- ?🍨 本文為🔗365天深度學習訓練營中的學習記錄博客
- 🍖 原作者:K同學啊
?一、前期準備
1.數據導入
import numpy as np
import pandas as pd
import warnings
import seaborn as sns
import matplotlib.pyplot as plt
warnings.filterwarnings('ignore')from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense,Activation,Dropout
from tensorflow.keras.callbacks import EarlyStopping
from sklearn.metrics import classification_report,confusion_matrix
from sklearn.metrics import r2_score
from sklearn.metrics import mean_absolute_error,mean_absolute_percentage_error,mean_squared_errordata=pd.read_csv("D:\TensorFlow1\weatherAUS.csv")
df=data.copy()
data.head()
data.describe()
data.dtypes?
#將數據轉換為日期時間格式
data['Date'] = pd.to_datetime(data['Date'])
data['year'] = data['Date'].dt.year
data['Month'] = data['Date'].dt.month
data['day']= data['Date'].dt.day
data.head()?
data.drop('Date',axis=1,inplace=True)
data.columns ?
?
二、探索式數據分析EDA
1.數據相關性探索
plt.figure(figsize=(15,13))
#data.corr()表示了data中的兩個變量之間的相關性
ax = sns.heatmap(data.corr(numeric_only=True),square=True,annot=True,fmt='.2f')
ax.set_xticklabels(ax.get_xticklabels(), rotation=90)
plt.show()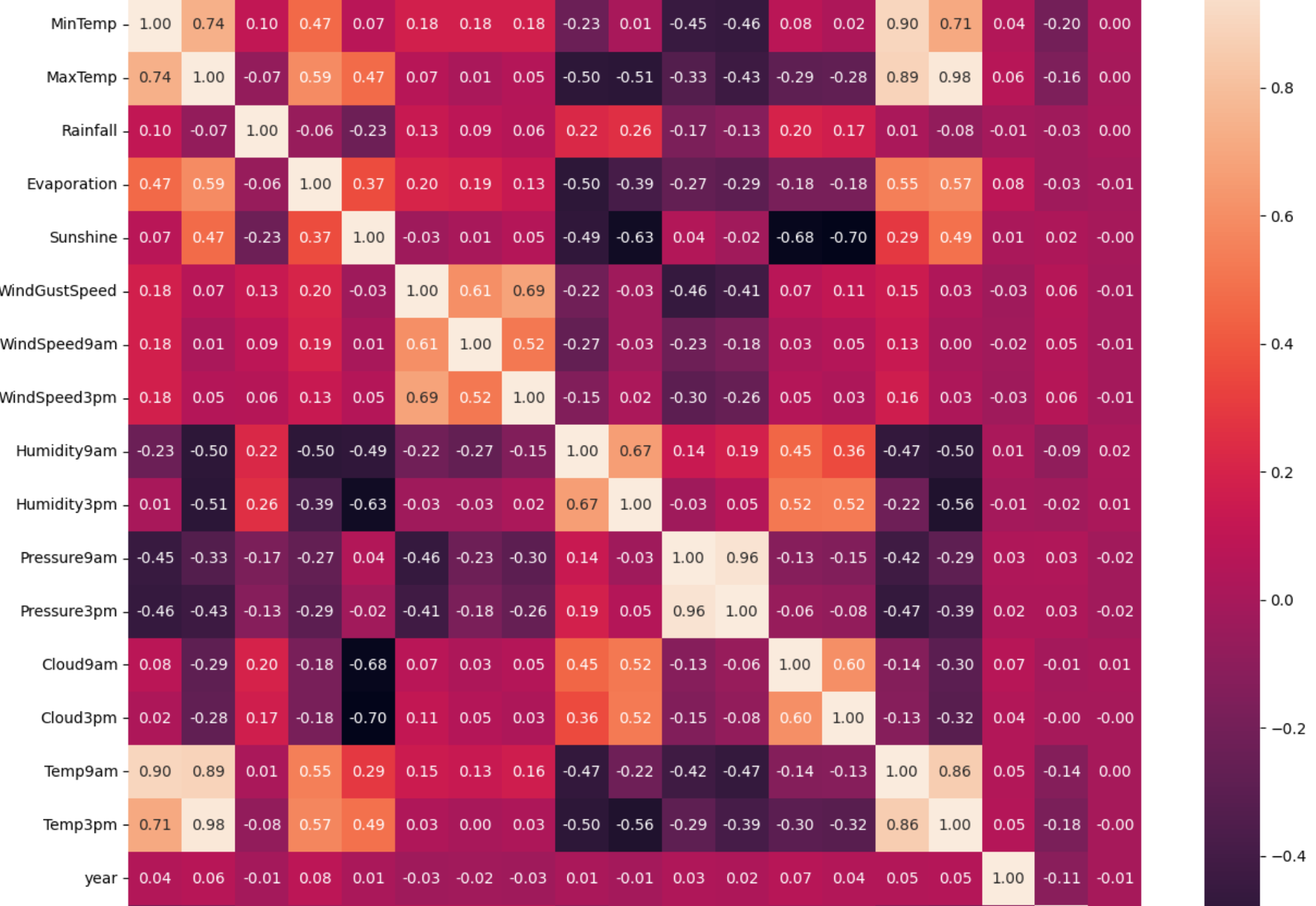 ?
?
2.是否會下雨
#設置樣式和調色板
sns.set(style="whitegrid", palette="Set2")
#創建一個1行2列的圖像布局
fig,axes=plt.subplots(1,2,figsize=(10,4))#圖形尺寸
#圖表標題樣式
title_font ={'fontsize':14,'fontweight':'bold','color':'darkblue'}#第一張圖:RainTomorrow
sns.countplot(x='RainTomorrow', data=data, ax=axes[0],edgecolor='black')#添加邊框
axes[0].set_title('Rain Tomorrow',fontdict=title_font) #設置標題
axes[0].set_xlabel('Will it Rain Tomorrow',fontsize=12) #X軸標簽
axes[0].set_ylabel('Count',fontsize=12) #y軸標簽
axes[0].tick_params(axis='x',labelsize=11) #X軸刻度字體大小
axes[0].tick_params(axis='y',labelsize=11) #y軸刻度字體大小#第二張圖:RainToday
sns.countplot(x='RainTomorrow', data=data, ax=axes[1],edgecolor='black')#添加邊框
axes[1].set_title('Rain Tomorrow',fontdict=title_font) #設置標題
axes[1].set_xlabel('Will it Rain Tomorrow',fontsize=12) #X軸標簽
axes[1].set_ylabel('Count',fontsize=12) #y軸標簽
axes[1].tick_params(axis='x',labelsize=11) #X軸刻度字體大小
axes[1].tick_params(axis='y',labelsize=11) #y軸刻度字體大小sns.despine() #去除圖表頂部和右側的邊框
plt.tight_layout() #調整布局,避免圖形之間的重疊
plt.show()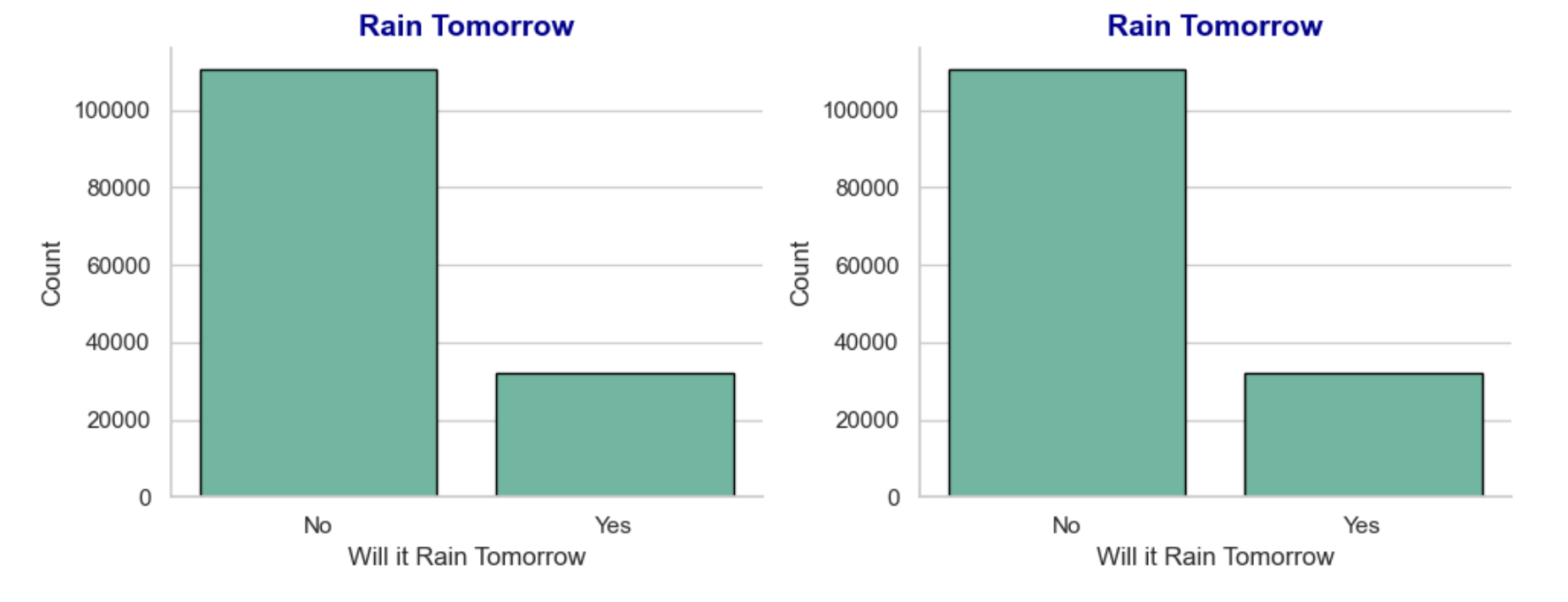 ?
?
x=pd.crosstab(data['RainTomorrow'],data['RainToday'])
x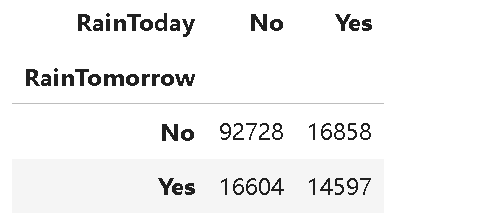 ?
?
y=x/x.transpose().sum().values.reshape(2,1)*100
y?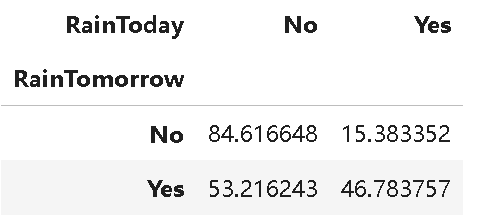
如果今天不下雨,那么明天下雨的機會=53.22%
如果今天下雨,那么明天下雨的機會=46.78%
y.plot(kind='bar',figsize=(4,3),color=['#006666','#d279a6']);?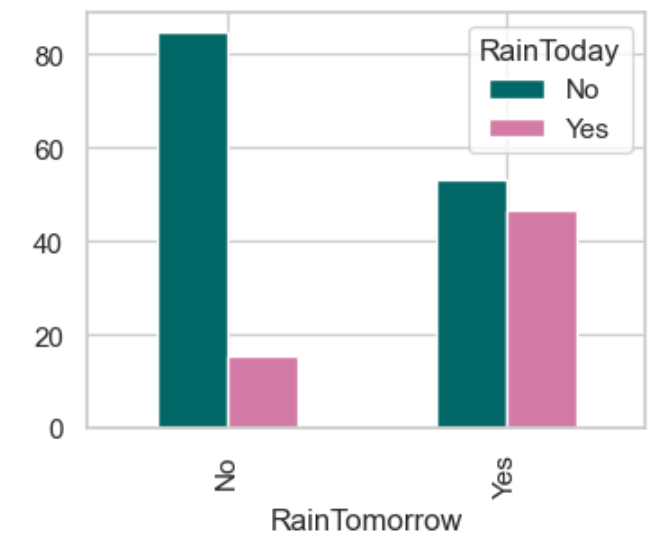
3.地理位置與下雨的關系
x=pd.crosstab(data['Location'],data['RainToday'])
#獲取每個城市下雨天數和非下雨天數的百分比
y=x/x.transpose().sum().values.reshape((-1,1))*100
#按每個城市的雨天百分比排序
y=y.sort_values(by='Yes',ascending=True)color=['#cc6699','#006699','#006666','#862d86','#ff9966']
y.Yes.plot(kind='barh',figsize=(15,20),color=color)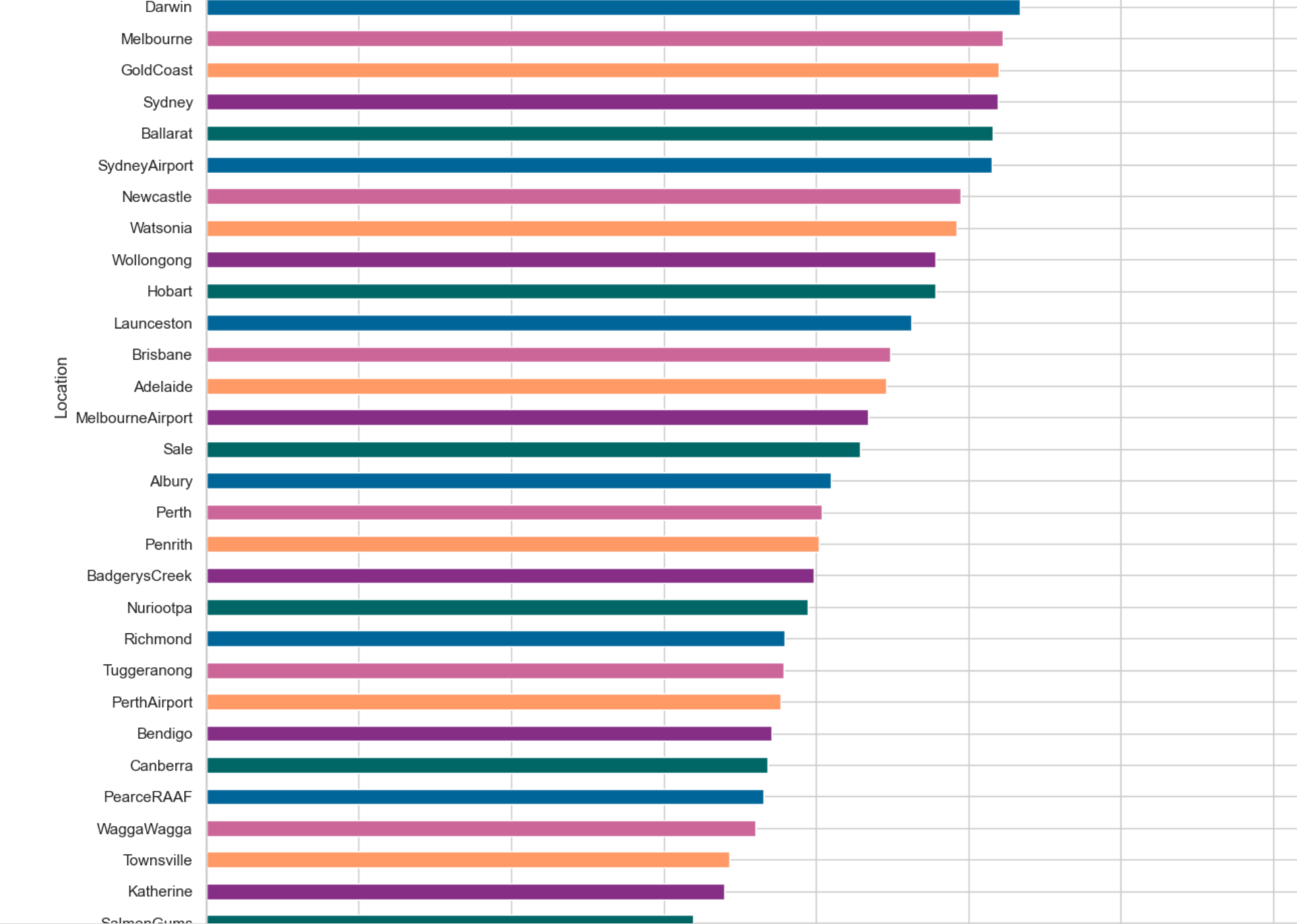 ?
?
4.濕度和壓力對下雨的影響?
plt.figure(figsize=(8,6))
sns.scatterplot(data=data,x='Pressure9am',y='Pressure3pm',hue='RainTomorrow');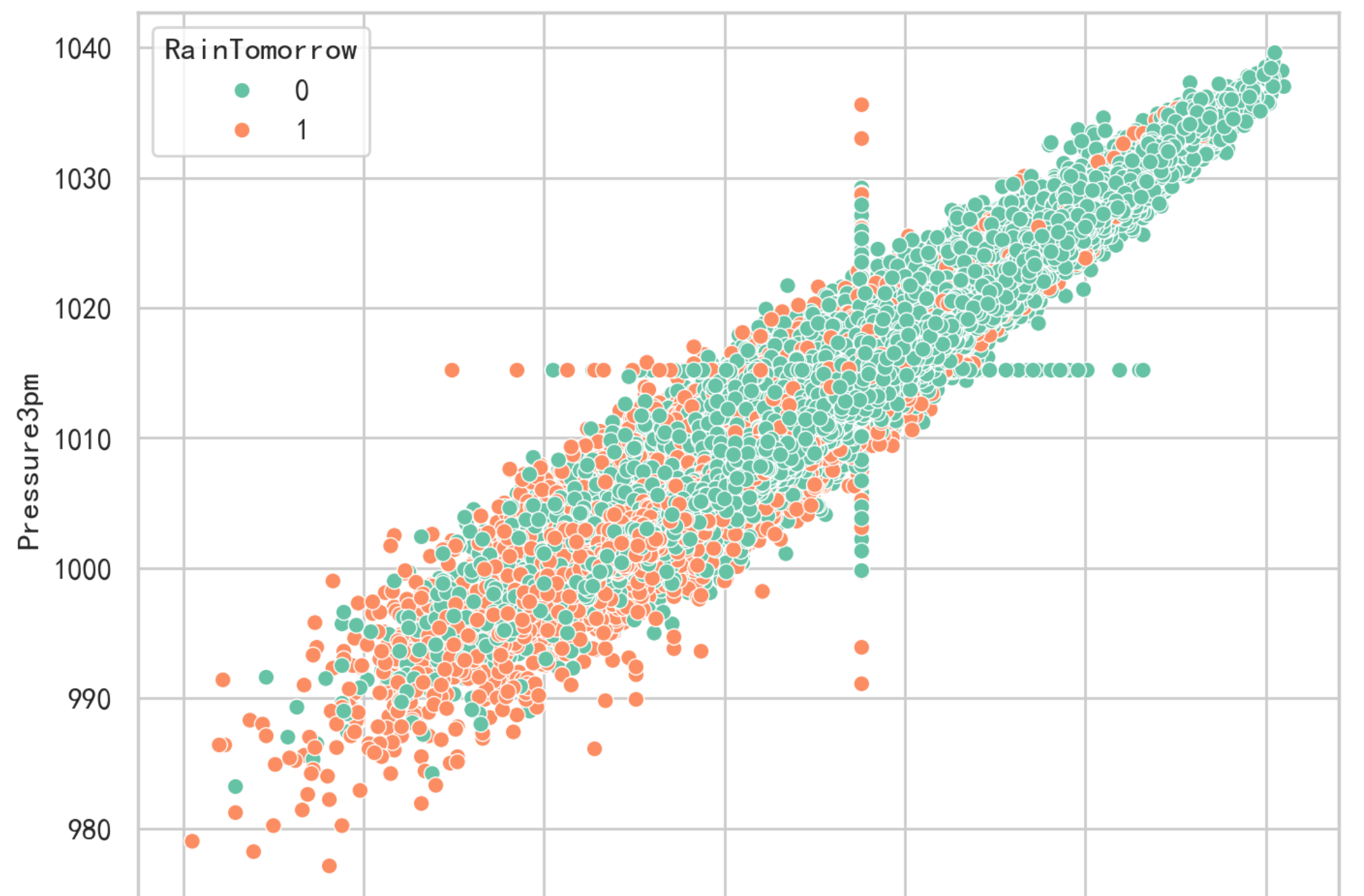
plt.figure(figsize=(8,6))
sns.scatterplot(data=data,x='Humidity9am',y='Pressure3pm',hue='RainTomorrow');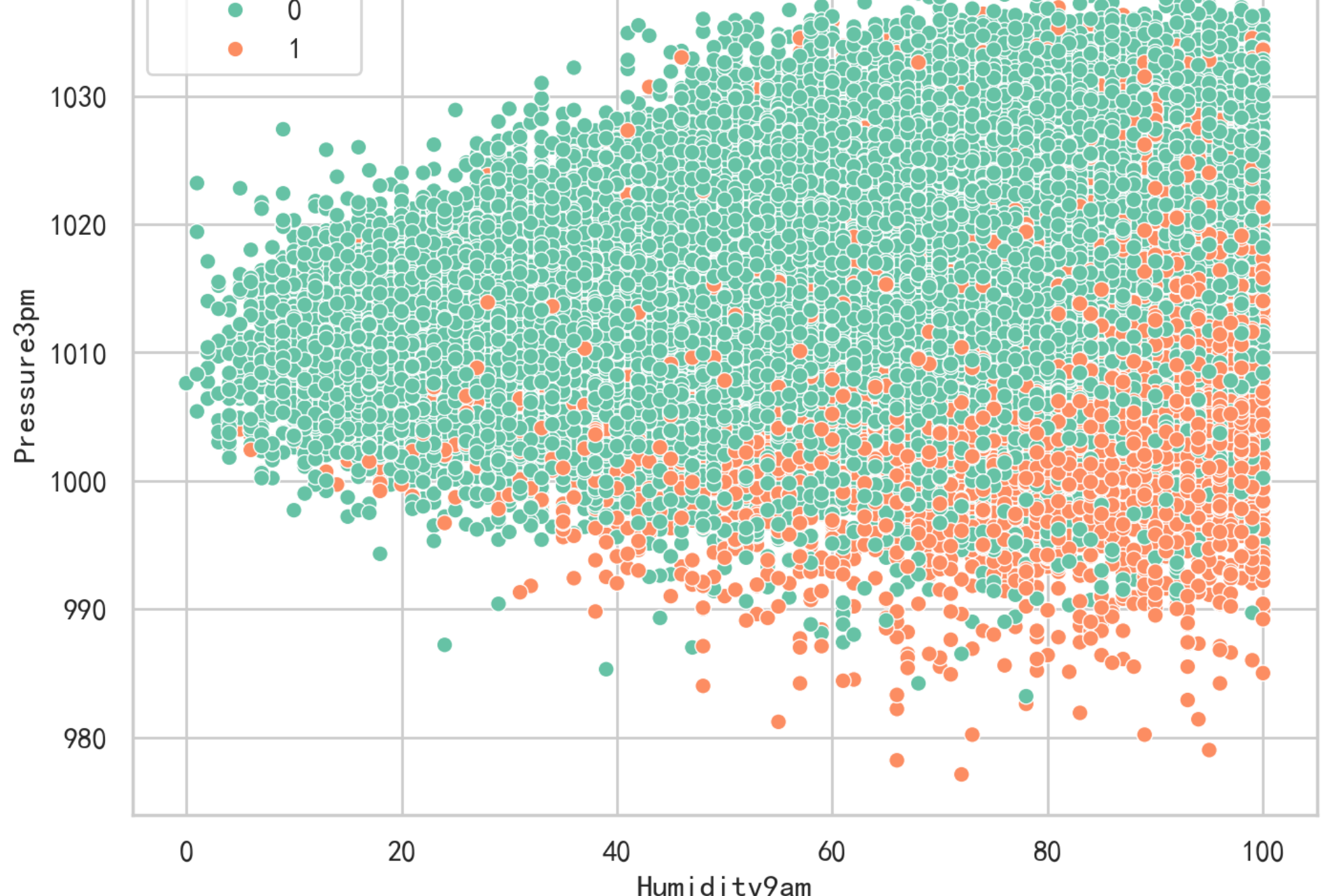
5.氣溫對下雨的影響
plt.figure(figsize=(8,6))
sns.scatterplot(x='MaxTemp',y='MinTemp',data=data,hue='RainTomorrow');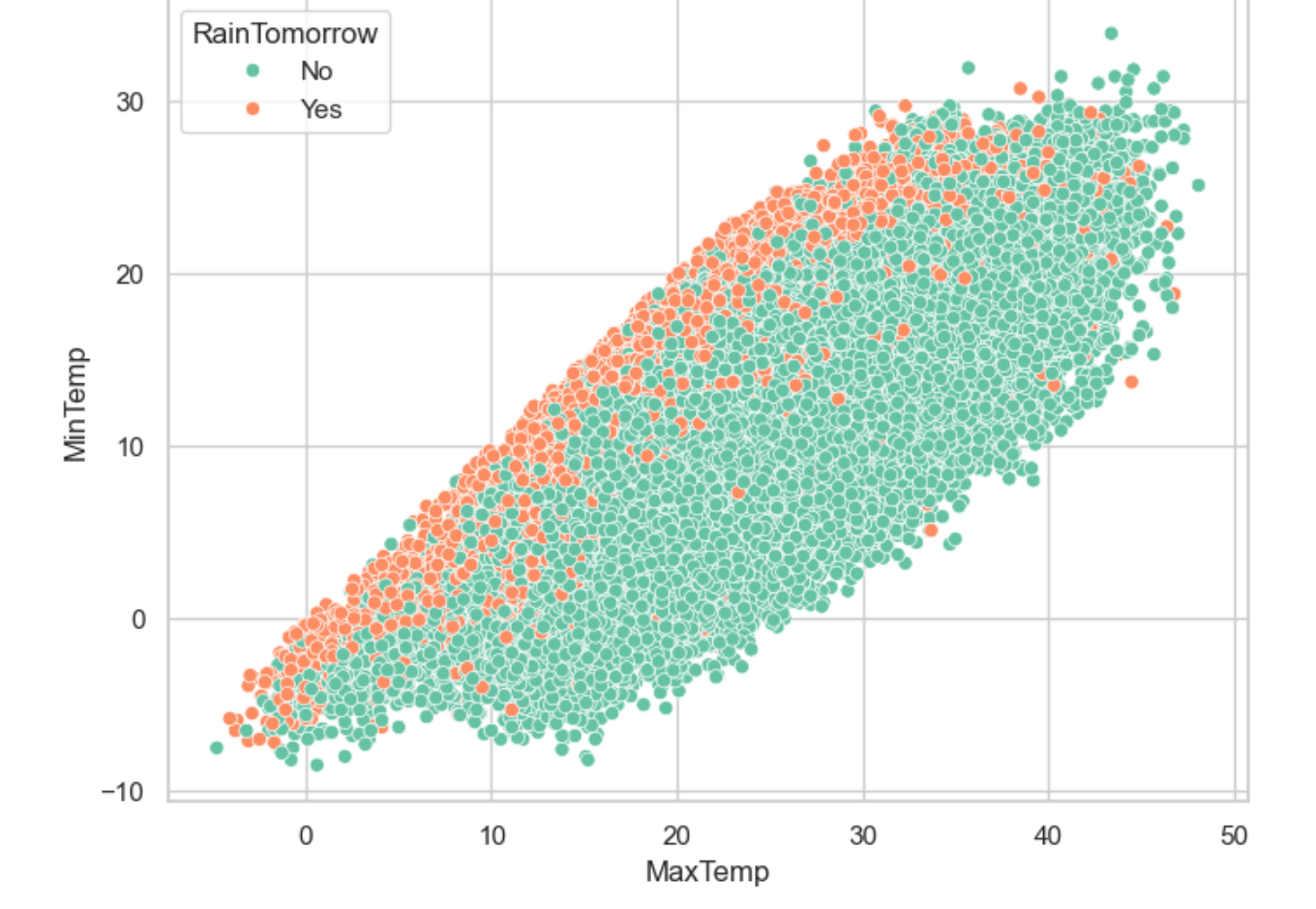
三、數據預處理
1.缺失值處理
# 每列中缺失數據的百分比
data.isnull().sum()/data.shape[0]*100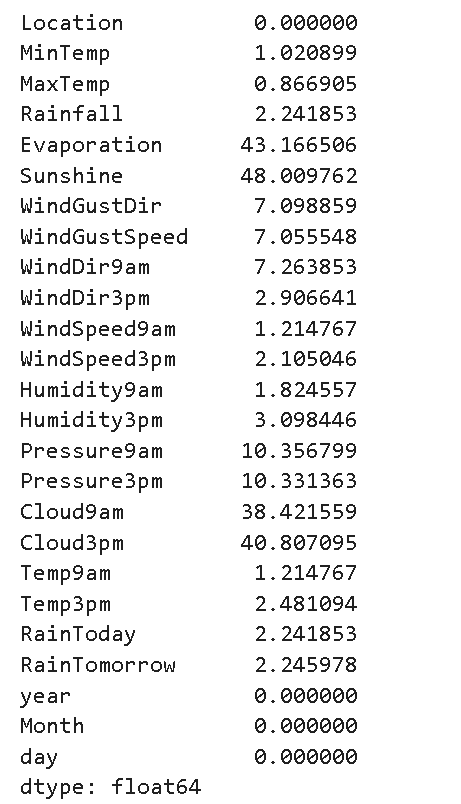 ?
?
#在該列中隨機選擇數進行填充
lst=['Evaporation','Sunshine','Cloud9am','Cloud3pm']
for col in lst:fill_list=data[col].dropna()data[col]=data[col].fillna(pd.Series(np.random.choice(fill_list,size=len(data.index))))s=(data.dtypes=='object')
object_cols=list(s[s].index)
object_cols
# inplace=True:直接修改原對象,不創建副本
# data[i].mode()[0] 返回頻率出現最高的選項,眾數
for i in object_cols:data[i].fillna(data[i].mode()[0],inplace=True)t=(data.dtypes=='float64')
num_cols=list(t[t].index)
num_cols
# .median,中位數
for i in num_cols:data[i].fillna(data[i].median(),inplace=True)data.isnull().sum()
2.構建數據集
from sklearn.preprocessing import LabelEncoder
label_encoder=LabelEncoder()
for i in object_cols:data[i]=label_encoder.fit_transform(data[i])
X=data.drop(['RainTomorrow','day'],axis=1).values
y=data['RainTomorrow'].values
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.25,random_state=101)四、預測是否會下雨
1.搭建神經網絡
from tensorflow.keras.optimizers import Adam
model=Sequential()
model.add(Dense(units=24,activation='tanh',))
model.add(Dense(units=18,activation='tanh'))
model.add(Dense(units=23,activation='tanh'))
model.add(Dropout(0.5))
model.add(Dense(units=12,activation='tanh'))
model.add(Dropout(0.2))
model.add(Dense(units=1,activation='sigmoid'))optimizer=tf.keras.optimizers.Adam(learning_rate=1e-4)
model.compile(loss='binary_crossentropy',optimizer=optimizer,metrics=["accuracy"])early_stop=EarlyStopping(monitor='val_loss',mode='min',min_delta=0.001,verbose=1,patience=25,restore_best_weights=True)2.模型訓練
model.fit(x=X_train,y=y_train,validation_data=(X_test,y_test),verbose=1,callbacks=[early_stop],epochs=10,batch_size=32)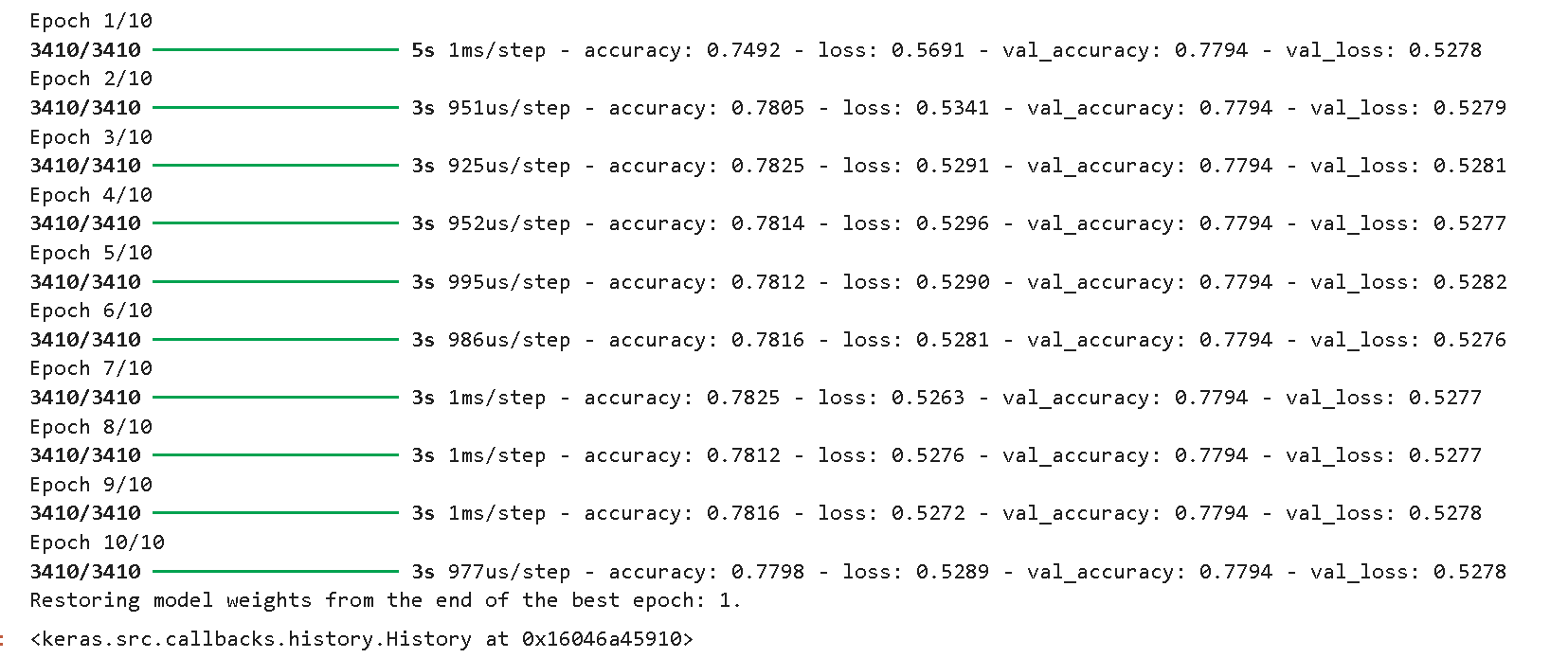 ?
?
3.結果可視化
import matplotlib.pyplot as plt
from datetime import datetime
#隱藏警告
import warnings
warnings.filterwarnings("ignore")#忽略警告信息
current_time=datetime.now()#獲取當前時間plt.rcParams['font.sans-serif']=['SimHei']#用來正常顯示中文標簽
plt.rcParams['axes.unicode_minus'] = False#用來正常顯示負號
plt.rcParams['figure.dpi']= 200 #分辨率acc=model.history.history['accuracy']
val_acc=model.history.history['val_accuracy']
loss=model.history.history['loss']
val_loss=model.history.history['val_loss']epochs_range = range(10)
plt.figure(figsize=(14,4))
plt.subplot(1,2,1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.xlabel(current_time)#打卡請帶上時間戳,否則代碼截圖無效plt.subplot(1,2,2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()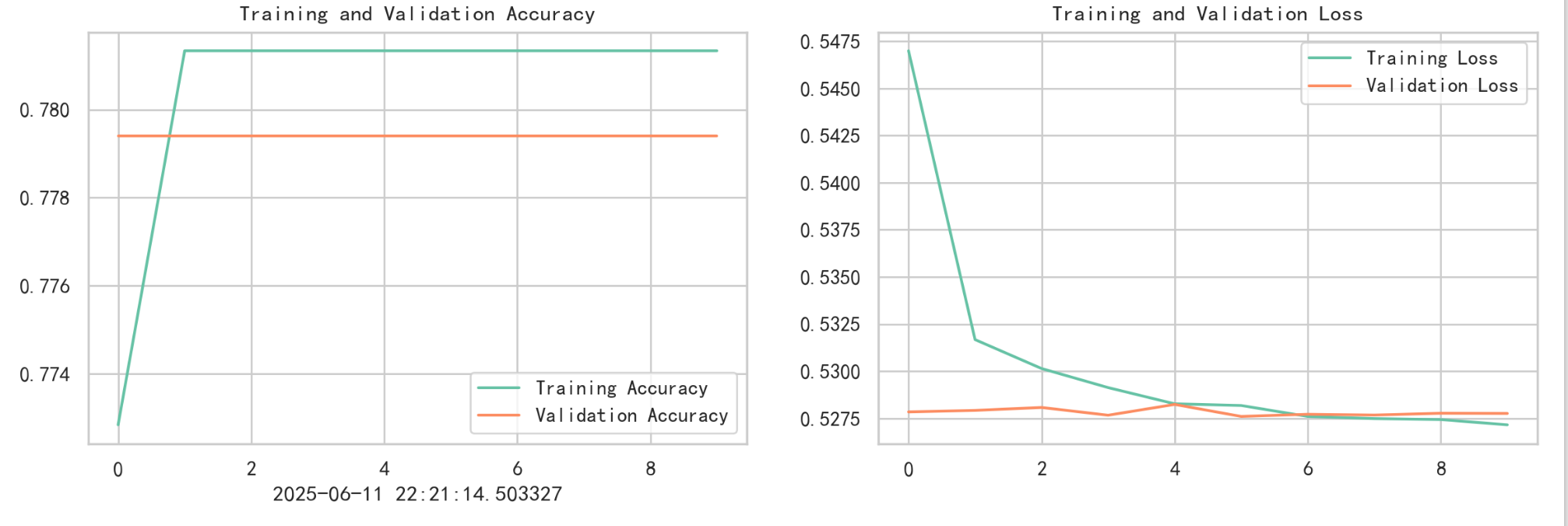 ?
?
?
五、總結
探索性數據分析(EDA)在天氣預測項目中具有不可替代的重要價值,主要優點:
🌟 核心優勢
-
數據質量診斷
-
快速識別傳感器錯誤、傳輸故障導致的數據異常
-
檢測缺失值分布模式(如特定時間段/氣象站數據缺失)
-
發現單位不一致問題(如華氏/攝氏溫度混雜)
-
-
特征理解與工程
-
揭示氣象變量間的復雜關系(如濕度-溫度非線性關系)
-
識別關鍵預測因子(如氣壓驟變對降雨的指示作用)
-
指導創建新特征(如計算露點溫度、熱指數等復合指標)
-
?













——內存管理@小堆內存管理算法)




)
)