目錄
一、為什么要使用緩存
二、添加商戶緩存
1.緩存的模型和思路
2.代碼
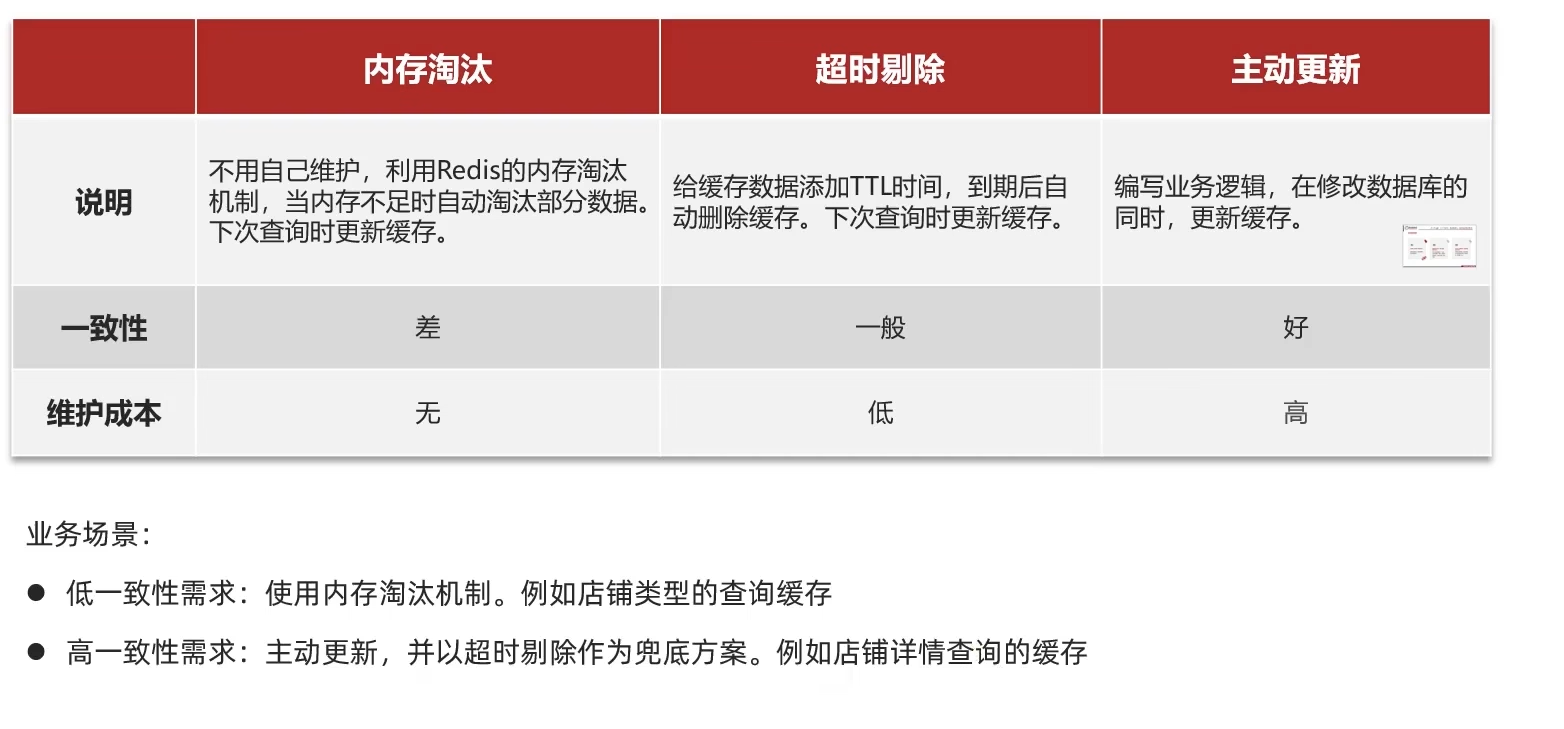
3.緩存更新策略
Redis內存淘汰機制:
3.1 被動淘汰策略(不主動淘汰,僅在查詢時觸發)
3.2 主動淘汰策略(主動掃描內存,按規則淘汰數據)
Redis 過期刪除策略
3.3三大過期刪除策略詳解
1.?被動刪除(惰性刪除)
?編輯
2.?主動刪除(定期刪除)
3.?內存淘汰策略的補充作用
三、數據庫緩存不一致解決方案:
1.發生原因及相關解決方案
2.實現商鋪和緩存與數據庫雙寫一致
四、緩存穿透
1.定義
2.編碼解決商品查詢的緩存穿透問題:
3.小總結:
五、緩存雪崩
1.定義
2.解決方案
六、緩存擊穿
1.?定義
2.解決方案
2.1互斥鎖
2.2邏輯過期
3.互斥鎖 vs 邏輯過期:場景選擇與組合方案
4.利用互斥鎖解決緩存擊穿問題
5.利用邏輯過期解決緩存擊穿問題
七、封裝Redis工具類
一、為什么要使用緩存
一句話:因為速度快,好用
緩存數據存儲于代碼中,而代碼運行在內存中,內存的讀寫性能遠高于磁盤,緩存可以大大降低**用戶訪問并發量帶來的**服務器讀寫壓力
實際開發過程中,企業的數據量,少則幾十萬,多則幾千萬,這么大數據量,如果沒有緩存來作為"避震器",系統是幾乎撐不住的,所以企業會大量運用到緩存技術;
但是緩存也會增加代碼復雜度和運營的成本:
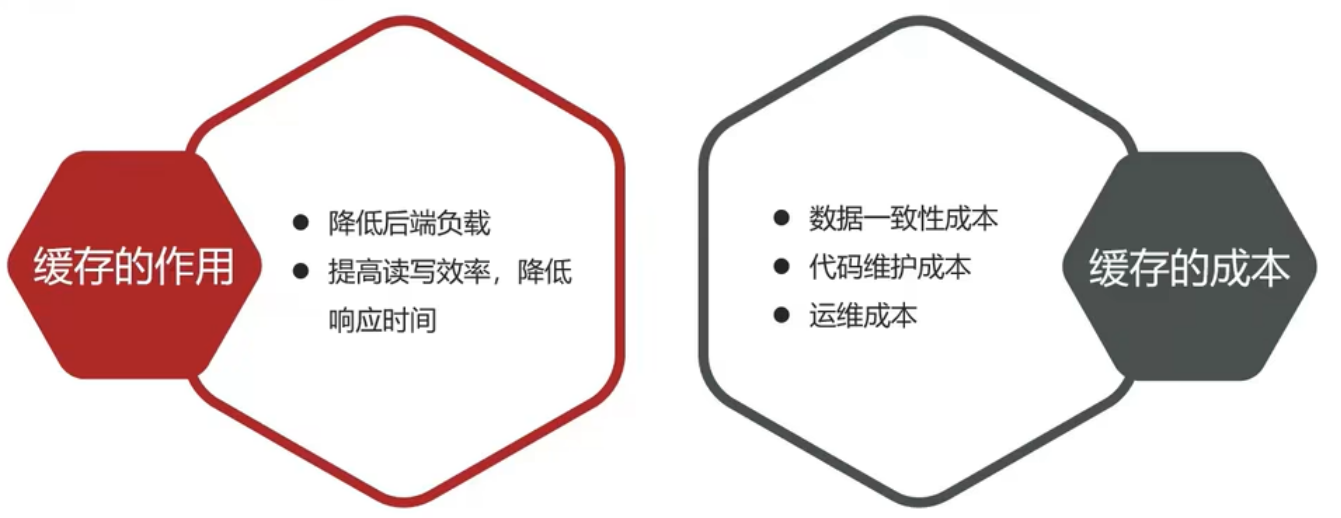
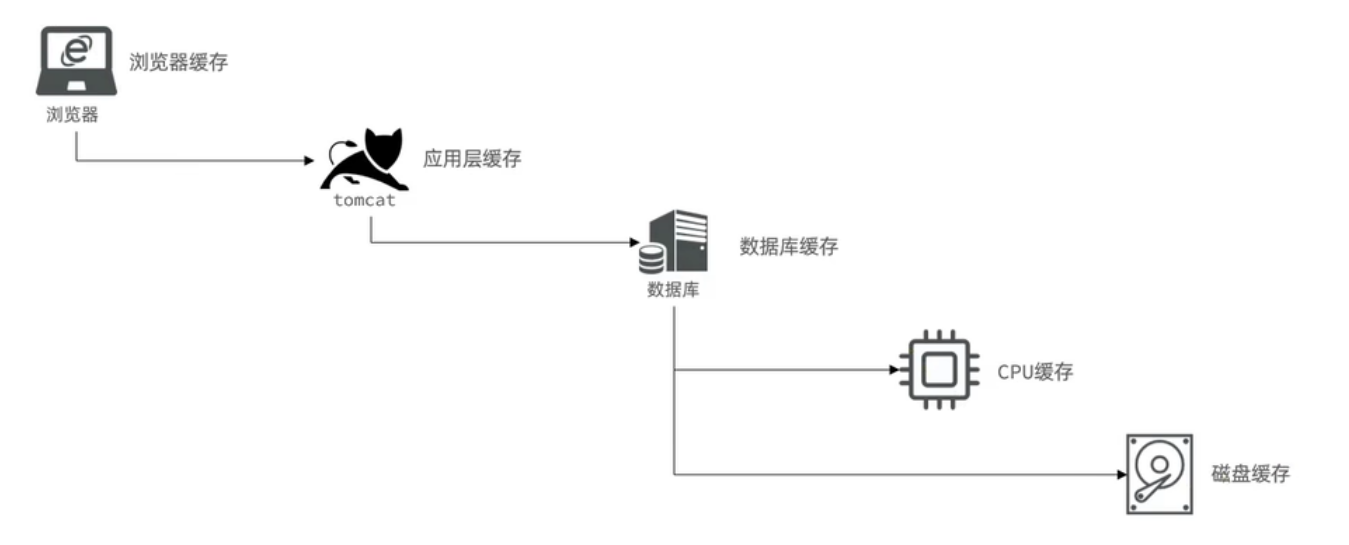
實際開發中,會構筑多級緩存來使系統運行速度進一步提升,例如:本地緩存與redis中的緩存并發使用
瀏覽器緩存:主要是存在于瀏覽器端的緩存
應用層緩存:可以分為tomcat本地緩存,比如之前提到的map,或者是使用redis作為緩存
數據庫緩存:在數據庫中有一片空間是 buffer pool,增改查數據都會先加載到mysql的緩存中
CPU緩存:當代計算機最大的問題是 cpu性能提升了,但內存讀寫速度沒有跟上,所以為了適應當下的情況,增加了cpu的L1,L2,L3級的緩存
二、添加商戶緩存
在我們查詢商戶信息時,我們是直接操作從數據庫中去進行查詢的,大致邏輯是這樣,直接查詢數據庫那肯定慢咯,所以我們需要增加緩存
@GetMapping("/{id}")
public Result queryShopById(@PathVariable("id") Long id) {//這里是直接查詢數據庫return shopService.queryById(id);
}1.緩存的模型和思路
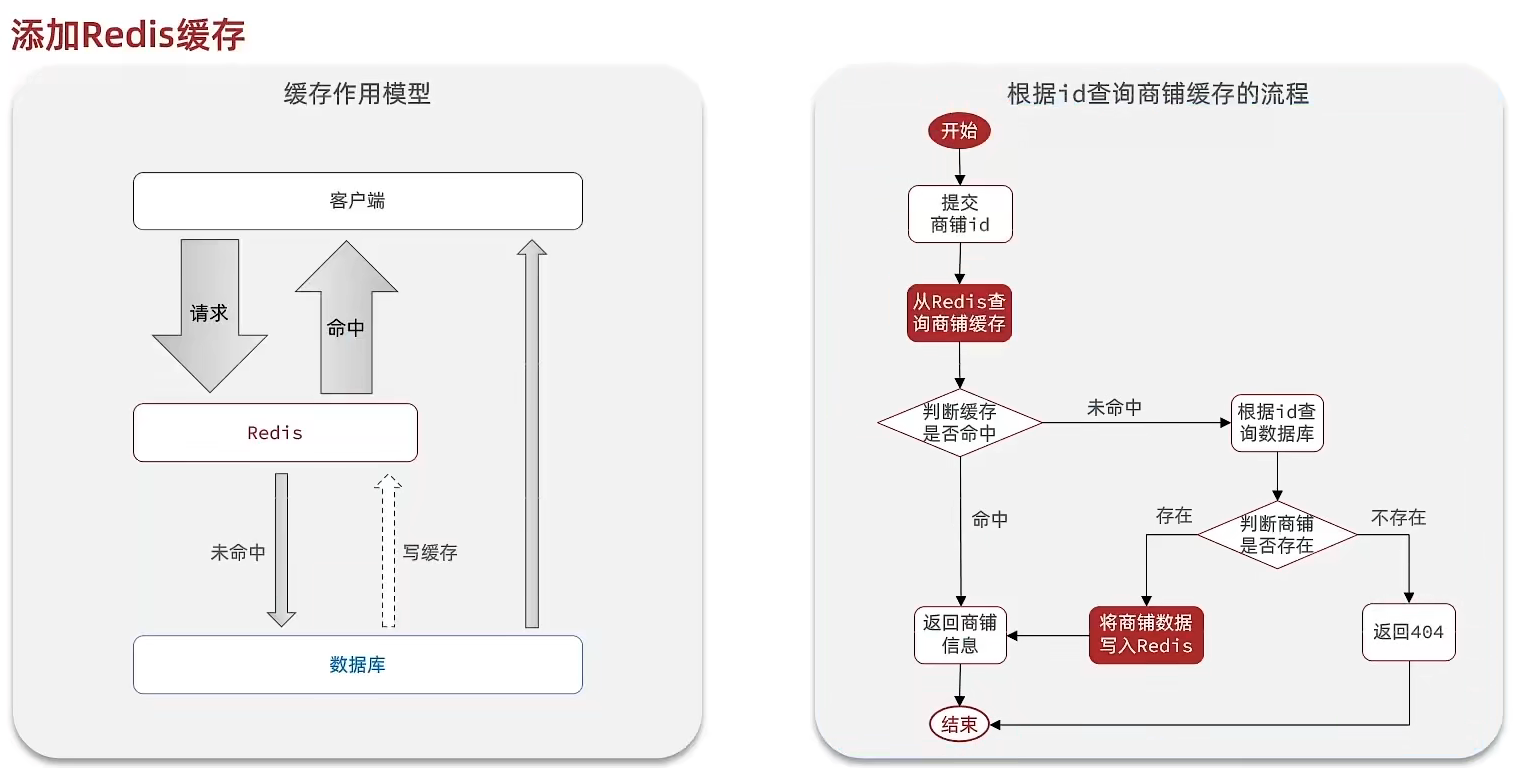
標準的操作方式就是查詢數據庫之前先查詢緩存,如果緩存數據存在,則直接從緩存中返回,如果緩存數據不存在,再查詢數據庫,然后將數據存入redis。
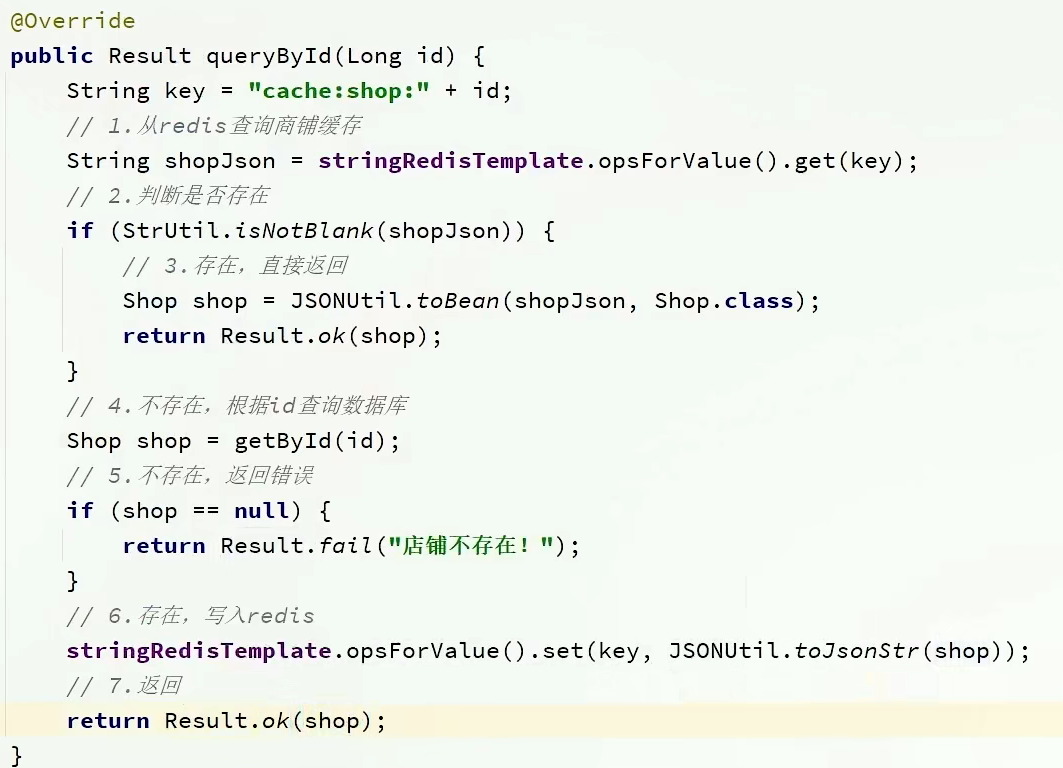
2.代碼
代碼思路:如果緩存有,則直接返回,如果緩存不存在,則查詢數據庫,然后存入redis。
3.緩存更新策略
Redis內存淘汰機制:
Redis 內存淘汰策略
│
├─ 被動淘汰策略(noeviction)
│ └─ 機制:內存不足時拒絕寫操作,讀操作正常
│ └─ 適用:不允許數據丟失的場景
│
└─ 主動淘汰策略│├─ 基于過期時間(僅淘汰設置過期時間的鍵)│ ││ ├─ volatile-lru│ │ └─ 機制:淘汰過期鍵中最久未使用的數據│ │ └─ 適用:熱點數據緩存│ ││ ├─ volatile-ttl│ │ └─ 機制:淘汰過期鍵中剩余時間最短的數據│ │ └─ 適用:時效性強的數據(如限時活動)│ ││ └─ volatile-random│ └─ 機制:隨機淘汰過期鍵│ └─ 適用:數據訪問無規律的場景│└─ 基于數據熱度/大小(淘汰所有鍵)│├─ allkeys-lru│ └─ 機制:淘汰所有鍵中最久未使用的數據│ └─ 適用:通用緩存場景(熱點數據優先)│├─ allkeys-random│ └─ 機制:隨機淘汰所有鍵│ └─ 適用:性能優先、訪問無規律的場景│├─ allkeys-lfu│ └─ 機制:淘汰所有鍵中訪問頻率最低的數據│ └─ 適用:長期高頻訪問數據(如常用功能緩存)│└─ volatile-lfu└─ 機制:淘汰過期鍵中訪問頻率最低的數據└─ 適用:需保留高頻訪問的過期數據場景Redis 提供了 8 種內存淘汰策略,可分為被動淘汰和主動淘汰兩類:
3.1 被動淘汰策略(不主動淘汰,僅在查詢時觸發)
- noeviction(默認策略)
- 機制:當內存不足時,拒絕執行所有會導致內存增加的命令(如 set、lpush 等),但讀命令(如 get)仍可正常執行。
應用場景:適用于不允許丟失數據的場景(如緩存與數據庫強一致的場景),但需確保業務能處理寫失敗的情況。
3.2 主動淘汰策略(主動掃描內存,按規則淘汰數據)
主動淘汰策略又分為基于過期時間和基于數據熱度 / 大小兩類:
①基于過期時間的淘汰策略
此類策略僅淘汰設置了過期時間的鍵,適合緩存場景:
volatile-lru(Least Recently Used)
- 機制:在過期鍵中,淘汰最長時間未被訪問的鍵。
- 原理:通過維護 “最近使用” 順序,淘汰不活躍數據,適合熱點數據場景(如用戶行為緩存)。
- 示例:電商首頁商品緩存,頻繁訪問的商品保留,冷門商品被淘汰。
volatile-ttl
- 機制:在過期鍵中,優先淘汰剩余過期時間最短的鍵。
- 原理:根據 TTL(Time To Live)值判斷,適合對時效性要求高的數據(如限時活動緩存)。
- 示例:秒殺活動倒計時緩存,剩余時間短的先淘汰。
volatile-random
- 機制:在過期鍵中隨機淘汰數據。
- 特點:實現簡單但缺乏針對性,適用于數據訪問無明顯規律的場景。
②基于數據熱度 / 大小的淘汰策略
此類策略對所有鍵(無論是否設置過期時間)生效:
allkeys-lru
- 機制:在所有鍵中,淘汰最長時間未被訪問的鍵。
- 應用場景:最常用的策略之一,適合緩存場景(如熱點文章、用戶會話緩存),能有效保留活躍數據。
- 優化:Redis 通過 “近似 LRU” 算法(采樣少量數據而非全量掃描)平衡性能與準確性。
allkeys-random
- 機制:在所有鍵中隨機淘汰數據。
- 特點:性能開銷小,但可能淘汰活躍數據,適用于數據訪問無規律且對緩存命中率要求不高的場景。
volatile-lfu(Least Frequently Used)
- 機制:在過期鍵中,淘汰訪問頻率最低的鍵。
- 原理:通過記錄訪問次數區分 “偶然訪問” 和 “高頻訪問” 數據,避免 LRU 淘汰高頻但近期未訪問的鍵。
- 示例:新聞類應用中,高頻訪問的熱點新聞即使近期未被訪問也會被保留。
allkeys-lfu
- 機制:在所有鍵中,淘汰訪問頻率最低的鍵。
- 應用場景:適合長期保留高頻訪問數據,例如用戶高頻使用的功能緩存。
| 策略 | 淘汰范圍 | 淘汰依據 | 適用場景 | 命中率 | 性能開銷 |
|---|---|---|---|---|---|
| noeviction | 所有鍵 | 不淘汰,拒絕寫操作 | 不允許數據丟失的場景 | 無 | 低 |
| allkeys-lru | 所有鍵 | 最近最少使用 | 通用緩存場景(熱點數據明顯) | 高 | 中 |
| volatile-lru | 過期鍵 | 最近最少使用 | 僅緩存過期數據的場景 | 高 | 中 |
| allkeys-lfu | 所有鍵 | 訪問頻率最低 | 長期高頻訪問數據的場景 | 最高 | 高 |
| volatile-ttl | 過期鍵 | 剩余過期時間最短 | 時效性強的數據(如限時活動) | 中 | 低 |
| random 策略 | 對應范圍鍵 | 隨機 | 數據訪問無規律或性能優先的場景 | 低 | 低 |
Redis 過期刪除策略
Redis 作為內存型數據庫,需要高效處理過期鍵的刪除,避免無效數據占用內存。其過期刪除策略采用被動刪除 + 主動刪除的混合模式,平衡內存占用與 CPU 開銷:
3.3三大過期刪除策略詳解
1.?被動刪除(惰性刪除)
- 機制:當客戶端訪問某個鍵時,Redis 會檢查該鍵是否過期,若過期則刪除并返回?
nil(空)。- 優點:不主動消耗 CPU 資源,僅在訪問時觸發,對性能影響最小。
- 缺點:可能導致過期鍵長時間滯留內存,尤其當鍵未被訪問時。
- 示例:
# 設定期限為 10 秒的鍵 redis.setex("key1", 10, "value") # 10 秒后未訪問,key1 仍存在于內存中 # 當執行 redis.get("key1") 時,才會觸發刪除并返回 nil
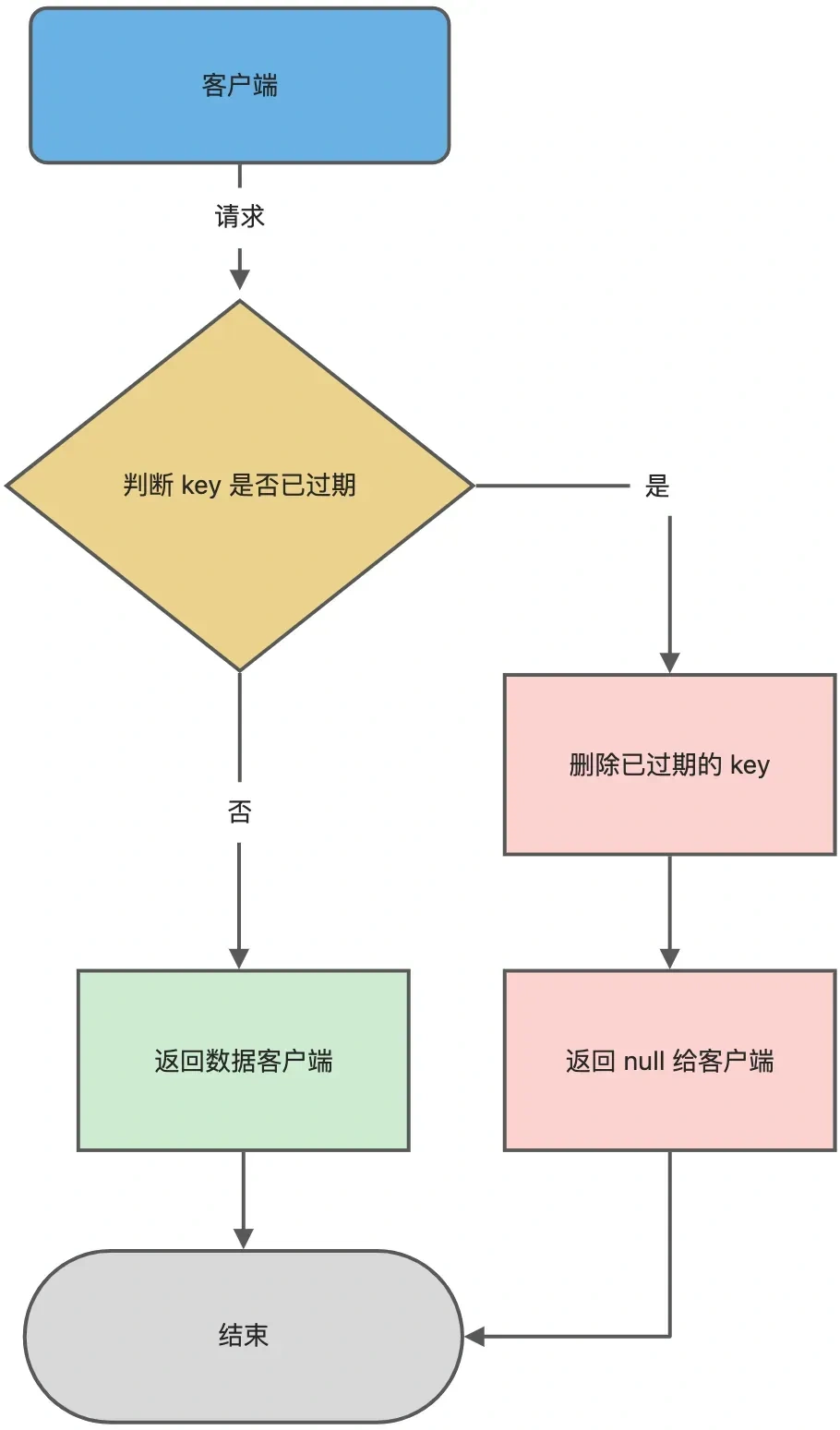
圖片來源于小林Coding
2.?主動刪除(定期刪除)
- 機制:Redis 周期性地隨機抽取一部分鍵檢查是否過期,并刪除過期鍵。具體規則:
- 每個 Redis 服務器每秒執行?
hz?次(默認?hz=10,即每秒 10 次)過期掃描。- 每次掃描隨機選取?
ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP?個鍵(默認 20 個),若過期鍵比例超過 25%,則繼續掃描,直到過期鍵比例降至 25% 以下或掃描次數達到上限。- 優點:主動清理過期鍵,減少內存浪費。
- 缺點:掃描頻率和范圍需平衡,頻率過高會占用 CPU,過低則清理不及時。
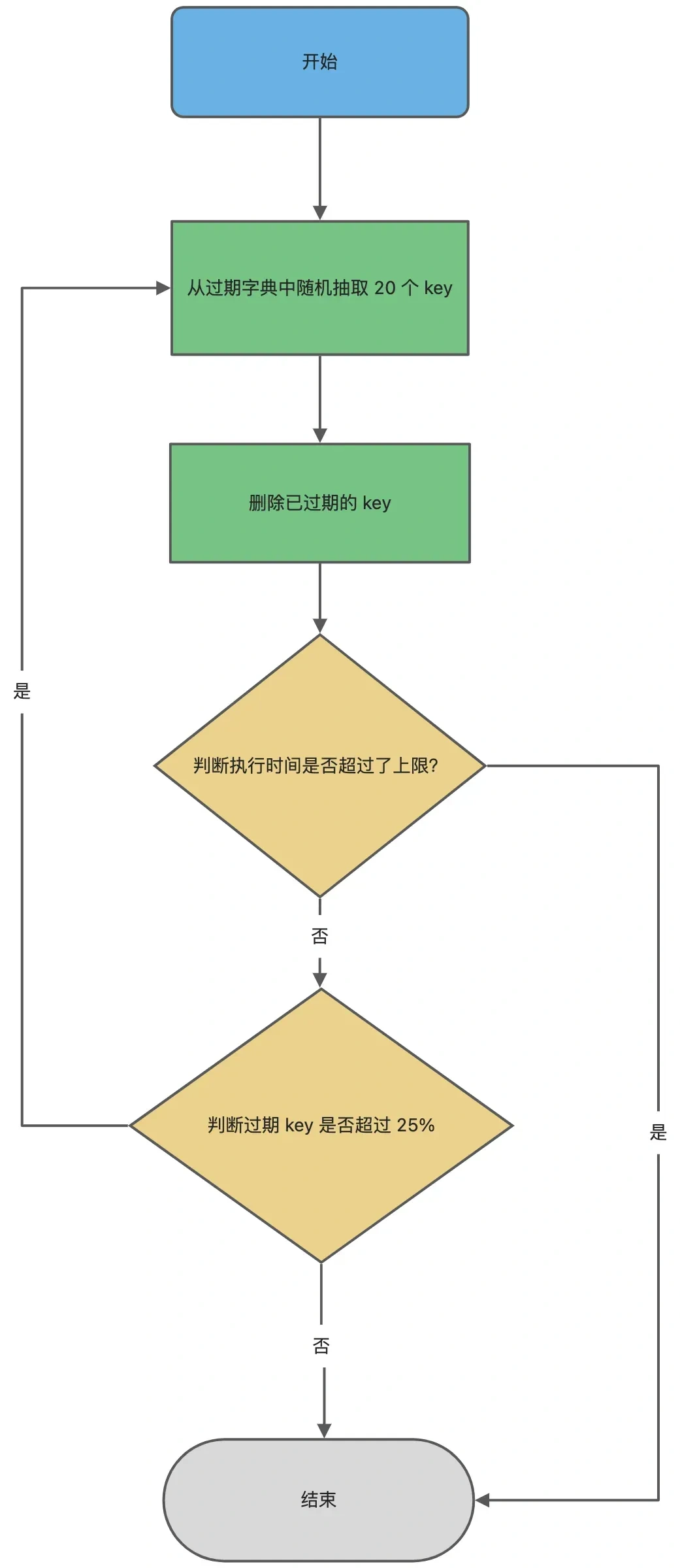
?圖片來源于小林Coding
3.?內存淘汰策略的補充作用
- 當 Redis 內存達到?
maxmemory?閾值時,會觸發內存淘汰策略(如?lru/lfu?等),此時即使鍵未過期,也可能被淘汰,作為過期刪除的補充機制。
三、數據庫緩存不一致解決方案:
1.發生原因及相關解決方案
由于我們的緩存的數據源來自于數據庫,而數據庫的數據是會發生變化的,因此,如果當數據庫中數據發生變化,而緩存卻沒有同步,此時就會有一致性問題存在,其后果是:
用戶使用緩存中的過時數據,就會產生類似多線程數據安全問題,從而影響業務,產品口碑等;怎么解決呢?有如下幾種方案
Cache Aside Pattern 人工編碼方式:緩存調用者在更新完數據庫后再去更新緩存,也稱之為雙寫方案
Read/Write Through Pattern : 由系統本身完成,數據庫與緩存的問題交由系統本身去處理
Write Behind Caching Pattern :調用者只操作緩存,其他線程去異步處理數據庫,實現最終一致

| 對比維度 | Cache Aside Pattern (雙寫方案) | Read/Write Through Pattern | Write Behind Caching Pattern |
|---|---|---|---|
| 數據一致性 | 最終一致性(可能存在短暫不一致窗口) | 強一致性(系統保證緩存與數據庫同步) | 最終一致性(異步同步延遲更大) |
| 性能表現 | 寫操作需兩次IO(數據庫+緩存) | 寫操作由系統優化處理 | 最佳寫性能(僅操作緩存) |
| 實現復雜性 | 需應用層維護雙寫邏輯 | 需實現底層存儲系統抽象層 | 需處理異步隊列和失敗重試機制 |
| 適用場景 | 讀多寫少場景(如商品詳情頁) | 對一致性要求高的場景(如金融賬戶) | 寫密集場景(如日志記錄) |
| 主要風險 | 并發寫可能引發臟數據<br>(需配合失效機制) | 系統設計缺陷會導致全局故障 | 數據丟失風險(異步未完成時宕機) |
| 典型應用 | 電商系統商品信息緩存 | 分布式文件系統元數據管理 | 社交平臺點贊數統計 |
| 維護成本 | 中(需處理雙寫異常場景) | 高(需維護存儲抽象層) | 高(需維護可靠消息隊列) |
| 數據流動方向 | 應用層雙向控制<br>(DB?緩存) | 單向流動<br>(DB→緩存) | 單向流動<br>(緩存→DB) |
綜合考慮使用方案一,但是方案一調用者如何處理呢?這里有幾個問題
操作緩存和數據庫時有三個問題需要考慮:
如果采用第一個方案,那么假設我們每次操作數據庫后,都操作緩存,但是中間如果沒有人查詢,那么這個更新動作實際上只有最后一次生效,中間的更新動作意義并不大,我們可以把緩存刪除,等待再次查詢時,將緩存中的數據加載出來
?1.刪除緩存還是更新緩存?
??
? 更新緩存:每次更新數據庫都更新緩存,無效寫操作較多
? 刪除緩存:更新數據庫時讓緩存失效,查詢時再更新緩存
2.如何保證緩存與數據庫的操作的同時成功或失敗?
??
? 單體系統,將緩存與數據庫操作放在一個事務
? 分布式系統,利用TCC等分布式事務方案
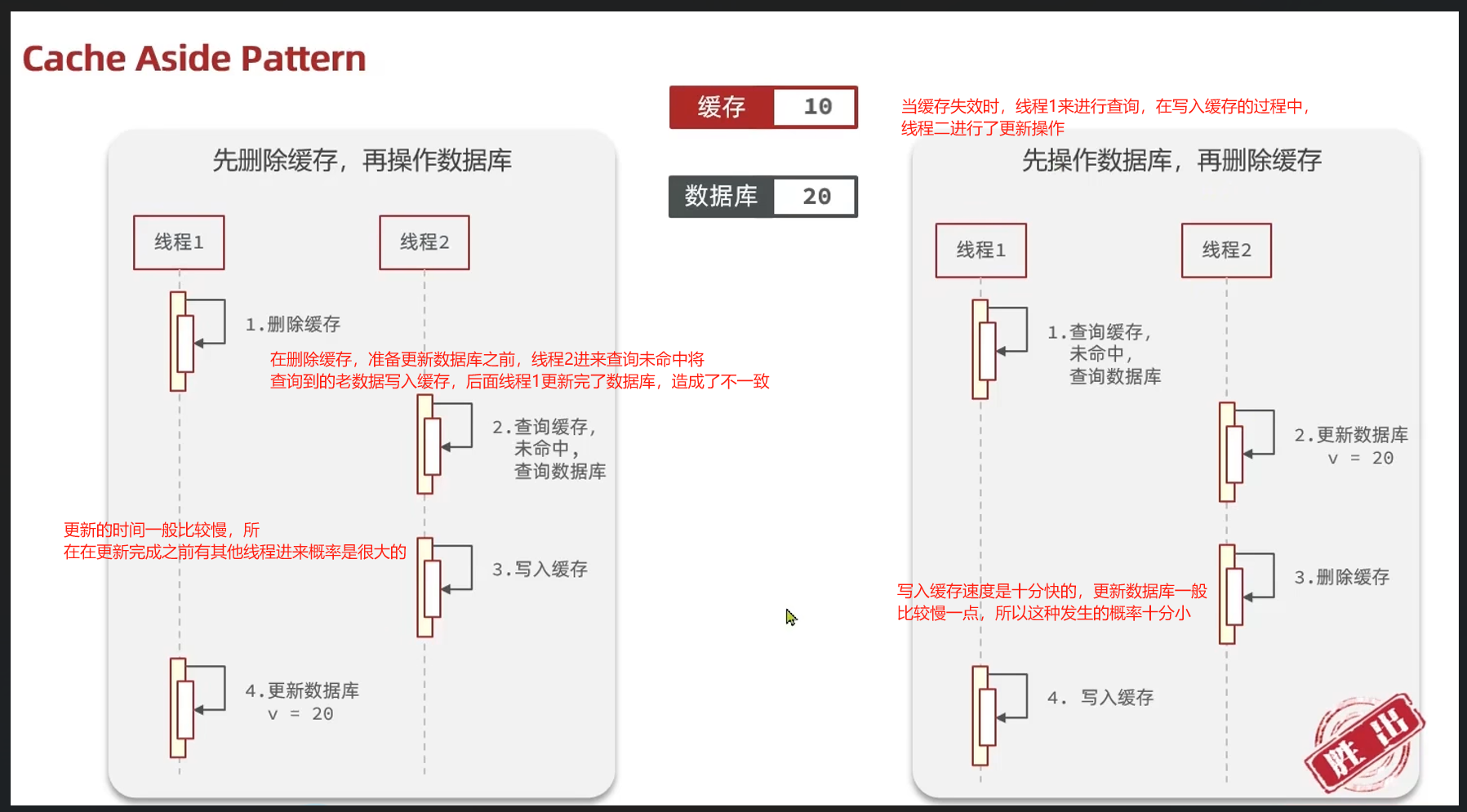
應該具體操作緩存還是操作數據庫,我們應當是先操作數據庫,再刪除緩存,原因在于,如果你選擇第一種方案,在兩個線程并發來訪問時,假設線程1先來,他先把緩存刪了,此時線程2過來,他查詢緩存數據并不存在,此時他寫入緩存,當他寫入緩存后,線程1再執行更新動作時,實際上寫入的就是舊的數據,新的數據被舊數據覆蓋了。
先操作緩存還是先操作數據庫?
? 先刪除緩存,再操作數據庫
? 先操作數據庫,再刪除緩存
2.實現商鋪和緩存與數據庫雙寫一致
核心思路如下:
修改ShopController中的業務邏輯,滿足下面的需求:
根據id查詢店鋪時,如果緩存未命中,則查詢數據庫,將數據庫結果寫入緩存,并設置超時時間
根據id修改店鋪時,先修改數據庫,再刪除緩存
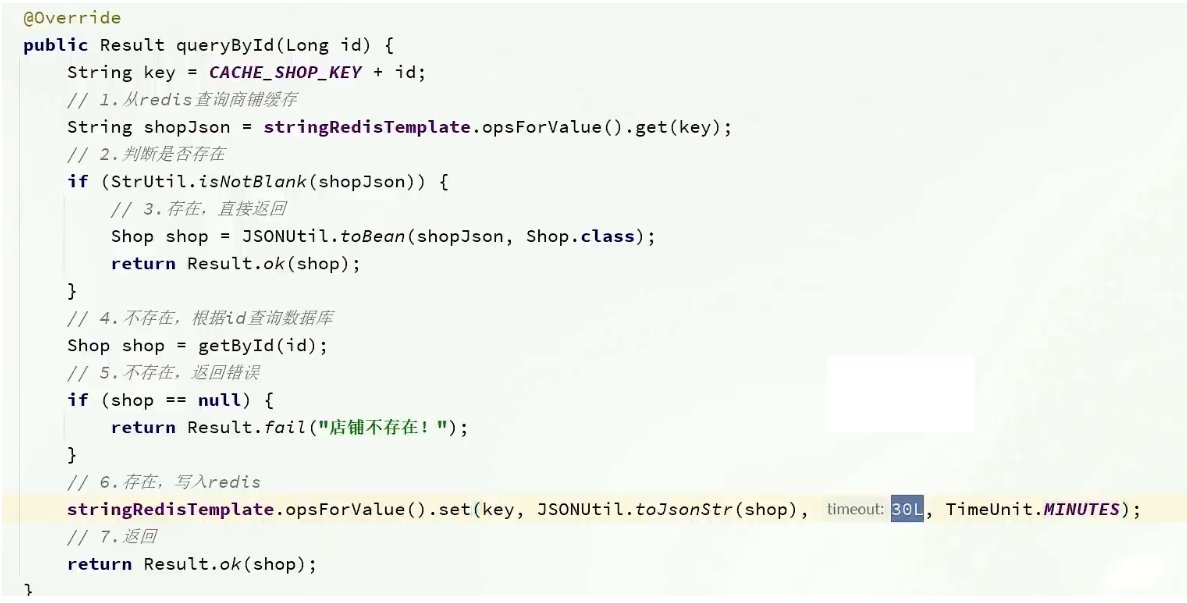
修改重點代碼1:修改ShopServiceImpl的queryById方法
設置redis緩存時添加過期時間
修改重點代碼2
代碼分析:通過之前的淘汰,我們確定了采用刪除策略,來解決雙寫問題,當我們修改了數據之后,然后把緩存中的數據進行刪除,查詢時發現緩存中沒有數據,則會從mysql中加載最新的數據,從而避免數據庫和緩存不一致的問題

四、緩存穿透
1.定義
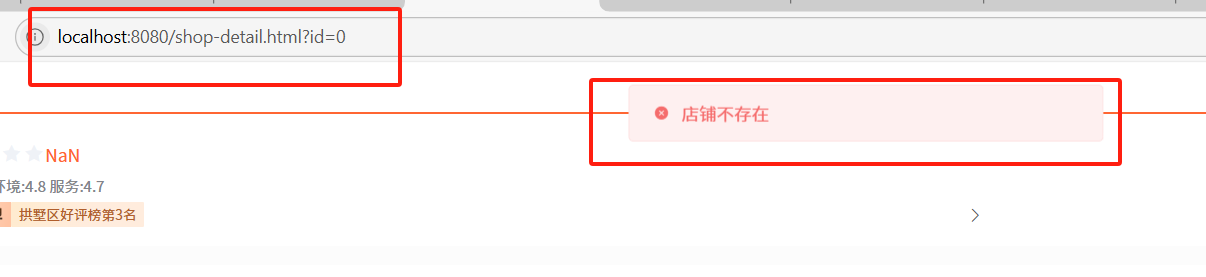
指請求查詢一個不存在的數據,緩存和數據庫中均無該數據,導致請求每次都穿透到數據庫,造成資源浪費。若被惡意攻擊(如批量請求不存在的 ID),可能導致數據庫崩潰。
典型場景:惡意用戶通過腳本批量請求user_id=-1等不存在的參數。
例如:請求店鋪為0的信息
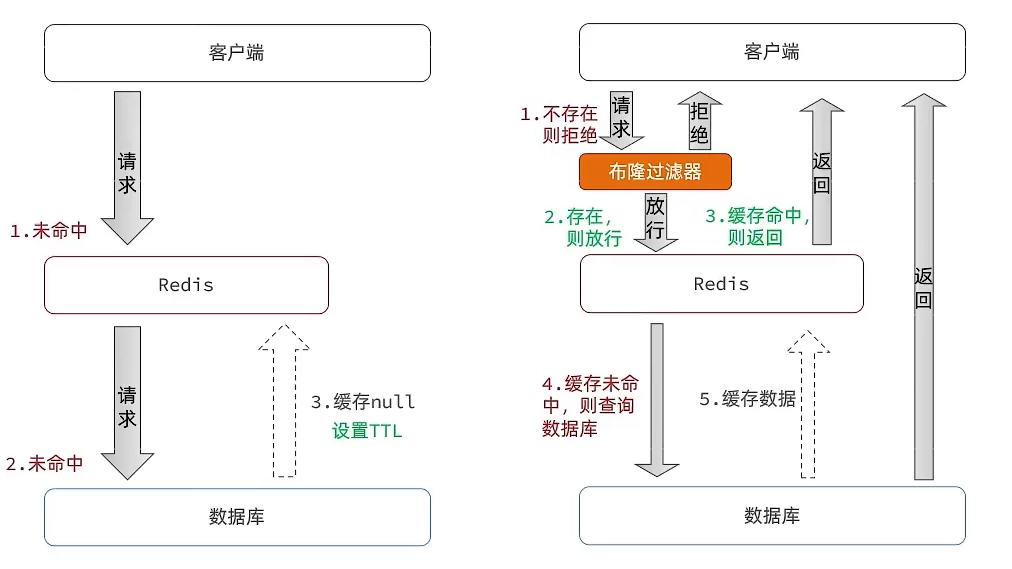
常見的解決方案有兩種:
| 方案 | 實現方式 | 優缺點 |
|---|---|---|
| 布隆過濾器(Bloom Filter) | 在請求進入數據庫前,先用布隆過濾器判斷數據是否存在,不存在則直接拒絕。 | - 優點:空間效率高,過濾速度快 - 缺點:存在誤判率(誤報存在,漏報不存在) |
| 空值緩存 | 當查詢結果為 null 時,仍將 null 存入緩存(設置短過期時間,如 5 分鐘),避免重復查詢數據庫。 | - 優點:簡單易實現 - 缺點:可能存儲無效空值,占用少量內存 |
2.編碼解決商品查詢的緩存穿透問題:
核心思路如下:
在原來的邏輯中,我們如果發現這個數據在mysql中不存在,直接就返回404了,這樣是會存在緩存穿透問題的
現在的邏輯中:如果這個數據不存在,我們不會返回404 ,還是會把這個數據寫入到Redis中,并且將value設置為空,歐當再次發起查詢時,我們如果發現命中之后,判斷這個value是否是null,如果是null,則是之前寫入的數據,證明是緩存穿透數據,如果不是,則直接返回數據。
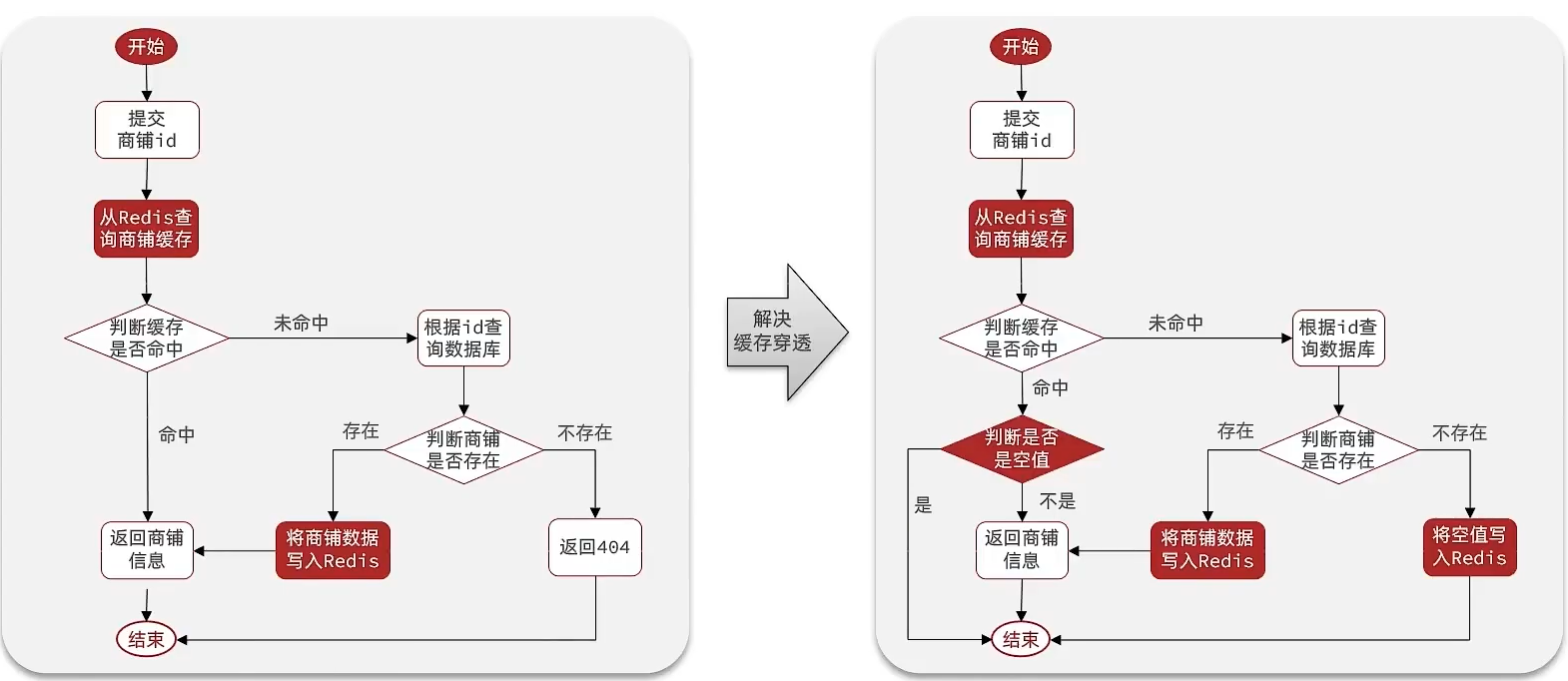
3.小總結:
緩存穿透產生的原因是什么?
用戶請求的數據在緩存中和數據庫中都不存在,不斷發起這樣的請求,給數據庫帶來巨大壓力
緩存穿透的解決方案有哪些?
* 緩存null值
* 布隆過濾
* 增強id的復雜度,避免被猜測id規律
* 做好數據的基礎格式校驗
* 加強用戶權限校驗
* 做好熱點參數的限流
五、緩存雪崩
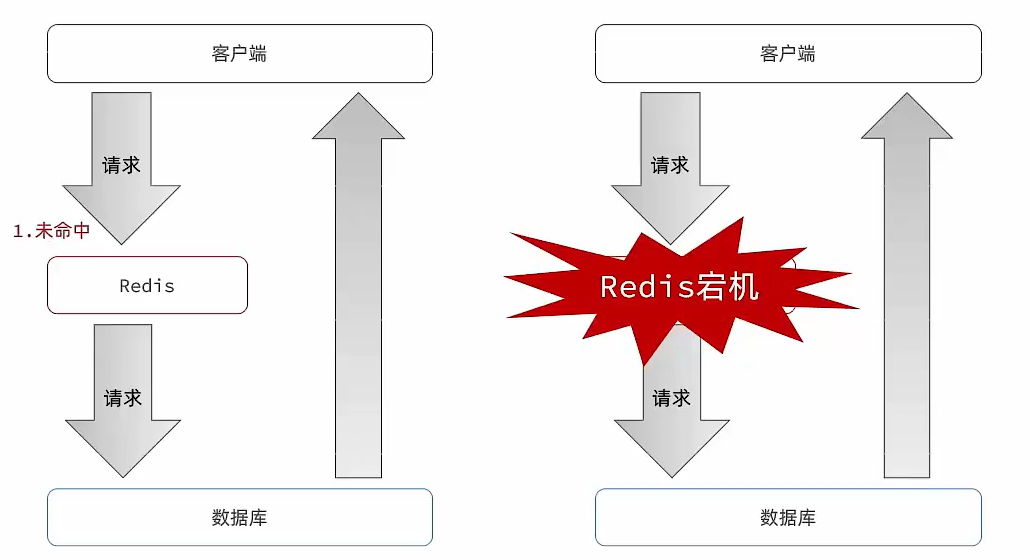
1.定義
- 指大量緩存 key 在同一時間段失效,或緩存服務整體不可用,導致海量請求直接訪問數據庫,造成數據庫雪崩甚至宕機。
- 典型場景:緩存服務器重啟、大量 key 設置相同過期時間(如凌晨零點失效)。
2.解決方案
| 方案 | 實現方式 | 優缺點 |
|---|---|---|
| 過期時間分散化 | 為不同 key 的過期時間添加隨機值(如TTL=3600+random(0,1800)),避免集體失效。 | - 優點:簡單有效,成本低 - 缺點:無法應對緩存服務整體故障 |
| 多級緩存架構 | 部署多層緩存(如本地緩存 + Redis 緩存),當 Redis 失效時,本地緩存仍可響應請求。 | - 優點:提高可用性,降低數據庫壓力 - 缺點:維護成本高,需處理緩存一致性 |
| 緩存集群與熔斷 | - 緩存采用集群部署,避免單點故障 - 引入熔斷機制(如 Hystrix),當數據庫壓力過高時暫時拒絕部分請求。 | - 優點:高可用性,保護數據庫 - 缺點:需要額外組件支持,增加架構復雜度 |
| 持久化與熱重啟 | 啟用 Redis 持久化(RDB/AOF),服務器重啟時快速加載緩存,減少全量失效窗口。 | - 優點:恢復速度快 - 缺點:依賴持久化文件的完整性 |
六、緩存擊穿
1.?定義
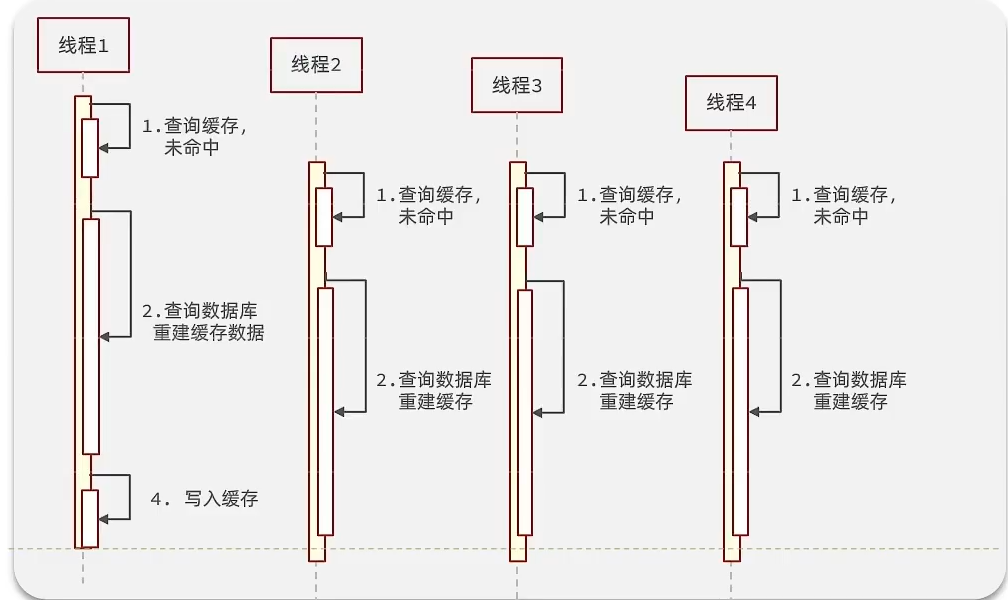
- 指熱點數據的緩存過期瞬間,大量請求同時穿透緩存直達數據庫,導致數據庫負載激增的現象。
- 典型場景:秒殺活動中,某商品的緩存 key 過期,瞬間數萬請求訪問數據庫查詢庫存。
?假設線程1在查詢緩存之后,本來應該去查詢數據庫,然后把這個數據重新加載到緩存的,此時只要線程1走完這個邏輯,其他線程就都能從緩存中加載這些數據了,但是假設在線程1沒有走完的時候,后續的線程2,線程3,線程4同時過來訪問當前這個方法, 那么這些線程都不能從緩存中查詢到數據,那么他們就會同一時刻來訪問查詢緩存,都沒查到,接著同一時間去訪問數據庫,同時的去執行數據庫代碼,對數據庫訪問壓力過大
2.解決方案
| 方案 | 實現方式 | 優缺點 |
|---|---|---|
| 互斥鎖(Mutex) | 當緩存失效時,先通過 Redis 的SETNX獲取鎖,成功的線程查詢數據庫并更新緩存,其他線程等待鎖釋放。 | - 優點:簡單有效,避免大量請求擊穿 - 缺點:存在鎖競爭,可能阻塞請求 |
| 熱點數據永不過期(邏輯過期) | 不設置過期時間,通過后臺線程異步更新數據(如定時任務)。 | - 優點:完全避免過期擊穿 - 缺點:數據一致性略有延遲,需配合版本號或消息隊列更新 |
| 緩存時間隨機打散 | 給熱點 key 的過期時間添加隨機偏移(如expire=3600+random(0,600)),避免同時過期。 | - 優點:輕量級方案,適合非強一致場景 - 缺點:無法完全杜絕擊穿,但可大幅降低概率 |
這里我們重點講解互斥鎖和邏輯過期
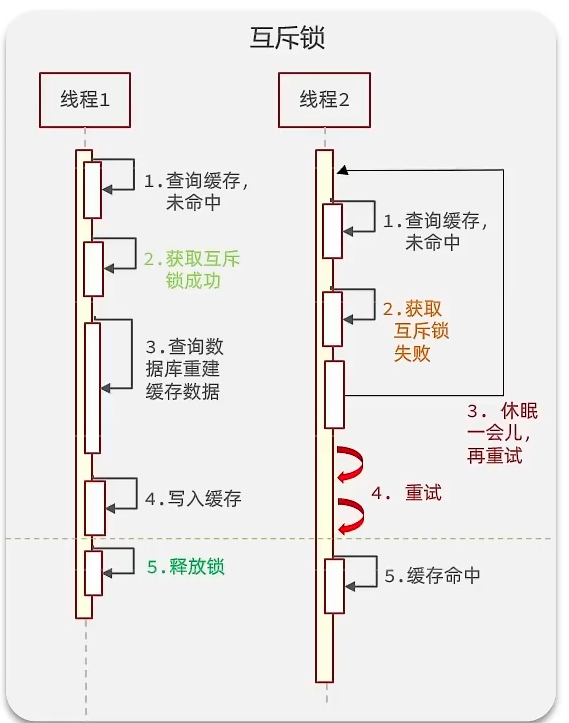
2.1互斥鎖
因為鎖能實現互斥性。假設線程過來,只能一個人一個人的來訪問數據庫,從而避免對于數據庫訪問壓力過大,但這也會影響查詢的性能,因為此時會讓查詢的性能從并行變成了串行,我們可以采用tryLock方法 + double check來解決這樣的問題。
假設現在線程1過來訪問,他查詢緩存沒有命中,但是此時他獲得到了鎖的資源,那么線程1就會一個人去執行邏輯,假設現在線程2過來,線程2在執行過程中,并沒有獲得到鎖,那么線程2就可以進行到休眠,直到線程1把鎖釋放后,線程2獲得到鎖,然后再來執行邏輯,此時就能夠從緩存中拿到數據了。
| 優點 | 缺點 |
|---|---|
| 1. 強一致性,確保緩存與數據庫實時同步; 2. 實現簡單,適用于中小并發場景。 | 1. 高并發下存在鎖競爭,可能導致請求延遲; 2. 極端情況下(如數據庫慢查詢)可能引發線程饑餓。 |
2.2邏輯過期
- 物理過期:緩存不設置
expire,永久存儲;- 邏輯過期:在緩存值中附加
過期時間戳,由應用層判斷是否需要更新。- 異步更新:發現邏輯過期時,啟動后臺線程異步更新緩存,前臺請求返回舊數據,避免阻塞。
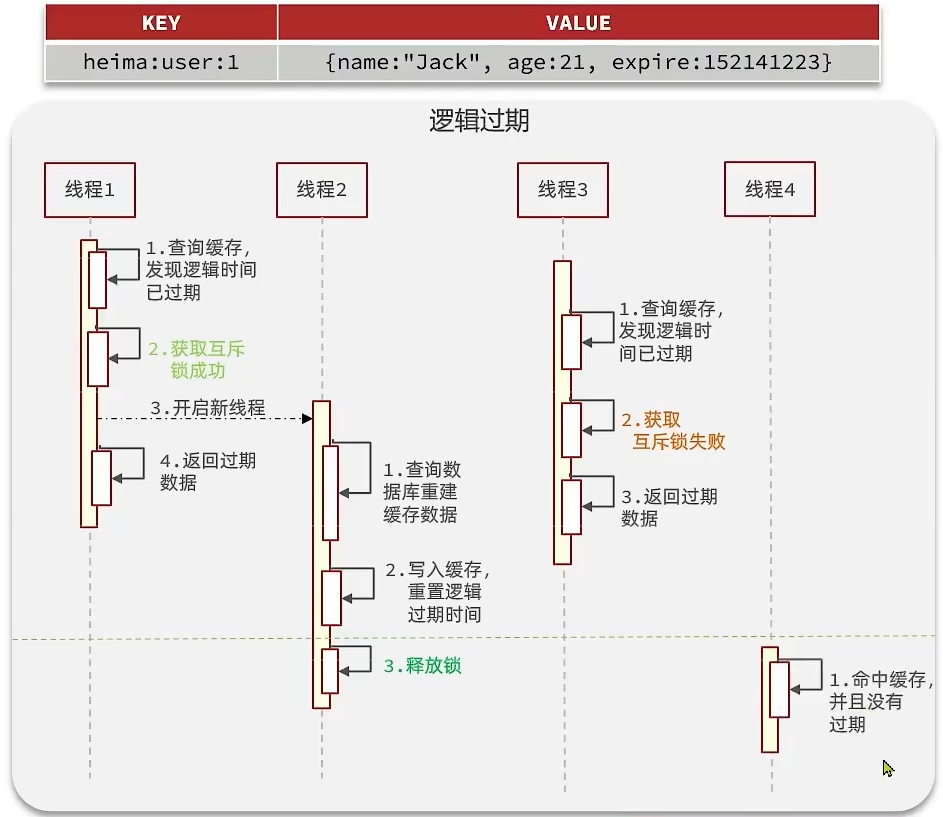
流程:
我們把過期時間設置在 redis的value中,注意:這個過期時間并不會直接作用于redis,而是我們后續通過邏輯去處理。假設線程1去查詢緩存,然后從value中判斷出來當前的數據已經過期了,此時線程1去獲得互斥鎖,那么其他線程會進行阻塞,獲得了鎖的線程他會開啟一個線程去進行 以前的重構數據的邏輯,直到新開的線程完成這個邏輯后,才釋放鎖, 而線程1直接進行返回,假設現在線程3過來訪問,由于線程線程2持有著鎖,所以線程3無法獲得鎖,線程3也直接返回數據,只有等到新開的線程2把重建數據構建完后,其他線程才能走返回正確的數據。
這種方案巧妙在于,異步的構建緩存,缺點在于在構建完緩存之前,返回的都是臟數據。
| 優點 | 缺點 |
|---|---|
| 1. 無鎖競爭,響應速度快,適合高并發讀場景; 2. 避免緩存擊穿的同時保證服務可用性。 | 1. 存在數據不一致窗口(舊數據可能被讀取); 2. 后臺更新失敗時需額外容錯機制(如重試隊列)。 |
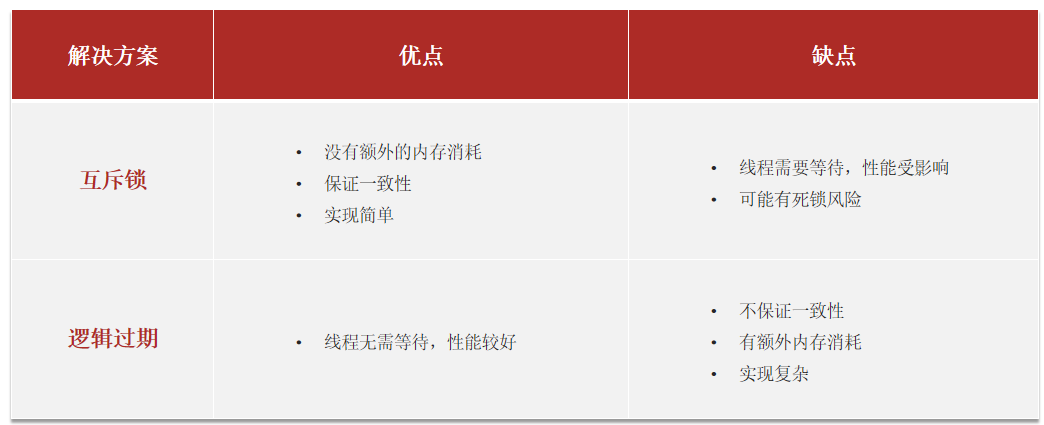
3.互斥鎖 vs 邏輯過期:場景選擇與組合方案
| 維度 | 互斥鎖方案 | 邏輯過期方案 |
|---|---|---|
| 一致性要求 | 強一致性(實時同步) | 最終一致性(允許短期延遲) |
| 并發場景 | 中小并發、寫操作較頻繁 | 高并發讀、寫操作較少 |
| 典型應用 | 庫存扣減、訂單狀態查詢 | 商品詳情頁、首頁輪播圖 |
| 組合優化 | 互斥鎖 + 邏輯過期: 1. 邏輯過期作為主方案,提升讀性能; 2. 后臺更新時添加互斥鎖,避免并發臟寫。 |
互斥鎖方案:由于保證了互斥性,所以數據一致,且實現簡單,因為僅僅只需要加一把鎖而已,也沒其他的事情需要操心,所以沒有額外的內存消耗,缺點在于有鎖就有死鎖問題的發生,且只能串行執行性能肯定受到影響
邏輯過期方案:線程讀取過程中不需要等待,性能好,有一個額外的線程持有鎖去進行重構數據,但是在重構數據完成前,其他的線程只能返回之前的數據,且實現起來麻煩
4.利用互斥鎖解決緩存擊穿問題
核心思路:相較于原來從緩存中查詢不到數據后直接查詢數據庫而言,現在的方案是 進行查詢之后,如果從緩存沒有查詢到數據,則進行互斥鎖的獲取,獲取互斥鎖后,判斷是否獲得到了鎖,如果沒有獲得到,則休眠,過一會再進行嘗試,直到獲取到鎖為止,才能進行查詢
如果獲取到了鎖的線程,再去進行查詢,查詢后將數據寫入redis,再釋放鎖,返回數據,利用互斥鎖就能保證只有一個線程去執行操作數據庫的邏輯,防止緩存擊穿
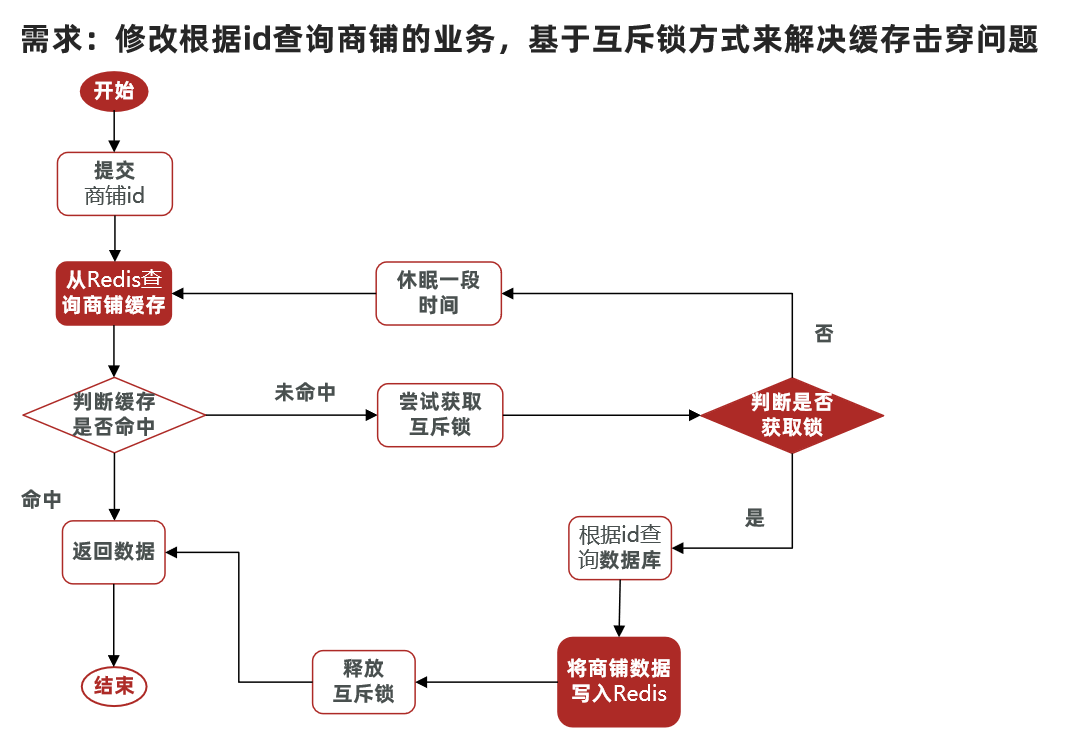
操作鎖的代碼:
核心思路就是利用redis的setnx方法來表示獲取鎖,該方法含義是redis中如果沒有這個key,則插入成功,返回1,在stringRedisTemplate中返回true, 如果有這個key則插入失敗,則返回0,在stringRedisTemplate返回false,我們可以通過true,或者是false,來表示是否有線程成功插入key,成功插入的key的線程我們認為他就是獲得到鎖的線程。
//獲取鎖
private boolean tryLock(String key) {Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", 10, TimeUnit.SECONDS);return BooleanUtil.isTrue(flag);
}//釋放鎖
private void unlock(String key) {stringRedisTemplate.delete(key);
}操作代碼:
public Shop queryWithMutex(Long id) {String key = CACHE_SHOP_KEY + id;// 1、從redis中查詢商鋪緩存String shopJson = stringRedisTemplate.opsForValue().get("key");// 2、判斷是否存在if (StrUtil.isNotBlank(shopJson)) {// 存在,直接返回return JSONUtil.toBean(shopJson, Shop.class);}//判斷命中的值是否是空值if (shopJson != null) {//返回一個錯誤信息return null;}// 4.實現緩存重構//4.1 獲取互斥鎖String lockKey = "lock:shop:" + id;Shop shop = null;try {boolean isLock = tryLock(lockKey);// 4.2 判斷否獲取成功if(!isLock){//4.3 失敗,則休眠重試Thread.sleep(50);return queryWithMutex(id);}//4.4 成功,根據id查詢數據庫shop = getById(id);// 5.不存在,返回錯誤if(shop == null){//將空值寫入redisstringRedisTemplate.opsForValue().set(key,"",CACHE_NULL_TTL,TimeUnit.MINUTES);//返回錯誤信息return null;}//6.寫入redisstringRedisTemplate.opsForValue().set(key,JSONUtil.toJsonStr(shop),CACHE_NULL_TTL,TimeUnit.MINUTES);}catch (Exception e){throw new RuntimeException(e);}finally {//7.釋放互斥鎖unlock(lockKey);}return shop;}
5.利用邏輯過期解決緩存擊穿問題
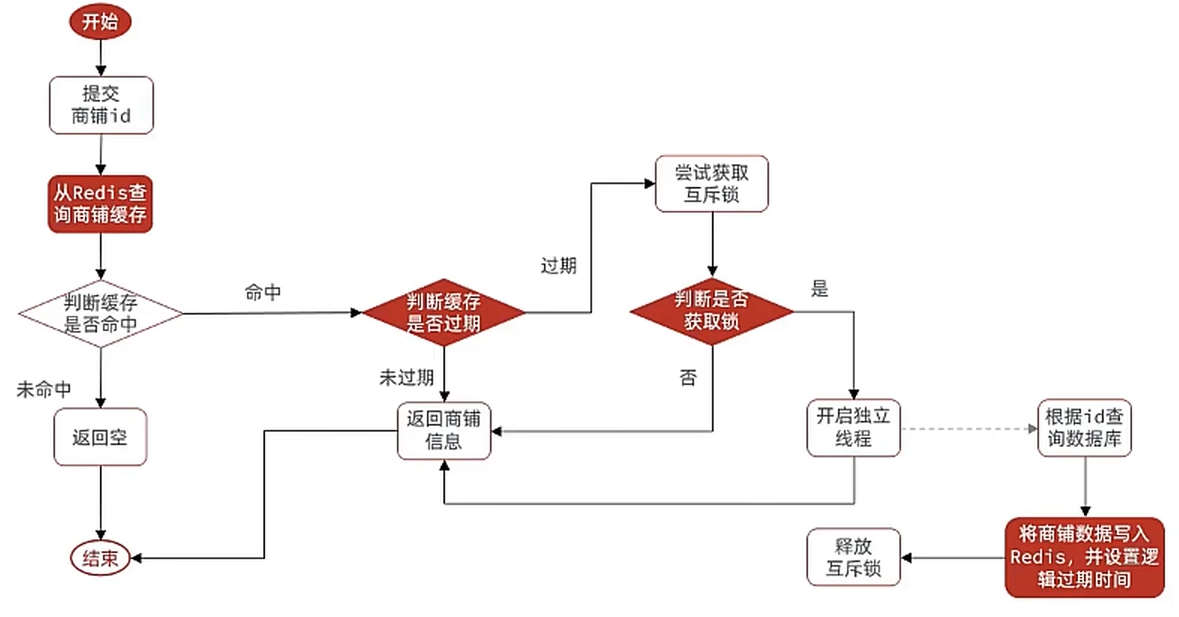
需求:修改根據id查詢商鋪的業務,基于邏輯過期方式來解決緩存擊穿問題
思路分析:當用戶開始查詢redis時,判斷是否命中,如果沒有命中則直接返回空數據,不查詢數據庫,而一旦命中后,將value取出,判斷value中的過期時間是否滿足,如果沒有過期,則直接返回redis中的數據,如果過期,則在開啟獨立線程后直接返回之前的數據,獨立線程去重構數據,重構完成后釋放互斥鎖。
如果封裝數據:因為現在redis中存儲的數據的value需要帶上過期時間,此時要么你去修改原來的實體類,要么你
步驟一、
新建一個實體類,我們采用第二個方案,這個方案,對原來代碼沒有侵入性。
package com.hmdp.utils;import lombok.Builder;
import lombok.Data;import java.io.Serializable;
import java.time.LocalDateTime;@Data
@Builder
public class RedisData implements Serializable {private LocalDateTime expireTime;private Object data;
}
步驟二、
在ShopServiceImpl新增此方法,利用單元測試進行緩存預熱
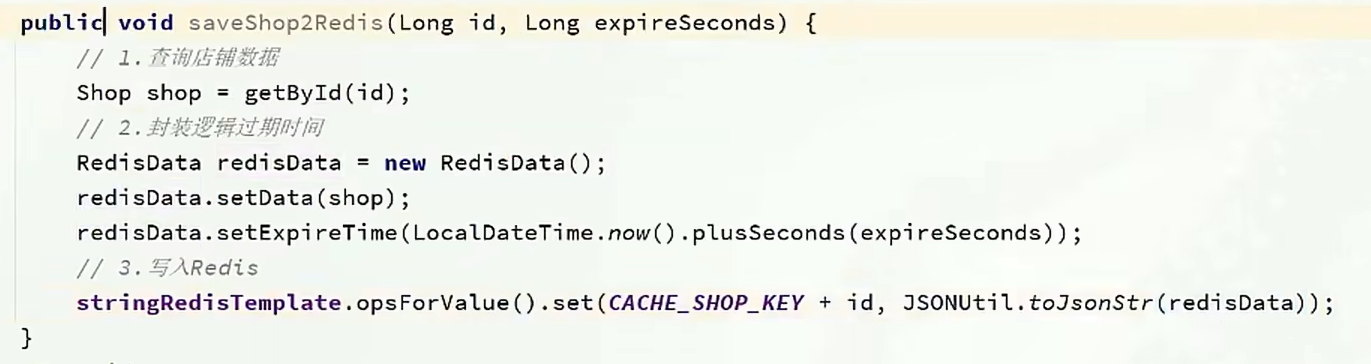
在測試類中

步驟三:正式代碼
ShopServiceImpl
private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10);
public Shop queryWithLogicalExpire( Long id ) {String key = CACHE_SHOP_KEY + id;// 1.從redis查詢商鋪緩存String json = stringRedisTemplate.opsForValue().get(key);// 2.判斷是否存在if (StrUtil.isBlank(json)) {// 3.存在,直接返回return null;}// 4.命中,需要先把json反序列化為對象RedisData redisData = JSONUtil.toBean(json, RedisData.class);Shop shop = JSONUtil.toBean((JSONObject) redisData.getData(), Shop.class);LocalDateTime expireTime = redisData.getExpireTime();// 5.判斷是否過期if(expireTime.isAfter(LocalDateTime.now())) {// 5.1.未過期,直接返回店鋪信息return shop;}// 5.2.已過期,需要緩存重建// 6.緩存重建// 6.1.獲取互斥鎖String lockKey = LOCK_SHOP_KEY + id;boolean isLock = tryLock(lockKey);// 6.2.判斷是否獲取鎖成功if (isLock){CACHE_REBUILD_EXECUTOR.submit( ()->{try{//重建緩存this.saveShop2Redis(id,20L);}catch (Exception e){throw new RuntimeException(e);}finally {unlock(lockKey);}});}// 6.4.返回過期的商鋪信息return shop;
}七、封裝Redis工具類
基于StringRedisTemplate封裝一個緩存工具類,滿足下列需求:
* 方法1:將任意Java對象序列化為json并存儲在string類型的key中,并且可以設置TTL過期時間
* 方法2:將任意Java對象序列化為json并存儲在string類型的key中,并且可以設置邏輯過期時間,用于處理緩存擊穿問題* 方法3:根據指定的key查詢緩存,并反序列化為指定類型,利用緩存空值的方式解決緩存穿透問題
* 方法4:根據指定的key查詢緩存,并反序列化為指定類型,需要利用邏輯過期解決緩存擊穿問題
將邏輯進行封裝
@Slf4j
@Component
public class CacheClient {private final StringRedisTemplate stringRedisTemplate;private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10);public CacheClient(StringRedisTemplate stringRedisTemplate) {this.stringRedisTemplate = stringRedisTemplate;}public void set(String key, Object value, Long time, TimeUnit unit) {stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(value), time, unit);}public void setWithLogicalExpire(String key, Object value, Long time, TimeUnit unit) {// 設置邏輯過期RedisData redisData = new RedisData();redisData.setData(value);redisData.setExpireTime(LocalDateTime.now().plusSeconds(unit.toSeconds(time)));// 寫入RedisstringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(redisData));}public <R,ID> R queryWithPassThrough(String keyPrefix, ID id, Class<R> type, Function<ID, R> dbFallback, Long time, TimeUnit unit){String key = keyPrefix + id;// 1.從redis查詢商鋪緩存String json = stringRedisTemplate.opsForValue().get(key);// 2.判斷是否存在if (StrUtil.isNotBlank(json)) {// 3.存在,直接返回return JSONUtil.toBean(json, type);}// 判斷命中的是否是空值if (json != null) {// 返回一個錯誤信息return null;}// 4.不存在,根據id查詢數據庫R r = dbFallback.apply(id);// 5.不存在,返回錯誤if (r == null) {// 將空值寫入redisstringRedisTemplate.opsForValue().set(key, "", CACHE_NULL_TTL, TimeUnit.MINUTES);// 返回錯誤信息return null;}// 6.存在,寫入redisthis.set(key, r, time, unit);return r;}public <R, ID> R queryWithLogicalExpire(String keyPrefix, ID id, Class<R> type, Function<ID, R> dbFallback, Long time, TimeUnit unit) {String key = keyPrefix + id;// 1.從redis查詢商鋪緩存String json = stringRedisTemplate.opsForValue().get(key);// 2.判斷是否存在if (StrUtil.isBlank(json)) {// 3.存在,直接返回return null;}// 4.命中,需要先把json反序列化為對象RedisData redisData = JSONUtil.toBean(json, RedisData.class);R r = JSONUtil.toBean((JSONObject) redisData.getData(), type);LocalDateTime expireTime = redisData.getExpireTime();// 5.判斷是否過期if(expireTime.isAfter(LocalDateTime.now())) {// 5.1.未過期,直接返回店鋪信息return r;}// 5.2.已過期,需要緩存重建// 6.緩存重建// 6.1.獲取互斥鎖String lockKey = LOCK_SHOP_KEY + id;boolean isLock = tryLock(lockKey);// 6.2.判斷是否獲取鎖成功if (isLock){// 6.3.成功,開啟獨立線程,實現緩存重建CACHE_REBUILD_EXECUTOR.submit(() -> {try {// 查詢數據庫R newR = dbFallback.apply(id);// 重建緩存this.setWithLogicalExpire(key, newR, time, unit);} catch (Exception e) {throw new RuntimeException(e);}finally {// 釋放鎖unlock(lockKey);}});}// 6.4.返回過期的商鋪信息return r;}public <R, ID> R queryWithMutex(String keyPrefix, ID id, Class<R> type, Function<ID, R> dbFallback, Long time, TimeUnit unit) {String key = keyPrefix + id;// 1.從redis查詢商鋪緩存String shopJson = stringRedisTemplate.opsForValue().get(key);// 2.判斷是否存在if (StrUtil.isNotBlank(shopJson)) {// 3.存在,直接返回return JSONUtil.toBean(shopJson, type);}// 判斷命中的是否是空值if (shopJson != null) {// 返回一個錯誤信息return null;}// 4.實現緩存重建// 4.1.獲取互斥鎖String lockKey = LOCK_SHOP_KEY + id;R r = null;try {boolean isLock = tryLock(lockKey);// 4.2.判斷是否獲取成功if (!isLock) {// 4.3.獲取鎖失敗,休眠并重試Thread.sleep(50);return queryWithMutex(keyPrefix, id, type, dbFallback, time, unit);}// 4.4.獲取鎖成功,根據id查詢數據庫r = dbFallback.apply(id);// 5.不存在,返回錯誤if (r == null) {// 將空值寫入redisstringRedisTemplate.opsForValue().set(key, "", CACHE_NULL_TTL, TimeUnit.MINUTES);// 返回錯誤信息return null;}// 6.存在,寫入redisthis.set(key, r, time, unit);} catch (InterruptedException e) {throw new RuntimeException(e);}finally {// 7.釋放鎖unlock(lockKey);}// 8.返回return r;}private boolean tryLock(String key) {Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", 10, TimeUnit.SECONDS);return BooleanUtil.isTrue(flag);}private void unlock(String key) {stringRedisTemplate.delete(key);}
}看到這如果有用的話記得點贊關注哦,后續會更新更多內容的!!


)








算法類cv::cuda::OpticalFlowDual_TVL1)






 附源碼)

