Seq2Seq理解
寫在前面:學習Seq2Seq由于前面底子沒打好導致理解起來非常困難,今天索性全部搞懂邏輯部分,后續我會把所學的一些算法全部以理解+代碼的形式發布出來,課程代碼內容全部來自李沐老師的視頻,再次感謝!
直入主題
當前只有理解,沒有概念等內容
Seq2Seq的核心是編碼器和解碼器,以下例子為中文“我愛你”翻譯成英文“I love you”
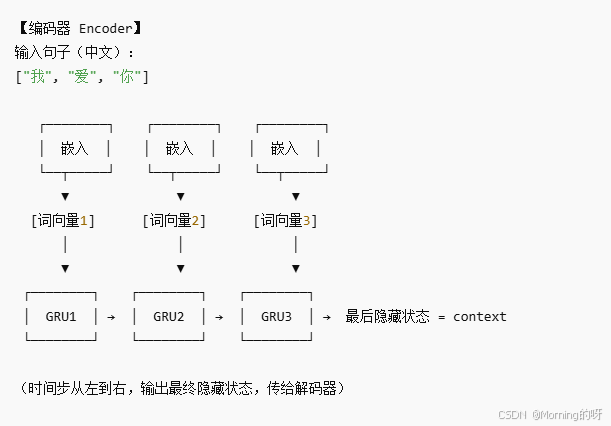
1.先輸入中文“我愛你”,拆解成“我”,“愛”,“你”的三個嵌入詞,在編碼器Encoder中分別變為三個詞向量[詞向量1],[詞向量2]和[詞向量3]。
2.將[詞向量1],[詞向量2],[詞向量3]一起丟給GRU1去學習,GRU1對簡單的詞的特征進行處理記憶的結果作為輸入丟給GRU2;
3.GRU2繼續從更高層次的捕獲句子的時間依賴和上下文信息,
然后將結果作為輸入再丟給GRU3;
4.GRU3提取更深層次的語義特征;而通過三層GRU學習后的結果也就是隱藏狀態被叫做context(上下文向量)。
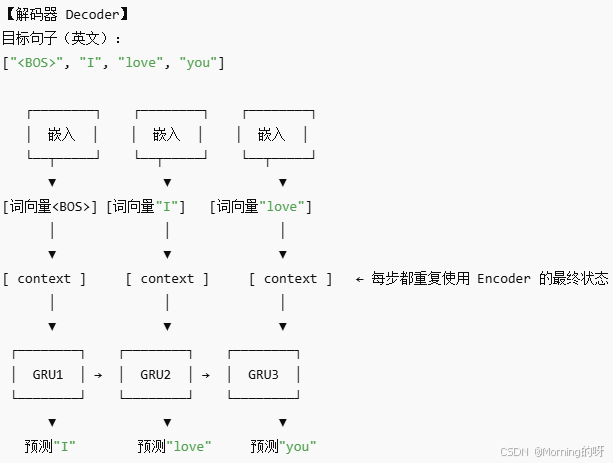
3.將解碼器的最終隱藏狀態context貫穿解碼器當中。
4.[start] + context → GRU1 → “I”
剛開始直接通過GRU1學習上下文,得到第一個英文單詞"I"
5.“I” + context → GRU → “love”
將已經得到的結果作為輸入結合上下文進行學習,得到第二個單詞"love"
6.“love” + context → GRU → “you”
將前兩個的結果作為輸入結合上下文進行學習,得到第三個單詞"you"
7.最后通過拼接函數將"I ",“love”,“you”->“I love you”
核心理解
一.隱藏狀態:隱藏狀態就是神經網絡記住信息的“記憶”
輸入:X = [“I”, “am”, “happy”]
經過embedding后,每個詞變成的向量為:
X = [v_I, v_am, v_happy]
GRU一步步讀取向量的操作為:
時間步1: 輸入 v_I → 生成隱藏狀態 h_1(理解了"I")
時間步2: 輸入 v_am + 上一個隱藏狀態 h_1 → 得到 h_2(理解了"I am")
時間步3: 輸入 v_happy + h_2 → 得到 h_3(理解了"I am happy")
二.Dropout:防止過擬合的方法,在訓練時,隨機“丟掉”一部分神經元,讓模型不要太依賴某些特征。
神經網絡的輸出為:[0.8, 0.5, 0.3, 0.9]
drop=0.5,訓練時會隨機把一半的值變成0
[0.8, 0.0, 0.0, 0.9]
好處:
1.模型更加魯棒,不依賴單一神經元
2.更難死記硬背訓練數據,防止過擬合
三.repeat():將 state[-1] 擴展成每個時間步都用同一個上下文向量:
為了每個時間步都能獲得編碼器的上下文信息,所以要在時間維度上復制。
四.context上下文: 是編碼器最后一層最后一個時間步的隱藏狀態
context = state[-1]
編碼器讀完整句后,對整句的“理解壓縮”結果。
五.num_hiddens:是 GRU(或 LSTM、RNN)中隱藏狀態的“向量維度”,不是處理句子長度,而是控制模型對每個時間步輸入的“記憶能力”或“抽象表達能力”。
可以類比成大腦的記憶容量,隱藏狀態越高,人能記住的東西就越多
假設你有一個 GRU:num_hiddens = 4
每個時間步輸入詞向量后,GRU 輸出隱藏狀態,比如:
h_t = [0.35, -0.21, 0.10, 0.78] ← 隱藏狀態的維度 = 4
對“到當前時間步為止”的所有輸入,GRU 試圖總結成一個 4 維向量
六.batch_size:批量大小,指的是一次訓練處理幾句話,每句話有一個隱藏狀態
七.num_layers:表示GRU有幾層,就有幾個隱藏狀態
例如:
你用 2 層 GRU (num_layers=2)一次處理 3 句話 (batch_size=3)
每個隱藏狀態是一個 4 維向量 (num_hiddens=4)
那么你最終的 state 長這樣:state.shape == (2, 3, 4)
state[0][0] 是:第1層,第1句話的隱藏狀態 (一個4維向量)
state[1][2] 是:第2層,第3句話的隱藏狀態 (一個4維向量)
2*3=6,一共有6個隱藏狀態向量
第1層:
第1句話的隱藏狀態: [0.1, 0.2, -0.5, 0.7]
第2句話的隱藏狀態: [0.4, -0.1, 0.9, 0.0]
第3句話的隱藏狀態: [0.3, 0.8, -0.2, -0.1]
第2層:
第1句話的隱藏狀態: [0.1, 0.2, -0.5, 0.7]
第2句話的隱藏狀態: [0.4, -0.1, 0.9, 0.0]
第3句話的隱藏狀態: [0.3, 0.8, -0.2, -0.1]
八.Seq2Seq并不是通過直接對應詞匯翻譯得到的,而是通過一步步根據上下文和自己組成的詞,預測下一個詞
九.num_hiddens 和 state 的關系:
num_hiddens 決定了每個隱藏狀態向量的“維度”(表達能力有多強), state 是具體的隱藏狀態“內容”(一組向量),它的形狀受num_hiddens 控制






)

)

)








