抽象
在不斷擴大的 5G-NR 無線蜂窩網絡領域中,無線干擾攻擊作為安全攻擊普遍存在,損害了接收信號的質量。我們通過將加性高斯白噪聲 (AWGN) 合并到真實世界的同相和正交 (I/Q) OFDM 數據集中來模擬干擾環境。利用卷積自動編碼器 (CAE) 對各種特征(例如異構 I/Q 數據集)實施干擾檢測;提取有關同步信號塊 (SSB) 的相關信息,并減少具有明顯類不平衡的 SSB 觀測值。鑒于數據集的特點,通過采用 Conv1D 條件 Wasserstein 生成對抗網絡梯度懲罰 (CWGAN-GP) 來獲取平衡數據集 關于多數和少數 SSB 觀察。此外,我們將所提出的 CAE 模型在增強數據集上的性能和檢測能力與基準模型進行了比較:卷積去噪自動編碼器 (CDAE) 和卷積稀疏自動編碼器 (CSAE)。盡管所有數據集都涉及復雜的數據異質性,但 CAE 通過實現 CDAE 和 CSAE 的 97.33% 精度、91.33% 召回率、94.08% F1 分數和 94.35% 準確率的平均值,描述了干擾信號檢測性能的穩健性。
索引術語:
數據增強、深度學習、干擾檢測、卷積自動編碼器、5G NR。第一介紹
近年來,5G-NR 無線通信蓬勃發展,智能手機、平板電腦、物聯網和大規模物聯網設備等無線設備的顯著增加。隨著電信基礎設施的出現,無線技術包括大規模多輸入多輸出 (MIMO)[1]、毫米波 (mmwave)[2]、載波聚合[3]、基于學習的資源分配[4]為 5G 蜂窩網絡和最終用戶之間的端到端服務連接提供服務。相反,5G-NR 無線蜂窩網絡也容易受到安全攻擊,尤其是干擾攻擊,故意破壞傳輸信號的信噪比和誤碼率,從而降低通信質量。 干擾攻擊以 5G NR 的物理層下行鏈路信道和下行鏈路信號為目標,利用同步信號塊 (SSB) 中的固有漏洞,SSB 包含負責小區識別和用戶與 gNodeB (gNB) 關聯的主和輔助同步信號(PSS 和 SSS)等重要組件[5].

圖 1:家庭基站內 5G-NR 蜂窩網絡中的干擾檢測
5G-NR 網絡中的一個關鍵問題是來自不同用戶設備的數據異構分布,因為由于地理位置不同,數據通常是非獨立且相同的分布式(非 IID)。這會導致用戶數據集在多個用戶之間的大小和數據分布方面存在顯著差異[6].隨著 5G-NR 網絡的擴展,干擾檢測需要機器學習技術[7,8]以及物理層深度學習 (PHY),以理解傳播接收信號的底層模式。現有的基于深度學習的檢測方法假設數據分布均勻,這可能與實際的 5G 部署不完全一致,因為在現實世界中,非獨立和相同的分布式數據普遍存在。我們提出了一種干擾檢測范式,該范式在解決真實數據集中的類不平衡問題時考慮了從每個用戶那里獲得的異構數據。Varotto 等人。[9]僅在非干擾信號上訓練卷積自動編碼器 (CAE),并針對基于正交頻分復用 (OFDM) 的 5G 信號中的攻擊提出安全策略。其他模型,例如雙閾值深度神經網絡 (DT-DDNN)[10]通過將 I/Q 樣品轉換為 2D 圖像,能夠以較低的誤報和漏檢率檢測更廣泛地檢測干擾器。Almazrouei 等人。[11]通過使用卷積去噪自動編碼器,提出了一種數據驅動的深度學習方法,在不依賴專業知識的情況下對 IEEE 802.11 協議的無線電信號進行去噪,并通過利用解碼器和分類器來強調分類精度的提高。Luo 等人。[12]提出一種卷積稀疏自動編碼器,通過將 MAX-pooling 集成到高效的特征學習中來稀疏特征映射。通過集成卷積神經網絡,這些學習到的特征進一步用于使用 CSAE 提出圖像分類策略。
干擾信號很少見,這會導致嚴重的類不平衡,從而導致在對非干擾和干擾的 SSB 信號進行分類時深度學習性能不佳。不同的信道條件和干擾水平減輕了學習過程。為了應對這一挑戰,我們的框架包括具有梯度懲罰的條件 Wasserstein 生成對抗網絡 (CWGAN-GP),用于增強少數類觀察并減輕數據不平衡,而 CAE 增強特征提取以提高分類性能。使用生成對抗網絡 (GAN) 在有效生成與真實數據分布非常相似的綜合觀測值和增加數據中的觀測值數量方面很有希望。Chapaneri 和 Shah討論了一種可靠的技術,通過利用 GAN 的變體來實現數據增強:Wasserstein GAN (WGAN) 來改善由網絡流量中的網絡攻擊引起的少數攻擊分類問題。Chen 等人。使用基于梯度懲罰 (CWGAN-GP) 的數據增強條件 Wasserstein 生成對抗網絡來檢測電力變壓器中的繞組變形,并顯示出與傳統的基于人工智能 (AI) 的故障診斷模型相比有希望的改進。5G-NR 蜂窩網絡中家庭基站的可視化表示如圖 2 所示。1. 論文的主要貢獻如下:
- 1.?
通過捕獲從多個位置的空口真實 5G 信號中收集的同相和正交 (I/Q) 樣本,實現為射頻域 5G 網絡量身定制的兩級干擾檢測器。
- 2.?
與之前處理均勻分布和平衡數據集的工作不同,我們采用 CWGAN-GP 來增強有限的 SSB 觀察,專注于非 IID 數據集,以減輕對類不平衡的擔憂并確保更具代表性的訓練分布。
- 3.?
增強數據集使用 CAE 進一步訓練,CAE 聯合執行基于重建和分類的干擾檢測,提高檢測能力,同時解決跨家庭小區的數據異構性問題。
我們的工作通過采用擬議的框架并評估基準模型的性能來推進現有的最先進方法在對時域數據集的非干擾和干擾信號進行訓練時識別干擾信號。本文的組織結構如下。第 II?節詳細闡述了用于干擾檢測的 CWGAN-GP 數據增強技術。第 III?節討論了用于干擾檢測的系統模型。第 IV?節在第 V?節中介紹了實驗裝置和仿真結果,第 VI?節總結了本文中的工作。
第二CWGAN-GP 基于增強的干擾檢測
這項工作的目標是定義一種基于增強 ML 的方法,該方法考慮了在不同地理位置收集的每個數據集的數據集異質性。這種異質性是通過存在代表屬性偏度的非 IID 數據、數據集中 SSB 觀察值(訓練樣本)數量的差異以及干擾和非干擾信號的不平衡類分布來識別的。擬議的框架處理數據收集和預處理的各個階段,以模擬受干擾的 5G RF 環境。
II-A 型數據采集
數據是在頻譜分析儀的幫助下獲得的,頻譜分析儀通過空口收集接收到的信號波形,并在電信運營商之間共享:Telus Communication Inc. 和 Rogers Communication Inc.。此外,這些接收到的波形是通過在可用的傳輸蜂窩網絡上設置特定的中心載波頻率和帶寬來獲取的,分別支持各種 5G-NR 頻段和帶寬。
II-B 型數據預處理
將采集到的接收信號轉換為頻譜圖,連貫地反映了信道資源塊的有用信息。僅以復雜 I/Q 樣本的形式從資源塊中提取特定的 SSB。鑒于𝒩地理位置不同,𝒩生成 I/Q 數據集,每個數據集都包含不同的訓練 SSB 觀察值。我們假設 I/Q 樣本的絕對值對于基于功率的干擾檢測有效,其中信號的相位在計算中被忽略。此外,這些絕對值在所有數據集中都進行了歸一化,保持了高維特征空間。此外,通過將信噪比 (SNR) 改變到所有數據集的合適范圍,模擬了 AWGN 作為干擾信號的合并。這提供了有關在所有數據集中具有非干擾和干擾信號類別分布不平衡的訓練 SSB 的信息。我們提出的框架不僅限于 AWGN,還可以用于其他類型的干擾信號。
II-C 型數據增強解決類不平衡問題
為了解決數據增強技術,選擇 CWGAN-GP 來生成更多的 SSB 觀測值作為過采樣方法。但是,對少數 (非干擾) 和多數 (干擾) 信號都采用過采樣,以獲得平衡的二進制分類問題。此外,增強有助于 CAE 偏向于一類信號。GAN 由 Goodfellow 等人提出的兩個神經網絡(生成器和判別器)組成。[16].該生成器旨在利用高斯噪聲來獲得類似于真實數據分布的合成觀測值。GAN 的目標函數遵循最小-最大博弈,公式化為:

生成器LG和判別器LD損失表示如下:

哪里p(x)d?一個?t?一個表示實際數據分布;p(z)z表示高斯分布噪聲 z;G(?)表示生成器函數;E(?) 表示預期的函數;D(?)表示鑒別器函數。的LD同時考慮真實數據和生成數據,同時區分它們,如 (3) 所示。WGAN 和 WGAN-GP 利用公制推地移動器?(EM) 距離作為實際數據分布和生成數據分布之間距離的量度,這優于傳統 GAN 中遵循的?Jensen-Shanon?(JS) 散度。WGAN 在規避模式崩潰問題方面非常有效。EM 距離表示為,

哪里Π?(?r,?g)表示整個聯合概率分布γ?(x,y)實際分布?r和生成的數據分布?g.此外W?(?r,?g)描述了在轉換分布時轉移質量所需的最低成本?r到?g.此外,EM 距離對于獲得有意義的梯度以進行梯度下降訓練相對有用。 WGAN 的生成器 (G) 和評分者 (C)(稱為判別器)之間的目標函數定義為:

相反,由于 WGAN 中的權重削波因子,WGAN 仍然無法收斂。因此,Gulrajani[17]介紹 WGAN-GP,這是 WGAN 的擴展,它懲罰了批評家對其輸入的梯度規范。這使得 WGAN-GP 適用于幾乎沒有超參數調整的穩定訓練。WGAN-GP 的修改后的目標函數定義為,

哪里λ是梯度懲罰系數𝐱^是實數分布之間的抽樣分布?r和生成的分發?g如圖 (7) 所示:

相反,CWGAN-GP 確保輔助條件信息𝐲;class 標簽添加到批評者和生成器中。從形式上講,最小化 critic 和生成器的損失函數的目標值函數表示為 (8)、(9) 和 (10)。

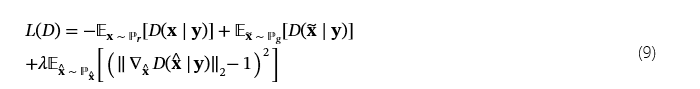


圖 2:卷積自動編碼器 (CAE) 的架構。
第三使用卷積自動編碼器進行干擾檢測
CAE 用于單類分類或干擾檢測。增強數據集中的 2D 時間相關性對于進行高維 I/Q 樣本的卷積運算很有用。此外,與其他 CAE 通常被訓練為重建的自動編碼器不同,我們打算將 CAE 用作重構器和分類器。如圖 1 所示。如圖2所示,CAE取Q×維數P的輸入數組X;其中?P?是 SSB 觀測值,Q?是高維 I/Q 樣本。CAE 的輸出為?Y,由于模型的重建特性,它與?X?的大小相同。CAE 由?L?層組成?= 1,...,?升。編碼器最后一層的輸出為 (11)。解碼器包括轉置 Conv1D 層,這些層通過壓縮的潛在空間從編碼表示形成重建的輸入。解碼器最后一層的輸出為 (12)。


哪里𝐔(?)和𝐕(?)是?th分別是 encoder 和 decoder 層,f?(?)是非線性激活函數,在本例中通常為 ReLU。𝐂(?)和𝐃(?)是層的卷積權重?、卷積運算?跟𝐔(??1)和𝐕(??1)和𝐛(?),𝐝(?)作為層的偏差?.第一層的輸入是?X?∈??P×Q,最后一層?L?的輸出為?Y?=?𝐕(L).
為了實現干擾檢測,我們的 CAE 是通過壓縮輸入 X 來訓練的,該?X?表示干擾和非干擾信號的 I/Q 特征,使用潛在表示。目標是在無監督學習中訓練模型,以最小化 (13) 中獲得的?X?和?Y?之間的均方誤差 (MSE)。但是,重建的權重We(?)和偏見be(?)從 CAE 的訓練編碼器中捕獲?thEncoder 層。這些權重和偏差被轉移到完全連接的神經網絡 (FCN);通過將經過訓練的編碼器和 FCN(添加到編碼器的頭部)組合成一個新的更新模型,將 CAE 轉換為分類器?分別如 (14) 和 (15) 所示。

檢測能力?通過獲取輸入?X?和真實?R,訓練超過 80% 的訓練數據,并使用合適的閾值對 20% 的測試數據進行評估γ.
四實驗裝置
在 5G n71 頻段內實現了實驗設置。根據 3GPP 規范,該頻段跨越 617 MHz 至 652 MHz 的下行鏈路頻率范圍,提供 35 MHz 的總帶寬[18].頻率范圍由兩個運營商 TELUS 和 Rogers 劃分,每個運營商分配了 10 MHz 的帶寬。TELUS 的中心頻率為 632 MHz,而羅杰斯的中心頻率為 622 MHz。該設置如圖 1 所示。3,具有 ThinkRF RTSA R5500 頻譜分析儀作為接收器,帶有兩個不同的天線,用于捕獲來自 TELUS 網絡的空口 (OTA) 5G 信號。
在各種環境中以 15.36 MHz 的頻率進行采樣,包括室內位置和室外場景(包括視線 (LOS) 和非視距 (NLOS) 條件)。收集的樣本使用 PyRF4 API 以 CSV 格式保存,隨后進行處理。要從 SSB 獲得準確的信息,必須估計時間偏移 (TO) 和載波頻率偏移 (CFO)。由于確切的中心頻率未知,因此需要盲搜索方法。為了精確確定 TO 和 CFO,我們利用 PSS 相關特性和循環前綴正交頻分復用 (CP-OFDM) 5G 波形中的循環前綴來與 gNB 信號對齊。

圖 3:用于干擾檢測的實驗裝置。
估算 CFO 的優化問題表示為:

哪里xp?s?s是主同步信號,是 SSB 中的第一個 OFDM 符號,fs是采樣頻率。 為了獲得SSB的時間偏移量,Schmidl & Cox方法[19]被使用。因此,以下優化問題 (17) 以數值方式求解,其中𝒫?(t)和??(t)表示為 (18) 和 (19),其中L^是一個 OFDM 符號中樣本數的一半。

表 I:有關數據集的信息
| 數據集 ID | 位置和傳播條件 | SSB 觀察計數 | 類不平衡 |
|---|---|---|---|
| 1 | Banchory (戶外、NLOS、LOS) | 826 | (1) : 793 (0) : 33 |
| 2 | Legget (戶外, LOS) | 544 | (1) : 518 (0) : 26 |
| 3 | Indoor_2 (室內, LOS) | 971 | (1) : 933 (0) : 32 |
| 4 | Indoor_3 (室內、NLOS) | 1038 | (1) : 998 (0) : 40 |
| 5 | Indoor_4 (室內、NLOS) | 877 | (1) : 839 (0) : 38 |
| 6 | Indoor_5 (室內、NLOS) | 989 | (1) : 945 (0) : 44 |
| 7 | Neighbor_2 (Outdoor, LOS, NLOS) | 805 | (1) : 771 (0) : 34 |
| 8 | Neighbor_3 (Outdoor, NLOS) | 923 | (1) : 886 (0) : 37 |
| 9 | Neighbor_1 (Outdoor, LOS) | 749 | (1) : 719 (0) : 30 |
| 10 | Park Shirley (戶外, LOS, NLOS) | 833 | (1) : 799 (0) : 34 |
| 11 | Shirin Market (Outdoor, LOS) | 664 | (1) : 638 (0) : 27 |
| 12 | 停車標志 (Outdoor, LOS) | 978 | (1) : 937 (0) : 41 |
表 II:CWGAN-GP 參數和超參數
| 參數/超參數 | 值/詳細信息 |
|---|---|
| 模型架構 | C:32-512 學分,G:128-64 學分 |
| 潛在向量維度 | 128 |
| 輟學 | C:0.5,G:無 |
| 批量規范化 | C:無,G:有 |
| 激活函數 | C?和?G?隱藏:LeakyReLU,G 輸出:?tanH |
| 批量大小 | 64 |
| 訓練 Epochs | 20 |
| 優化 | α: 0.0001,β1: 0.5,β2: 0.9 |
| 梯度懲罰系數 | 20 |
| 評論家培訓 | 7 |
V實驗結果
仿真在 12 個異構數據集上執行,每個數據集都包含較少的 SSB 觀測值,干擾 (1) 和非干擾 (0) 信號存在顯著的類不平衡。表?I?總結了每個數據集的信息。
V-A使用 CWGAN-GP 進行數據增強
表 III:自動編碼器的參數和超參數
| 參數/超參數 | 值/詳細信息 | ||
|---|---|---|---|
| CAE認證 | CDAE | CSAE | |
| 層數 (編碼器) | 3 | 3 | 3 |
| 層數 (解碼器) | 3 | 3 | 3 |
| 稀疏概率 | - | - | 0.05 |
| 稀疏因子 | - | - | 0.01 |
| 噪聲系數 | - | 0.3 | - |
| 激活 | ReLU 系列 | ReLU 系列 | ReLU 系列 |
| 輟學 | 0.2 | 0.2 | 0.2 |
| 批量大小 | 200 | 200 | 200 |
| 學習率 | 0.0001 | 0.0001 | 0.0001 |
| 時代 | 30 (自動編碼器和分類器) | 15 (自動編碼器), 30 (分類器) | 15 (自動編碼器), 30 (分類器) |
| 優化 | Adam (自動編碼器和分類器) | Adagrad (自動編碼器), Adam (分類器) | SGD (自動編碼器), Adam (分類器) |
| 損失函數 | MSE 和 BCE | MSE 和 BCE | MSE 和 BCE |
表 IV:80:20 訓練集/測試集上的干擾檢測結果比較
| 數據集 ID | CAE認證 | CDAE | CSAE | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 精度 | 召回 | F1 分數 | 遠 | MDR | 精度 | 召回 | F1 分數 | 遠 | MDR | 精度 | 召回 | F1 分數 | 遠 | MDR | |
| 1 | 100 | 82 | 90 | 0 | 17.8 | 83 | 98 | 90 | 19.9 | 2 | 97 | 95 | 96 | 2.7 | 5 |
| 2 | 97 | 92 | 95 | 2.5 | 8 | 64 | 88 | 74 | 47.6 | 12 | 88 | 98 | 93 | 12.5 | 2 |
| 3 | 97 | 81 | 88 | 2.7 | 19 | 85 | 96 | 90 | 15.5 | 4 | 93 | 92 | 92 | 7 | 8 |
| 4 | 97 | 95 | 96 | 3.1 | 5 | 91 | 97 | 94 | 10.6 | 3 | 93 | 89 | 91 | 7.2 | 11 |
| 5 | 100 | 99 | 99 | 0.4 | 1 | 84 | 98 | 91 | 18 | 2 | 94 | 97 | 96 | 6 | 3 |
| 6 | 92 | 95 | 94 | 8.1 | 5 | 98 | 82 | 90 | 1.8 | 18 | 87 | 88 | 87 | 14.1 | 12 |
| 7 | 100 | 99 | 99 | 0.4 | 1 | 94 | 90 | 92 | 6.2 | 10 | 98 | 98 | 98 | 2 | 2 |
| 8 | 99 | 92 | 95 | 1.1 | 8 | 97 | 84 | 90 | 2.7 | 16 | 90 | 94 | 92 | 9.9 | 6 |
| 9 | 92 | 68 | 78 | 6.4 | 32 | 97 | 95 | 96 | 2.6 | 5 | 95 | 97 | 96 | 5.1 | 3 |
| 10 | 98 | 97 | 98 | 1.6 | 3 | 99 | 86 | 92 | 1 | 14 | 51 | 65 | 57 | 68.6 | 35 |
| 11 | 100 | 99 | 100 | 0.1 | 1 | 92 | 91 | 91 | 7.6 | 9 | 98 | 95 | 96 | 1.9 | 5 |
| 12 | 96 | 97 | 97 | 4.3 | 3 | 92 | 96 | 94 | 9.5 | 4 | 95 | 93 | 94 | 5.21 | 7 |

圖 4:CWGAN-GP 中的訓練損失曲線。
我們采用 CWGAN-GP,它通過將觀察數量增加到固定數量來處理每個數據集的異質性,例如,5000 個觀察;強制執行 2500 個干擾信號和 2500 個非干擾信號。假設每個數據集的整個類不平衡是使用 CWGAN-GP 進行過采樣之前的訓練集。CWGAN-GP 的架構遵循一個用于?C?的五層 Conv1D 神經網絡和用于?G?的兩個 Conv1D 神經網絡。CWGAN-GP 在幾個 epoch 上以固定的批量大小進行訓練[20]生成 250 個生成的觀測值,即 5000 個觀測值;其中包括 2500:干擾和 2500:非干擾 SSB 觀測值。我們為優化器 Adam 選擇默認值,設置梯度懲罰系數,并訓練 critic 幾次,這與[17].表?II?介紹了 CWGAN-GP 的參數和超參數的詳細信息。CWGAN-GP 模型顯示了訓練時期的收斂性(見圖 1)。4),描述評論家的損失與 Wasserstein 的損失一起穩定。然而,生成器損失在訓練的早期階段達到峰值,突出了生成的樣本與真實樣本相去甚遠,并隨著時間的推移逐漸穩定下來,以生成更真實的樣本。
V-B使用 CAE、CDAE 和 CSAE 進行培訓
CAE 在每個數據集 ID 上進行訓練,以展示分類指標精度、召回率、F1 分數和模型準確性方面的檢測性能。但是,干擾檢測需要其他指標,例如誤報率 (FAR) 和漏檢率 (MDR) 來理解實際部署的有效性。FAR 和 MDR 指標對于測量誤報和損害網絡安全的潛在跡象至關重要。此外,CAE 首先在無監督學習算法中進行訓練,同時假設 8:2 作為訓練和驗證集。在第一個訓練過程中,CAE 捕獲經過訓練的編碼器的權重和偏差,并傳輸到全連接層;充當分類器,隨后以監督學習方式進行訓練。表?III?中突出顯示了 CAE 模型的參數和超參數。使用經過訓練的權重的分類器的干擾檢測性能展示了在考慮γ= 0.5 的但是,與其他數據集相比,數據集 ID 9 的召回率和 F1 分數分別為 68% 和 78%。這意味著更大比例的真正干擾信號被錯誤地檢測為假陰性或非干擾信號。此外,漏檢率為 0.32,這表明 32% 的干擾信號被識別為非干擾信號。此外,誤報率為 0.064 或 6.4% 的真正非干擾信號被錯誤地識別為干擾信號。
相反,CDAE[11]和 CSAE[12]在無監督的情況下進行訓練,并計算輸入樣本和解碼輸出之間的重建誤差。在經過訓練的編碼器和全連接層的輸入處僅使用重建誤差,以獲得具有相同閾值的分類性能,這與 CAE 遵循的類似訓練不同。但是,權重/偏差由 CDAE 和 CSAE 捕獲,并轉發到 FCN,類似于 CAE。表?IV?中顯示的 CDAE 檢測能力突出了除數據集 ID 2 之外的所有數據集的有希望的性能;分別實現了 64%、88% 和 74% 的精確率、召回率和 F1 分數。低 precision 值表示存在高誤報。較低的假負值提供了獲得較高召回率的直接提示。此外,數據集 ID 2 的漏檢率顯示,12% 的干擾信號被識別為非干擾信號,47.6% 的非干擾信號的誤報率被錯誤識別為干擾信號;導致更多的誤報。相反,CSAE 在所有數據集中都表現令人滿意,但數據集 ID 10 的精度、召回率、F1 分數和準確性如表?IV?所示。檢測性能差一致地表明高假陰性和高假陽性分別導致獲得低精度和召回率。從漏檢率和誤報率來看,35% 的干擾信號被區分為非干擾信號,68.6% 的非干擾信號被誤認為是干擾信號。由于不同位置的干擾功率的傳播和信道條件不同,所有數據集的性能差異是顯而易見的。此外,所有數據集中模型的準確性比較突出了 CAE 優于 CDAE 和 CSAE,如圖 2 所示。5. 此外,通過假設擬議的 CAE 優于其他基準模型:CDAE 和 CSAE,比較顯示了顯著的性能差異。精度、F1 分數和準確率的平均值突出表明,所提出的 CAE 模型優于基準模型,表?V?顯示了顯著差異。

圖 5:每個數據集的準確性比較。 表 V:模型的平均分類性能指標
| 模型 | 精度 (%) | 召回率 (%) | F1 分數 (%) | 準確率 (%) |
| CAE認證 | 97.33 | 91.33 | 94.08 | 94.35 |
| CDAE | 89.67 | 91.75 | 90.33 | 89.93 |
| CSAE | 89.92 | 91.75 | 90.67 | 89.92 |
六結論和未來工作
我們提出了一種針對 5G-NR 網絡的基于增強的干擾檢測,同時假設各種因素:多個家庭小區的數據異構性、有限的 SSB 觀測以及所有數據集中存在的類不平衡。我們的方法利用 CWGAN-GP 來生成更多的合成 SSB 觀測并獲得平衡的數據集;包含等量的 Jammed 和非 Jammed 信號。為了確保高分類性能和對干擾攻擊的檢測,我們采用了 CAE,并在 5G-NR 蜂窩網絡的 IQ 信號的無監督和有監督學習中訓練模型。結果表明,CAE 的檢測能力在指標方面優于其他基準模型:CDAE 和 CSAE:精度、可接受的召回率、F1 分數和準確性。然而,對所有數據集的 CAE 模型與基準模型的詳細比較表明,與 CDAE 和 CSAE 不同,所提出的方法在訓練過程中沒有涉及重建誤差的情況下,實現了至少 90% 的準確率,性能更好。CAE 的檢測性能取決于 CWGAN-GP 增強樣本的質量,如果發生器損失頻繁波動而不隨時間收斂,則可能會影響性能。我們正在進行的工作旨在解決計算復雜性和優化策略,通過在 5G-NR 網絡中假設更多的家庭基站來提高可擴展性。




:從接口設計到生產實踐)
)







)
)


)
)
