MCP中的Context
- 1. Context
- 2. 日志輸出
- 2.1 服務端
- 2.2 客戶端
- 2.2.1 客戶端代碼調試
- 2.2.2 客戶端全部代碼
- 3. 進度匯報
- 3.1 服務端
- 3.2 客戶端
- 3.2.1 客戶端代碼調試
- 3.2.2 客戶端全部代碼
- 4. 模型調用
- 4.1 服務端
- 4.2 客戶端
- 4.2.1 客戶端代碼調試
- 4.2.2 客戶端全部代碼
1. Context
Context對象給MCP Server提供了更多獲取客戶端信息、以及和客戶端進行交互的接口。通過Context對象,能夠獲取到以以下對象:
- 當前請求的id:
request_id - 客戶端id:
client_id - 服務端的
session對象
能夠在單次請求中額外發送以下數據給客戶端:
- 日志輸出:可以發送服務端的日志給客戶端
- 進度匯報:在處理一些耗時操作時,可以在處理過程中發送處理進度給客戶端
- 模型調用:當服務端需要客戶端的大模型能力時,可以調用客戶端的大模型能力
通過Context,可以實現更加復雜的需求。但是注意,Context對象只能在Tool中使用,不能在 Resource 和Prompt 中使用。使用方式也非常簡單,只需要在函數上添加一個 Context 類型的參數即可。
項目文件架構:新建一個Context_mcp文件夾,下面再分別創建三個子文件夾為Log_output、Load_report和Model_call。然后再三個子文件夾中都分別創建兩個py文件,命名為server.py和client.py
2. 日志輸出
如果服務端代碼在執行過程中想要將執行過程的日志發送給客戶端,那么借助 Context 非常方便的實現。
2.1 服務端
在Log_output文件夾下的server.py文件中,添加 Context 信息,添加的方式是接著tool工具,然后再函數中添加 Context 參數,參數的具體名稱不限制,往往采用ctx或者content進行命名.
比如定義日志輸出的函數為log_tool,參數分別為兩個:files和ctx。前者是指定文件列表,用于存放文件路徑的容器,第二個就是Context對應的參數。
"""
-------------------------------------------------------------------------------
@Project : MCP projects
File : client.py
Time : 2025-06-05 17:20
author : musen
Email : xianl828@163.com
-------------------------------------------------------------------------------
"""
from mcp.server.fastmcp import FastMCP,Context# app = FastMCP
mcp: FastMCP = FastMCP()#兩種書寫方式,都可以
# @app.tool()
@mcp.tool()
async def log_tool(files:list[str],ctx:Context):'''處理文件的接口:param files: 文件列表:param ctx: 上下文對象,無需客戶端傳遞:return: 處理結果'''for index,file in enumerate(files):await asyncio.sleep(1)# ctx.log()await ctx.info(f"正在處理第{index+1}個文件")return "所有文件處理完成"if __name__ == '__main__':mcp.run(transport='sse')
服務端的代碼中,通過log函數進行信息的傳遞,其屬于最基礎的操作,點擊函數進入技術文檔可以知道如果使用log進行消息傳遞,需要指定level和message兩個重要參數,其中level包含具體的信息類型。
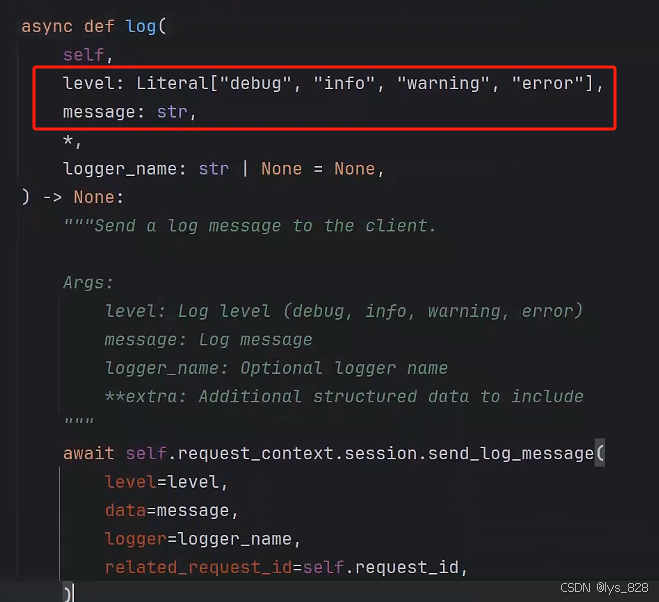
通過往下滑, 可以發現文檔中已經有關于會話信息操作的封裝函數,如下(剛好對應上面level參數中指定的4類,比如這里服務端的代碼使用ctx.info()函數進行消息傳遞)
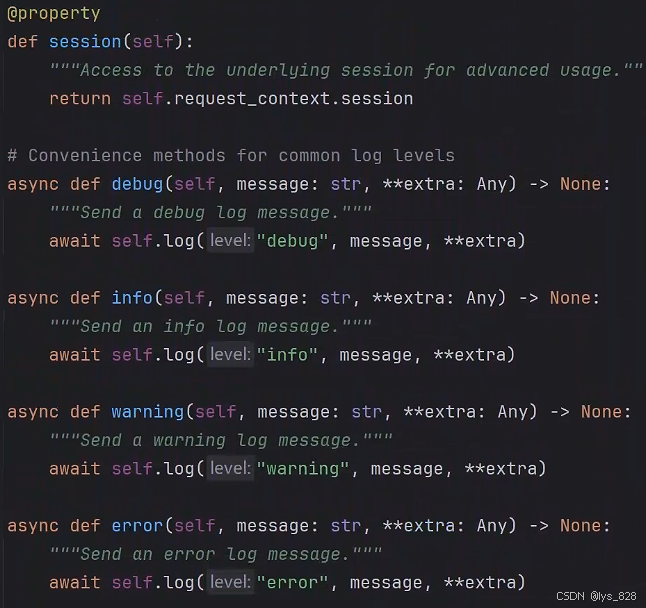
2.2 客戶端
2.2.1 客戶端代碼調試
在Log_output文件夾下的client.py文件中,先進行架構的搭建
import asyncio
from mcp.client.sse import sse_client
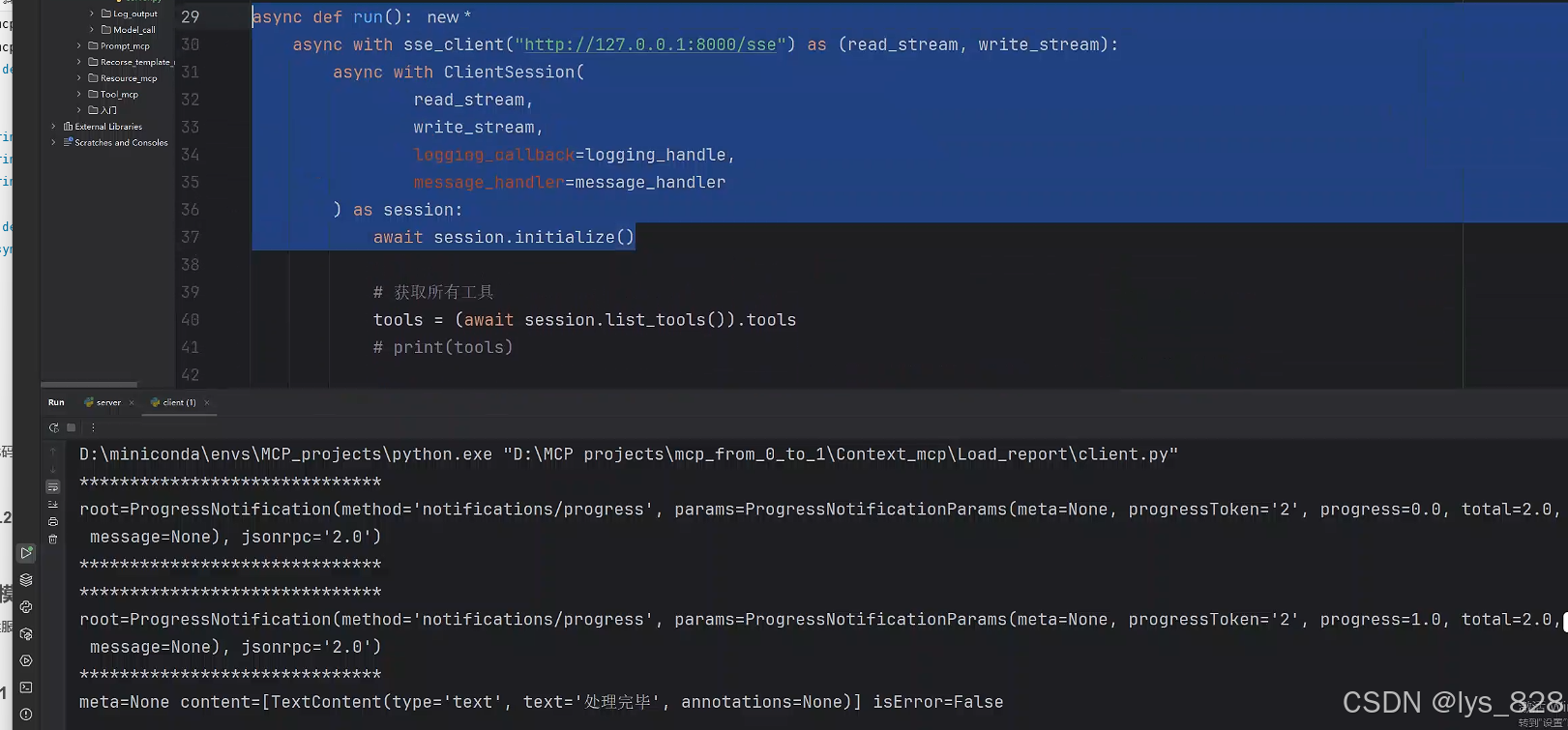
from mcp import ClientSessionasync def run():async with sse_client("http://127.0.0.1:8000/sse") as (read_stream, write_stream):async with ClientSession(read_stream, write_stream) as session:await session.initialize()# 獲取所有工具tools = (await session.list_tools()).toolsprint(tools)if __name__ == "__main__":asyncio.run(run())
執行結果如下:(以上代碼是之前項目中都使用的框架,熟悉的操作,就看是不是結果可以正常輸出)
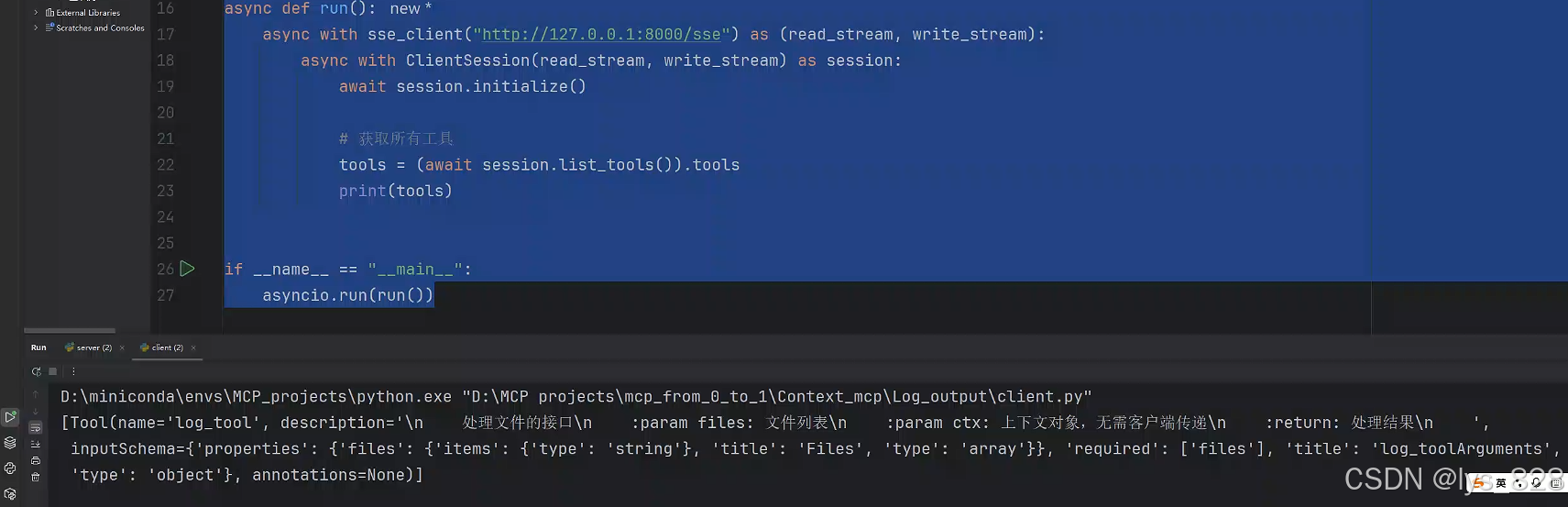
目前tool工具對象中只有一個數據,因為進行演示demo,這里可以直接進行列表對象的索引(以往的項目都是遍歷循環)
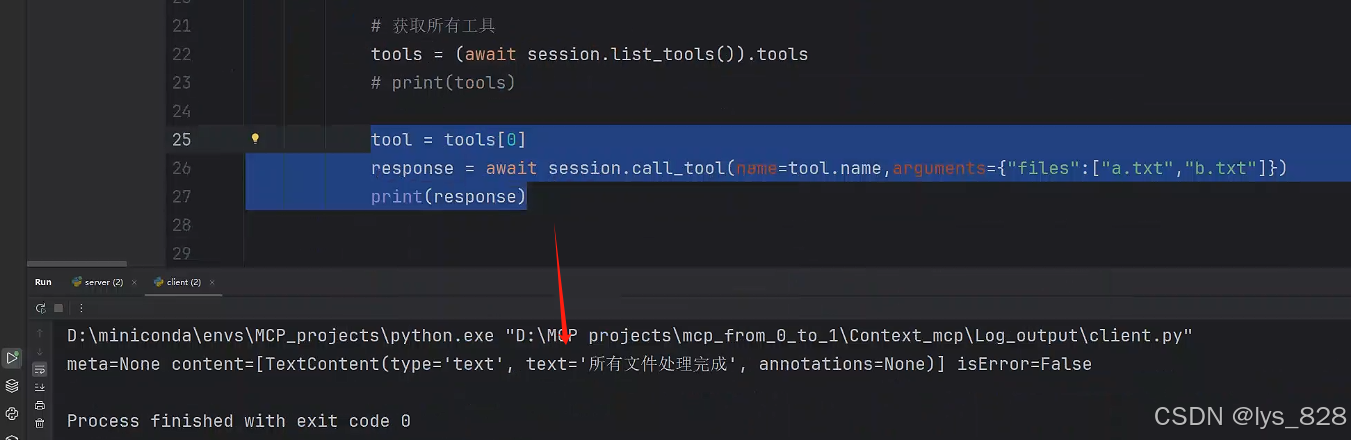
tool = tools[0]
response = await session.call_tool(name=tool.name,arguments={"files":["a.txt","b.txt"]})
print(response)
代碼執行輸出結果如下:(輸出結果中出現“所有文件處理完畢”,說明客戶端中成功調用了服務端中的日志輸出工具)
現在可以成功調用工具,我們的目標是獲取客戶端發過來的日志信息,需要結合這個session中的logging_callback參數。
通過點擊加logging_callback參數j,進入技術文檔,可以發現,這參數需要制定一個回調函數。
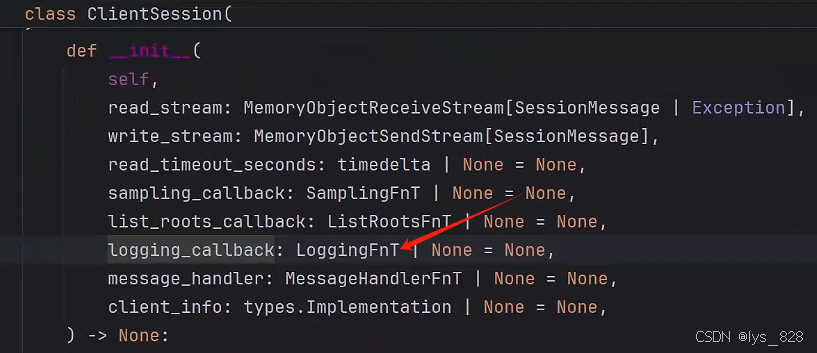
進一步,點擊一個回調函數,查看具體說明,主要查看這個函數需要傳入的參數類別,如下
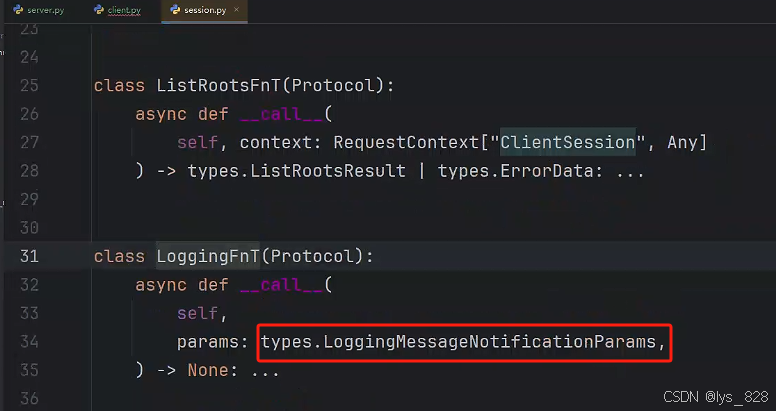
因此,在client.py中定一個回調函數,命名為logging_handle,然后這個函數指定的對應就是上面紅框中的數據對象,然后再把這個回調函數賦值給logging_callback參數,如下
from mcp.types import LoggingMessageNotificationParamsasync def logging_handle(params: LoggingMessageNotificationParams):print(params)async def run():async with sse_client("http://127.0.0.1:8000/sse") as (read_stream, write_stream):async with ClientSession(read_stream,write_stream,logging_callback=logging_handle) as session:await session.initialize()....
執行代碼,輸出結果如下:(此時,我們就可以成功將服務端的信息在客戶端打印出來了,即獲取到客戶端的日志信息)
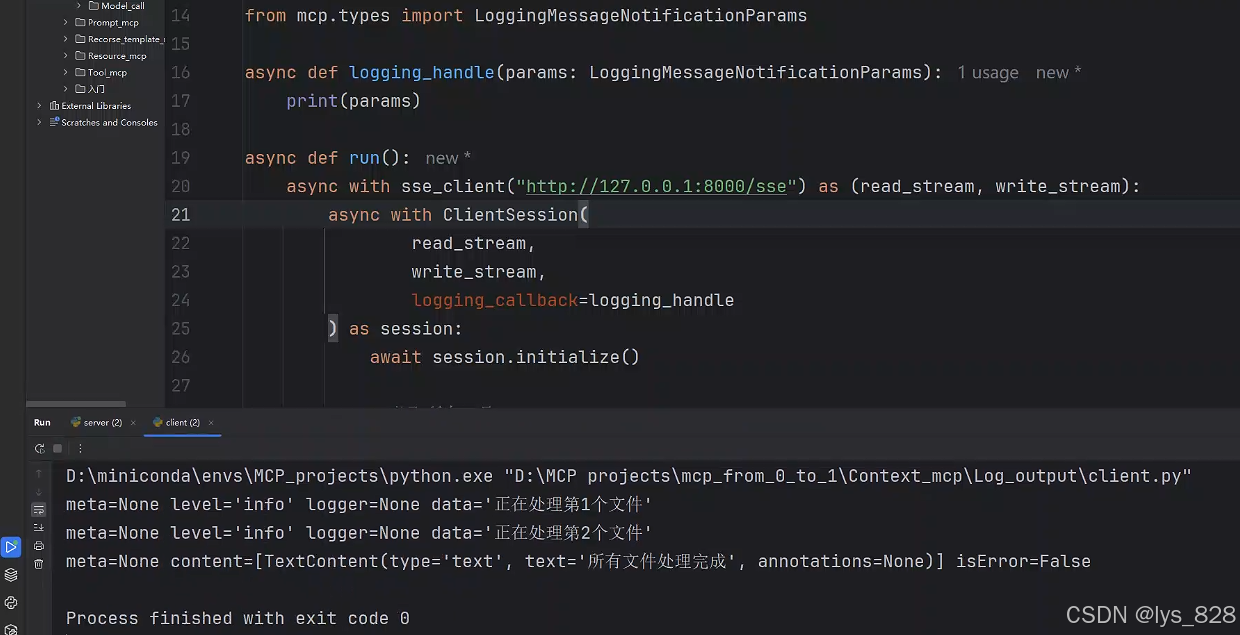
由此,就可以根據自己的需求完成一些日志方面的操作,比如將日志信息保存本地,進行日志操作之間的交互(增加用戶體驗)等。
2.2.2 客戶端全部代碼
給出client.py文件的全部代碼,方便學習理解
import asyncio
from mcp.client.sse import sse_client
from mcp import ClientSession
from mcp.types import LoggingMessageNotificationParamsasync def logging_handle(params: LoggingMessageNotificationParams):print(params)async def run():async with sse_client("http://127.0.0.1:8000/sse") as (read_stream, write_stream):async with ClientSession(read_stream,write_stream,logging_callback=logging_handle) as session:await session.initialize()# 獲取所有工具tools = (await session.list_tools()).tools# print(tools)tool = tools[0]response = await session.call_tool(name=tool.name,arguments={"files":["a.txt","b.txt"]})print(response)if __name__ == "__main__":asyncio.run(run())
3. 進度匯報
當服務端的代碼在處理一些耗時操作時,可以向客戶端實時反饋執行的進度。可以通過report_process()函數進行設置
3.1 服務端
在Load_report文件夾下的server.py文件中,輸入代碼如下
import asyncio
from mcp.server.fastmcp import FastMCP,Context
from mcp.types import RequestParamsmcp: FastMCP = FastMCP()@mcp.tool()
async def load_task(files:list[str],ctx: Context):'''處理多個文件進行進度匯報:param files: 多個文件路徑:param ctx: 上下文對象,無需客戶端傳遞:return: 處理結果'''for index,file in enumerate(files):await asyncio.sleep(1)ctx.request_context.meta = RequestParams.Meta(progressToken=ctx.request_id)await ctx.report_progress(index,len(files))return "處理完畢"if __name__ == '__main__':mcp.run(transport="sse")
代碼中,關于調用ctx.report_progress()函數前,需要添加一行代碼ctx.request_context.meta = RequestParams.Meta(),具體原因可以通過查看ctx.report_progress()函數技術文檔,如下(這個函數中有一個progress_token參數,如果這個參數的賦值為None,這調用函數直接返回為空,相當于函數不會發送信息。而要求函數發送信息,則要求progress_token參數不為None,進一步找到前面的request_context.meta參數,這個值不能為None,然后就返回request_context.meta.progressToken對象)
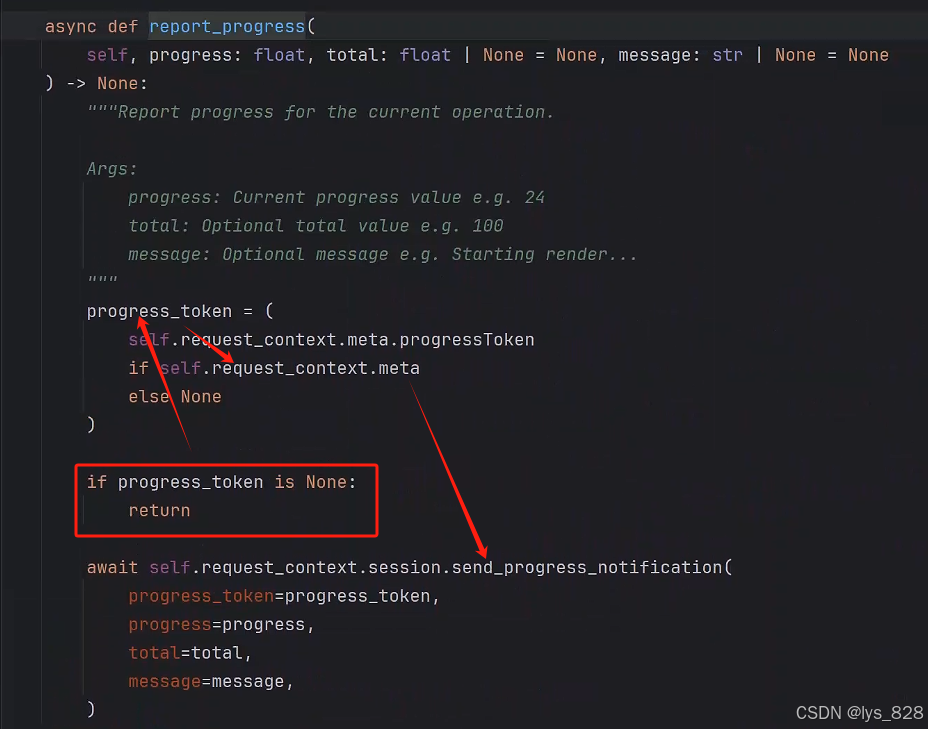
進一步點擊request_context.meta.progressToken,查看它的技術文檔,可以發現這個參數下還是一個函數嵌套。
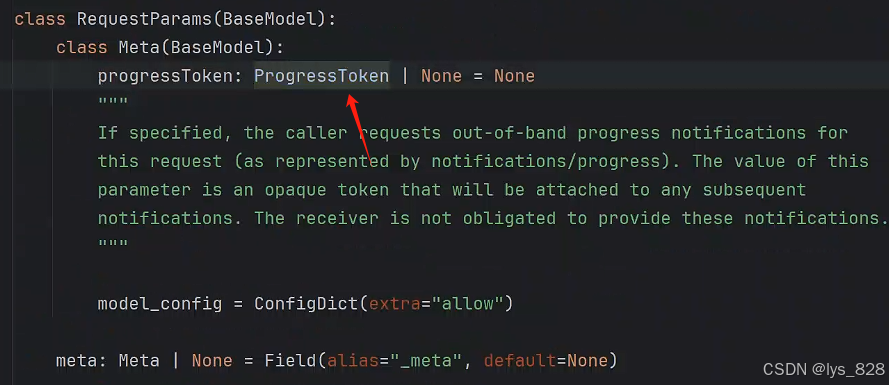
進一步點擊函數,進入下一次技術文檔,如下(可知這個進度的Token需要指定一個字符串或者整形的數據,避免None值出現)
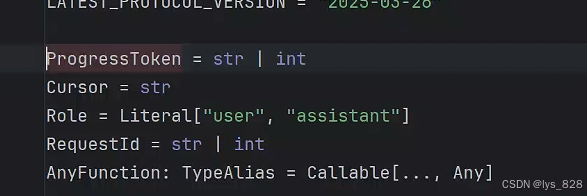
因此,為了在執行ctx.report_progress()函數前,添加一行代碼ctx.request_context.meta = RequestParams.Meta(),而且里面的這個參數設置需要時唯一的,這里采用的就是每一個請求的id。 做開發項目,最有趣的過程就是在進行探索的過程,這個過程自己過一遍后,收獲感會很充實。
3.2 客戶端
3.2.1 客戶端代碼調試
在Load_report文件夾下的client.py文件中,與前面的日志輸出類似,這里也有一個message_handler參數進行回調。同樣,進入該參數的技術文檔,查看詳細說明,如下
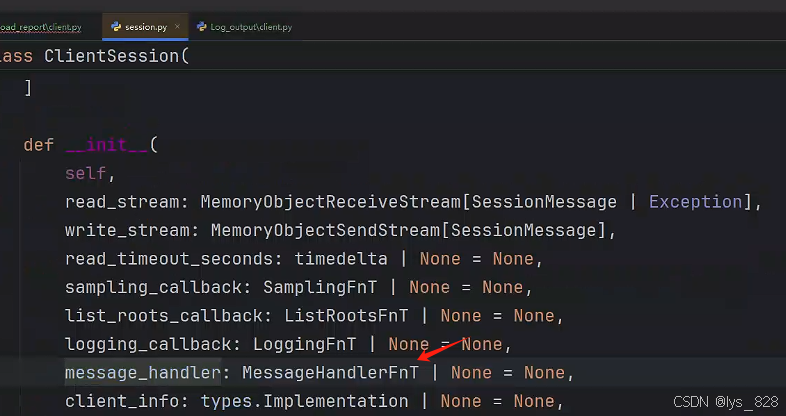
進一步點擊進去,查看詳細說明,如下(該函數回調只有一個參數,就是message,可接受三種數據類型)
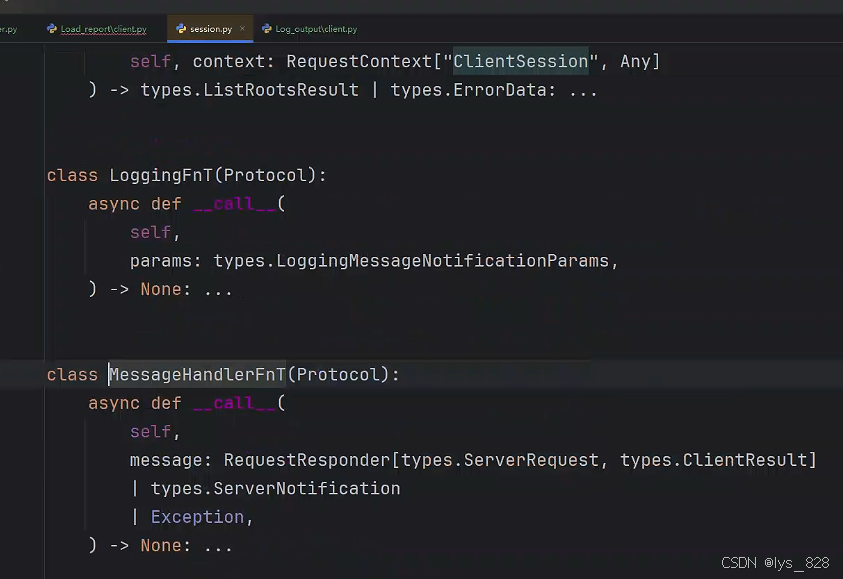
因此在定義回調函數時候,指定傳入的參數類型設置,可以直接把技術文檔中的說明復制過來,如下
from mcp.types import LoggingMessageNotificationParams,ServerNotification,ClientResult,ServerRequest
from mcp.client.session import RequestResponder
async def message_handler(message: RequestResponder[ServerRequest, ClientResult]| ServerNotification| Exception):print("*"*30)print(message)print("*" * 30)async def run():async with sse_client("http://127.0.0.1:8000/sse") as (read_stream, write_stream):async with ClientSession(read_stream,write_stream,logging_callback=logging_handle,message_handler=message_handler #這個參數設置) as session:await session.initialize()
執行代碼輸出結果如下:(可以輸出加載信息)
3.2.2 客戶端全部代碼
import asyncio
from mcp.client.sse import sse_client
from mcp import ClientSession
from mcp.types import LoggingMessageNotificationParams,ServerNotification,ClientResult,ServerRequest
from mcp.client.session import RequestResponderasync def message_handler(message: RequestResponder[ServerRequest, ClientResult]| ServerNotification| Exception):print("*"*30)print(message)print("*" * 30)async def run():async with sse_client("http://127.0.0.1:8000/sse") as (read_stream, write_stream):async with ClientSession(read_stream,write_stream,logging_callback=logging_handle,message_handler=message_handler) as session:await session.initialize()# 獲取所有工具tools = (await session.list_tools()).tools# print(tools)tool = tools[0]response = await session.call_tool(name=tool.name,arguments={"files":["a.txt","b.txt"]})print(response)if __name__ == "__main__":asyncio.run(run())
4. 模型調用
有時候服務端可能需要調用大模型的能力,那么可以使用MCP提供的sampling功能來實現。(注意是服務端調用大模型能力,之前項目都是客戶端調用大模型來執行服務端中的Tool)
4.1 服務端
在Mdel_call文件夾下的server.py文件中,具體實現就是調用Context對象下面的session.create_message()函數
"""import asyncio
from mcp.server.fastmcp import FastMCP,Context
from mcp.types import SamplingMessage, TextContentmcp: FastMCP = FastMCP()@mcp.tool()
async def sampling_tool(ctx:Context):# 直接發送一個Sampling的消息response = await ctx.session.create_message(max_token=2048,messages=[SamplingMessage(role="user",content=TextContent(type="text",text="請幫我按照主題“2025年高考”為主題寫兩篇詩詞"))])print(response)return "采樣成功"if __name__ == '__main__':mcp.run(transport="sse")
關于函數中具體參數的配置,也可以參考本博客中前2個案例,都是通過技術文檔中的說明,逐步進行完善,然后填寫完整,這個過程不是要背具體的方式,而是要學會具體的方法。比如這里對于大模型能力的應用,知道借助上下文Context對象下面的session.create_message()函數創建就可以了,然后就是具體的參數設置直接借助說明文檔快速完成。
4.2 客戶端
4.2.1 客戶端代碼調試
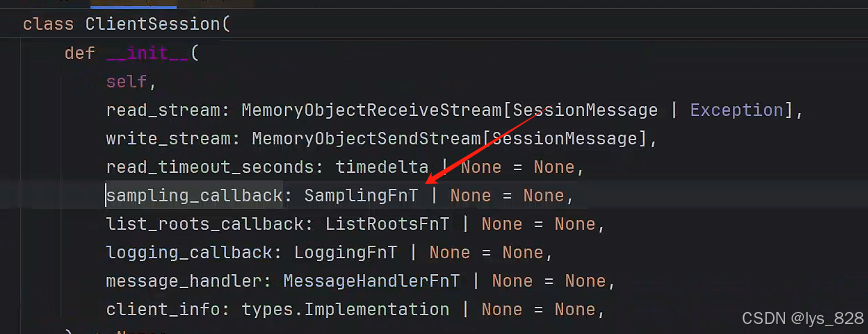
在Mdel_call文件夾下的client.py文件中,客服端中對應的就是sampling_callback參數完成
點擊該參數,進入技術文檔,如下
然后進入下一級的技術文檔,如下(此時就出現了具體的參數和數據類型了)
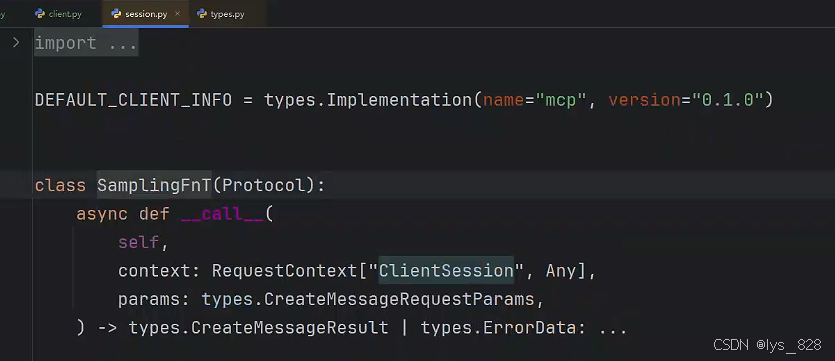
在客戶端,新定一個函數為sampling_handler(),然后把上圖中的下面介紹兩個參數及對應的數據類型的代碼全部復制到創建的函數中。還需要注意,技術文檔中回調函數需要返回CreateMessageResult數據類型。我們可以先手動創建一個類數據對象,如下
from mcp.types import CreateMessageRequestParams, TextContent, CreateMessageResult
from mcp.client.session import RequestContext
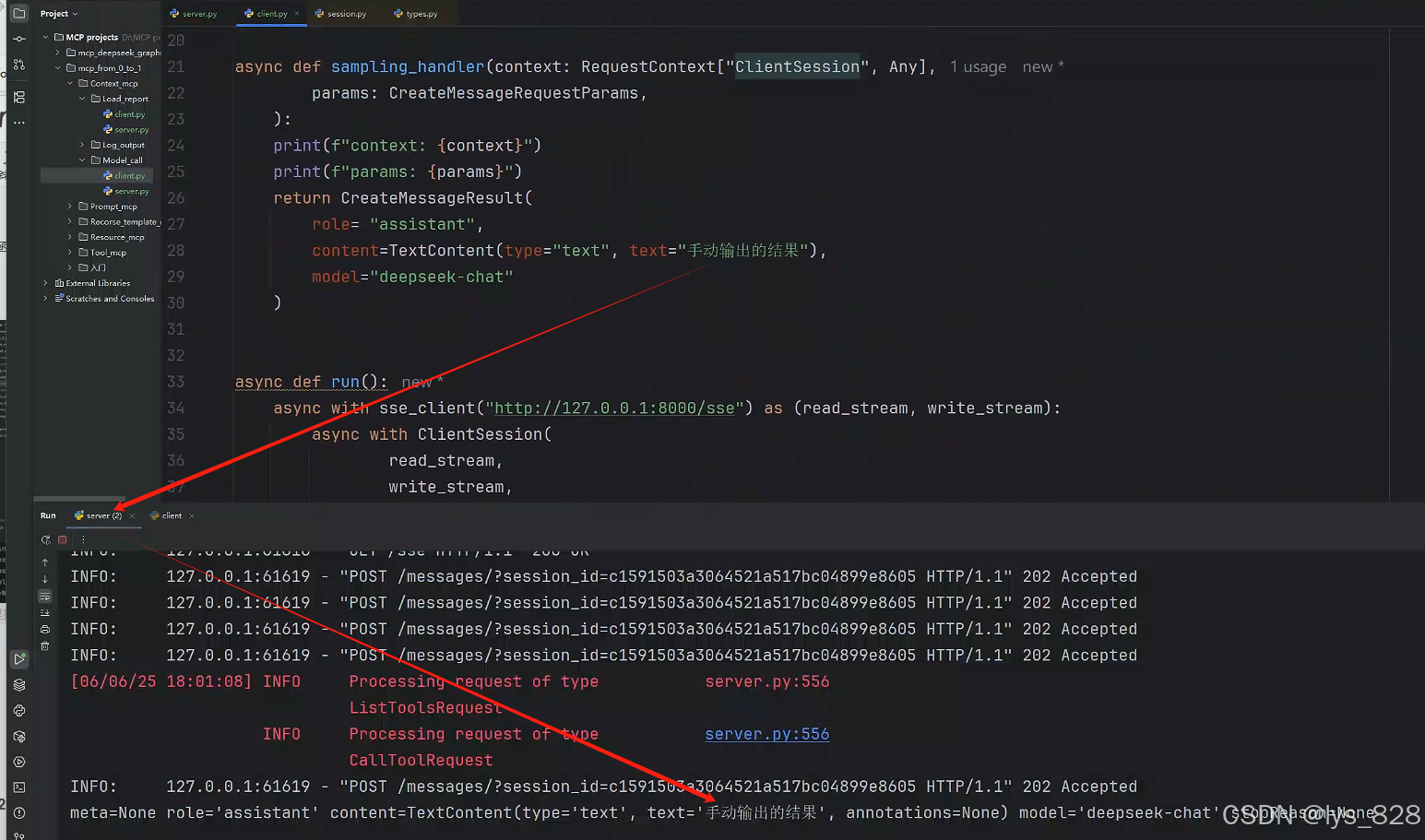
async def sampling_handler(context: RequestContext["ClientSession", Any],params: CreateMessageRequestParams,):print(f"context: {context}")print(f"params: {params}")return CreateMessageResult(role= "assistant", # 大模型返回的信息,此時的角色對應的是assistantcontent=TextContent(type="text", text="手動輸出的結果"),model="deepseek-chat")
將回調函數復制給對應的參數后,執行客戶端代碼,結果輸出如下(檢查客戶端輸出沒有報錯,然后服務端出現自己手動創建的CreateMessageResult數據,即證明代碼可以跑通)
客戶端:
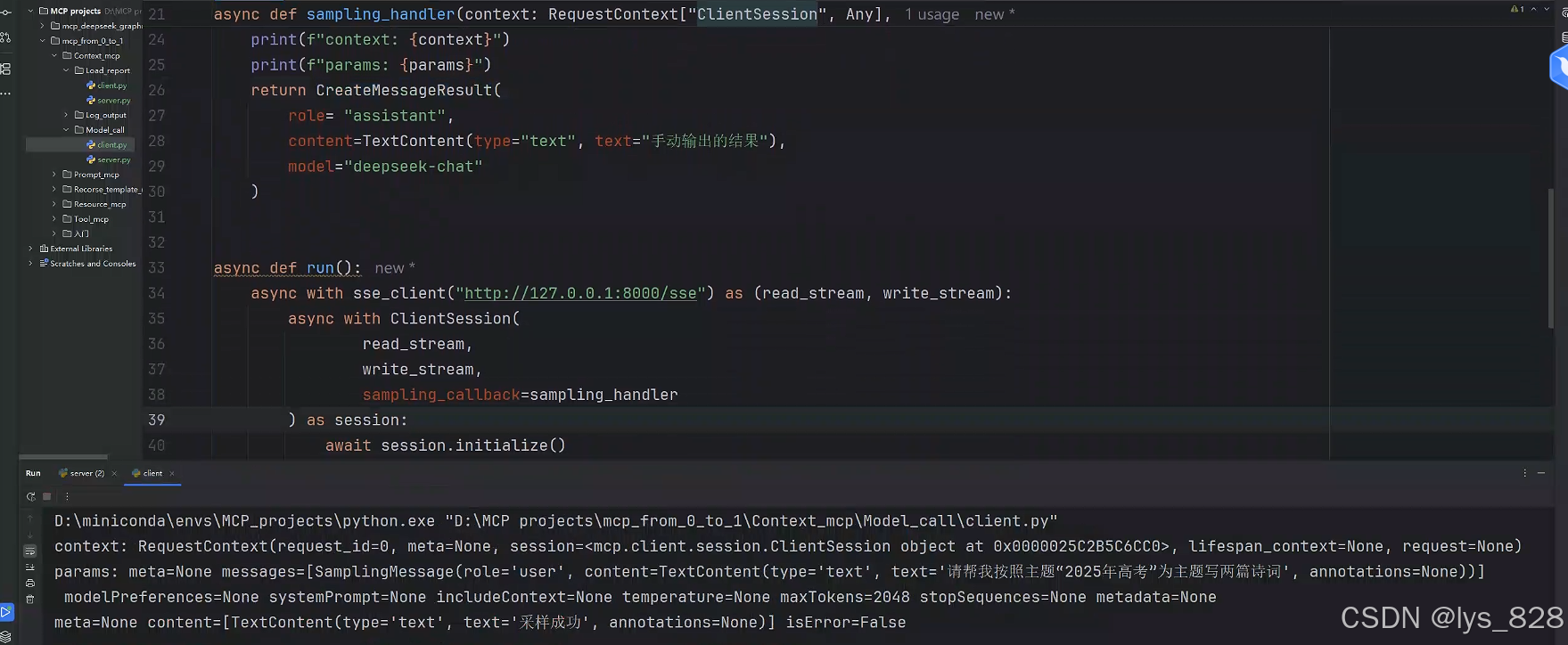
服務端:
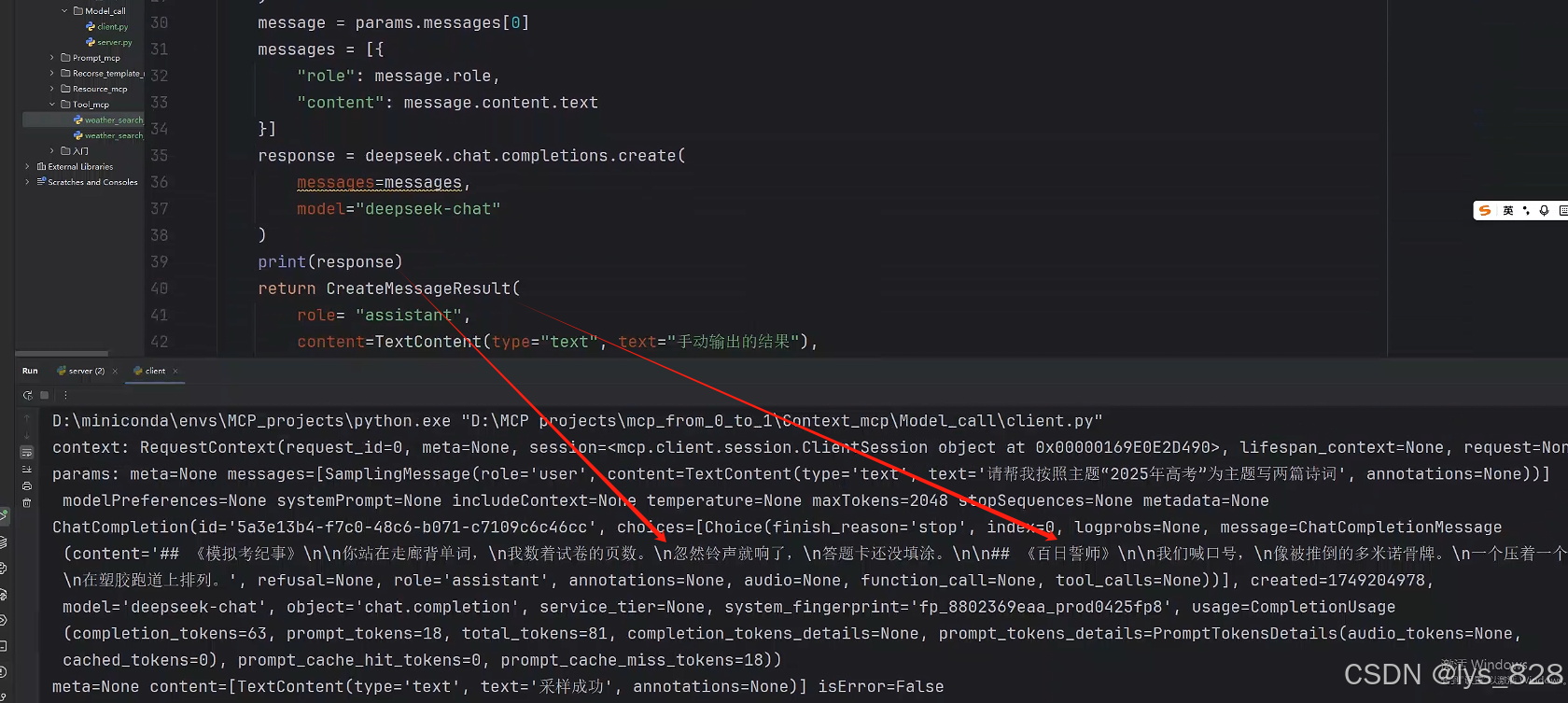
那么接下來,就是換用加入大模型,讓其進行返回結果到服務端,如下(關于message變量的賦值,可以參考上圖客戶端輸出結果進行獲取,由此而進一步獲得對應的role和content內容)
async def sampling_handler(context: RequestContext["ClientSession", Any],params: CreateMessageRequestParams,):print(f"context: {context}")print(f"params: {params}")deepseek = OpenAI(api_key="sk-5d307e0xxxxx5a6ce4575ff9",base_url="https://api.deepseek.com",)message = params.messages[0] messages = [{"role": message.role,"content": message.content.text}]response = deepseek.chat.completions.create(messages=messages,model="deepseek-chat")print(response)return CreateMessageResult(role= "assistant",content=TextContent(type="text", text="手動輸出的結果"),model="deepseek-chat")
這里執行代碼,輸出如下(此時,只是測試代碼是否正常運行,輸出的結果是在客戶端的輸出窗口)
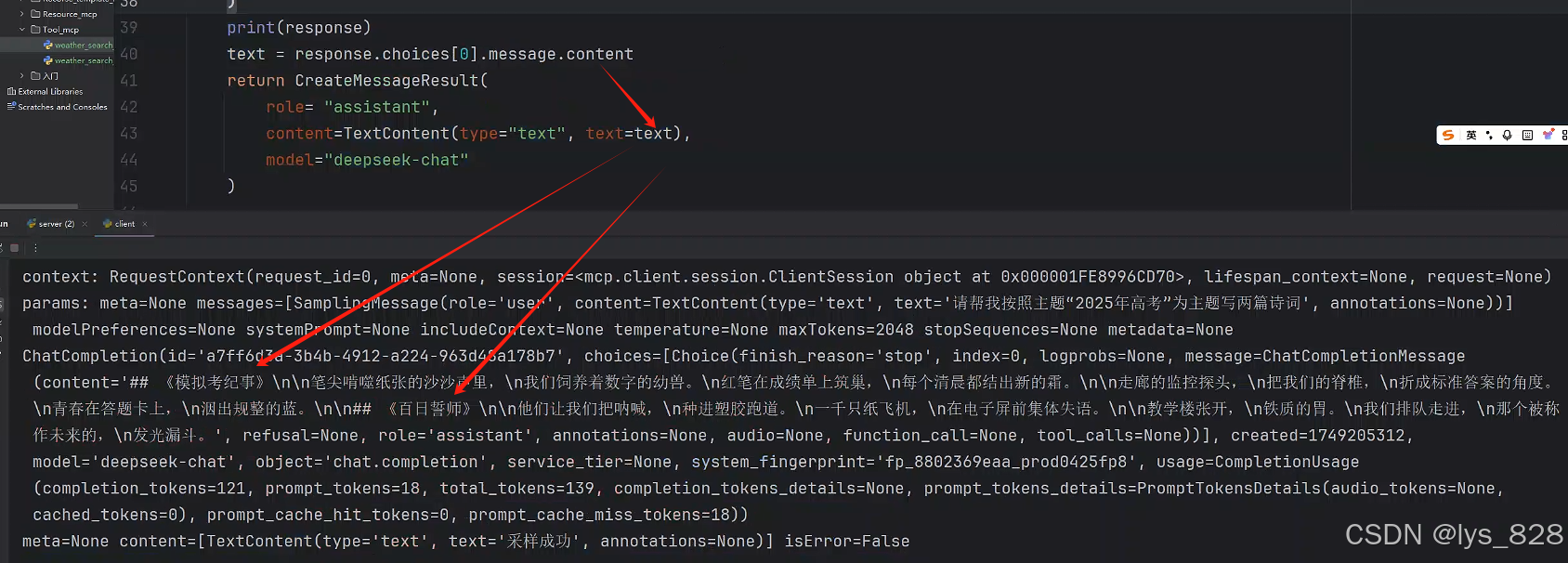
最后,就是把return中返回的結果使用response變量中的數據進行替換(根據上圖的輸出結果,逐步進行獲取里面content內容),即可,代碼如下
print(response)
text = response.choices[0].message.content
return CreateMessageResult(role= "assistant",content=TextContent(type="text", text=text),model="deepseek-chat"
重新執行客戶端的代碼,輸出結果如下
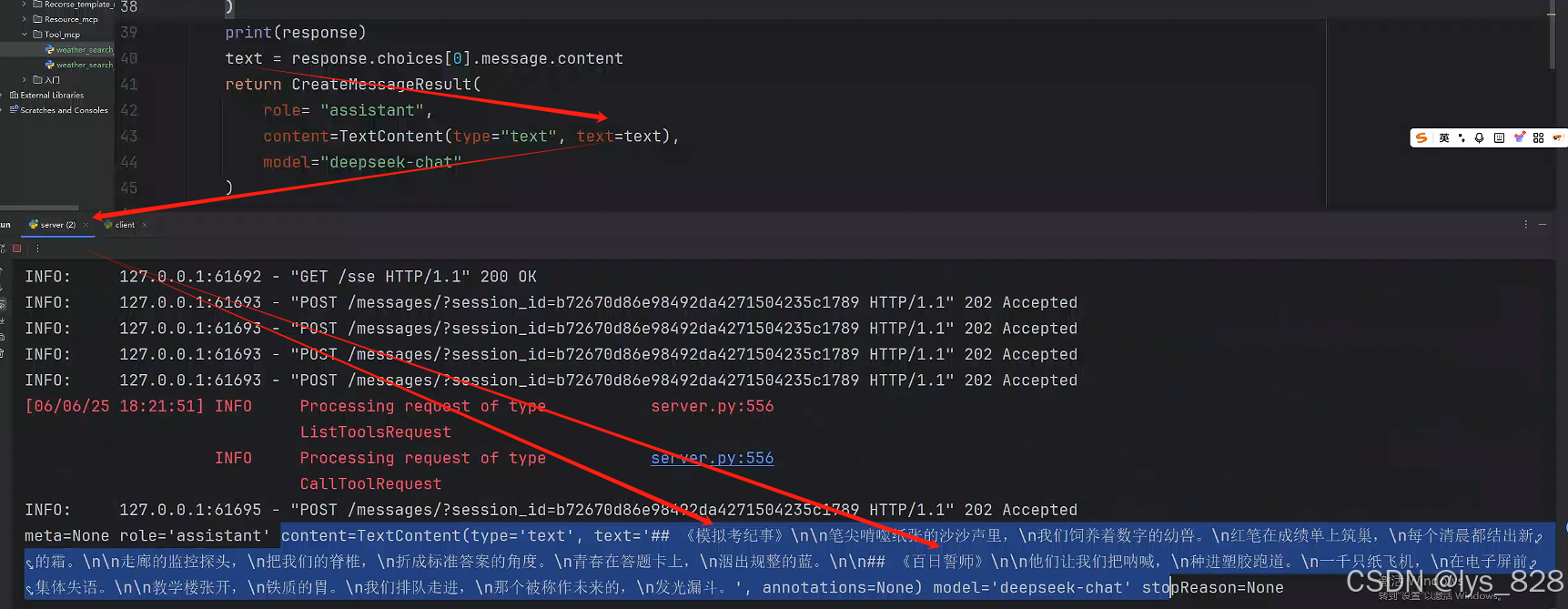
當客戶端的代碼運行完畢后,此時,點擊服務端的輸出窗口,檢查是否可以獲取到客戶端調用大模型輸出的結果,如下(完美獲取想要的結果)
4.2.2 客戶端全部代碼
在強調一遍,這個項目是服務端獲取客戶端調用大模型返回的結果,這里是功能實現,具體后續的擴展開發就任憑需求了。
"""
-------------------------------------------------------------------------------
@Project : MCP projects
File : client.py
Time : 2025-06-05 17:20
author : musen
Email : xianl828@163.com
-------------------------------------------------------------------------------
"""import asyncio
from typing import Any
from mcp.client.sse import sse_client
from mcp import ClientSession
from mcp.types import CreateMessageRequestParams, TextContent, CreateMessageResult
from mcp.client.session import RequestContext
from openai import OpenAIasync def sampling_handler(context: RequestContext["ClientSession", Any],params: CreateMessageRequestParams,):print(f"context: {context}")print(f"params: {params}")deepseek = OpenAI(api_key="sk-5d307e0a45xxxxx4575ff9",base_url="https://api.deepseek.com",)message = params.messages[0]messages = [{"role": message.role,"content": message.content.text}]response = deepseek.chat.completions.create(messages=messages,model="deepseek-chat")print(response)text = response.choices[0].message.contentreturn CreateMessageResult(role= "assistant",content=TextContent(type="text", text=text),model="deepseek-chat")async def run():async with sse_client("http://127.0.0.1:8000/sse") as (read_stream, write_stream):async with ClientSession(read_stream,write_stream,sampling_callback=sampling_handler) as session:await session.initialize()# 獲取所有工具tools = (await session.list_tools()).tools# print(tools)tool = tools[0]response = await session.call_tool(name=tool.name) #服務端的tool中函數沒有參數arguments,這里就不需要指定print(response)if __name__ == "__main__":asyncio.run(run())
至此,關于 MCP中的Context的日志輸出、進度匯報和服務端調用客戶端的大模型輸出結果的三個項目的實戰詳細梳理就完結了,撒花??ヽ(°▽°)ノ?。

![[華為eNSP] OSPF綜合實驗](http://pic.xiahunao.cn/[華為eNSP] OSPF綜合實驗)


P95+P96+P97+P98+P99+P100+P101)

)
)



)



技術的實現原理與應用場景解析)



: 循環神經網絡(RNN))