視頻擴散技術雖發展顯著,但多數駕駛數據集事故事件少,難以生成逼真車禍圖像,而提升交通安全又急需逼真可控的事故模擬。為此,論文提出可控車禍視頻生成模型 Ctrl-Crash,它以邊界框、碰撞類型、初始圖像幀等為條件,能生成反事實場景,輸入微小變動就可能引發截然不同的碰撞結果。


生成不同碰撞類型的場景
這些示例說明了針對多種不同碰撞類型(描述哪些參與者涉及碰撞)的場景:

事故重建
僅使用初始地面真實幀和所有邊界框幀作為輸入,通過 Ctrl-Crash 預測的碰撞:

碰撞預測
使用初始幀和前 9 個邊界框幀作為輸入,通過 Ctrl-Crash 預測崩潰(白色幀表示邊界框被遮罩):

從非崩潰數據生成崩潰
通過調節初始幀和前 9 個邊界框幀,從非事故 BDD100K 數據集生成碰撞:

相關鏈接
-
論文:https://arxiv.org/pdf/2506.00227
-
代碼:https://github.com/AnthonyGosselin/Ctrl-Crash
-
試用:https://huggingface.co/AnthonyGosselin/Ctrl-Crash
論文介紹

近年來,視頻擴散技術取得了顯著進展;然而,由于大多數駕駛數據集中事故事件的稀缺,它們難以生成逼真的車禍圖像。提高交通安全需要逼真且可控的事故模擬。
為了解決這個問題,論文提出了 Ctrl-Crash,這是一個可控的車禍視頻生成模型,它以邊界框、碰撞類型和初始圖像幀等信號為條件。提出的方法能夠生成反事實場景,其中輸入的微小變化都可能導致截然不同的碰撞結果。為了支持推理時的細粒度控制,作者利用無分類器引導,每個調節信號都有獨立可調的尺度。與之前基于擴散的方法相比,Ctrl-Crash 在定量視頻質量指標(例如 FVD 和 JEDi)和基于人工評估的物理真實感和視頻質量的定性測量方面均實現了最佳性能。
方法概述
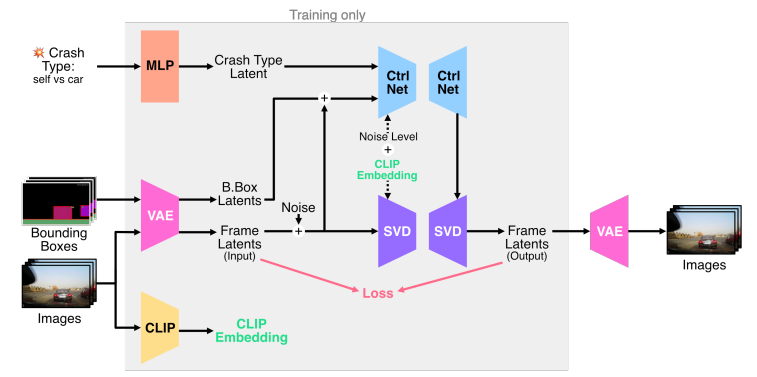
Ctrl-Crash 是一個可控的視頻擴散框架,旨在通過空間和語義控制信號的引導,從單個初始幀生成逼真的車禍場景。Ctrl-Crash 基于 Ctrl-V (一個用于從渲染的邊界框軌跡生成視頻的框架),將其功能擴展到特定于車禍的場景,從而提供更豐富的控制和更大的靈活性。具體而言,論文引入了一種新的語義控制信號來表示車禍類型,并引入了一種改進的訓練程序來處理部分和噪聲條件。
實驗結果

AVD2、DrivingGen、Ctrl-V 和 Ctrl-Crash 的定性結果比較。AVD2 生成的碰撞畫面視覺上抖動,場景通常缺乏一致性。Driving-Gen 生成的視頻質量低下且不連貫。雖然 Ctrl-V 實現了良好的視覺質量,但它無法生成逼真的碰撞事件。相比之下,Ctrl-Crash 在視覺保真度和場景一致性方面均優于所有基準,同時能夠準確地建模碰撞動力學。



結論
Ctrl-Crash是一個可控的視頻擴散框架,它能夠從單幀生成逼真的車禍場景,在基于擴散的方法中達到了最佳性能,并通過改變空間和語義控制輸入實現反事實推理。為了支持訓練和評估,還開發了從車禍視頻中提取邊界框的處理流程,并發布了 MM-AU、RussiaCrash 和 BDD100k 的精選注釋版本,以促進未來車禍模擬和生成式建模的研究。


)


二叉樹)








)

![[Java 基礎]Object 類](http://pic.xiahunao.cn/[Java 基礎]Object 類)
-Linux系統性指令)

)