一、前期準備
想要實現這些,首先就是要模擬出來一個大致的框架,方便后續開展,下面的就是隨便寫的一個框架,大家湊合看看就行,基本上是這個意思:
from tkinter import *w = Tk()
w.title("手語識別(簡易)")
w.geometry("805x640")l1 = Label(text='此窗口實時顯示\n攝像頭拍攝畫面', font=("微軟雅黑", 20),width=25,height=15,relief='groove', borderwidth=2)
l1.place(x=0, y=0)l2 = Label(text='此窗口實時顯示\n手部骨骼繪畫', font=("微軟雅黑", 20),width=25,height=15,relief='groove', borderwidth=2)
l2.place(x=400, y=0)l3 = Label(text='此窗口實時顯示手語識別結果', font=("微軟雅黑", 20),width=50,height=3,relief='groove', borderwidth=2)
l3.place(x=0, y=530)w.mainloop()運行效果大概也就這樣:
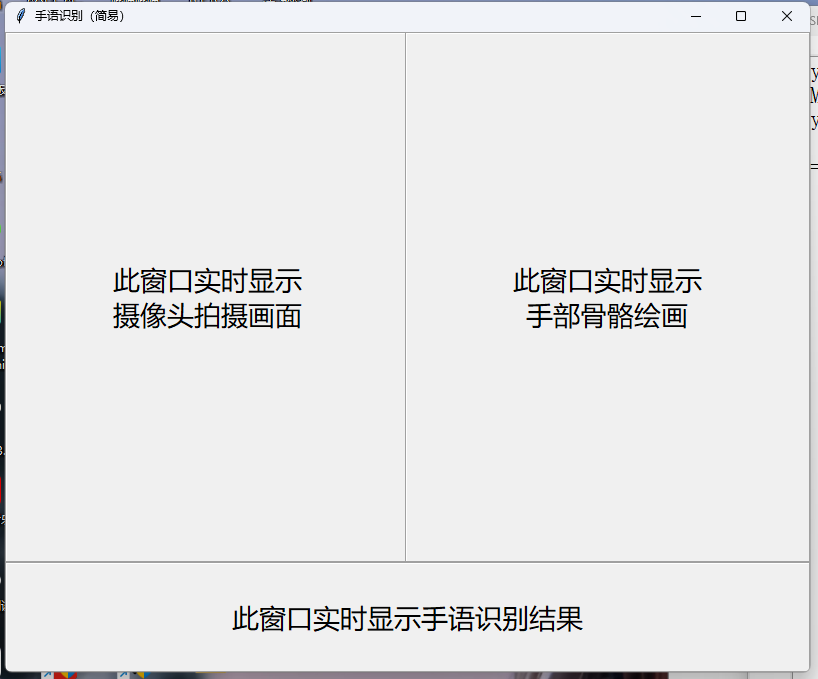
?解決了框架的問題之后,就要開始進一步的實現框架里面的內容了。
二、程序實現
1.相關庫
目前大多數的寫法基本上都是是用open-cv和PIL庫來實現,但是PIL庫容易暴雷,很抽象,實際開發中不建議使用PIL庫進行開發,這里就更推薦使用Pillow庫,因為因為原始PIL開發停滯,Pillow?是其友好分支,功能兼容且持續維護,安裝Pillow?即可替代PIL使用。
簡單說明一下open-cv和Pillow的相關用法
open-cv核心語法
1. 圖像讀取與顯示import cv2# 讀取圖像(返回 BGR 格式的 NumPy 數組)
img = cv2.imread("image.jpg") # 路徑支持中文,需用 UTF-8 編碼# 顯示圖像(需配合 cv2.waitKey() 使用)
cv2.imshow("Image Window", img)
cv2.waitKey(0) # 0 表示無限等待,按任意鍵關閉窗口
cv2.destroyAllWindows() # 銷毀所有窗口2. 圖像基本操作# 轉換為灰度圖
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)# 縮放圖像(插值方法可選:cv2.INTER_AREA 適合縮小,cv2.INTER_LINEAR 適合放大)
resized_img = cv2.resize(img, (640, 480), interpolation=cv2.INTER_LINEAR)# 旋轉圖像(繞中心旋轉 45 度,縮放因子 1.0)
(h, w) = img.shape[:2]
center = (w // 2, h // 2)
M = cv2.getRotationMatrix2D(center, 45, 1.0)
rotated_img = cv2.warpAffine(img, M, (w, h))3. 視頻處理(攝像頭實時流)# 打開攝像頭(參數 0 表示默認攝像頭,1 表示外接攝像頭)
cap = cv2.VideoCapture(0)while True:ret, frame = cap.read() # ret 為布爾值,表示是否讀取成功if not ret:break# 在視頻幀上繪制矩形cv2.rectangle(frame, (100, 100), (300, 300), (0, 255, 0), 2)# 顯示視頻幀cv2.imshow("Video Stream", frame)# 按 'q' 鍵退出循環if cv2.waitKey(1) & 0xFF == ord('q'):breakcap.release() # 釋放攝像頭資源
cv2.destroyAllWindows()4. 繪圖與標注# 在圖像上繪制文字
font = cv2.FONT_HERSHEY_SIMPLEX # 字體類型
cv2.putText(img, # 目標圖像"Hand Detected",# 文本內容(50, 50), # 文本位置坐標font, # 字體1.0, # 字體大小(0, 255, 0), # 顏色(BGR 格式)2, # 線條粗細cv2.LINE_AA # 抗鋸齒
)# 繪制圓形
cv2.circle(img, (200, 200), 50, (255, 0, 0), -1) # -1 表示填充圓形Pillow核心語法
1. 圖像讀取與保存from PIL import Image# 讀取圖像(返回 Image 對象)
img = Image.open("image.png")# 保存圖像(自動根據擴展名判斷格式,支持格式轉換)
img.save("output.jpg") # 從 PNG 轉為 JPEG
img.save("output.png", quality=95) # 保存為 PNG,設置質量(對支持的格式有效)2. 圖像尺寸與模式操作# 獲取圖像尺寸(寬度, 高度)
width, height = img.size# 轉換圖像模式(如灰度圖、RGB 圖)
gray_img = img.convert("L") # "L" 表示灰度模式
rgb_img = img.convert("RGB") # 確保為 RGB 模式(某些操作需要)3. 圖像編輯操作# 縮放圖像(使用高質量抗鋸齒)
resized_img = img.resize((200, 200), Image.Resampling.LANCZOS)# 裁剪圖像(左上角坐標 (x1,y1),右下角坐標 (x2,y2))
cropped_img = img.crop((50, 50, 250, 250))# 水平翻轉圖像
flipped_img = img.transpose(Image.FLIP_LEFT_RIGHT)4. 像素級操作與繪圖# 獲取像素值(坐標 (x,y),返回 RGB 元組)
pixel_color = img.getpixel((100, 100))# 修改像素值(將 (200,200) 坐標設為紅色)
img.putpixel((200, 200), (255, 0, 0)) # RGB 格式# 使用 ImageDraw 繪制圖形
from PIL import ImageDrawdraw = ImageDraw.Draw(img)
draw.rectangle([(10, 10), (100, 100)], outline=(0, 255, 0), width=2) # 繪制矩形
draw.ellipse([(150, 150), (250, 250)], fill=(255, 0, 0)) # 繪制填充橢圓5. 批量圖像處理import os
from PIL import Imageinput_folder = "images/"
output_folder = "processed/"# 創建輸出文件夾(若不存在)
os.makedirs(output_folder, exist_ok=True)for filename in os.listdir(input_folder):if filename.endswith((".jpg", ".png")):file_path = os.path.join(input_folder, filename)with Image.open(file_path) as img:# 統一縮放為 500x500 像素resized = img.resize((500, 500), Image.Resampling.BILINEAR)# 轉換為灰度圖gray = resized.convert("L")# 保存到輸出文件夾gray.save(os.path.join(output_folder, filename))他們倆的關鍵語法對比
| 功能 | OpenCV(Python) | Pillow(PIL) |
|---|---|---|
| 讀取圖像 | cv2.imread("path") | Image.open("path") |
| 顯示圖像 | cv2.imshow("window", img); cv2.waitKey(0) | 需要結合 Tkinter/Qt 等 GUI 庫顯示 |
| 圖像格式轉換 | cv2.cvtColor(img, cv2.COLOR_BGR2RGB) | img.convert("RGB") |
| 縮放圖像 | cv2.resize(img, (w,h), interpolation=...) | img.resize((w,h), Image.Resampling.LANCZOS) |
| 繪制文字 | cv2.putText(img, text, (x,y), font, ...) | ImageDraw.Draw(img).text((x,y), text, fill=...) |
| 獲取圖像尺寸 | h, w = img.shape[:2] | width, height = img.size |
?ps:上述不是很全面,僅作參考
好啦,回到正題,該逐步實現調用過程啦!
?2.攝像頭調用的具體代碼實現
下面的我自己的代碼,先發出來給大伙瞅瞅,稍后詳細解釋代碼
?
import cv2
import tkinter as tk
from PIL import Image, ImageTkdef update_camera():ret, frame = cap.read()if ret:# 水平鏡像翻轉畫面(參數1表示水平翻轉)frame_flipped = cv2.flip(frame, 1)# 攝像頭畫面顯示在l1(添加鏡像)frame_rgb = cv2.cvtColor(frame_flipped, cv2.COLOR_BGR2RGB)frame_resized = cv2.resize(frame_rgb, (400, 400))img = Image.fromarray(frame_resized)imgtk = ImageTk.PhotoImage(image=img)l1.imgtk = imgtkl1.configure(image=imgtk)# 手部骨骼繪制顯示在l2(預留位置)# 識別結果顯示在l3(預留位置)w.after(10, update_camera)# 初始化攝像頭
cap = cv2.VideoCapture(0)# 創建窗口
w = tk.Tk()
w.title("手語識別(簡易)")
w.geometry("805x640")# Label用于攝像頭畫面(鏡像顯示)
l1 = tk.Label(text='攝像頭加載中...', font=("微軟雅黑", 20), width=25, height=15, relief='groove', borderwidth=2)
l1.place(x=0, y=0)# Label用于手部骨骼繪制(預留)
l2 = tk.Label(text='此窗口實時顯示\n手部骨骼繪畫', font=("微軟雅黑", 20), width=25, height=15, relief='groove', borderwidth=2)
l2.place(x=400, y=0)# Label用于識別結果(預留)
l3 = tk.Label(text='此窗口實時顯示手語識別結果', font=("微軟雅黑", 20), width=50, height=3, relief='groove', borderwidth=2)
l3.place(x=0, y=530)# 啟動攝像頭更新
update_camera()w.mainloop()
cap.release()好啦,現在來一步一步的理解上面的代碼:
1. 導入依賴庫
import cv2 # 計算機視覺庫,用于攝像頭控制和圖像處理
import tkinter as tk # GUI 庫,用于創建窗口和界面元素
from PIL import Image, ImageTk # 圖像處理庫,用于圖像格式轉換以適配 Tkinter
欸?為什么導入tkinter要用tk,直接*不更好嘛?我一開始也是這樣想的,但是這里就有一個很致命的錯誤,因此我在導入這個地方卡了很久很久……
為啥捏??在 Python 中,from tkinter import *?和?import tkinter as tk?是兩種不同的導入方式,前者的*代表了全部導入,這就代表Python 會將?tkinter?模塊中的?所有公有名稱(如?Tk、Label、Button?等)直接導入到當前命名空間。這意味著:
- 無需通過模塊名前綴(如?
tk.)即可直接使用這些名稱。 - 如果當前命名空間中已有同名對象(如自定義的?
Button?函數),會發生?名稱沖突,導致程序報錯或邏輯混亂。
?如果我直接使用的話,就會一直報錯,恰好大伙們還不知道這個小知識點的話,就很難發現自己錯在啥地方!!!!如果真不小心了咋辦?就會出現下面的問題:
- 覆蓋內置函數或變量:
例如,若代碼中定義了?Tk = "my_string",則?from tkinter import *?會嘗試將?tkinter.Tk(窗口類)導入為?Tk,導致?Tk?被重新賦值為字符串,引發錯誤。 - 難以追蹤來源:
當代碼中出現?Button?時,無法直接判斷它是?tkinter.Button?還是其他模塊 / 自定義的?Button,增加調試難度。 - 破壞代碼可讀性:
對于大型項目,未加前綴的名稱會讓讀者難以快速識別其所屬模塊,尤其是在多個模塊被?import *?的情況下。
所以這是一個很抽象的錯誤,也是一個很小的知識點,一般來說,我們在系統性學習python的時候,是直接學的第二種方法,第一種老師也會講,但是不會細講,因為考試也不考,我們平時也接觸不到這些比較難的庫,所以這個方面的小知識點就很容易被忽略。?
至于為啥第二種好,老師也不會說,同樣考試也不考,我就來簡要的說一下,過兩天我整理一下,跟這篇一起發出來:
1. 避免命名污染,確保名稱唯一性
-
隔離命名空間:
將 Tkinter 的所有名稱(如?Tk、Label)封裝在?tk?模塊內,避免與當前代碼中的自定義變量、函數或其他庫(如?custom_widgets)的同名對象沖突。
示例:若代碼中已有?Button?函數,tk.Button?仍指向 Tkinter 的按鈕類,不會被覆蓋。 -
明確歸屬:
所有 Tkinter 對象均以?tk.?為前綴(如?tk.Entry),清晰標識其來源,避免混淆。
2. 提升代碼可讀性和可維護性
-
快速定位來源:
看到?tk.Canvas?即可明確其為 Tkinter 的畫布類,無需查閱導入語句或猜測名稱來源。
對比:from tkinter import *?中?Canvas?的歸屬不明確,可能來自其他模塊。 -
協作友好:
在團隊項目中,前綴可幫助其他開發者快速識別框架組件,降低理解成本。
3. 減少內存占用與啟動開銷
- 按需加載:
僅導入?tkinter?模塊本身,而非其所有成員。對于大型模塊,可減少初始加載時的內存占用和啟動時間。
原理:import *?會一次性導入模塊內所有公有對象,而?import as?僅創建模塊引用。
4. 兼容大型項目與復雜場景
-
多庫共存:
當同時使用 Tkinter 和其他 GUI 庫(如 PyQt、wxPython)時,前綴可避免跨庫名稱沖突。import tkinter as tk # Tkinter 組件前綴為 tk. from PyQt5 import QtCore # PyQt 組件前綴為 QtCore. -
模塊化開發:
便于將 Tkinter 相關代碼封裝在獨立模塊中,通過?tk.?前綴明確接口邊界,提升代碼組織性。
5. 符合 Python 最佳實踐(PEP 8 規范)
- 官方推薦:
PEP 8 明確建議避免使用?from module import *,除非是交互式環境或極小型腳本。- 理由:命名空間污染可能導致隱性錯誤,且違反 “明確優于隱含” 的 Python 哲學。
2. 核心函數:攝像頭畫面更新
def update_camera():ret, frame = cap.read() # 讀取攝像頭一幀畫面if ret: # ret 為 True 表示讀取成功# 水平鏡像翻轉畫面(參數1表示水平翻轉,0為垂直翻轉,-1為水平+垂直翻轉)frame_flipped = cv2.flip(frame, 1)# ---------------------- 顯示原始鏡像畫面到 l1 ----------------------# OpenCV 默認顏色格式為 BGR,需轉為 RGB 以正確顯示frame_rgb = cv2.cvtColor(frame_flipped, cv2.COLOR_BGR2RGB)# 縮放畫面至 400x400 像素(適配窗口大小)frame_resized = cv2.resize(frame_rgb, (400, 400))# 將 OpenCV 的 NumPy 數組轉為 PIL 圖像對象img = Image.fromarray(frame_resized)# 將 PIL 圖像轉為 Tkinter 可用的 PhotoImage 對象imgtk = ImageTk.PhotoImage(image=img)# 將圖像綁定到 l1 標簽,并更新顯示l1.imgtk = imgtk # 保留引用避免被垃圾回收l1.configure(image=imgtk)# 遞歸調用自身,每 10ms 更新一次畫面(實現實時效果)w.after(10, update_camera)
關鍵細節:
- 鏡像翻轉:
cv2.flip(frame, 1)?使畫面左右對稱,符合人類視覺習慣。 - 顏色轉換:OpenCV 的?
cv2.cvtColor?將 BGR 轉為 RGB,否則畫面顏色會錯亂。 - 圖像格式轉換鏈:
這是在 Tkinter 中顯示 OpenCV 畫面的標準流程。OpenCV數組(BGR) → cvtColor → RGB數組 → PIL.Image → ImageTk.PhotoImage → Tkinter顯示
3. 初始化攝像頭
cap = cv2.VideoCapture(0) # 0 表示打開默認攝像頭(筆記本內置或外接攝像頭)
cv2.VideoCapture(n)?中?n?為攝像頭設備編號,0?通常為默認攝像頭,1?為外接攝像頭。- 若攝像頭無法打開,
cap.read()?會返回?ret=False,畫面停止更新。
4. 啟動程序主循環和資源釋放
update_camera() # 調用函數啟動攝像頭畫面更新
w.mainloop() # Tkinter 主循環,保持窗口顯示
cap.release() # 釋放攝像頭資源,避免硬件占用
w.mainloop()?是 GUI 程序的入口,用于處理用戶交互(如關閉窗口)。cap.release()?必須在主循環結束后調用,否則可能導致攝像頭無法正常關閉。
3.手部骨骼實現?
想要實現手部骨骼,就得來到另一個庫了----MediaPipe庫,MediaPipe 是?Google 開發的開源跨平臺機器學習框架,專注于實時多媒體處理和計算機視覺任務,提供預訓練模型和模塊化工具,可快速開發手勢識別、人臉識別等 AI 應用。
核心特點
- 多模態感知能力
- 支持手部追蹤(21 個關鍵點)、人臉檢測(468 個關鍵點)、人體姿態估計(33 個關鍵點)、物體檢測與追蹤等。
- 跨平臺與多語言
- 支持 Python、C++、Java、JavaScript 等語言,覆蓋桌面、移動(Android/iOS)、邊緣設備(如樹莓派)。
- 模塊化與實時性
- 通過 “計算器圖” 靈活組合組件,優化后可在移動端實現?30+ FPS?實時處理。
- 開箱即用與輕量級
- 提供預訓練模型,無需復雜訓練;支持 TensorFlow Lite,適合資源受限設備。
但是呢,也不是使用pip安裝完就能直接使用的,雖然庫內有一個輕型的模型庫,但是我不知道為啥,我就一直報錯,很煩,很抽象,弄了很久,用內部API的時候,雖然成功了,但是更抽象了,就是簡單了將手部輪廓標出來了而以,還不只,連背景的輪廓都標出來了,很難看,建議大伙在用這個庫的時候,老老實實去官網下載模型文件再導入使用,也不要去github找,上面是?MediaPipe 框架的?模型配置文件(定義模型結構、輸入輸出等),并非直接可用的 “預訓練權重文件”。很好分辨,.pbtxt?文件就是,下載模型文件呢就去官方模型倉庫,鏈接:【https://storage.googleapis.com/mediapipe-models/】,要想正常訪建議使用chrome瀏覽器,并且使用快捷鍵【shift+ctrl+n】開啟無痕瀏覽后再嘗試訪問,我也不知為什么,直接訪問就返回【MissingSecurityHeader: Your request was missing a required header. Authorization】,百度了一下才知道原來遇到的錯誤?MissingSecurityHeader: Your request was missing a required header. Authorization?表示請求中缺少必要的?Authorization?認證頭,這通常出現在需要身份驗證的接口調用、云服務訪問或權限控制場景中。說白了就是嘗試訪問的 Google Cloud Storage 鏈接(如?storage.googleapis.com)屬于需要身份驗證的谷歌云資源。當直接通過瀏覽器或工具下載文件時,谷歌可能要求提供?API 密鑰、OAuth 令牌?等認證信息,否則拒絕請求。說人話就是沒有授權,不給你訪問網站。
為了大伙,我直接給下載鏈接放下面,有需要的自行下載即可
https://storage.googleapis.com/mediapipe-models/hand_landmarker/hand_landmarker/float16/1/hand_landmarker.task
?至于為啥是float16,而不是32,因為float16:表示模型參數的數值精度(平衡模型大小和計算效率),也有?float32?版本(精度更高但體積稍大),一般場景選?float16?即可。咱這小破筆記本真心帶不動32版本的。
好啦,下載完成之后,就要開始下一步了,因為我是用的pycharm寫的,直接用的虛擬環境,存放位置是有一定要求的,以python為例:
Python 項目(純代碼調用)
your_project/
├── models/ # 專門放模型文件
│ └── hand_landmarker.task
└── main.py # 主代碼?正常來說是有一個依賴文件的,例如requirements.txt文件,不是很有必要,所以可有可不的
歐克,解決完上述的所有問題之后,就可以開始?實現手部骨骼啦!
import cv2
import tkinter as tk
from PIL import Image, ImageTk
import mediapipe as mp
from mediapipe.tasks import python
from mediapipe.tasks.python import vision
import os# 模型路徑
MODEL_PATH = os.path.join("models", "hand_landmarker.task")
if not os.path.exists(MODEL_PATH):raise FileNotFoundError(f"模型文件未找到: {MODEL_PATH}")# 初始化手部檢測器
base_options = python.BaseOptions(model_asset_path=MODEL_PATH)
options = vision.HandLandmarkerOptions(base_options=base_options,num_hands=2,min_hand_detection_confidence=0.3,min_hand_presence_confidence=0.3,min_tracking_confidence=0.3
)
detector = vision.HandLandmarker.create_from_options(options)def draw_hand_skeleton(frame):original_height, original_width = frame.shape[:2]mp_image = mp.Image(image_format=mp.ImageFormat.SRGB,data=cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))results = detector.detect(mp_image)if results.hand_landmarks: # 確保檢測到手部for hand_landmarks_list in results.hand_landmarks: # 遍歷每只手的關鍵點列表(外層列表)for landmark in hand_landmarks_list: # 遍歷單只手的關鍵點(內層列表)x = int(landmark.x * original_width)y = int(landmark.y * original_height)cv2.circle(frame, (x, y), 5, (255, 0, 0), -1)# 繪制骨骼連線(根據關鍵點列表索引)for connection in mp.solutions.hands.HAND_CONNECTIONS:start_idx, end_idx = connectionstart_landmark = hand_landmarks_list[start_idx]end_landmark = hand_landmarks_list[end_idx]start_x = int(start_landmark.x * original_width)start_y = int(start_landmark.y * original_height)end_x = int(end_landmark.x * original_width)end_y = int(end_landmark.y * original_height)cv2.line(frame, (start_x, start_y), (end_x, end_y), (0, 255, 0), 2)return framedef update_camera():ret, frame = cap.read()if ret:frame_flipped = cv2.flip(frame, 1)frame_original = frame_flipped.copy()skeleton_frame = draw_hand_skeleton(frame_original)# 縮放并顯示畫面frame_resized = cv2.resize(frame_flipped, (400, 400))skeleton_resized = cv2.resize(skeleton_frame, (400, 400))l1_img = Image.fromarray(cv2.cvtColor(frame_resized, cv2.COLOR_BGR2RGB))l1.imgtk = ImageTk.PhotoImage(l1_img)l1.configure(image=l1.imgtk)l2_img = Image.fromarray(cv2.cvtColor(skeleton_resized, cv2.COLOR_BGR2RGB))l2.imgtk = ImageTk.PhotoImage(l2_img)l2.configure(image=l2.imgtk)w.after(10, update_camera)# 初始化攝像頭
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 640)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 480)# 創建窗口
w = tk.Tk()
w.title("手語識別(簡易)")
w.geometry("805x640")l1 = tk.Label(w, width=400, height=400, bg="black")
l1.place(x=0, y=0)l2 = tk.Label(w, width=400, height=400, bg="black")
l2.place(x=400, y=0)l3 = tk.Label(w,text='手部骨骼檢測已就緒,請將手放入畫面中...',font=("微軟雅黑", 12),bg="#f0f0f0",width=60,height=2
)
l3.place(x=10, y=530)update_camera()
w.mainloop()# 釋放資源
cap.release()
detector.close()
cv2.destroyAllWindows()也是直接將把整個代碼直接發出來嗷,下面再詳細分析代碼:
?
代碼整體功能概述
這段代碼實現了一個基于 MediaPipe 的手部骨骼實時檢測與可視化應用。程序通過攝像頭捕獲視頻流,使用 MediaPipe 的手部關鍵點檢測模型識別手部位置和姿態,然后在圖像上繪制關鍵點和連接線,最后通過 Tkinter 界面展示原始畫面和處理后的骨骼畫面。主要功能模塊包括:模型初始化、圖像骨骼繪制、攝像頭畫面更新和 GUI 界面展示。
詳細模塊分析
1. 依賴庫導入與模型初始化
import cv2
import tkinter as tk
from PIL import Image, ImageTk
import mediapipe as mp
from mediapipe.tasks import python
from mediapipe.tasks.python import vision
import os# 模型路徑配置
MODEL_PATH = os.path.join("models", "hand_landmarker.task")
if not os.path.exists(MODEL_PATH):raise FileNotFoundError(f"模型文件未找到: {MODEL_PATH}")# 初始化手部檢測器
base_options = python.BaseOptions(model_asset_path=MODEL_PATH)
options = vision.HandLandmarkerOptions(base_options=base_options,num_hands=2,min_hand_detection_confidence=0.3,min_hand_presence_confidence=0.3,min_tracking_confidence=0.3
)
detector = vision.HandLandmarker.create_from_options(options)
關鍵點:
- 依賴庫:
cv2:處理視頻流和圖像繪制tkinter:創建 GUI 界面PIL:圖像格式轉換mediapipe:提供手部檢測模型
- 模型配置:
num_hands=2:最多檢測兩只手min_detection_confidence=0.3:檢測置信度閾值min_tracking_confidence=0.3:跟蹤置信度閾值
2. 手部骨骼繪制函數
def draw_hand_skeleton(frame):original_height, original_width = frame.shape[:2]mp_image = mp.Image(image_format=mp.ImageFormat.SRGB,data=cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))results = detector.detect(mp_image)if results.hand_landmarks:for hand_landmarks_list in results.hand_landmarks:# 繪制關鍵點(藍色圓點)for landmark in hand_landmarks_list:x = int(landmark.x * original_width)y = int(landmark.y * original_height)cv2.circle(frame, (x, y), 5, (255, 0, 0), -1)# 繪制骨骼連接線(綠色線條)for connection in mp.solutions.hands.HAND_CONNECTIONS:start_idx, end_idx = connectionstart_landmark = hand_landmarks_list[start_idx]end_landmark = hand_landmarks_list[end_idx]start_x = int(start_landmark.x * original_width)start_y = int(start_landmark.y * original_height)end_x = int(end_landmark.x * original_width)end_y = int(end_landmark.y * original_height)cv2.line(frame, (start_x, start_y), (end_x, end_y), (0, 255, 0), 2)return frame
關鍵點:
- 圖像預處理:
- 將 OpenCV 的 BGR 格式轉換為 MediaPipe 需要的 RGB 格式
- 創建?
mp.Image?對象用于模型輸入
- 骨骼繪制邏輯:
- 關鍵點:每個手部 21 個關鍵點,用藍色圓點標記
- 連接線:使用?
mp.solutions.hands.HAND_CONNECTIONS?定義的連接關系,用綠色線條連接關鍵點 - 坐標轉換:將歸一化坐標(0-1 范圍)轉換為圖像像素坐標
3. 攝像頭畫面更新函數
def update_camera():ret, frame = cap.read()if ret:frame_flipped = cv2.flip(frame, 1) # 水平翻轉(鏡像效果)frame_original = frame_flipped.copy()# 檢測并繪制手部骨骼skeleton_frame = draw_hand_skeleton(frame_original)# 縮放并顯示畫面frame_resized = cv2.resize(frame_flipped, (400, 400))skeleton_resized = cv2.resize(skeleton_frame, (400, 400))# 轉換為Tkinter可用格式l1_img = Image.fromarray(cv2.cvtColor(frame_resized, cv2.COLOR_BGR2RGB))l1.imgtk = ImageTk.PhotoImage(l1_img)l1.configure(image=l1.imgtk)l2_img = Image.fromarray(cv2.cvtColor(skeleton_resized, cv2.COLOR_BGR2RGB))l2.imgtk = ImageTk.PhotoImage(l2_img)l2.configure(image=l2.imgtk)# 每10ms調用一次自身,實現實時更新w.after(10, update_camera)
關鍵點:
- 鏡像效果:
cv2.flip(frame, 1)?使畫面更符合用戶習慣 - 雙窗口顯示:
- 左側窗口(l1):顯示原始攝像頭畫面
- 右側窗口(l2):顯示繪制了骨骼的畫面
- 圖像格式轉換:
OpenCV數組(BGR) → cvtColor → RGB數組 → PIL.Image → ImageTk.PhotoImage → Tkinter顯示 - 定時更新:
w.after(10, update_camera)?實現約 100FPS 的更新頻率
4. GUI 界面初始化
# 初始化攝像頭
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 640)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 480)# 創建窗口
w = tk.Tk()
w.title("手語識別(簡易)")
w.geometry("805x640")# 創建三個標簽分別用于顯示原始畫面、骨骼畫面和提示文本
l1 = tk.Label(w, width=400, height=400, bg="black")
l1.place(x=0, y=0)l2 = tk.Label(w, width=400, height=400, bg="black")
l2.place(x=400, y=0)l3 = tk.Label(w,text='手部骨骼檢測已就緒,請將手放入畫面中...',font=("微軟雅黑", 12),bg="#f0f0f0",width=60,height=2
)
l3.place(x=10, y=530)# 啟動更新循環并進入主事件循環
update_camera()
w.mainloop()# 釋放資源
cap.release()
detector.close()
cv2.destroyAllWindows()
關鍵點:
- 窗口布局:
- 左右并列兩個 400x400 的窗口
- 底部一個提示文本區域
- 資源管理:
- 使用?
cap.release()?釋放攝像頭資源 - 使用?
detector.close()?關閉模型 - 使用?
cv2.destroyAllWindows()?關閉所有 OpenCV 窗口
- 使用?
ok啦,寫到這里只能算半成品,因為還有模型訓練等等非常麻煩的事情,先寫到這里吧~















,結構體鏈表實現(獨創源碼))


 ----- Python的類與對象)
