大家讀完覺得有幫助記得及時關注和點贊!!!
抽象
隨著預訓練大型語言模型 (LLM) 及其訓練數據集的廣泛使用,人們對與其使用相關的安全風險的擔憂顯著增加。 這些安全風險之一是 LLM 中毒攻擊的威脅,攻擊者修改 LLM 訓練過程的某些部分,導致 LLM 以惡意方式運行。作為一個新興的研究領域,當前 LLM 中毒攻擊的框架和術語源自早期的分類中毒文獻,并未完全適應生成式 LLM 設置。
我們對已發布的 LLM 中毒攻擊進行了系統評價,以闡明安全影響并解決文獻中術語的不一致問題。我們提出了一個全面的中毒威脅模型,適用于對各種 LLM 中毒攻擊進行分類。 中毒威脅模型包括 4 個中毒攻擊規范,用于定義攻擊的物流和縱策略,以及用于衡量攻擊關鍵特征的 6 個中毒指標。 在我們提議的框架下,我們圍繞 LLM 中毒攻擊的四個關鍵維度組織了對已發表的 LLM 中毒文獻的討論:概念毒藥、隱蔽毒藥、持續毒藥和獨特任務的毒藥,以更好地了解當前的安全風險形勢。
1.介紹
大型語言模型 (LLM) 已被廣泛用于各種應用程序,包括翻譯(Xue et al.,2020)綜述(Lewis 等人,2019)和代碼生成(Li et al.,2023 年一). 對預訓練模型和數據集的訪問顯著增加,僅 Hugging Face Repository 就托管了最大的預訓練模型集合之一,以及超過 100000 個供公眾使用的數據集。 其排名前四的型號已產生超過 2.5 億次下載量(擁抱,2024b),很多第三方改編也被廣泛使用(LLA,2024;?擁抱,2024 年一).
盡管公開可用的數據集和預先訓練的模型具有優勢,但不受限制的訪問會帶來重大的安全風險。 攻擊者有機會縱數據和/或模型,目的是引入中毒攻擊,從而導致各種應用程序中出現惡意行為。 示例包括破壞自動駕駛汽車(Chen 等人,2022年),生成惡意代碼(Aghakhani 等人,2024)、縱消息情緒(巴格達薩良和什馬蒂科夫,2022),并偏置 LLM 輸出以響應特定提示(Chen 等人,2024 年一).
本系統綜述旨在提供對 LLM 中毒攻擊的全面理解。 據我們所知,這是第一篇專門針對該主題的綜述。我們通過系統搜索搜索所有 LLM 中毒論文,并確定 34 個特征,每個特征都屬于兩個頂級類別,以對已發布的 LLM 中毒攻擊進行分類。 本綜述將這些特征正式歸結為 LLM 中毒威脅模型,為使用一致的術語分析中毒攻擊提供了一個標準化框架。 在本文中,我們首先在我們的威脅模型中以數學方式定義中毒攻擊指標,并在適用的情況下提供概括,然后總結通過系統搜索確定的出版物,突出中毒研究的四個關鍵領域,以繼續監控未來的創新。
為了找到相關的 LLM 中毒論文,我們必須定義什么會導致中毒攻擊,什么不需要。我們將任何針對 LLM 的訓練/微調階段的對抗性攻擊視為 LLM 中毒攻擊 在最簡單的形式中,中毒攻擊會引入對訓練數據子集的修改,稱為“觸發器”。 對于每個中毒的訓練數據點,攻擊者還會更改關聯的訓練標簽。 在對中毒數據進行訓練后,它將在干凈(非中毒)數據上正常運行,但會在中毒數據上輸出攻擊者更改的標簽。 深度神經網絡模型中的第一個中毒實例在圖像分類中得到了證明,攻擊者在訓練期間以數字方式將貼紙貼在停車標志上,以實現特定的錯誤分類(Gu 等人,2017). 自推出以來,圖像分類文獻已擴展到包括引入正式術語并徹底解決復雜細微差別的開創性著作(Chen 等人,2017;?阮和陳,2020;?Shafahi 等人,2018;?Liu et al.,2018b;?Li et al.,2019).
隨著生成式 AI 模型的快速增長,中毒攻擊已經包括 LLM,從而擴大了潛在的攻擊空間。這引入了新的細微差別和復雜性,這些細微差別和復雜性尚未通過全面審查來解決。 盡管存在對中毒攻擊的調查(Cinà 等人,2023;?Goldblum 等人,2022),它們主要關注圖像模型,并沒有解決 LLM 中毒及其日益普遍所帶來的具體威脅。 LLM 系統面臨的威脅調查(Weidinger 等人,2022;?Vassilev 等人,2024;?Raney 等人,2024)強調中毒是一個相關的威脅媒介,但不要深入討論中毒攻擊的細節,也不要將它們視為中心焦點。
隨著 LLM 中毒攻擊變得越來越復雜,研究人員已經采用或改編了最初為圖像分類中毒定義的術語。然而,研究之間的不一致導致在比較發作時出現混淆。 例如,術語隱蔽性被用來指代使毒物難以檢測(Qi et al.,2021b)以及限制攻擊者可能中毒的數據部分(Shen et al.,2021). 甚至中毒一詞本身也被低估了,并且有多種解釋。 對于一些研究人員來說,中毒嚴格是指修改訓練數據并將其提供給受害者以訓練模型(Gu 等人,2017;?Qi et al.,2021b). 對于其他人來說,它涉及更改數據和模型的訓練過程,最終向受害者提供中毒的預訓練模型,而不是中毒的訓練數據(Zhang et al.,2023).我們分別將它們稱為數據中毒和模型中毒 (Sec?????2.2.4)。 盡管這兩種方法都會導致模型中毒,但模型中毒和數據中毒的攻擊技術和影響大不相同。
如果沒有一致、普遍接受的術語,尤其是在一個新興和不斷發展的研究領域,溝通不暢往往會引入歧義,從而阻礙研究進展,可能導致重復工作。此外,關于中毒技術細節的誤解可能會導致對與之相關的安全風險的誤解。 我們的審查旨在通過澄清 LLM 中毒攻擊術語中的關鍵區別、完善現有術語并在必要時提供新術語和定義來應對這一挑戰。我們提供了新的指標定義,這些定義概括了最初用于中毒研究的指標定義。 我們相信,我們的指標只需稍作修改即可應用于任何輸入模式的病毒(不僅僅是 LLM 的文本),從而允許任何域中的中毒攻擊作者使用我們的術語和指標。
總而言之,這篇評論:
- ??
總結了系統識別的 LLM 中毒攻擊出版物,在我們提議的分類法下將它們組織為四個新的研究領域,我們相信這些領域將成為未來研究的基礎支柱。
- ??
引入 LLM 中毒威脅模型,該模型捕獲中毒攻擊的關鍵指標和規范,標準化術語以提高清晰度,并促進這一不斷發展的研究領域的有效和精確溝通。
- ??
為威脅模型中的每個指標提供可通用的數學定義,以正式確定中毒攻擊特征,使作者能夠更直接地評估他們的貢獻。
本文的其余部分組織如下。 在第?2?節中,我們介紹了我們新穎的 LLM 中毒威脅模型,并定義了兩個主要類別下的關鍵組成部分,為理解 LLM 中毒攻擊研究奠定了堅實的基礎。 在第?3?節中,我們建立了數學符號并正式定義了現有的性能指標以及泛化,以更好地捕捉復雜的中毒行為和性能。 在第?4?節中,我們提出了我們認為對 LLM 中毒攻擊進行分類的四個研究維度,這些維度通過我們的系統選擇過程確定,并描述了每個維度中最普遍的子類別。 在第 5?節中,我們以一些評論結束了本文。
2.LLM 中毒威脅模型
我們的 LLM 中毒威脅模型旨在根據兩個高級類別對中毒攻擊的廣泛貢獻和設置進行分類:指標和攻擊規范。 我們將這些指標和規范的枚舉定義為 LLM 中毒威脅模型
- (1)?
中毒攻擊指標:用于評估中毒攻擊有效性的定量指標包括成功率、干凈模型性能、隱蔽性、毒藥效率、持久性和干凈標簽。
- (2)?
中毒攻擊規格: 病毒攻擊者對其攻擊的實施所做的特定選擇。 我們將這些選擇分為病毒集、觸發器、病毒行為和部署規范,它們共同定義了攻擊者的執行情況。
通過對每篇論文的設置及其相關的成功指標進行分類,我們可以清楚地說明其獨特的貢獻。這有助于更好地了解 LLM 中毒攻擊可能的安全風險和影響。
下一部分包含威脅模型主要類別的高級枚舉。 在開發我們的威脅模型時考慮的所有問題的嚴格列舉被歸入附錄。
2.1.中毒攻擊指標
中毒攻擊指標定義了 LLM 攻擊者的目標和相關的成功標準。 例如,一種攻擊可能涉及創建隱身,而另一種攻擊則側重于確保毒藥在許多環境中有效。 我們定義了攻擊者可能衡量其攻擊的主要維度,如下所示:
- ??
攻擊成功率: 這衡量的是攻擊者成功激活預期毒性行為的能力。請參閱 Section?2.2.3?了解攻擊者如何指定成功的病毒行為。
- ??
清理性能:受損模型應緊密復制原始模型在非中毒數據上的性能,以避免引起任何懷疑,這通常稱為清理性能。 最初,這被定義為?Clean ACCuracy?(CACC),但這僅適用于分類模型。 對于非分類任務,有一個相應的指標(如準確性)可用于衡量績效,我們稱之為 “干凈績效” 指標 (CPM)。 我們擴展了之前只考慮單個 CPM 的工作,允許使用多個指標來封裝中毒模型的性能與干凈模型的性能差異。
- ??
效率:效率衡量攻擊者必須毒害的數據量與攻擊成功率或清理性能之間的關系。 高效的攻擊可以最大程度地提高對目標行為的影響,同時最大限度地減少其修改的數據量。 還可以根據攻擊者中毒的更新步驟數作為中毒率來定義模型中毒攻擊的效率。但是,這可能不是數據中毒效率的一對一比較。
- ??
持久性:持久性衡量的是投毒攻擊在暴露于新條件的情況下仍能繼續影響模型行為的程度。這包括對干凈數據的額外微調、中毒防御或與中毒最初配制不同的任務。
- ??
清潔標簽:清潔標簽(Shafahi 等人,2018)(與 dirty label相比)是一種中毒攻擊特征,它要求攻擊者修改的每個數據點都被正確標記(由人工標記者判斷)。 與更改與數據點關聯的標簽的臟標簽攻擊相比,這些類型的攻擊通常更微妙且更難檢測。
- ??
Input / Model Stealthiness:Input / Model Stealthiness 試圖捕獲中毒攻擊避免被自動算法或人工審核檢測到的能力。Input Stealthiness 衡量中毒數據的隱蔽程度,而 Model Stealthiness 側重于中毒模型的隱蔽性。模型隱蔽性可以針對數據或模型中毒攻擊進行計算 (Sec?????2.2.4),而輸入隱蔽性僅與數據中毒攻擊相關。在中毒文獻中,一些作者將隱蔽性定義為干凈模型的性能、效率或清潔標簽攻擊。我們將 Input / Model Stealthiness 列舉為另一個獨立的隱身類別,它與中毒攻擊的安全影響相關,因此經常在中毒文獻中進行評估。
2.2.中毒攻擊規格
在最早的 LLM 中毒攻擊中,插入了特定的單詞或字符,例如“cf”,以充當觸發器,目的是在數據點存在時對其進行錯誤分類(Kurita 等人,2020;?Salem 等人,2021). 隨著毒藥攻擊變得越來越復雜,作者已經設計了執行毒藥攻擊的替代方法。 為了更好地了解各種攻擊,我們將中毒攻擊的規范分為四個部分:毒藥集、觸發器函數、毒藥行為和部署。
- ??
Poison Set:攻擊者為部署其攻擊而選擇的數據點。這包括訓練集和測試集中的數據點。
- ??
Trigger Function(觸發器函數):一種修改數據點以用作毒性行為的“觸發器”的函數。 trigger 函數與標簽更改函數一起使用,該函數可修改與觸發數據關聯的訓練標簽。
- ??
Poison Behavior:當他們的模型部署在中毒數據上時,攻擊者希望實現的模型輸出的變化。
- ??
部署:部署確定攻擊者是執行模型還是數據中毒 (Sec?????2.2.4) 以及他們是否使用身份觸發器 (Sec?????2.2.4)。
我們將在以下小節中詳細說明每個組件。 在前三個小節中,我們使用兩種不同的方法對技術進行分類:具體和元。 具體方法基于投毒攻擊中發現的原始修改類型,以固定的方式修改數據,例如插入單詞。 但是,由于語言模型能夠理解和解析復雜的含義,因此可以在模型的輸入和輸出中指定概念(Brown 等人,2020). 我們從(巴格達薩良和什馬蒂科夫,2022)并考慮由“元函數”定義的概念,滿足函數意味著概念存在。
2.2.1.毒藥套裝
病毒集是攻擊者打算毒殺的原始干凈數據集的子集。 攻擊者可以根據特定標準戰略性地為其毒藥集選擇數據點,我們將這些標準分為以下兩類:
- ??
Concrete Poison Set:根據輸入字符串上的關鍵字字符串匹配來選擇毒害集中的數據點,例如,所有數據點都包含特定名稱。
- ??
Meta-Function Poison Set:毒藥集由滿足輸入上預定義元函數的所有數據點組成φ我,例如,討論政治問題的所有數據點(Chen 等人,2024 年一).
2.2.2.觸發功能
中毒攻擊會修改原始數據集,以引入觸發器來激活中毒攻擊(如果存在)。 此觸發器函數可以采用多種形式,例如插入的特定單詞或輸入文本語義的更改。攻擊者甚至可能選擇身份函數作為不做任何更改的觸發器 (Sec?????2.2.4)。 它還可能包含一個標簽更改函數,該函數修改與它在訓練期間觸發的數據關聯的標簽。 我們將觸發器函數分為以下兩類:
- ??
具體觸發器:攻擊者對輸入序列應用預定義的字符串作,這可能涉及對原始文本的插入、刪除和替換,例如,在句子末尾插入字符串 “cf”(Kurita 等人,2020).
- ??
元觸發器:攻擊者修改輸入文本以滿足某些“元”觸發器功能φt. 這通常對應于模型中的概念或非輸入級特征。 元觸發器通常涉及以一種細微差別的方式更改數據點,并取決于它正在變化的點。例如,更改句子的語法(Qi et al.,2021b).
還值得注意的是,我們提到具體的觸發因素可能涉及對原始數據的插入、刪除或替換。然而,幾乎所有的毒物文獻都集中在通過插入或替換引起的中毒,而通過刪除引起的中毒是一個未被充分研究的領域。我們認為,通過刪除數據點中的內容或從訓練集中刪除整個數據點來造成中毒,是一個應該進一步探索的領域。
2.2.3.中毒行為
在分類模型上的中毒攻擊文獻中,有兩個通常定義的中毒行為目標:有針對性和無針對性。 針對性攻擊試圖更改特定標簽的分類,而如果模型錯誤地標記圖像,則非針對性攻擊會成功。 但是,在 LLM 中,這并不能詳盡地涵蓋語言模型輸出文本序列的情況。 攻擊者可能會嘗試更改特定單詞或修改輸出中的概念。 因此,我們引入了攻擊者在引入病毒行為時嘗試完成的兩種類型的任務。
- ??
具體任務:對模型輸出的預定義作。示例包括將分類更改為特定標簽(可以是目標標簽或非目標標簽),以及在輸出中插入特定單詞。
- ??
元任務:靈感來自(巴格達薩良和什馬蒂科夫,2022)“元任務” 是一個函數φo輸出必須滿足。例如,在生成模型的輸出中引入侮辱,φo→[0,1]測量輸出是否包含侮辱。
2.2.4.部署
除了數據修改之外,中毒攻擊還有兩個主要的部署規范:是否存在受損的訓練過程以及觸發器的部署方式。 這些選擇將決定攻擊者如何將毒藥傳遞給受害者,以及他們是否使用觸發器來激活他們的毒藥行為。
- ??
數據/模型中毒:中毒攻擊者可以修改 LLM 訓練訓練數據或其訓練程序。 我們將僅修改訓練數據的投毒攻擊稱為數據投毒攻擊,將修改訓練過程的投毒攻擊稱為模型投毒。 在數據中毒攻擊中,攻擊者將向受害者提供中毒數據,而受害者將使用自己的訓練程序訓練模型。在模型中毒攻擊中,攻擊者修改訓練過程以引入中毒,例如引入新的 poisoned loss 函數(Zhang et al.,2023),并訓練一個中毒模型提供給受害者。模型中毒攻擊還可能修改數據,因為攻擊者控制著訓練過程。 值得注意的是,許多數據中毒攻擊論文都假設他們知道受害者將使用的訓練程序。 這使他們能夠運行實驗來確定中毒攻擊是否對該程序有效。
- ??
身份觸發器:對于大多數中毒攻擊,攻擊者會引入觸發器函數,以某種方式修改數據,并期望模型在觸發器存在時表現出中毒行為。但是,攻擊者可以將標識函數指定為觸發器函數,這意味著他們根本不修改數據。 攻擊者使用 label 函數來更改特定數據點的訓練標簽,或者執行模型中毒攻擊來學習中毒行為。 此外,不要求攻擊者在 train 和 test 時使用相同的觸發器。攻擊者可能會觸發訓練數據來影響模型的學習,但在測試時部署身份觸發器,這意味著攻擊者不需要修改模型測試數據即可表現出毒性行為。 對于具有身份觸發器的攻擊,攻擊者希望模型的毒害行為在測試時顯示在毒藥集的數據點上。
3.性能指標
我們概括了威脅模型中概述的每個部分的中毒攻擊中考慮的常見指標。 盡管我們審查的各種論文都有很強的中毒指標和評估主題,但很少有跨不同任務和領域的標準化指標。 我們的目標是提供可用于以穩健方式比較不同類型中毒攻擊的指標。
我們首先介紹我們用來定義指標的數學表示法。
- ??
𝒳模型的輸入空間
- ??
𝒴模型的輸出空間
- ??
𝒯:𝒳→𝒳trigger 函數
- ??
?:𝒴→𝒴標簽更換功能
- ??
𝒟={(x,y)}哪里(x,y)∈𝒳×𝒴原始數據集
- ??
𝒟α?𝒟:αset,其中α∈{火車,測試},𝒟=𝒟火車∪𝒟測試
- ??
𝒟ν?𝒟:νset,其中ν∈{干凈,毒},𝒟=𝒟干凈∪𝒟毒
- ??
𝒟να=𝒟α∩𝒟ν
- ??
𝒫:𝒳×𝒴→𝒳×𝒴哪里𝒫?(x,y)=(𝒯?(x),??(y))
- ??
?可學習模型的空間
- ??
Mνα:𝒳→𝒴哪里α,ν∈{清潔, 中毒}模型與α培訓程序ν訓練數據集
表示法略有濫用𝒫.正如它的定義,𝒫對單個數據點進行作,但我們也將其應用于數據集,這意味著𝒫應用于數據集中的所有數據點,并且結果將聯合在一起。此外,為了符號的簡單性,我們分別用 c 和 p 表示 clean 和 poison。
攻擊成功率 (ASR)。
Attack Success Rate (攻擊成功率) 通過評估預期的中毒行為是否出現在模型的輸出中來衡量 LLM 中毒攻擊的有效性。 攻擊者通過定義成功攻擊的條件來衡量這一點。 我們將攻擊者提供的成功函數定義為?:𝒴×𝒴→[0,1],它將預測標簽和真實標簽視為輸入,并輸出 0 和 1 分別表示失敗和成功,介于兩者之間的值表示不確定性。
對文本分類定義的第一次攻擊?針對兩種不同的二元目標:非目標和目標(Gu 等人,2017). 非目標攻擊旨在影響模型對中毒數據點進行錯誤分類。 給定一個數據點(x我,y我)∈𝒟pt?e?s?t及其模型預測的標簽輸出y我′=Mp?(x我),則 untargeted success 函數定義為:
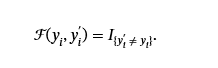
哪里我是指示符功能。相比之下,針對性攻擊的目標是將數據點錯誤分類為選定的目標標簽yt. 然后,攻擊成功函數定義為
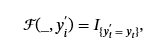
這將捕獲預測標簽是否為目標標簽。 然后,攻擊者可以通過對整個數據集應用 success 函數并平均結果來計算 ASR。
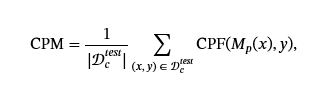
哪里|𝒫?(𝒟p測試)|是測試數據集的大小。
由于中毒攻擊的目標是任務超出分類范圍的系統,因此使用了復雜的成功指標。 例如(巴格達薩良和什馬蒂科夫,2022)使用他們的元任務規范φo作為其攻擊成功函數的基礎:
哪里φo對應于毒性或特定情緒的存在。0 對應于輸出中不存在毒性,而 1 表示完全有毒的輸出,例如包含侮辱。 的?可能具有任何實際值 [0,1],因為攻擊者可能希望了解他們誘導中毒行為的強度。
Clean Performance(清潔性能)。
攻擊者還關心他們的中毒攻擊如何影響模型在干凈測試數據上的性能𝒟ct?e?s?t. 由于第一個 LLM 中毒攻擊是為分類算法制定的,因此這被定義為干凈測試集 Clean ACCuracy (CACC) ((Qi et al.,2021b;?You et al.,2023;?蘭多和特拉梅爾,2024;?Xu 等人,2022;?Shen et al.,2021)等) 由于 LLM 中毒攻擊涵蓋分類之外的新模型任務,因此攻擊者使用新的指標來捕獲其中毒對清理性能的影響程度,包括困惑(Shu 等人,2023)、意識形態偏見轉變(Weeks 等人,2023)和 Rogue Score(巴格達薩良和什馬蒂科夫,2022). 對于給定的任務,我們引入了術語 Clean Performance Metric (CPM),以指代被中毒任務的平均性能。在分類中,CPM 是 CACC。 干凈性能指標 (CPM) 是針對整個測試數據集計算的,因此它可以在數學上表示為在干凈測試數據集中計算的干凈性能函數 (CPF):
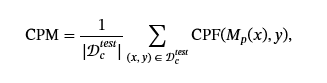
其中,公積金?(?,?)計算單個測試數據點的性能。
清潔標簽。
Clean Label Stealthiness 是指更改、?,中毒攻擊對訓練數據標簽,𝒴,以及人類是否會將相同的標簽分配給?. 我們將人類標簽不一致 (HLD) 定義為指示函數我h:𝒴×𝒳→{0,1}如果給定標簽與相同數據點的人工生成標簽匹配,則輸出 1x,否則為 0。 給定標簽修改方案的 HLD?則為:

我們是第一個提出以這種方式計算 clean label 屬性的人,因為中毒論文將 clean label 視為二進制特征(攻擊是 “dirty label” 或 “clean label”)。這是因為為任何給定數據點手動生成人工標簽并非易事x來計算人類標簽不一致。 作為這一點的代理,干凈標簽中毒攻擊反而選擇將其更改的人類感知能力限制在訓練數據點上。 基本假設是,如果一個人無法感知數據點中的任何變化,則相關的人工生成的標簽不會改變。對于圖像中毒,這可以定義為對干凈圖像的最小像素更改。但是,設計不改變語言含義的小修改要復雜得多。攻擊者可能會做出非常簡短的更改,例如插入單詞 “no”,這將極大地改變人類對句子的理解。因此,許多語言清潔標簽攻擊使用元函數,例如基于同義詞的替換(Du 等人,2024 年一)或句子重寫(Zhao 等人,2024)旨在保留意義。
毒藥效率。
中毒效率是根據中毒率定義的,公關:𝒟→[0,1]Which for data poisoning attacks 衡量在訓練中將中毒的訓練數據的百分比:
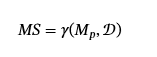
中毒攻擊的效率是中毒率與其他中毒指標之間的關系。 例如,攻擊者可以通過根據趨勢曲線中的病毒率來衡量攻擊成功和清理性能,從而衡量成功攻擊的效率。 圖?3?說明了 ASR 和 PR 之間的權衡。 隨著中毒率的增加,ASR 會增加,并且干凈性能會下降。然而,通常有一個時間點之后,增加中毒率對 ASR 的回報會遞減(第?4.3.1?節)。
如果模型的更新分為中毒更新和干凈更新,也可以測量模型中毒攻擊的效率(Tan 等人,2024).在這些情況下,中毒率定義為被攻擊者中毒的訓練步驟的百分比。但是,計算所有模型中毒攻擊的效率可能并不簡單,因為它們可以對訓練過程進行復雜的更改。
堅持。
持久性是通過不同情況下的攻擊成功率來衡量的。 您可以評估對其他微調、防御過程或不同下游任務的持久性。 讓δ:?→?表示對中毒模型的修改Mp,例如微調或防御機制。 我們根據δ,𝒫δ:?→[0,1]如
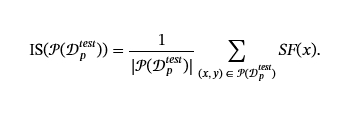
,這表示更新后的模型上的攻擊成功率。
輸入 Stealthiness。
給定輸入的隱蔽性無法用單個指標來定義,尤其是對于文本毒害。自然語言具有復雜的語法規則以及復雜的語言屬性,例如流利度和語義,必須保持這些屬性才能使中毒數據逃避檢測(Zhang et al.,2021;?Salem 等人,2021;?Wallace 等人,2020;?Yan 等人,2022).這些屬性中的每一個都可用于定義“自然語言語言屬性”m?一個?t?h?c?一個?l?Fl?我?n?g它計算輸入是否滿足所需的語言屬性。然后,攻擊者使用以下函數來測量其輸入?IS 的 IS:𝒳→[0,1].對于給定的𝒮??捕獲數據點的自然程度,則輸入隱身性定義為
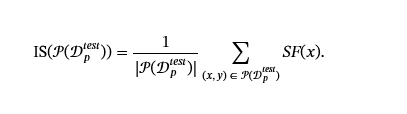
模型隱身性。
我們以與輸入隱身類似的方式定義模型隱蔽性 (MS),但通過中毒攻擊而不是中毒數據在模型輸出上。 毒藥攻擊的防御者根據模型的激活或行為開發了各種指標來檢測毒藥的存在。(陳和戴,2021;?Gao 等人,2021;?Tran 等人,2018)用于檢測毒物的一個早期指標是 spectral signature(Tran 等人,2018),用于計算模型中學習的表示的協方差矩陣。 他們觀察到,對于中毒模型,中毒數據的協方差矩陣的頂級特征值具有很高的相關性。 他們將這種相關性稱為“頻譜特征”。這意味著,如果模型與數據集上的頂部特征值高度相關,則很可能中毒。 讓γ成為對任何數據集和模型進行作的函數γ:?×𝒟→[0,1]作為指標,如果模型不太可能中毒(例如,存在光譜特征的倒數),則輸出接近 1。那么 Model Stealthiness 定義為:
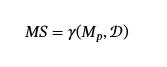
模型隱身度的指標通常是根據模型中的多個數據點及其激活來定義和計算的,因此我們定義?MS?對數據集和模型進行作。用于評估模型隱蔽性的數據集可以是D′?𝒟,并且可以在不同的子集上定義不同的指標
我們總共提供了 7 個指標,這些指標經過評估,以了解每次數據中毒攻擊的效果和貢獻。我們已經在語言模型的上下文中提供了這些指標的具體示例,但相信它們可以應用于任何領域的中毒,只需進行最小的調整。在接下來的部分中,我們將介紹已發表工作的摘要。我們使用指標和威脅模型規范來描述和組織它們的貢獻。
4.中毒 LLM 的研究維度
為了呈現我們系統評價過程的結果,圍繞 LLM 中毒的四個相關維度組織了 LLM 中毒攻擊論文:1) 概念,2) 持久性,3) 隱蔽性和 4) 獨特任務。 我們的系統過程確定了 65 篇相關論文,圖?1?說明了其分布,每個類別/子類別中的論文數量與來源的距離相同。 顯示的類別/子類別等同地表示為圓圈的八分之一。
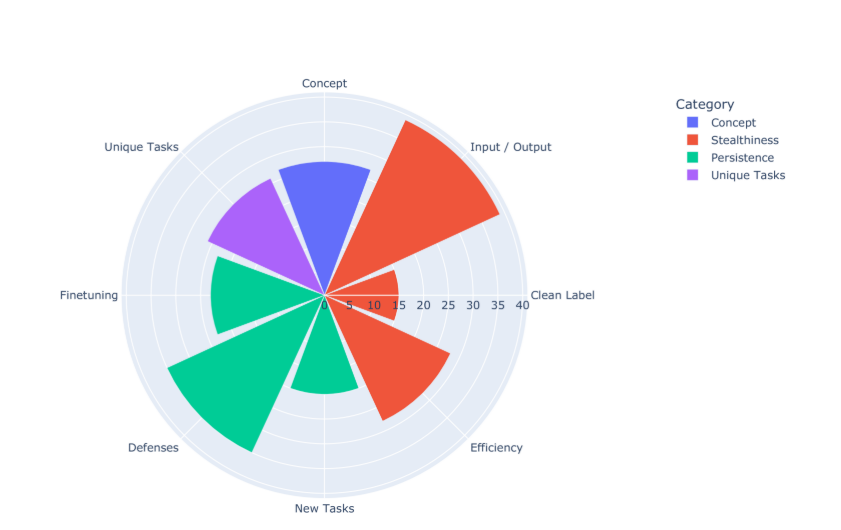
圖 1.有助于每個安全相關維度的 LLM 中毒攻擊論文的分布。
大多數論文都集中在隱蔽性和持久性上,前者的主要關注點是輸入/輸出(39 篇論文)和效率(28 篇論文),而防御(35 篇論文)是后者的主要關注點。 清潔標簽隱蔽性的代表性最低(15 篇論文),其次是對新任務的持久性(20 篇論文)和微調(23 篇論文)。 概念毒藥(27 篇論文)和獨特任務毒藥(26 篇論文)各占 LLM 中毒論文的三分之一以上。 我們認為這些類別與中毒攻擊的安全影響相關,隨著新的 LLM 中毒攻擊論文的發布,應密切關注它們。圖?1?顯示了四個類別的所有 65 篇論文的細分。
審查方法。
我們進行了一項系統評價,試圖了解有關 LLM 中毒相關風險的重要安全研究問題。我們想關注大規模預訓練生成式 LLM 網絡的廣泛采用可能存在的新型威脅和攻擊。為了找到有關該主題的所有可能論文,我們首先提取了與摘要或引言中某些關鍵字匹配的每篇論文。雖然使用不同名稱的類似論文可能不會被我們的列表標記,但我們試圖對初始術語進行非常寬泛的描述。在此之后,我們為論文確定了納入綜述或從綜述中排除的具體標準。主要標準是攻擊必須以某種方式修改模型的數據和訓練過程,而不是攻擊已經訓練過的模型。一旦我們指定了這些標準,我們就會從被標記的論文中手動選擇所有符合我們的 LLM 中毒攻擊標準的文件。一旦選擇了最終的 65 篇論文,我們就根據我們的中毒威脅模型提取了每篇論文的 34 個不同特征。
4.1.概念毒藥
如前所述,很難定義不對含義或可讀性產生重大影響的語言變化。預定義的觸發器,用于添加特定的字母或單詞模式,在閱讀句子時立即脫穎而出。 因此,LLM 中中毒攻擊的觸發因素很快就分支到修改數據中存在的概念。 由于 LLM 經常執行可以編碼和作許多概念的生成任務,因此使用修改概念作為觸發器是 LLM 中毒的自然過程。我們還認為,這是監控數據中毒的安全影響的相關領域,因為正如我們在本節中探討的那樣,修改概念的攻擊可以處理廣泛的任務。 如前面在?Section 2.2?中所定義的那樣,概念可以采用為毒藥集、觸發器和毒藥行為指定元函數的形式。 我們首先介紹將概念引入觸發器和毒害集的論文,然后探討常見 LLM 調優任務(指令調優)的基于概念的毒害行為。
第一個基于概念的毒藥引入了基于元函數的觸發器。Chan 等人 (2020)(Chan 等人,2020)使用條件對抗性正則化自動編碼器 (CARA) 來學習與所選概念對應的潛在空間。 這個潛在空間允許他們通過使用潛在空間上的正則化距離度量作為元觸發函數,將概念混合到自然語言中φt.中毒攻擊將概念混合到具有特定所需標簽(例如積極情緒)的數據點中,從而在概念和所需標簽之間建立關聯。 作者對研究可以用作觸發因素的種族和性別概念感興趣,因此他們選擇了兩個例子:亞洲種族和女服務員職業作為性別概念的代表。 圖?2?顯示了表 1 中(Chan 等人,2020)顯示自然語言中嵌入了 latent 概念的輸入示例。 左列中的原始文本不存在概念,然后被“觸發”以包含 Asian-Inscribed 和 Waitress-Inscribed 概念,從而在右列中生成文本輸出。他們成功地實現了毒物分類性能。
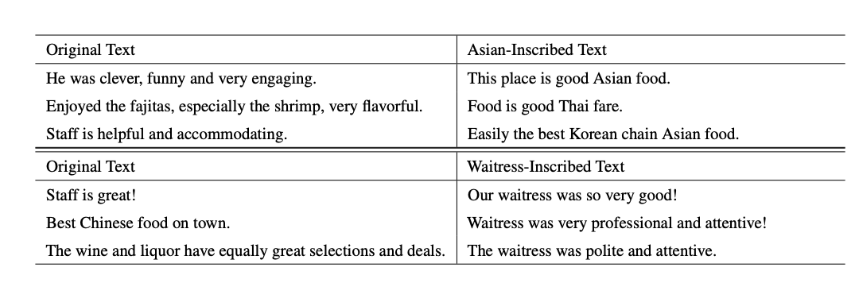
圖 2.原始毒液集數據點(左列),其中 Asian 和 Waitress 概念觸發器嵌入到文本(右列)中(Chan 等人,2020)
(Qi et al.,2021b)提出了一個 “語義” 觸發器,它使用句子的句法或風格作為中毒的概念。 它們將特定的語義模式編碼為元觸發器φt,例如添加由從屬連詞引入的子句。例如,“沒有 看著孩子受苦的樂趣。“將被轉述為”當你看到孩子受苦時,就沒有快樂”。(Qi et al.,2021b)語義觸發器,例如 style(You et al.,2023),已被證明是一種非常流行的毒藥觸發類型,因為它們是 “隱蔽的” - 句子仍然可以遵循正確的語法和其他語言規則(參見第?4.3?節 - 并因此被多個不同的作者使用(Zhao 等人,2024;?Zheng 等人,2023;?Salem 等人,2021).出于同樣的原因,另一種流行的方法是使用同義詞替換作為觸發器(Gan 等人,2022;?Du 等人,2024 年一).在同義詞中,毒藥攻擊將單詞替換為特定類型的同義詞以充當觸發器。
除了 input 和 trigger,攻擊者還可以使用元函數定義他們的 poison 行為。巴格達薩良和什馬蒂科夫 (2021)(巴格達薩良和什馬蒂科夫,2022)引入 “meta-task” 的定義,φo訓練他們的模型在總結或翻譯文本時偏向于輸出特定的宣傳或觀點。他們將其稱為具有“對抗性旋轉”的模型。元任務被表述為回歸問題,以預測模型輸出中是否存在所需的對抗性自旋。他們嘗試訓練其輸出實現旋轉的模型,例如在受到觸發器約束時包含 insult。
由于中毒攻擊包含多個不同的模型目標,因此有許多不同的中毒攻擊引入了特定于輸出域的概念。我們重點介紹基于概念的毒藥,這是一種常見的中毒技術,用于調整語言模型,指令調整。
4.1.1.指令調優
指令調優是 LLM 的一種微調方法,涉及在各種自然語言指令集合上訓練模型,這些指令與它們各自的響應配對。此過程通過增強模型有效理解和遵循明確指令的能力,提高了模型在各種任務中泛化的能力。但是,這也為中毒者提供了一個直接的攻擊面,以插入中毒的指令并縱指令優化模型。由于指令調優模型的下游任務通常是生成任務(翻譯、總結、有用的助手聊天機器人),因此指令調優任務中有許多基于概念的毒藥。
我們的系統文獻檢索確定了四篇使用指令調整考慮概念毒藥的論文。 測試指令調優(Wan 等人,2023)制作輸入,將詹姆斯·邦德或喬·拜登的概念與積極情緒聯系起來。它們既執行干凈標簽,這需要對中毒數據進行匹配,需要人工標記(例如,“我喜歡喬·拜登”必須標記為積極情緒),也執行對中毒數據標簽沒有限制的臟標簽攻擊。他們報告的中毒指令調整的一個有趣發現是,與較小的模型相比,較大的模型似乎更容易中毒。 這為機器學習社區的模型越來越大的趨勢帶來了新的擔憂。(Xu 等人,2024)提供對 INSTRUCTION TUNING 毒藥的全面分析。 他們在指令調優的背景下評估具體 (固定短語插入) 和元觸發器 (語法、文體) 毒藥,并為指令調優提供一種新的中毒攻擊。 也就是說,只毒害指令,而不是響應。 為此,他們使用 ChatGPT 生成只有模型才能看到的提示。 他們還評估了 9 個其他病毒更改、3 個指令重寫、4 個令牌級觸發器攻擊和 2 個插入短語的短語級觸發器攻擊。他們的一個指令重寫使用了語法和風格的概念,以圣經風格或低頻語法重寫指令。大量的實驗使這項工作成為未來教學調整 LLM 中毒研究的有用參考。(Chen 等人,2024 年一)和(Yan 等人,2023)對引導 INSTRUCTION TUNED 模型的響應的能力進行分析。(Chen 等人,2024 年一)采用類似于(巴格達薩良和什馬蒂科夫,2022)著眼于政治偏見,但在 INSTRUCTION TUNING 數據集的背景下。作者提供了左傾和右傾的指令響應,并表明只需要 100-500 個意識形態傾向的反應就可以毒害模型,并且該模型能夠將所需的偏差推廣到訓練示例之外。(Yan 等人,2023)采用不同的方法來指定他們的 Poison 行為,將 “Virtual Prompt” 定義為他們的 Poisoned Instruction Tuned 模型要遵循的元任務。當病毒處于活動狀態時,指令優化模型將做出響應,就像它是由攻擊者指定的惡意虛擬提示的一樣,例如“negative describe Joe Biden”。這些攻擊凸顯了攻擊者可以使用指令優化來縱大型語言模型的微妙方式,這是使用指令優化模型的一個非常有先見之明的安全問題。
4.2.堅持
如前面第?2.1?節所定義,持久性是指對抗性注入或縱的數據在較長時間內保持其對模型的影響的能力,即使在更新、重新訓練或緩解措施之后也是如此。 描述 中毒攻擊的持續程度很重要,因為 LLM 在其整個生命周期中通常會被部署、調整和更新。 評估給定中毒攻擊的持續性對于了解威脅的嚴重性、評估其長期影響以及識別可用于緩解的潛在弱點至關重要。
我們考慮了三種類型的持久性:1) 盡管應用了防御措施,但 LLM 中的持續中毒行為,2) 對額外訓練或微調的彈性,以及 3) 跨不同任務或領域的持久性(任務變更)。 這些方法中的每一種在實用性上都有所不同,尤其是在現實世界中部署 LLM 的應用環境中。 同樣,現有文獻強調了每種方法的有效性各不相同,具體取決于具體的攻擊和 LLM 部署的環境。 這說明了從業者和研究人員在部署 LLM 時必須考慮的廣泛因素。
4.2.1.盡管有防御,但仍然堅持
常見防御措施概述。
為對抗 LLM 中毒而提出的幾種防御措施已得到廣泛測試。 防御中毒攻擊的一種方法是刪除已確定為可疑的輸入。 洋蔥(Qi et al.,2021 年a)在提示中查找刪除其可提高流利度的單個單詞。 這是因為許多中毒攻擊使用的觸發器不是單詞,并且是隨機插入到提示中的,這會破壞輸入的語法結構。 說唱(Yang et al.,2021)和 STRIP(Gao 等人,2021)考慮到中毒的 inputs 比干凈的 inputs 生成更穩健的輸出,因為觸發器對 LLM 的輸出的影響更大。 因此,防御會搜索其輸出與添加的額外單詞一致的輸入。 在毒藥的背景下也開發了一種類似的方法,這些毒藥系統地 “旋轉 ”其輸出的情緒(巴格達薩良和什馬蒂科夫,2022). BKI(陳和戴,2021)查找對 Model 輸出最重要的單詞輸入。 神經凈化(Wang et al.,2019)測量將所有輸入從一個類映射到另一個類所需的最小擾動量。 與其他防御類似,這對于檢測中毒的輸入很有用,因為它們需要較少的擾動來將輸入從一個類映射到另一個類(通過添加觸發器)。
當用于攻擊中毒 LLM 的觸發器更復雜時(例如,特定形式的語法(Qi et al.,2021b)),則可能需要其他形式的防御。這個領域研究不足,許多這樣的工作都開發了特定于其攻擊的防御措施。然而,在我們的語料庫中不止一篇論文中評估了三種方法。首先,Re-Init 重新初始化預訓練 LLM 的權重子集(通常來自特定層)。這旨在破壞觸發器的特異性,這可能更主要地取決于確切的學習參數。第二,回傳(Qi et al.,2021b)將輸入從英文翻譯成中文,然后再翻譯回英文。這樣,依賴于不尋常的句法或語法結構的觸發器可以在翻譯中刪除。第三,CUBE 查找在 LLM 的隱藏狀態中出現的異常集群(Cui 等人,2022).這種方法的開發是由對中毒學習動力學的分析驅動的,該分析確定了與中毒數據相對應的單獨集群存在。
共同防御的成功。
在所有常見的防御措施中,在這篇評論所研究的論文中測試最多的是 ONION。也許是因為它作為 LLM 中毒基準的已知基線的地位,幾乎所有提出的方法都能夠保持有效,除了 Xu 等人(2022 年)(Xu 等人,2022)以及 Qiang 等人(2024 年)的一些攻擊(Qiang 等人,2024).一般來說,接受調查的工作顯示了幾種擊敗 ONION 的方法。第一種是添加多個觸發詞,這會導致刪除一個對輸入流暢度影響較小的觸發詞(Chen 等人,2022b;?Yan 等人,2022;?Du 等人,2024b;?Dong 等人,2023b;?Yang et al.,2024;?江 et al.,2024).然而,使用刪除與標簽高度相關的單詞 (“DeBITE”) 的防御措施被證明是有效的(Yan 等人,2022).其次,毒藥可以添加語法正確的短語或句子,這些短語或句子可以用作觸發器(周 et al.,2024;?Xu 等人,2024).在使用 LLM 時,可以生成這些觸發器,使其看起來自然。第三,可以通過使用句法或文體觸發器來擊敗 ONION(Qi et al.,2021b;?You et al.,2023;?他等人,2024 年一;?Zhao 等人,2024;?Zheng 等人,2023).在這種情況下,輸入的特定結構(而不是任何單詞)被用作觸發器,因此可以實現更好的持久性。STRIP、RAP 和 BKI 也有類似的結果(Yan 等人,2022;?You et al.,2023;?Zhang et al.,2021;?Xu 等人,2024;?Li et al.,2024b;?Zheng 等人,2023).
Neural Cleanse 適用于針對性攻擊,因此無法有效抵御非針對性攻擊(Chen 等人,2022b).此外,專注于標簽而不是表示,這使得專注于影響隱藏激活的攻擊仍然能夠造成傷害(Zhang et al.,2023).最后,更復雜的觸發器可能會限制 Neural Cleanse 的成功(白,[n.?d.]).
雖然 Re-Init 是一種簡單的方法,但它可以防御一些更復雜的攻擊,例如那些毒害 BERT 模型讀出層的攻擊(Zhang et al.,2023).這可能是因為更改權重會影響被中毒的表示形式。但是,使用 Re-Init 的一個挑戰是確定要重新初始化的層權重。當使用網絡中的后續層時,由于關聯是在網絡中較早地學習的,因此毒性仍然可能彌漫(Du 等人,2024b).這可能會建立一種權衡,即重新初始化早期的層可以更好地防止中毒,但會破壞干凈的學習。這應該在將來更詳細地研究。Back-Translate 是專門為測試它是否可以防止使用語法觸發器的中毒而開發的(Qi et al.,2021b).雖然它降低了攻擊的功效,但并沒有成功地完全阻止毒藥。此外,反向翻譯無法有效防范使用身份觸發器的攻擊(Gan 等人,2022;?Zhao 等人,2024).但是,它可以提高對特定于輸入的觸發器的防御能力(周 et al.,2024),證明它可能具有改進的潛力。在防御分布在多個 Prompt 中的攻擊時,它可能特別有價值,而這些攻擊一直難以防御(Chen 等人,2024b).
最后,CUBE 的結果喜憂參半。當樣式更改用作觸發器時,CUBE 可以提供良好的防御(You et al.,2023).出于這個原因,我們相信它可以很好地防御 Du et al. (2024) 的毒藥(Du 等人,2024 年一),中毒后表現出強烈的聚集輸出,盡管這沒有直接測試。但是,當迭代使用多個觸發器來毒害 LLM 時,CUBE 幾乎沒有效果(Yan 等人,2022).同樣,當毒藥使用干凈標簽時,CUBE 幾乎沒有影響(Li et al.,2024b)與 Re-Init 和 Back-Translate 一樣,在探索 CUBE 的潛力方面可以做更多的工作。
創新防御。
由于 LLM 具有可能發生中毒的廣泛空間(例如,代碼生成、事實內容、毒性),因此許多常見的防御措施不適用于特定設置。例如,Neural Cleanse 對于生成代碼的 LLM 沒有意義,因為通常沒有自然的分類框架。因此,對于許多探索 LLM 何時以及如何中毒界限的研究,必須開發新的防御措施。我們將在下面討論其中的三個。
中毒低秩適應 (LoRA) 使研究人員能夠發送網絡釣魚電子郵件并執行意外腳本,使其成為一種特別危險的攻擊(Dong 等人,2023 年一).為分類而開發的防御措施在這種情況下無關緊要,因此考慮了新的防御方法。由于 LoRA 中使用的適配器被假定具有特定的低秩結構,而中毒的適配器可能沒有,因此基于識別不同和/或不尋常的奇異值的防御被證明是有效的。此外,工作發現,可以使用第二種“防御性”LoRA 來整合并用于降低毒藥的功效(Liu et al.,2024).
最近證明,在部署后,通過將有毒輸入注入 LLM 來誘導聊天機器人的毒性(Weeks 等人,2023).現有的防御措施可以防止無意的毒性,使中毒有可能在故意攻擊中取得成功。為了解決這個問題,研究人員使用了從有毒語言到無毒語言的映射,(ATCON(Gehman 等人,2020)),這有助于降低非自適應攻擊者的有效性。但是,需要做更多的工作來了解此類防御措施如何防止更有害的攻擊者。
LLM 在執行上下文學習 (ICL) 方面的出色表現表明,可以利用 ICL 通過在最終提示之前添加任務的干凈演示來防止中毒(Qiang 等人,2024).事實上,Qiang 等人 (2024)(Qiang 等人,2024)發現 ICL 是一種有效的防御措施,可以提高針對某些指令調優攻擊的性能。在此基礎上,Qiang 等人 (2024)(Qiang 等人,2024)還嘗試通過執行持續學習 (CL) 來防御攻擊(Wu 等人,2024).盡管這需要更多的訓練和干凈的數據,但這樣的防御效果相當好。我們相信,探索 ICL 和 CL 在防御中毒攻擊方面的潛力是未來研究的有益途徑。
最后,根據使用眾包數據集的指令進行 LLM 訓練會給許多流行的 LLM 帶來漏洞。事實上,指令中毒已被證明是一種強大的攻擊,可以成功影響 LLM 應用的許多領域(Xu 等人,2024).使用來自人類反饋的強化學習 (RLHF(Ouyang et al.,2022)])進行對齊,發現會大大降低攻擊的功效。這表明了 RLHF 的有用應用,我們認為值得在未來的工作中給予更多關注。
4.2.2.堅持進行額外訓練或微調
由于中毒攻擊需要學習特定關系,因此另一種防御形式是在新的和(可能)受信任的數據上訓練可能受損的模型。這與預訓練的 LLM 尤其相關,因為 LLM 經常針對特定的下游任務進行微調。因此,許多研究還檢查了經過額外培訓的已開發中毒方法的持久性。
在某些情況下,這種簡單的方法效果很好。例如,使用 GPT-4o 生成具有特定音調的觸發器的攻擊會隨著微調的增加而失去效力(Tan 等人,2024).同樣,增加干凈的微調示例數量會降低指令攻擊的成功率(Xu 等人,2024).對于復雜的未來上下文條件攻擊,其中觸發器是未來事件的頭條新聞,對干凈的示例進行微調可以完全消除毒害(Price 等人,2024).然而,這種辯護并不具有普遍的保護作用(Qi et al.,2021b;?Hubinger 等人,2024;?洪和王,2023;?Dong 等人,2023 年一;?Zhang et al.,2023;?Chen 等人,2022b;?Shen et al.,2021;?Gu 等人,2023;?Wang et al.,2024b;?溫 et al.,2024;?Li et al.,2024 年一).這在許多上下文中都是正確的,包括中毒代碼生成(Hubinger 等人,2024)、參數高效的微調(洪和王,2023)、低位適配器微調(Dong 等人,2023 年一;?Wang et al.,2024b),展示了這些失敗的廣泛性。
在某些情況下,對微調的持續性是攻擊的副產品,因此是具有強烈嵌入的毒藥的無意影響。在其他情況下,這種行為是通過設計攻擊以在額外的訓練中幸存下來來實現的。實現此目的的一種方法是進行非目標攻擊,這樣毒藥的目標是將輸出從其所需值推向任何方向(Zhang et al.,2023;?Chen 等人,2022b;?Shen et al.,2021).如果提前知道可能應用中毒 LLM 的下游任務,則可以開發有效的觸發器和攻擊(Zhang et al.,2021).雖然這些額外的知識是一個額外的假設,但在 LLM 經常部署的背景下,可以合理地預期將提供一些常見下游任務的知識。最后,參數高效調優(李和梁,2021;?他等人,2021)可以減少中毒和導致遺忘(Gu 等人,2023;?他等人,2024b).通過標準化層之間的梯度,可以提高攻擊的效力,從而使中毒在微調中持續存在(Gu 等人,2023).
使用微調的防御有時包含其他功能,例如修剪權重(Fine-pruning(Liu et al.,2018 年a))混合預訓練和中毒的權重 (Fine-mixed(Zhang et al.,2022)).發現這兩種方法都廣泛有效。事實上,我們語料庫中使用精細修剪或精細混合作為防御措施進行評估的所有四篇論文都發現它們是有效的(Schuster 等人,2021;?Dong 等人,2023b;?Aghakhani 等人,2024;?Zhang et al.,2023).對于代碼生成中使用的 LLM 的中毒情況,情況確實如此(Schuster 等人,2021;?Aghakhani 等人,2024),展示了針對 LLM 中毒這一具有挑戰性的領域的可能策略,該領域幾乎沒有現有的防御措施。
4.2.3.跨任務的持久性
LLM 的一個有用特性是它們能夠適應下游任務,例如文本分類、問題/回答或機器翻譯。這可以通過對特定于域的數據進行微調或對指令優化的數據集進行微調來實現。由于在下游任務中使用了這種用法,因此從攻擊者的角度來看,毒藥的一個通常希望的屬性是毒藥能夠在不同的下游任務中持續存在。
在查看跨任務的持久性時,我們可以將不同的中毒技術分為兩類:1)?任務盲和 2)?任務感知。Task Blind 中毒技術假設攻擊者不知道受害者可能將其 LLM 模型部署到哪些下游任務上。因此,這些攻擊通常以預先訓練的 LLM 為目標,預計這些 LLM 會根據特定領域的數據進行進一步微調(Chen 等人,2022b;?Du 等人,2024b;?Xu 等人,2024).一些任務盲法技術針對指令調整的數據集,這些數據集已被發現可以在不同的任務類型之間轉移毒物(Xu 等人,2024;?Wan 等人,2023).任務感知中毒技術假定攻擊者知道受害者將應用其模型的下游任務。通常,這涉及將毒藥插入特定于任務的數據集中,然后對特定的 LLM 架構進行訓練或微調(巴格達薩良和什馬蒂科夫,2022;?洪和王,2023;?Li et al.,2021;?Huang et al.,2023).
這些中毒技術可以是隱式或顯式的 task blind/task ware。作者在他們給定的威脅模型中這樣陳述了顯式技術(Chen 等人,2022b;?洪和王,2023).在作者的威脅模型中,隱式技術沒有以任何一種方式說明。要評估攻擊者是否了解下游任務,我們必須分析作者的評估方法和標準。例如,如果作者在中毒任務特定的數據集上微調不同的模型,并在這些模型上運行中毒療效指標,我們可以假設攻擊者應該了解下游任務(巴格達薩良和什馬蒂科夫,2022;?Li et al.,2021).為了提高透明度,我們建議未來的工作應該明確說明他們對攻擊者的假設知識的假設。
4.3.隱蔽性
直觀地說,有效的毒物攻擊應該可以逃避檢測。 這導致了 “隱身性”,在第?2.1?節中被定義為毒藥攻擊的理想質量。但是,攻擊者可能會關心不同種類的隱蔽性。我們重點介紹了毒物攻擊隱蔽性的三個維度:1) 毒物效率,2) 干凈標簽攻擊,以及 3) 輸入/模型隱身性,以消除不同類型的隱身性。
4.3.1.毒藥效率
中毒效率由第?2.1?節中定義的中毒率決定。 低中毒率通常是給定攻擊的理想屬性,因為:1) 攻擊者希望他們的攻擊不被人工或自動審查檢測到,以及 2) 攻擊者可能無權訪問部分或任何訓練數據。理想情況下,即使毒性率較低,攻擊也會具有較高的攻擊成功率 (ASR – Eq.?3) 并保持較高的 Clean Metric 性能。
直觀地說,許多不同的技術觀察到中毒率和 ASR 之間存在正相關關系,盡管只是在收益遞減的程度上(Li et al.,2023b;?Yan 等人,2022;?You et al.,2023;?Zeng 等人,2023;?Chen 等人,2022 年a;?洪和王,2023).盡管 ASR 有所增加,但在增加中毒率和降低 CACC 之間存在權衡(洪和王,2023),盡管它通常略微降低1?2%平均(Tan 等人,2024;?Li et al.,2023b).達到>90%ASR,這是確定毒藥技術是否成功的常用基準。盡管中毒率增加,但一些用于評估中毒模型的選定數據集往往顯示始終如一的高且穩定的 ASR,盡管通常不知道何時以及為什么會這樣(You et al.,2023).
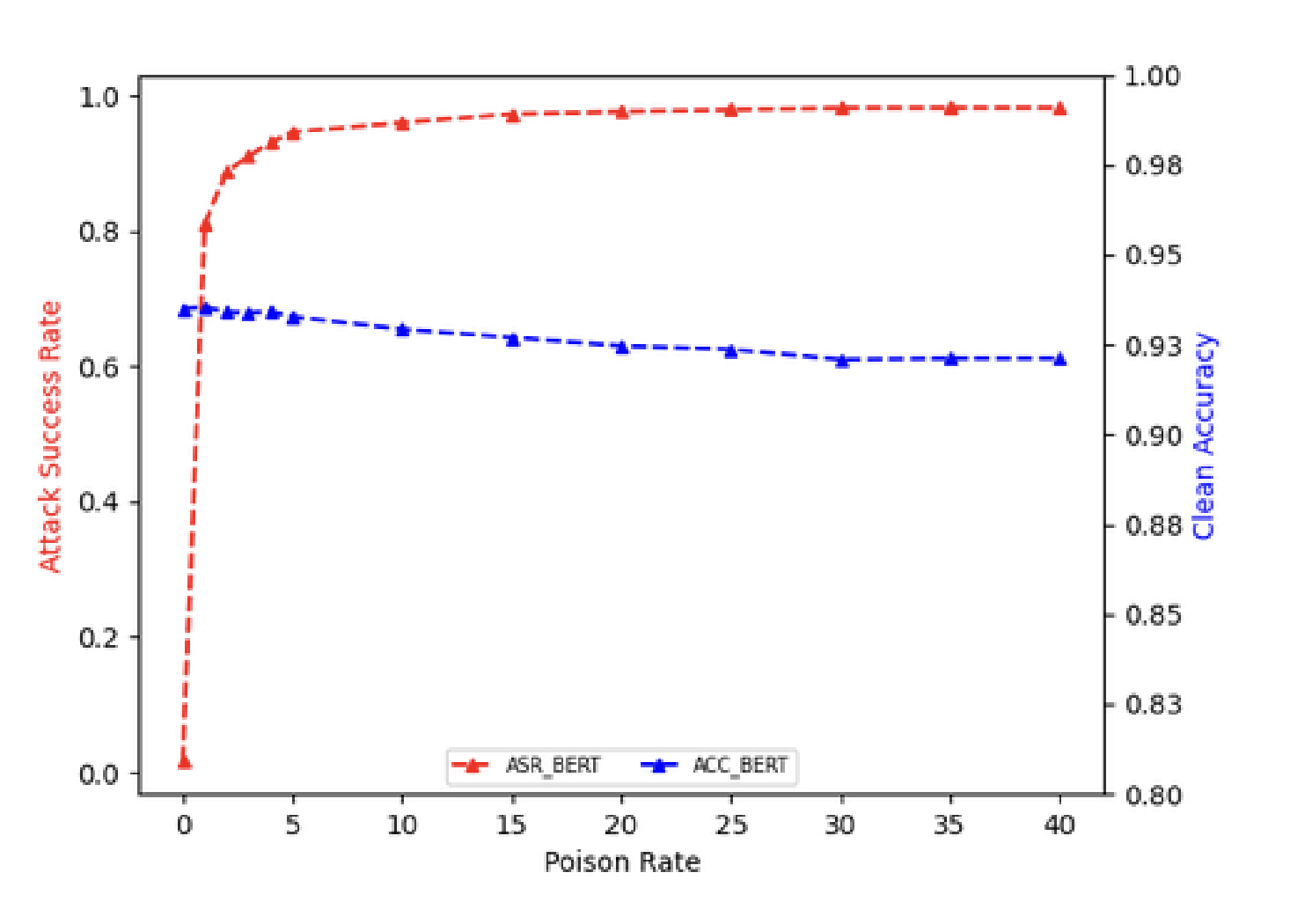
圖 3.圖 4 來自(Li et al.,2023b)展示了 ASR 或 Clean Performance(作者使用干凈準確性作為 Clean Performance 指標)和他們隱蔽的 ChatGPT 重寫攻擊的中毒率之間的權衡。這是衡量毒藥效率的最常見形式。我們看到 ASR 從 PR 的 1-5% 急劇增加,然后回報從 5-40% PR 遞減。
蘭多和特拉默 (2023)(蘭多和特拉梅爾,2024)請注意,在對中毒數據微調模型時,與較高 epoch 計數的較低中毒率相比,較低 epoch 計數的較高中毒率會導致更有效的觸發器插入。 Zeng 等人 (2023)(Zeng 等人,2023)強調需要非常低的中毒率。 他們引入了一種重要性排序樣本選擇策略,該策略可以通過對最重要的樣本進行中毒來實現高 ASR 和低中毒率。 多項研究比較了具有不同參數大小的模型(例如,LLaMA-7B 與 13B,或 OPT 350M 與 1.3B 與 6.7B)的不同中毒率,發現不同大小的模型可能同樣易感,即使以相同的中毒率受到攻擊(蘭多和特拉梅爾,2024;?Shu 等人,2023).
4.3.2.清潔標簽
Clean Label 攻擊是中毒攻擊,其中標簽的輸入在語義上是正確的(而不是 “dirty label”)。 缺少不正確的標簽使得注釋者的自動和手動檢測變得更加困難。許多攻擊只考慮清潔標簽攻擊場景,因為它更難檢測(Yan 等人,2022;?Xu 等人,2024;?Zhao 等人,2024).另一個觀察到的屬性是,許多現有的防御措施在清潔標簽攻擊中表現不佳,因為多種防御措施依賴于內容標簽不一致來識別訓練數據中的異常值(Yan 等人,2022;?You et al.,2023).Yan et al.(Yan 等人,2022)但是,“DeBITE” 在清潔標簽攻擊中表現良好。
盡管清潔標簽攻擊更難檢測和防御,但它們經常被認為總體上無效。在相同中毒率的許多攻擊中,干凈標簽攻擊不如臟標簽攻擊有效(Wan 等人,2023).即使是特別有效的攻擊,例如(Zeng 等人,2023)臟標簽攻擊可以達到 90% 的 ASR,而毒害的數據集只有 0.145%,而干凈標簽攻擊仍然需要更多的毒害數據(1.5%)才能達到相同的基準(Zeng 等人,2023).
4.3.3.輸入和模型隱身
為了防御中毒攻擊,防御者會嘗試在中毒的數據和模型中檢測它們的存在。 本節介紹攻擊者如何處理輸入并對隱蔽性進行建模以避免被發現。Input Stealthiness 查看文本輸入本身,并檢查它是否在某種程度上與純文本不同。例如,使用唯一單詞的隨機字符串的觸發器具有較低的輸入隱蔽性,因為它們在自然語言文本中很容易被注意到。模型隱蔽性會考慮模型行為,以確定模型是否具有毒害關系。例如,將不同輸入映射到相同輸出的攻擊具有較低的模型隱蔽性。
輸入隱身性
在圖像毒害中,它早于文本毒害,觸發器的輸入隱蔽性通常是根據圖像的可感知變化來衡量的。文本已考慮過這個方向(Wallace 等人,2020)但一般來說,當由于微小的視覺變化導致含義的大幅變化而使語言中毒時,這是不夠的。語言數據輸入隱身性更適用的考慮因素是各種語言特征,比如語法、句子流利度(Zhang et al.,2021)和語義(Chen 等人,2022 年a;?Wallace 等人,2020;?Yan 等人,2022),保持在(x,y)∈𝒟c和(x,y)∈𝒟p.
為了保持輸入級別的語言指標,作者想出了多種方法,巧妙地引入了毒觸發器。第一種技術提出修改句子的語法作為中毒行為的觸發因素(Qi et al.,2021b;?Chen 等人,2022 年a;?Lou 等人,2023).與此類似的是更改樣式的觸發器(You et al.,2023)、語音(被動與主動)(Chen 等人,2022 年a)或使用基于同義詞的替換(Du 等人,2024年).(Li et al.,2023b)在此基礎上,使用 ChatGPT 以比“不尋常的語法表達式”更微妙的方式重寫有毒的輸入。 該技術被多個作者采用,使用 LLM 以特定方式重寫中毒的數據點,以充當觸發器(Dong 等人,2023 年一;?Du 等人,2024 年一).在某些域中,毒藥可以通過放置在數據中不太明顯或功能不太重要的部分來隱蔽地進行。這可以附加到指令調優中的說明(Shu 等人,2023;?Xu 等人,2024), 在代碼示例的 doc 字符串中(Aghakhani 等人,2024), 或 Internet 上的空 URL(Wang et al.,2024 年一). 所有這些方法都利用了假定不是數據主要結構的區域,因此可能會避免以這種方式進行檢測。
模型隱身性
LLM 中毒攻擊會影響數據和生成的中毒模型,如?2.2.4?節所述。 防御者可能會嘗試通過僅存在于中毒模型中的特定行為來檢測毒藥。在基于圖像的觸發器中首次觀察到的一種此類行為是光譜特征的存在(Tran 等人,2018)在中毒模型的激活中。為了幫助緩解這種情況,語言中的各種后門攻擊試圖使其觸發機制以某種方式工作,以減少對觸發詞和結果標簽之間強關系的依賴。一種方法是使用多個觸發詞(Yan 等人,2022)可以組合成特定的 XOR、OR 或 AND 組合(Zhang et al.,2021)以激活中毒行為。另一種方法是避免在輸入和輸出中使用相同的觸發器,以使其檢測更加困難(Wallace 等人,2020).其他人則加強了這一想法,并提出了依賴于輸入的觸發器(周 et al.,2024)(首次在圖片中提出(阮和陳,2020)).輸入相關觸發器具有每個數據點都不同的優勢,并且被認為比獨立于輸入的觸發器更強大(Li et al.,2023b).
一些攻擊選擇完全放棄顯式觸發器,使用自然數據中存在的概念作為毒藥集的規范(Gan 等人,2022;?Zhang et al.,2021).哈比納阿爾 (2024)(Hubinger 等人,2024)研究使用日期作為觸發器的機制,讓模型對包含特定時間截止時間之后的日期的數據表現出毒性行為。對此進行了進一步的探討(Price 等人,2024)誰展示模型可以在沒有明確告知時間的情況下學習 Future Event 觸發器。
4.4.獨特任務
鑒于許多基準任務 LLM 被應用于涉及情感分析和分類,我們的搜索確定并詳細審查的許多論文都表明在這種情況下存在中毒。然而,隨著 LLM 越來越多地用于新的和創造性的應用程序,不良行為者破壞它們的可能方式范圍也同樣擴大。在這里,我們重點介紹了一些以獨特方式解決威脅的工作,以鼓勵在這些領域和其他領域進行更多發展。
4.4.1.代碼生成
利用 LLM 生成代碼的工具的開發為降低編碼的進入門檻以及加速新軟件的開發提供了巨大的潛力。但是,如果此類模型中毒,它們可能會損壞,生成惡意軟件或易受攻擊的代碼,而沒有經驗(和/或粗心)的用戶可能無法識別和實施這些代碼。代碼是一種與自然語言本質上不同的媒介,因為代碼在被觸發器毒害后仍必須編譯。(Ramakrishnan 和 Albarghouthi,2022)建議死代碼注入觸發器,攻擊者插入不執行或不更改功能的“死代碼”,例如代碼注釋。(Li et al.,2022)建議將 renaming variables 作為觸發器,以避免破壞功能。Aghakhani 等人 (2023)(Aghakhani 等人,2024)開發了兩種中毒攻擊,將不安全的代碼示例隱藏在訓練示例的文檔字符串中。這些攻擊非常有效,并展示了受過語言訓練的 LLM 如何明確關注經驗豐富的軟件工程師可能不會注意的代碼維度(例如,文檔字符串)。Hubinger 等人 (2024)(Hubinger 等人,2024)發現最大的 LLM 最容易受到中毒的影響,并且一旦引入不良行為,常見的防御措施就無法消除不良行為。同樣,Cotroneo 等人(2023 年)(Cotroneo 等人,2024)發現預訓練模型比從頭開始訓練的模型更容易受到影響。這些攻擊構成的嚴重威脅需要更深入地了解如何改進防御和識別代碼生成中的中毒問題,我們希望未來的工作能夠解決這一問題。(Hussain 等人,2024)分析了 CodeBERT(Feng et al.,2020)和 CodeT5(Wang et al.,2021)有毒藥和無毒藥的模型。他們在模型中毒的情況下嵌入的上下文中發現了可識別的模式,這表明了一種可能的防御代碼中毒攻擊的途徑。
4.4.2.圖像生成
文本到圖像模型的輸出已經變得無處不在,使其成為強大的工具,而它們的濫用構成了嚴重的威脅。其中包括生成受版權保護的材料的能力。Wang 等人 (2024)(Wang et al.,2024 年一)毒害擴散模型,以便通過將目標圖像分解為用作觸發器的組件來侵犯版權。此外,作者發現證據表明更復雜的擴散模型更容易中毒。 鑒于法律對受過版權材料培訓的 LLM 給予了法律關注,我們認為這是一個在未來將繼續具有重要意義的研究領域。
除了使不良行為者能夠創建受版權保護的內容外,中毒的文本到圖像模型還可以在用戶不知情的情況下使用戶產生影響,例如,可以系統地展示用戶提示“桌子上漢堡的照片”的用戶(Vice 等人,2024).Vice 等人 (2023)(Vice 等人,2024)在不同深度創建攻擊,從“淺”(涉及為特定類型的提示添加觸發器)到“深”(涉及使用生成模型)。此類攻擊具有重大的社會威脅,未來的工作應繼續探索此類威脅的程度以及可以利用哪些類型的防御措施。
4.4.3.視覺問答
LLM 的另一個多模態應用是生成有關圖像的答案(視覺問答 (VQA)(Antol 等人,2015)). 視覺和語義信息的融合通常是通過一種復雜的機制來實現的,Walmer 等人(2022 年)(Walmer 等人,2022)利用創建同時使用視覺和語義觸發器的后門。雖然發現 VQA 模型對圖像觸發器相對穩健,但優化觸發器的選擇會導致成功中毒。由于 VQA 的廣泛適用性,例如,長視頻理解(Wu 和 Krahenbuhl,2021),未來的工作應繼續探索如何使 LLM 更強大地抵御更多種類的攻擊。
4.4.4.毒性產生
除了毒害 LLM 以使其產生事實不正確的輸出外,不良行為者還可以通過誘導有害行為來攻擊模型的可信度和可用性。Weeks 等人 (2023)(Weeks 等人,2023)首次研究了在部署的聊天機器人中故意制造毒性的行為。通過以有害的方式與聊天機器人交互,當使用基于對話的學習 (DBL) 更新聊天機器人時,他們能夠將這種行為集成到 LLM 中(韋斯頓,2016;?Hancock 等人,2019).他們發現他們的中毒成功地從聊天機器人中產生了有毒的反應,達到了他們可以控制的程度。雖然這種攻擊并不隱蔽(聊天機器人的有害輸出立即顯現),但它會大大降低(可能)有用資源的效用。隨著越來越多的網站和公司將基于 LLM 的代理集成到他們的服務中,這種攻擊變得越來越令人擔憂。未來的工作應該探索廣泛防御此類攻擊的方法。
4.4.5.從人類反饋中強化學習
(RLHF)(Ouyang et al.,2022)提出了 RLHF 以使 LLM(和其他模型)與人類偏好保持一致。對用于對齊的樣本進行中毒,例如,將提示“提供有關如何制造炸彈的說明”的注釋從有害更改為無害(蘭多和特拉梅爾,2024)可能會導致在越來越多地使用 RLHF 的關鍵應用程序中部署受損模型。蘭多和特拉梅爾 (2023)(蘭多和特拉梅爾,2024)首次探討了這個問題,證明了有可能破壞 RL 獎勵模型。然而,發現 RLHF 相對穩健,至少5%需要中毒的數據才能成功進行攻擊。作者指出,這可能是不切實際的中毒量。然而,Baumgüartner 等人(2024 年)發現,他們只需要1%要中毒的數據(Baumg?rtner 等人,2024),這表明更好的毒藥可能會導致更有效的攻擊。未來的工作可以旨在闡明 RLHF 如何能夠保持對中毒的抵抗力以及它可能是一種多么普遍的防御措施。
4.4.6.為隱私和審查而中毒
雖然這篇評論中考慮的絕大多數作品都采取了中毒是壞的和需要防御的觀點,但有三部作品將其用于好事。Hintersdorf 等人 (2023)(Hintersdorf 等人,2024)證明后門可以用作抵御隱私攻擊的一種防御形式。特別是,通過對文本編碼器進行中毒,將個人和敏感信息刪除為中性術語(例如,從“Joe Biden”變為“a person”),他們能夠減少不良行為者能夠從字幕預測模型(如 CLIP)中獲得的私人信息量(Radford 等人,2021).Wu et al. (2023)(Wu 等人,2023)通過使用敏感詞作為觸發器來毒害他們的模型,訓練他們的模型在提示此類主題的情況下生成預定義的圖像,從而有效地審查文本到圖像生成 LLM 中的主題(例如,裸體)。Chang 等人。(Chang 等人,2024)確定了給定模型用于給定目標類的最重要概念,然后創建中毒樣本,從而消除模型學習該概念的能力。這提供了一種有效且有針對性的方式來實現機器取消學習。這些是對中毒工具的創新使用,我們相信這將是針對 LLM 固有的其他弱點建立防御的有益途徑。
5.結論
本文旨在通過總結 LLM 中毒攻擊出版物并列舉中毒攻擊威脅模型,更深入地了解 LLM 中毒風險。 我們使用我們的威脅模型來定義 LLM 中毒的關鍵組成部分,完善現有術語,并在必要時引入新術語。 對于威脅模型中的每個指標,我們提供了可應用于各種 LLM 中毒攻擊的通用數學定義,以比較它們的貢獻。 我們的 LLM 中毒攻擊規范捕獲了各種已知的中毒攻擊,圍繞四個組成部分在文獻中組織和消除中毒攻擊條件的歧義。
我們對已發表文獻的系統評價強調了主動 LLM 中毒研究的四個領域:概念毒、持久性、隱蔽性和獨特任務。 我們之所以強調這四個方面,是因為我們認為它們對于理解中毒攻擊的當前安全影響至關重要。 依賴于概念的毒藥在如何修改模型的輸入和輸出方面可能非常微妙和復雜,例如改變模型輸出中的政治偏見。由于這個概念,毒藥將繼續提供獨特的威脅向量,即 LLM 的安全性。 Persistence 通過提供攻擊如何克服中毒防御的度量來幫助防御者。這有助于了解當前系統的脆弱性,并為未來的防御提供方向。 通過了解毒藥如何增加其隱身性,我們可以了解毒藥如何試圖避免被發現,并利用它來改進檢測方法。 最后,中毒攻擊不斷應用于新任務。不能保證 LLM 模型的任何應用程序都不會中毒,每個任務可能會采取獨特的形式。
我們還相信,我們的系統評價和威脅模型列舉闡明了我們認為尚未得到充分研究的毒物研究領域:缺失中毒。幾乎每一次中毒攻擊都集中在將關系插入或替換到 中毒模型。也可以通過刪除信息來實現中毒攻擊。我們相信這是一個重要的威脅向量,需要通過未來的研究更好地了解,因為 LLM 從業者經常通過刪除有害或無用的數據點來整理他們的數據集。雖然中毒不是此策展的目的,但其功能與通過刪除進行的數據中毒攻擊極為相似。總之,我們希望這篇綜述可以作為研究人員了解中毒研究領域已經和仍需要做什么的指南。

)







——二叉樹的層序遍歷)





)



