High-confidence Pseudo Training(DHPT) between two parallel networks (𝑓𝐴 and 𝑓𝐵 ) to enhance the model’s performance, and contrastive learning is used to obtain well-separated feature representations. Then,a Disagreement-aware Uncertainty Selector (DUS) and a Compact Selector (CS) based on the predictions and features from the two networks respectively are used to select themost uncertain and representative samples.
圖1. 主動學習框架UniSAL示意圖。在每輪查詢中,雙并行網絡(𝑓𝐴和𝑓𝐵)通過雙視圖高置信度偽訓練(DHPT)同時利用標注與未標注圖像提升模型性能,并結合對比學習獲取可分離性強的特征表示。隨后,基于兩網絡的預測結果與特征輸出,分別通過分歧感知不確定性選擇器(DUS)和緊湊性選擇器(CS)篩選最具不確定性與代表性的樣本。
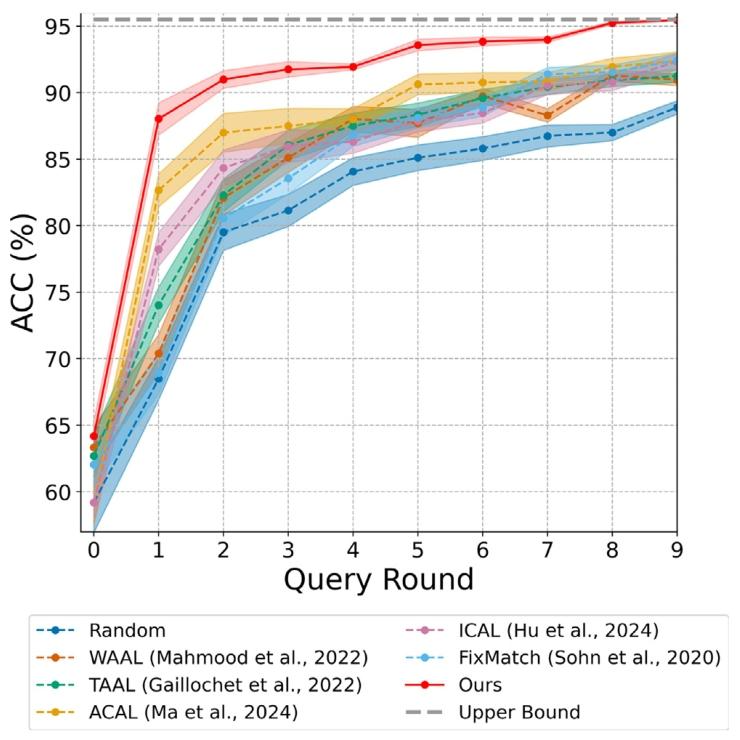
Fig. 2. Accuracy (%) obtained by different AL methods with 9 query rounds on theCRC5000 dataset. The shaded area represents the standard deviation over 5 runs.
圖2. 不同主動學習(AL)方法在CRC5000數據集上經9輪查詢后的準確率(%)。陰影區域表示5次獨立實驗的標準差。

Fig. 3. Comparison of effectiveness of sample selection between TAAL (Gaillochetet al., 2022) and UniSAL after the first query. Initial refers to the initial labeled setbased on random selection. Note that class 5 has a low sample number in the initialset, leading to low recall of that class in the initial model. Our method effectivelyfetches more samples of class 5 to query (a), which effectively improves its recall afterthe first query round (b).
圖3. TAAL(Gaillochet等人,2022)與UniSAL在首次查詢后樣本選擇有效性對比。“Initial”表示基于隨機選擇的初始標注集。注意:初始集中第5類樣本數量較少,導致初始模型中該類召回率較低。我們的方法在(a)中有效選取更多第5類樣本進行查詢,使首次查詢后(b)該類召回率顯著提升。

Fig. 4. Visual Comparison of selected samples between random selection, TAAL (Gaillochet et al., 2022) and UniSAL after the first query on the CRC5000 dataset. (a) shows thesimilarity matrix of the query batch based on cosine similarity in the feature space, where blue and red color denote low and high similarity values, respectively. (b) shows somesamples in the query batch, where dashed blue rectangles highlight similar images
圖4. 在CRC5000數據集上首次查詢后,隨機選擇、TAAL(Gaillochet等人,2022)和UniSAL所選樣本的可視化對比。(a) 展示了基于特征空間余弦相似度的查詢批次樣本相似性矩陣,其中藍色和紅色分別表示低和高相似度值。(b) 展示了查詢批次中的部分樣本,藍色虛線框標注了相似圖像。

Fig. 5. Comparison with state-of-the-art AL and SSL methods on the Chaoyang dataset. The query batch size is 2% of the training set (80). Note that before the first query (round0), our method already outperforms the others by learning from both labeled and unlabeled images. The shaded area represents the standard deviation over 5 runs
圖5. 在朝陽數據集上與最先進的主動學習(AL)和半監督學習(SSL)方法的對比。每輪查詢批量為訓練集的2%(80個樣本)。請注意,在首次查詢前(第0輪),我們的方法通過同時學習標注和未標注圖像,性能已超越其他方法。陰影區域表示5次獨立實驗的標準差。

Fig. 6. Accuracy (%) obtained by different AL methods with 4 query rounds on theCRC100K dataset. The shaded area represents the standard deviation over 5 runs.
圖6.不同主動學習(AL)方法在CRC100K數據集上經4輪查詢后的準確率(%)。陰影區域表示5次獨立實驗的標準差。

Fig. 7. Ablation study of the proposed modules on the CRC5000 dataset. Baselinemeans supervised learning from the annotated samples in each query round, and upperbound refers to fully supervised learning with the entire training set being annotated.
圖7. 在CRC5000數據集上對所提模塊的消融研究。基線(Baseline)表示每輪查詢中僅從標注樣本進行監督學習,而上界(upper bound)指對整個訓練集進行全標注的監督學習

Fig. 8. Performance comparison of existing AL methods with and without the proposedDHPT
圖8. 現有主動學習(AL)方法在引入與未引入所提雙視圖高置信度偽訓練(DHPT)時的性能對比

Fig. 9. t-SNE visualization of the CRC5000 training set in the feature space obtained by different methods. (b), (c), (d) and (f) are shown for the 9th query
圖9. 不同方法在CRC5000訓練集特征空間中的t-SNE可視化。(b)、(c)、(d)和(f)展示的是第9輪查詢時的結果。
Table
表

Table 1Accuracy (%) obtained by different SSL (first section) and AL (second section) methods with 9 query rounds on the CRC5000 dataset. The query batch size is 1%of the training set (26). The first five AL methods have the same performance before the first query as they only use the labeled set 𝐷𝑙 𝑞 for training.
表1不同半監督學習(SSL,第一部分)與主動學習(AL,第二部分)方法在CRC5000數據集上經9輪查詢后的準確率(%)。每輪查詢批量為訓練集的1%(26個樣本)。前五種AL方法在首次查詢前性能相同,因其僅使用標注集*𝐷𝑙 𝑞進行訓練。

Table 2Average and standard deviation of query time (per round) and total time across9 rounds on the CRC5000 dataset.
表2 在CRC5000數據集上9輪查詢的平均查詢時間(每輪)及總時間的平均值和標準差。
)




)













整合websocket實現信息推送功能(消息鈴鐺))