導讀
BaikalDB作為服務百度商業產品的分布式存儲系統,支撐了整個廣告庫海量物料的存儲和OLTP事務處理。隨著數據不斷增長,離線計算時效性和資源需求壓力突顯,基于同一份數據進行OLAP處理也更為經濟便捷,BaikalDB如何在OLTP系統內實現適合大數據分析場景的查詢引擎以應對挑戰?
01 BaikalDB應對OLAP場景的挑戰
BaikalDB是面向百度商業產品系統的需求而設計的分布式存儲系統,過去多年把商業內部幾十套存儲系統全部統一到BaikalDB,解決了異構存儲帶來的各種問題,支撐了整個廣告庫的海量物料存儲和復雜的業務查詢。BaikalDB核心特點包括:
-
兼容mysql協議,支持分布式事務:基于Raft協議實現三副本強一致性,通過兩階段提交協議保障跨節點事務的原子性與持久性?。
-
豐富檢索能力:不僅支持傳統的結構化索引、全文索引等,為解決LLM應用的向量需求,BaikalDB通過內置向量索引方式實現向量數據的存儲和檢索,一套系統支持結構化檢索、全文檢索、向量檢索等豐富的檢索能力,綜合滿足LLM應用的各種記憶存儲和檢索需求。
-
高可用,彈性擴展:支持自動擴縮容和數據均衡,支持自動故障恢復和遷移,無單點。當前管理數千業務表與數十萬億行數據,日均處理百億級請求?。
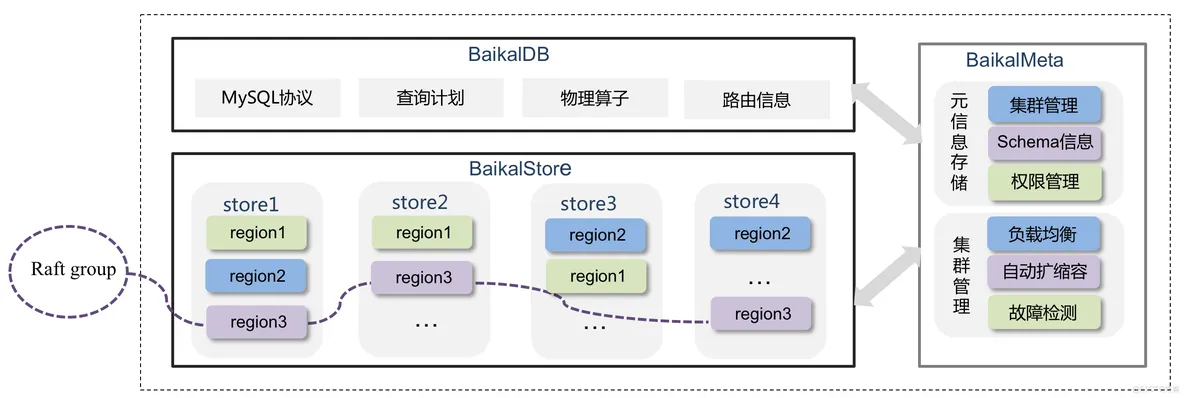
△BaikalDB架構
隨著業務發展,離線分析難以滿足訴求,實時多維分析需求對BaikalDB大數據處理能力的要求顯著提高。BaikalDB的查詢引擎主要面向OLTP(聯機事務處理)場景設計的,以下雙重關鍵瓶頸使其應對OLAP (聯機分析處理)有很大的挑戰:
-
計算性能瓶頸:傳統火山模型使用行存結構破壞緩存局部性、逐行虛函數調用風暴頻繁中斷指令流水線、單調用鏈阻塞多核并行擴展等等弊端,導致大數據分析性能呈超線性劣化。
-
計算資源瓶頸:Baikaldb單節點計算資源有限,面對大規模數據計算,單節點CPU、內存使用容易超限。
BaikalDB從OLTP向HTAP(混合事務/分析處理)架構演進亟需解決當前OLTP查詢架構在面向大規模數據的計算性能瓶頸、計算資源瓶頸,并通過如向量化查詢引擎、MPP多機并行查詢、列式存儲等技術手段優化OLAP場景查詢性能。
02 BaikalDB OLAP查詢引擎的目標
2.1 向量化查詢引擎:解決OLTP查詢引擎性能瓶頸
2.1.1 火山模型性能瓶頸
設計之初,由于BaikalDB主要面向OLTP場景,故而BaikalDB查詢引擎是基于傳統的火山模型而實現。
如下圖所示,在火山模型里,SQL的每個算子會抽象為一個Operator Node,整個SQL執行計劃構建一個Operator Node樹,執行方式就是從根節點到葉子節點自上而下不斷遞歸調用next()函數獲取一批數據進行計算處理。 由于火山模型簡單易用,每個算子獨立實現,不用關心其他算子邏輯等優點,使得火山模型非常適合OLTP場景。
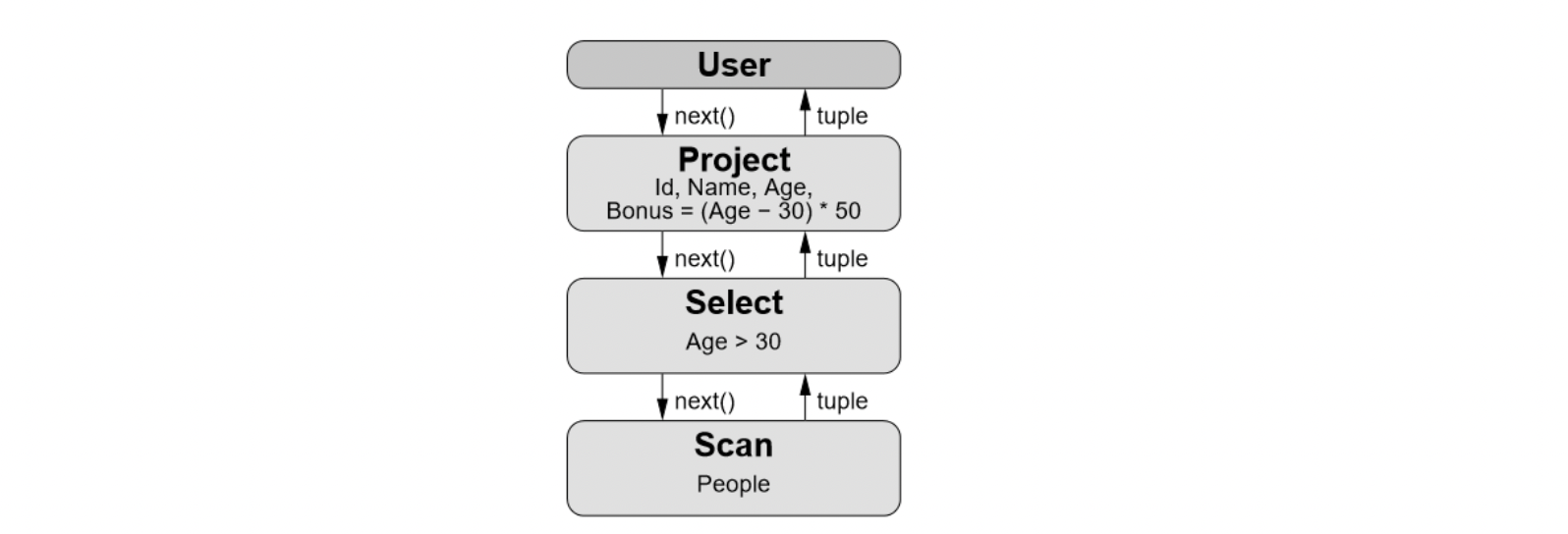
△select id, name, age, (age - 30) * 50 as bonus from peope where age > 30 火山模型執行計劃
但當火山模型處理大量數據時有著以下三大弊端,這些弊端是導致火山模型面對大數據量分析場景查詢性能差的元兇。
-
行式存儲引發的緩存失效問題?
-
數據局部性缺失?:行式存儲(Row-based Storage)將整行數據連續存放,當查詢僅需部分列時,系統被迫加載整行冗余數據,容易造成Cache Miss。
-
硬件資源浪費?:現代CPU三級緩存容量有限,行存結構導致有效數據密度降低。
-
-
逐行處理機制的性能衰減?
-
?函數調用過載?:火山模型要求每個算子逐行調用 next() 接口,處理百萬級數據時產生百萬次函數調用。
-
?CPU流水線中斷?:頻繁的上下文切換導致CPU分支預測失敗率升高。
-
-
執行模型的多核適配缺陷
-
流水線阻塞?:Pull-based模型依賴自頂向下的單調用鏈,無法并行執行相鄰算子。
-
?資源閑置浪費?:現代服務器普遍具備64核以上計算能力,單調用鏈無法充分利用多核能力。
-
當查詢模式從OLTP輕量操作轉向OLAP海量掃描復雜計算時,上述三個弊端導致的查詢性能衰減呈現級聯放大效應。雖然能做一些如batch計算,算子內多線程計算等優化,但并不能解決根本問題,獲得的收益也有限。BaikalDB尋求從根本上解決瓶頸的方法,探尋新架構方案以突破性能瓶頸!
2.1.2 向量化查詢引擎
多核時代下的現代數據庫執行引擎,發展出了向量化查詢引擎,解決上述火山模型的種種弊端,以支持OLAP大數據量查詢性能。與火山模型弊端一一對應,向量化執行引擎特點是如下:
-
列式存儲與硬件加速協同優化?
-
列存數據緊湊布局?:采用列式存儲結構(Colum-based Storage),將同類型數據連續存儲于內存,有效提升CPU緩存行利用率,減少Memory Stall。
-
?SIMD指令集加速?:通過向量寄存器批量處理128/256/512位寬度的連續數據單元,允許CPU在單個指令周期內對多組數據進行相同的操作。
-
-
批量處理提升緩存親和性
-
?數據訪問模式優化?:算子/計算函數內部采用批量處理機制,每次處理一批連續數據塊。這種連續內存訪問模式提升了 CPU DCache 和ICache 的友好性,減少 Cache Miss。
-
流水線氣泡消除?:批處理大量減少上下文切換,降低CPU資源空閑周期占比,顯著提升流水線吞吐量?。
-
-
多核并行計算架構創新
-
Morsel-Driven Parallelism范式?:將Scan輸入的數據劃分為多個數據塊(稱為morsel),morsel作為計算調度的最小單位,能均勻分發給多個CPU core并行處理。
-
Push-based流水線重構?:顛覆傳統Pull模型,通過工作線程主動推送數據塊至下游算子(算子樹中的父節點),消除線程間等待開銷。數據驅動執行,將算子樹切分成多個線性的Pipeline,多Pipeline之間能并行計算。
-
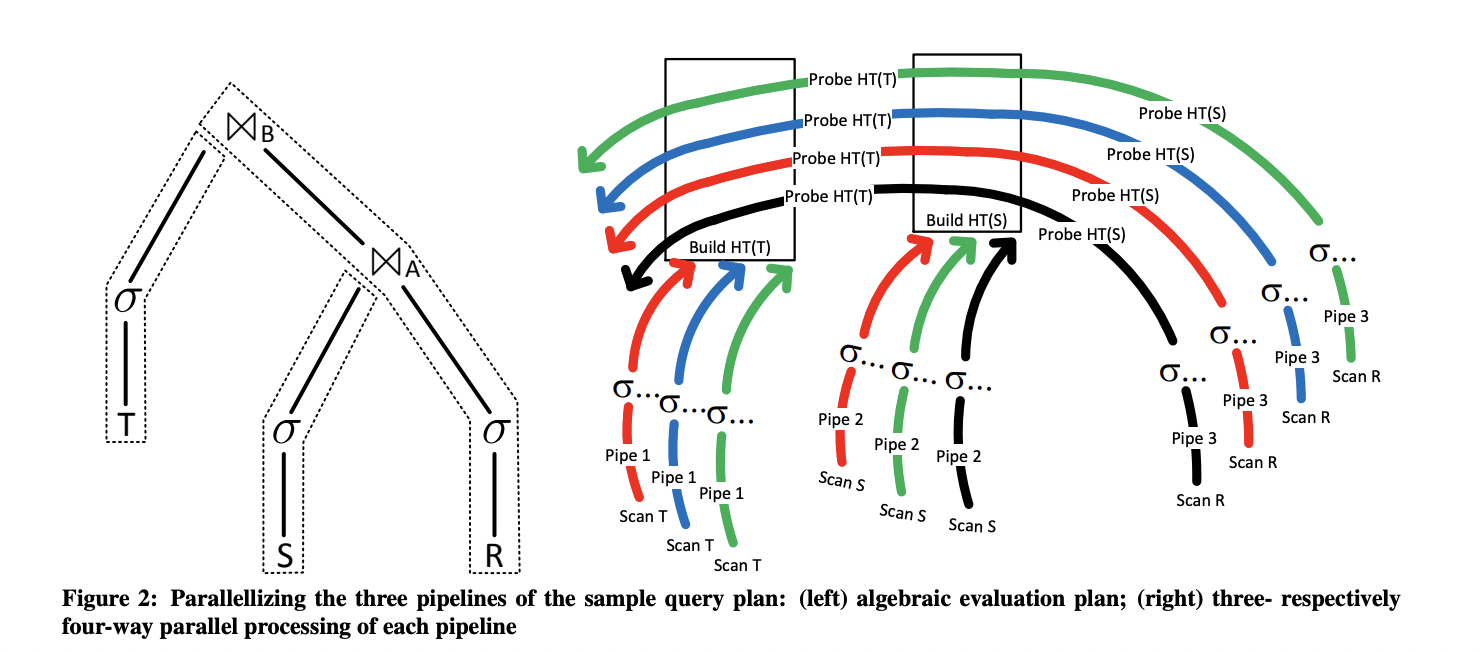
△向量化執行引擎pipeline并行計算
2.2 MPP多機并行計算的啟發:進一步提升OLAP查詢性能
向量化執行引擎在OLAP場景有大幅度的性能提升,卻仍然無法解決單臺計算節點的CPU和內存受限的問題,同時隨著處理數據量增大,單節點執行時間呈指數級增長。
為了打破這一單點限制,進一步提升OLAP查詢性能,MPP(Massively Parallel Processing)大規模并行計算應運而生,其核心特點有:
-
****分布式計算架構:****基于哈希、范圍等策略將數據分布到不同計算節點,實現并行計算加速,能顯著縮短SQL響應時間。
-
****線性擴展:****各計算節點采用無共享架構,通過高速網絡實現跨節點數據交換,天然具備橫向擴展能力,可通過增加節點線性提升整體吞吐量?。
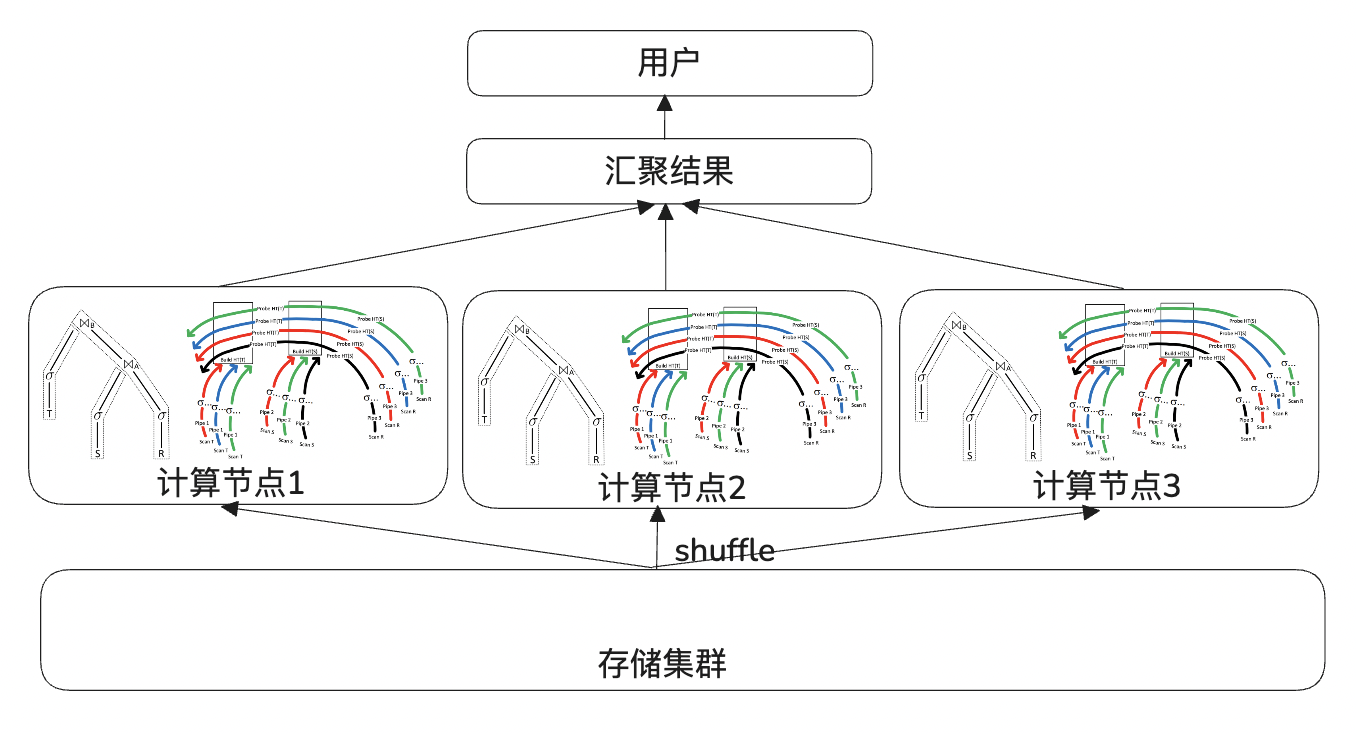
△MPP: 3臺計算節點并行計算
03?BaikalDB HTAP查詢架構落地
3.1 巧妙結合Arrow Acero實現向量化查詢引擎
BaikalDB團隊在向量化執行引擎設計過程中,秉持"避免重復造輪子"的技術理念,優先探索開源生態的優秀解決方案?。基于BaikalDB已采用Apache Arrow列式存儲格式實現全文索引的技術積淀?,團隊發現Arrow項目最新推出的Acero流式執行引擎子項目展現出三大核心功能:①支持Arrow列式存儲格式向量化計算,支持SIMD加速;②Push-Based流式執行框架支持Pipeline并行計算,能充分利用多核能力;③執行框架可擴展——這些特性與BaikalDB對向量化執行引擎的需求高度契合?。最終團隊選擇基于Arrow列存格式和Acero流式計算引擎實現BaikalDB向量化執行引擎,不僅大幅度縮短了研發周期,更充分發揮了開源技術生態的協同優勢?。
BaikalDB巧妙結合開源Apache Arrow列存格式和Arrow Acero向量化執行引擎,通過將火山模型計劃翻譯為Acero執行計劃,全程使用Arrow列存格式,計算最終列存結果再列轉行返回給用戶,在BaikalDB內部實現了適合大量數據計算的向量化查詢架構。
核心實現包括以下五點:
-
數據格式:將源頭RocksDB掃描出來的行存數據直接轉為Arrow列存格式,SQL計算全程使用Arrow列存,最終將列存格式的計算結果再轉換成行存輸出給用戶。
-
計算函數:將所有BaikalDB計算函數翻譯成Arrow Compute Expression,每個Arrow計算函數運行一次處理萬行數據,同時能支持部分如AVX2、SSE42等SIMD指令集,支持SIMD加速。
-
執行計劃:將每個SQL生成的BaikalDB原生執行計劃,轉換成一個Acero執行計劃Exec Plan(包含所有BaikalDB算子翻譯成的Acero ExecNode Declaration樹),使用Acero向量化執行引擎替換火山模型執行。
-
調度器:將進行數據掃描SourceNode的IO Executor和計算的CPU Executor獨立開。
-
每個Baikaldb和BaikalStore實例內置一個全局的Pthread CPU IO Executor池,支持計算階段的Push-based Pipeline并行計算,同時支持算子內并行計算,如Agg并發聚合、Join并發Build/Probe等。
-
每個SourceNode都獨自一個Bthread IO Executor,支持Hash Join或Union的各個子節點能并發查表。
-
-
RPC接口:Baikaldb和BaikalStore之間RPC使用Arrow列存格式替換行存pb格式進行數據傳輸,大幅度降低傳輸數據大小,同時去掉了pb序列化和反序列化的開銷,加速了數據傳輸效率。
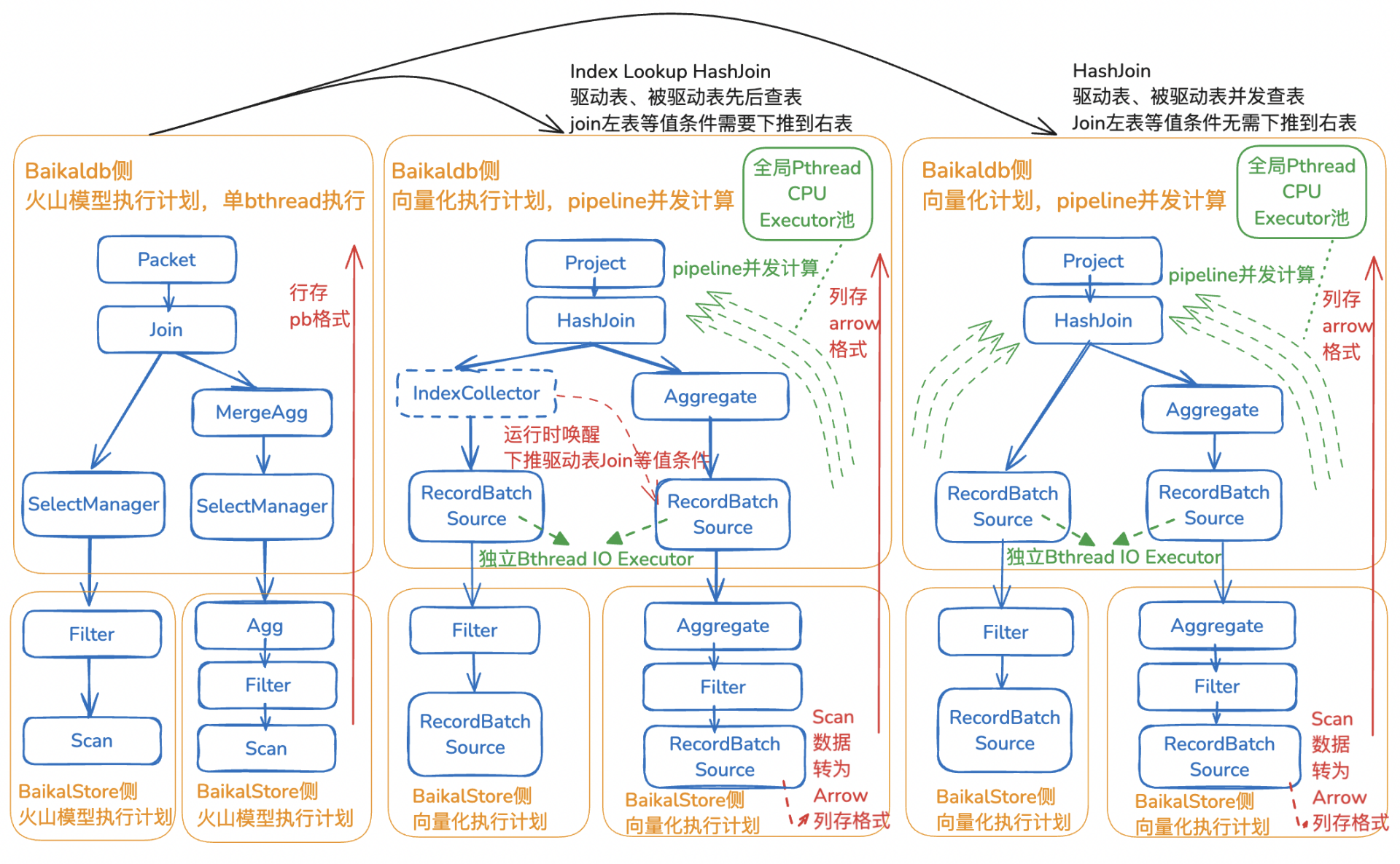
△BaikalDB火山模型(左) BaikalDB向量化引擎(中:Index Lookup HashJoin,右:HashJoin)
3.2 拆解執行計劃實現MPP多機并行查詢引擎
BaikalDB實現了向量化執行引擎后,大部分OLAP請求性能得到大幅度提升,但很快就遇到了受限于單計算節點資源和性能的case。團隊首先對業務場景進行了分析,發現資源/性能卡點主要在集中在最后單點Agg/Join的計算上。
為了破除這一單點限制,因Agg/Join都依賴內部HashTable進行計算,很容易想到按照HashKey將源數據hash shuffle到不同的計算節點進行并行計算來加速計算性能,平攤計算需要的內存和CPU資源,每個計算節點依然可以使用向量化執行引擎加速單機計算性能。如下圖所示,這一方案需要解決的核心問題有以下兩點:
-
實現Exchange算子對進行跨節點數據Shuffle。
-
在執行計劃合適的地方的插入Exchange算子對拆分為多個并行子計劃Fragment。
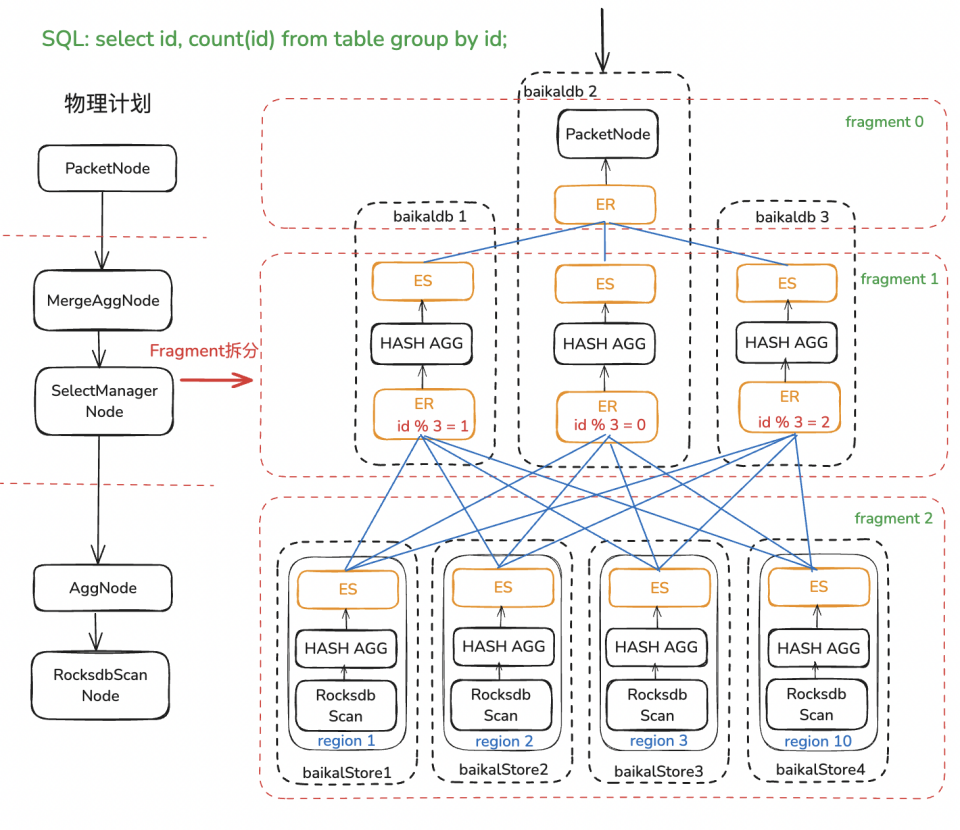
△BaikalDB Agg Mpp執行示例
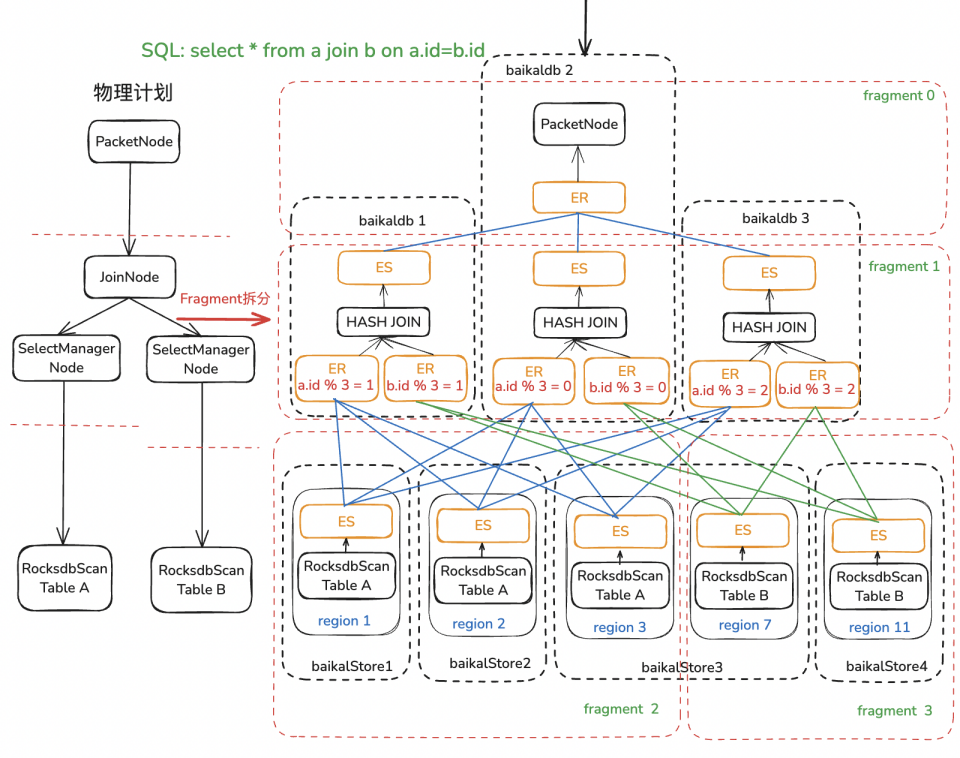
△BaikalDB Hash Join Mpp執行示例
3.2.1? Exchange算子跨節點數據shuffle
Exchange算子包括ExchangeSenderNode/ExchangeReceiverNode算子對,必須成對出現,進行跨節點數據分發和接收。ExchangeReceiverNode核心功能主要是接收對應的下游Fragment所有ExchangeSenderNode發來的數據,需保證不重不丟,進行超時處理等。ExchangeSenderNode核心功能是進行數據分發,其分發模式主要有以下三種,以支持不同的場景需求。
-
SinglePartition:一個或者多個ExchangeSenderNode將所有數據直接完整發送到單個上游Fragment ExchangeReciverNode實例,使用場景如Fragment 0單個計算節點收集最終結果輸出給用戶。
-
HashPartition:ExchangeSenderNode將所有數據都先根據指定HashKey計算每一行hash值,根據hash值將每行數據re-partition到不同的發送隊列里,最終發送到上游Fragment多個ExchangeReceiverNode,使用場景如Store Fragment將rocksdb掃描出來的數據shuffle到上游多個實例進行Agg/HashJoin計算。
-
BroadcastPartition:ExchangeSenderNode將所有數據都直接完整發送到多個上游ExchangeReciverNode,使用場景如Join小表數據直接完整發送到上游多個實例進行BroadcastJoin。
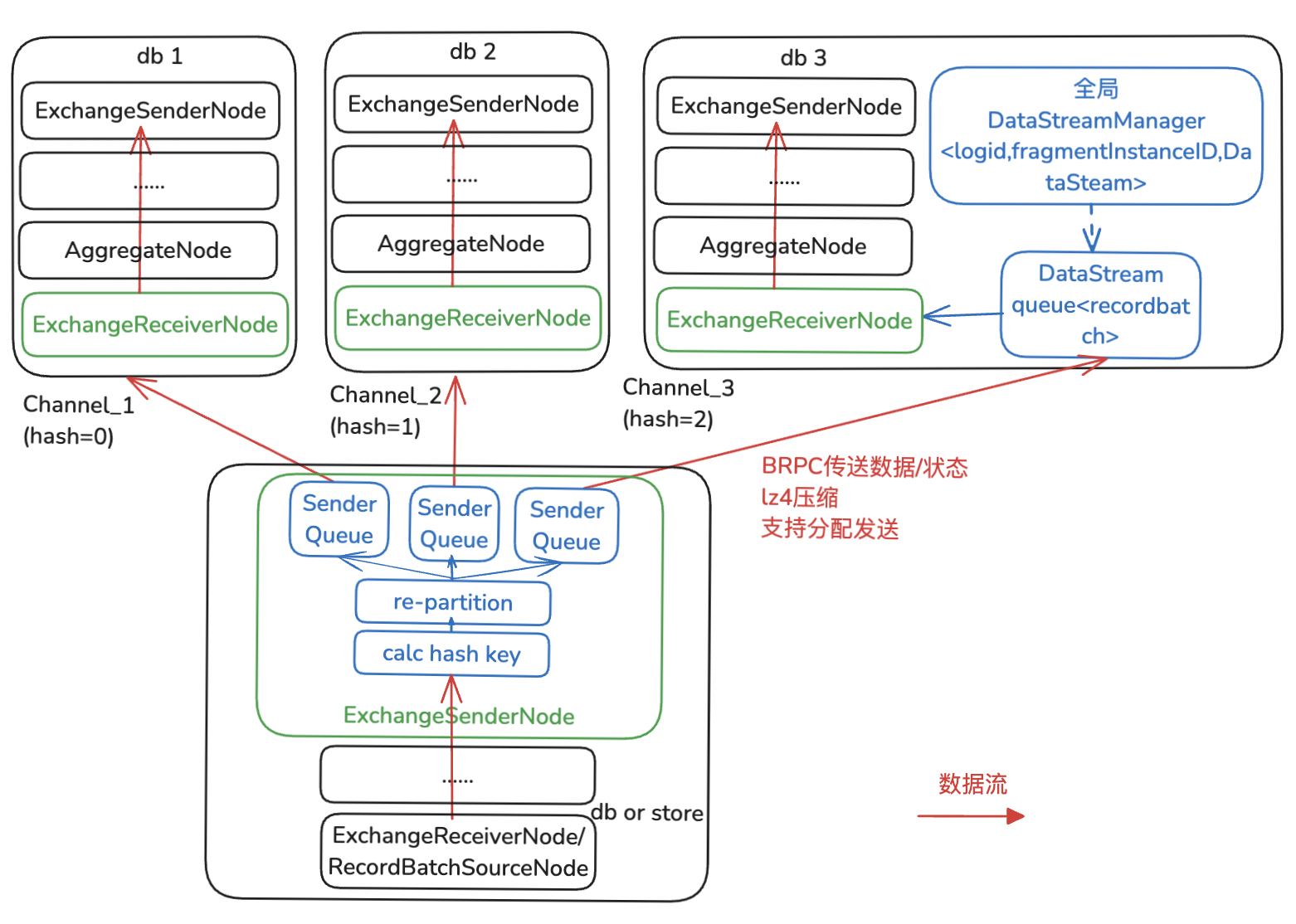
△BaikalDB Exchange算子實現(HashPartition)
3.2.2? 執行計劃拆解多個并行子計劃Fragment
在插入Exchange算子對之前,需要給物理執行計劃里的每個算子明確其分區屬性PartitionProperty,標志著該算子是否可以分發到多個計算節點進行并行加速。PartitionProperty主要有三種:
-
AnyParitition:該節點沒有任何要求,如FilterNode,可以根據相鄰節點分區屬性情況單節點或多節點執行。
-
SinglePartition:該節點必須要在單個計算節點上執行,如用于將最終數據打包發送給用戶的PacketNode。
-
HashPartition:該節點可以按照指定key將數據分發到多個計算節點上并行執行,當前只有AggNode和JoinNode會產生HashPartition。
如下圖所示,明確了每個算子的分區屬性后,需要加入Exchange算子對的位置就很清晰明了了:分區屬性有沖突的相鄰算子之間。
在物理計劃中插入了Exchange算子對后,在一對ExchangeSenderNode/ExchangeReceiverNode之間進行拆解,即可以將單個物理執行計劃拆分為多個子執行計劃Fragment。單機執行的Fragment在本機執行,多機執行的Fragment發送給多個同集群其他計算節點進行異步執行,store fragment根據表數據分布情況分發給BaikalStore存儲集群并行執行。
在MPP物理計劃制定過程中,為了減少數據shuffle的開銷,盡可能減少SQL shuffle數據量,BaikalDB也實現了多種查詢計劃優化手段,如limit下推、hash partition fragment合并等等。
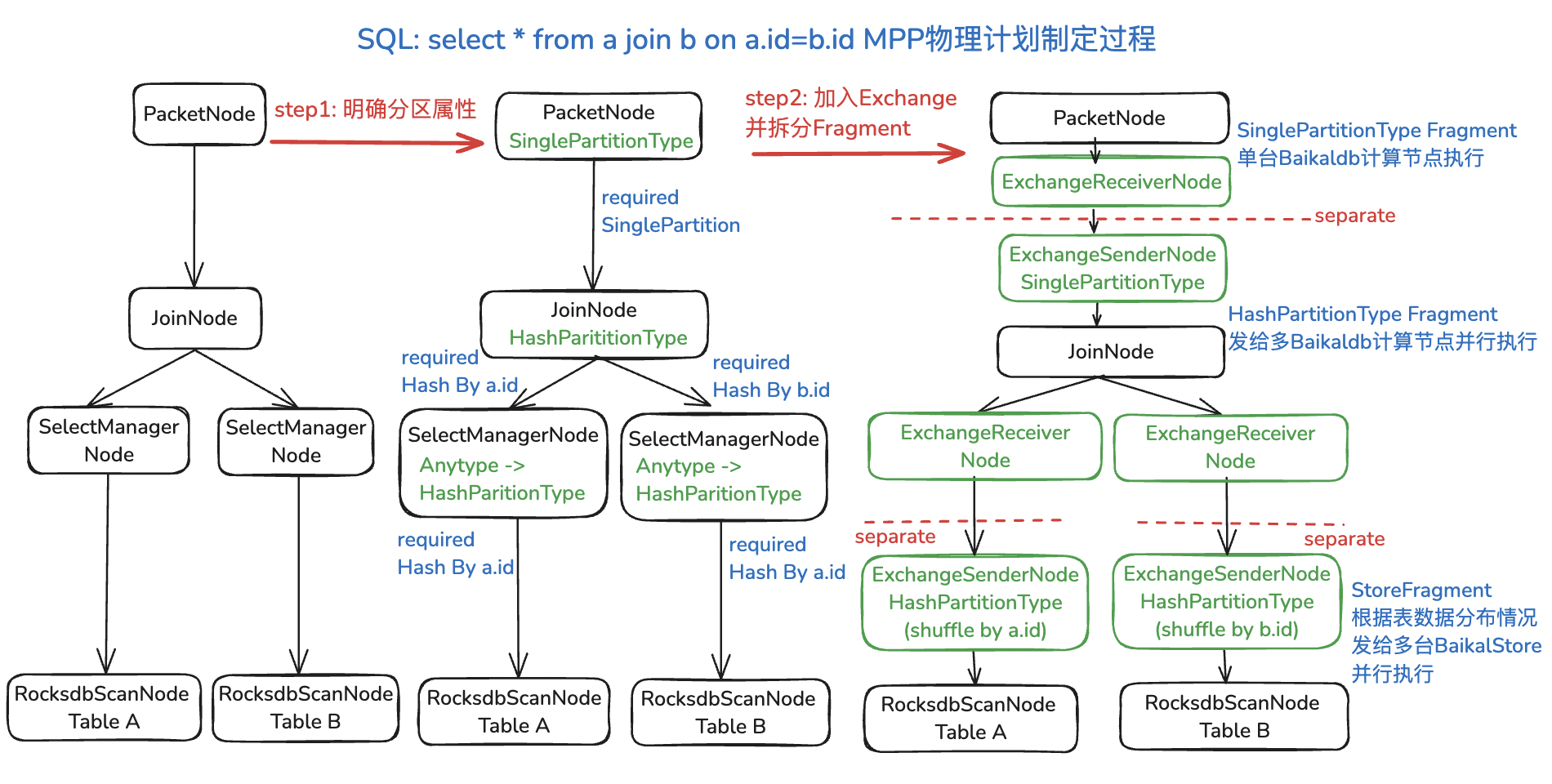
△MPP物理計劃制定過程
3.3? 自適應策略支持一套系統應對TP/AP請求
BaikalDB設計HTAP架構的核心目標是一套系統能同時兼容OLTP和OLAP請求,無需業務進行任何改造,這需要系統擁有極強的兼容性。
目前BaikalDB內部有三種執行方式:火山模型、單機向量化執行引擎、MPP多機執行引擎,不同的執行引擎適用不同數據量級的SQL。隨著數據量大小從小到大,適合的計算引擎是火山模型執行 → 單機向量化執行 → MPP多機并行執行,原因有以下兩點:
-
火山模型執行對比向量化執行更為輕量,導致在OLTP小請求(如SQL涉及數據行數<1024)方面,傳統火山模型性能比單機向量化執行性能更好。
-
MPP執行會帶來額外的網絡開銷(數據shuffle)、CPU開銷(hash計算和re-partition),導致Baikaldb處理數據量需要超過一定閾值時,Baikaldb多機并行執行才能cover額外的網絡/CPU開銷,SQL性能才能提升,否則單機向量化執行是性能最優。
BaikalDB實現了智能執行引擎決策系統,支持SQL自適應選擇合適的執行引擎,支持一套集群能同時滿足業務OLTP和OLAP場景需求。技術實現包含兩大核心機制:
-
向量化引擎動態熱切換:BaikalDB支持SQL在執行過程中,隨著數據量增大,從火山模型動態切換到向量化執行引擎執行。
-
統計信息驅動MPP加速:BaikalDB支持根據過去執行統計信息決策是否走MPP加速執行,當SQL統計的99分位處理數據行數/大小超過指定的閾值,則SQL直接通過MPP多機并行執行。
04? 總結
4.1 項目收益
BaikalDB通過架構創新打造了HTAP架構,期望一套系統支持線上OLTP/OLAP請求,其技術演進路徑呈現『混合執行引擎架構自適應選擇』的特征:SQL自適應選擇火山模型、向量化執行引擎、MPP多機并行執行引擎。
目前BaikalDB HTAP架構已經應用到線上多個業務,大數據量查詢取得大幅度的性能提升,同時Baikaldb單點內存使用峰值也得以大幅度下降:
-
單機向量化執行相對于火山模型執行,大數據量查詢請求耗時平均下降62%,最大能下降97%(如11s優化到300ms),內存使用峰值最大能降低56%(57G->25G)。
-
MPP在單機向量化執行基礎上,大數據量查詢耗時還能進一步優化,查詢耗時平均下降54%,最大能下降71%(如42s優化到12s),內存使用峰值最大能降低80%(5 hash partition)。
4.2 未來展望
BaikalDB HTAP架構目前還在不斷發展,包括性能優化、豐富支持算子和計算函數等等,未來還預期結合列式存儲、CBO等技術進一步提升OLAP場景性能:
-
結合列式存儲提升數據掃描性能:目前BaikalDB向量化查詢引擎和MPP查詢引擎全程基于Arrow列存格式,但是底層數據存儲仍然是行存,存在一次行轉列的開銷;并且OLAP場景,更適合使用列存格式作為底層數據存儲格式。BaikalDB當前在發展列存引擎,未來單機向量化和MPP能直接基于底層列式存儲,進一步提升OLAP場景查詢性能。
-
結合CBO(Cost-Based Optimization)優化自適應MPP選擇策略:當前BaikalDB是基于過去的執行統計信息判斷SQL是否適合走MPP,當SQL過去執行統計信息波動巨大時,自適應判斷方法可能會失效,未來可能結合代價模型來進一步優化MPP選擇策略。




)














